一、介绍
VOC 数据是 PASCAL VOC Challenge 用到的数据集,官网:http://host.robots.ox.ac.uk/pascal/VOC/
备注:VOC数据集常用的均值为:mean_RGB=(122.67891434, 116.66876762, 104.00698793)
Pytorch 上通用的数据集的归一化指标为:mean=(0.485, 0.456, 0.406) , std=(0.229, 0.224, 0.225)
voc2007 官网:http://host.robots.ox.ac.uk/pascal/VOC/voc2007/index.html
注意:在 VOC 官方给出的数据集中,只有 VOC2007 是给出了带有标记的测试集的。其他年份的数据集是没有给测试集,只给的有带标记的验证集。

二、VOCdevikit
里面是开发工具包代码和文档。解压后如下:
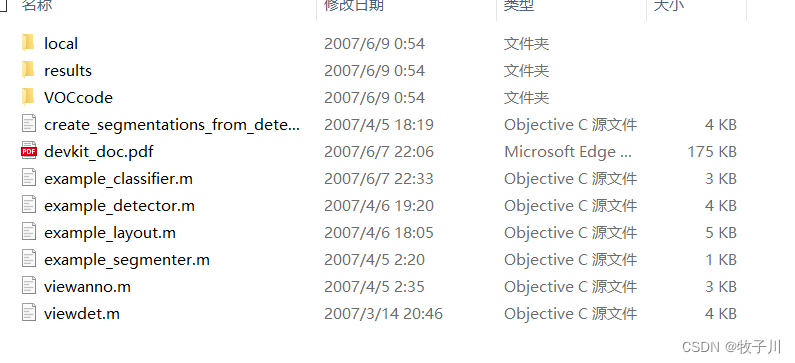
如图所示,里面是一些 MATLAB 代码,就是用这些代码处理的这个数据集,具体可以看看 devkit_doc.pdf, 就是一个比较详细的说明书。
三、VOCtrainval_06-Nov-2007
这个里面是具体的图片数据。

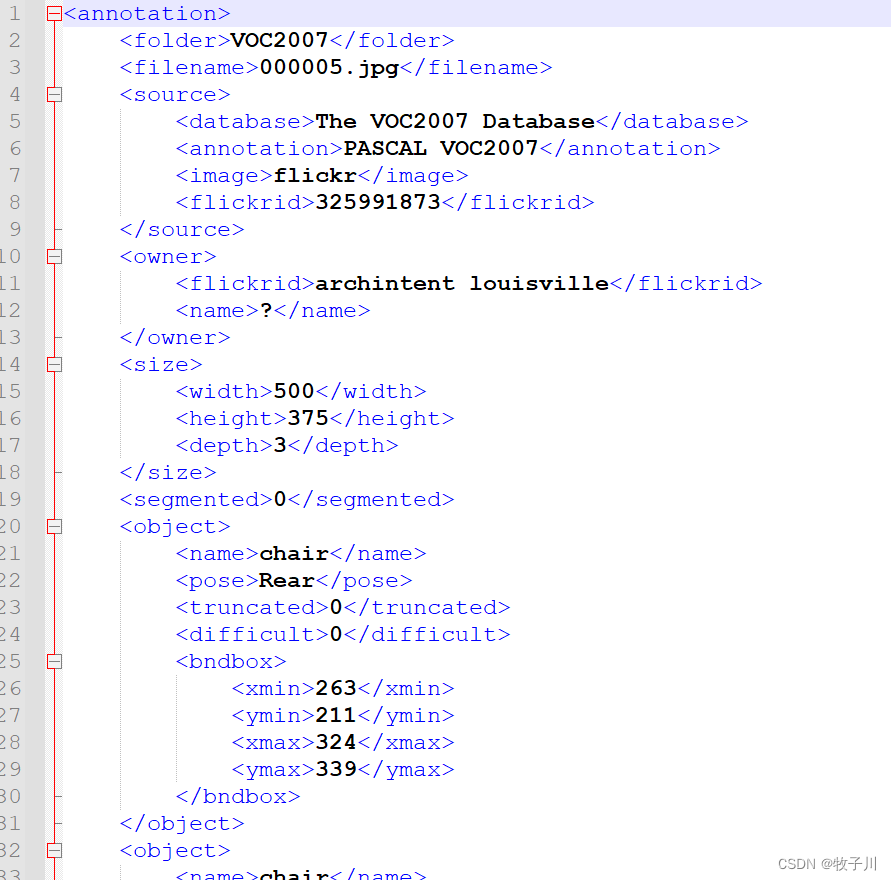
Annotations
里面是图片的标注信息,打开之后全是xml文件,文件名就是图像名称。
ImageSets
图像标签集合,里面划分了训练集、验证集、测试集。

