-
超过并发,超高性能分布式ID生成系统的要求
- 在复杂的超高并发、分布式系统中,往往需要对大量的数据和消息进行唯一标识
- 如在高并发、分布式的金融、支付、餐饮、酒店、电影等产品的系统中,数据日渐增长,对数据分库分表后需要有一个唯一ID来标识一条数据或消息,数据库的自增ID显然不能满足需求;特别一点的如订单、骑手、优惠券也都需要有唯一ID做标识
- 业务系统对ID号的要求有哪些呢?
- 全局唯一性:不能出现重复的ID号,既然是唯一标识,这是最基本的要求。
- 趋势递增:在MySQL InnoDB引擎中使用的是聚集索引,由于多数RDBMS使用B-tree的数据结构来存储索引数据,在主键的选择上面我们应该尽量使用有序的主键保证写入性能。
- 单调递增:保证下一个ID一定大于上一个ID,例如事务版本号、IM增量消息、排序等特殊需求。
- 信息安全:如果ID是连续的,恶意用户的扒取工作就非常容易做了,直接按照顺序下载指定URL即可;如果是订单号就更危险了,竞对可以直接知道我们一天的单量。所以在一些应用场景下,会需要ID无规则、不规则。
-
超高并发、超高性能分布式ID生成系统三个超高
- 超低延迟:平均延迟和TP999延迟都要尽可能低;
- 超高可用:可用性5个9;
- 超高并发: 高QPS。
- 超高并发, 最好是100Wqps以上,比如滴滴的tinyid,就达到千万QPS
-
什么是本地ID生成器、分布式ID生成器
- 本地ID生成器是指在本地环境中生成唯一标识符(ID)的工具或算法
- 本地ID生成器是相对于 分布式ID生成器而言的。二者的区分不是ID的用途,而是生产ID是否存在 网络IO开销
- 本地ID生成器在本地生产ID,没有网络IO开销
- 分布式ID生成器 需要进行远程调用生产ID,有网络IO开销
- 本地ID生成器所生产的ID并不是仅仅用于本地,也会用于分布式系统,拥有分布式系统中唯一标识实体或资源,例如数据库记录、消息、文件等
- 在设计本地ID生成器时,需要考虑以下几个方面:
- 唯一性:生成的ID必须在整个系统中是唯一的,以避免冲突。
- 可排序性:生成的ID应该具有可排序性,以便根据ID的顺序进行查询和排序操作。
- 性能:ID生成的过程应该高效,不应该成为系统的瓶颈。
- 可读性:生成的ID可以是可读的,便于调试和理解。
- 分布式支持:如果系统是分布式的,需要确保在多个节点上生成的ID也是唯一的。
-
常见的本地ID生成器算法包括
- 自增ID:使用一个计数器,在每次生成ID时递增。这种方式简单高效,但在分布式环境中需要额外的考虑,以避免冲突。
- UUID(Universally Unique Identifier):使用标准的UUID算法生成唯一的128位标识符。UUID可以使用时间戳、MAC地址等信息来保证唯一性,但不具备可排序性。
- 雪花算法(Snowflake):雪花算法是Twitter开源的一种分布式ID生成算法。它使用一个64位的整数,结合时间戳、机器ID和序列号来生成唯一的ID。雪花算法具备可排序性和高性能,适用于分布式环境。
-
常见的分布式ID生成器算法包括
- 数据库自增id,如Mysql 生产ID
- Redis生成ID
- Mongdb 生产ID
- zookeeper 生产ID
- 其他的分布式生产ID
- 分布式雪花算法
- 分布式号段算法
-
uuid
- UUID是一种本地生成ID的方式
- UUID(Universally Unique Identifier)的标准型式包含32个16进制数字,以连字号分为五段,形式为8-4-4-4-12的36个字符。
- UUID的优点是:性能非常高,本地生成,没有网络消耗
- UUID的缺点是:不易于存储,信息不安全
- uuid有两种包
- github.com/google/uuid ,仅支持V1和V4版本
- github.com/gofrs/uuid ,支持全部五个版本
- 下面简单说下五种版本的区别
- Version 1,基于mac地址、时间戳。
- Version 2,based on timestamp,MAC address and POSIX UID/GID (DCE 1.1)
- Version 3,Hash获取入参并对结果进行MD5。
- Version 4,纯随机数。
- Version 5,based on SHA-1 hashing of a named value
- 特点
- 5个版本可供选择。
- 定长36字节,偏长。
- 无序。
-
shortuuid
- 初始值基于uuid Version4
- 第二步根据alphabet变量长度(定长57)计算id长度(定长22)
- 第三步依次用DivMod(欧几里得除法和模)返回值与alphabet做映射,合并生成id
- 特点
- 基于uuid,但比uuid的长度短,定长22字节
-
xid
- XID(eXtended Identifier)是一个用于生成全局唯一标识符(GUID)的库。它是一个基于时间的、分布式的ID生成算法,旨在提供高性能和唯一性。
- XID生成的ID是一个64位的整数,由以下部分组成
- 时间戳(40位):使用40位存储纳秒级的时间戳,可以支持约34年的时间范围。与雪花算法不同,XID使用纳秒级时间戳,因此具有更高的时间分辨率。
- 机器ID(16位):使用16位表示机器的唯一标识符。每个机器在分布式系统中应具有唯一的机器ID,可以手动配置或通过自动分配获得。
- 序列号(8位):使用8位表示在同一纳秒内生成的序列号。如果在同一纳秒内生成的ID数量超过了8位能够表示的范围,那么会等待下一纳秒再生成ID。
- xid是由时间戳、进程id、Mac地址、随机数组成
- 有序性来源于对随机数部分的原子+1
- XID特点
- 长度短。
- 有序。
- 不重复。
- 时间戳这个随机数原子+1操作,避免了时钟回拨的问题
- XID生成的ID是趋势递增、唯一且可排序的,适用于分布式环境下的ID生成需求。与雪花算法相比,XID具有更高的时间分辨率,但在唯一性方面稍微弱一些,因为它使用了较短的机器ID和序列号
- XID库提供了生成ID、解析ID和验证ID的功能
- XID是一个用于生成全局唯一标识符的库,基于时间和机器ID生成唯一的ID。
-
ksuid
- KSUID(K-Sortable Unique Identifier)是一种用于生成全局唯一标识符(GUID)的算法和格式。它是由Segment.io开发的一种分布式ID生成方案,旨在提供高性能、唯一性和可排序性
- KSUID生成的ID是一个全局唯一的字符串,由以下部分组成
- 时间戳(32位):使用32位存储秒级的时间戳,表示自协调世界时(UTC)1970年1月1日以来的秒数。与传统的UNIX时间戳相比,KSUID使用了更长的时间戳,可以支持更长的时间范围。
- 随机字节(16位):使用16位随机生成的字节,用于增加ID的唯一性。
- 附加信息(可选):在KSUID的格式中,还可以包含附加的信息,例如节点ID或其他标识符。这部分是可选的,可以根据需要进行使用。
- KSUID生成的ID是按照时间顺序排序的,因此可以方便地按照生成的顺序进行排序和比较。它具有全局唯一性,并且不依赖于任何中央化的ID生成服务
- KSUID是一种用于生成全局唯一标识符的算法和格式。它具有高性能、唯一性和可排序性的特点,适用于分布式系统中的ID生成需求。通过使用 github.com/segmentio/ksuid 库,可以方便地生成和操作KSUID
-
ulid
- 随机数和时间戳组成
-
snowflake
- Snowflake是Twitter开源的一种分布式ID生成算法,用于在分布式系统中生成全局唯一的ID。它的设计目标是高性能、低延迟和趋势递增的ID生成
- Snowflake生成的ID是一个64位的整数,由以下部分组成
- 时间戳(41位):使用41位存储毫秒级的时间戳,表示自定义的起始时间(Epoch)到生成ID的时间之间的毫秒数。
- 节点ID(10位):用于标识不同的节点或机器。在分布式系统中,每个节点应具有唯一的节点ID
- 序列号(12位):在同一毫秒内生成的序列号。如果在同一毫秒内生成的ID数量超过了12位能够表示的范围,那么会等待下一毫秒再生成ID
- Snowflake生成的ID具有趋势递增的特点,因为高位部分是基于时间戳生成的。这样设计的目的是为了在数据库索引中提供更好的性能,使新生成的ID更容易被插入到索引的末尾,减少索引的分裂和碎片化
- Snowflake是一种分布式ID生成算法,用于在分布式系统中生成全局唯一的ID。它具有高性能、低延迟和趋势递增的特点,适用于需要在分布式环境下生成唯一ID的场景
- 相对于UUID来说,雪花算法不会暴露MAC地址更安全、生成的ID也不会过于冗余
- 雪花的一部分ID序列是基于时间戳的,snowflake 存在一个很大的问题:时钟回拨 问题
-
什么是 时钟回拨问题
- 服务器上的时间突然倒退回之前的时间
- 可能是人为的调整时间;
- 也可能是服务器之间的时间校对
- 具体来说,时钟回拨(Clock Drift)指的是系统时钟在某个时刻向回调整,即时间向过去移动。时钟回拨可能发生在分布式系统中的某个节点上,这可能是由于时钟同步问题、时钟漂移或其他原因导致的
- 时钟回拨可能对系统造成一些问题,特别是对于依赖于时间顺序的应用程序或算法
