一、背景介绍
把《狂飙》换成其他影视剧,套用代码即可得分析结论!
2023《狂飙》热播剧引发全民追剧,不仅全员演技在线,且符合主旋律,创下多个收视记录!
基于此热门事件,我用python抓取了B站上千条评论,并进行可视化舆情分析。
二、爬虫代码
2.1 展示爬取结果
首先,看下部分爬取数据:
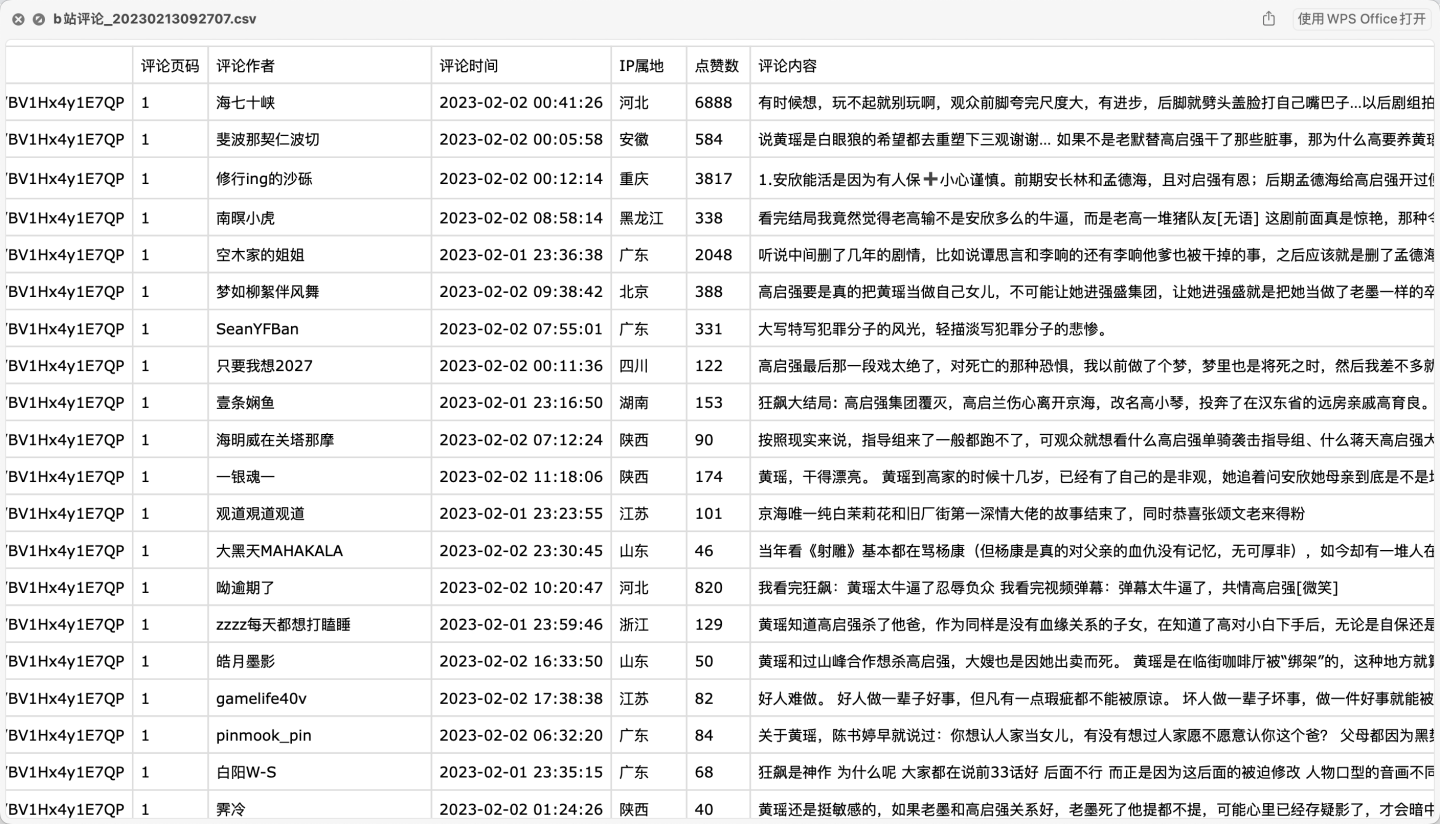
爬取字段含:视频链接、评论页码、评论作者、评论时间、IP属地、点赞数、评论内容。
2.2 爬虫代码讲解
导入需要用到的库:
import requests # 发送请求
import pandas as pd # 保存csv文件
import os # 判断文件是否存在
import time
from time import sleep # 设置等待,防止反爬
import random # 生成随机数
定义一个请求头:
# 请求头
headers = {
'authority': 'api.bilibili.com',
