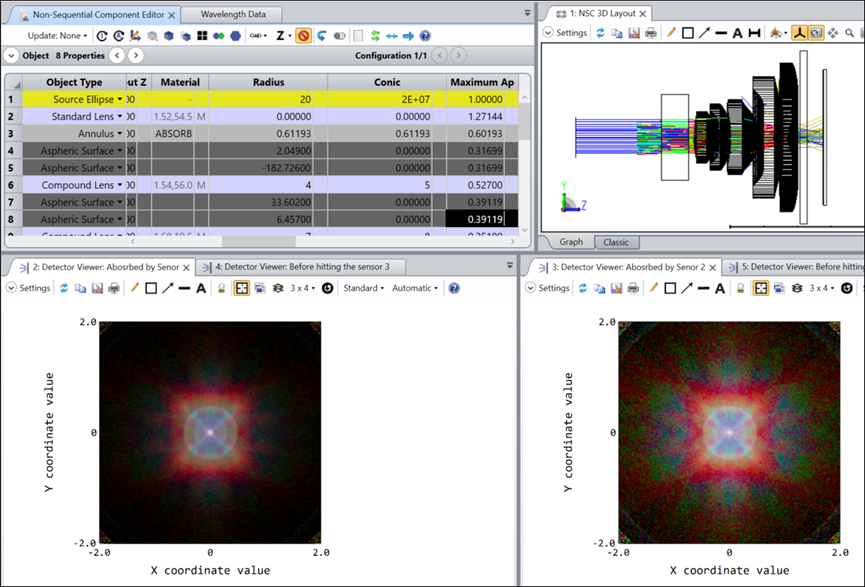
JPEG压缩是一种有损压缩技术,常用于数字图像。它通过减少图像文件大小来实现压缩,但会造成一定程度的图像质量损失。
目录
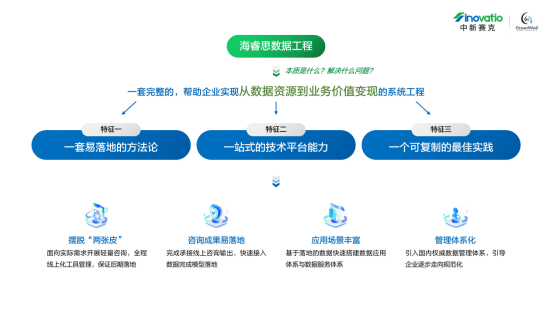
- 一、JPEG压缩
- 1.1 JPEG压缩原理
- 1.2 JPEG压缩优点
- 1.3 JPEG压缩缺点
- 二、图像退化中加入JPEG压缩
- 2.1 优势
- 2.1.1 更逼真的模拟
- 2.1.2 提高效率
- 2.1.3 简化模型
- 2.2 缺点
- 2.3 加入 JPEG 压缩模拟的具体示例
- 2.3.1 模拟镜头模糊
- 2.3.2 模拟大气散射
- 2.3.3 模拟压缩伪影
- 三、代码
- 3.1 cv2.imencode库和cv2.imdecode库
- 3.1.1 函数原型
- 3.1.2 示例代码
- 3.2 DiffJPEG压缩
- 3.2.1 参数修改
- 3.2.2 代码
- 四、压缩效果
- 五、总结
一、JPEG压缩
1.1 JPEG压缩原理
JPEG压缩的工作原理是利用人眼的视觉特性,对图像进行离散余弦变换和量化。简单来说,就是将图像分成一个个小的方块,然后分析每个方块的亮度和颜色信息。人眼对亮度变化更敏感,对颜色变化的敏感度较低,因此JPEG压缩会保留更多的亮度信息,而舍弃一些颜色信息。
JPEG压缩的压缩程度可以通过压缩率来控制。压缩率越高,图像文件越小,但图像质量也会越差。一般来说,压缩率在70%到80%之间是比较合适的,既能大幅减小文件大小,又能保持较好的图像质量。
1.2 JPEG压缩优点
可以大幅减小图像文件大小,节省存储空间和传输带宽。
压缩后的图像仍然保持较好的视觉质量。
广泛支持,几乎所有图像编辑软件和数码设备都支持JPEG格式。
1.3 JPEG压缩缺点
压缩过程会造成一定程度的图像质量损失,特别是高压缩率下更加明显。
不适用于需要保留原始图像信息的场景,例如医学图像、印刷图像等。
二、图像退化中加入JPEG压缩
2.1 优势
在模拟图像退化过程中加入JPEG压缩,好处见下:
2.1.1 更逼真的模拟
JPEG 压缩会引入块效应、伪影和瑕疵等痕迹,这些痕迹与现实世界中的图像退化现象(例如,镜头模糊、大气散射、压缩伪影等)相似。因此,在模拟图像退化过程中加入 JPEG 压缩可以使模拟结果更加逼真。
2.1.2 提高效率
JPEG 压缩可以显著减小图像文件大小。这在处理大量图像数据时尤其有益,因为它可以节省存储空间和计算资源。
2.1.3 简化模型
JPEG 压缩引入的块效应和伪影可以简化图像退化模型。例如,在模拟运动模糊时,可以先对图像进行 JPEG 压缩,然后再应用运动模糊模型。这样可以避免在运动模糊模型中显式地模拟 JPEG 压缩引起的块效应和伪影。
2.2 缺点
在模拟图像退化过程中加入 JPEG 压缩也有一些潜在的缺点:
可能引入额外的误差: JPEG 压缩本身会造成一定的图像质量损失。如果在模拟图像退化过程中加入 JPEG 压缩,可能会进一步降低图像质量。
可能使模型更难解释: JPEG 压缩引入的块效应和伪影会使图像退化模型更加复杂,从而更难理解和解释。
2.3 加入 JPEG 压缩模拟的具体示例
2.3.1 模拟镜头模糊
镜头模糊会导致图像出现一定的模糊和失真。为了模拟镜头模糊,可以先对图像进行 JPEG 压缩,然后再应用高斯滤波或其他模糊滤波器。
2.3.2 模拟大气散射
大气散射会导致图像出现一定的朦胧和色彩失真。为了模拟大气散射,可以先对图像进行 JPEG 压缩,然后再降低图像的对比度和饱和度。
2.3.3 模拟压缩伪影
除了 JPEG 压缩之外,还有其他类型的图像压缩,例如 PNG 和 GIF 压缩。这些压缩格式也会引入不同的伪影。为了模拟其他类型的压缩伪影,可以先对图像进行相应的压缩,然后再进行其他类型的退化模拟。
三、代码
3.1 cv2.imencode库和cv2.imdecode库
cv2.imencode() 和 cv2.imdecode() 都是 OpenCV 库中用于处理图像编码和解码的函数。
cv2.imencode() 用于将图像编码为特定格式的字节流。它通常用于将图像转换为 JPEG 或 PNG 格式并将其保存到内存中。
3.1.1 函数原型
cv2.imencode(ext, img, [params]) -> (retval, buf)
cv2.imencode()参数说明:
ext: 要使用的图像格式的后缀,例如 ‘jpg’ 或 ‘png’。
img: 要编码的图像。
params: 可选参数,用于控制编码过程。例如,对于 JPEG 格式,可以使用 params 参数来控制压缩质量。
cv2.imdecode(buf, flags) -> img