- 在分布式系统中,时钟回拨可能导致以下问题
- ID冲突:如果系统使用基于时间的算法生成唯一ID(如雪花算法),时钟回拨可能导致生成的ID与之前生成的ID冲突,破坏了唯一性
- 数据不一致:时钟回拨可能导致不同节点之间的时间戳不一致,这可能影响到分布式系统中的时间相关操作,如事件排序、超时判断等。数据的一致性可能会受到影响
- 缓存失效:时钟回拨可能导致缓存中的过期时间计算错误,使得缓存项在实际过期之前被错误地认为是过期的,从而导致缓存失效
- 为了应对时钟回拨问题,可以采取以下措施:
- 使用时钟同步服务:通过使用网络时间协议(NTP)等时钟同步服务,可以将节点的时钟与参考时钟进行同步,减少时钟回拨的可能性
- 引入时钟漂移校正:在分布式系统中,可以通过周期性地校正节点的时钟漂移,使其保持与其他节点的时间同步
- 容忍时钟回拨:某些应用场景下,可以容忍一定范围的时钟回拨。在设计应用程序时,可以考虑引入一些容错机制,以适应时钟回拨带来的影响
- 通过使用时钟同步服务、时钟漂移校正和容忍机制等方法,可以减少时钟回拨带来的问题
- 服务器上的时间突然倒退回之前的时间
-
分布式ID:数据库自增ID
- 特点如下:
- 架构简单容易实现。
- ID有序递增,IO写入连续性好。
- INT和BIGINT类型占用空间较小。
- 由于有序递增,易暴露业务量。
- 受到数据库性能限制,对高并发场景不友好。
- bigint最大是2^64-1,但是数据库单表肯定放不了这么多,那么就涉及到分表。如果业务量真的太大了,主键的自增id涨到头了,会发生什么?报错:主键冲突。
- 特点如下:
-
分布式ID:Redis生成ID
- 通过redis的原子操作INCR和INCRBY获得id
- 相比数据库自增ID,redis性能更好、更加灵活
- 不过架构强依赖redis,redis在整个架构中会产生单点问题
- 在流量较大的场景下,网络耗时也可能成为瓶颈
-
分布式ID:ZooKeeper唯一ID
- ZooKeeper是使用了Znode结构中的Zxid实现顺序增ID
- Zookeeper类似一个文件系统,每个节点都有唯一路径名(Znode),Zxid是个全局事务计数器,每个节点发生变化都会记录响应的版本(Zxid),这个版本号是全局唯一且顺序递增的
- 这种架构还是出现了ZooKeeper的单点问题
-
分布式雪花算法
- Snowflake 可以很容易扩展成为分布式架构
- Snowflake + 机器固定编号
- Snowflake +zookeeper 自增编号
- Snowflake + 数据库 自增编号
- 分布式雪花算法的代表作:百度的 UidGenerator
- UidGenerator是Java实现的, 基于Snowflake算法的唯一ID生成器
- UidGenerator以组件形式工作在应用项目中, 支持自定义workerId位数和初始化策略, 从而适用于docker等虚拟化环境下实例自动重启、漂移等场景
- 在实现上, UidGenerator通过借用未来时间来解决sequence天然存在的并发限制
- 采用RingBuffer来缓存已生成的UID, 并行化UID的生产和消费, 同时对CacheLine补齐,避免了由RingBuffer带来的硬件级「伪共享」问题. 最终单机QPS可达600万
- Snowflake 可以很容易扩展成为分布式架构
-
分布式雪花ID方案1:600万qps的百度UidGenerator
-
依赖版本:
- Java8及以上版本,
- MySQL(内置WorkerID分配器, 启动阶段通过DB进行分配; 如自定义实现, 则DB非必选依赖)
-
回顾Snowflake算法
-
Snowflake算法描述:指定机器 & 同一时刻 & 某一并发序列,是唯一的。据此可生成一个64 bits的唯一ID(long)。
-

-
固定1bit符号标识,即生成的UID为正数
-
delta seconds (28 bits)
- 当前时间,相对于时间基点"2016-05-20"的增量值,单位:秒,最多可支持约8.7年
-
worker id (22 bits)
- 机器id,最多可支持约420w次机器启动。内置实现为在启动时由数据库分配,默认分配策略为用后即弃,后续可提供复用策略
-
sequence (13 bits)
- 每秒下的并发序列,13 bits可支持每秒8192个并发
-
-
CachedUidGenerator
-
RingBuffer环形数组,数组每个元素成为一个slot。RingBuffer容量,默认为Snowflake算法中sequence最大值,且为2^N。可通过 boostPower 配置进行扩容,以提高RingBuffer读写吞吐量
-
Tail指针、Cursor指针用于环形数组上读写slot:
- Tail指针
- 表示Producer生产的最大序号(此序号从0开始,持续递增)。Tail不能超过Cursor,即生产者不能覆盖未消费的slot。当Tail已赶上curosr,此时可通过 rejectedPutBufferHandler 指定PutRejectPolicy
- Cursor指针
- 表示Consumer消费到的最小序号(序号序列与Producer序列相同)。Cursor不能超过Tail,即不能消费未生产的slot。当Cursor已赶上tail,此时可通过 rejectedTakeBufferHandler 指定TakeRejectPolicy
- Tail指针
-
CachedUidGenerator采用了双RingBuffer,Uid-RingBuffer用于存储Uid、Flag-RingBuffer用于存储Uid状态(是否可填充、是否可消费)
-
由于数组元素在内存中是连续分配的,可最大程度利用CPU cache以提升性能。但同时会带来「伪共享」FalseSharing问题,为此在Tail、Cursor指针、Flag-RingBuffer中采用了CacheLine补齐方式
5.
-
RingBuffer填充时机
- 初始化预填充
- RingBuffer初始化时,预先填充满整个RingBuffer.
- 即时填充
- Take消费时,即时检查剩余可用slot量( tail - cursor ),如小于设定阈值,则补全空闲slots。阈值可通过 paddingFactor 来进行配置,请参考Quick Start中CachedUidGenerator配置
- 周期填充
- 通过Schedule线程,定时补全空闲slots。可通过 scheduleInterval 配置,以应用定时填充功能,并指定Schedule时间间隔
- 初始化预填充
-
-
UidGeneratorQuick Start
-
介绍如何在基于Spring的项目中使用UidGenerator, 具体流程如下:
-
步骤1:安装依赖
- 先下载Java8, MySQL和Maven
-
设置环境变量
-
maven无须安装, 设置好MAVEN_HOME即可. 可像下述脚本这样设置JAVA_HOME和MAVEN_HOME, 如已设置请忽略
-
export MAVEN_HOME=/xxx/xxx/software/maven/apache-maven-3.3.9 export PATH=$MAVEN_HOME/bin:$PATH JAVA_HOME="/Library/Java/JavaVirtualMachines/jdk1.8.0_91.jdk/Contents/Home"; export JAVA_HOME;
-
-
创建表WORKER_NODE
-
运行sql脚本以导入表WORKER_NODE, 脚本如下:
-
DROP DATABASE IF EXISTS `xxxx`; CREATE DATABASE `xxxx` ; use `xxxx`; DROP TABLE IF EXISTS WORKER_NODE; CREATE TABLE WORKER_NODE ( ID BIGINT NOT NULL AUTO_INCREMENT COMMENT 'auto increment id', HOST_NAME VARCHAR(64) NOT NULL COMMENT 'host name', PORT VARCHAR(64) NOT NULL COMMENT 'port', TYPE INT NOT NULL COMMENT 'node type: ACTUAL or CONTAINER', LAUNCH_DATE DATE NOT NULL COMMENT 'launch date', MODIFIED TIMESTAMP NOT NULL COMMENT 'modified time', CREATED TIMESTAMP NOT NULL COMMENT 'created time', PRIMARY KEY(ID) ) COMMENT='DB WorkerID Assigner for UID Generator',ENGINE = INNODB; -
修改mysql.properties配置中, jdbc.url, jdbc.username和jdbc.password, 确保库地址, 名称, 端口号, 用户名和密码正确.
