文章目录
- 一、Hadoop介绍
- 二、Hadoop发展简史
- 三、Hadoop核心组件
- 四、Hadoop架构变迁
- 1、Hadoop 1.0
- 2、Hadoop 2.0
- 3、Hadoop 3.0
- 五、Hadoop集群简介
- 六、Hadoop部署模式
- 七、Hadoop 集群搭建
- 第一步:创建虚拟机
- 第二步:安装Linux镜像
- 第三步:网络配置
- 第四步:模板虚拟机配置要求
- 第五步:克隆两台虚拟机
- 第六步:在模板机上安装JDK
- 第七步:在模板机上安装Hadoop
- 第八步:完全分布式运行模式搭建
- 第九步:集群配置
- 第十步:启动集群
- 第十一步:集群测试
- 第十二步:配置日志的聚集
- 第十二步:编写Hadoop集群常用脚本
- 第十三步:集群时间同步及常用端口号说明
- 面试题
- 参考
一、Hadoop介绍
-
狭义上Hadoop指的是Apache的一款开源软件。
用Java语言实现的开源软件大数据框架
允许使用简单的编程模型进行跨计算机集群对大型数据集进行分布式处理。 -
广义上Hadoop是围绕Hadoop打造的大数据生态圈。

二、Hadoop发展简史
Hadoop是一个开源的分布式数据存储和处理框架,它的发展历史可以追溯到早期的搜索引擎和分布式计算研究。
Hadoop之父: Doug Cutting

Hadoop 起源于Apache Lucene子项目:Nutch
Nutch的设计目标是构建一个大型的全网搜索引擎
Google的三篇论文
《The Google File System》:谷歌分布式文件系统GFS
《MapReduce:Simplified Data Processing on Large Clusters》:谷歌分布式计算框架MapReduce
《Bigtable: A Distributed Storage System for Structured Data》:谷歌结构化数据存储系统
三、Hadoop核心组件
HDFS(Hadoop Distribute File System,分布式文件存储系统):解决海量数据存储
YARN(集群资源管理和任务调度框架):解决资源任务调度
MapReduce(分布式计算框架):解决海量数据计算
Hadoop现状:
HDFS作为分布式文件存储系统,处在 生态圈的底层与核心地位;
YARN作为分布式通用的集群资源管理系统和任务 调度平台,支撑各种计算引擎运行,保证了Hadoop地位;
MapReduce作为大数据生态圈第一代分布式计算引擎,由于自身设计的模型所产生的弊端,导致企业一线 几乎不再直接使用MapReduce进行编程处理,但是很多软件的底层依然在使用MapReduce引擎来处理数据。
四、Hadoop架构变迁

1、Hadoop 1.0
HDFS(分布式文件存储)
MapReduce(资源管理和分布式数据处理)
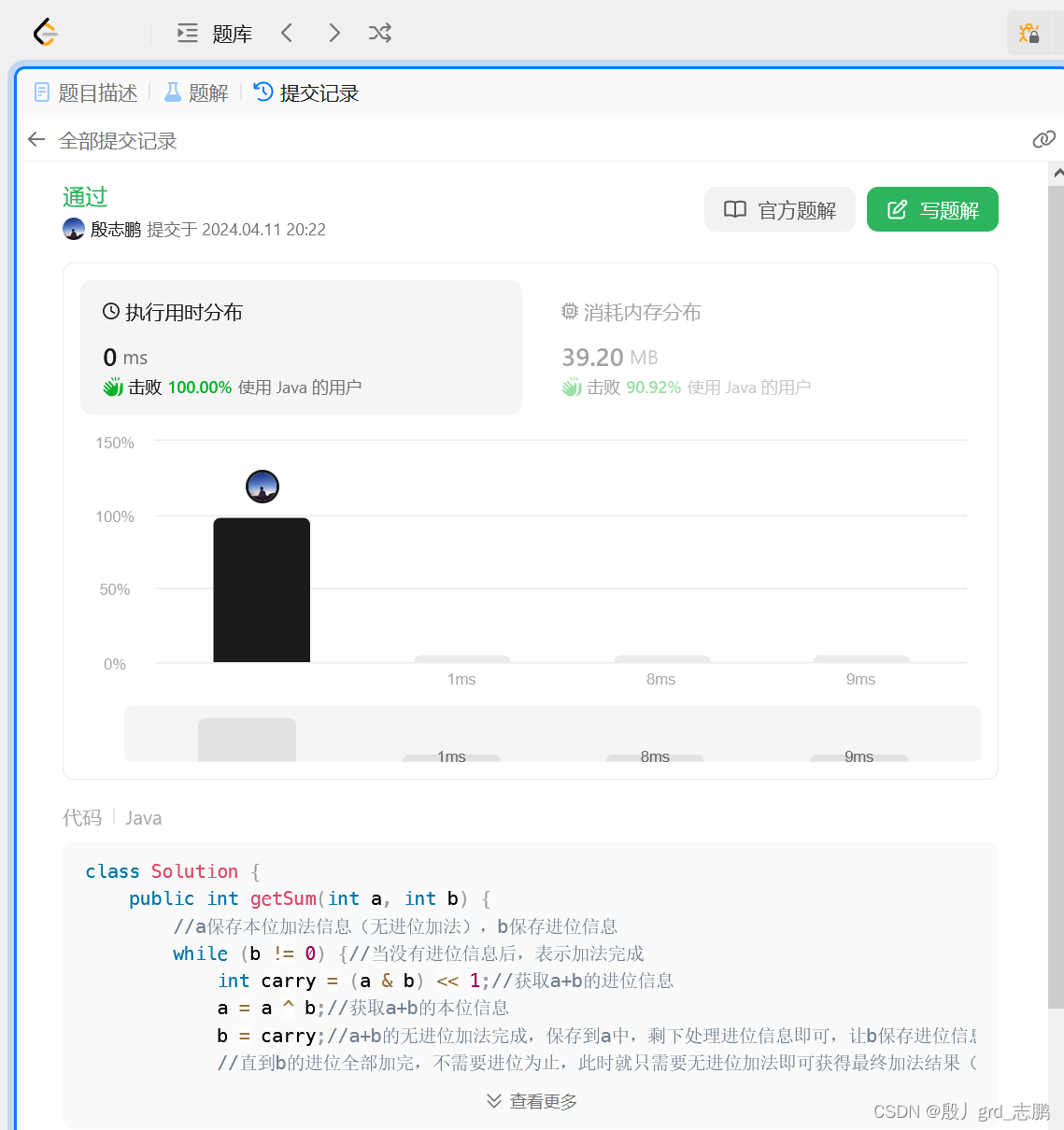
2、Hadoop 2.0
HDFS(分布式文件存储)
MapReduce(分布式数据处理)
YARN(集群资源管理、任务调度)
3、Hadoop 3.0
Hadoop 3.0架构组件和Hadoop 2.0类似,3.0着重于性能优化

五、Hadoop集群简介
Hadoop 集群包括两个集群:HDFS集群、YARN集群
两个集群逻辑上分离、通常物理上在一起
逻辑上分离:两个集群相互之间没依赖、互不影响
物理上在一起:某些角色进程往往部署在同一台物理服务器上
两个集群都是标准的主从架构