cv2.imdecode()参数说明:
buf: 要解码的字节流。
flags: 可选参数,用于指定图像的色彩空间。例如,cv2.IMREAD_COLOR 表示使用彩色模式解码图像,cv2.IMREAD_GRAYSCALE 表示使用灰度模式解码图像。
3.1.2 示例代码
import cv2
img_gt = cv2.imread('Images/Visible_Images/1.jpg')
encode_param = [int(cv2.IMWRITE_JPEG_QUALITY), 20] # 设置JPEG图像的质量参数为20,参数可以自定义调整
_, encimg = cv2.imencode('.jpg', img_gt, encode_param) # 以JPEG格式进行编码
img_lq = np.float32(cv2.imdecode(encimg, 1)) # 解码编码后的图像,并将其转换为浮点类型
cv2.imwrite('Result/DiffJpeg/CV_Result/cv2_JPEG_20.png', img_lq) # 将解码后的图像保存为’cv2_JPEG_20.png’
3.2 DiffJPEG压缩
DiffJPEG压缩是基于pythorch实现的,压缩图像与OpecnCV包压缩的图像略有不同。
3.2.1 参数修改
使用代码,只需要修改下面参数即可:

3.2.2 代码
import itertools
import numpy as np
import torch
import torch.nn as nn
from torch.nn import functional as F
# ------------------------ utils ------------------------#
y_table = np.array(
[[16, 11, 10, 16, 24, 40, 51, 61], [12, 12, 14, 19, 26, 58, 60, 55], [14, 13, 16, 24, 40, 57, 69, 56],
[14, 17, 22, 29, 51, 87, 80, 62], [18, 22, 37, 56, 68, 109, 103, 77], [24, 35, 55, 64, 81, 104, 113, 92],
[49, 64, 78, 87, 103, 121, 120, 101], [72, 92, 95, 98, 112, 100, 103, 99]],
dtype=np.float32).T
y_table = nn.Parameter(torch.from_numpy(y_table))
c_table = np.empty((8, 8), dtype=np.float32)
c_table.fill(99)
c_table[:4, :4] = np.array([[17, 18, 24, 47], [18, 21, 26, 66], [24, 26, 56, 99], [47, 66, 99, 99]]).T
c_table = nn.Parameter(torch.from_numpy(c_table))
def diff_round(x):
""" Differentiable rounding function
"""
return torch.round(x) + (x - torch.round(x))**3
def quality_to_factor(quality):
""" Calculate factor corresponding to quality
Args:
quality(float): Quality for jpeg compression.
Returns:
float: Compression factor.
"""
if quality < 50:
quality = 5000. / quality
else:
quality = 200. - quality * 2
return quality / 100.
# ------------------------ compression ------------------------#
class RGB2YCbCrJpeg(nn.Module):
""" Converts RGB image to YCbCr
"""
def __init__(self):
super(RGB2YCbCrJpeg, self).__init__()
matrix = np.array([[0.299, 0.587, 0.114], [-0.168736, -0.331264, 0.5], [0.5, -0.418688, -0.081312]],
dtype=np.float32).T
