引言:数学问题解决在大语言模型中的挑战
在当今的人工智能领域,大语言模型(Large Language Models,LLMs)已经在理解和生成人类语言方面取得了显著的进展。这些模型在文本摘要、问答、角色扮演对话等多种语言任务上展现出了惊人的能力。然而,当这些模型被应用于需要数学推理的复杂问题时,它们的表现往往不尽如人意。尽管开发了许多策略和数据集来增强LLMs在数学方面的能力,但在实际部署的LLM系统中同时保持和提升语言和数学能力仍然是一个显著的挑战。
GPT-3.5研究测试: https://hujiaoai.cn
GPT-4研究测试: https://higpt4.cn
Claude-3研究测试(全面吊打GPT-4): https://hiclaude3.com
传统的通过人类反馈进行强化学习(Reinforcement Learning from Human Feedback,RLHF)方法主要是通过反映人类偏好的奖励模型来增强文本生成的质量。虽然这种方法提升了生成文本的质量,但它通常忽视了解决数学问题所必需的准确性和逻辑连贯性,导致在数学推理任务上的表现出现所谓的“对齐税”(alignment tax)。与此相反,旨在增强LLMs数学能力的尝试通常涉及到监督式微调(Supervised Fine-tuning,SFT),这不可避免地会降低它们在语言多样性上的表现,为LLM系统的实际应用带来了困境。
本文介绍了一种新颖的方法,旨在提升LLMs在语言和数学技能上的能力,而不会牺牲其中的任何一个。我们的策略与传统的RLHF方法不同,它包含了从LLM自身派生出的数学批判模型(Math-Critique model),该模型用于评估其数学输出。这种自我批判机制使模型能够从专门针对数学内容的AI生成反馈中学习。
论文标题:
ChatGLM-Math: Improving Math Problem-Solving in Large Language Models with a Self-Critique Pipeline
论文链接:
https://arxiv.org/pdf/2404.02893.pdf
自我批判管道(Self-Critique Pipeline)的介绍
在优化大语言模型(LLMs)的过程中,研究者们面临着一个显著的挑战:如何在不牺牲语言理解能力的前提下,提升模型在数学问题解决方面的性能。传统的强化学习方法虽然能够提高文本生成的质量,但往往忽视了解决数学问题所需的准确性和逻辑一致性。为了解决这一问题,本文介绍了一种新颖的自我批判管道(Self-Critique Pipeline),旨在同时提升LLMs的数学和语言能力。
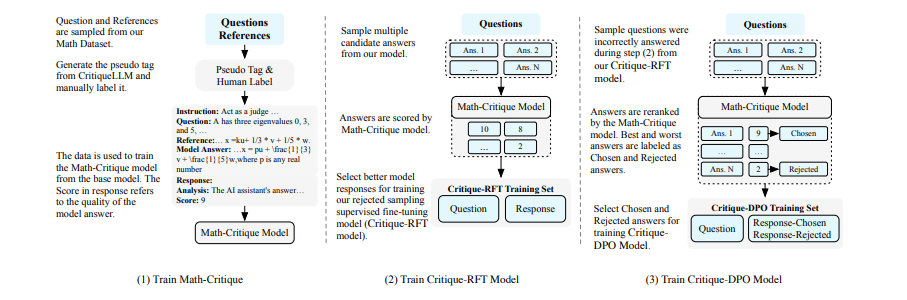
自我批判管道包括两个主要阶段:
1. 拒绝性微调(Rejective Fine-tuning, RFT):在此阶段,采用拒绝采样技术,即淘汰不符合Math-Critique标准的响应,而将其余响应进一步微调。这一阶段的目标是提高模型在数学回答方面的准确性和一致性,同时确保所选答案的多样性。
2. 直接偏好优化(Direct Preference Optimization, DPO):在RFT的基础上,通过直接从正确和错误答案对中学习,进一步提炼通过Math-Critique的答案,重点解决上一阶段中最具挑战性的问题。
自我批判管道的引入,不仅提升了LLMs在数学问题解决方面的性能,而且还改善了其语言能力。通过在ChatGLM3-32B模型上的一系列实验,结果表明,该管道显著增强了LLMs的数学问题解决能力,并在MATHUSEREVAL等数据集上取得了优于规模更大两倍的LLMs的性能。
Math-Critique模型的设计与实现
Math-Critique模型的设计灵感来源于利用大模型进行评估的工作。该方法通过对模型生成的数学回答进行评分,包括解释性分析和1到10之间的分数输出,与传统的奖励模型相比,Math-Critique利用语言模型的上下文能力,通过整合参考答案,实现更准确的判断。