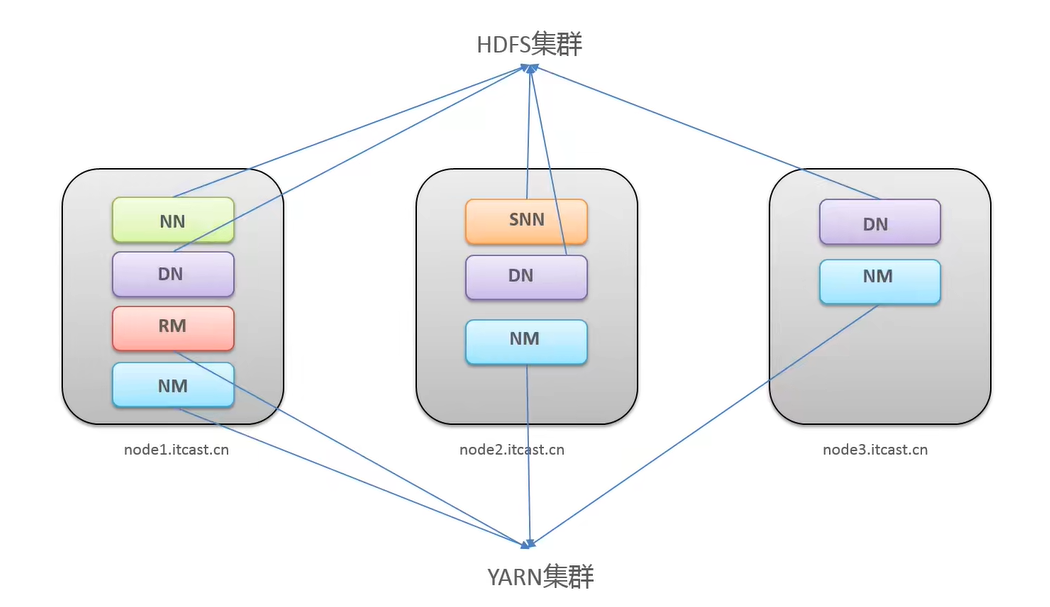
Hadoop 集群 = HDFS集群+YARN集群
角色规划的准则:根据软件工作特性和服务硬件资源情况合理分配
- 资源上有抢夺冲突的,尽量不要部署在一起
- 工作上需要相互配合的,尽量部署在一起
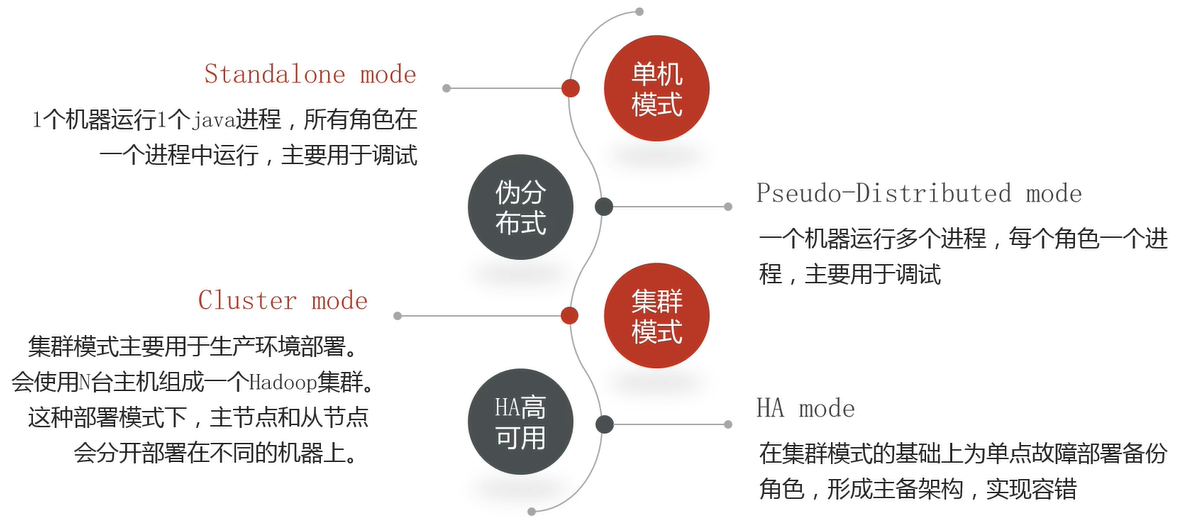
六、Hadoop部署模式
七、Hadoop 集群搭建
https://pan.baidu.com/s/1P5JAtWlGDKMAPWmHAAcbyA,提取码:5h60
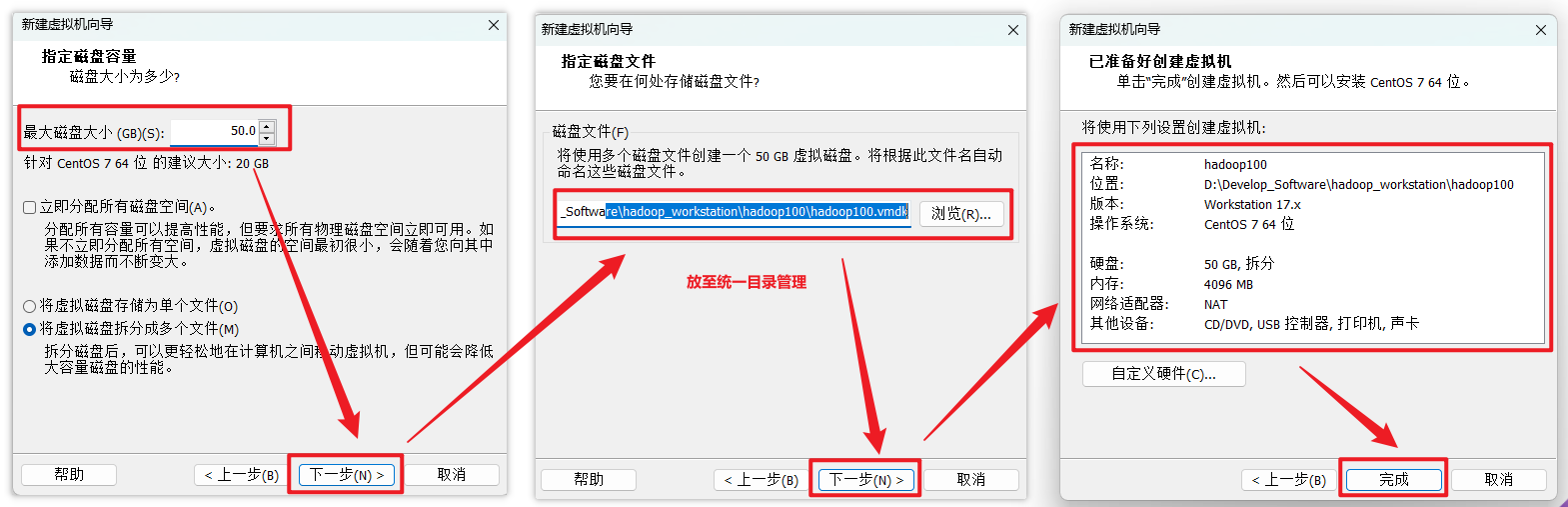
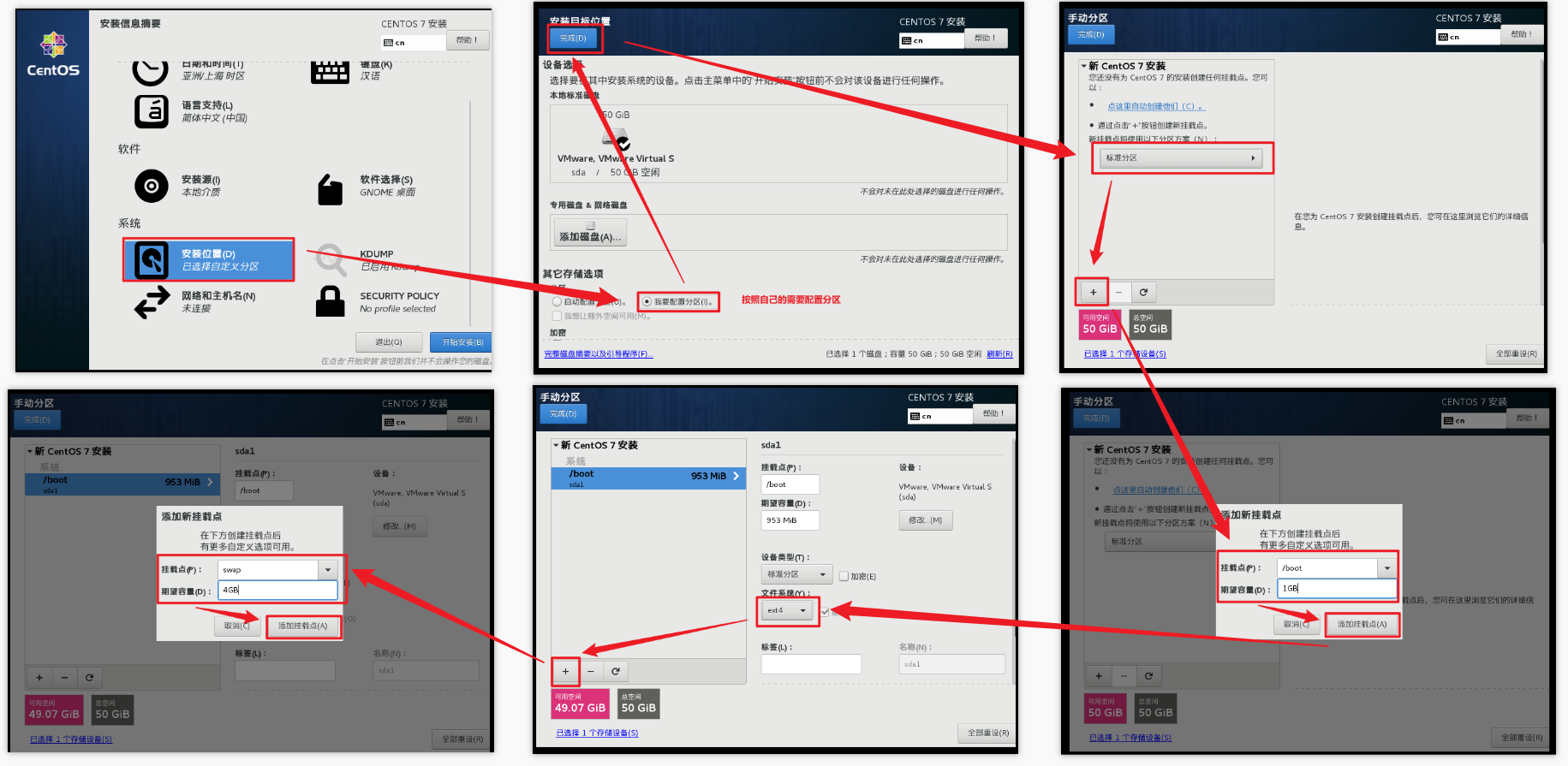
第一步:创建虚拟机
自定义新的虚拟机
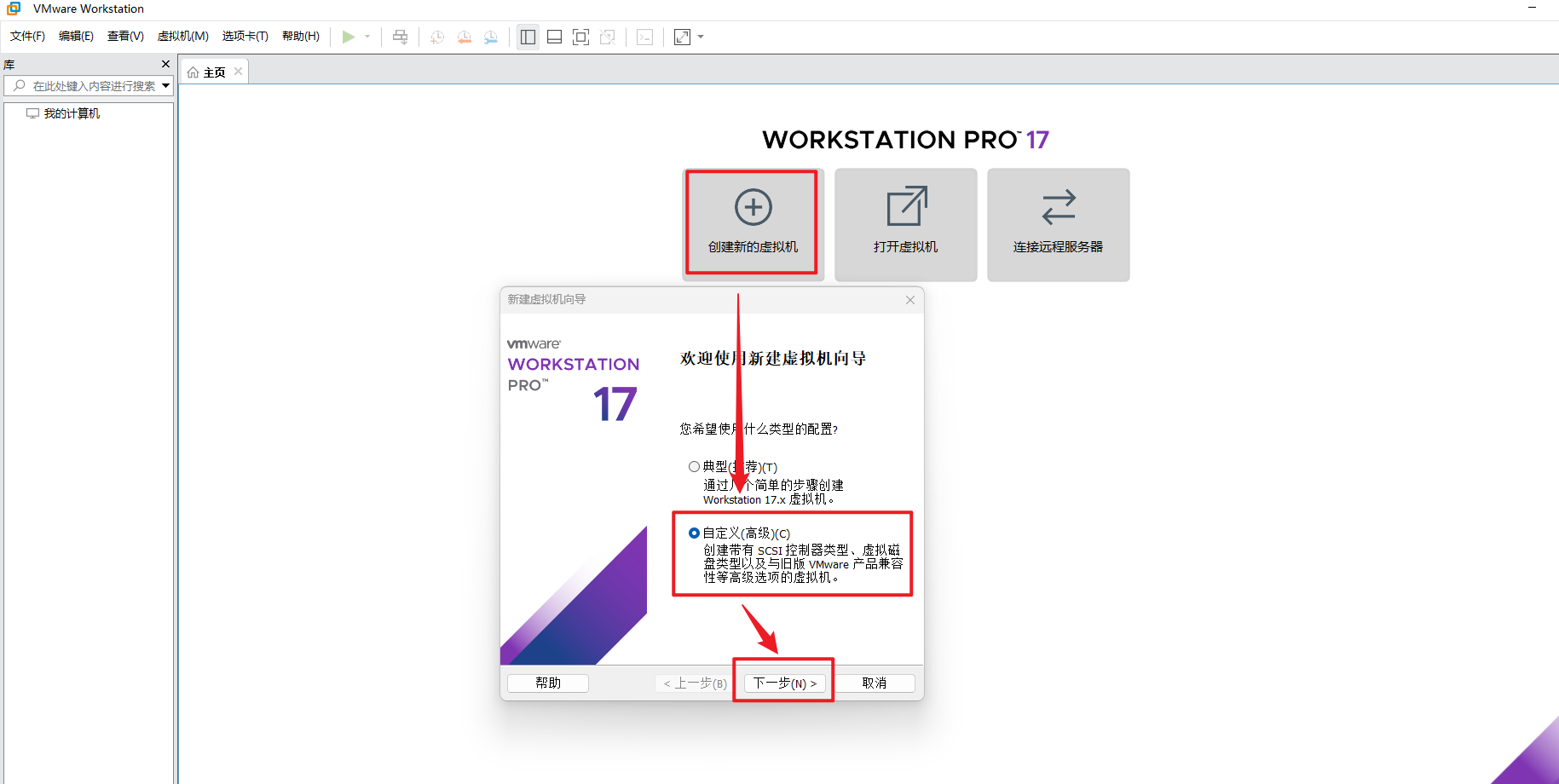
我们先配置电脑(虚拟机),再安装系统,所以选择稍后安装操作系统。
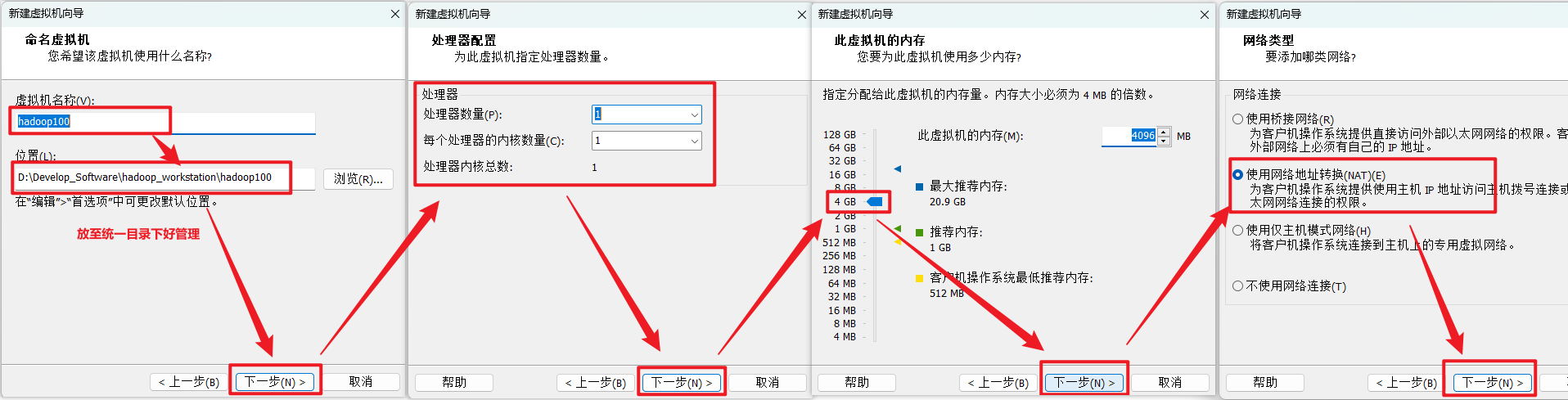
给自己配置电脑(虚拟机)取个名字,并存放在物理机的位置在哪。
建议放至在统一目录下。
设置处理器数量,建议:(处理器数量 * 每个处理器的内核数量 = 处理器内核总数) < 实际处理器数量
内存大小有一定要求,建议4G,不能给太多,后期会有多台虚拟机同时启动。
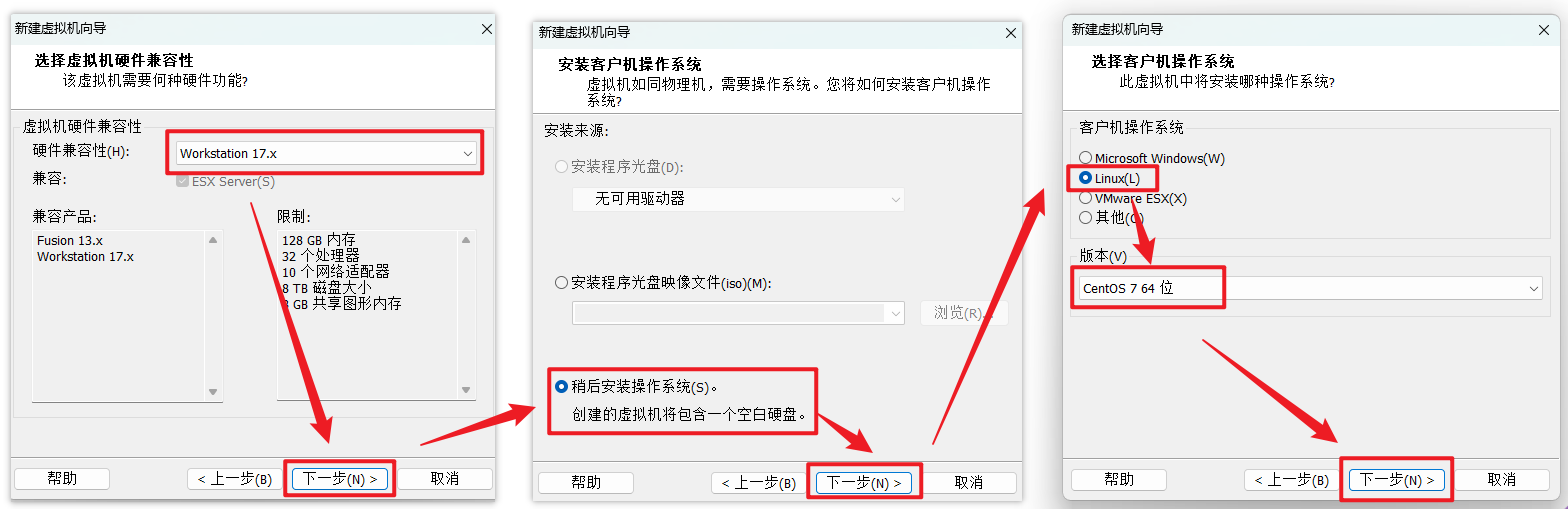
下面的操作默认就行
选择对应的文件系统的IO方式,按推荐的来
选择磁盘的类型,按推荐的来
选择磁盘的种类,选择‘创建新虚拟磁盘’
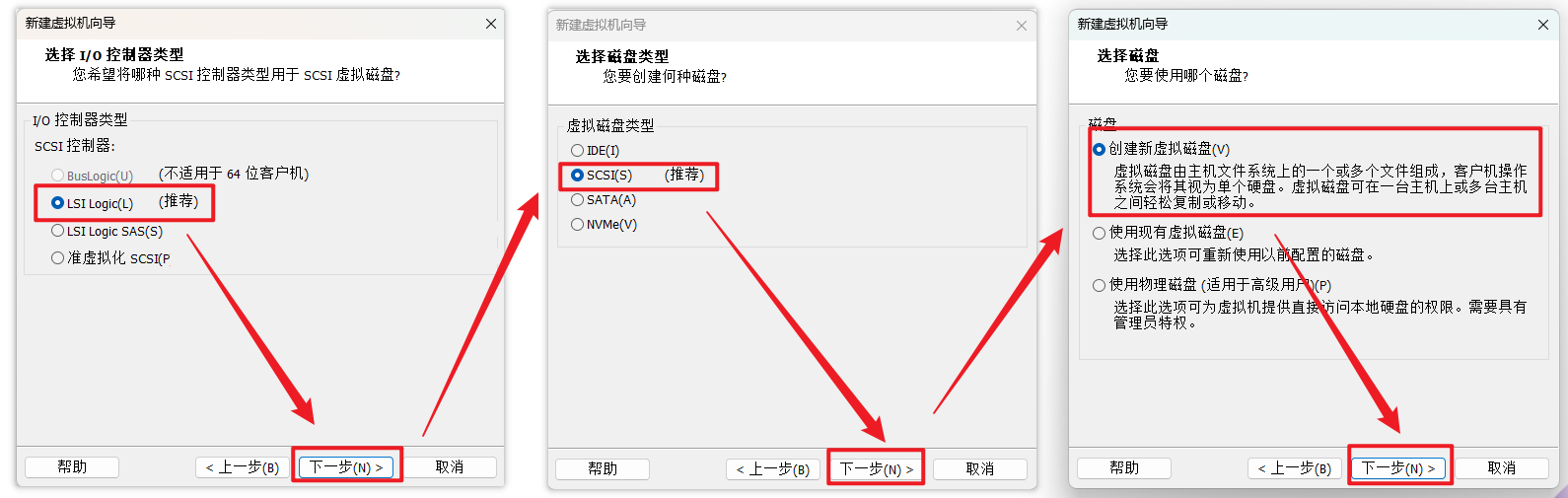
下面的按实际需求给定
第二步:安装Linux镜像

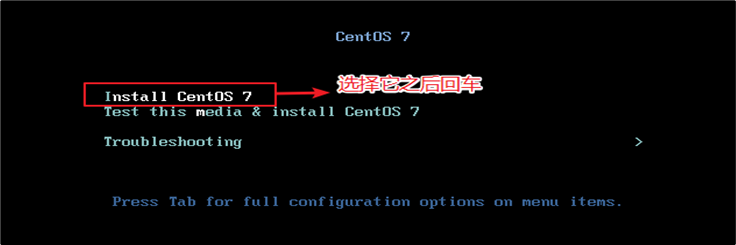
直接点击开启虚拟机开始安装系统

你得需要将鼠标点击进入界面中,但是鼠标会消失,你此刻得用键盘的上下键来控制选项,图标变白了表示当前选中的是哪个选项,然后敲回车,表示执行所选选项。
注意:如果这个时候你需要鼠标可以使用ctrl+alt一起按呼出鼠标