self.shift = nn.Parameter(torch.tensor([0., 128., 128.]))
self.matrix = nn.Parameter(torch.from_numpy(matrix))
def forward(self, image):
"""
Args:
image(Tensor): batch x 3 x height x width
Returns:
Tensor: batch x height x width x 3
"""
image = image.permute(0, 2, 3, 1)
result = torch.tensordot(image, self.matrix, dims=1) + self.shift
return result.view(image.shape)
class ChromaSubsampling(nn.Module):
""" Chroma subsampling on CbCr channels
"""
def __init__(self):
super(ChromaSubsampling, self).__init__()
def forward(self, image):
"""
Args:
image(tensor): batch x height x width x 3
Returns:
y(tensor): batch x height x width
cb(tensor): batch x height/2 x width/2
cr(tensor): batch x height/2 x width/2
"""
image_2 = image.permute(0, 3, 1, 2).clone()
cb = F.avg_pool2d(image_2[:, 1, :, :].unsqueeze(1), kernel_size=2, stride=(2, 2), count_include_pad=False)
cr = F.avg_pool2d(image_2[:, 2, :, :].unsqueeze(1), kernel_size=2, stride=(2, 2), count_include_pad=False)
cb = cb.permute(0, 2, 3, 1)
cr = cr.permute(0, 2, 3, 1)
return image[:, :, :, 0], cb.squeeze(3), cr.squeeze(3)
class BlockSplitting(nn.Module):
""" Splitting image into patches
"""
def __init__(self):
super(BlockSplitting, self).__init__()
self.k = 8
def forward(self, image):
"""
Args:
image(tensor): batch x height x width
Returns:
Tensor: batch x h*w/64 x h x w
"""
height, _ = image.shape[1:3]
batch_size = image.shape[0]
image_reshaped = image.view(batch_size, height // self.k, self.k, -1, self.k)
image_transposed = image_reshaped.permute(0, 1, 3, 2, 4)
return image_transposed.contiguous().view(batch_size, -1, self.k, self.k)
class DCT8x8(nn.Module):
""" Discrete Cosine Transformation
"""
def __init__(self):
super(DCT8x8, self).__init__()
tensor = np.zeros((8, 8, 8, 8), dtype=np.float32)
for x, y, u, v in itertools.product(range(8), repeat=4):
tensor[x, y, u, v] = np.cos((2 * x + 1) * u * np.pi / 16) * np.cos((2 * y + 1) * v * np.pi / 16)
alpha = np.array([1. / np.sqrt(2)] + [1] * 7)
self.tensor = nn.Parameter(torch.from_numpy(tensor).float())
self.scale = nn.Parameter(torch.from_numpy(np.outer(alpha, alpha) * 0.25).float())
