🏠关于专栏:Linux的浅学到熟知专栏用于记录Linux系统编程、网络编程等内容。
🎯每天努力一点点,技术变化看得见
文章目录
- 程序地址空间概览
- 进程地址空间
程序地址空间概览
我们在执行一个C语言程序时,它包含代码、变量,这些数据均需要空间,那它们的存储规律是什么样的呢?下面我们通过一段代码来验证一下↓↓↓
#include <stdio.h>
#include <stdlib.h>
int g_val = 100;
int u_g_val;
int main(int argc, char* argv[], char* env[])
{
printf("code:%p\n", main);
printf("init_g_val:%p\n", &g_val);
printf("uninit_g_val:%p\n", &u_g_val);
char* arr1 = (char*)malloc(sizeof(char) * 4);
char* arr2 = (char*)malloc(sizeof(char) * 4);
char* arr3 = (char*)malloc(sizeof(char) * 4);
char* arr4 = (char*)malloc(sizeof(char) * 4);
printf("heap:%p\n", arr1);
printf("heap:%p\n", arr2);
printf("heap:%p\n", arr3);
printf("heap:%p\n", arr4);
printf("stack:%p\n", &arr1);
printf("stack:%p\n", &arr2);
printf("stack:%p\n", &arr3);
printf("stack:%p\n", &arr4);
printf("&argc=%p\n", &argc);
printf("argv=%p\n", argv);
printf("env=%p\n", env);
return 0;
}
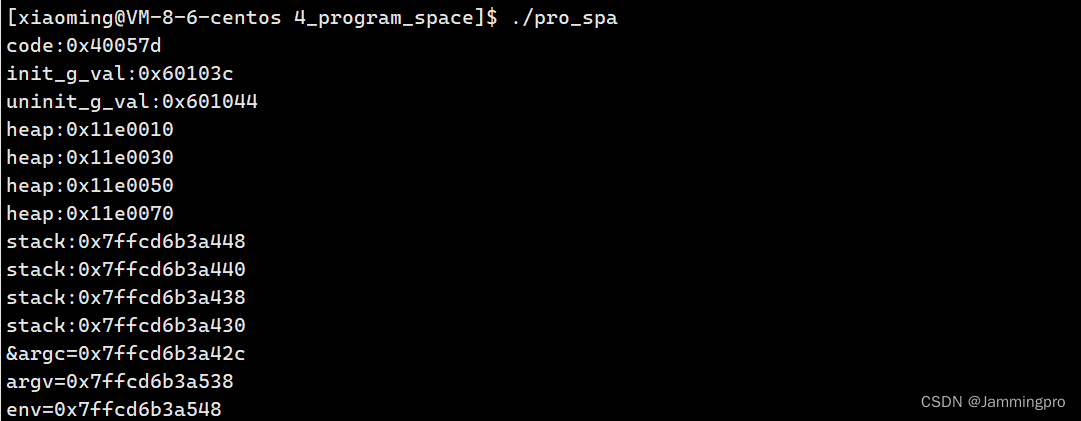
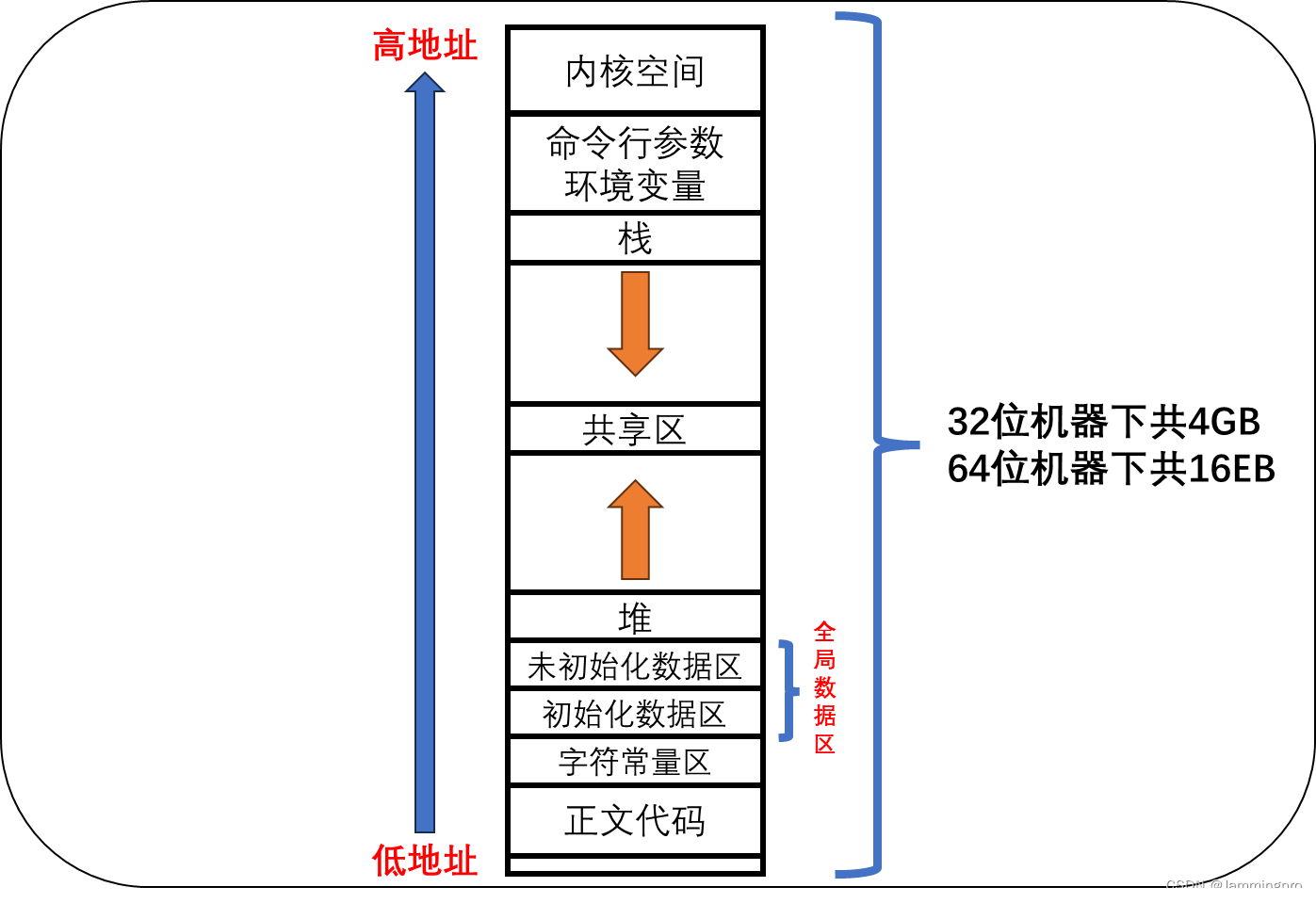
由上面代码的执行结果可知,从低地址到高地址存储的依次是:代码段、初始化全局数据区、未初始化全局数据区、堆区、栈区、命令行参数与环境变量。其中,堆区的空间是从小到大增长的,而栈区的空间是从大到小增长的。因而,可以总结出下图↓↓↓
★ps:32位机器中,表示一个地址时使用的是32个比特位,32个比特位能表示的空间为 2 32 2^{32} 232,即4GB;64位机器中,表示一个地址时则使用64个比特位,64个比特能表示的空间为 2 64 2^{64} 264,即16EB。
但这个空间是真正的内存吗?我们来看一段程序及其运行结果↓↓↓