'accept': 'application/json, text/plain, */*',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
# 需定期更换cookie,否则location爬不到
'cookie': "需换成自己的cookie值",
'origin': 'https://www.bilibili.com',
'referer': 'https://www.bilibili.com/video/BV1FG4y1Z7po/?spm_id_from=333.337.search-card.all.click&vd_source=69a50ad969074af9e79ad13b34b1a548',
'sec-ch-ua': '"Chromium";v="106", "Microsoft Edge";v="106", "Not;A=Brand";v="99"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-site',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36 Edg/106.0.1370.47'
}
请求头中的cookie是个很关键的参数,如果不设置cookie,会导致数据残缺或无法爬取到数据。
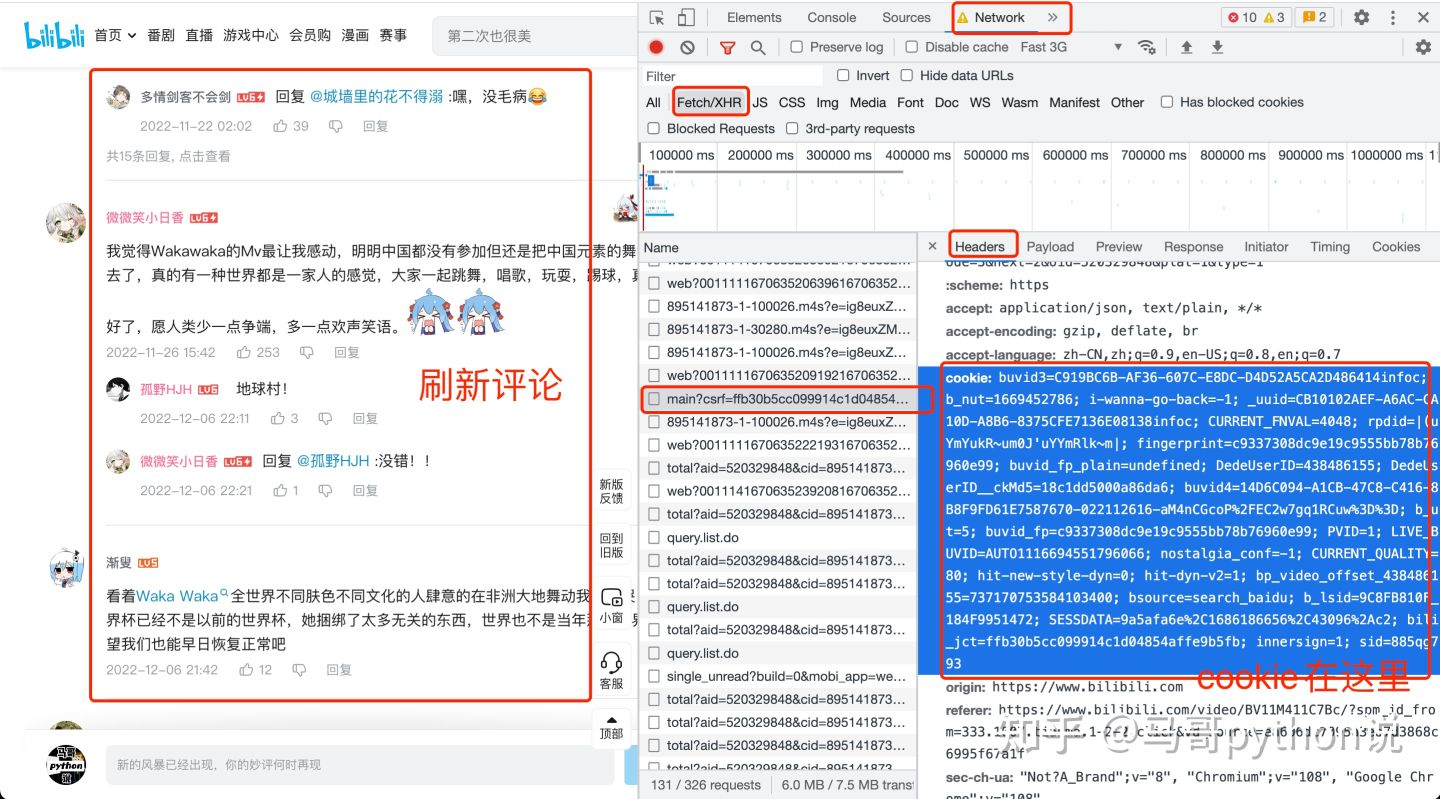
那么cookie如何获取呢?打开开发者模式,见下图:
由于评论时间是个十位数:
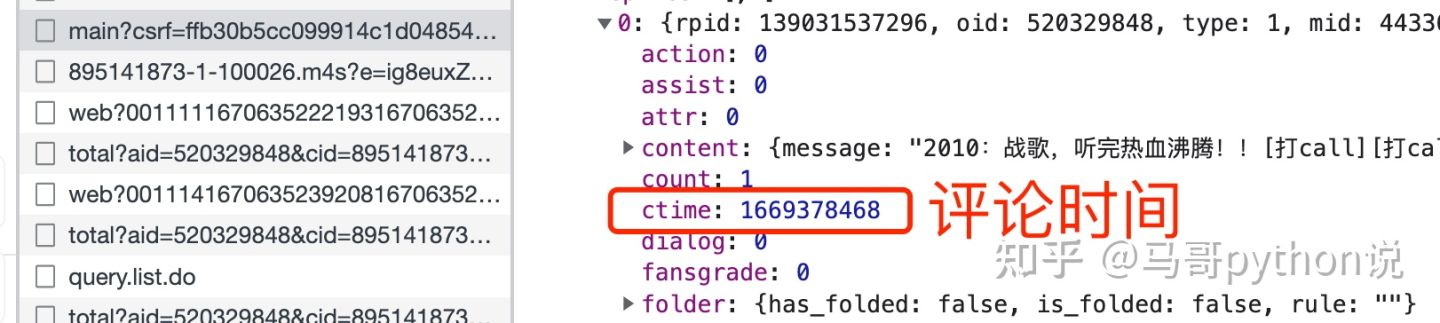
所以开发一个函数用于转换时间格式:
def trans_date(v_timestamp):
"""10位时间戳转换为时间字符串"""
timeArray = time.localtime(v_timestamp)
otherStyleTime = time.strftime("%Y-%m-%d %H:%M:%S", timeArray)
return otherStyleTime
向B站发送请求:
response = requests.get(url, headers=headers, ) # 发送请求
接收到返回数据了,怎么解析数据呢?看一下json数据结构:
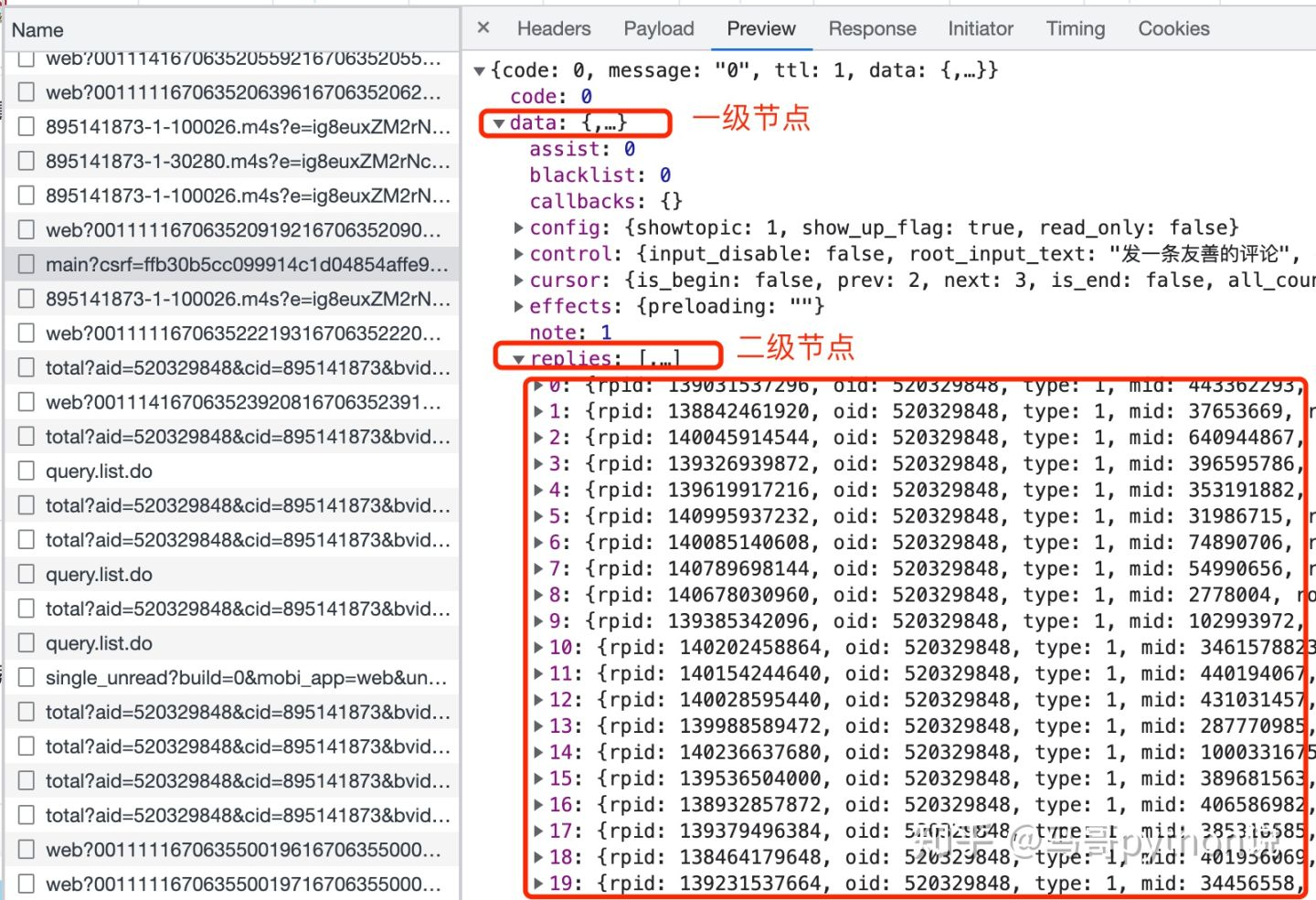
0-19个评论,都存放在replies下面,replies又在data下面,所以,这样解析数据:
data_list = response.json()['data']['replies'] # 解析评论数据
这样,data_list里面就是存储的每条评论数据了。
接下来吗,就是解析出每条评论里的各个字段了。
我们以评论内容这个字段为例:
comment_list = [] # 评论内容空列表
# 循环爬取每一条评论数据
for a in data_list:
# 评论内容
comment = a['content']['message']
comment_list.append(comment)
其他字段同理,不再赘述。
最后,把这些列表数据保存到DataFrame里面,再to_csv保存到csv文件,持久化存储完成:
# 把列表拼装为DataFrame数据
df = pd.DataFrame({
'视频链接': 'https://www.bilibili.com/video/' + v_bid,
'评论页码': (i + 1),
'评论作者': user_list,
'评论时间': time_list,
'IP属地': location_list,
'点赞数': like_list,
'评论内容': comment_list,
})
# 把评论数据保存到csv文件
df.to_csv(outfile, mode='a+', encoding='utf_8_sig', index=False, header=header)
注意,加上encoding=‘utf_8_sig’,否则可能会产生乱码问题!
下面,是主函数循环爬取部分代码:(支持多个视频的循环爬取)
# 随便找了几个"狂飙"相关的视频ID
bid_list = ['BV1Hx4y1E7QP', 'BV1Ev4y1r737', 'BV19x4y177ni']
# 评论最大爬取页(每页20条评论)
max_page = 50
# 循环爬取这几个视频的评论
for bid in bid_list:
# 输出文件名
outfile = 'b站评论_{}.csv'.format(now)
# 转换aid
aid = bv2av(bid=bid)
# 爬取评论
get_comment(v_aid=aid, v_bid=bid)
三、可视化代码
为了方便看效果,以下代码采用jupyter notebook进行演示。
3.1 读取数据
用read_csv读取刚才爬取的B站评论数据:
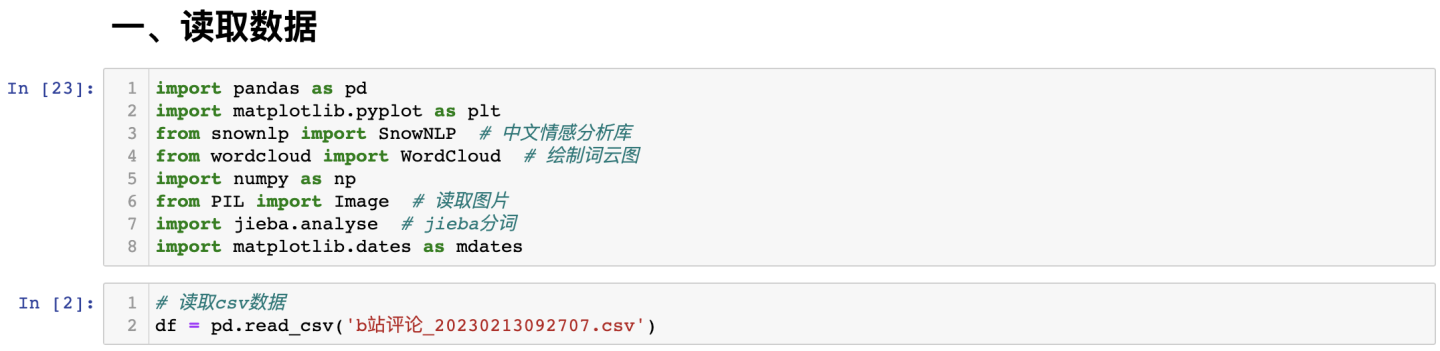
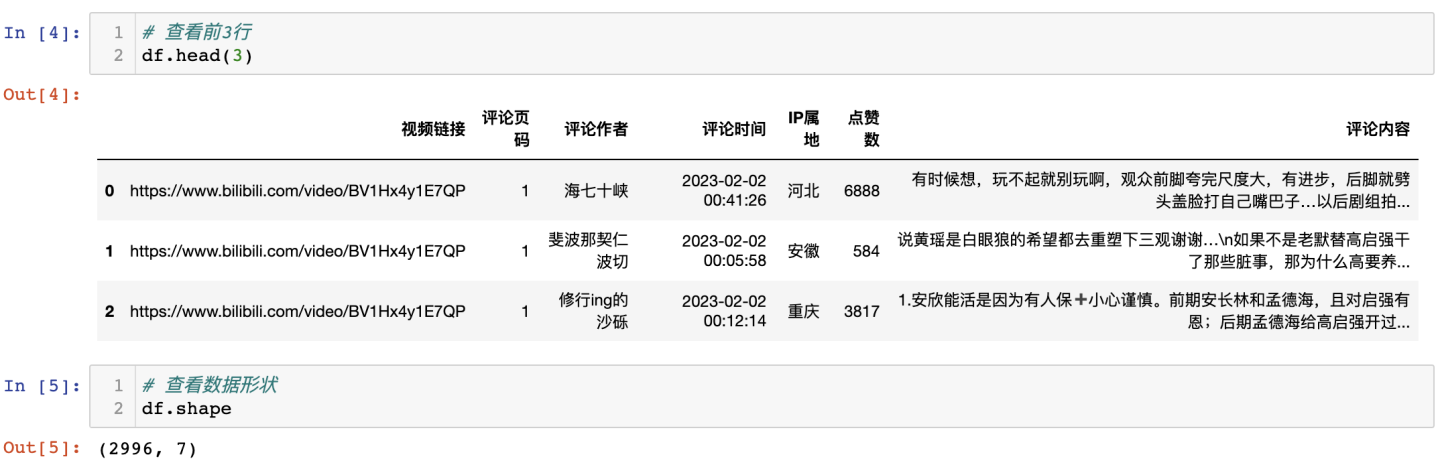
查看前3行及数据形状:
3.2 数据清洗
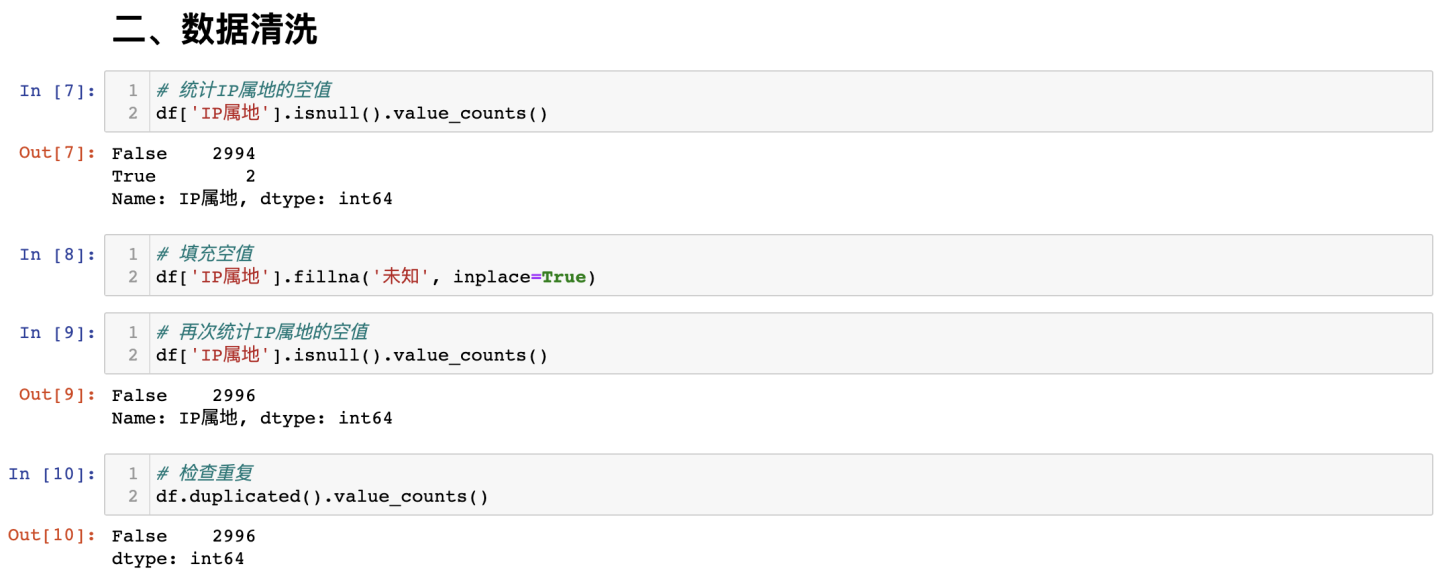
处理空值及重复值:
3.3 可视化
3.3.1 IP属地分析-柱形图
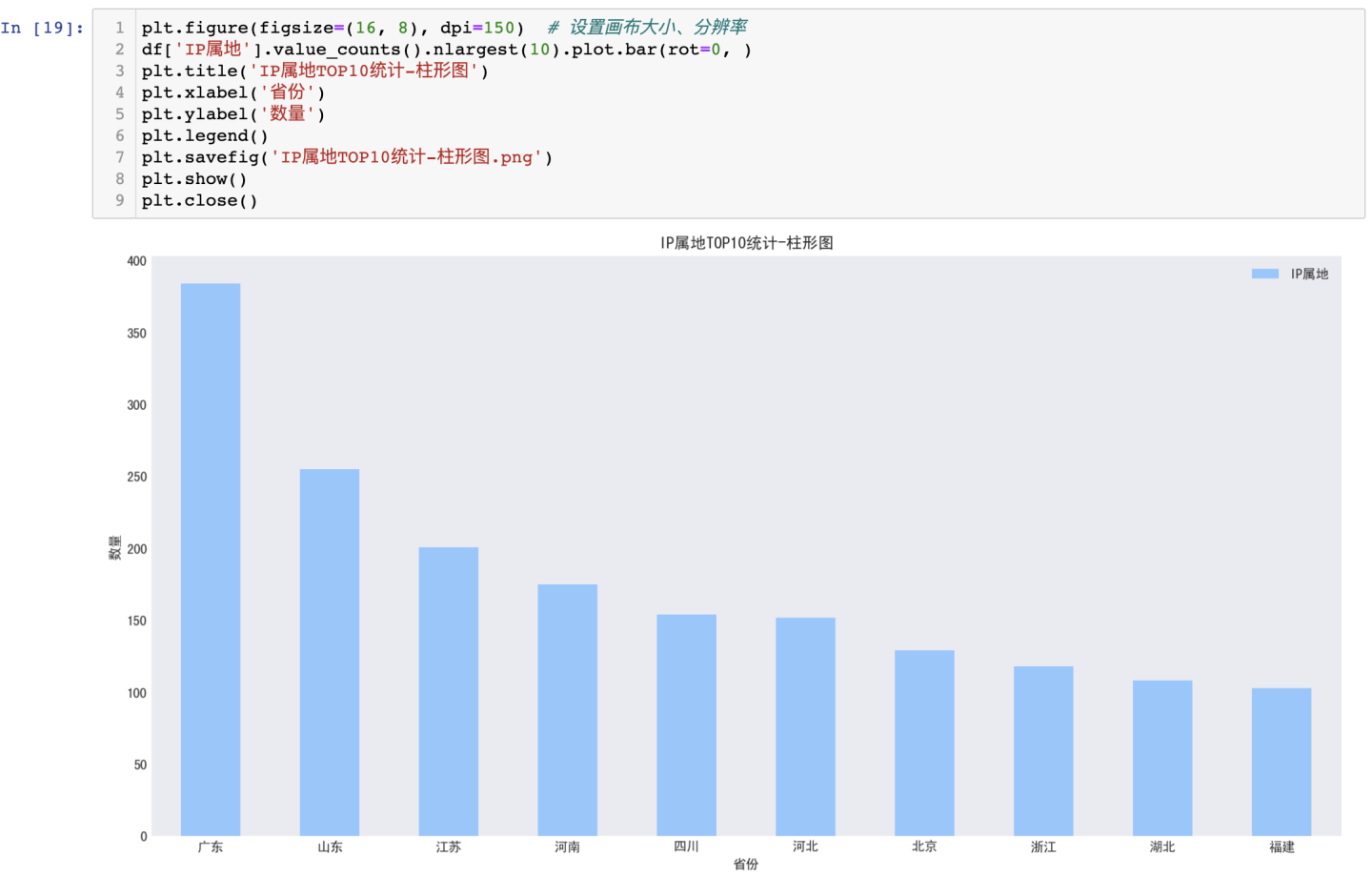
