Python学习从0开始——项目一day01爬虫`(二)`
- 一、解析response数据
- 二、json转换
- 三、文件保存
- 四、存储json对象
- 五、完整代码
上一篇
一、解析response数据
在已经知道我们获取图片的最终URL存在于请求响应response中,下一步的重点就放在解析response。
首先给出现在的代码,以下代码暂时删除了图片写入的部分,在文章末尾会给出完整的爬虫代码。
#coding=utf-8
#!/usr/bin/python
# 导入requests库
import requests
# 导入文件操作库
import os
import bs4
from bs4 import BeautifulSoup
import sys
import importlib
importlib.reload(sys)
import re
import json
import urllib.parse
# 给请求指定一个请求头来模拟chrome浏览器
global headers
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36'}
# 爬图地址
mziTu = 'https://image.baidu.com/'
# 定义存储位置
global save_path
save_path ='./picture'
# 创建文件夹
def createFile(file_path):
if os.path.exists(file_path) is False:
os.makedirs(file_path)
# 切换路径至上面创建的文件夹
os.chdir(file_path)
# 下载文件
def download(page_no, file_path):
global headers
res_sub = requests.get(page_no, headers=headers)
# 解析html
soup_sub = BeautifulSoup(res_sub.text, 'html.parser')
# 获取页面的栏目地址
all_a = soup_sub.find('div',id='bd-home-content-album').find_all('a',target='_blank')
count = 0
for a in all_a:
count = count + 1
if (count % 2) == 0:
print("内页第几页:" + str(count))
# 提取href
href = a.attrs['href']
print("套图地址:" + href)
res_sub_1 = requests.get(href, headers=headers)
soup_sub_1 = BeautifulSoup(res_sub_1.text, 'html.parser')
# 主方法
def main():
res = requests.get(mziTu, headers=headers)
# 使用自带的html.parser解析
soup = BeautifulSoup(res.text, 'html.parser')
# 创建文件夹
createFile(save_path)
file = save_path
createFile(file)
print("开始执行")
download(mziTu, file)
if __name__ == '__main__':
main()
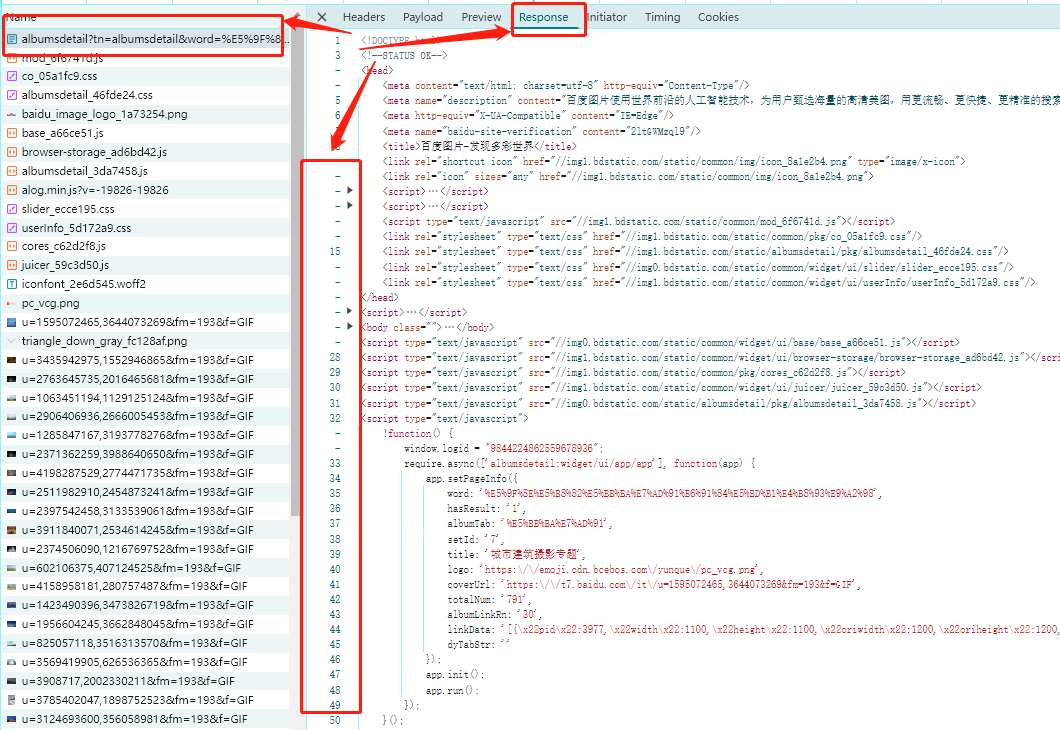
在谷歌浏览器中,折叠代码块,快速定位到我们需要的<script>中,第十三个<script>是linkData所在标签,然后对代码继续修改,在53行添加如下内容:
# 找到所有的<script>标签
scripts = soup_sub_1.find_all('script')
# 第十三个是linkData所在标签
script_content = BeautifulSoup(scripts[12].text, 'html.parser').text
#打印值
print(script_content)
#终端输出如下
!function(){ window.logid = "7865333382831002903";
require.async(['albumsdetail:widget/ui/app/app'], function (app) {
app.setPageInfo({