def forward(self, image):
"""
Args:
image(tensor): batch x height x width
Returns:
Tensor: batch x height x width
"""
image = image - 128
result = self.scale * torch.tensordot(image, self.tensor, dims=2)
result.view(image.shape)
return result
class YQuantize(nn.Module):
""" JPEG Quantization for Y channel
Args:
rounding(function): rounding function to use
"""
def __init__(self, rounding):
super(YQuantize, self).__init__()
self.rounding = rounding
self.y_table = y_table
def forward(self, image, factor=1):
"""
Args:
image(tensor): batch x height x width
Returns:
Tensor: batch x height x width
"""
if isinstance(factor, (int, float)):
image = image.float() / (self.y_table * factor)
else:
b = factor.size(0)
table = self.y_table.expand(b, 1, 8, 8) * factor.view(b, 1, 1, 1)
image = image.float() / table
image = self.rounding(image)
return image
class CQuantize(nn.Module):
""" JPEG Quantization for CbCr channels
Args:
rounding(function): rounding function to use
"""
def __init__(self, rounding):
super(CQuantize, self).__init__()
self.rounding = rounding
self.c_table = c_table
def forward(self, image, factor=1):
"""
Args:
image(tensor): batch x height x width
Returns:
Tensor: batch x height x width
"""
if isinstance(factor, (int, float)):
image = image.float() / (self.c_table * factor)
else:
b = factor.size(0)
table = self.c_table.expand(b, 1, 8, 8) * factor.view(b, 1, 1, 1)
image = image.float() / table
image = self.rounding(image)
return image
class CompressJpeg(nn.Module):
"""Full JPEG compression algorithm
Args:
rounding(function): rounding function to use
"""
def __init__(self, rounding=torch.round):
super(CompressJpeg, self).__init__()
self.l1 = nn.Sequential(RGB2YCbCrJpeg(), ChromaSubsampling())
self.l2 = nn.Sequential(BlockSplitting(), DCT8x8())
self.c_quantize = CQuantize(rounding=rounding)
self.y_quantize = YQuantize(rounding=rounding)
def forward(self, image, factor=1):
"""
Args:
image(tensor): batch x 3 x height x width
Returns:
dict(tensor): Compressed tensor with batch x h*w/64 x 8 x 8.
