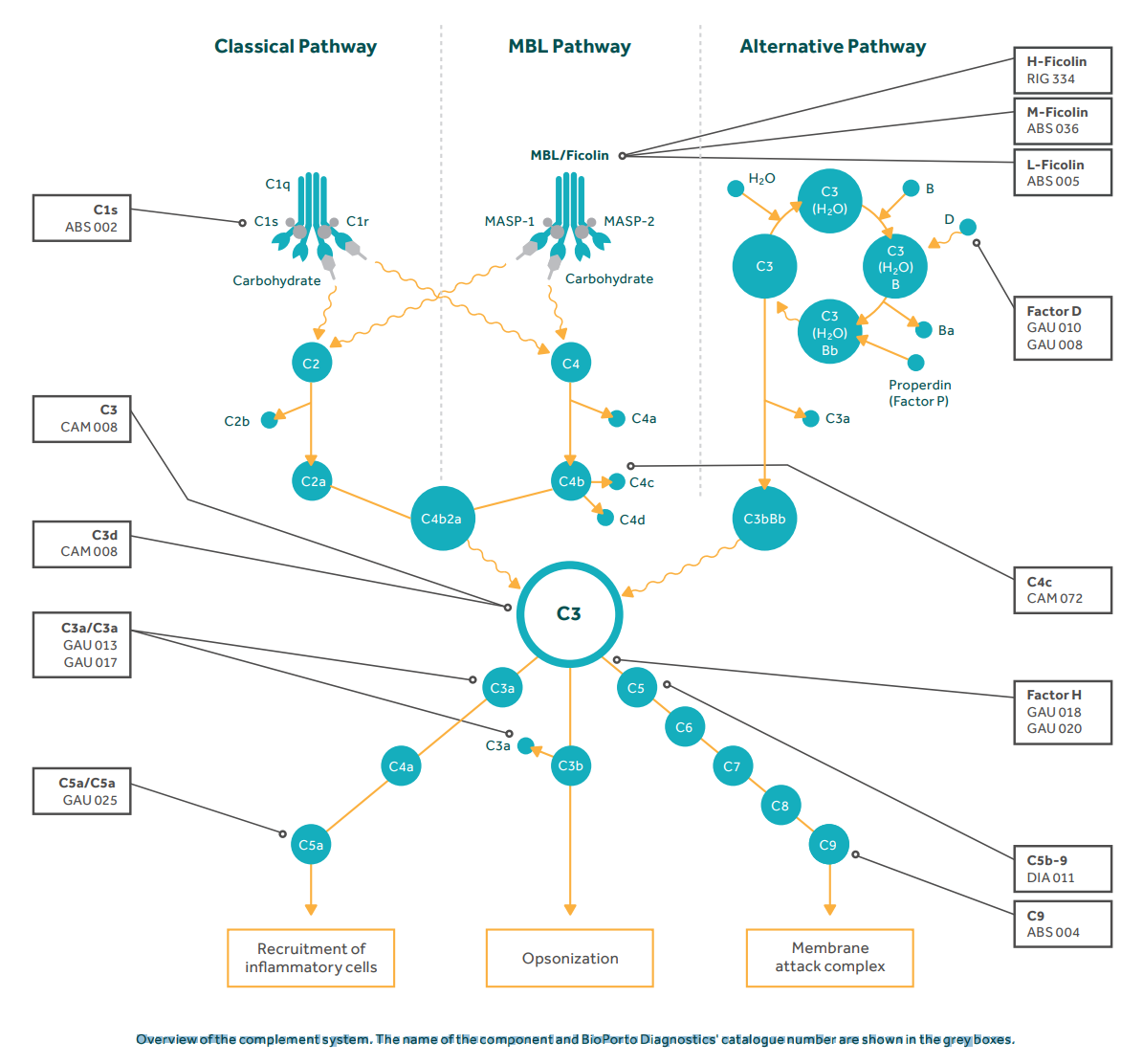
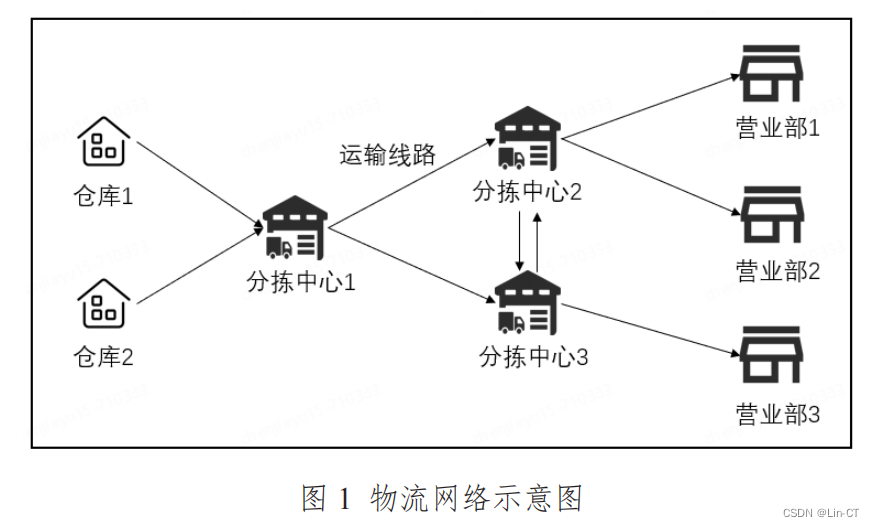
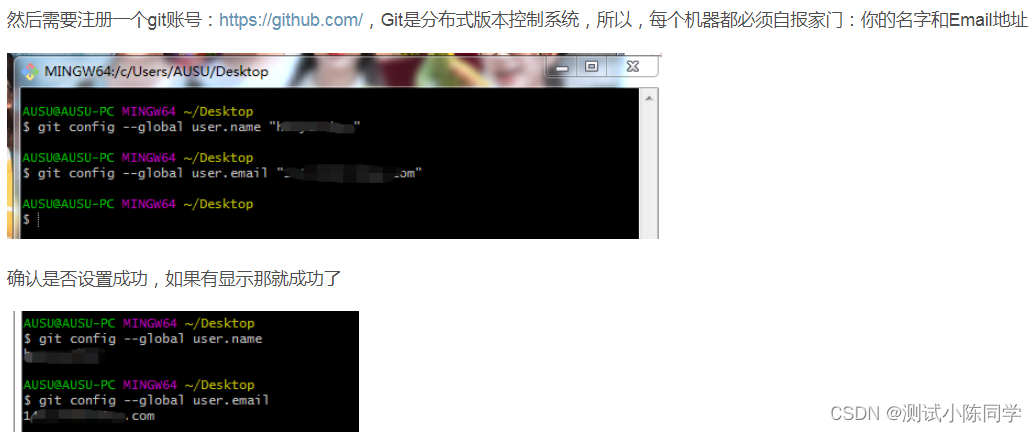
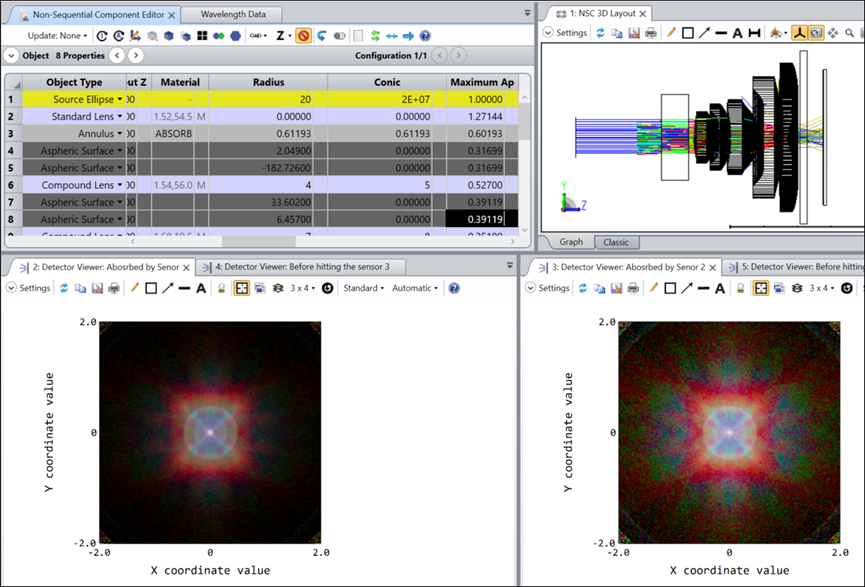
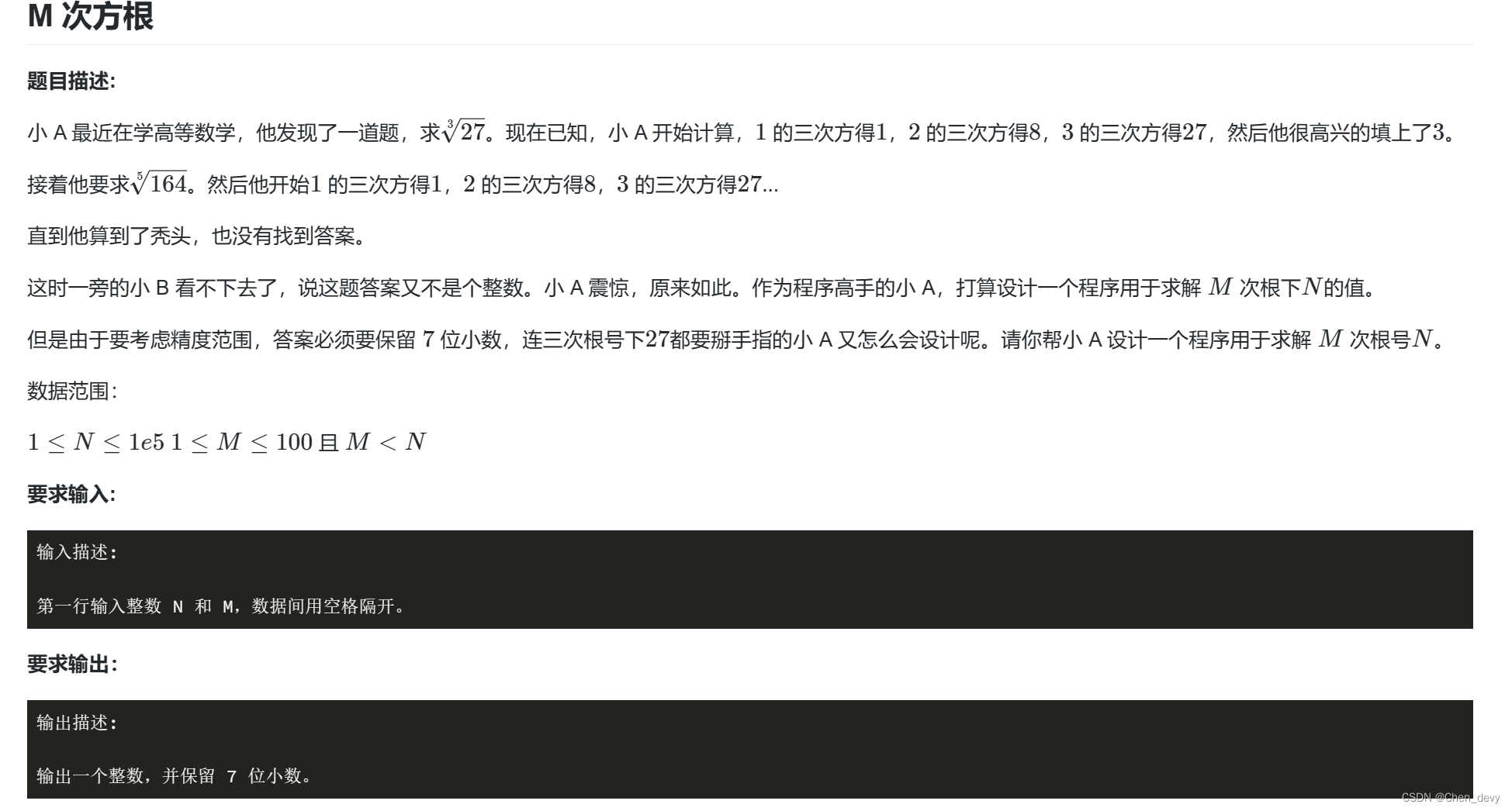
练习1 地区收入的PCA主成分分析
0. 变量说明
1.导包操作 核心思路:导入基础数据操作库包,PCA、k-means 库包,数据可视化库包
import pandas as pd import numpy as np from sklearn . decomposition import PCA from sklearn . preprocessing import StandardScaler from sklearn . cluster import KMeans from sklearn . metrics import silhouette_score import matplotlib . pyplot as plt import seaborn as sns % matplotlib inline #如遇中文显示问题可加入以下代码 from pylab import mpl plt . rcParams [ 'font.sans-serif' ] = [ 'SimHei' ] # 指定默认字体 plt . rcParams [ 'axes.unicode_minus' ] = False # 解决保存图像是负号'-'显示为方块的问题 import warnings warnings . filterwarnings ( 'ignore' )