-
-
步骤3:修改Spring配置
-
提供了两种生成器: DefaultUidGenerator、CachedUidGenerator
-
如对UID生成性能有要求, 请使用CachedUidGenerator
-
DefaultUidGenerator配置
-
<!-- DefaultUidGenerator --> <bean id="defaultUidGenerator" class="com.baidu.fsg.uid.impl.DefaultUidGenerator" lazy-init="false"> <property name="workerIdAssigner" ref="disposableWorkerIdAssigner"/> <!-- Specified bits & epoch as your demand. No specified the default value will be used --> <property name="timeBits" value="29"/> <property name="workerBits" value="21"/> <property name="seqBits" value="13"/> <property name="epochStr" value="2016-09-20"/> </bean> <!-- 用完即弃的WorkerIdAssigner,依赖DB操作 --> <bean id="disposableWorkerIdAssigner" class="com.baidu.fsg.uid.worker.DisposableWorkerIdAssigner" /> -
CachedUidGenerator配置
-
<!-- CachedUidGenerator --> <bean id="cachedUidGenerator" class="com.baidu.fsg.uid.impl.CachedUidGenerator"> <property name="workerIdAssigner" ref="disposableWorkerIdAssigner" /> <!-- 以下为可选配置, 如未指定将采用默认值 --> <!-- Specified bits & epoch as your demand. No specified the default value will be used --> <property name="timeBits" value="29"/> <property name="workerBits" value="21"/> <property name="seqBits" value="13"/> <property name="epochStr" value="2016-09-20"/> <!-- RingBuffer size扩容参数, 可提高UID生成的吞吐量. --> <!-- 默认:3, 原bufferSize=8192, 扩容后bufferSize= 8192 << 3 = 65536 --> <property name="boostPower" value="3"></property> <!-- 指定何时向RingBuffer中填充UID, 取值为百分比(0, 100), 默认为50 --> <!-- 举例: bufferSize=1024, paddingFactor=50 -> threshold=1024 * 50 / 100 = 512. --> <!-- 当环上可用UID数量 < 512时, 将自动对RingBuffer进行填充补全 --> <property name="paddingFactor" value="50"></property> <!-- 另外一种RingBuffer填充时机, 在Schedule线程中, 周期性检查填充 --> <!-- 默认:不配置此项, 即不实用Schedule线程. 如需使用, 请指定Schedule线程时间间隔, 单 位:秒 --> <property name="scheduleInterval" value="60"></property> <!-- 拒绝策略: 当环已满, 无法继续填充时 --> <!-- 默认无需指定, 将丢弃Put操作, 仅日志记录. 如有特殊需求, 请实现 RejectedPutBufferHandler接口(支持Lambda表达式) --> <property name="rejectedPutBufferHandler" ref="XxxxYourPutRejectPolicy"> </property> <!-- 拒绝策略: 当环已空, 无法继续获取时 --> <!-- 默认无需指定, 将记录日志, 并抛出UidGenerateException异常. 如有特殊需求, 请实现 RejectedTakeBufferHandler接口(支持Lambda表达式) --> <property name="rejectedTakeBufferHandler" ref="XxxxYourTakeRejectPolicy"> </property> </bean> <!-- 用完即弃的WorkerIdAssigner, 依赖DB操作 --> <bean id="disposableWorkerIdAssigner" class="com.baidu.fsg.uid.worker.DisposableWorkerIdAssigner" />
-
-
Mybatis配置
-
mybatis-spring.xml配置说明如下
-
<!-- Spring annotation扫描 --> <context:component-scan base-package="com.baidu.fsg.uid" /> <bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean"> <property name="dataSource" ref="dataSource" /> <property name="mapperLocations" value="classpath:/METAINF/mybatis/mapper/M_WORKER*.xml" /> </bean> <!-- 事务相关配置 --> <tx:annotation-driven transaction-manager="transactionManager" order="1" /> <bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager"> <property name="dataSource" ref="dataSource" /> </bean> <!-- Mybatis Mapper扫描 --> <bean class="org.mybatis.spring.mapper.MapperScannerConfigurer"> <property name="annotationClass" value="org.springframework.stereotype.Repository" /> <property name="basePackage" value="com.baidu.fsg.uid.worker.dao" /> <property name="sqlSessionFactoryBeanName" value="sqlSessionFactory" /> </bean> <!-- 数据源配置 --> <bean id="dataSource" parent="abstractDataSource"> <property name="driverClassName" value="${mysql.driver}" /> <property name="maxActive" value="${jdbc.maxActive}" /> <property name="url" value="${jdbc.url}" /> <property name="username" value="${jdbc.username}" /> <property name="password" value="${jdbc.password}" /> </bean> <bean id="abstractDataSource" class="com.alibaba.druid.pool.DruidDataSource" destroy-method="close"> <property name="filters" value="${datasource.filters}" /> <property name="defaultAutoCommit" value="${datasource.defaultAutoCommit}" /> <property name="initialSize" value="${datasource.initialSize}" /> <property name="minIdle" value="${datasource.minIdle}" /> <property name="maxWait" value="${datasource.maxWait}" /> <property name="testWhileIdle" value="${datasource.testWhileIdle}" /> <property name="testOnBorrow" value="${datasource.testOnBorrow}" /> <property name="testOnReturn" value="${datasource.testOnReturn}" /> <property name="validationQuery" value="${datasource.validationQuery}" /> <property name="timeBetweenEvictionRunsMillis" value="${datasource.timeBetweenEvictionRunsMillis}" /> <property name="minEvictableIdleTimeMillis" value="${datasource.minEvictableIdleTimeMillis}" /> <property name="logAbandoned" value="${datasource.logAbandoned}" /> <property name="removeAbandoned" value="${datasource.removeAbandoned}" /> <property name="removeAbandonedTimeout" value="${datasource.removeAbandonedTimeout}" /> </bean> <bean id="batchSqlSession" class="org.mybatis.spring.SqlSessionTemplate"> <constructor-arg index="0" ref="sqlSessionFactory" /> <constructor-arg index="1" value="BATCH" /> </bean>
-
-
步骤4: 运行示例单测
-
运行单测CachedUidGeneratorTest, 展示UID生成、解析等功能
-
@Resource private UidGenerator uidGenerator; @Test public void testSerialGenerate() { // Generate UID long uid = uidGenerator.getUID(); // Parse UID into [Timestamp, WorkerId, Sequence] // {"UID":"180363646902239241","parsed":{ "timestamp":"2017-01-19 12:15:46", "workerId":"4", "sequence":"9" }} System.out.println(uidGenerator.parseUID(uid)); }
-
-
-
-
分布式雪花ID方案2:美团Leaf-snowflake
-
美团 Leaf-snowflake方案,属于 Snowflake +zookeeper 自增编号 的类型
-

-
用Zookeeper顺序增、全局唯一的节点版本号,替换了原有的机器地址。
-
强依赖ZooKeeper的缺点:强依赖ZooKeeper、大流量下的网络下,存在网络瓶颈。
-
解决了时钟回拨的问题运行时,时差小于5ms会等待时差两倍时间,如果时差大于5ms报警并停止启动。
-
通过缓存一个ZooKeeper文件夹,提高可用性
-
Leaf-snowflake方案完全沿用snowflake方案的bit位设计,即是“1+41+10+12”的方式组装ID号
-
对于workerID的分配,当服务集群数量较小的情况下,完全可以手动配置。Leaf服务规模较大,动手配置成本太高
-
所以使用Zookeeper持久顺序节点的特性自动对snowflake节点配置wokerID
-
Leaf-snowflake是按照下面几个步骤启动的:
- 启动Leaf-snowflake服务,连接Zookeeper,在leaf_forever父节点下检查自己是否已经注册过(是否有该顺序子节点)
- 如果有注册过直接取回自己的workerID(zk顺序节点生成的int类型ID号),启动服务
- 如果没有注册过,就在该父节点下面创建一个持久顺序节点,创建成功后取回顺序号当做自己的workerID号,启动服务
-
从强依赖ZooKeeper优化为弱依赖ZooKeeper
- 除了每次会去ZK拿数据以外,也会在本机文件系统上缓存一个workerID文件
- 当ZooKeeper出现问题,恰好机器出现问题需要重启时,能保证服务能够正常启动
- 这样做到了对三方组件的弱依赖,一定程度上提高了 系统的可用性
-
解决时钟问题
-
因为这种方案依赖时间,如果机器的时钟发生了回拨,那么就会有可能生成重复的ID号,需要解决时钟回退的问题
-
服务启动时首先检查自己是否写过ZooKeeper leaf_forever节点
- 若写过,则用自身系统时间与 leaf_forever/ s e l f 节点记录时间做比较,若小于 l e a f f o r e v e r / {self} 节点记录时间做比较,若小于leaf_forever/ self节点记录时间做比较,若小于leafforever/{self} 时间则认为机器时间发生了大步长回拨,服务启动失败并报警。