word: '%E6%B8%90%E5%8F%98%E9%A3%8E%E6%A0%BC%E6%8F%92%E7%94%BB',
hasResult: '1',
albumTab: '%E8%AE%BE%E8%AE%A1%E7%B4%A0%E6%9D%90',
setId: '409',
title: '渐变风格插画',
logo: 'https:\/\/emoji.cdn.bcebos.com\/yunque\/pc_vcg.png',
coverUrl: 'https:\/\/t7.baidu.com\/it\/u=1819248061,230866778&fm=193&f=GIF',
totalNum: '314',
albumLinkRn: '30',
linkData: '[{\x22pid\x22:144520,\x22width\x22:1200,\x22height\x22:562,\x22oriwidth\x22:1200,\x22oriheight\x22:562,\x22thumbnailUrl\x22:\x22https:\\\/\\\/t7.baidu.com\\\/it\\\/u=1819248061,230866778&fm=193&f=GIF\x22,\x22fromUrl\x22:\x22https:\\\/\\\/www.vcg.com\\\/creative\\\/1274231988\x22,\x22contSign\x22:\x221819248061,230866778\x22},{\x22pid\x22:144521,\x22width\x22:562,\x22height\x22:1000,\x22oriwidth\x22:562,\x22oriheight\x22:1000,\x22thumbnailUrl\x22:\x22https:\\\/\\\/t7.baidu.com\\\/it\\\/u=4036010509,3445021118&fm=193&f=GIF\x22,\x22fromUrl\x22:\x22https:\\\/\\\/www.vcg.com\\\/creative\\\/1147957933\x22,\x22contSign\x22:\x224036010509,3445021118\x22},……]
经过以上操作,成功的获取了linkData所在的<script>,下一步是获取linkData,我们通过正则来获取数据:
# 使用正则表达式来查找linkData的值
link_data_pattern = r"linkData: '([^']*)'"
match = re.search(link_data_pattern, script_content)
#查看输出
print(match)
#终端输入
python3 spider.py
#终端输出
<re.Match object; span=(605, 10524), match="linkData: '[{\\x22pid\\x22:144520,\\x22width\\x22>
这看起来并不符合我们的预期,我们期望的输出是linkData里的值。
这时,我们需要关注re.search(),其返回结果是一个捕获组,可以通过group()来获取每一组的数据,group(1) 表示获取第一个捕获组的内容。如果没有捕获组或者索引超出了捕获组的范围,group() 方法会抛出 IndexError 异常。
将输出替换为以下内容:
print(match.group(1))
#终端输入
python3 spider.py
#捕获组终端输出
[{\x22pid\x22:144520,\x22width\x22:1200,\x22height\x22:562,\x22oriwidth\x22:1200,\x22oriheight\x22:562,\x22thumbnailUrl\x22:\x22https:\\\/\\\/t7.baidu.com\\\/it\\\/u=1819248061,230866778&fm=193&f=GIF\x22,\x22fromUrl\x22:\x22https:\\\/\\\/www.vcg.com\\\/creative\\\/1274231988\x22,\x22contSign\x22:\x221819248061,230866778\x22},^}
下一步需要将捕获组的内容转为我们可以使用的数据。
二、json转换
为什么要将捕获组转换成json数据,什么情况下需要我们转为json数据?