这3个文件夹对应的是 VOC challenge 中3类不同的任务。
Main:对应 classification 和 detection 两个任务

在这里面一共有63个文件。
如何得到的:
train.txt、 trainval.txt、 val.txt:划分的训练集、验证集、测试集
剩余60个文件:20 * 3(类别名_train.txt、类别名_trainval.txt、类别名_val.txt ) = 60
VOC 2007 类别(20类):
-
person
-
bird, cat, cow, dog, horse, sheep
-
aeroplane, bicycle, boat, bus, car, motorbike, train
-
bottle, chair, dining table, pottedplant, sofa, tv/monitor
然后打开这些子类的文本文档的时候,会稍显不同,以 aeroplane_train.txt (飞机)为例:
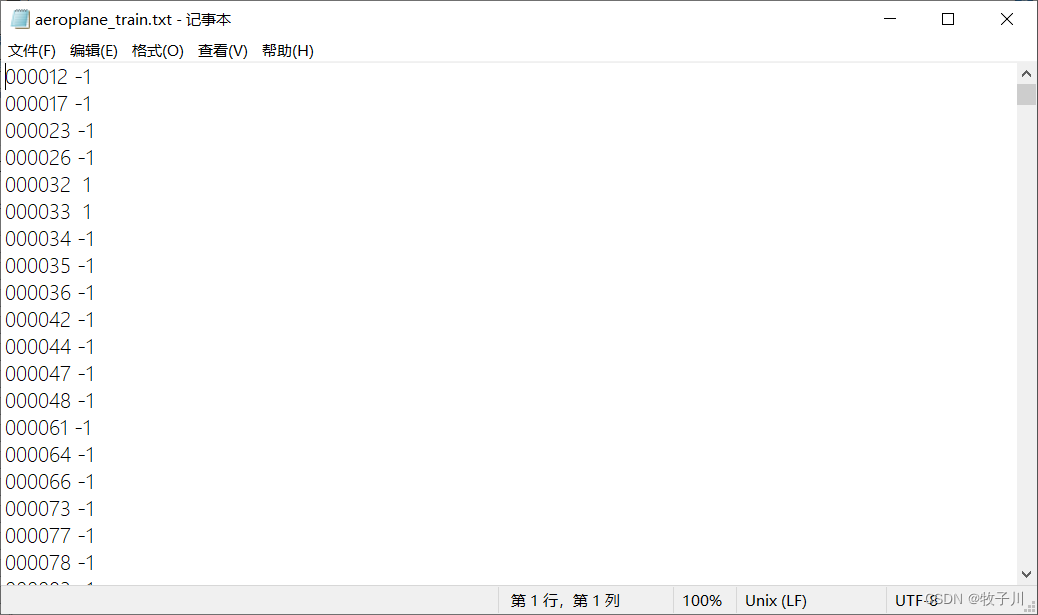
该文件一共有2501行,说明此任务训练集图片共有2501个。在
图像ID 后面还有一个数字(-1,1,0)。
意义如下:
-1:表示当前图像中没有该类物体;
1:表示当前图像中有该类物体;
0:表示当前图像中该类物体只露出了一部分。
Layout、Segmentation 为另外两个任务。
所以这3个文件夹中包含的是3类不同的任务需要用到的不同的图片集合。
其中 Layout 和 Segmentation:
train.txt 表示的是训练集,val.txt 表示的是验证集, trainval.txt 是把前两者写到了一起

JPEGImages
里面全都是原始图片数据,一共有5011张个图像。
SegmentationClass
该文件夹是专门用于 Segmentation 任务的一个文件夹,里面存放的是 Segmentation 任务的 label 信息。用于Semantic segmentation [语义分割]。这里的图片共有20+1(背景色)种颜色。

该文件夹中的图片共有422张,在 Imageseets/Segmentation 文件夹中的 trainval.txt 文档,也有422行。
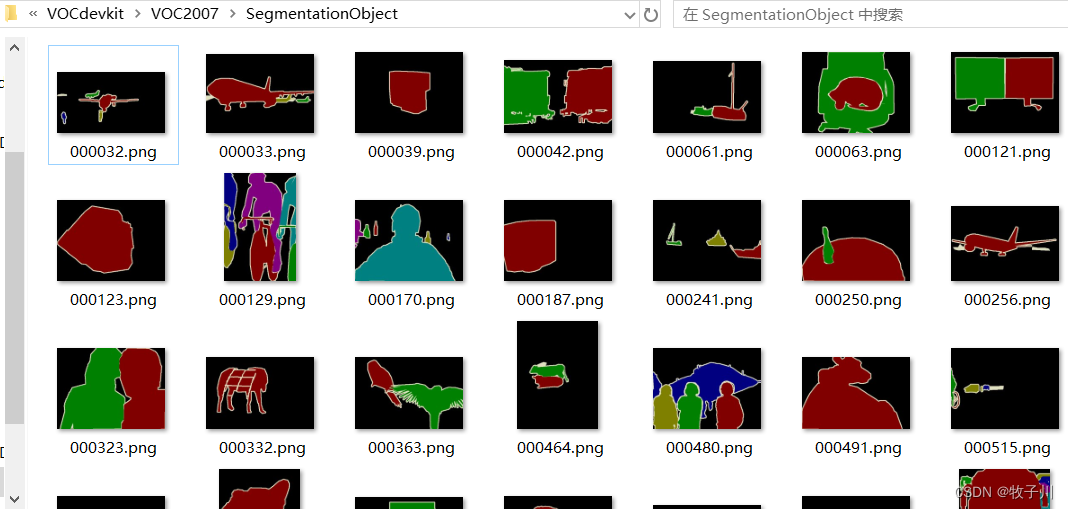
SegmentationObject
用于 Instance Segmentation(实例分割)。在Class里面,一张图片里如果有多架飞机,那么会全部标注为红色。而在Object里面,同一张图片里面的飞机会被不同颜色标注出来。
四、VOCtest_06-Nov-2007
同 VOCtrainval_06-Nov-2007
五、数据下载
【目标检测数据集】VOC2007 数据集介绍
六、链接作者
欢迎关注我的公众号:@AI算法与电子竞赛
硬性的标准其实限制不了无限可能的我们,所以啊!少年们加油吧!