耐心等待它的安装
会自动跳转下面的界面
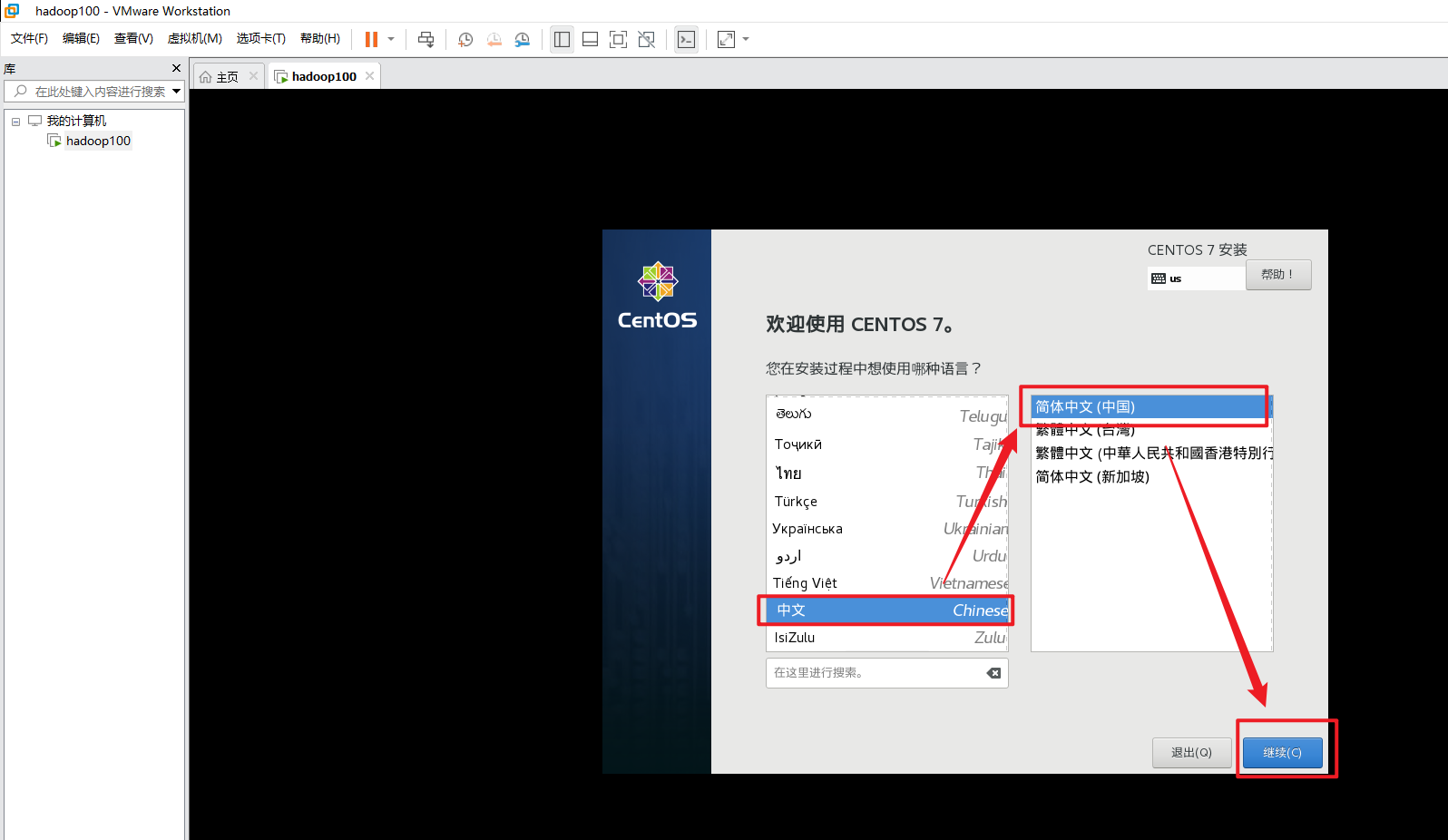
需要定制化的内容

安装GHOME(图形化界面的方式)
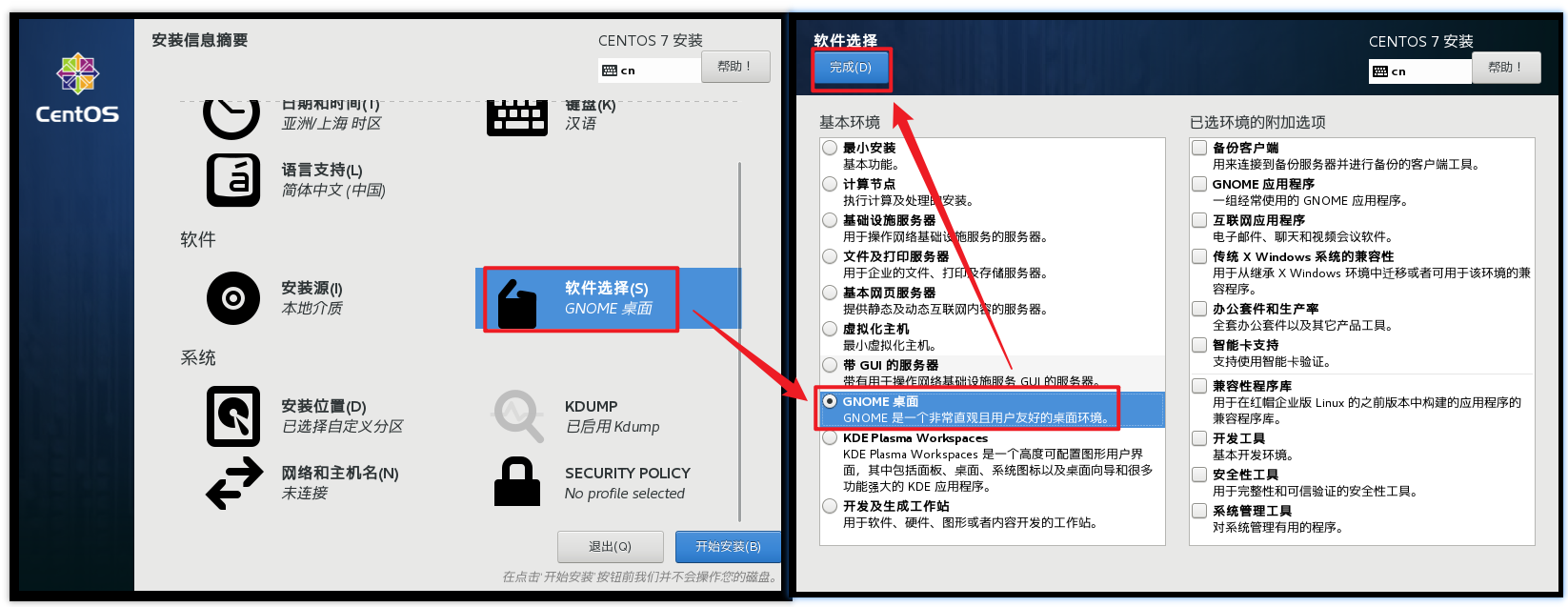
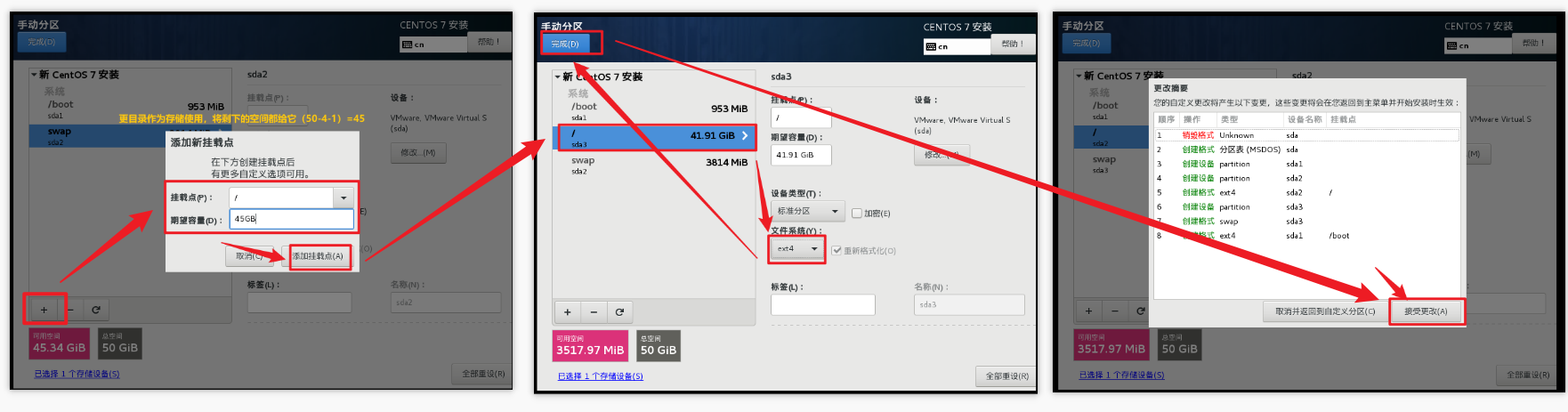
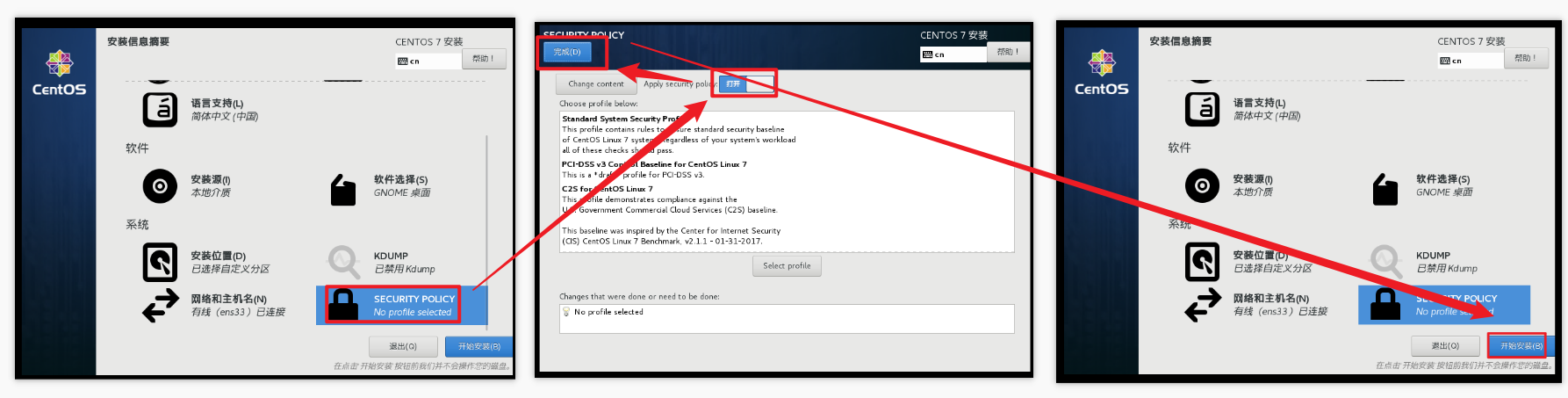
配置磁盘分区,3个分区都配置完毕过后才可以点击完成
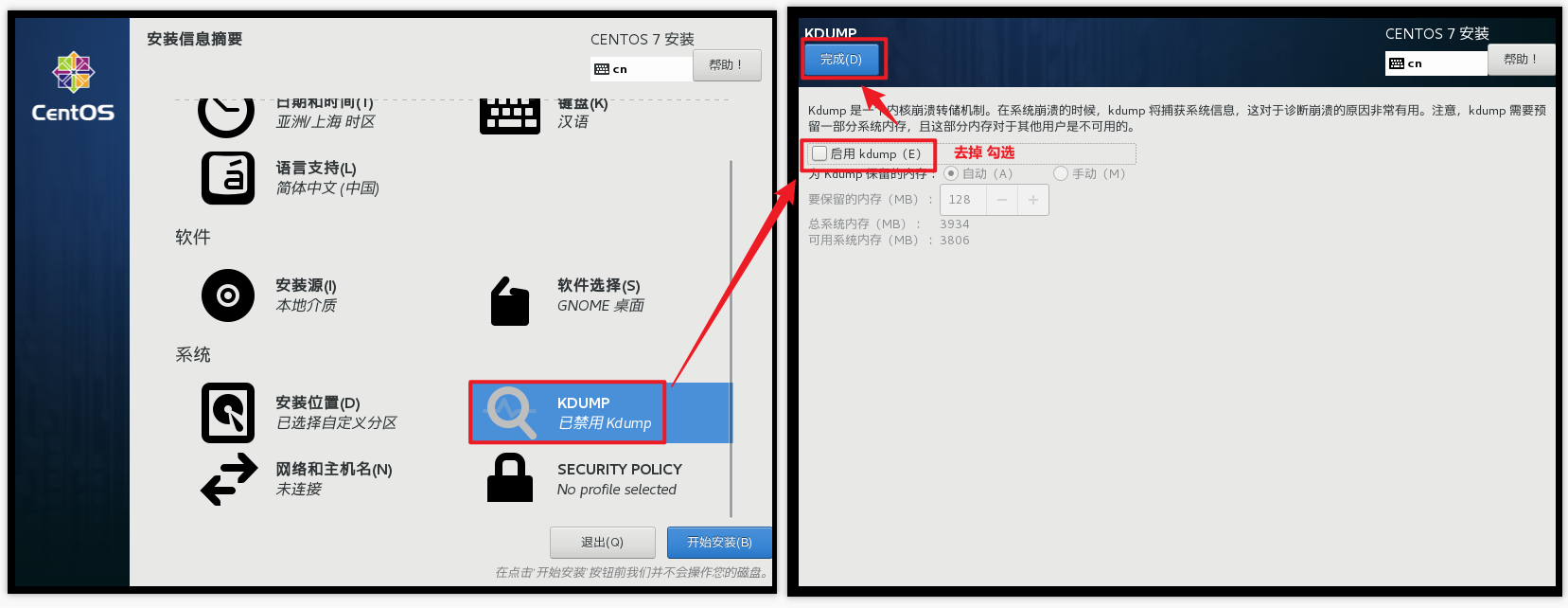
关闭kdump本身虚拟机内存就不够,它会吃掉一部分内存,我们尽量省一点
修改主机名
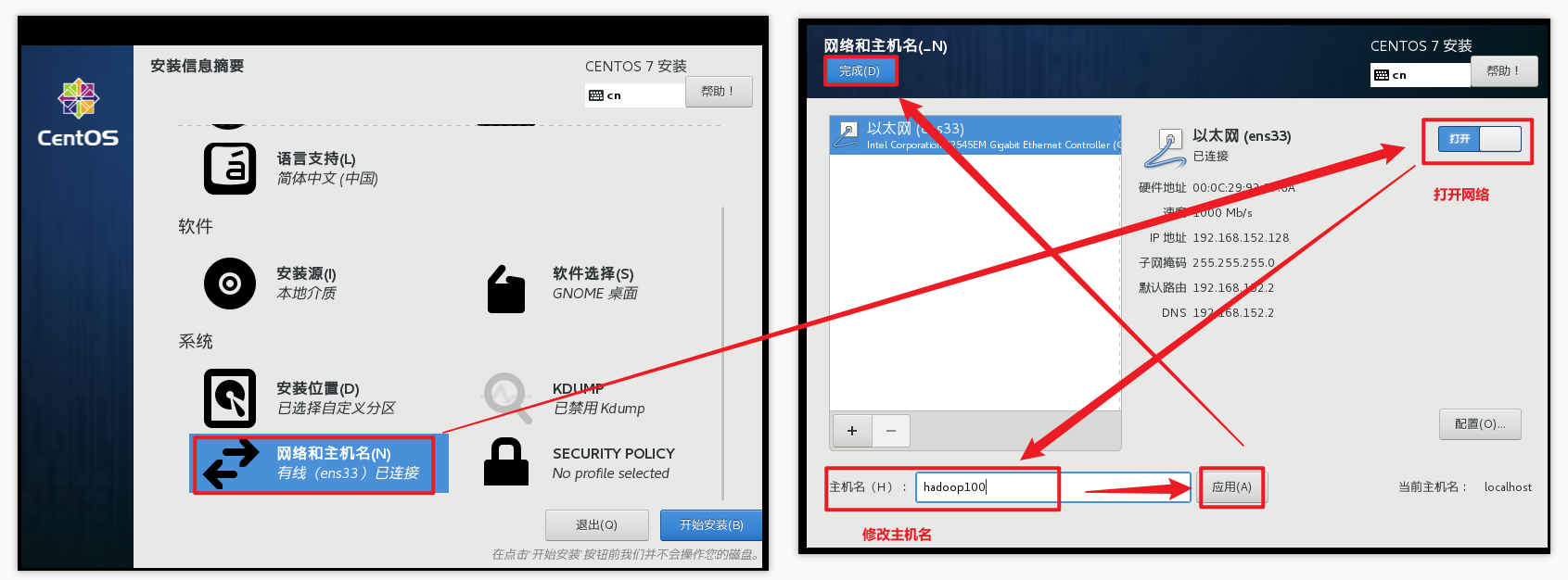
是否打开安全协议(开启与否都可以)
设置root用户密码,一定要设置(安装时间比较长,大概需要10几分钟)