2.读取数据 核心代码:pd.read_csv(path,encoding=编码格式),注意这里的编码是gb2312
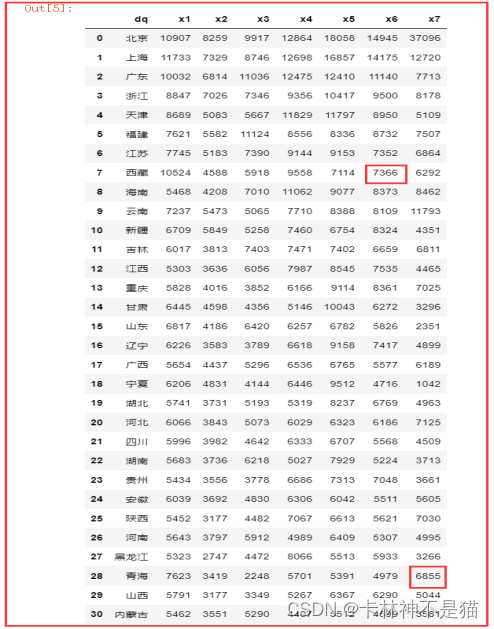
# 读取数据 df = pd . read_csv ( fr"./各地区年平均收入.csv" , encoding = "gb2312" ) df
3.数据预处理 3.1.查看数据类型 核心代码:df.dtypes
核心思路:sum_col / count (列和 / 非空个数)
import pandas as pd import numpy as np def calculate_and_replace_mean ( df , column ) : # 计算列的平均值,仅包括可以转换为整数的值 count = 0 sum_col = 0 for value in df [ column ] : if value != " " and pd . notnull ( value ) : try: count += 1 sum_col += int ( value ) except ValueError : continue # 计算平均值,如果无法计算则返回NaN column_mean = sum_col / count if count > 0 else np . nan # 取整数 column_mean = int ( column_mean ) # 将列中的空格替换为平均值 df [ column ] = df [ column ]. replace ( " " , column_mean ) return df
