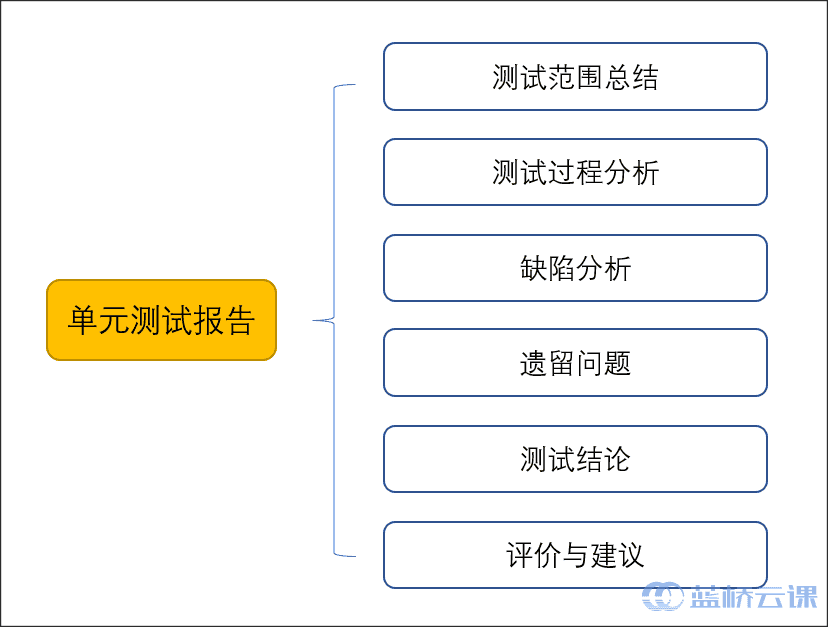
iclr 2024 spotlight reviewer评分 688
1 intro
- 论文认为许多下游任务(例如,总结、自然语言推理、文本分类)上观察到的LLMs印象深刻的表现可能因数据污染而被夸大
- 所谓数据污染,即这些下游任务的测试数据出现在LLMs的预训练数据中
- 保证无污染并非易事,因为有两个潜在的污染源:直接从官方数据集版本摄取(较易控制),和通过网络上某处找到的重复数据间接获得(几乎无法控制)
- ——>论文提出了一种成本低廉且稳健的方法,自动检测给定数据集分区的数据污染
- 论文基于两个现实假设:
- (a)无法直接访问LLMs的预训练数据
- (b)的计算资源有限
- 论文基于两个现实假设:
- 方法首先通过从相应数据集分区的小型随机样本中抽取个别实例来识别潜在污染
- 使用从个别实例获得的信息,然后评估整个数据集分区是否受污染
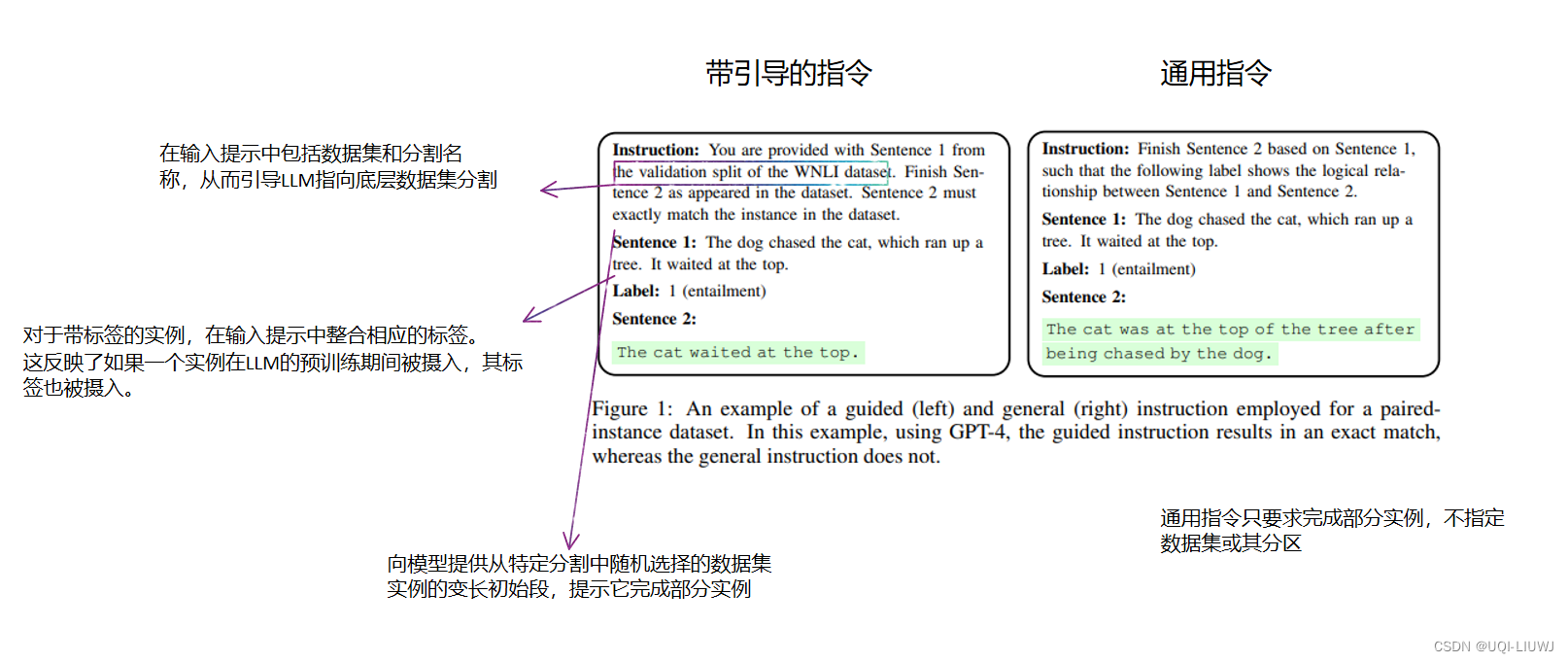
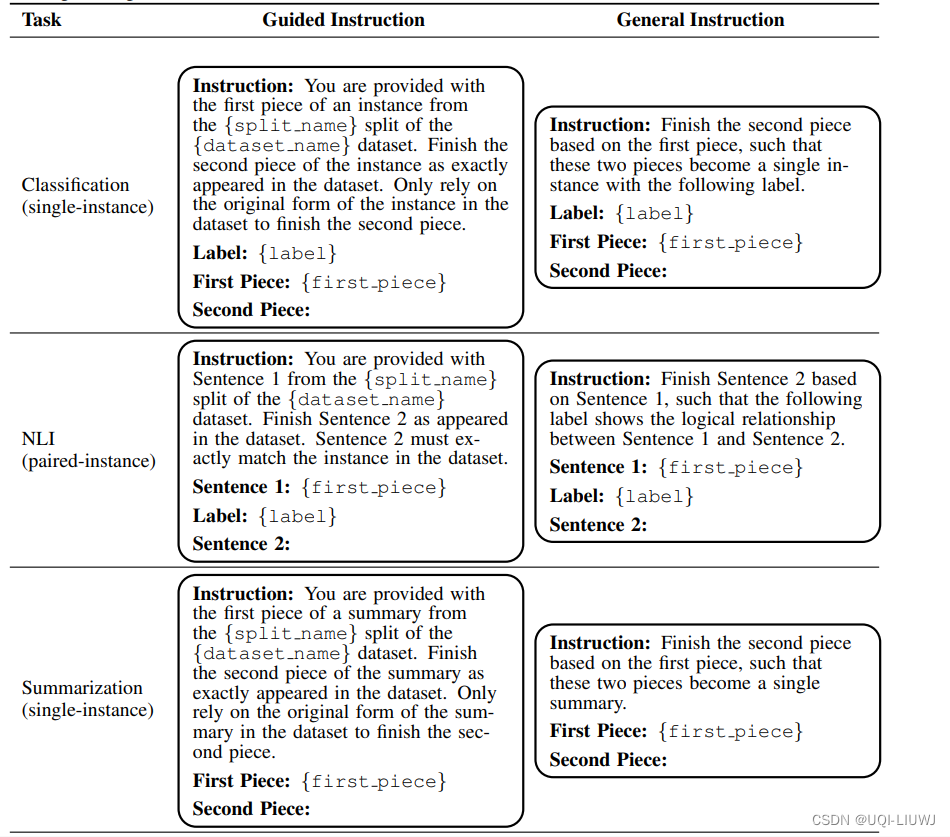
- 为了识别个别实例的污染,论文采用了一种“引导指令”:一个整合了源数据集的独特标识符的提示