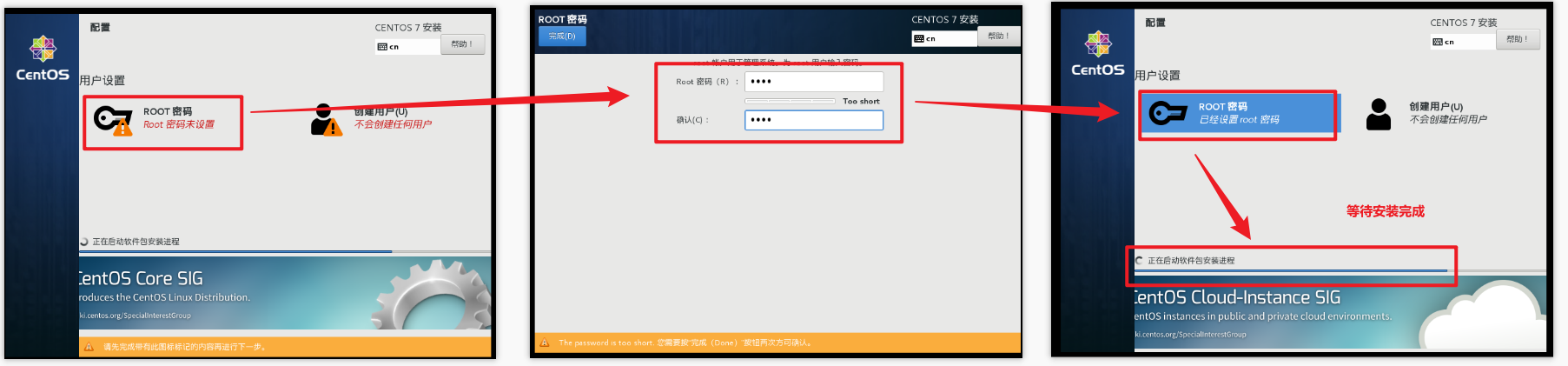
准备好后,点击‘重启’,进入引导界面【按照下面截图操作就行】
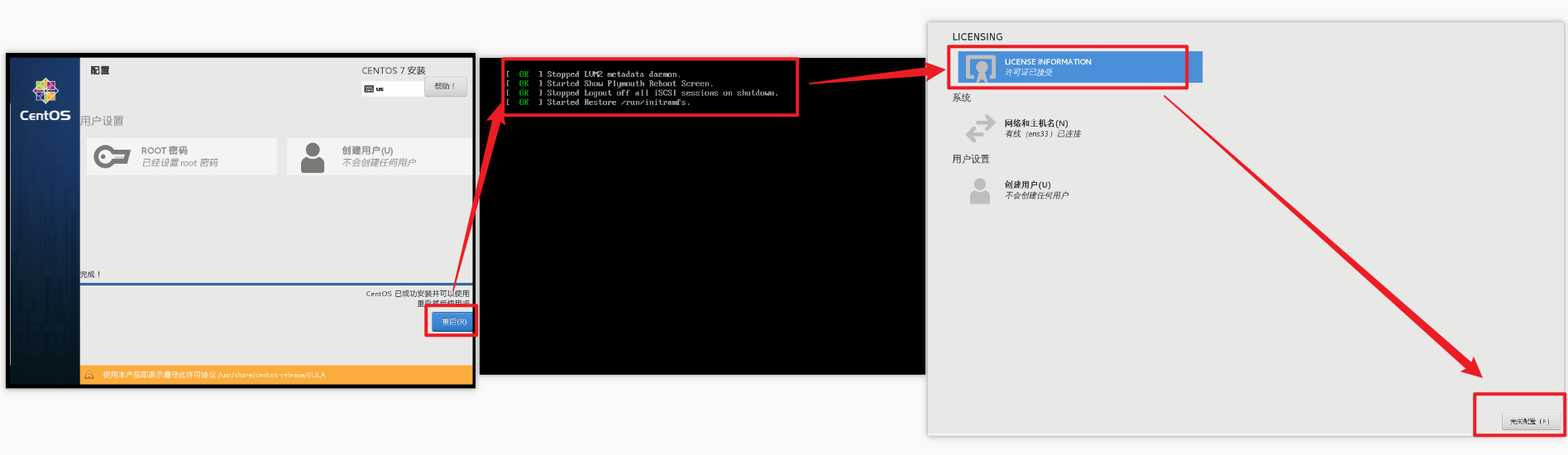
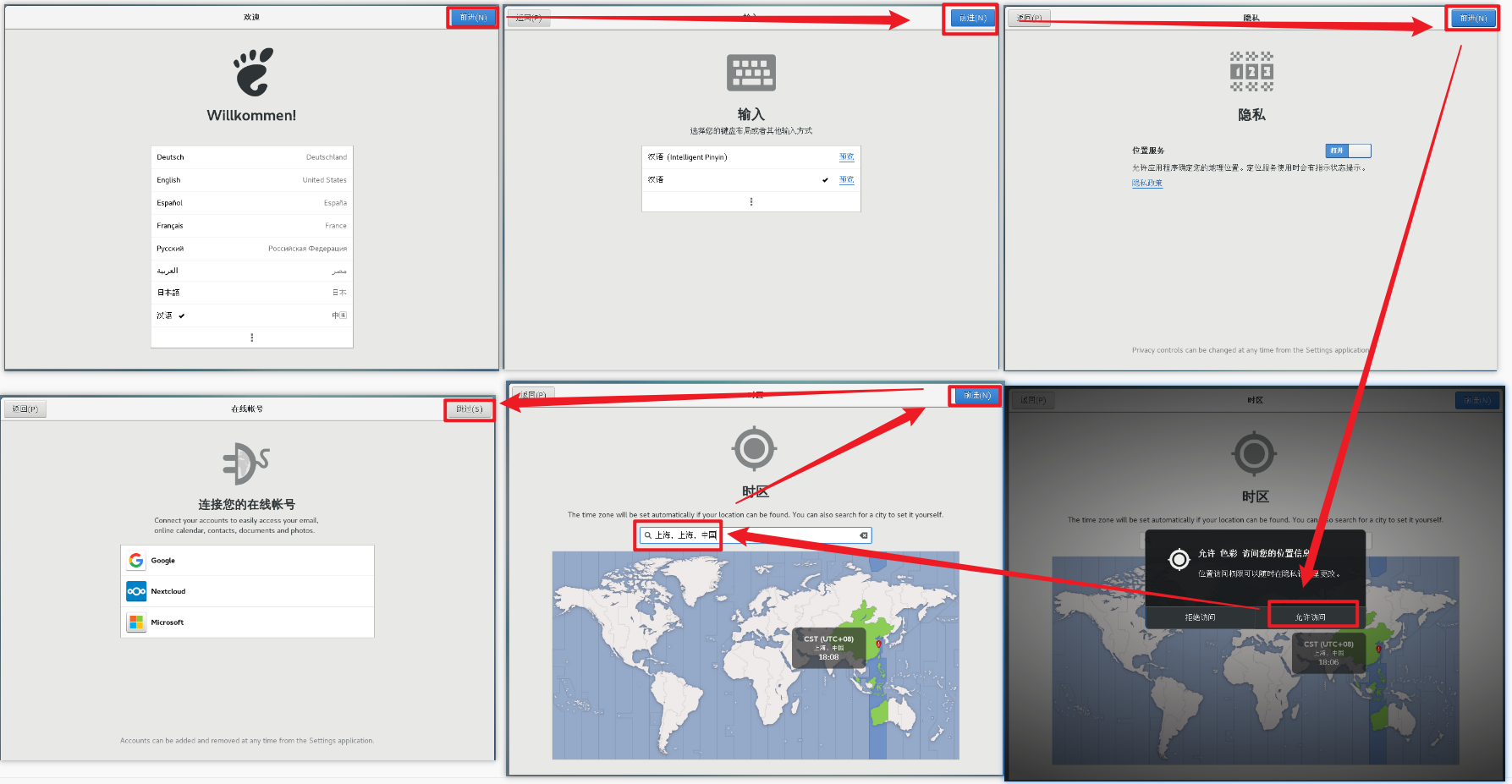
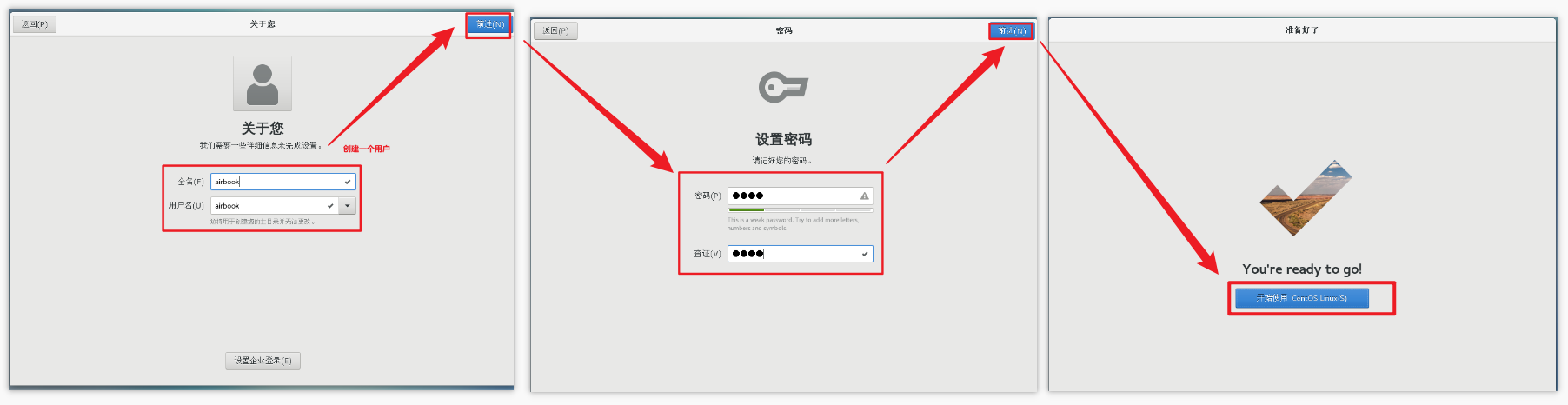
当前登录的用户是刚刚创建的用户,权限会缺少,所以使用root,修改一些内容更加方便
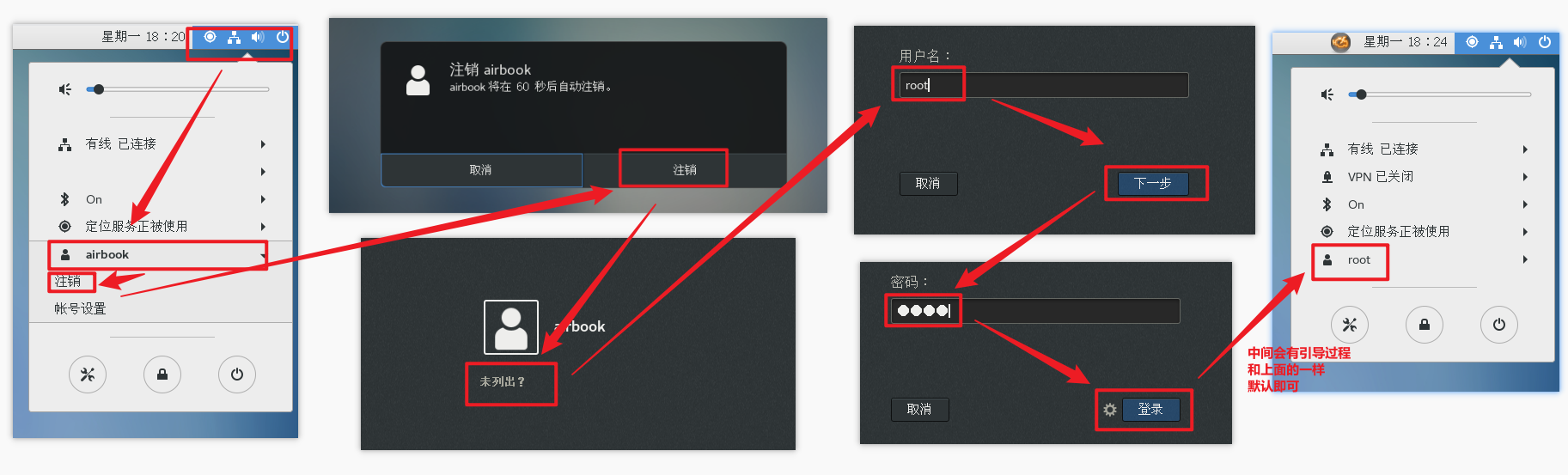
第三步:网络配置
对安装好的VMware进行网络配置,方便虚拟机连接网络,本次设置建议选择NAT模式,需要宿主机的Windows和虚拟机的Linux能够进行网络连接,同时虚拟机的Linux可以通过宿主机的Windows进入互联网。
编辑VMware的网络配置