- 若未写过,证明是新服务节点,直接创建持久节点 leaf_forever/${self} 并写入自身系统时间,接下来综合对比其余Leaf节点的系统时间来判断自身系统时间是否准确,具体做法是取leaf_temporary下的所有临时节点(所有运行中的Leaf-snowflake节点)的服务IP:Port,然后通过RPC请求得到所有节点的系统时间,计算 sum(time)/nodeSize 。
- 若abs( 系统时间 -sum(time)/nodeSize) < 阈值,认为当前系统时间准确,正常启动服务,同时写临时节点 leaf_temporary/${self} 维持租约
- 否则认为本机系统时间发生大步长偏移,启动失败并报警
- 每隔一段时间(3s)上报自身系统时间写入 leaf_forever/${self}
-
由于强依赖时钟,对时间的要求比较敏感,在机器工作时NTP同步也会造成秒级别的回退,建议可以直接关闭NTP同步
-
要么在时钟回拨的时候直接不提供服务直接返回ERROR_CODE,等时钟追上即可
-
或者做一层重试,然后上报报警系统,更或者是发现有时钟回拨之后自动摘除本身节点并报警
-
//发生了回拨,此刻时间小于上次发号时间 if (timestamp < lastTimestamp) { long offset = lastTimestamp - timestamp; if (offset <= 5) { try { //时间偏差大小小于5ms,则等待两倍时间 wait(offset << 1);//wait timestamp = timeGen(); if (timestamp < lastTimestamp) { //还是小于,抛异常并上报 throwClockBackwardsEx(timestamp); } } catch (InterruptedException e) { throw e; } } else { //throw throwClockBackwardsEx(timestamp); } } //分配ID -
从上线情况来看,在2017年闰秒出现那一次出现过部分机器回拨,由于Leaf-snowflake的策略保证,成功避免了对业务造成的影响
-
-
-
分布式ID:号段模式
- 号段模式ID生成器是一种常见的本地ID生成器算法,也称为段号生成器或区间号生成器。它通过预分配一段连续的ID号段,然后在本地使用这些号段来生成唯一的ID
- 具体的工作流程如下
- 预分配号段:在生成ID之前,首先预分配一段连续的ID号段。例如,可以预分配一个范围为1,000,000到1,999,999的号段
- 本地使用号段:在本地环境中,每次需要生成ID时,从预分配的号段中获取一个ID。可以使用一个计数器来记录当前使用的ID,在获取一个ID后,将计数器递增
- 号段用尽时重新分配:当本地使用的号段用尽时,再次预分配一个新的号段。可以通过一种机制来触发重新分配,例如当计数器超过当前号段的上限时
- 确保唯一性:在分布式环境中,可以为每个节点分配不同的号段,以确保生成的ID在整个分布式系统中是唯一的
- 号段模式ID生成器的优点是简单高效,生成的ID具备可排序性,并且可以在本地环境中生成唯一的ID。然而,需要注意的是,在分布式环境中,需要额外的机制来协调不同节点之间的号段分配,以避免冲突和重复。
-
Leaf-segment(叶段模式)
- Leaf-segment(叶段)是一种分布式ID生成方案,它基于号段模式ID生成器的思想
- Leaf-segment的设计目标是在分布式环境下生成高性能、可排序、唯一的ID。
- 具体工作流程如下:
- 预分配号段:Leaf-segment将ID号段分为多个小段(segment),每个小段包含一定数量的ID。这些小段可以在分布式环境中的不同节点上进行分配,每个节点负责管理和生成自己分配到的小段。
- 本地使用号段:在每个节点上,本地维护一个当前号段(current segment)的指针,指向当前使用的号段。当需要生成ID时,节点会从当前号段中获取一个ID,并将指针递增
- 号段用尽时重新分配:当节点的当前号段用尽时,节点会向中心化的协调者(coordinator)请求获取一个新的号段。协调者负责分配新的号段,并将新的号段分配给请求的节点。
- 确保唯一性:通过将每个节点分配不同的号段,Leaf-segment保证了在整个分布式系统中生成的ID是唯一的。
- 和数据库的自增主键相比,Leaf-segment(叶段)把数据库自增主键换成了计数法。
- Leaf-segment(叶段) 每个业务分配一个biz_tag、并记录各业务最大id(max_id)、号段跨度(step)等数据
- 这样每次取号只需要更新biz_tag对应的max_id,就可以拿到step个id
- Leaf-segment的优点是具备高性能、可排序和唯一性,并且可以在分布式环境中有效地生成ID。它通过将ID号段分配给每个节点,减少了节点之间的通信和协调开销,提高了生成ID的效率
- 然而,Leaf-segment也存在一些注意事项。首先,需要一个可靠的协调者来分配号段,并确保号段的唯一性。其次,如果协调者发生故障或网络分区,可能会影响新号段的分配和节点的正常运行。因此,在使用Leaf-segment时需要考虑容错和故障恢复机制
- 总之,Leaf-segment是一种可行的分布式ID生成方案,适用于需要在分布式环境中生成唯一ID的应用场景。它提供了一种高性能、可排序、唯一的ID生成解决方案
- 优点
- 除了拥有自增ID的优点之外,在性能上比自增ID更好
- 扩展灵活。
- 使用灵活、可配置性强。
- 缓存机制,突发状况下短时间内能保证服务正常运转。
- 缺点
- id是有序自增,容易暴露信息,不可用于订单。
- 在leaf的缓存ID用完再去获取新号段的间隙,性能会有波动。
- 强依赖DB
-
增强版Leaf-segment
- 增强版是对上面描述的缺点2进行的改进——双cache,在leaf的ID消耗到一定百分比时,常驻的后台进程会预先去号段服务获取新的号段并缓存。具体消耗百分比、及号段step根据业务消耗速度来定。
- 增强版Leaf-segment是对Leaf-segment方案的扩展和改进,旨在进一步提升分布式ID生成的性能和可扩展性
- 具体来说,增强版Leaf-segment在Leaf-segment的基础上引入了以下改进
- 分布式协调者:引入多个协调者节点,形成一个分布式的协调者集群。每个协调者负责管理一部分号段,并协调节点之间的号段分配和归还。这样可以提高协调者的容错性和可用性,并减轻单个协调者的负载压力
- 异步号段分配:将号段分配过程改为异步操作。当节点的当前号段用尽时,节点向协调者请求获取新的号段,但不会阻塞等待结果。而是继续使用当前号段生成ID,同时在后台等待协调者的响应。这样可以减少节点的等待时间,提高ID生成的效率
- 号段预取:节点在本地维护一个号段缓存,提前预取一定数量的号段。当节点的当前号段用尽时,可以直接从缓存中获取下一个号段,而无需立即向协调者请求新的号段。这样可以减少节点与协调者的通信次数,降低延迟并提高吞吐量
- 动态调整号段大小:根据系统的负载情况和需求变化,动态调整号段的大小。例如,当系统负载较低时,可以增加号段的大小,减少号段分配的频率;当系统负载较高时,可以减小号段的大小,提高号段的利用率。
- 增强版Leaf-segment通过引入分布式协调者、异步号段分配、号段预取和动态调整号段大小等改进,进一步提升了分布式ID生成的性能和可扩展性。它能够更好地适应高并发、大规模分布式系统的需求,并提供可靠、高效的ID生成方案
-
滴滴 Tinyid号段模式
- 和增强版Leaf-segment类似,也是号段模式,提前加载号段。
-
美团Leaf-segment
-
美团Leaf-segment方案,在使用数据库的方案上,做了如下改变:
- 原方案每次获取ID都得读写一次数据库,造成数据库压力大
- 改为利用proxy server批量获取,每次获取一个segment(step决定大小)号段的值。用完之后再去数据库获取新的号段,可以大大的减轻数据库的压力。
- 各个业务不同的发号需求用biz_tag字段来区分,每个biz-tag的ID获取相互隔离,互不影响。如果以后有性能需求需要对数据库扩容,不需要上述描述的复杂的扩容操作,只需要对biz_tag分库分表就行
-
Leaf-segment数据库数据库表设计如下
-
+-------------+--------------+------+-----+-------------------+----------------- ------------+ | Field | Type | Null | Key | Default | Extra | +-------------+--------------+------+-----+-------------------+----------------- ------------+ | biz_tag | varchar(128) | NO | PRI | | | | max_id | bigint(20) | NO | | 1 | | | step | int(11) | NO | | NULL | | | desc | varchar(256) | YES | | NULL | | | update_time | timestamp | NO | | CURRENT_TIMESTAMP | on update CURRENT_TIMESTAMP | +-------------+--------------+------+-----+-------------------+----------------- ------------+ -
重要字段说明:biz_tag用来区分业务,max_id表示该biz_tag目前所被分配的ID号段的最大值,step表示每次分配的号段长度。原来获取ID每次都需要写数据库,现在只需要把step设置得足够大,比如1000
-
那么只有当1000个号被消耗完了之后才会去重新读写一次数据库。读写数据库的频率从1减小到了1/step,
-
test_tag在第一台Leaf机器上是11000的号段,当这个号段用完时,会去加载另一个长度为step=1000的号段,假设另外两台号段都没有更新,这个时候第一台机器新加载的号段就应该是30014000
-
同时数据库对应的biz_tag这条数据的max_id会从3000被更新成4000,更新号段的SQL语句如下:
-
Begin UPDATE table SET max_id=max_id+step WHERE biz_tag=xxx SELECT tag, max_id, step FROM table WHERE biz_tag=xxx Commit
-
-
优点:
- Leaf服务可以很方便的线性扩展,性能完全能够支撑大多数业务场景。
- ID号码是趋势递增的8byte的64位数字,满足上述数据库存储的主键要求。
- 容灾性高:Leaf服务内部有号段缓存,即使DB宕机,短时间内Leaf仍能正常对外提供服务。
- 可以自定义max_id的大小,非常方便业务从原有的ID方式上迁移过来
-
缺点
- ID号码不够随机,能够泄露发号数量的信息,不太安全。
- TP999数据波动大,当号段使用完之后还是会hang在更新数据库的I/O上,tg999数据会出现偶尔的尖刺。
- DB宕机会造成整个系统不可用
- ID号码不够随机,能够泄露发号数量的信息,不太安全。比如某个竞争对手在两天中午12点分别下单,通过订单id号相减就能大致计算出公司一天的订单量,这个是不能忍受的。面对这一问题,美团提供了Leaf-snowflake方案
-
双buffer优化
- 对于第二个缺点,Leaf-segment做了一些优化,简单的说就是:
- Leaf 取号段的时机是在号段消耗完的时候进行的,也就意味着号段临界点的ID下发时间取决于下一次从DB取回号段的时间,并且在这期间进来的请求也会因为DB号段没有取回来,导致线程阻塞。如果请求DB的网络和DB的性能稳定,这种情况对系统的影响是不大的,但是假如取DB的时候网络发生抖动,或者DB发生慢查询就会导致整个系统的响应时间变慢
- 为此,我们希望DB取号段的过程能够做到无阻塞,不需要在DB取号段的时候阻塞请求线程,即当号段消费到某个点时就异步的把下一个号段加载到内存中。而不需要等到号段用尽的时候才去更新号段。这样做就可以很大程度上的降低系统的TP999指标
- 采用双buffer的方式,Leaf服务内部有两个号段缓存区segment。当前号段已下发10%时,如果下一个号段未更新,则另启一个更新线程去更新下一个号段。当前号段全部下发完后,如果下个号段准备好了则切换到下个号段为当前segment接着下发,循环往复
- 每个biz-tag都有消费速度监控,通常推荐segment长度设置为服务高峰期发号QPS的600倍(10分钟),这样即使DB宕机,Leaf仍能持续发号10-20分钟不受影响。
- 每次请求来临时都会判断下个号段的状态,从而更新此号段,所以偶尔的网络抖动不会影响下个号段的更新
-
Leaf高可用容灾
- 对于第三点“DB可用性”问题,我们目前采用一主两从的方式,同时分机房部署,Master和Slave之间采用半同步方式同步数据。同时使用公司Atlas数据库中间件(已开源,改名为DBProxy)做主从切换
- 当然这种方案在一些情况会退化成异步模式,甚至在非常极端情况下仍然会造成数据不一致的情况,但是出现的概率非常小
- 如果你的系统要保证100%的数据强一致,可以选择使用“类Paxos算法”实现的强一致MySQL方案,如MySQL 5.7前段时间刚刚GA的MySQL Group Replication。但是运维成本和精力都会相应的增加,根据实际情况选型即可
- 同时Leaf服务分IDC部署,内部的服务化框架是“MTthrift RPC”。
- 服务调用的时候,根据负载均衡算法会优先调用同机房的Leaf服务。在该IDC内Leaf服务不可用的时候才会选择其他机房的Leaf服务
- 同时服务治理平台OCTO还提供了针对服务的过载保护、一键截流、动态流量分配等对服务的保护措施
-
-
Tinyid:滴滴1000W级qps的分布式ID生成器
-
Tinyid是一个ID生成器服务,它提供了REST API和Java客户端等多种获取方式,
-
如果使用Java客户端获取方式的话,官方宣称能单实例能达到1kw QPS(Over 10 million QPS persingle instance when using the java client.)