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
int g_val = 100;
int main()
{
pid_t id = fork();
if(id == 0)
{
//子进程
int cnt = 5;
while(1)
{
printf("I am child process, pid = %d, g_val = %d, &g_val = %p\n", getpid(), g_val, &g_val);
sleep(1);
if(cnt == 0)
{
printf("Child process change g_val from 100 to 200\n");
g_val = 200;
}
cnt--;
}
}
else
{
while(1)
{
printf("I am parent process, pid = %d, g_val = %d, &g_val = %p\n", getpid(), g_val, &g_val);
sleep(1);
}
}
return 0;
}
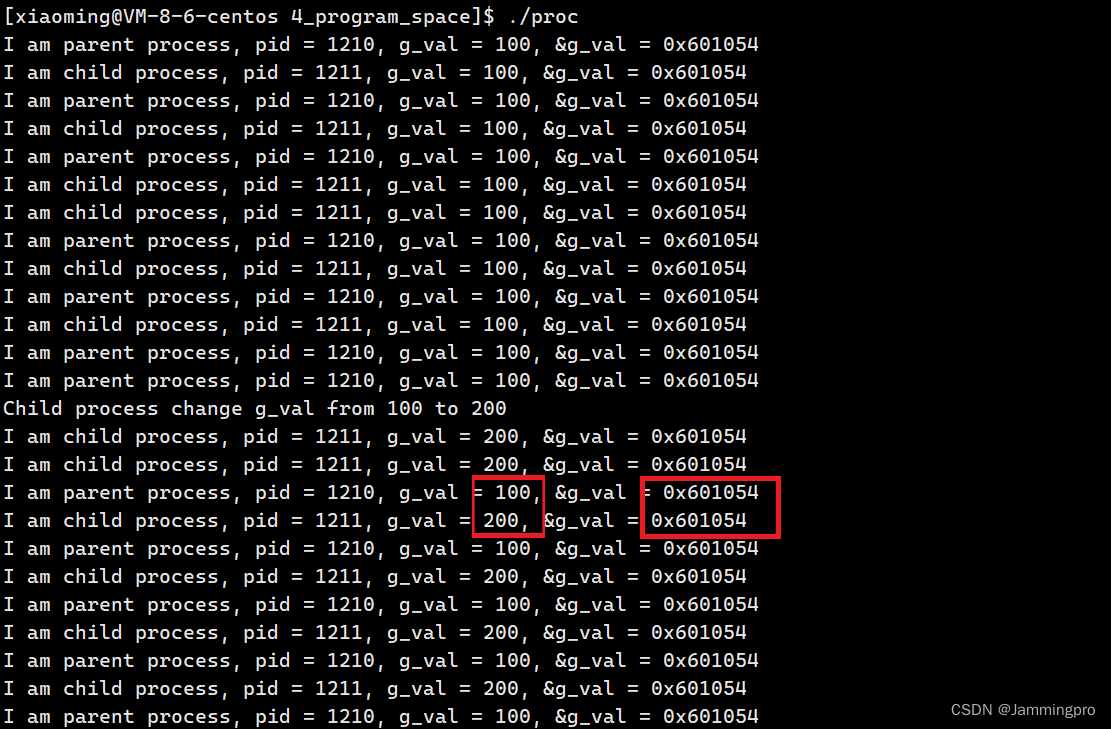
我们发现,子进程将g_val从100改为200后,父子进程的g_val数值不同,但g_val的地址却是相同的!怎么可能从同一个地址中读取不同的数据呢?如果是物理地址,则不可能出现这种情况,说明这里的程序地址空间并不是物理地址。也说明了,我们平时在使用的C/C++指针保存的地址并不是物理地址。这种地址被称为线性地址或虚拟地址。