看上方的捕获组输出,我们能明显的识别出这些数据具有统一的属性,直接截取字符串需要经过多次split或者replace,如果通过属性去获取值,会很便于我们操作。
#继续添加如下内容
if match:
# 获取第一个捕获组的内容
encoded_link_data = match.group(1)
print(encoded_link_data)
# 解析JSON对象
link_data_list = json.loads(encoded_link_data)
else:
print("未能找到linkData的值")
继续执行代码:
#终端输入
python3 spider.py
#终端输出
Traceback (most recent call last):
File "/root/Python_02/Python/Day01/learn/spider.py", line 98, in <module>
main()
File "/root/Python_02/Python/Day01/learn/spider.py", line 95, in main
download(mziTu, file)
File "/root/Python_02/Python/Day01/learn/spider.py", line 70, in download
link_data_list = json.loads(encoded_link_data)
File "/usr/lib/python3.9/json/__init__.py", line 346, in loads
return _default_decoder.decode(s)
File "/usr/lib/python3.9/json/decoder.py", line 337, in decode
obj, end = self.raw_decode(s, idx=_w(s, 0).end())
File "/usr/lib/python3.9/json/decoder.py", line 353, in raw_decode
obj, end = self.scan_once(s, idx)
json.decoder.JSONDecodeError: Expecting property name enclosed in double quotes: line 1 column 3 (char 2)
根据提示,我们知道现在无法解析为json数据。我们来看一下json的示例数据格式:
[{
"name":"a",
"age":1
},{
"name":"b",
"age":2
}]
显而易见,问题出在双引号上,那么下一步就需要将’\x22’字串替换为双引号。
#修改赋值
encoded_link_data = match.group(1).replace('\x22', '"')
此时,我们会发现,经过替换后仍旧报相同的错误,而且终端的输出的encoded_link_data 值和替换前没有区别。
为什么呢?
再来观察’\x22’,我们能发现它是一个转义序列,用于表示一个ASCII值为0x22的字符,即双引号,Python会通过转义序列将其解释为双引号,这就造成实际上是双引号替换双引号,故输出不变。而我们并不需要这种转义,我们需要Python将其解释为普通的字符串。
#修改赋值,同时替换双引号和斜杠的转义
encoded_link_data = match.group(1).replace(r'\x22', '"').replace(r'\\\/', '/')
#encoded_link_data = match.group(1).replace('\x22', '"')
print(encoded_link_data)
# 解析JSON对象
link_data_list = json.loads(encoded_link_data)
#终端输入
cd Python/Day01/learn/
python3 spider.py
#输出,数据正常
[{"pid":144520,"width":1200,"height":562,"oriwidth":1200,"oriheight":562,"thumbnailUrl":"https://t7.baidu.com/it/u=1819248061,230866778&fm=193&f=GIF","fromUrl":"https://www.vcg.com/creative/1274231988","contSign":"1819248061,230866778"},……]
三、文件保存
link_data_list现在已经存储了json数据,我们通过get方法获取对应的URL值,然后发送请求获取响应,继续添加以下内容:
#添加到if match: 里
for item in link_data_list:
# 提取thumbnailUrl字段的值
thumbnail_url = item.get('thumbnailUrl')
res_sub_2 = requests.get(thumbnail_url, headers=headers)
soup_sub_2 = BeautifulSoup(res_sub_2.text, "html.parser")
print("开始提取图片")
file_name = thumbnail_url
f = open(file_name, 'ab')
f.write(soup_sub_2)
f.close()
#终端执行
python3 spider.py
#终端输出
开始提取图片
Traceback (most recent call last):
File "/root/Python_02/Python/Day01/learn/spider.py", line 103, in <module>
main()
File "/root/Python_02/Python/Day01/learn/spider.py", line 100, in main
download(mziTu, file)
File "/root/Python_02/Python/Day01/learn/spider.py", line 79, in download
f = open(file_name, 'ab')
FileNotFoundError: [Errno 2] No such file or directory: 'https://t7.baidu.com/it/u=1819248061,230866778&fm=193&f=GIF'
使用初始代码的方法行不通,可能是因为没加文件类型,我们做一些小更改:
f = open(file_name+'.jpg', 'wb')
还报错,按照文件的输入输出来说我们的操作是正常的,符合流程的,问题会不会还是出现在文件名?