-
Tinyid开源的Github地址:https://github.com/didi/tinyid。
-
运行Tinyid
-
将Tinyid源码下载到本地,并导入idea后,接下来准备把它运行起来
-
导入SQL
-
Tinyid依赖的SQL脚本路径:tinyid/tinyid-server/db.sql,是MySQL数据库的脚本
-
登陆mysql客户端并创建一个tinyid数据库后,执行命令 source /data/tinyid/tinyid-server/db.sql。
-
如果show tables后能看到两个表tiny_id_info和tiny_id_token表示创建成功
-
并且脚本已经初始化了两条数据
-
select id,token,biz_type from tiny_id_token; id | token | biz_type | +----+----------------------------------+----------+ | 1 | 0f673adf80504e2eaa552f5d791b644c | test | | 2 | 0f673adf80504e2eaa552f5d791b644c | test_odd | select id,biz_type,begin_id,max_id,step,delta from tiny_id_info; +----+----------+----------+--------+--------+-------+ | id | biz_type | begin_id | max_id | step | delta | +----+----------+----------+--------+--------+-------+ | 1 | test | 1 | 1 | 100000 | 1 | | 2 | test_odd | 1 | 1 | 100000 | 2 | +----+----------+----------+--------+--------+-------+
-
-
mysql依赖
-
这里需要注意的是,tinyid项目默认依赖5.x版本MySQL驱动包
-
如果你的MySQL服务器是8.x版本(笔者本地就是8.x的MySQL),可能会碰到在启动过程中报连接数据库错误
-
Caused by: java.sql.SQLException: Unable to load authentication plugin 'caching_sha2_password'. at com.mysql.jdbc.SQLError.createSQLException(SQLError.java:868) ~[mysqlconnector-java-5.1.44.jar:5.1.44] at com.mysql.jdbc.SQLError.createSQLException(SQLError.java:864) ~[mysqlconnector-java-5.1.44.jar:5.1.44] at com.mysql.jdbc.MysqlIO.proceedHandshakeWithPluggableAuthentication(MysqlIO.java: 1746) ~[mysql-connector-java-5.1.44.jar:5.1.44] at com.mysql.jdbc.MysqlIO.doHandshake(MysqlIO.java:1226) ~[mysql-connectorjava-5.1.44.jar:5.1.44] ... ... -
这样的话,需要将你的MySQL驱动升级到8.x版本(说明:如果你是其他MySQL版本,启动tinyid时碰到类似的异常,那么MySQL驱动版本请视情况而定进行升级)
-
<dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>8.0.11</version> </dependency> -
修改配置
-
接下来需要更新配置application.properties文件。主要更新数据库相关配置,具体值根据你的MySQL环境而定
-
datasource.tinyid.primary.driver-class-name=com.mysql.jdbc.Driver datasource.tinyid.primary.url=jdbc:mysql://localhost:3306/tinyid? autoReconnect=true&useUnicode=true&characterEncoding=UTF-8 datasource.tinyid.primary.username=root datasource.tinyid.primary.password=123456
-
-
启动tinyid
-
tinyid项目基于Springboot开发的,所以启动非常简单。
-
只需要运行主类TinyIdServerApplication.java即可。
-
运行后如果能看到如下日志,表示启动成功:
-
00:20:55,761 [main] [INFO] o.s.b.c.e.t.TomcatEmbeddedServletContainer - Tomcat started on port(s): 9999 (http) 00:20:55,767 [main] [INFO] c.x.u.t.s.TinyIdServerApplication - Started TinyIdServerApplication in 5.092 seconds (JVM running for 6.29) 00:21:00,001 [pool-3-thread-1] [INFO] c.x.u.t.s.s.i.TinyIdTokenServiceImpl - refresh token begin 00:21:00,002 [pool-3-thread-1] [INFO] c.x.u.t.s.s.i.TinyIdTokenServiceImpl - tinyId token init begin 00:21:00,006 [pool-3-thread-1] [INFO] c.x.u.t.s.s.i.TinyIdTokenServiceImpl - tinyId token init success, token size:2 00:22:00,001 [pool-3-thread-1] [INFO] c.x.u.t.s.s.i.TinyIdTokenServiceImpl - refresh token begin 。。。 。。。
-
-
获取唯一ID
-
接下来可以尝试通过REST API获取分布式唯一ID,请求实例如下,bizType和token的值请参考tiny_id_token表:
-
http://localhost:9999/tinyid/id/nextId? bizType=test&token=0f673adf80504e2eaa552f5d791b644c
-
-
Client集成
-
tinyid还支持Client集成模式,只需要引入如下Maven坐标:
-
<dependency> <groupId>com.xiaoju.uemc.tinyid</groupId> <artifactId>tinyid-client</artifactId> <version>${tinyid.version}</version> </dependency> -
然后在你的classpath路径下创建配置文件tinyid_client.properties,内容如下,这两个参数IdGeneratorFactoryClient.java中tinyid服务端请求地址"http://{0}/tinyid/id/nextSegmentIdSimple?token={1}&bizType="的第一个和第二个参数
-
tinyid.server=localhost:9999 tinyid.token=0f673adf80504e2eaa552f5d791b644c -
tinyid.server还支持多个地址配置,多个地址之间以英文逗号隔开,例如:tinyid.server=host1:9999,tinyid.server=host2:9999
-
接下来,就能简单的通过调用tinyid封装的API获取分布式ID,实例代码如下,test就是bizType的值:
-
// 单个分布式ID获取 Long id = TinyId.nextId("test"); // 多个分布式ID批量获取 List<Long> ids = TinyId.nextId("test", 10) -
通过配置可知,tinyid-client本质上还是依赖tinyid-server,只不过它封装了对tinyid-server的HTTP请求,然后暴露最简单的API给用户使用而已。它对tinyid-server的HTTP请求封装在TinyIdHttpUtils.java中,依赖JDK原生HttpURLConnection,居然没有使用其他第三方优秀的HTTP Client包例如okhttp!