进程地址空间
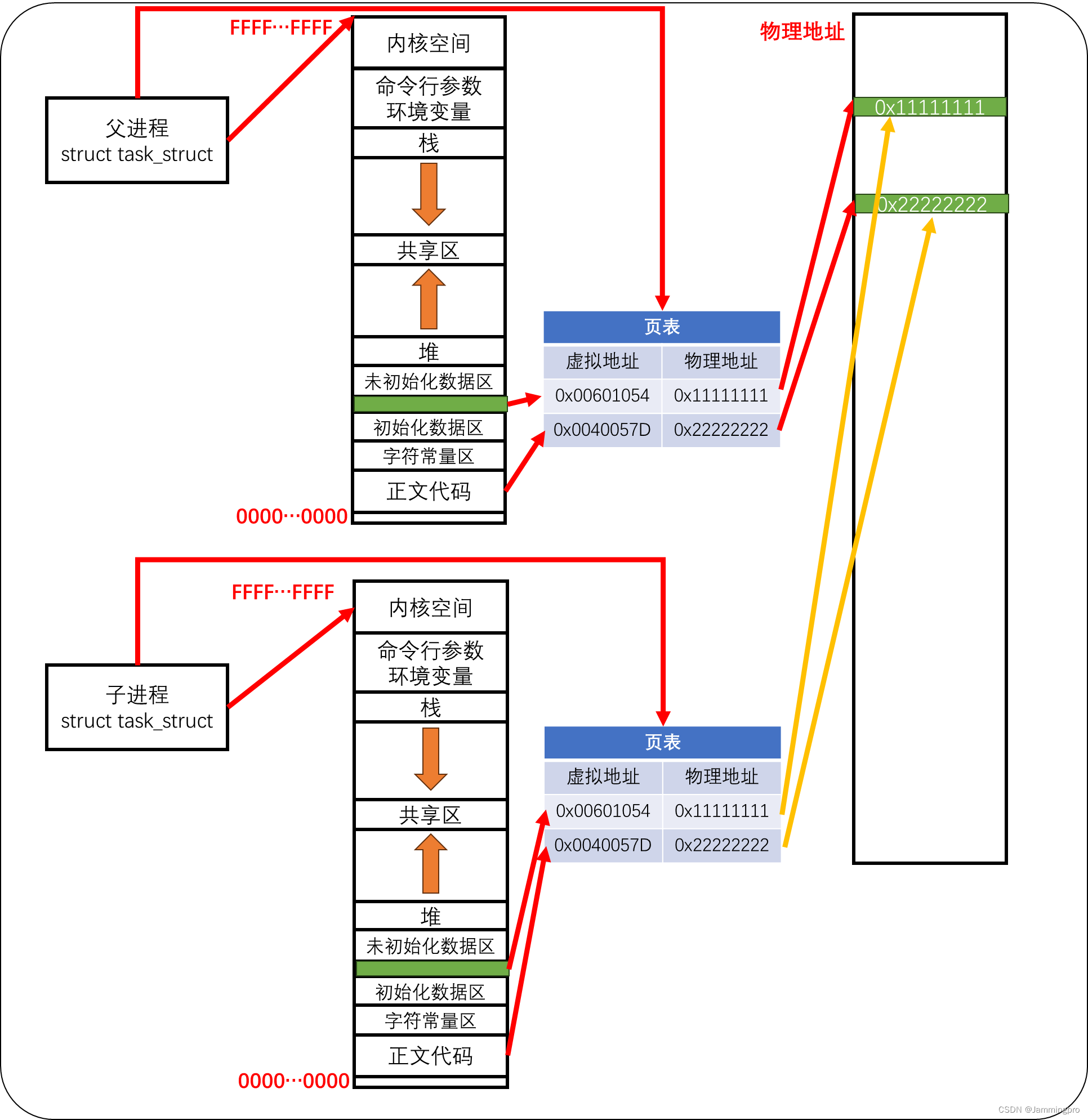
对于每个进程,它维护着一片虚拟地址空间,进程中各个变量的地址是该虚拟空间内的地址,虚拟地址空间中的地址并不是真正的物理地址。那这里的地址如何与真正的物理地址空间产生关联的呢?进程的PCB中指向一张维护虚拟空间与物理地址映射关系的页表(左侧为虚拟地址,右侧为物理地址的key-value映射表)。
当我们获取初始化全局数据g_val时,它的虚拟地址为0x00601054;拿着它的虚拟地址到页表中查找它的物理地址,再从物理地址中返回g_val的值。
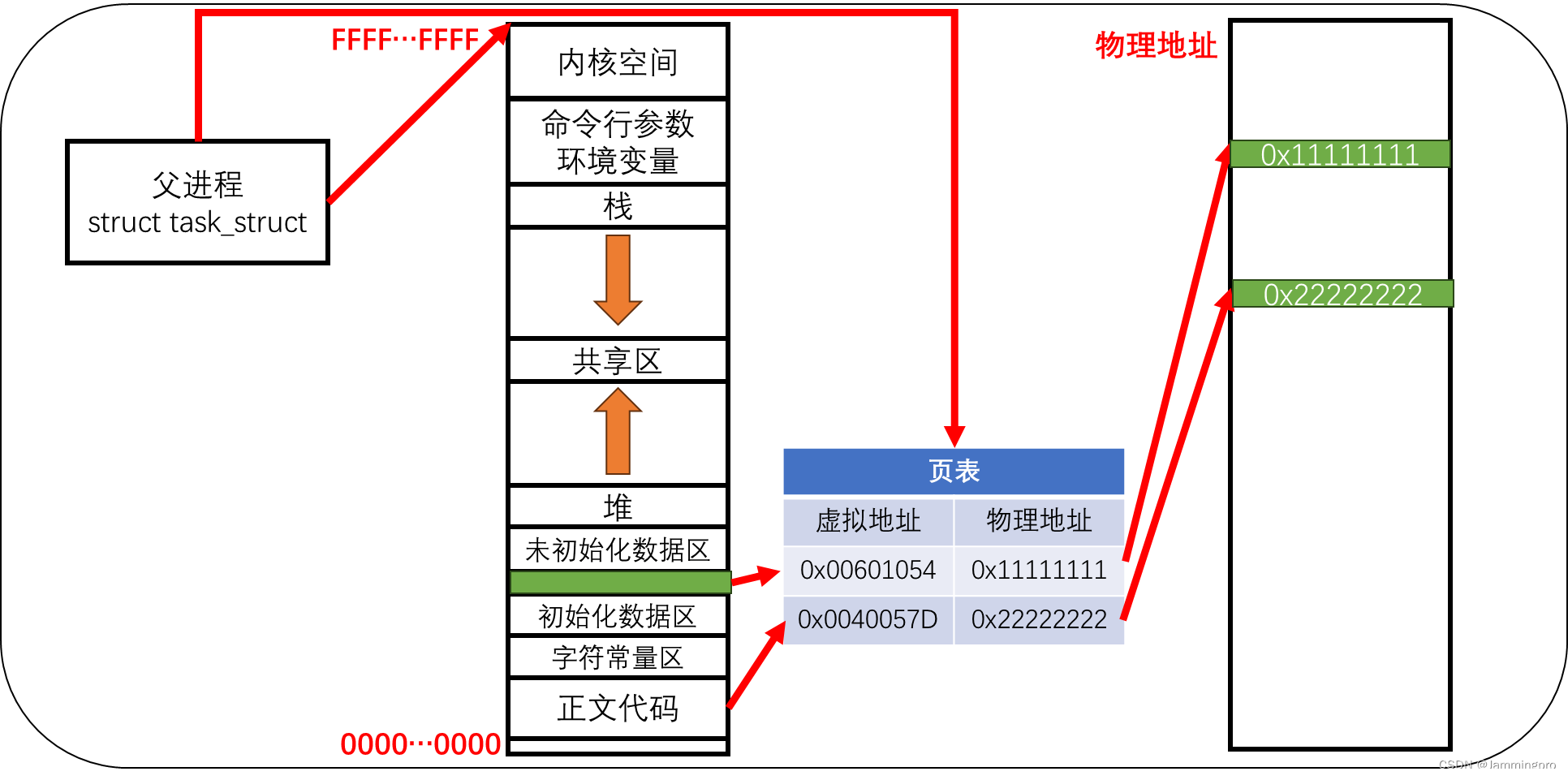
当父进程fork出一个子进程时,由于每个进程都有自己的虚拟地址空间,因而子进程也有自己的虚拟地址空间,该空间是从父进程那里继承下来的。这时,子进程的页表中虚拟地址到物理地址的映射关系与父进程相同。也就是说,子进程与父进程共享同一个g_val的存储位置及正文代码。
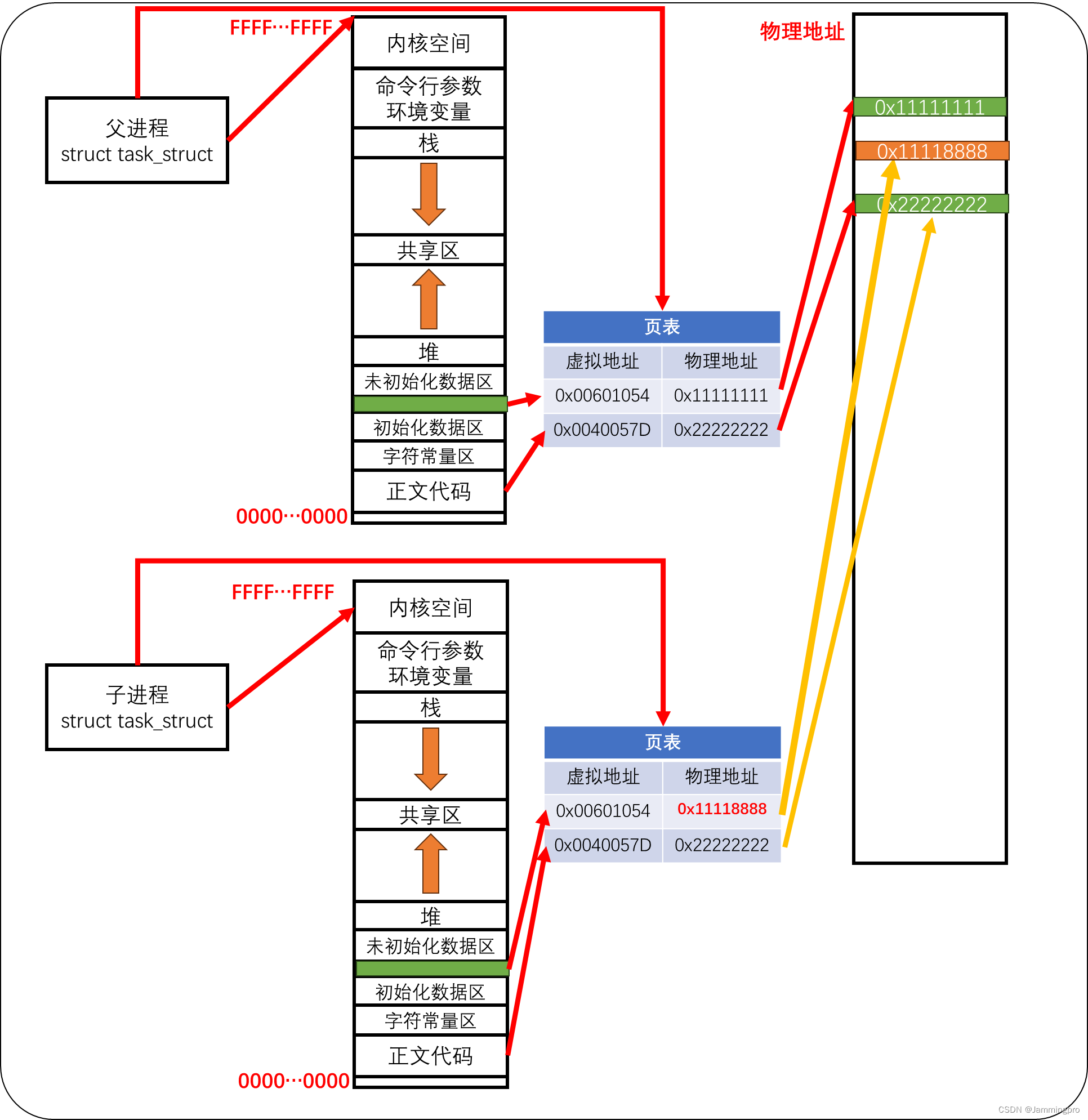
当子进程尝试修改g_val的值时,为了保证进程之间的独立性(也就是说,子进程的数值修改不应该影响父进程),此时就会发生写时拷贝。会给子进程的g_val开辟独立的物理地址空间,而不是与父进程共享同一空间。