在Math-Critique的指导下,回答被分类为完全错误、部分正确的方法但结果错误、准确的结论但方法部分有缺陷和完全正确四个类别。这些类别与1-2、3-5、6-8和9-10的评分范围相对应。
Math-Critique的实现包括以下步骤:
-
从训练数据中筛选出包含数学问题及其参考答案和模型响应的数据集,主要来源于从初中到大学级别的考试题目。
-
使用CritiqueLLM和ORM对数据集进行注释,选择代表最好和最差评分极端的注释,并直接用这些伪标签进行训练,共生成了10k条注释数据。
-
对于中间范围的分数结果,选择一部分进行手动注释,分为四个类别,然后将这些结果映射到10分制上。同时,从训练数据集中划分出一个测试集,并采用相同的四类别注释方法,生成了5k条训练数据和800条测试数据。
Math-Critique模型的训练过程中,基于ChatGLM3-32B作为初始的Math-Critique基础模型,每次迭代后,通过SFT或Critique RFT精炼的当前模型将作为基础。使用的学习率为3e-6,批量大小为128,适用于6B和32B规模的模型。
在自我批判管道中,Math-Critique模型的数据构建仅涉及少量的手动注释。这批注释是一次性的努力,因为只需要这批注释数据作为其余迭代的引导。之后,所有剩余步骤都可以通过推理和自动模型过滤来完成。
MATHUSEREVAL数据集的创建
在创建MATHUSEREVAL数据集的过程中,研究团队采取了一系列步骤以确保数据集能够准确评估大语言模型(LLMs)在解决实际数学问题方面的能力。
MATHUSEREVAL数据集的特点是包含了一系列多样化的问题,这些问题不仅仅局限于学术练习,还扩展到了实际应用场景,更好地反映了用户的需求,与传统的学术数学数据集相比,它提供了一个更高标准的实际数学推理能力评估。

1. 数据集来源
数据集的主要来源包括公开数据集的训练集和公开可用的中学及大学考试题。研究团队从GSM8k和MATH训练集中挑选了所有提示作为英文数据的问题集,并使用原始数据集中的回答作为标准答案。对于公开可用的中学和大学考试题,研究者使用了考试试卷提供的答案格式作为通用答案,无需进一步处理。
2. 数据集分类
基于收集到的数据分布,研究团队将测试集分为两个主要类别:基础数学和高级数学,并进一步细分为八个子类别。由于计算应用类问题难度较低,且与之前公开数据集的范围较为一致,因此在此类别中选择的问题较少。所有问题都以开放式格式提出,可能的答案包括单个数字、多个数字或数学表达式。
3. 评估方法
研究团队提供了两种评估方法:GPT-4-1106——Preview评估和Math-Critique评估。前者采用alignbench的评估方法,以提供更准确、公平和可访问的评估方式;后者则采用与上述Math-Critique相同的使用方式。同样,研究团队也将报告两种类型的分数:平均分和硬分割分。
实验结果与分析
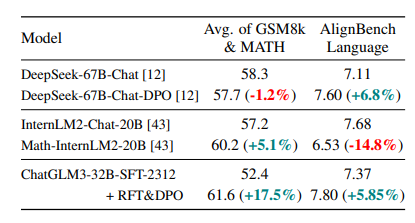
在实验中,研究团队使用了ChatGLM3-32B-SFT-2312版本作为基线模型。RFT阶段在所有数学数据集上都显著提高了性能。相比之下,DPO阶段的改进集中在开放式数学问题上,包括MATHUSEREVAL、匈牙利考试和通用的AlignBench。
尽管研究者们在MT-bench上的改进不显著,但考虑到超过90%的训练数据是中文,研究者们认为保持平衡本质上表明我们的方法保留了原始的英文通用或多轮能力。
与专有模型相比,特别是OpenAI的GPT系列,GLM-4在特定领域展示了竞争性或更优越的性能。例如,GPT-4-1106-Preview在大多数任务中表现最佳,包括在中英文基准测试中的最高分,突显了其在各种数学问题解决环境中的有效性。

然而,GLM-4在Ape210k和AlignBench基准测试中超越了它,表明了在数学推理和跨语言泛化方面的特定优势。