编辑Windows的网络配置
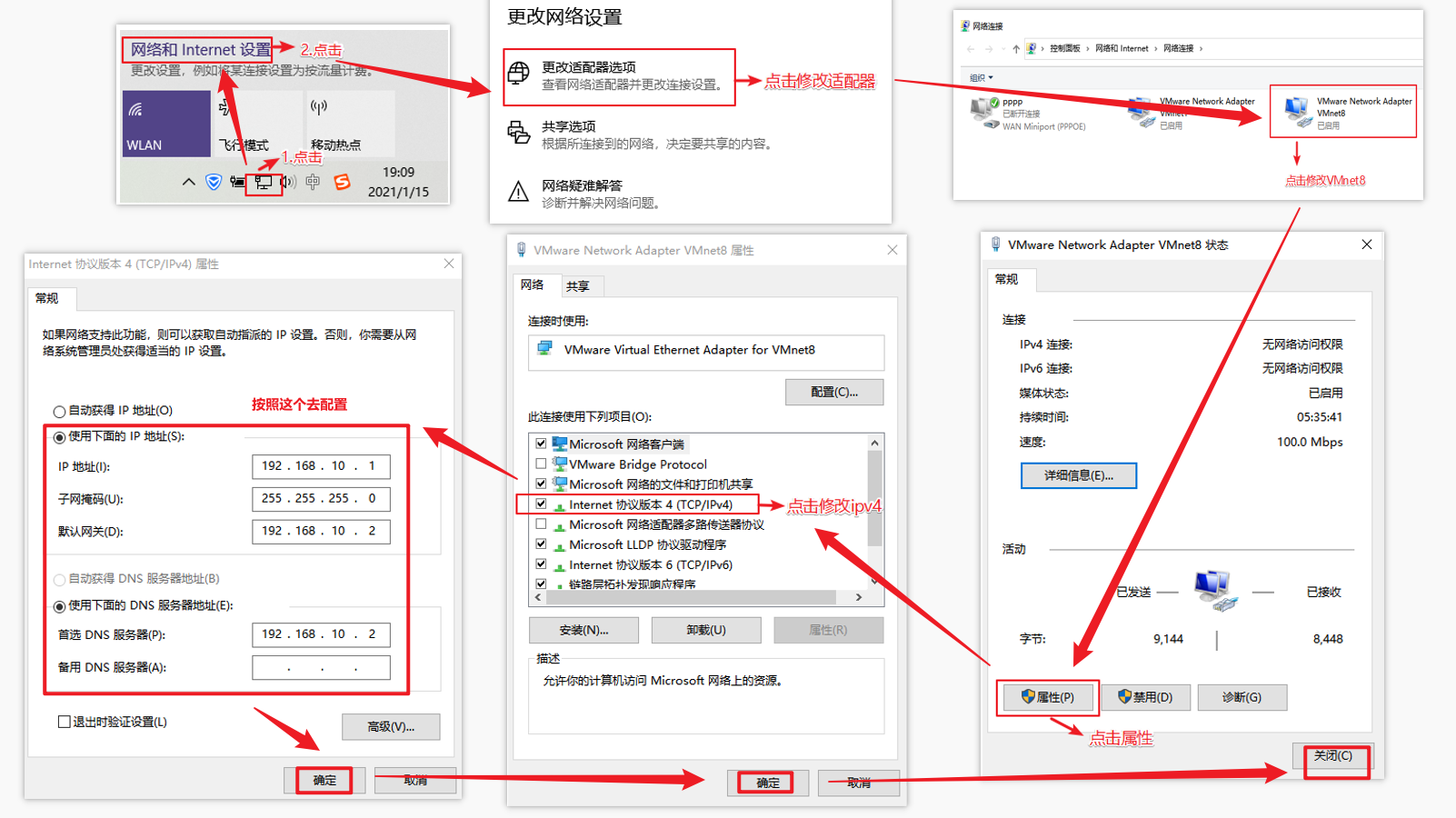
虚拟机网络IP修改地址配置
1)修改网络IP地址为静态IP地址,避免IP地址经常变化,从而方便节点服务器间的互相通信。
[root@hadoop100 ~]#vim /etc/sysconfig/network-scripts/ifcfg-ens33
2)以下带有标注【必须修改】的项必须修改,有值的按照下面的值修改,没有该项的则需要增加。
TYPE="Ethernet" #网络类型(通常是Ethemet)
PROXY_METHOD="none"
BROWSER_ONLY="no"
BOOTPROTO="static" #【必须修改】IP的配置方法[none|static|bootp|dhcp](引导时不使用协议|静态分配IP|BOOTP协议|DHCP协议)
DEFROUTE="yes"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_FAILURE_FATAL="no"
IPV6_ADDR_GEN_MODE="stable-privacy"
NAME="ens33"
UUID="e83804c1-3257-4584-81bb-660665ac22f6" #随机id
DEVICE="ens33" #接口名(设备,网卡)
ONBOOT="yes" #系统启动的时候网络接口是否有效(yes/no)
#IP地址
IPADDR=192.168.10.100
#网关
GATEWAY=192.168.10.2
#域名解析器
DNS1=192.168.10.2
3)修改IP地址后的结果如图所示,执行“:wq”命令,保存退出
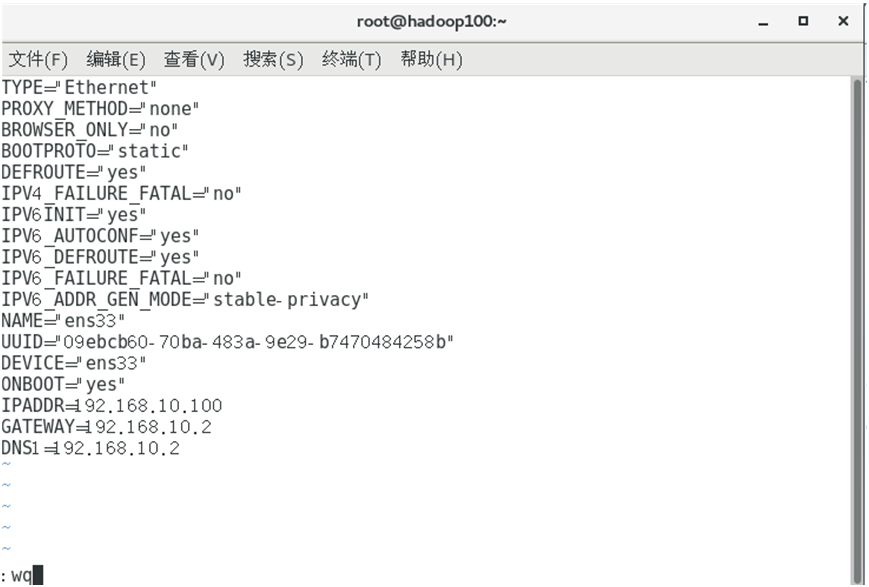
4)执行systemctl restart network命令,重启网络服务。如果报错,则执行“reboot”命令,重启虚拟机
[root@hadoop100 ~]# systemctl restart network
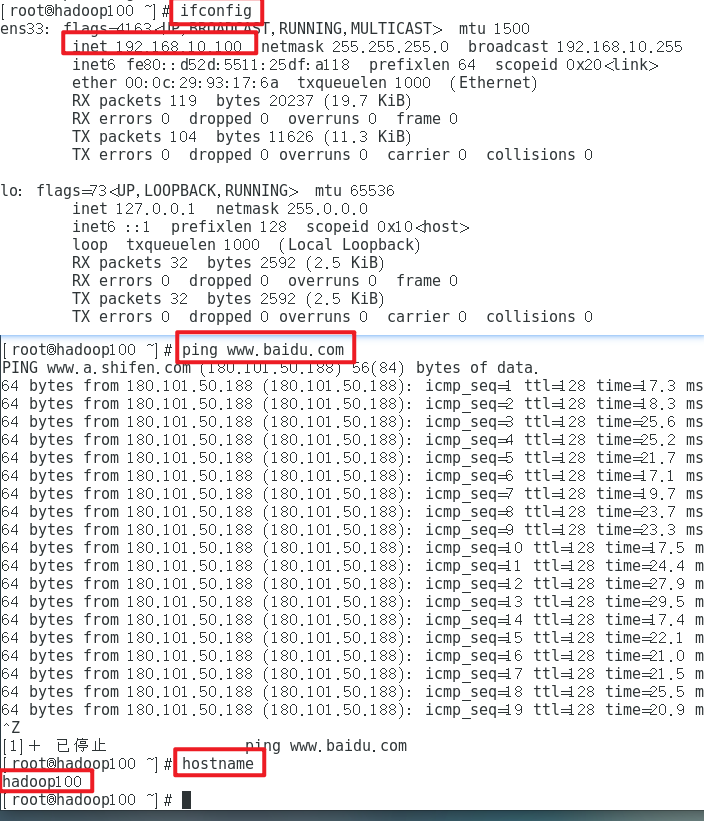
5)使用ifconfig命令查看当前IP
[root@hadoop100 ~]# ifconfig