★ps:如果子进程在创建时,就将父进程的所有数据拷贝一遍,若此时子进程只用到父进程的1个/2个数据,则会出现大量的空间浪费。引入写时拷贝后,如果子进程不需要对父进程的数据做修改,就不会为子进程的该数据创建独立的物理空间,可以大大提高内存的使用效率,提高整机效率。
下面我们来探索一下三个问题↓↓↓
- 什么叫做地址空间?

在32位机器下,数据与地址总线共32根,每根数据与地址线可以产生充电和放电两种状态,即产生0或1。因此地址总线排列组合形成地址范围[0,2^32],这就是地址空间。
- 如何理解地址空间上的区域划分?
【示例】小学生划分38线
小明和李华是同桌,他们的桌子长度为200cm,他们约定每个人占用100cm的空间。即将课桌划分为[0,100],[101,200]这两个区域。这也就是区域划分。
如果要记录区域的结果,我们就需要先描述再组织。即使用结构体保存。
struct deskstop
{
int xiaoming_start;
int xiaoming_end;
int lihua_start;
int lihua_end;
}
操作系统为每个进程创建了进程地址空间的结构体mm_struct,用于记录每个进程的各个区域(堆区、栈区、代码区等)的起始和结束位置。在已经被分配给某进程的空间范围内,该进程可以随意访问与使用。
- 为什么要有进程地址空间?
