大家好,我是大明哥,一个专注「死磕 Java」系列创作的硬核程序员。
本文已收录到我的技术网站:https://www.skjava.com。有全网最优质的系列文章、Java 全栈技术文档以及大厂完整面经
回答
在使用 hash 表时, hash 冲突是一个非常常见的问题,该问题出现的主要原因是两个不同的输入值,通过 hash 函数计算得到了相同的 hash 值,尝试存储在 hash 表的同一个位置。解决 hash 冲突主要有如下几种方式:
- 链地址法:解决 hash 冲突最经典的方法。它是通过将具有相同 hash 值的所有元素存储在同一个索引位置的链表中来解决冲突的。
- 开放定址法:在 hash 表的数组本身中找到一个空闲的槽位来存储冲突的元素。它的核心思想是:当发生 hash 冲突时,按照某种探测技术来探测下一个空闲的槽位。
- 再 hash 法:依赖多个 hash 函数来寻找空闲槽位,其思想是:当第一个 hash 函数
h1(x)导致冲突时,系统将尝试第二个 hash 函数h2(x),如果仍然冲突,将继续尝试第三个 hash 函数h3(x),依此类推,直到找到一个空闲槽位为止。
详解
链地址法
链地址法是解决 hash 冲突最经典方法,Java 中的 HashMap 使用的就是它。它是通过将具有相同 hash 值的所有元素存储在同一个索引位置的链表中来解决冲突。这种方法允许多个条目存在于 hash 表的同一个位置,从而避免了冲突直接导致的存储问题。其结构如下:
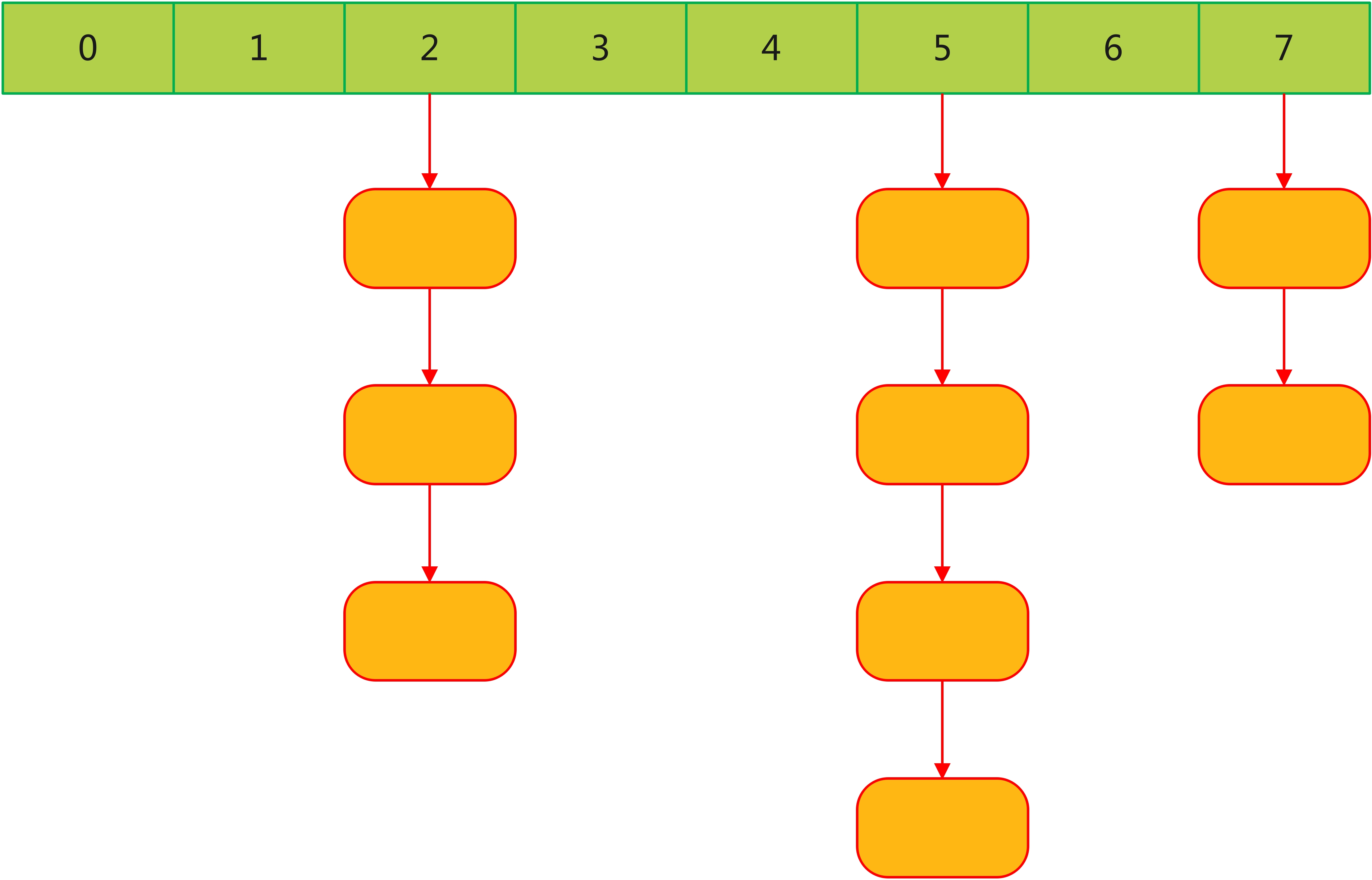
其工作原理如下:
- 初始化 hash 表:创建一个 hash 表(数组),每个索引位置初始为空,用于存放链表的头节点。
- 定义 hash函数:设计一个 hash 函数,该函数将存储的键转换为 hash 表的索引。注意, hash 函数的设计对于性能至关重要,好的 hash 函数能够均匀分布键,从而减少冲突。
- 插入操作:
- 使用 hash 函数计算出键的 hash 值,确定在 hash 表中的索引位置;
- 如果该索引位置没有链表存在,则创建一个新的链表,并将键值对作为链表的第一个节点添加到此索引位置;
- 如果该索引位置已存在链表,则将新的键值对节点添加到链表的末尾或头部;
查询和删除操作和插入步骤一直,先计算 hash 值得到索引位置,然后根据链表来查询或删除。
优缺点
- 优点
- 容易实现:链地址法的数据结构和算法相对简单,易于实现和理解。
- 处理冲突比较灵活:链地址法通过链表来管理同一 hash 值的多个元素,能够灵活应对冲突,理论上链表可以无限延长。
- 动态扩展:由于使用链表来存储相同 hash 值的元素,链地址法允许 hash 表动态增长。
- 删除和添加高效:删除和添加都是在链表中完成,性能较高。
- 缺点
- 增加了内存开销:每个元素都需要额外的存储空间来存储指向链表中下一个元素的指针,增加了内存开销。