6)保证Linux系统ifcfg-ens33文件中IP地址、虚拟网络编辑器地址和Windows系统VM8网络IP地址相同
修改主机名和hosts文件
1)修改主机名称
[root@hadoop100 ~]# vim /etc/hostname
hadoop100
2)配置Linux克隆机主机名称映射hosts文件,打开/etc/hosts
[root@hadoop100 ~]# vim /etc/hosts
添加如下内容【这里搞了八个映射】
192.168.10.100 hadoop100
192.168.10.101 hadoop101
192.168.10.102 hadoop102
192.168.10.103 hadoop103
192.168.10.104 hadoop104
192.168.10.105 hadoop105
192.168.10.106 hadoop106
192.168.10.107 hadoop107
192.168.10.108 hadoop108
3)重启克隆机hadoop100
[root@hadoop100 ~]# reboot
重启后检查:
4)修改windows的主机映射文件(hosts文件)
- 如果操作系统是window7,可以直接修改
(a)进入C:\Windows\System32\drivers\etc路径
(b)打开hosts文件并添加如下内容,然后保存
192.168.10.100 hadoop100
192.168.10.101 hadoop101
192.168.10.102 hadoop102
192.168.10.103 hadoop103
192.168.10.104 hadoop104
192.168.10.105 hadoop105
192.168.10.106 hadoop106
192.168.10.107 hadoop107
192.168.10.108 hadoop108
- 如果操作系统是window10,先拷贝出来,修改保存以后,再覆盖即可
(a)进入C:\Windows\System32\drivers\etc路径
(b)拷贝hosts文件到桌面
(c)打开桌面hosts文件并添加如下内容
192.168.10.100 hadoop100
192.168.10.101 hadoop101
192.168.10.102 hadoop102
192.168.10.103 hadoop103
192.168.10.104 hadoop104
192.168.10.105 hadoop105
192.168.10.106 hadoop106
192.168.10.107 hadoop107
192.168.10.108 hadoop108
(d)将桌面hosts文件覆盖C:\Windows\System32\drivers\etc路径hosts文件
第四步:模板虚拟机配置要求
安装epel-release
Extra Packages for Enterprise Linux是为“红帽系”的操作系统提供额外的软件包,适用于RHEL、CentOS和Scientific Linux。相当于是一个软件仓库,大多数rpm包在官方 repository 中是找不到的)
[root@hadoop100 ~]# yum install -y epel-release
关闭防火墙,关闭防火墙开机自启【每台机器都操作一下】
[root@hadoop100 ~]# systemctl stop firewalld
[root@hadoop100 ~]# systemctl disable firewalld.service
注意:在企业开发时,通常单个服务器的防火墙时关闭的。公司整体对外会设置非常安全的防火墙
创建用户,并修改用户的密码
[root@hadoop100 ~]# useradd username
[root@hadoop100 ~]# passwd userpwd
配置用户具有root权限,方便后期加sudo执行root权限的命令
[root@hadoop100 ~]# vim /etc/sudoers
修改/etc/sudoers文件,在%wheel这行下面添加一行,如下所示:
## Allow root to run any commands anywhere
root ALL=(ALL) ALL
## Allows people in group wheel to run all commands
%wheel ALL=(ALL) ALL
username ALL=(ALL) NOPASSWD:ALL
注意:username这一行不要直接放到root行下面,因为所有用户都属于wheel组,你先配置了username具有免密功能,但是程序执行到%wheel行时,该功能又被覆盖回需要密码。所以username要放到%wheel这行下面。
在/opt目录下创建文件夹,并修改所属主和所属组
- (1)在/opt目录下创建module、software文件夹
[root@hadoop100 ~]# mkdir /opt/module
[root@hadoop100 ~]# mkdir /opt/software
- (2)修改module、software文件夹的所有者和所属组均为atguigu用户
[root@hadoop100 ~]# chown username:username /opt/module
[root@hadoop100 ~]# chown username:username /opt/software
- (3)查看module、software文件夹的所有者和所属组
[root@hadoop100 ~]# cd /opt/
[root@hadoop100 opt]# ll
总用量 12
drwxr-xr-x. 2 username username 4096 5月 28 17:18 module
drwxr-xr-x. 2 root root 4096 9月 7 2017 rh
drwxr-xr-x. 2 username username 4096 5月 28 17:18 software
卸载虚拟机自带的JDK
注意:如果你的虚拟机是最小化安装不需要执行这一步。
[root@hadoop100 ~]# rpm -qa | grep -i java | xargs -n1 rpm -e --nodeps
- rpm -qa:查询所安装的所有rpm软件包
- grep -i:忽略大小写
- xargs -n1:表示每次只传递一个参数
- rpm -e –nodeps:强制卸载软件
重启虚拟机
[root@hadoop100 ~]# reboot
第五步:克隆两台虚拟机
利用模板机hadoop100,克隆两台虚拟机:hadoop101 hadoop102
注意:克隆时,要先关闭hadoop100

修改主机名称

修改克隆机主机名,以下以hadoop102举例说明
修改克隆虚拟机的静态IP
[root@hadoop100 ~]# vim /etc/sysconfig/network-scripts/ifcfg-ens33
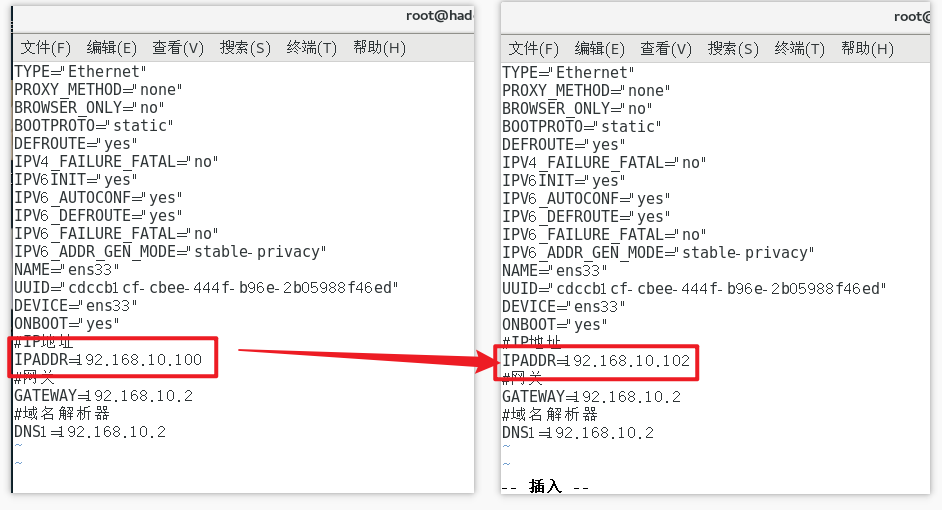
修改主机名称
[root@hadoop100 ~]# vim /etc/hostname
配置Linux克隆机主机名称映射hosts文件,打开/etc/hosts
[root@hadoop100 ~]# vim /etc/hosts
添加如下内容【克隆的模板机上有,所以克隆出来的机器也有】
192.168.10.100 hadoop100
192.168.10.101 hadoop101
192.168.10.102 hadoop102
192.168.10.103 hadoop103
192.168.10.104 hadoop104
192.168.10.105 hadoop105
192.168.10.106 hadoop106
192.168.10.107 hadoop107
192.168.10.108 hadoop108
重启克隆机hadoop102
[root@hadoop100 ~]# reboot
第六步:在模板机上安装JDK
注意:安装JDK前,一定确保提前删除了虚拟机自带的JDK。
在hadoop100安装JDK
事先在三台虚拟机(服务器)的opt目录下,创建两个文件
[root@hadoop101 ~]# cd /opt/
[root@hadoop101 opt]# mkdir mudule
[root@hadoop101 opt]# mkdir software
用XShell传输工具将JDK导入到opt目录下面的software文件夹下面
Xshell:链接:https://pan.baidu.com/s/17nTapWa31vud3RasEg8aOA
提取码:b85r
Xftp:链接:https://pan.baidu.com/s/1XEDLfsotXFNyt1q2DpBzBg
提取码:3pge
来源:https://blog.csdn.net/crr411422/article/details/131144560

解压JDK到/opt/module目录下
[root@hadoop100 software]# tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module/
配置JDK环境变量
(1)新建/etc/profile.d/my_env.sh文件
[root@hadoop100 ~]# vim /etc/profile.d/my_env.sh
添加如下内容
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
(2)保存后退出,source一下/etc/profile文件,让新的环境变量PATH生效
source /etc/profile
测试JDK是否安装成功
[root@hadoop100 ~]# source /etc/profile
如果能看到以下结果,则代表Java安装成功。
java version "1.8.0_212"
第七步:在模板机上安装Hadoop
用XShell文件传输工具将hadoop-3.1.3.tar.gz导入到opt目录下面的software文件夹下面,这个第六步操作过了