【示例1】大富翁的3个私生子
某个有100亿的大富翁,他有3个私生子,3个私生子互相不知道对方的存在,他们各自坚信自己能获得老爹的100亿。当某个儿子有需求时,他回向他父亲申请1万,此时大富翁会将对应的钱数给他;但如果申请100亿时,可能无法申请成功(因为有一部分被大富翁的其他私生子占用了),但他并不会觉得这100亿不是他的,而是觉得自己申请的太多了。
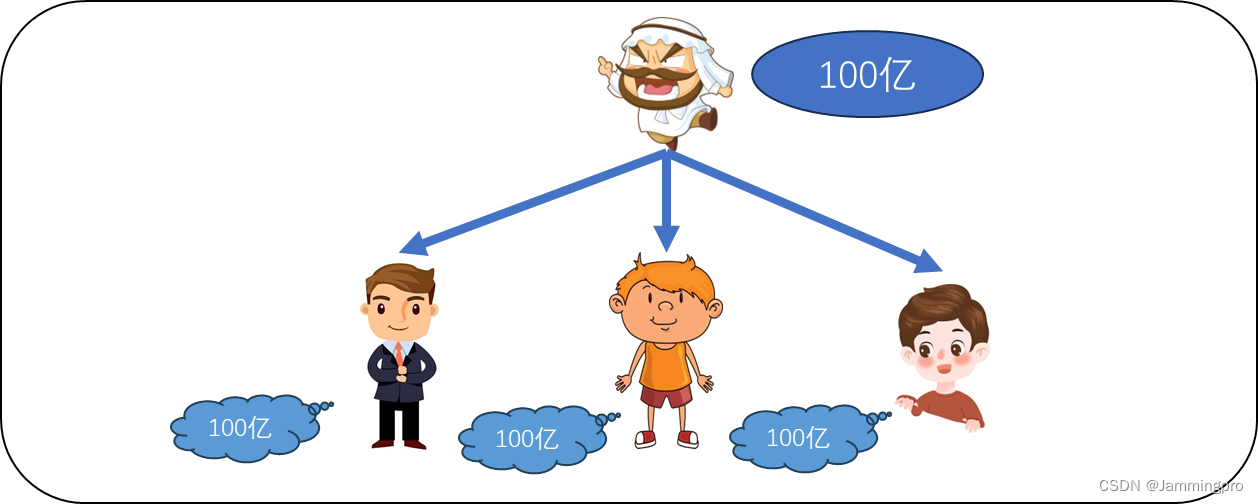
而这里的大富翁就等同于操作系统,而这3个私生子就等同于系统上的进程。操作系统拥有4GB的内存空间,进程坚信自己拥有操作系统的全部空间(即4GB),但通常情况下,进程并不会申请过大的空间。
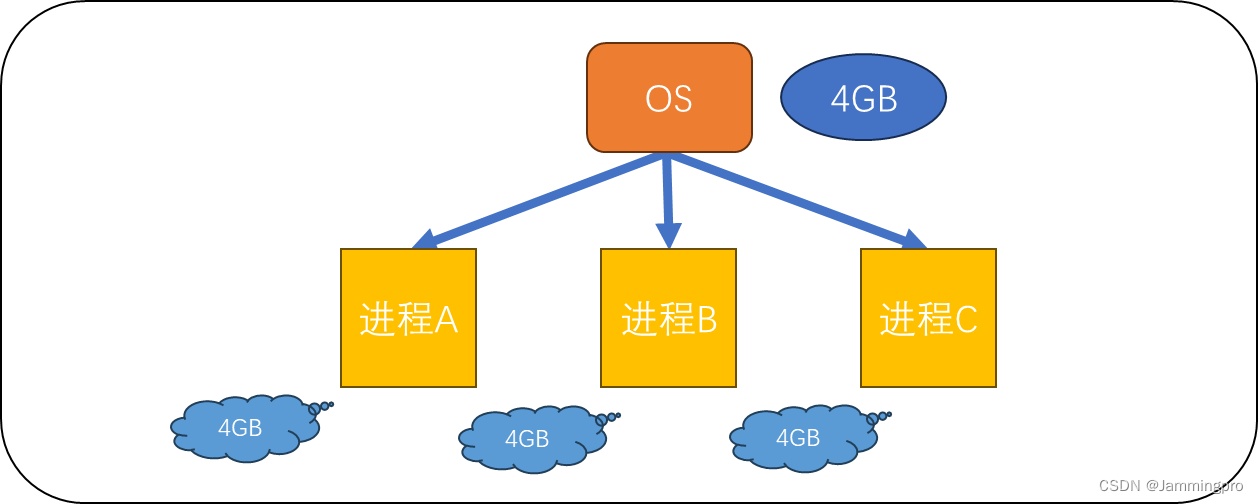
由上面的示例我们可以得出为什么要有进程空间第一个结论:
①让进程以统一视角看待内存(当两个进程申请同一个地址空间时,他们貌似能使用同一个地址空间,但操作系统给它分配的实际的物理地址并不是同一个;只是由于页表的存在,将他们想要的地址和实际操作系统分配的地址形成映射,让进程以为自己独占内存,即让进程得以按统一视角看待内存)
【示例2】小朋友的红包被妈妈管理
小时候收到红包时,妈妈会说:我帮你管理,等你需要买什么了,我再给你。如果我要买的是橡皮擦,妈妈会给我对应的钱数(即合法访问);如果我要买50块钱的游戏机,妈妈不会给我钱还会骂我一顿(即非法访问)。
在操作系统中,页表除了包含虚拟地址到物理地址的映射关系,还记录了该区域的读写权限。当用户对其已申请空间做了超出读写权限外的操作,则会被操作系统识别到,并终止该进程。
★ps:物理地址本身没有读写权限,我们在语言中的const等限制某个地址空间的读写权限,本质是在页表中添加读写权限。
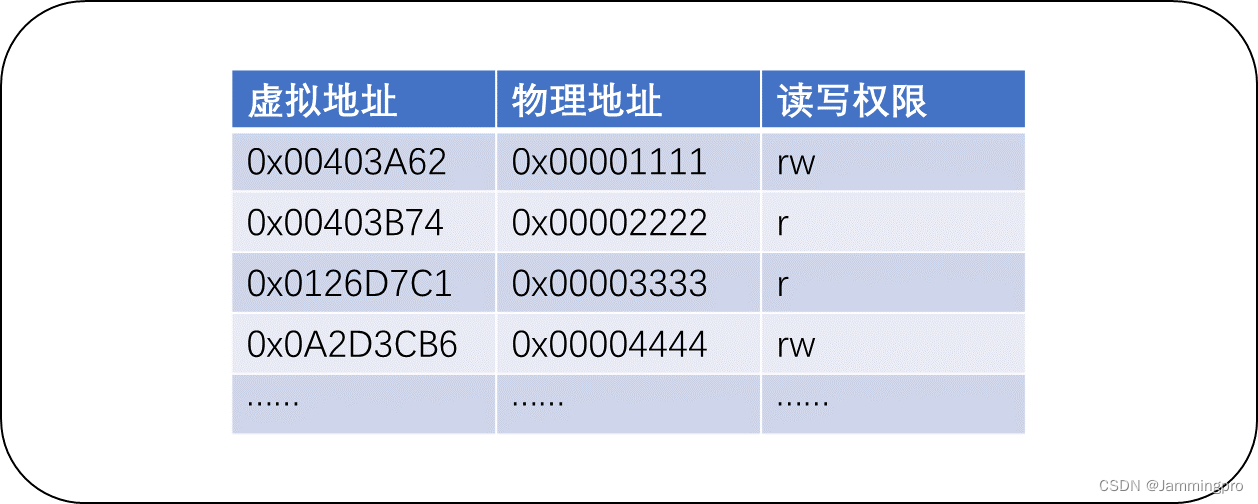
如果直接使用物理地址,而非虚拟地址。当我们对野指针进行访问时,由于物理地址没有读写权限控制,导致我们修改了其他进程的数据,破坏了进程的独立性。因而,使用虚拟地址+页表的方式可以保证进程的独立性。