-
-
tinyid原理
-
tinyid的原理非常简单,就是经典的segment模式,和美团的leaf原理几乎一致。
-
首先,回顾一下生成全局唯一ID有如下三个思路
- 基于数据库生成;
- 基于分布式集群协调器生成(ZooKeeper, Consul ,Etcd等);
- 划分命名空间并行生成(Snowflake为代表)
-
Tinyid 借鉴和吸纳第一种思路,进行优化和改进,然后生成全局唯一ID。
-
纯粹的第一种思路,基于数据库生产id,核心问题如下:
- 纯粹的第一种思路,使用db的auto_increment,虽然实现简单、但性能比较差。
- 并且,纯粹的第一种思路,对db访问比较频繁,db的压力会比较大
-
tinyid原理如何改进呢? 四个优化手段
- 优化手段一:号段、
- 优化手段二:双缓存
- 优化手段三:多db支持
- 优化手段四:分布式部署
-
优化手段一:号段
-
Tinyid解决了该问题,主要实现思路为一批id,可以看成是一个id范围,例如(1000,2000],这个1000到2000也可以称为一个"号段"
-
我们一次向db申请一个号段,加载到内存中,然后采用自增的方式来生成id,这个号段用完后,再次向db申请一个新的号段,这样对db的压力就减轻了很多,同时内存中直接生成id,性能则提高了很多。
-
所以Tinyid数据库表设计时,只需要满足能存储一个范围即可,一个端点(Tinyid使用右端点)和一个步长可以确定一个范围。
-
id biz_type max_id step version 1 1000 2000 1000 0 -
biz_type:业务类型,不同业务的id隔离
-
max_id:当前号段最大可用id,即右端点
-
step:步长,根据每个业务的qps来设置一个合理的长度
-
version:当前版本,用于实现乐观锁,每次更新都加上version,能够保证并发更新的正确性
-
@Override @Transactional(isolation = Isolation.READ_COMMITTED) public SegmentId getNextSegmentId(String bizType) { // 获取nextTinyId的时候,有可能存在version冲突,需要重试 for (int i = 0; i < Constants.RETRY; i++) { // select id, biz_type, begin_id, max_id, step, delta, remainder, create_time, update_time, version // from tiny_id_info where biz_type = ? TinyIdInfo tinyIdInfo = tinyIdInfoDAO.queryByBizType(bizType); if (tinyIdInfo == null) { throw new TinyIdSysException("can not find biztype:" + bizType); } Long newMaxId = tinyIdInfo.getMaxId() + tinyIdInfo.getStep(); Long oldMaxId = tinyIdInfo.getMaxId(); // update tiny_id_info set max_id= ?, update_time=now(), version=version+1 // where id=? and max_id=? and version=? and biz_type=? // CAS int row = tinyIdInfoDAO.updateMaxId(tinyIdInfo.getId(), newMaxId, oldMaxId, tinyIdInfo.getVersion(), tinyIdInfo.getBizType()); if (row == 1) { tinyIdInfo.setMaxId(newMaxId); SegmentId segmentId = convert(tinyIdInfo); logger.info("getNextSegmentId success tinyIdInfo:{} current:{}", tinyIdInfo, segmentId); return segmentId; } else { logger.info("getNextSegmentId conflict tinyIdInfo:{}", tinyIdInfo); } } throw new TinyIdSysException("get next segmentId conflict"); } -
以上是获取号段代码,基于CAS(Compare and Swap)思想 。
-
这里比较值得注意一点是该方法事务的隔离级别设置为READ_COMMITTED(提交读),主要为了考虑以下两点:
- Transactional标记保证query和update使用的是同一连接。
- MySQL默认事务隔离级别为REPEATABLE_READ(可重复读, MySQL底层使用MVCC),保证同一个事务中读到的version字段相同(循环调用 tinyIdInfoDAO.queryByBizType(bizType) 获取的结果是没有变化的),感知不到其他事务对version字段的改变,可能会导致CAS失败
-
-
优化手段二:双缓存
-
在一个号段用完后,需要向数据库申请下一个号段,此时客户端需要等待,造成性能波动
-
Tinyid使用双缓存(重数据库加载到内存中的号段)解决这个问题,在号段用到一定程度(默认20%)的时候,就去异步加载下一个号段,保证内存中始终有可用号段,则可避免性能波动。
-
protected SegmentIdService segmentIdService; protected volatile SegmentId current; // 当前号段 protected volatile SegmentId next; // 下一号段 private volatile boolean isLoadingNext; // 是否正在加载下一号段 private Object lock = new Object(); private ExecutorService executorService = Executors.newSingleThreadExecutor(new NamedThreadFactory("tinyid-generator")); // 加载下一号段的异步线程池 -
nextId() 方法用于从缓存中获取一个id。
-
@Override public Long nextId() { while (true) { if (current == null) { // 懒加载,申请当前号段 loadCurrent(); continue; } // 从当前号段缓存中获取一个id Result result = current.nextId(); // 当前号段缓存的id用尽 if (result.getCode() == ResultCode.OVER) { loadCurrent(); } else { // 当前号段用到一定程度,触发异步加载下一号段 if (result.getCode() == ResultCode.LOADING) { loadNext(); } return result.getId(); } } } -