进入到Hadoop安装包路径下
[root@hadoop100 ~]# cd /opt/software/
解压安装文件到/opt/module下面
[root@hadoop100 software]# tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/
查看是否解压成功
[root@hadoop100 software]# ls /opt/module/
hadoop-3.1.3 jdk1.8.0_212
将Hadoop添加到环境变量
(1)获取Hadoop安装路径
[root@hadoop100 hadoop-3.1.3]# pwd
/opt/module/hadoop-3.1.3
(2)打开/etc/profile.d/my_env.sh文件。并在my_env.sh文件末尾添加如下内容
[root@hadoop100 hadoop-3.1.3]# vim /etc/profile.d/my_env.sh
添加:
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
(3)让修改后的文件生效
[root@hadoop100 hadoop-3.1.3]# source /etc/profile
测试是否安装成功
[root@hadoop100 hadoop-3.1.3]# hadoop version
Hadoop 3.1.3
查看Hadoop目录结构
[root@hadoop100 hadoop-3.1.3]# ll
总用量 200
drwxr-xr-x. 2 airbook airbook 4096 9月 12 2019 bin
drwxr-xr-x. 3 airbook airbook 4096 9月 12 2019 etc
drwxr-xr-x. 2 airbook airbook 4096 9月 12 2019 include
drwxr-xr-x. 3 airbook airbook 4096 9月 12 2019 lib
drwxr-xr-x. 4 airbook airbook 4096 9月 12 2019 libexec
-rw-rw-r--. 1 airbook airbook 147145 9月 4 2019 LICENSE.txt
-rw-rw-r--. 1 airbook airbook 21867 9月 4 2019 NOTICE.txt
-rw-rw-r--. 1 airbook airbook 1366 9月 4 2019 README.txt
drwxr-xr-x. 3 airbook airbook 4096 9月 12 2019 sbin
drwxr-xr-x. 4 airbook airbook 4096 9月 12 2019 share
重要目录
- bin目录:存放对Hadoop相关服务(hdfs,yarn,mapred)进行操作的脚本
- etc目录:Hadoop的配置文件目录,存放Hadoop的配置文件
- lib目录:存放Hadoop的本地库(对数据进行压缩解压缩功能)
- sbin目录:存放启动或停止Hadoop相关服务的脚本
- share目录:存放Hadoop的依赖jar包、文档、和官方案例
第八步:完全分布式运行模式搭建
Hadoop运行模式包括:本地模式、伪分布式模式以及完全分布式模式。
- 本地模式:单机运行,只是用来演示一下官方案例。生产环境不用。
- 伪分布式模式:也是单机运行,但是具备Hadoop集群的所有功能,一台服务器模拟一个分布式的环境。个别缺钱的公司用来测试,生产环境不用。
- 完全分布式模式:多台服务器组成分布式环境。生产环境使用。
SSH无密登录配置
一般情况下需要输入密码
[root@hadoop101 bin]# ssh hadoop101
The authenticity of host 'hadoop101 (192.168.10.101)' can't be established.
ECDSA key fingerprint is SHA256:TLuh8zQJfLEcrPP+7H7Y9uBz/7zrGJb9oggHZM1LHbU.
ECDSA key fingerprint is MD5:b8:38:45:ab:e7:83:af:d4:0f:ed:81:74:7c:1f:ee:57.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'hadoop101,192.168.10.101' (ECDSA) to the list of known hosts.
root@hadoop101's password:
Last login: Tue Oct 3 08:04:24 2023 from 192.168.10.1
[root@hadoop101 ~]# exit
登出
Connection to hadoop101 closed.
免密登录原理
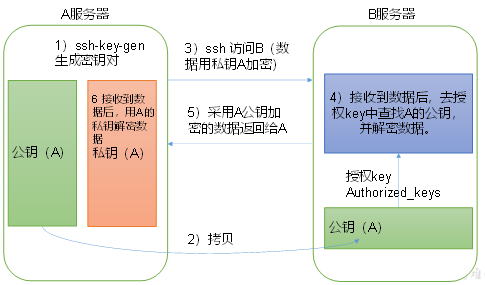
生成公钥和私钥
然后敲(三个回车),就会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
[root@hadoop100 home]# ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:PmJv92LPzXulOWGWr7otEJLzGolr8W+4KlcA3r42x9Y root@hadoop100
The key's randomart image is:
+---[RSA 2048]----+
| |
| . |
| . o . |
| . o + . |
| . oS= . . |
| +.+ o = .|
| oBo= . o =.|
| ..BoO.E..++ o|
| =.*o*.+*+*= |
+----[SHA256]-----+
[root@hadoop100 home]# ll
总用量 4
drwx------. 15 airbook airbook 4096 10月 2 18:14 airbook
[root@hadoop100 home]# cd /root
[root@hadoop100 ~]# ll .ssh
总用量 12
-rw-------. 1 root root 1679 10月 3 10:20 id_rsa
-rw-r--r--. 1 root root 396 10月 3 10:20 id_rsa.pub
-rw-r--r--. 1 root root 186 10月 3 09:51 known_hosts
将公钥拷贝到要免密登录的目标机器上
[root@hadoop100 .ssh]# ssh-copy-id hadoop101
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub"
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@hadoop101's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'hadoop101'"
and check to make sure that only the key(s) you wanted were added.
[root@hadoop100 .ssh]# ssh hadoop101
Last login: Tue Oct 3 10:15:01 2023 from hadoop101
[root@hadoop101 ~]# hostname
hadoop101
[root@hadoop101 ~]# exit
登出
[root@hadoop100 .ssh]# ssh-copy-id hadoop102
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub"
The authenticity of host 'hadoop102 (192.168.10.102)' can't be established.
ECDSA key fingerprint is SHA256:TLuh8zQJfLEcrPP+7H7Y9uBz/7zrGJb9oggHZM1LHbU.
ECDSA key fingerprint is MD5:b8:38:45:ab:e7:83:af:d4:0f:ed:81:74:7c:1f:ee:57.
Are you sure you want to continue connecting (yes/no)? yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@hadoop102's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'hadoop102'"
and check to make sure that only the key(s) you wanted were added.
[root@hadoop100 .ssh]# ssh hadoop102
Last login: Tue Oct 3 08:04:26 2023 from 192.168.10.1
[root@hadoop102 ~]# hostname
hadoop102
[root@hadoop102 ~]# exit
登出
Connection to hadoop102 closed.
注意:
上面是设置hadoop100的免密登录到hadoop101和hadoop102
需要用同样的方法:
设置hadoop101的免密登录到hadoop100和hadoop102
[root@hadoop101 home]# ssh-keygen -t rsa
[root@hadoop101 home]# cd /root/.ssh
[root@hadoop101 .ssh]# ssh-copy-id hadoop100
[root@hadoop101 .ssh]# ssh-copy-id hadoop102
设置hadoop102的免密登录到hadoop100和hadoop101
[root@hadoop102 home]# ssh-keygen -t rsa
[root@hadoop102 home]# cd /root/.ssh
[root@hadoop102 .ssh]# ssh-copy-id hadoop100
[root@hadoop102 .ssh]# ssh-copy-id hadoop101
设置hadoop100的免密登录到hadoop100【注意:建议每个分别对安装HDFS和YARN的机器分别操作!届时启动的时候都要免密登录】
[root@hadoop100 ~]# ll .ssh
总用量 16
-rw-------. 1 root root 792 10月 3 11:19 authorized_keys
-rw-------. 1 root root 1679 10月 3 10:20 id_rsa
-rw-r--r--. 1 root root 396 10月 3 10:20 id_rsa.pub
-rw-r--r--. 1 root root 558 10月 3 18:02 known_hosts
[root@hadoop100 ~]# cd .ssh
[root@hadoop100 .ssh]# ll
总用量 16
-rw-------. 1 root root 792 10月 3 11:19 authorized_keys
-rw-------. 1 root root 1679 10月 3 10:20 id_rsa
-rw-r--r--. 1 root root 396 10月 3 10:20 id_rsa.pub
-rw-r--r--. 1 root root 558 10月 3 18:02 known_hosts
[root@hadoop100 .ssh]# cat id_rsa.pub >> authorized_keys
[root@hadoop100 .ssh]# chmod 600 authorized_keys
.ssh文件夹下(~/.ssh)的文件功能解释
| 名称 | 含义 |
|---|---|
| known_hosts | 记录ssh访问过计算机的公钥(public key) |
| id_rsa | 生成的私钥 |
| id_rsa.pub | 生成的公钥 |
| authorized_keys | 存放授权过的无密登录服务器公钥 |
编写集群分发脚本xsync
1)scp(secure copy)安全拷贝
(1)scp定义
scp可以实现服务器与服务器之间的数据拷贝。(from server1 to server2)
(2)基本语法
scp -r $pdir/$fname $user@$host:$pdir/$fname
命令 递归 要拷贝的文件路径/名称 目的地用户@主机:目的地路径/名称
(3)案例实操
前提:在hadoop100、hadoop101、hadoop102都已经创建好的/opt/module、/opt/software两个目录
在hadoop100上,将hadoop100中/opt/module/jdk1.8.0_212目录拷贝到hadoop101上。
[root@hadoop100 /]# scp -r /opt/module/jdk1.8.0_212 root@hadoop101:/opt/module
2)rsync远程同步工具
rsync主要用于备份和镜像。具有速度快、避免复制相同内容和支持符号链接的优点。
rsync和scp区别:用rsync做文件的复制要比scp的速度快,rsync只对差异文件做更新。scp是把所有文件都复制过去。
(1)基本语法
rsync -av $pdir/$fname $user@$host:$pdir/$fname
命令 选项参数 要拷贝的文件路径/名称 目的地用户@主机:目的地路径/名称
选项参数说明
选项 功能
-a 归档拷贝
-v 显示复制过程
(2)案例实操
同步hadoop100中的/opt/module/hadoop-3.1.3到hadoop101
[root@hadoop100 /]# rsync -av hadoop-3.1.3/ root@hadoop101:/opt/module/hadoop-3.1.3/
3)xsync集群分发脚本
(1)需求:循环复制文件到所有节点的相同目录下
(2)需求分析:
- (a)rsync命令原始拷贝:
rsync -av /opt/module root@hadoop101:/opt/
- (b)期望脚本:
xsync要同步的文件名称 - (c)期望脚本在任何路径都能使用(脚本放在声明了全局环境变量的路径)
[root@hadoop100 bin]# echo $PATH
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin:/opt/module/jdk1.8.0_212/bin:/opt/module/jdk1.8.0_212/bin:/opt/module/jdk1.8.0_212/bin:/opt/module/hadoop-3.1.3/bin:/opt/module/hadoop-3.1.3/sbin
(3)脚本实现
- (a)在/usr/bin目录下创建xsync文件
[root@hadoop101 opt]# cd /home
[root@hadoop101 home]# mkdir bin
[root@hadoop101 home]# cd bin
[root@hadoop101 bin]# vim xsync
在该文件中编写如下代码
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器,有几台加几台
for host in hadoop101 hadoop102
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4. 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
修改脚本 xsync 具有执行权限
[root@hadoop101 bin]# ll
总用量 4
-rw-r--r--. 1 root root 740 10月 3 10:11 xsync
[root@hadoop101 bin]# chmod +x xsync
[root@hadoop101 bin]# ll
总用量 4
-rwxr-xr-x. 1 root root 740 10月 3 10:11 xsync
将脚本复制到/bin中,以便全局调用
[root@hadoop100 bin]# cp xsync /bin/
同步环境变量配置
[root@hadoop100 bin]# xsync /etc/profile.d/my_env.sh
==================== hadoop101 ====================
sending incremental file list
my_env.sh
sent 312 bytes received 35 bytes 694.00 bytes/sec
total size is 217 speedup is 0.63
==================== hadoop102 ====================
sending incremental file list
sent 48 bytes received 12 bytes 120.00 bytes/sec
total size is 217 speedup is 3.62
在Hadoop101和Hadoop102中,让环境变量生效
[root@hadoop101 .ssh]# cd /etc/profile.d
[root@hadoop101 profile.d]# ll
总用量 88
-rw-r--r--. 1 root root 771 4月 11 2018 256term.csh
-rw-r--r--. 1 root root 841 4月 11 2018 256term.sh
-rw-r--r--. 1 root root 1348 4月 27 2018 abrt-console-notification.sh
-rw-r--r--. 1 root root 660 6月 10 2014 bash_completion.sh
-rw-r--r--. 1 root root 196 3月 25 2017 colorgrep.csh
-rw-r--r--. 1 root root 201 3月 25 2017 colorgrep.sh
-rw-r--r--. 1 root root 1741 4月 11 2018 colorls.csh
-rw-r--r--. 1 root root 1606 4月 11 2018 colorls.sh
-rw-r--r--. 1 root root 80 4月 11 2018 csh.local
-rw-r--r--. 1 root root 373 4月 11 2018 flatpak.sh
-rw-r--r--. 1 root root 1706 4月 11 2018 lang.csh
-rw-r--r--. 1 root root 2703 4月 11 2018 lang.sh
-rw-r--r--. 1 root root 123 7月 31 2015 less.csh
-rw-r--r--. 1 root root 121 7月 31 2015 less.sh
-rw-r--r--. 1 root root 217 10月 3 08:24 my_env.sh
-rw-r--r--. 1 root root 1202 8月 6 2017 PackageKit.sh
-rw-r--r--. 1 root root 81 4月 11 2018 sh.local
-rw-r--r--. 1 root root 105 4月 11 2018 vim.csh
-rw-r--r--. 1 root root 269 4月 11 2018 vim.sh
-rw-r--r--. 1 root root 2092 9月 4 2017 vte.sh
-rw-r--r--. 1 root root 164 1月 28 2014 which2.csh
-rw-r--r--. 1 root root 169 1月 28 2014 which2.sh
[root@hadoop101 profile.d]# source /etc/profile
[root@hadoop102 .ssh]# cd /etc/profile.d
[root@hadoop102 profile.d]# ll
总用量 88
-rw-r--r--. 1 root root 771 4月 11 2018 256term.csh
-rw-r--r--. 1 root root 841 4月 11 2018 256term.sh
-rw-r--r--. 1 root root 1348 4月 27 2018 abrt-console-notification.sh
-rw-r--r--. 1 root root 660 6月 10 2014 bash_completion.sh
-rw-r--r--. 1 root root 196 3月 25 2017 colorgrep.csh
-rw-r--r--. 1 root root 201 3月 25 2017 colorgrep.sh
-rw-r--r--. 1 root root 1741 4月 11 2018 colorls.csh
-rw-r--r--. 1 root root 1606 4月 11 2018 colorls.sh
-rw-r--r--. 1 root root 80 4月 11 2018 csh.local
-rw-r--r--. 1 root root 373 4月 11 2018 flatpak.sh
-rw-r--r--. 1 root root 1706 4月 11 2018 lang.csh
-rw-r--r--. 1 root root 2703 4月 11 2018 lang.sh
-rw-r--r--. 1 root root 123 7月 31 2015 less.csh
-rw-r--r--. 1 root root 121 7月 31 2015 less.sh
-rw-r--r--. 1 root root 217 10月 3 08:24 my_env.sh
-rw-r--r--. 1 root root 1202 8月 6 2017 PackageKit.sh
-rw-r--r--. 1 root root 81 4月 11 2018 sh.local
-rw-r--r--. 1 root root 105 4月 11 2018 vim.csh
-rw-r--r--. 1 root root 269 4月 11 2018 vim.sh
-rw-r--r--. 1 root root 2092 9月 4 2017 vte.sh
-rw-r--r--. 1 root root 164 1月 28 2014 which2.csh
-rw-r--r--. 1 root root 169 1月 28 2014 which2.sh
[root@hadoop102 profile.d]# source /etc/profile
同步jdk和Hadoop,从Hadoop100至Hadoop101和Hadoop102
[root@hadoop100 bin]# xsync /opt/module
第九步:集群配置
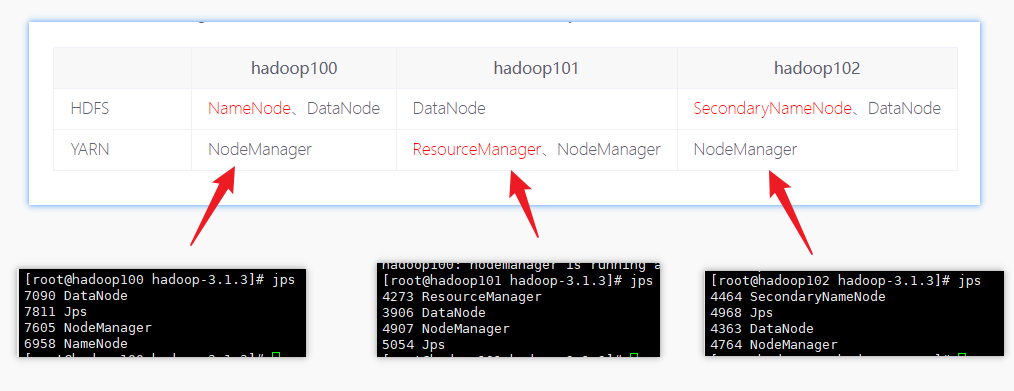
集群部署规划
注意:
- NameNode和SecondaryNameNode不要安装在同一台服务器,因为它们都比耗内存
- ResourceManager也很消耗内存,不要和NameNode、SecondaryNameNode配置在同一台机器上。
| hadoop100 | hadoop101 | hadoop102 | |
|---|---|---|---|
| HDFS | NameNode、DataNode | DataNode | SecondaryNameNode、DataNode |
| YARN | NodeManager | ResourceManager、NodeManager | NodeManager |
配置文件说明
Hadoop配置文件分两类:默认配置文件和自定义配置文件,只有用户想修改某一默认配置值时,才需要修改自定义配置文件,更改相应属性值。
- 默认配置文件:
| 要获取的默认文件 | 文件存放在Hadoop的jar包中的位置 |
|---|---|
| [core-default.xml] | hadoop-common-3.1.3.jar/core-default.xml |
| [hdfs-default.xml] | hadoop-hdfs-3.1.3.jar/hdfs-default.xml |
| [yarn-default.xml] | hadoop-yarn-common-3.1.3.jar/yarn-default.xml |
| [mapred-default.xml] | hadoop-mapreduce-client-core-3.1.3.jar/mapred-default.xml |
- 自定义配置文件:
core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml四个配置文件存放在$HADOOP_HOME/etc/hadoop这个路径上,用户可以根据项目需求重新进行修改配置。
[root@hadoop100 ~]# cd /opt/module/hadoop-3.1.3/
[root@hadoop100 hadoop-3.1.3]# ll
总用量 200
drwxr-xr-x. 2 airbook airbook 4096 9月 12 2019 bin
drwxr-xr-x. 3 airbook airbook 4096 9月 12 2019 etc
drwxr-xr-x. 2 airbook airbook 4096 9月 12 2019 include
drwxr-xr-x. 3 airbook airbook 4096 9月 12 2019 lib
drwxr-xr-x. 4 airbook airbook 4096 9月 12 2019 libexec
-rw-rw-r--. 1 airbook airbook 147145 9月 4 2019 LICENSE.txt
-rw-rw-r--. 1 airbook airbook 21867 9月 4 2019 NOTICE.txt
-rw-rw-r--. 1 airbook airbook 1366 9月 4 2019 README.txt
drwxr-xr-x. 3 airbook airbook 4096 9月 12 2019 sbin
drwxr-xr-x. 4 airbook airbook 4096 9月 12 2019 share
[root@hadoop100 hadoop-3.1.3]# cd etc/hadoop/
[root@hadoop100 hadoop]# ll
总用量 176
-rw-r--r--. 1 airbook airbook 8260 9月 12 2019 capacity-scheduler.xml
-rw-r--r--. 1 airbook airbook 1335 9月 12 2019 configuration.xsl
-rw-r--r--. 1 airbook airbook 1940 9月 12 2019 container-executor.cfg
-rw-r--r--. 1 airbook airbook 774 9月 12 2019 core-site.xml
-rw-r--r--. 1 airbook airbook 3999 9月 12 2019 hadoop-env.cmd
-rw-r--r--. 1 airbook airbook 15903 9月 12 2019 hadoop-env.sh
-rw-r--r--. 1 airbook airbook 3323 9月 12 2019 hadoop-metrics2.properties
-rw-r--r--. 1 airbook airbook 11392 9月 12 2019 hadoop-policy.xml
-rw-r--r--. 1 airbook airbook 3414 9月 12 2019 hadoop-user-functions.sh.example
-rw-r--r--. 1 airbook airbook 775 9月 12 2019 hdfs-site.xml
-rw-r--r--. 1 airbook airbook 1484 9月 12 2019 httpfs-env.sh
-rw-r--r--. 1 airbook airbook 1657 9月 12 2019 httpfs-log4j.properties
-rw-r--r--. 1 airbook airbook 21 9月 12 2019 httpfs-signature.secret
-rw-r--r--. 1 airbook airbook 620 9月 12 2019 httpfs-site.xml
-rw-r--r--. 1 airbook airbook 3518 9月 12 2019 kms-acls.xml
-rw-r--r--. 1 airbook airbook 1351 9月 12 2019 kms-env.sh
-rw-r--r--. 1 airbook airbook 1747 9月 12 2019 kms-log4j.properties
-rw-r--r--. 1 airbook airbook 682 9月 12 2019 kms-site.xml
-rw-r--r--. 1 airbook airbook 13326 9月 12 2019 log4j.properties
-rw-r--r--. 1 airbook airbook 951 9月 12 2019 mapred-env.cmd
-rw-r--r--. 1 airbook airbook 1764 9月 12 2019 mapred-env.sh
-rw-r--r--. 1 airbook airbook 4113 9月 12 2019 mapred-queues.xml.template
-rw-r--r--. 1 airbook airbook 758 9月 12 2019 mapred-site.xml
drwxr-xr-x. 2 airbook airbook 4096 9月 12 2019 shellprofile.d
-rw-r--r--. 1 airbook airbook 2316 9月 12 2019 ssl-client.xml.example
-rw-r--r--. 1 airbook airbook 2697 9月 12 2019 ssl-server.xml.example
-rw-r--r--. 1 airbook airbook 2642 9月 12 2019 user_ec_policies.xml.template
-rw-r--r--. 1 airbook airbook 10 9月 12 2019 workers
-rw-r--r--. 1 airbook airbook 2250 9月 12 2019 yarn-env.cmd
-rw-r--r--. 1 airbook airbook 6056 9月 12 2019 yarn-env.sh
-rw-r--r--. 1 airbook airbook 2591 9月 12 2019 yarnservice-log4j.properties
-rw-r--r--. 1 airbook airbook 690 9月 12 2019 yarn-site.xml
核心文件配置
- 配置core-site.xml
[root@hadoop100 hadoop]# cd $HADOOP_HOME/etc/hadoop
[root@hadoop100 hadoop]# vim core-site.xml
文件内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop100:8020</value>
</property>
<!-- 指定hadoop数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
<!-- 配置HDFS网页登录使用的静态用户为root -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
</configuration>
HDFS配置文件
配置hdfs-site.xml
[root@hadoop100 hadoop]# vim hdfs-site.xml
文件内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- nn web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop100:9870</value>
</property>
<!-- 2nn web端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop102:9868</value>
</property>
</configuration>
YARN配置文件
配置yarn-site.xml
[root@hadoop100 hadoop]# vim yarn-site.xml
文件内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定MR走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop101</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
MapReduce配置文件
配置mapred-site.xml
[root@hadoop100 hadoop]# vim mapred-site.xml
文件内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定MapReduce程序运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
在集群上分发配置好的Hadoop配置文件
[root@hadoop100 hadoop]# cd ..
[root@hadoop100 etc]# xsync hadoop/
==================== hadoop101 ====================
sending incremental file list
hadoop/
hadoop/core-site.xml
hadoop/hdfs-site.xml
hadoop/mapred-site.xml
hadoop/yarn-site.xml
sent 3,422 bytes received 139 bytes 418.94 bytes/sec
total size is 107,596 speedup is 30.22
==================== hadoop102 ====================
sending incremental file list
hadoop/
hadoop/core-site.xml
hadoop/hdfs-site.xml
hadoop/mapred-site.xml
hadoop/yarn-site.xml
sent 3,422 bytes received 139 bytes 7,122.00 bytes/sec
total size is 107,596 speedup is 30.22
去101和102上查看文件分发情况
[root@hadoop101 hadoop]# cat /opt/module/hadoop-3.1.3/etc/hadoop/core-site.xml
[root@hadoop102 hadoop]# cat /opt/module/hadoop-3.1.3/etc/hadoop/core-site.xml
配置workers
[root@hadoop100 hadoop]# vim workers
[root@hadoop100 hadoop]# xsync workers
==================== hadoop101 ====================
sending incremental file list
workers
sent 141 bytes received 41 bytes 52.00 bytes/sec
total size is 30 speedup is 0.16
==================== hadoop102 ====================
sending incremental file list
workers
sent 141 bytes received 41 bytes 4.00 bytes/sec
total size is 30 speedup is 0.16
在该文件中增加如下内容:【注意:不能有空格】
hadoop100
hadoop101
hadoop102
第十步:启动集群
如果集群是第一次启动,需要在hadoop102节点格式化NameNode(注意:格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到已往数据。如果集群在运行过程中报错,需要重新格式化NameNode的话,一定要先停止namenode和datanode进程,并且要删除所有机器的data和logs目录,然后再进行格式化。)
[root@hadoop100 hadoop-3.1.3]# cd /opt/module/hadoop-3.1.3
[root@hadoop100 hadoop-3.1.3]# hdfs namenode -format
如果成功了会多出data和logs文件夹