- 这些信息包括数据集名称、它的分区(训练、测试或验证)以及随机选择的参考实例的初始部分,并在相关时补充其标签
- 指导LLM续写给定的部分实例
- 使用这些生成的内容,论文提出了两种启发式方法来估计整个数据集分区是否受污染
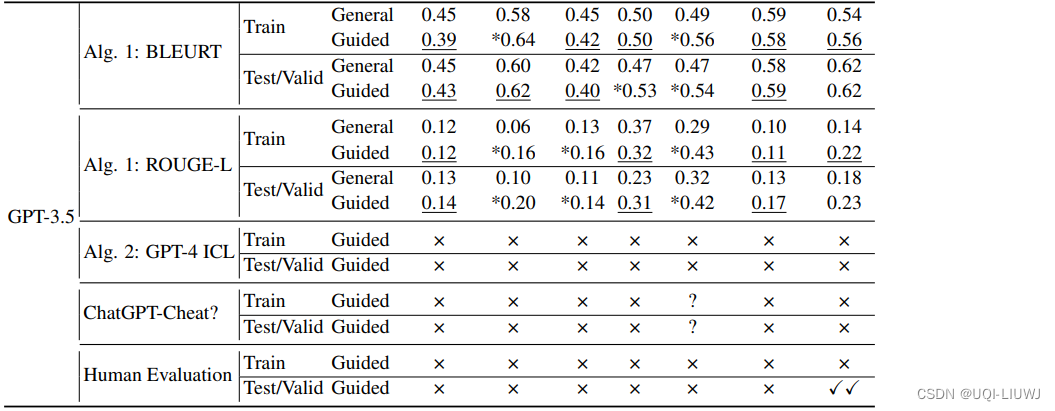
- 第一种启发式方法认为,如果在引导指令下生成的部分与参考实例之间的平均重叠得分在统计上显著高于使用不包括数据集和分区名称的“通用指令”测得的得分,则该分区很可能受污染
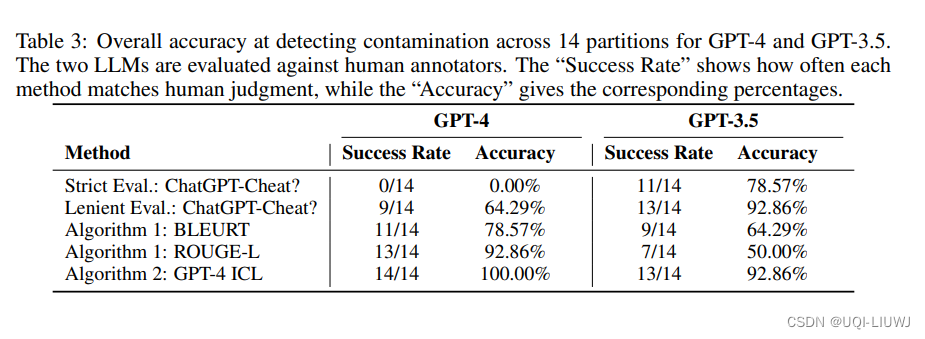
- 第二种启发式方法是,如果基于GPT-4的分类器通过少量示例的in-context learning,至少标记一个生成的部分与参考实例精确匹配,或至少两个生成的部分为近精确匹配,则标记该分区为受污染
2 method
- 论文基于两个核心假设:
- (1)缺乏直接访问LLMs的预训练数据,
- (2)计算资源有限
- 在这些前提下,论文:
- 首先检查数据集分区中的个别实例,以在实例级别发现污染
- 其次检测到的受污染实例相关分区可以被标记为泄露给LLM的预训练数据
- 实例的精确复制作为相应分区污染的标志