- 性能依赖于 hash 函数:链地址法的性能在很大程度上取决于 hash 函数的质量,如果 hash 函数质量不高,则会导致大量数据聚集在少数的几个位置,性能会显著下降。
性能优化
- 使用高质量的hash 函数。
- 取代链表:当链表中的元素超过某个阈值时,则将链表结构调整为红黑树,改善查询效率。
开放定址法
开放定址法与链地址法不同,它是在 hash 表的数组本身中找到一个空闲的槽位来存储冲突的元素。它的核心思想是:当发生 hash 冲突时,按照某种探测技术来探测下一个空闲的槽位。其工作原理如下:
- 初始插入:使用 hash 函数计算数据的 hash 值,得到其在 hash 表中的索引位置。
- 冲突检测:如果该位置已经被占用,表明发生了 hash 冲突。
- 解决冲突:通过某种探测技术在 hash 表中寻找另一个空闲槽位。
- 数据插入:将数据插入到找到的空闲槽位中。
开放定址法主要通过以下三种探测技术解决冲突。
一、线性探测
当发生冲突时,顺序探查下一个槽位,直到找到一个空槽位。这种方法简单,但可能导致"聚集"现象,即连续的槽位被占用,从而影响后续插入和查找操作的效率。
比如我们使用大小为 8 的 hash 表,一次添加 5、10、2、4、18,如下:

详细过程如下:
- 插入5:
h(5) = 5 % 8 = 5,位置 5 是空的,所以 5 插入位置 5。 - 插入10:
h(10) = 10 % 8 = 2,位置 2 是空的,所以 10 插入位置 2。 - 插入2:
h(2) = 2 % 8 = 2,但位置 2 已被 10 占用,因此我们线性探测下一个位置,即位置 3,位置 3 是空的,所以 2 插入位置 3。 - 插入4:
h(4) = 4 % 8 = 4,位置 4 是空的,所以 4 插入位置 4。 - 插入18:
h(18) = 18 % 8 = 2,位置 2 已被 10 占用,位置 3 被 2 占用,继续线性探测到位置 4,但位置 4 被4 占用,再次线性探测到位置 5,位置 5 已被 5 占用。继续探测到位置 6,位置 6 是空的,所以 18 插入位置 6。
二、二次探测
在发生冲突时,不是简单地检查下一个槽位,而是使用二次函数来计算探测的间隔。在二次探测中,如果第一个计算得到的 hash 地址已经被占用,将会尝试一个二次方程式来计算下一个地址,直到找到空位置。
二次探测减少了线性探测的“聚集”现象,但可能仍存在二次聚集问题。
如果我们的 hash 函数是 h(key) = key % table_size,那么在遇到冲突时,二次探测的探测序列会是这样的:
- 第一次探测:
h(key) + 1^2 % table_size - 第二次探测:
h(key) + 2^2 % table_size - 第三次探测:
h(key) + 3^2 % table_size
所以,使用上面的例子,二次探测结果如下:

详细过程如下:
- 插入5:
h(5) = 5 % 8 = 5,位置 5 空,放入 5。 - 插入10:
h(10) = 10 % 8 = 2,位置 2 空,放入 10。 - 插入2:
h(2) = 2 % 8 = 2,位置 2 已占,进行二次探测:2 + 1^2 = 3,位置 3 空,放入 2。 - 插入4:
h(4) = 4 % 8 = 4,位置 4 空,放入 4。 - 插入18:
h(18) = 18 % 8 = 2,位置 2 已占,进行二次探测:2 + 1^2 = 3,位置 3 已占,2 + 2^2 = 6,位置 6 空,放入 18。
三、双重 hash
使用两个 hash 函数。当第一个 hash 函数导致冲突时,使用第二个 hash 函数计算探测步长。这种方法通常能够更均匀地分布 hash 冲突,减少“聚集”现象,提高 hash 表的整体性能。其原理如下:
双重 hash 使用两个 hash 函数,记为 h1(x) 和 h2(x)。当在 hash 表中插入一个元素时,首先使用第一个 hash 函数 h1(x) 确定元素的初始位置。如果该位置没有被占用,则直接插入。如果该位置已被占用(发生了冲突),则使用第二个 hash 函数 h2(x) 来计算探测序列的步长,然后按此步长在 hash 表中进行探测,直到找到空槽或目标元素。
具体公式如下:
p i = ( h 1 ( x ) + i ⋅ h 2 ( x ) ) m o d M p_{i}=\left(h_{1}(x)+i \cdot h_{2}(x)\right) \bmod M pi=(h1(x)+i⋅h2(x))modM
M 表示 hash 表的大小,h1(x) 表示第一个 hash 函数,h2(x) 表示第二个 hash 函数,i 表示探测的次数。
我们继续上面的例子:
h1(x) = x % 8h2(x) = 5 - (x % 5):一般第二个 hash 函数最好能确保它产生的步长是非零的,且与表的大小互质(假设表的大小为 8,那么步长应该是与 8 互质的数)。
详细过程如下:
- 插入5
- 第一次尝试: 使用
h1(5) = 5 % 8 = 5,位置 5 是空的,所以 5 被直接插入到位置 5。
- 第一次尝试: 使用
- 插入10
- 第一次尝试: 使用
h1(10) = 10 % 8 = 2,位置 2 是空的,因此 10 被直接插入到位置 2。
- 第一次尝试: 使用
- 插入2
- 第一次尝试: 使用
h1(2) = 2 % 8 = 2,位置 2 已被 10 占用。 - 双重 hash 探测: 使用
h2(2) = 5 - (2 % 5) = 3,因此新位置计算为(2 + 1*3) % 8 = 5,位置 5 已被 5 占用。 - 继续探测: 更新探测
(2 + 2*3) % 8 = 0,位置 0 是空的,2 被插入到位置 0。
- 第一次尝试: 使用
- 插入4