# 对x1到x7列计算并替换平均值 for col in [ 'x1' , 'x2' , 'x3' , 'x4' , 'x5' , 'x6' , 'x7' ] : df = calculate_and_replace_mean ( df , col ) # 替换dq列中的空格为"MIssing" df [ 'dq' ] = df [ 'dq' ]. replace ( " " , "MIssing" ) # 显示更新后的DataFrame df
3.3.转换数据类型 核心代码:df[字段名].astype(新类型)
# 装换字段类型 df [ 'x6' ] = df [ 'x6' ]. astype ( int ) df [ 'x7' ] = df [ 'x7' ]. astype ( int ) df . dtypes
4.抽取数据 核心思路:df[字段列表],提取数值型的数据
# 数据截取 df_train = df [[ "x1" , "x2" , "x3" , "x4" , "x5" , "x6" , "x7" ]] df_train
5.特征工程 核心思路:特征工程标转化,高维数据转化为低维数据
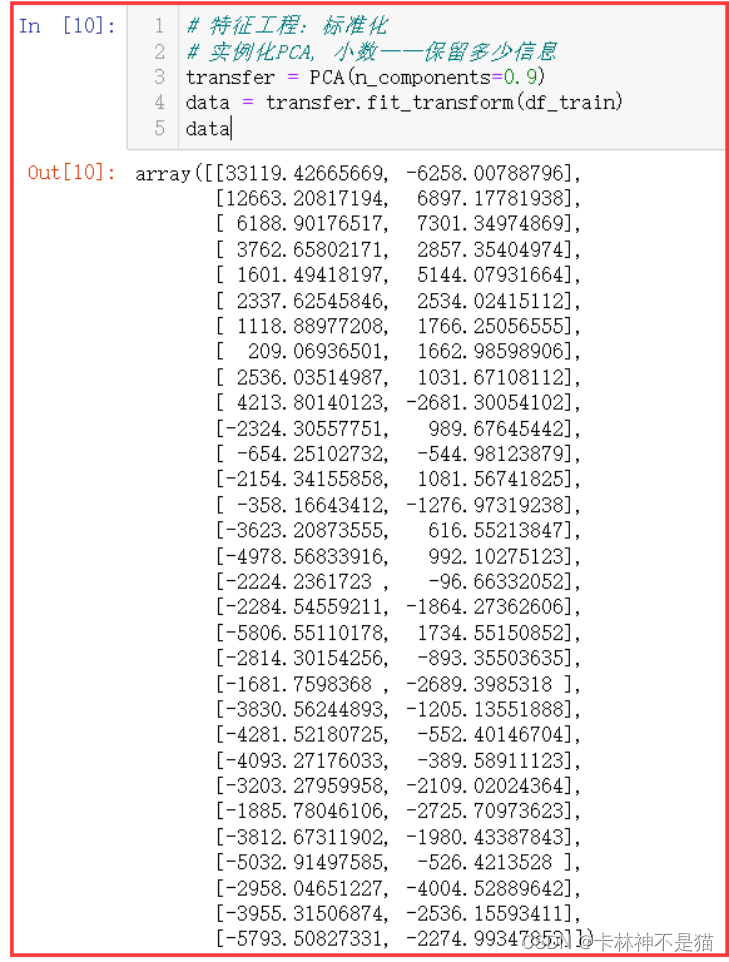
# 特征工程:标准化 # 实例化PCA, 小数——保留多少信息 transfer = PCA ( n_components = 0.9 ) data = transfer . fit_transform ( df_train ) data
6.机器学习 6.1.肘部法确定k值 核心思路:选择曲线开始变得平坦的点作为K值。