启动HDFS
[root@hadoop100 hadoop-3.1.3]# sbin/start-dfs.sh
启动的时候可能报错:
[root@hadoop100 sbin]# start-dfs.sh
Starting namenodes on [hadoop100]
ERROR: Attempting to operate on hdfs namenode as root
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.
Starting datanodes
ERROR: Attempting to operate on hdfs datanode as root
ERROR: but there is no HDFS_DATANODE_USER defined. Aborting operation.
Starting secondary namenodes [hadoop102]
ERROR: Attempting to operate on hdfs secondarynamenode as root
ERROR: but there is no HDFS_SECONDARYNAMENODE_USER defined. Aborting operation.
解决方法是直接在环境变量中添加配置
my_env.sh是自己添加的文件,不建议直接修改profile.d
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
然后分发,并在使其均生效
[root@hadoop100 hadoop-3.1.3]# vim /etc/profile.d/my_env.sh
[root@hadoop100 hadoop-3.1.3]# xsync /etc/profile.d/my_env.sh
[root@hadoop101 ~]# source /etc/profile
[root@hadoop102 ~]# source /etc/profile
完事后,直接再次启动即可:
[root@hadoop100 hadoop-3.1.3]# sbin/start-dfs.sh
这下我们可以看到每个服务器都跑着我们设置好的角色:
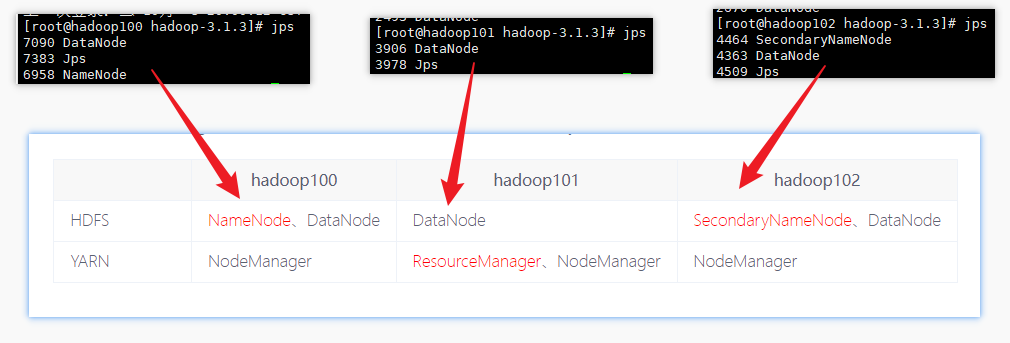
在配置了ResourceManager的节点(hadoop103)启动YARN
[root@hadoop101 hadoop-3.1.3]# sbin/start-yarn.sh
Web端查看HDFS的NameNode
浏览器中输入:http://hadoop100:9870 or http://192.168.10.100:9870
查看HDFS上存储的数据信息
Web端查看YARN的ResourceManager
浏览器中输入:http://hadoop101:8088 or http://192.168.10.101:8088
查看YARN上运行的Job信息
第十一步:集群测试
创建一个小文件word_news.txt,并输入一些内容
[root@hadoop100 opt]# vim word_news.txt
[root@hadoop100 opt]# cat word_news.txt
a aa aaa
i aa aaa
i ii iii
c cc ccc
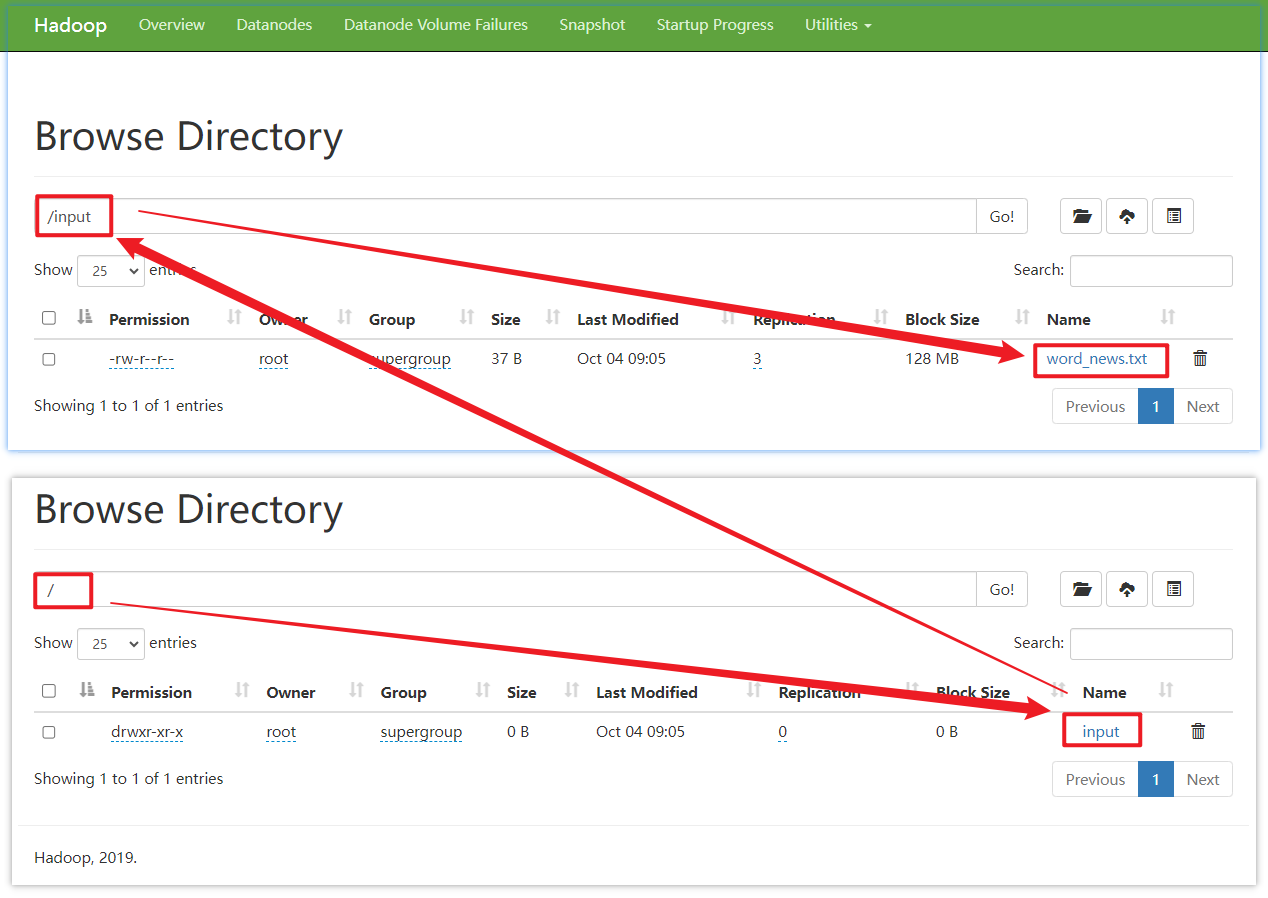
接着,我们使用命令上传
[root@hadoop100 hadoop-3.1.3]# hadoop fs -mkdir /input
[root@hadoop100 hadoop-3.1.3]# hadoop fs -put /opt/word_news.txt /input
2023-10-04 09:05:11,857 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
我们在web端,http://192.168.10.100:9870 就能看到相关的数据
如果我们上传一个大文件,也是OK的
[root@hadoop100 hadoop-3.1.3]# hadoop fs -put /opt/software/jdk-8u212-linux-x64.tar.gz /input
2023-10-04 09:11:15,209 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2023-10-04 09:12:56,356 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
上传文件后查看文件存放在什么位置
存储在DataNode节点
查看HDFS文件存储路径,按照下面的路径去找,就可以找到【注意:BP-178731379-192.168.10.100-1696328228716是不一样的,其他都一样】
[root@hadoop100 subdir0]# pwd
/opt/module/hadoop-3.1.3/data/dfs/data/current/BP-178731379-192.168.10.100-1696328228716/current/finalized/subdir0/subdir0
我们查看其中一个文件
[root@hadoop100 subdir0]# pwd
/opt/module/hadoop-3.1.3/data/dfs/data/current/BP-178731379-192.168.10.100-1696328228716/current/finalized/subdir0/subdir0
[root@hadoop100 subdir0]# ll
总用量 191944
-rw-r--r--. 1 root root 37 10月 4 09:05 blk_1073741825
-rw-r--r--. 1 root root 11 10月 4 09:05 blk_1073741825_1001.meta
-rw-r--r--. 1 root root 134217728 10月 4 09:12 blk_1073741826
-rw-r--r--. 1 root root 1048583 10月 4 09:12 blk_1073741826_1002.meta
-rw-r--r--. 1 root root 60795424 10月 4 09:13 blk_1073741827
-rw-r--r--. 1 root root 474975 10月 4 09:13 blk_1073741827_1003.meta
[root@hadoop100 subdir0]# cat blk_1073741825
a aa aaa
i aa aaa
i ii iii
c cc ccc
发现其内容就是我们之前上传的word_news.txt
查看另一个压缩的文件jdk-8u212-linux-x64.tar.gz,我们使用追加到一个文件的方法
[root@hadoop100 subdir0]# cat blk_1073741826 >> tmp.tar.gz
[root@hadoop100 subdir0]# cat blk_1073741827 >> tmp.tar.gz
[root@hadoop100 subdir0]# tar -zxvf tmp.tar.gz
[root@hadoop100 subdir0]# ll
总用量 382392
-rw-r--r--. 1 root root 37 10月 4 09:05 blk_1073741825
-rw-r--r--. 1 root root 11 10月 4 09:05 blk_1073741825_1001.meta
-rw-r--r--. 1 root root 134217728 10月 4 09:12 blk_1073741826
-rw-r--r--. 1 root root 1048583 10月 4 09:12 blk_1073741826_1002.meta
-rw-r--r--. 1 root root 60795424 10月 4 09:13 blk_1073741827
-rw-r--r--. 1 root root 474975 10月 4 09:13 blk_1073741827_1003.meta
drwxr-xr-x. 7 10 143 4096 4月 2 2019 jdk1.8.0_212
-rw-r--r--. 1 root root 195013152 10月 4 09:22 tmp.tar.gz
解压缩后可以看到,其实就是我们上传的Jdk。
关于下载文件,我们可以在web界面操作,也可以使用命令
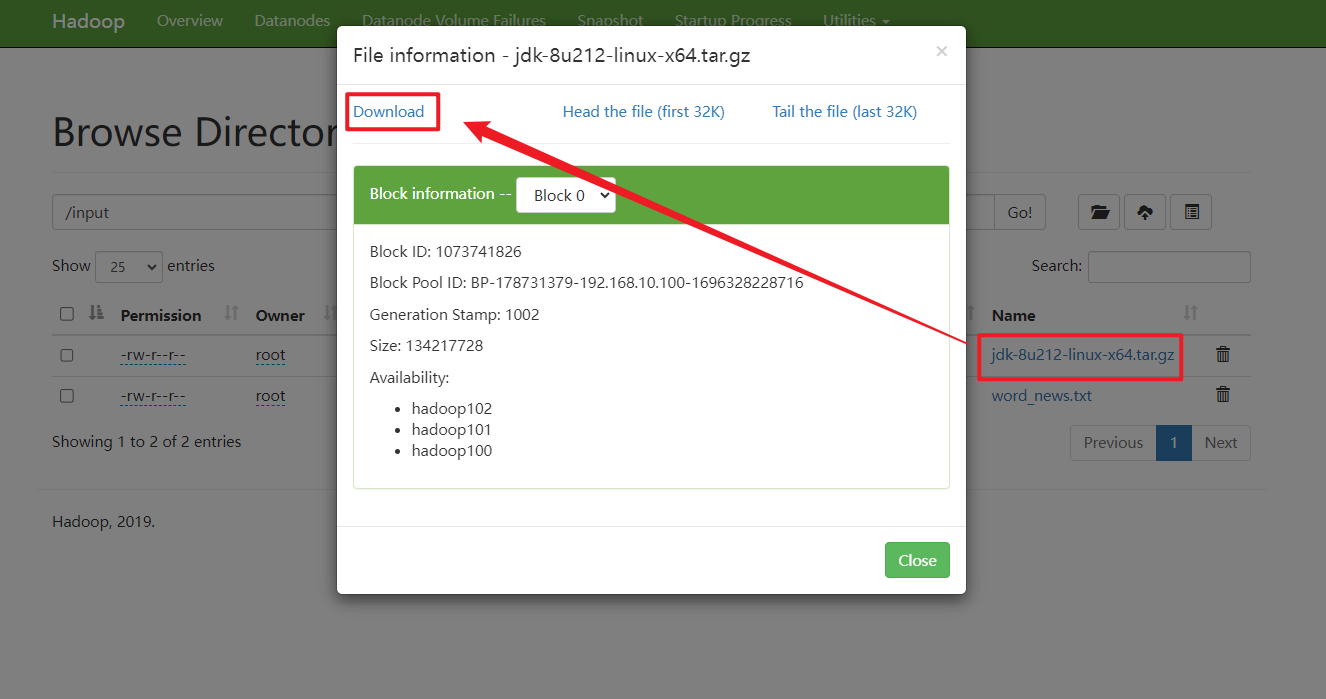
[root@hadoop100 software]# hadoop fs -get /jdk-8u212-linux-x64.tar.gz ./
执行wordcount程序
[root@hadoop100 subdir0]# cd /opt/module/hadoop-3.1.3/
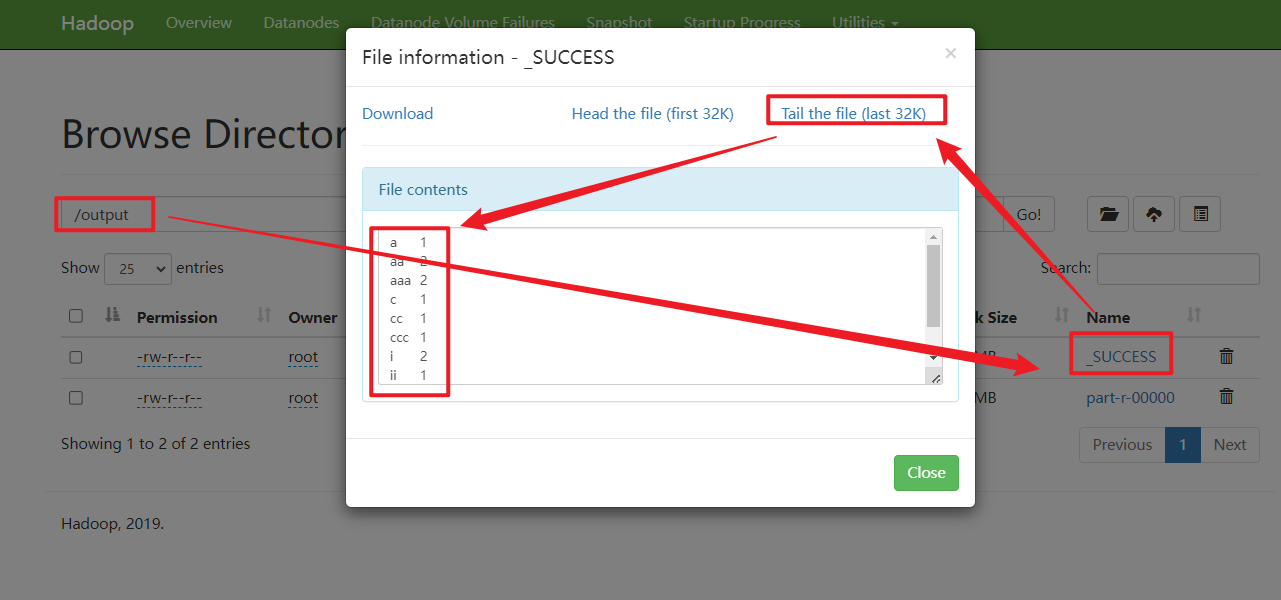
[root@hadoop100 hadoop-3.1.3]# hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output
在web界面:http://192.168.10.100:9870 可以查看到程序的输出结果
执行上面程序的可以可能会报错:
[2023-10-04 09:46:55.577]Container [pid=14974,containerID=container_1696383799680_0001_01_000003] is running 225016320B beyond the 'VIRTUAL' memory limit. Current usage: 73.0 MB of 1 GB physical memory used; 2.3 GB of 2.1 GB virtual memory used. Killing container.
解决方案是:
在/opt/module/hadoop-3.1.4/etc/hadoop/下的mapred-site.xml中添加如下配置
[root@hadoop100 hadoop-3.1.3]# vim etc/hadoop/yarn-site.xml
[root@hadoop100 hadoop-3.1.3]# xsync etc/hadoop/yarn-site.xml
添加内容:
<property>
<!-- 是否对容器强制执行虚拟内存限制 -->
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
<description>Whether virtual memory limits will be enforced for containers</description>
</property>
<property>
<!-- 为容器设置内存限制时虚拟内存与物理内存之间的比率 -->
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>4</value>
<description>Ratio between virtual memory to physical memory when setting memory limits for containers</description>
</property>
然后,分发和重启YARN
[root@hadoop100 etc]# xsync hadoop/
[root@hadoop101 sbin]# stop-yarn.sh
[root@hadoop101 sbin]# start-yarn.sh
``
## 第十一步:配置历史服务器
```shell
[root@hadoop100 hadoop]# vim mapred-site.xml
在该文件里面增加如下配置:
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop100:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop100:19888</value>
</property>
分发配置
[root@hadoop100 hadoop]# xsync $HADOOP_HOME/etc/hadoop/mapred-site.xml
在hadoop100启动历史服务器
[root@hadoop100 hadoop]# mapred --daemon start historyserver
[root@hadoop100 hadoop]# jps
18641 Jps
7090 DataNode
18584 JobHistoryServer
6958 NameNode
17487 NodeManager
web端查看JobHistory:http://hadoop100:19888/jobhistory or http://192.168.10.100:19888/jobhistory
第十二步:配置日志的聚集
日志聚集概念:应用运行完成以后,将程序运行日志信息上传到HDFS系统上。
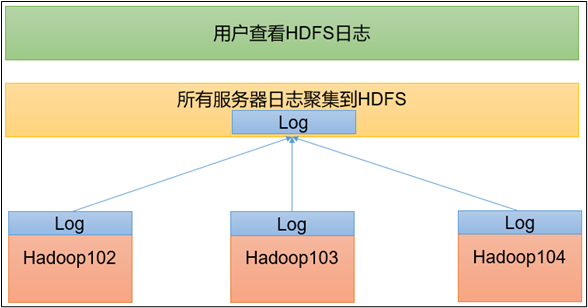
日志聚集功能好处:可以方便的查看到程序运行详情,方便开发调试。
注意:开启日志聚集功能,需要重新启动NodeManager 、ResourceManager和HistoryServer。
开启日志聚集功能具体步骤如下:
[root@hadoop100 hadoop]# vim yarn-site.xml
在该文件里面增加如下配置。
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop100:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
分发配置:
[root@hadoop100 hadoop]# xsync $HADOOP_HOME/etc/hadoop/yarn-site.xml
在YARN服务器(Hadoop101)上操作
[root@hadoop101 hadoop-3.1.3]# sbin/stop-yarn.sh
[root@hadoop100 hadoop-3.1.3]# mapred --daemon stop historyserver
[root@hadoop101 hadoop-3.1.3]# sbin/start-yarn.sh
[root@hadoop100 hadoop-3.1.3]# mapred --daemon start historyserver
删除HDFS上已经存在的输出文件
[root@hadoop101 hadoop-3.1.3]# hadoop fs -rm -r /output
Deleted /output
执行WordCount程序
[root@hadoop101 hadoop-3.1.3]# hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output
查看详情日志,历史服务器地址:http://hadoop101:19888/jobhistory or http://192.168.10.101:19888/jobhistory

第十二步:编写Hadoop集群常用脚本
各个服务组件逐一启动/停止
分别启动/停止HDFS组件
hdfs --daemon start/stop namenode/datanode/secondarynamenode
启动/停止YARN
yarn --daemon start/stop resourcemanager/nodemanager
Hadoop集群启停脚本(包含HDFS,Yarn,Historyserver):myhadoop.sh
[root@hadoop100 home]# cd bin
[root@hadoop100 bin]# ll
总用量 4
-rwxr-xr-x. 1 root root 731 10月 3 11:43 xsync
[root@hadoop100 bin]# vim myhadoop.sh
脚本内容:
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit ;
fi
case $1 in
"start")
echo " =================== 启动 hadoop集群 ==================="
echo " --------------- 启动 hdfs ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/start-dfs.sh"
echo " --------------- 启动 yarn ---------------"
ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/start-yarn.sh"
echo " --------------- 启动 historyserver ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon start historyserver"
;;
"stop")
echo " =================== 关闭 hadoop集群 ==================="
echo " --------------- 关闭 historyserver ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon stop historyserver"
echo " --------------- 关闭 yarn ---------------"
ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/stop-yarn.sh"
echo " --------------- 关闭 hdfs ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/stop-dfs.sh"
;;
*)
echo "Input Args Error..."
;;
esac
保存后退出,然后赋予脚本执行权限
[root@hadoop100 bin]# chmod +x myhadoop.sh
查看三台服务器Java进程脚本:jpsall
[root@hadoop100 bin]# vim jpsall
脚本内容:
#!/bin/bash
for host in hadoop102 hadoop103 hadoop104
do
echo =============== $host ===============
ssh $host jps
done
保存后退出,然后赋予脚本执行权限
[root@hadoop100 bin]# chmod +x jpsall
分发/home/bin目录,保证自定义脚本在三台机器上都可以使用
[root@hadoop100 home]# xsync /home/bin/
==================== hadoop101 ====================
sending incremental file list
bin/
bin/jpsall
bin/myhadoop.sh
bin/xsync
sent 2,225 bytes received 89 bytes 4,628.00 bytes/sec
total size is 2,000 speedup is 0.86
==================== hadoop102 ====================
sending incremental file list
bin/
bin/jpsall
bin/myhadoop.sh
bin/xsync
sent 2,261 bytes received 77 bytes 4,676.00 bytes/sec
total size is 2,000 speedup is 0.86
第十三步:集群时间同步及常用端口号说明
集群时间同步
如果服务器在公网环境(能连接外网),可以不采用集群时间同步,因为服务器会定期和公网时间进行校准;
如果服务器在内网环境,必须要配置集群时间同步,否则时间久了,会产生时间偏差,导致集群执行任务时间不同步。
1)需求
找一个机器,作为时间服务器,所有的机器与这台集群时间进行定时的同步,生产环境根据任务对时间的准确程度要求周期同步。测试环境为了尽快看到效果,采用1分钟同步一次。

2)时间服务器配置(必须root用户)
(1)查看所有节点ntpd服务状态和开机自启动状态
[root@hadoop100 hadoop-3.1.3]# systemctl status ntpd
[root@hadoop100 hadoop-3.1.3]# systemctl start ntpd
[root@hadoop100 hadoop-3.1.3]# systemctl is-enabled ntpd
(2)修改hadoop100的ntp.conf配置文件
[root@hadoop100 hadoop-3.1.3]# vim /etc/ntp.conf
修改内容如下
(a)修改1(授权192.168.10.0-192.168.10.255网段上的所有机器可以从这台机器上查询和同步时间)
#restrict 192.168.10.0 mask 255.255.255.0 nomodify notrap
为restrict 192.168.10.0 mask 255.255.255.0 nomodify notrap
(b)修改2(集群在局域网中,不使用其他互联网上的时间)
server 0.centos.pool.ntp.org iburst
server 1.centos.pool.ntp.org iburst
server 2.centos.pool.ntp.org iburst
server 3.centos.pool.ntp.org iburst
为
#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst
(c)添加3(当该节点丢失网络连接,依然可以采用本地时间作为时间服务器为集群中的其他节点提供时间同步)
server 127.127.1.0
fudge 127.127.1.0 stratum 10
(3)修改hadoop100的/etc/sysconfig/ntpd 文件
[root@hadoop100 hadoop-3.1.3]# vim /etc/sysconfig/ntpd
增加内容如下(让硬件时间与系统时间一起同步)
SYNC_HWCLOCK=yes
(4)重新启动ntpd服务
[root@hadoop100 hadoop-3.1.3]# systemctl start ntpd
(5)设置ntpd服务开机启动
[root@hadoop100 hadoop-3.1.3]# systemctl enable ntpd
3)其他机器配置(必须root用户)
(1)关闭所有节点上ntp服务和自启动
[root@hadoop101 hadoop-3.1.3]# systemctl stop ntpd
[root@hadoop101 hadoop-3.1.3]# systemctl disable ntpd
[root@hadoop102 hadoop-3.1.3]# systemctl stop ntpd
[root@hadoop102 hadoop-3.1.3]# systemctl disable ntpd
(2)在其他机器配置1分钟与时间服务器同步一次
对于Hadoop101
[root@hadoop101 hadoop-3.1.3]# sudo crontab -e
编写定时任务如下:
*/1 * * * * /usr/sbin/ntpdate hadoop100
对于Hadoop102
[root@hadoop102 hadoop-3.1.3]# sudo crontab -e
编写定时任务如下:
*/1 * * * * /usr/sbin/ntpdate hadoop100
(3)修改任意机器时间
[root@hadoop100 hadoop-3.1.3]# date -s "2021-9-11 11:11:11"
(4)1分钟后查看机器是否与时间服务器同步
[root@hadoop100 hadoop-3.1.3]# date
面试题
常用端口号说明
| 端口名称 | Hadoop2.x | Hadoop3.x |
|---|---|---|
| NameNode内部通信端口 | 8020 / 9000 | 8020 / 9000/9820 |
| NameNode HTTP UI | 50070 | 9870 |
| MapReduce查看执行任务端口 | 8088 | 8088 |
| 历史服务器通信端口 | 19888 | 19888 |
常用配置文件说明
| Hadoop2.x | Hadoop3.x |
|---|---|
| core-site.xml | core-site.xml |
| hdfs-site.xml | hdfs-site.xml |
| yarn-site.xml | yarn-site.xml |
| mapred-site.xml | mapred-site.xml |
| slaves | workers |
参考
[1]https://www.bilibili.com/video/BV1Qp4y1n7EN



![[linux api] of_irq_init](https://img-blog.csdnimg.cn/direct/75424a353cf64b6a88322a26e45ee426.png#pic_center)