由这个示例,我们可以的出第二个结论:
②增加进程虚拟地址可以让我们访问内存的时候,增加一个转换的过程,在这个转化过程中,可以对我们的寻址请求进行审查,所以一旦异常访问,直接拦截,该请求不会到达物理内存,即保护了物理内存。
在操作系统中,由于内存空间十分宝贵,进程中的代码和数据不一定会被全部加载到内存(这被称为操作系统的惰性加载方式),因而页表中还会有一个字段,用户标识虚拟地址指向的代码和数据是否在磁盘上。如果虚拟地址映射物理地址时,发现该数据或代码位于磁盘上(不再在内存中),则会引发缺页中断(即当前页表无法映射),此时系统再将对应的代码和数据加载到内存中。
★ps:惰性加载(也称为延迟分配),它可以提高整机效率。因而,在创建进程时,一定是先创建内核数据结构,而不是先加载对应的代码和数据到内存的。如果创建内核数据结构后,调用该进程时,即使代码和数据不存在于内存,只要发生缺页中断即可,这样可以大大提高创建进程的效率。
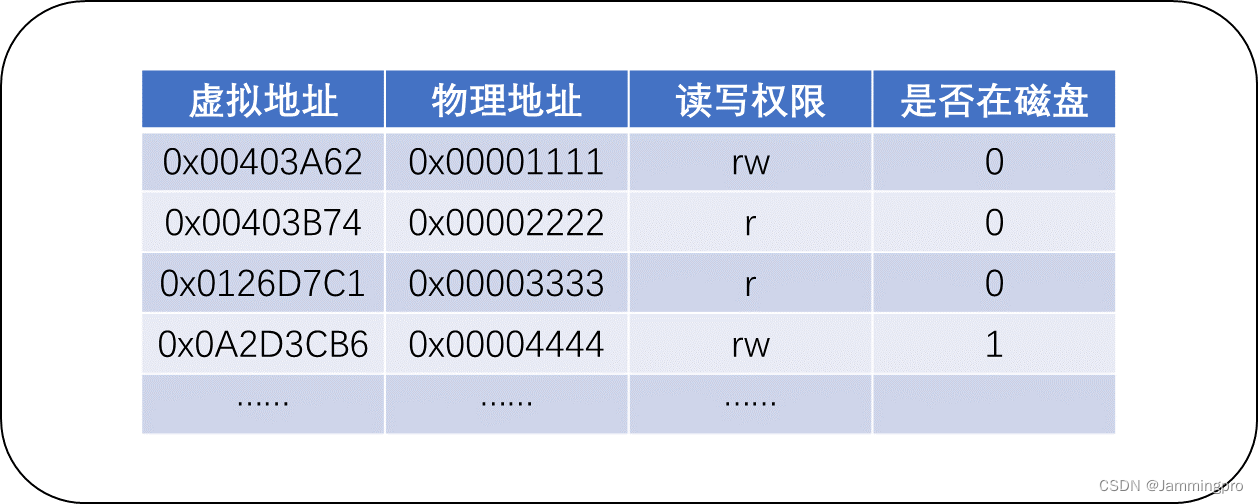
同时,如果因为内存资源紧张,可能会将某个进程挂起,即将它的代码和数据先保存到磁盘中;待内存资源不紧张时再重新加载进来,但重新加载后的物理地址可能与之前的物理地址不再相同。假设进程没有使用虚拟地址空间+页表映射的方式,则每次将进程代码和数据加载到内存就需要改动PCB中的地址空间内容,而不是修改页表的内容。这么样将使得进程管理与内存管理耦合度过高。
同时,物理内存中几乎所有的数据和代码都是乱序的,由于页表的存在,它可以将物理地址和虚拟地址进行映射,在进程视角,可以将内存分布有序化。
由上面可以得出第三个结论:
③因为有地址空间和页表的存在,将进程管理模块和内存管理模块进行了解耦合。
从上面还可以得到一个结论:
当某个进程被挂起(即它的代码和数据均在磁盘),它的状态可能是S/T/t/D等状态,而没有专门的挂起状态。但只要识别到它的代码段的"是否在磁盘上"标识为1,则表明该进程已经挂起,故无需专门设置挂起状态。
★ps:C/C++上new/malloc空间时,本质上是在哪里申请的?物理空间还是虚拟空间呢?