loadCurrent() 加载当前号段,使用 synchronized 关键字保证线程安全。有两个地方可能用到这个方法,一个是初始化时懒加载当前号段,另一个是当前号段缓存的id用尽,使用下一号段替换当前号段
-
public synchronized void loadCurrent() { if (current == null || !current.useful()) { if (next == null) { // 从数据库中查询一个号段 SegmentId segmentId = querySegmentId(); this.current = segmentId; } else { // 用下一号段替换当前号段 current = next; next = null; } } } -
当前号段用到一定程度,调用 loadNext() 方法异步加载下一号段。
-
public void loadNext() { // double check if (next == null && !isLoadingNext) { synchronized (lock) { if (next == null && !isLoadingNext) { isLoadingNext = true; executorService.submit(new Runnable() { @Override public void run() { try { // 无论获取下个segmentId成功与否,都要将isLoadingNext赋值 为false next = querySegmentId(); } finally { isLoadingNext = false; } } }); } } } }
-
-
优化手段三:多db支持
-
只有一个数据库时,可用性难以保证,当主库挂了会造成申请号段不可用
-
另外扩展性差,性能有上限,因为写入是单点,数据库主库的写性能决定ID的生成性能上限,并且难以扩展。
-
为了解决此问题,Tinyid 可以增加主库,避免写入单点。为了保证各主库生成的ID不重复,需要为每个主库设置不同的auto_increment初始值,以及相同的增长步长
-
例如,有三个主库DB-0,DB-1,DB-2,将auto_increment初始值分别设置为0,1,2,步长都为3,则库DB-0生成0,3,6,9…,库DB-1生成1,4,7,10,库DB-2生成2,5,8,11…;
-
但数据库需要增加两个字段delta和remainder,分别表示增长步长和auto_increment初始值。
-
id biz_type max_id step delta remainder version 1 1000 2000 1000 2 0 0 -
但是这里有个问题,比如从申请到号段(1000,2000]后,如果delta=3, remainder=0,则这个号段从哪个id开始分配,肯定不是1001,所以这里就需要计算。
-
设置好初始id之后,就以delta的方式递增分配。因为会先递增,所以会浪费一个id,所以做了一次减delta的操作,实际会从999开始增,第一个id还是1002
-
public Result nextId() { init(); // 先自增 long id = currentId.addAndGet(delta); if (id > maxId) { return new Result(ResultCode.OVER, id); } if (id >= loadingId) { return new Result(ResultCode.LOADING, id); } return new Result(ResultCode.NORMAL, id); } public void init() { if (isInit) { return; } // double check synchronized (this) { if (isInit) { return; } long id = currentId.get(); if (id % delta == remainder) { isInit = true; return; } for (int i = 0; i <= delta; i++) { id = currentId.incrementAndGet(); if (id % delta == remainder) { // 避免浪费 减掉系统自己占用的一个id currentId.addAndGet(0 - delta); isInit = true; return; } } } } -
在决定数据源时,使用一下方法
-
@Override protected Object determineCurrentLookupKey() { // 只有一个数据源时 if(dataSourceKeys.size() == 1) { return dataSourceKeys.get(0); } // 多个数据源时,随机选择一个 Random r = new Random(); return dataSourceKeys.get(r.nextInt(dataSourceKeys.size())); } -
从上面可以看出,如果有多个数据源,则随机选择一个,所有生成的id不是严格单调递增的,而是趋势递增,能满足大部分业务场景
-
-
优化手段四:分布式部署
-
虽然数据库单点问题解决了,但是还是单个服务选择多个数据库,服务挂了怎么办,服务单点问题并没有解决。
-
一个简单的解决方案就是将服务部署到多个机房的多台机器。但是问题又随之而来,多个服务之间怎么协调
-
在Spring Cloud中微服务多实例部署,可以将其注册到服务注册中心,然后在客户端使用负载均衡算法访问服务。或者在服务端使用反向代理,为多实例做负载均衡
-
但是Tinyid 作为一个独立服务部署,引入这些组件将增加维护成本,所以呢,Tinyid 提供了SDK,在SDK中做了客户端负载均衡(随机算法)。
-
private String chooseService(String bizType) { List<String> serverList = TinyIdClientConfig.getInstance().getServerList(); String url = ""; if (serverList != null && serverList.size() == 1) { url = serverList.get(0); } else if (serverList != null && serverList.size() > 1) { // 多实例部署时,随机选择一个服务 Random r = new Random(); url = serverList.get(r.nextInt(serverList.size())); } url += bizType; return url; } -

-
-
-
-
分布式ID的方案和架构