- 第一次尝试: 使用
h1(4) = 4 % 8 = 4,位置 4 是空的,因此 4 被直接插入到位置 4。
- 第一次尝试: 使用
- 插入18
- 第一次尝试: 使用
h1(18) = 18 % 8 = 2,位置 2 已被 10 占用。 - 双重 hash 探测: 使用
h2(18) = 5 - (18 % 5) = 2,因此新位置计算为(2 + 1*2) % 8 = 4,位置 4 已被 4 占用。 - 继续探测: 更新探测
(2 + 2*2) % 8 = 6,位置 6 是空的,18 被插入到位置 6。
- 第一次尝试: 使用
优点
- 不需要额外的数据结构来存储数据,相比链地址法,使用的内存空间更加少。
- 由于数据存储在连续的内存空间,所以在寻址时可能有更好的缓存性能。
缺点
- 当 hash 表较满时,开放定址法的性能会显著下降,原因是空闲槽位的查找会变得比较困难。
- 有“聚集”现象。
再哈希法
再哈希法与开放定址法中的双重 hash 差不多。再哈希法依赖多个 hash 函数来寻找空闲槽位,其思想是:当第一个 hash 函数 h1(x) 导致冲突时,系统将尝试第二个 hash 函数 h2(x),如果仍然冲突,将继续尝试第三个 hash 函数 h3(x),依此类推,直到找到一个空闲槽位为止。
继续上面例子,比如我们有如下三个 hash 函数:
h1(x) = x % 8h2(x) = 7 - (x % 7)h3(x) = 5 - (x % 5)
- 插入5:
h1(5) = 5 % 8 = 5,位置 5 空,放入 5。 - 插入10:
h1(10) = 10 % 8 = 2,位置 2 空,放入 10。 - 插入2
h1(2) = 2 % 8 = 2,位置 2 已占- 进行二次 hash:
h2(2) = 7 - (2 % 7) = 5,位置 5 已占 - 进行三次 hash:
h3(2) = 5 - (2 % 5) = 3,位置 3 空,放入 2
- 插入4:
h(4) = 4 % 8 = 4,位置 4 空,放入 4。 - 插入18
h1(18) = 18 % 8 = 2,位置 2 已占- 进行二次 hash:
h2(18) = 7 - (18 % 7) = 4,位置4 已占 - 进行三次 hash:
h3(18) = 5 - (18 % 5) = 2,位置 2 已占,直接选择其他 hash 算法,比如这里大明哥就直接穷举了,从 hash 表 0 位置开始,位置 0 空,放入 18。
优点
- 能够减少“聚集”现象:与单一 hash 函数相比,再哈希法通过多个 hash 函数减少了聚集现象,提高了 hash 表的均匀性。
缺点
- 性能开销:虽然再哈希法可以减少冲突,但每次冲突时尝试多个 hash 函数会增加计算开销。
- 依赖 hash 函数:每个 hash 函数都需要精心设计,以确保它们之间的独立性和生成的索引位置的均匀性。否则会格外的增加计算开销。