换个名字试一下。
f = open('a.jpg', 'ab')
#终端执行
python3 spider.py
#终端输出
Traceback (most recent call last):
File "/root/Python_02/Python/Day01/learn/spider.py", line 105, in <module>
main()
File "/root/Python_02/Python/Day01/learn/spider.py", line 102, in main
download(mziTu, file)
File "/root/Python_02/Python/Day01/learn/spider.py", line 82, in download
f.write(soup_sub_2)
TypeError: a bytes-like object is required, not 'BeautifulSoup'
虽然还是报错,但是报错内容变了,那现在可以确定,问题出现在文件名,对于Python来说,它本身并不直接限制文件名以"https"开头。但是,当我们试图创建、读取或操作一个文件时,实际上是在与底层的操作系统和文件系统交互。因此,真正限制使用"https"作为文件名开头的因素来自这些底层系统。知道原因后,我们就能解决问题了。
同时根据以上终端输出的内容,可以知道f.write()需要的是字节对象,而不是我们现在赋值的BeautifulSoup类型。继续修改:
file_name = thumbnail_url.replace(r'https://t7.baidu.com/it/u=','')
f = open(file_name+'.jpg', 'ab')
f.write(res_sub_2.content)
这次正常执行了,来看一下输出的文件:
四、存储json对象
#修改代码
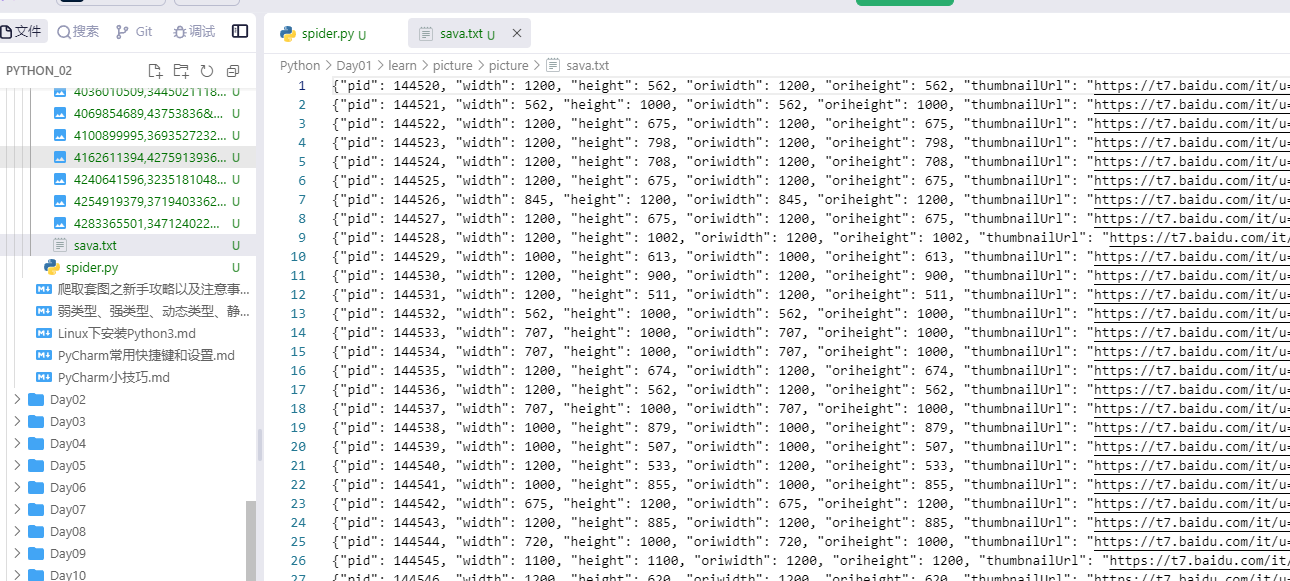
#添加行,存储数据,json数据以字符串形式存储,不是二进制
data = open('sava.txt', 'a')
if match:
# 获取第一个捕获组的内容
# 提取匹配到的linkData字符串,字符替换时一定要使用r
encoded_link_data = match.group(1).replace(r'\x22', '"').replace(r'\\\/', '/')
#encoded_link_data = match.group(1).replace('\x22', '"')
#print(encoded_link_data)
# 解析JSON对象
link_data_list = json.loads(encoded_link_data)
for item in link_data_list:
# 提取thumbnailUrl字段的值
thumbnail_url = item.get('thumbnailUrl')
res_sub_2 = requests.get(thumbnail_url, headers=headers)
soup_sub_2 = BeautifulSoup(res_sub_2.text, "html.parser")
print("开始提取图片")
file_name = thumbnail_url
# f = open(file_name, 'ab')
# f = open(file_name+'.jpg', 'ab')
# f = open('a.jpg', 'ab')
file_name = thumbnail_url.replace(r'https://t7.baidu.com/it/u=','')
f = open(file_name+'.jpg', 'ab')
# f.write(soup_sub_2)
f.write(res_sub_2.content)
#添加,写入,json转字符串写入
data.write(json.dumps(item)+'\n')
f.close()
else:
print("未能找到linkData的值")
#关闭输入
data.close()
至此,完整的一次爬虫结束。
五、完整代码
代码仅供参考学习使用。
#coding=utf-8
#!/usr/bin/python
# 导入requests库
import requests
# 导入文件操作库
import os
import bs4
from bs4 import BeautifulSoup
import sys
import importlib
importlib.reload(sys)
import re
import json
import urllib.parse
# 给请求指定一个请求头来模拟chrome浏览器
global headers
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36'}
# 爬图地址
mziTu = 'https://image.baidu.com/'
# 定义存储位置
global save_path