1. 数据组成的影响
研究团队选择了相对较强的Metamath训练集作为基线。在应用Critique-RFT之后,发现仅使用学术数据集构建RFT数据在面向现实生活场景的MATHUSEREVAL和学术测试集上的性能不如在整合了现实生活场景数据之后的结果。
此外,引入英文数据显著提高了英文数据集的性能,而不会对中文能力产生实质性影响。
2. 对一般能力的影响
考虑到目标不是开发一个专门的数学模型来攀登排行榜,而是一个具有强大数学能力的通用模型,研究者们使用Alignbench测试了结果,这是一个中文通用开放式问答数据集。结果表明,模型在中文语言能力方面超过了不包含专门数学数据的类似基线模型的训练成果。此外,与其他开源中文数学/通用模型相比,它的表现也非常出色。
在英文通用能力方面,使用MT-Bench作为测试集。考虑到超过90%的训练数据是中文,MT-Bench上的结果在训练过程中基本保持不变,表明英文语言能力没有受到显著影响。
3. Math-Critique的有效性
在手动注释过程中,收集了800个问题的测试集,所有这些问题都根据答案和程序的正确性进行了手动标记,从而形成了一个四类测试;Math-Critique的输出结果根据指令的要求映射到这四个类别。
研究者们通过实证实验验证了Math-Critique本身的有效性。设置了两种评估方法:直接评分判断正确/错误结果的准确性和判断我们定义的四个类别的准确性。从中国初高中考试题和MATHUSEREVAL中提取了测试集,并由专家注释正确判断。
结果表明,Math-Critique-32B模型在判断准确性和与人类注释相比的相关系数方面显著超过了GPT-3.5-Turbo,并且基本与GPT-4-0613持平。
4. 超出分布测试
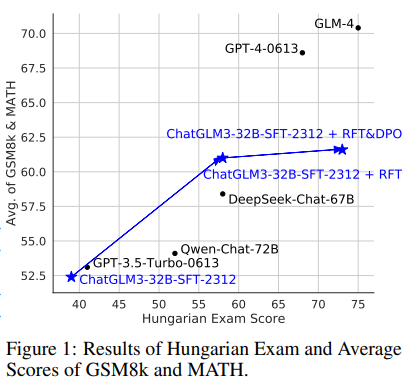
遵循Grok-1的方法,为了测试超出分布数据集的性能,选择了匈牙利国家期末考试。这是一个没有训练集的33个考试问题的测试集,其优势在于它允许评估模型在完全OOD环境中的数学能力。
使用人类专家评估,研究者们发现在32B模型规模下,RFT模型得分为57,而DPO模型得分为73。然而,需要注意的是,由于模型的主要语言是中文,如果模型用中文正确回答,通常会给予评分。研究者们计划在未来的模型中解决这个问题。
模型在数学问题解决中的错误案例分析
在数学问题解决的实际应用中,大语言模型(LLMs)虽然在语言理解方面表现出色,但在数学问题的准确性和逻辑一致性方面仍存在挑战。这些挑战通常归因于模型在训练过程中的对齐税(alignment tax),即在数学推理任务上应用常规的文本生成增强方法时,可能会导致性能的不一致。
讨论与未来工作
本研究提出了自我批评(Self-Critique)管道,旨在提高LLMs的数学问题解决能力,同时保持其语言能力。通过自我生成的反馈,我们的方法在不需要外部监督模型和手动注释的情况下,显著提高了LLMs在MATHUSEREVAL等数据集上的数学问题解决能力。
1. 未来工作方向
-
图形思维和绘图能力:目前的模型在处理需要绘图的问题上存在不足,未来可以探索集成多模态输入和输出组件的方法。
-
精确计算能力:模型在处理多位小数的乘法、除法或指数运算时可能会出现高达5%的偏差。未来的工作可以考虑使用外部工具进行计算或直接使用带有代码解释器的代码。
-
模型的通用能力:目标是开发一个具有强大数学能力的通用模型,而不仅仅是为了领先排行榜。未来的研究可以继续探索如何在增强特定能力的同时保持模型的通用性。
2. 结论
本研究证明了自我批评方法在提高LLMs数学问题解决能力方面的有效性,并在多个数据集上取得了优于现有开源和专有模型的结果。该方法已经在GLM-4的开发过程中应用,以提高其数学能力,并在MATHUSEREVAL等数据集上取得了最佳结果。未来将继续探索和改进这些方法,以进一步提高模型在实际应用中的表现。