# 确定k值 # 肘部法则(Elbow Method): # 通过计算不同K值下的簇内误差平方和(Inertia或称为Distortion),并绘制它们随K值变化的曲线。 # 注意:选择曲线开始变得平坦的点作为K值,这个点通常被认为是“肘部”。 distortions = [] K = range ( 1 , 10 ) for k in K : kmeanModel = KMeans ( n_clusters = k ). fit ( data ) distortions . append ( kmeanModel . inertia_ ) plt . plot ( K , distortions , 'bx-' ) plt . xlabel ( 'k' ) plt . ylabel ( 'Distortion' ) plt . title ( 'The Elbow Method showing the optimal k' ) plt . show ()
6.2.K-Means聚类
核心思路:将k值确定为肘部“4”
#机器学习(k-means) estimator = KMeans ( n_clusters = 4 , random_state = 22 ) y_predict = estimator . fit_predict ( data ) y_predict
7.模型评估 核心代码:silhouette_score ()
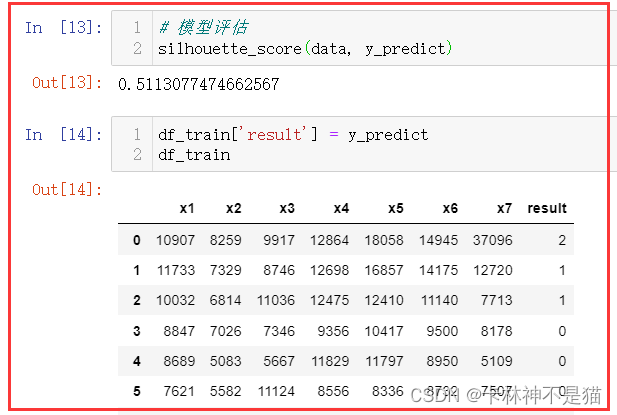