news2026/2/15 3:47:54
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/1593983.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章

常见公开可用的数据集——对算法的鲁棒性和性能进行全面评估
提供了一组公开可用的数据集,这些数据集包含不同的图像变换,允许对算法的鲁棒性和性能进行全面评估。特征匹配实验中使用的数据集汇总信息如表2所示,图14为除YFCC100M外各数据集的样例图像。
Proj:202404 CMC-R.W Citavi (1) VGG [115]: This dataset comprises 40 pairs…

一些 VLP 下游任务的相关探索
目录 一、Image-Text Retrieval (ITR , 图像文本检索)
任务目的:
数据集格式
训练流程
evaluation流程
实际使用推测猜想
二、Visual Question Answering (VQA , 视觉问答)
任务目的 数据集格式 训练流程 demo以及评估流…

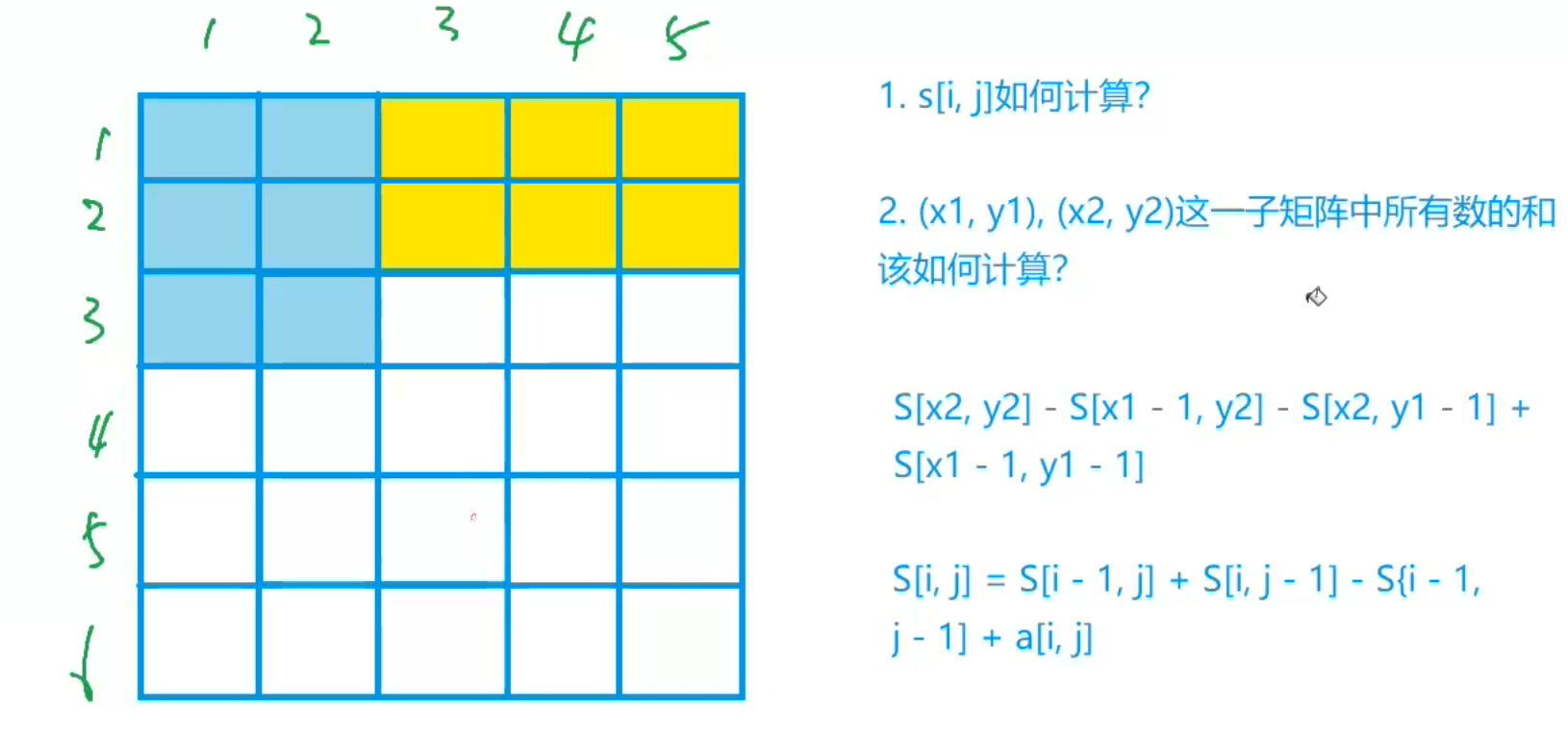
AcWing 796. 子矩阵的和——算法基础课题解
AcWing 796. 子矩阵的和
题目描述
输入一个 n 行 m 列的整数矩阵,再输入 q 个询问,每个询问包含四个整数 x1,y1,x2,y2,表示一个子矩阵的左上角坐标和右下角坐标。
对于每个询问输出子矩阵中所有数的和。
输入格式
第一行包含三个整数 n&…
前后端分离的Java医院云HIS信息管理系统源码(LIS源码+电子病历源码)
HIS系统采用主流成熟技术开发,软件结构简洁、代码规范易阅读,SaaS应用,全浏览器访问前后端分离,多服务协同,服务可拆分,功能易扩展。多医院、多集团统一登录患者主索引建立、主数据管理,统一对外…
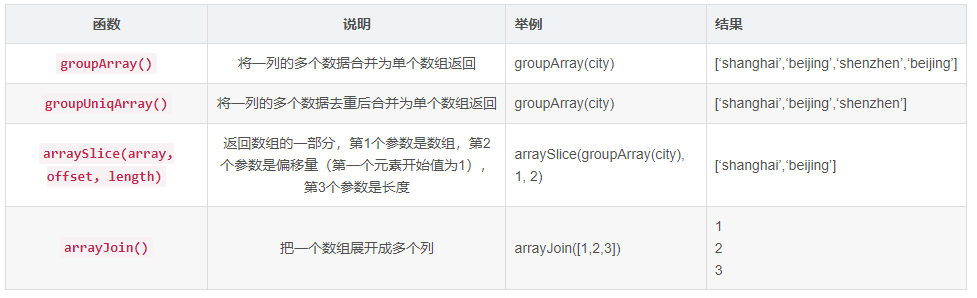
ClickHouse--16--普通函数
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 一、日期函数1、时间或日期截取函数(返回非日期)2、时间或日期截取函数(返回日期)3、日期或时间日期生成函数 二、类…

Arthas实战教程:定位Java应用CPU过高与线程死锁
引言
在Java应用开发中,我们可能会遇到CPU占用过高和线程死锁的问题。本文将介绍如何使用Arthas工具快速定位这些问题。
准备工作
首先,我们创建一个简单的Java应用,模拟CPU过高和线程死锁的情况。在这个示例中,我们将编写一个…


RobotFramework功能自动化测试框架基础篇
概念
RobotFramework是什么?
Robot Framework是一款python编写的功能自动化测试框架。具备良好的可扩展性,支持关键字驱动,可以同时测试多种类型的客户端或者接口,可以进行分布式测试执行。主要用于轮次很多的验收测试和验收测试…

2023年看雪安全技术峰会(公开)PPT合集(11份)
2023年看雪安全技术峰会(公开)PPT合集,共11份,供大家学习参阅。
1、MaginotDNS攻击:绕过DNS 缓存防御的马奇诺防线 2、从形式逻辑计算到神经计算:针对LLM角色扮演攻击的威胁分析以及防御实践 3、TheDog、0…
Vue.js前端开发零基础教学(五)
目录
4.1 动态组件
4.1.1 定义动态组件 4.1.2 利用KeepAlive组件实现组件缓存
4.1.3 组件缓存相关的生命周期函数
4.1.4 KeepAlive组件的常用属性 4.2 插槽
4.2.1 什么是插槽
编辑 4.2.2 具名插槽
4.2.3 作用域插槽
4.3 自定义指令
4.3.1 什么是自定义指令…

“木偶猴帝国”渐起,BRC-20生态Meme币PUPS成为新星
比特币生态中基于BRC20协议的木偶猴代币PUPS在最近一周内价格暴涨1101%,达到了44.56美元,而其他一些BRC20代币,如WZRD、W☮、ZBIT、$π等也经历了显著的价格上涨,带动交易量攀升。
PUPS正在形成一种图币新玩法,与木偶…
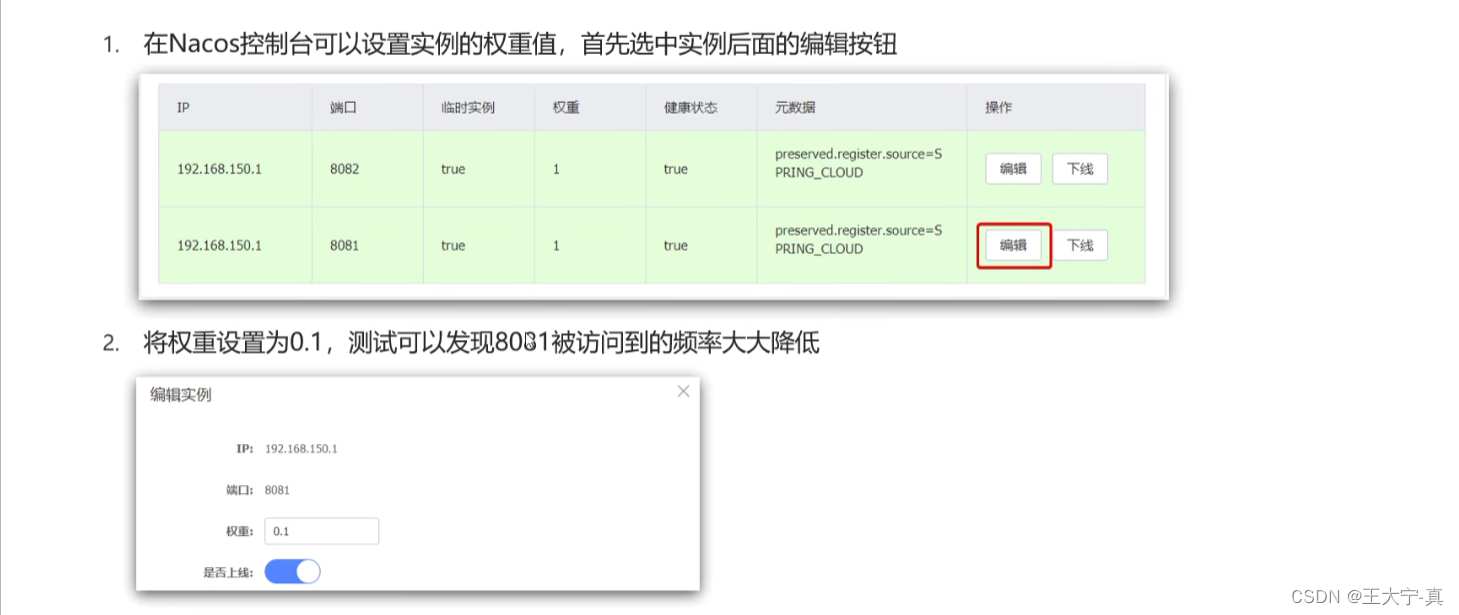
Nacos下载安装、案例解析(代码+注解)
简介:Nacos 在阿里巴巴起源于 2008 年五彩石项目(完成微服务拆分和业务中台建设),成长于十年双十一的洪峰考验,沉淀了简单易用、稳定可靠、性能卓越的核心竞争力。 目录
1、Nacos下载安装
2、项目应用
2.1 添加依赖…
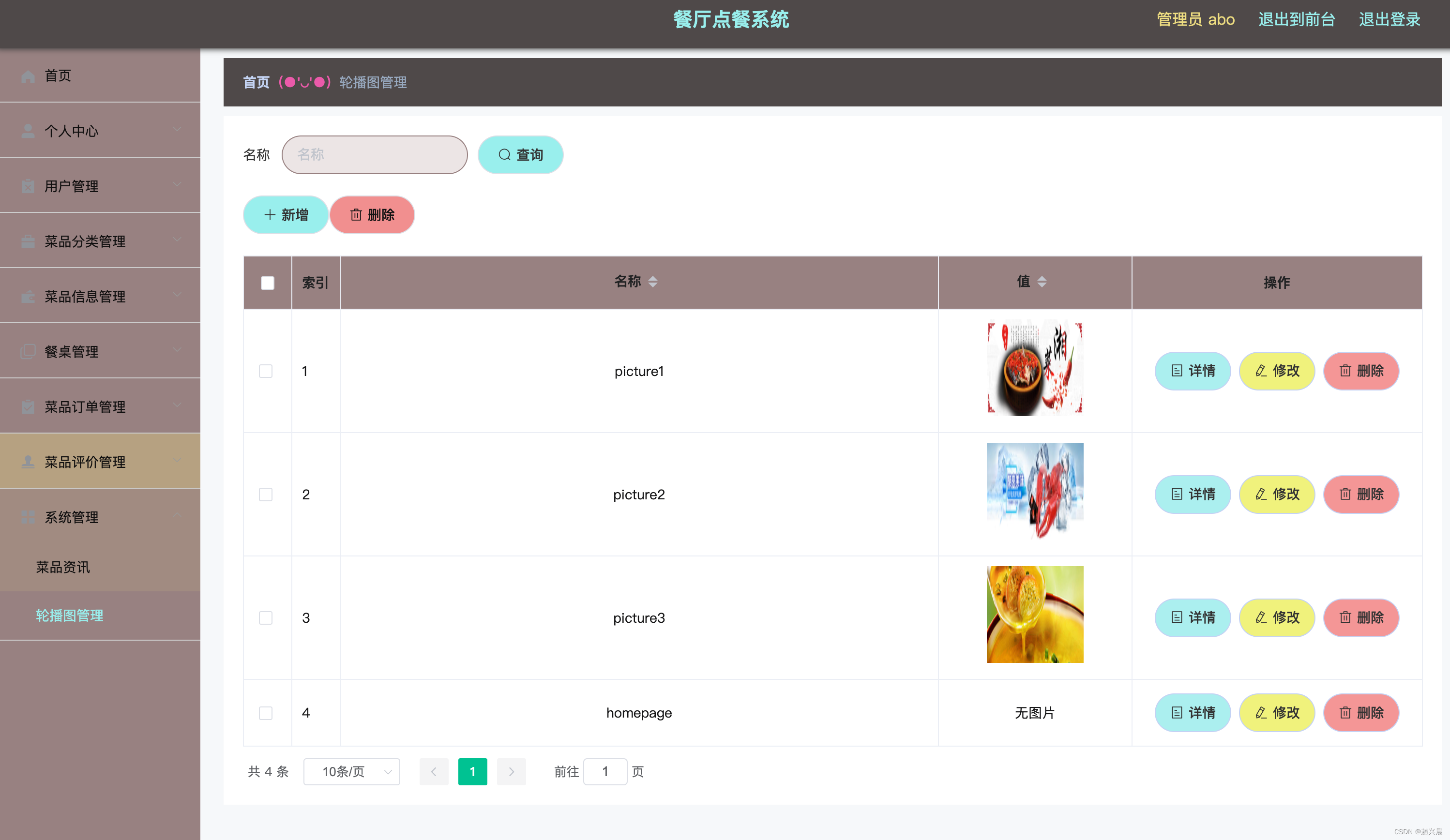
基于Springboot的餐厅点餐系统
基于SpringbootVue的餐厅点餐系统的设计与实现
开发语言:Java数据库:MySQL技术:SpringbootMybatis工具:IDEA、Maven、Navicat
系统展示
首页展示
菜品详情页
菜品信息
个人中心
后台管理
菜品信息管理
用户管理
菜…

AI大模型之idea通义灵码智能AI插件安装方式
问题描述
主要讲述如何进行开发工具 idea中如何进行通义灵码的插件的安装解决方案
直接在idea的plugin市场中安装 下载插件之后进行安装
见资源

每日一题:无重复字符的最长子串
给定一个字符串 s ,请你找出其中不含有重复字符的 最长子串的长度。 示例 1:
输入: s "abcabcbb"
输出: 3
解释: 因为无重复字符的最长子串是"abc",所以其长度为 3。示例 2:
输入: s "bbbbb"
输出: 1
解释: 因为无重…
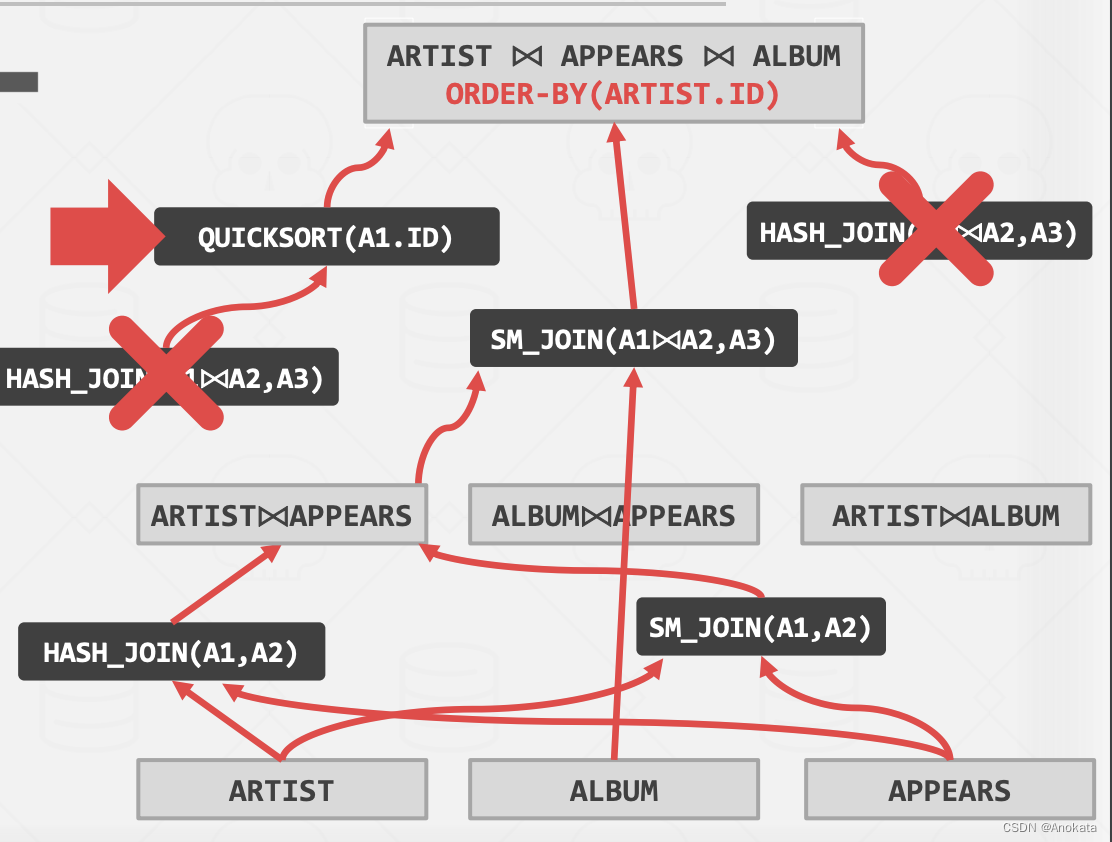
第十二讲 查询计划 优化
到目前为止,我们一直在说,我们得到一个 SQL 查询,我们希望可以解析它,将其转化为某种逻辑计划,然后生成我们可以用于执行的物理计划。而这正是查询优化器【Optimizer】的功能,对于给定的 SQL ,优…
ViT-DeiT:用于乳腺癌组织病理图像分类的集成模型
两种预训练Vision Transformer模型的集成模型,即Vision Transformer和数据高效视觉Transformer(Data-Efficient Image Transformer)。此集成模型是一种软投票模型。 近年来,乳腺癌的分类研究主要集中在超声图像分类、活检数据分类…

BUUCTF刷题十一道(12)附-SSTI专题二
文章目录 学习文章[CISCN2019 华东南赛区]Web11【存疑】[RootersCTF2019]I_<3_Flask 学习文章 SSTI-服务端模板注入漏洞 flask之ssti模板注入从零到入门 CTFSHOW SSTI篇-yu22x SSTI模板注入绕过(进阶篇)-yu22x SSTI模板注入学习-竹言笙熙 全部总结看最…

音视频学习—音视频理论基础(2)
音视频学习—音视频理论基础(2) 1、音频的基本概念2、声音的三要素3、声音的本质4、奈奎斯特采样定律5、采样和采样率6、采样数和采样位数7、量化8、比特率(码率)9、响度和强度10、编码11、音频帧12、音频文件大小的计算总结 1、音…