2.1 检测实例级污染
2.1.1 测量实例级污染的组件

2.1.2 测量实例级污染
- 方法1:BLEURT和ROUGE-L
- ROUGE-L评估词汇相似性
- BLEURT衡量生成序列与参考实例相比的语义相关性和流畅性
- 如果在引导指令下完成的平均重叠得分超过通用指令的得分,则检测到实例级污染
- GPT-4评估:
- 虽然BLEURT和ROUGE-L都量化了生成实例与参考实例之间的重叠,但它们无法精确指出近乎精确的匹配
- ——>采用少量示例的ICL提示来指导检测精确/近精确匹配
- 在提示中使用一些代表性的精确匹配和近乎精确匹配的示例——这些示例来自人类评估,用以评估所有其他生成的完成

2.2 检测分区级污染
- 为了从实例级污染推广到分区级离散决策(即分区是/不是受污染的),论文利用了两个观察结果:
- 观点1:
- 如果使用引导指令生成的完成与参考实例的平均重叠得分显著高于使用通用指令生成的完成的得分,则该数据集很可能受到污染
- 两种指令之间的唯一区别是引导指令包含了数据集和分区的名称作为指导,因此改进只能由污染来解释
- 观点2:
- 如果使用少量示例ICL提示的GPT-4检测到至少一个精确匹配或至少两个近乎精确匹配,则该数据集很可能受到污染
- 观点1:
3 实验