# 模型评估 silhouette_score ( data , y_predict )
# 添加聚类结果列
df_train [ 'result' ] = y_predict df_train
8.数据可视化 核心思路:散点图显示聚类簇和特征变量关系
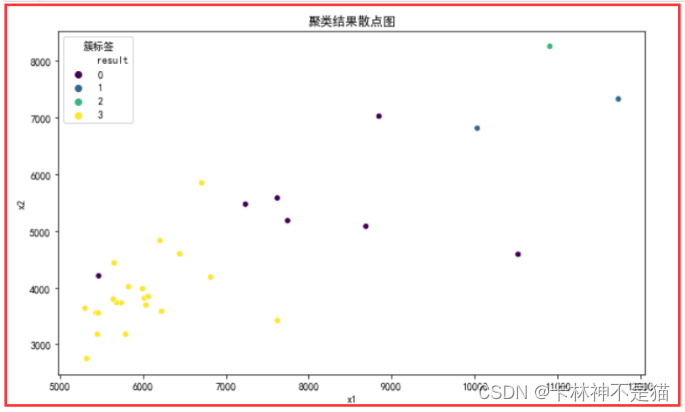
import matplotlib . pyplot as plt import seaborn as sns # x1 国有经济单位 # x2 集体经济单位 # x3 联营经济单位 # x4 股份制经济单位 # x5 外商投资经济单 # x6 港澳台经济单位 # x7 其他经济单位 feature1 = 'x1' # 请替换为实际的特征列名 feature2 = 'x2' # 请替换为实际的特征列名 # 绘制散点图 plt . figure ( figsize = ( 10 , 6 )) # 设置画布大小 sns . scatterplot ( x = df_train [ feature1 ], y = df_train [ feature2 ], hue = df_train [ 'result' ], palette = 'viridis' ) # 设置标题和坐标轴标签 plt . title ( '聚类结果散点图' ) plt . xlabel ( feature1 ) plt . ylabel ( feature2 ) # 显示图例 plt . legend ( title = '簇标签' ) # 显示图形 plt . show ()
“若有理解思路疏漏,感谢各位大佬批评指正!”