save_path ='./picture'
# 创建文件夹
def createFile(file_path):
if os.path.exists(file_path) is False:
os.makedirs(file_path)
# 切换路径至上面创建的文件夹
os.chdir(file_path)
# 下载文件
def download(page_no, file_path):
global headers
res_sub = requests.get(page_no, headers=headers)
# 解析html
soup_sub = BeautifulSoup(res_sub.text, 'html.parser')
# 获取页面的栏目地址
all_a = soup_sub.find('div',id='bd-home-content-album').find_all('a',target='_blank')
count = 0
for a in all_a:
count = count + 1
if (count % 2) == 0:
print("内页第几页:" + str(count))
# 提取href
href = a.attrs['href']
print("套图地址:" + href)
res_sub_1 = requests.get(href, headers=headers)
soup_sub_1 = BeautifulSoup(res_sub_1.text, 'html.parser')
# 找到所有的<script>标签
scripts = soup_sub_1.find_all('script')
# 第十三个是linkData所在标签
script_content = BeautifulSoup(scripts[12].text, 'html.parser').text
#print(script_content)
# 使用正则表达式来查找linkData的值
link_data_pattern = r"linkData: '([^']*)'"
match = re.search(link_data_pattern, script_content)
#print(match)
#print(match.group(1))
data = open('sava.txt', 'a')
if match:
# 获取第一个捕获组的内容
# 提取匹配到的linkData字符串,字符替换时一定要使用r
encoded_link_data = match.group(1).replace(r'\x22', '"').replace(r'\\\/', '/')
#encoded_link_data = match.group(1).replace('\x22', '"')
#print(encoded_link_data)
# 解析JSON对象
link_data_list = json.loads(encoded_link_data)
for item in link_data_list:
# 提取thumbnailUrl字段的值
thumbnail_url = item.get('thumbnailUrl')
res_sub_2 = requests.get(thumbnail_url, headers=headers)
soup_sub_2 = BeautifulSoup(res_sub_2.text, "html.parser")
print("开始提取图片")
file_name = thumbnail_url
# f = open(file_name, 'ab')
# f = open(file_name+'.jpg', 'ab')
# f = open('a.jpg', 'ab')
file_name = thumbnail_url.replace(r'https://t7.baidu.com/it/u=','')
f = open(file_name+'.jpg', 'ab')
# f.write(soup_sub_2)
f.write(res_sub_2.content)
data.write(json.dumps(item)+'\n')
f.close()
else:
print("未能找到linkData的值")
data.close()
# 主方法
def main():
res = requests.get(mziTu, headers=headers)
# 使用自带的html.parser解析
soup = BeautifulSoup(res.text, 'html.parser')
# 创建文件夹
createFile(save_path)
file = save_path
createFile(file)
print("开始执行")
download(mziTu, file)
if __name__ == '__main__':
main()
本来打算继续写存入数据库相关内容,但是MySQL服务器启动要会员,就只加了写数据到文件里,后续可以通过文件导入到数据库,线上就算了。