可得结论:TOP10地区中,评论里关注度最高为广东、山东、江苏等地区,其中,广东省的关注度最高。
3.3.2 评论时间分析-折线图
分析出评论时间的分布情况:
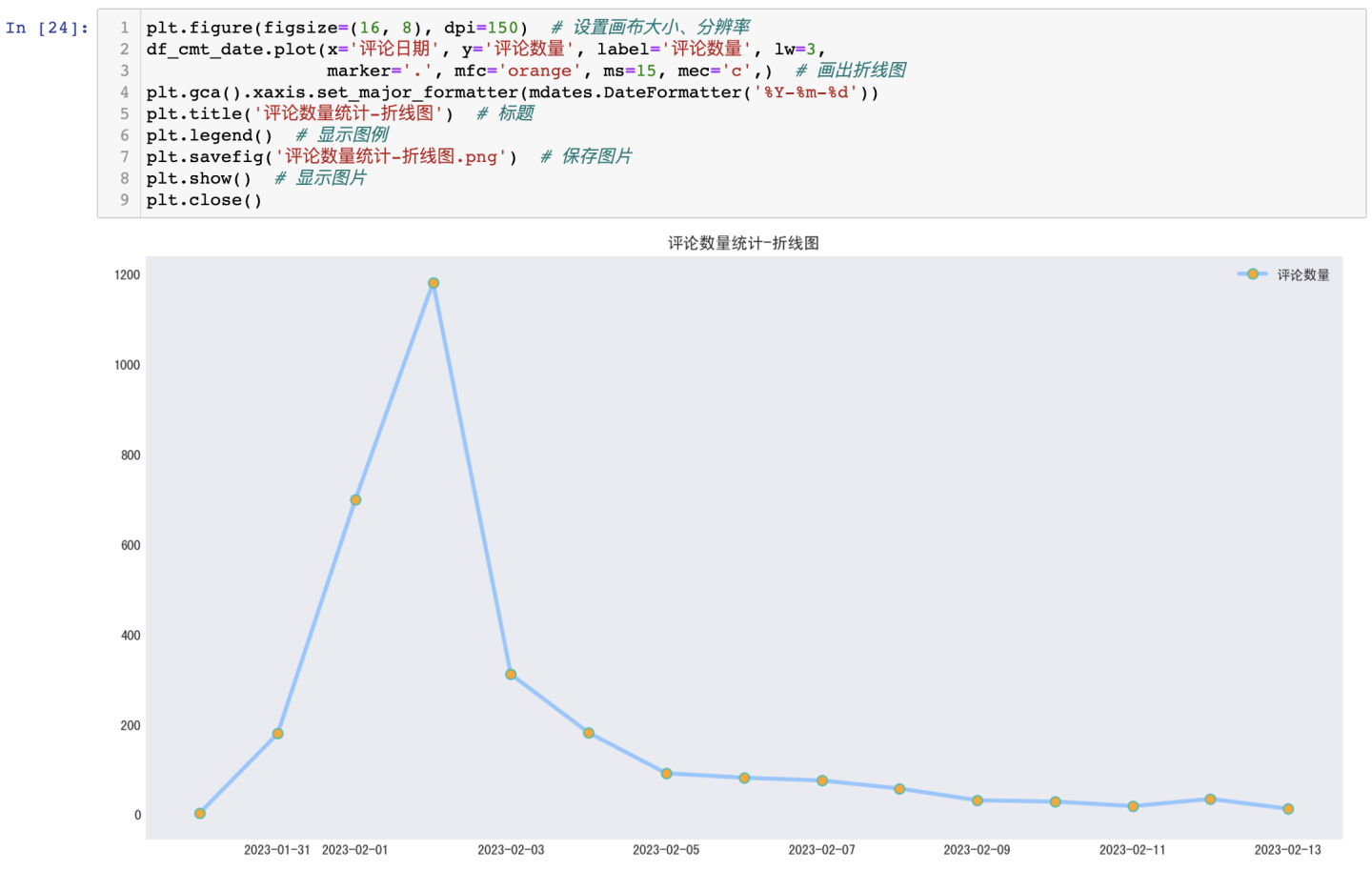
可得结论:关于"狂飙"这个话题,在抓取到的数据范围内,2月2日的评论数据量最大,网友讨论最热烈,达到了将近1200的数量峰值。
3.3.3 点赞数分布-直方图
由于点赞数大部分为0或个位数情况,个别点赞数到达成千上万,直方图展示效果不佳,因此,仅提取点赞数<30的数据绘制直方图。
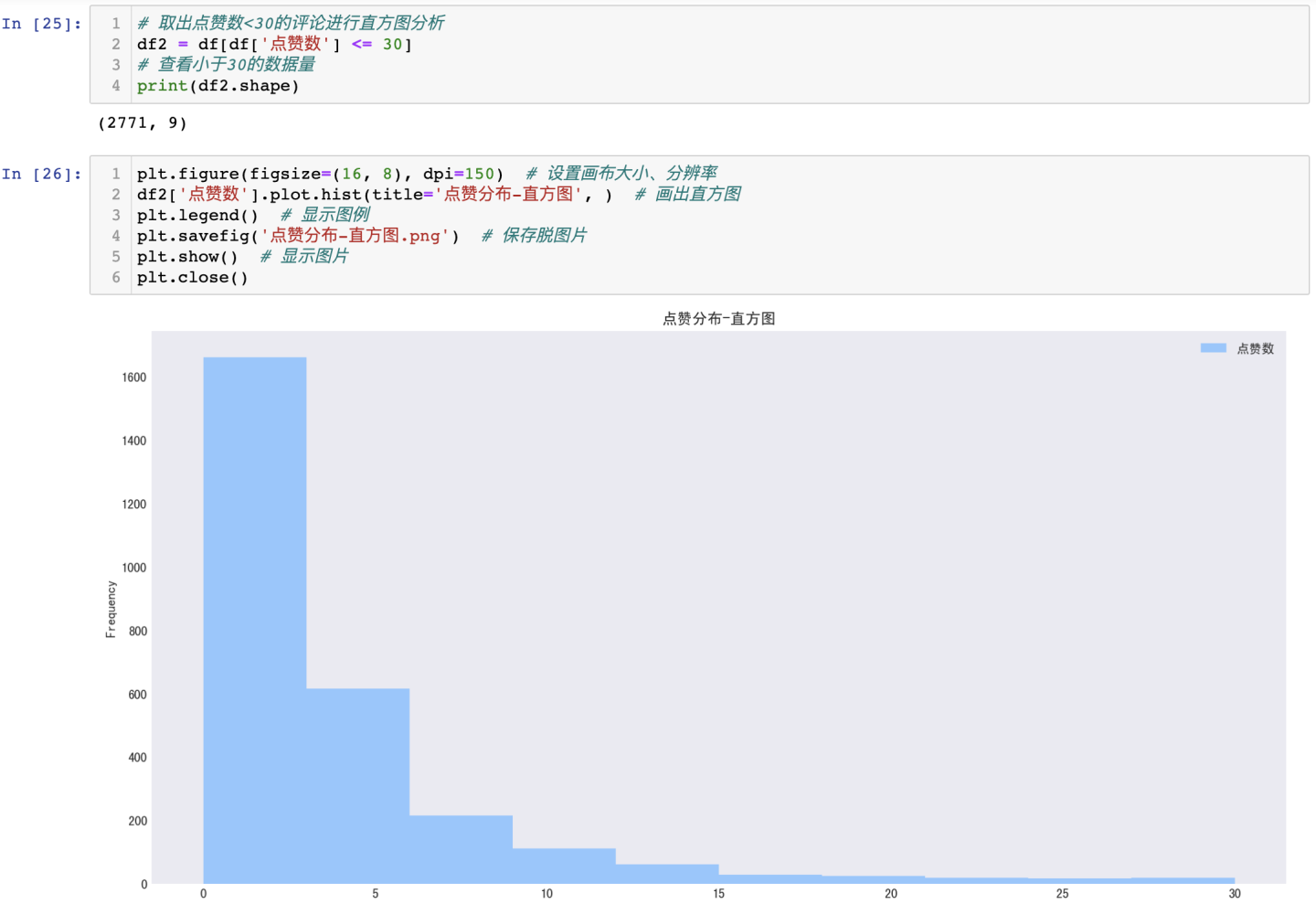
可得结论:从直方图的分布来看,点赞数在0-3个的评论占据大多数,很少点赞数达到了上千上万的情况。证明网友对狂飙这部作品的态度分布比较均匀,没有出现态度非常聚集的评论内容。
3.3.4 评论内容-情感分布饼图
针对中文评论数据,采用snownlp开发情感判定函数:
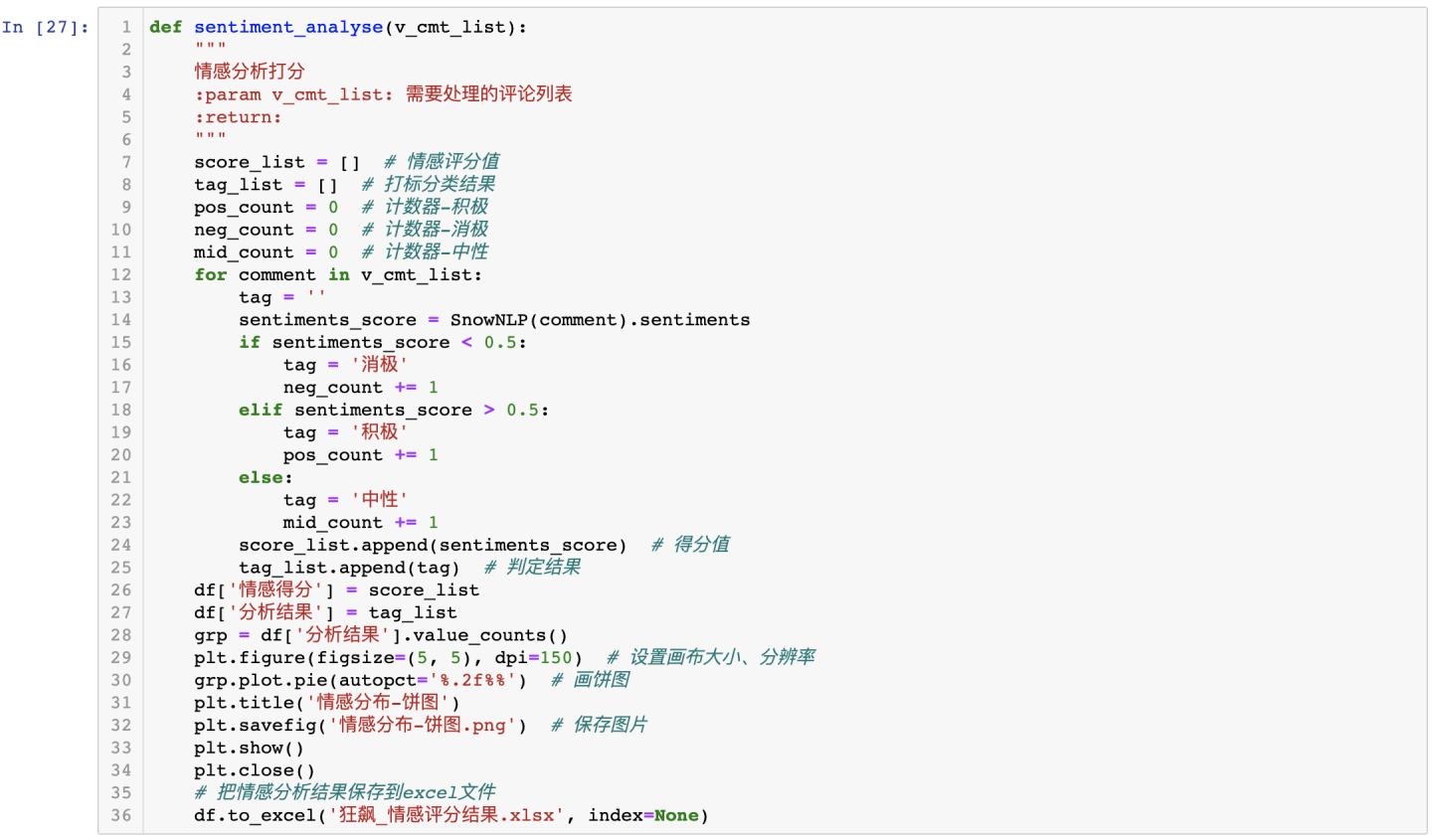
情感分布饼图,如下:
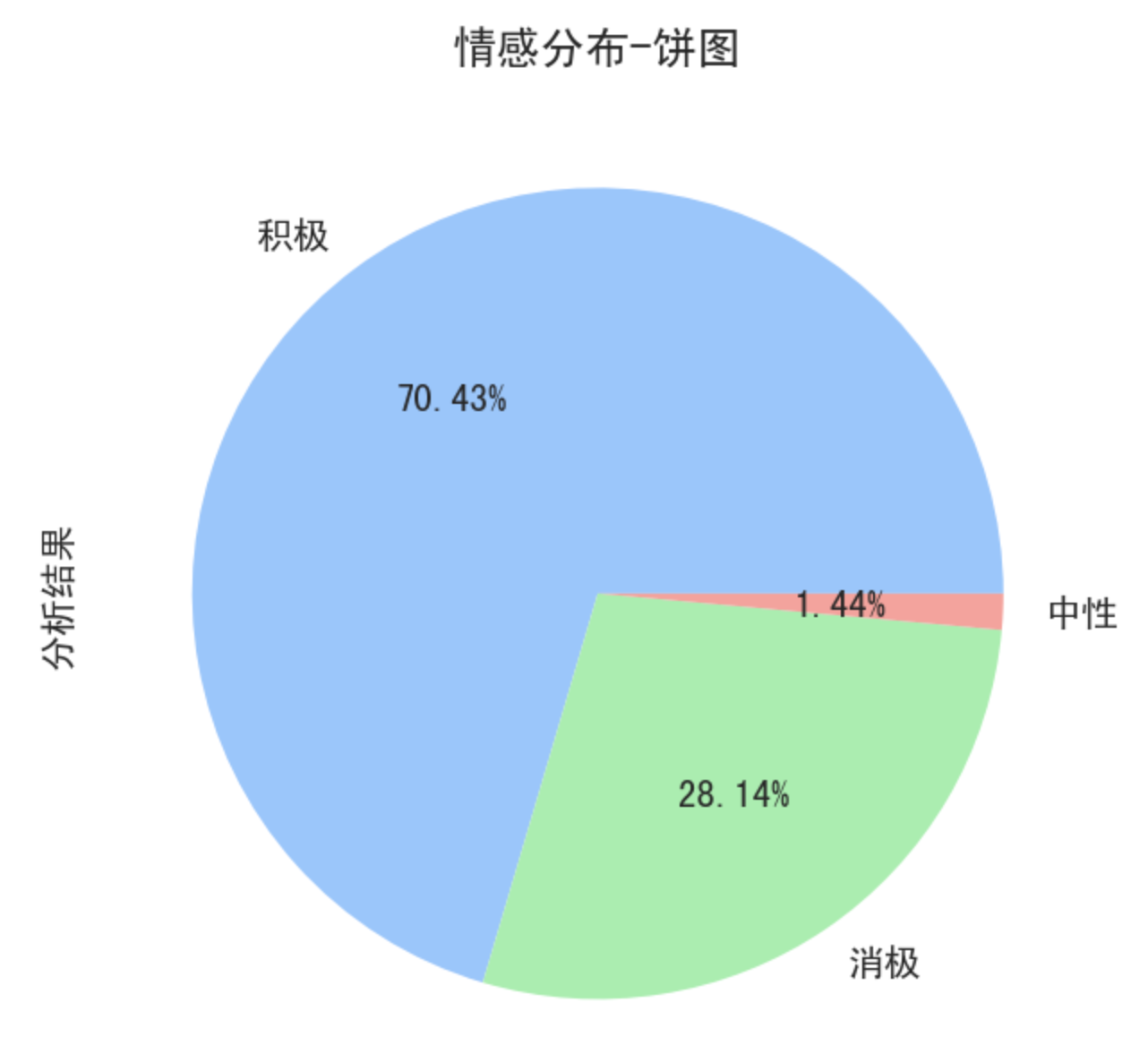
可得结论:关于狂飙这部电视剧,网友的评论情感以正面居多,占据了70.43%,说明这部电视剧获得了网友们很高的评价。
3.3.5 评论内容-词云图
除了哈工大停用词之外,还新增了自定义停用词:

jieba分词之后,对分词后数据进行绘制词云图:
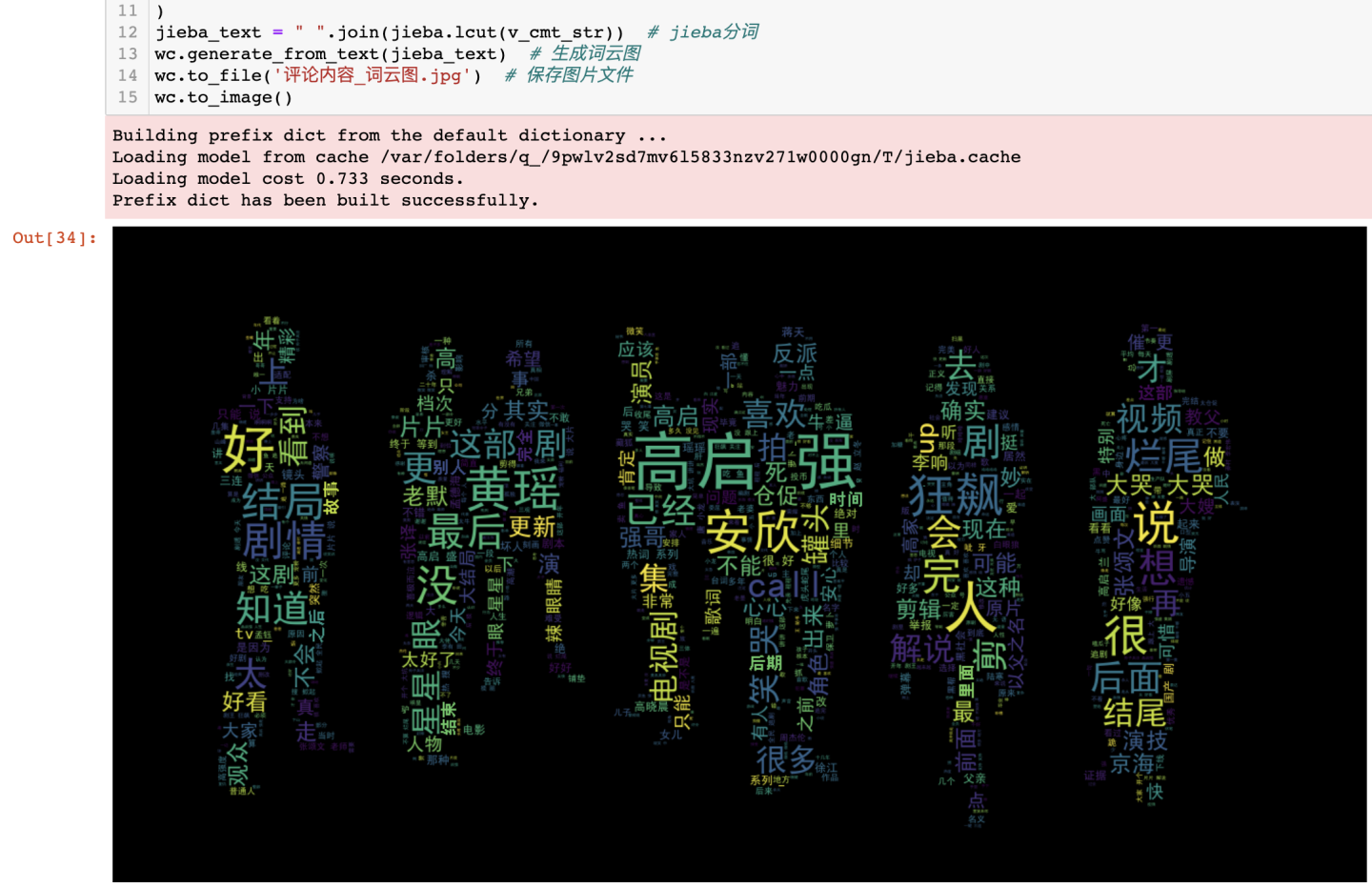
可得结论:在词云图中,狂飙、高启强、黄瑶、安欣、结局等词汇较大,出现频率较高,反应出众多网友对狂飙这部电视剧的剧情讨论热度很高。
附原始背景图,可对比看:(需要先人物抠图)

四、演示视频
代码演示视频:
https://www.bilibili.com/video/BV1D8411T7dm
五、附完整源码
完整源码,微信公众号"老男孩的平凡之路"后台回复"狂飙"即可获取。
点击直达:【爬虫+数据清洗+可视化分析】舆情分析哔哩哔哩"狂飙"的评论