本质上是在虚拟地址空间上申请的,物理空间甚至一个字段都不给。而是当我们需要访问对应内存空间时,才会执行内存的相关管理(由操作系统自动完成),再从物理空间处申请空间。
此时,有个问题:当我们的程序,在编译的时候,形成可执行程序的时候,没有被加载到内存中之前,我们的程序内部有地址吗?
我们可以使用obj -afh查看可执行程序的反汇编↓↓↓
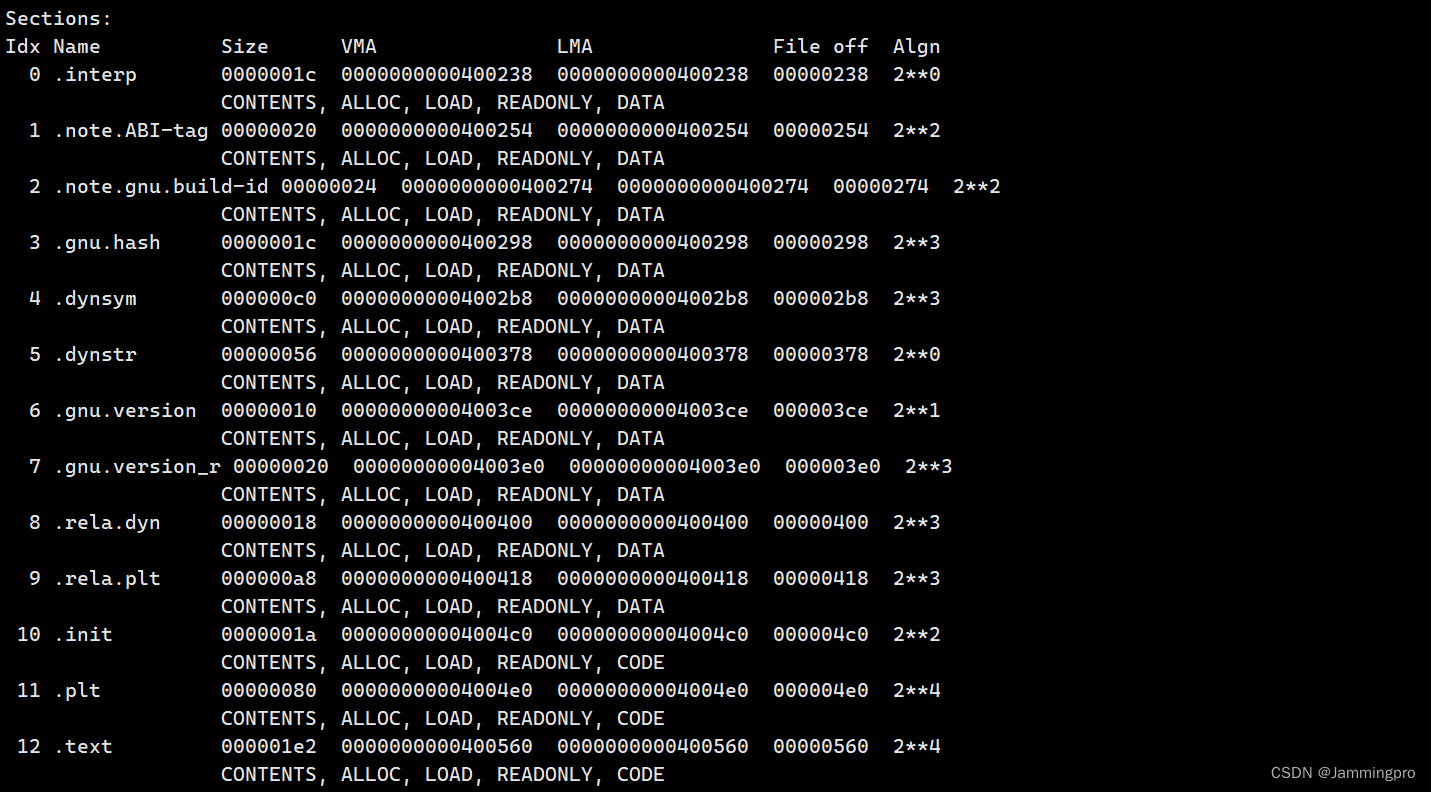
由上面可知,可执行程序在编译的时候,内部已经有地址了!(即VMA,虚拟地址)。地址空间不仅仅理解成操作系统内部要遵守的。编译器编译代码的时候,就已经给我们形成了各个区域:代码区、数据区…并且采用与Linux内核相同的编址方式,给每个变量,每一行代码都进行了编址。故程序在编译的时候,每一个字段早已经具有一个虚拟地址。
程序内部采用编译器编译好的虚拟地址,当程序加载到内存的时候,每行代码、每个变量就具有了虚拟到物理地址的映射。当CPU读到某行指令时,指令内部的虚拟地址会被转化为物理地址再执行。
在读完这篇文章后,我们对进程有了更深的理解,可以得出进程=内核数据结构(PCB+页表+进程地址空间)+代码和数据。
🎈欢迎进入从浅学到熟知Linux专栏,查看更多文章。
如果上述内容有任何问题,欢迎在下方留言区指正b( ̄▽ ̄)d