"""
y, cb, cr = self.l1(image * 255)
components = {'y': y, 'cb': cb, 'cr': cr}
for k in components.keys():
comp = self.l2(components[k])
if k in ('cb', 'cr'):
comp = self.c_quantize(comp, factor=factor)
else:
comp = self.y_quantize(comp, factor=factor)
components[k] = comp
return components['y'], components['cb'], components['cr']
# ------------------------ decompression ------------------------#
class YDequantize(nn.Module):
"""Dequantize Y channel
"""
def __init__(self):
super(YDequantize, self).__init__()
self.y_table = y_table
def forward(self, image, factor=1):
"""
Args:
image(tensor): batch x height x width
Returns:
Tensor: batch x height x width
"""
if isinstance(factor, (int, float)):
out = image * (self.y_table * factor)
else:
b = factor.size(0)
table = self.y_table.expand(b, 1, 8, 8) * factor.view(b, 1, 1, 1)
out = image * table
return out
class CDequantize(nn.Module):
"""Dequantize CbCr channel
"""
def __init__(self):
super(CDequantize, self).__init__()
self.c_table = c_table
def forward(self, image, factor=1):
"""
Args:
image(tensor): batch x height x width
Returns:
Tensor: batch x height x width
"""
if isinstance(factor, (int, float)):
out = image * (self.c_table * factor)
else:
b = factor.size(0)
table = self.c_table.expand(b, 1, 8, 8) * factor.view(b, 1, 1, 1)
out = image * table
return out
class iDCT8x8(nn.Module):
"""Inverse discrete Cosine Transformation
"""
def __init__(self):
super(iDCT8x8, self).__init__()
alpha = np.array([1. / np.sqrt(2)] + [1] * 7)
self.alpha = nn.Parameter(torch.from_numpy(np.outer(alpha, alpha)).float())
tensor = np.zeros((8, 8, 8, 8), dtype=np.float32)
for x, y, u, v in itertools.product(range(8), repeat=4):
tensor[x, y, u, v] = np.cos((2 * u + 1) * x * np.pi / 16) * np.cos((2 * v + 1) * y * np.pi / 16)
self.tensor = nn.Parameter(torch.from_numpy(tensor).float())
def forward(self, image):
"""
Args:
image(tensor): batch x height x width
Returns:
Tensor: batch x height x width
"""
image = image * self.alpha
result = 0.25 * torch.tensordot(image, self.tensor, dims=2) + 128
result.view(image.shape)
return result
class BlockMerging(nn.Module):
"""Merge patches into image
"""
def __init__(self):
super(BlockMerging, self).__init__()
def forward(self, patches, height, width):
"""
Args:
patches(tensor) batch x height*width/64, height x width
height(int)
width(int)
Returns:
Tensor: batch x height x width
"""
k = 8
batch_size = patches.shape[0]
image_reshaped = patches.view(batch_size, height // k, width // k, k, k)
image_transposed = image_reshaped.permute(0, 1, 3, 2, 4)
return image_transposed.contiguous().view(batch_size, height, width)
class ChromaUpsampling(nn.Module):
"""Upsample chroma layers
"""
def __init__(self):
super(ChromaUpsampling, self).__init__()
def forward(self, y, cb, cr):
"""
Args:
y(tensor): y channel image
cb(tensor): cb channel
cr(tensor): cr channel
Returns:
Tensor: batch x height x width x 3
"""
def repeat(x, k=2):
height, width = x.shape[1:3]
x = x.unsqueeze(-1)
x = x.repeat(1, 1, k, k)
x = x.view(-1, height * k, width * k)
return x
cb = repeat(cb)
cr = repeat(cr)
return torch.cat([y.unsqueeze(3), cb.unsqueeze(3), cr.unsqueeze(3)], dim=3)
class YCbCr2RGBJpeg(nn.Module):
"""Converts YCbCr image to RGB JPEG
"""
def __init__(self):
super(YCbCr2RGBJpeg, self).__init__()
matrix = np.array([[1., 0., 1.402], [1, -0.344136, -0.714136], [1, 1.772, 0]], dtype=np.float32).T
self.shift = nn.Parameter(torch.tensor([0, -128., -128.]))
self.matrix = nn.Parameter(torch.from_numpy(matrix))
def forward(self, image):
"""
Args:
image(tensor): batch x height x width x 3
Returns:
Tensor: batch x 3 x height x width
"""
result = torch.tensordot(image + self.shift, self.matrix, dims=1)
return result.view(image.shape).permute(0, 3, 1, 2)
class DeCompressJpeg(nn.Module):
"""Full JPEG decompression algorithm
Args:
rounding(function): rounding function to use
"""
def __init__(self, rounding=torch.round):
super(DeCompressJpeg, self).__init__()
self.c_dequantize = CDequantize()
self.y_dequantize = YDequantize()
self.idct = iDCT8x8()
self.merging = BlockMerging()
self.chroma = ChromaUpsampling()
self.colors = YCbCr2RGBJpeg()
def forward(self, y, cb, cr, imgh, imgw, factor=1):
"""
Args:
compressed(dict(tensor)): batch x h*w/64 x 8 x 8
imgh(int)
imgw(int)
factor(float)
Returns:
Tensor: batch x 3 x height x width
"""
components = {'y': y, 'cb': cb, 'cr': cr}
for k in components.keys():
if k in ('cb', 'cr'):
comp = self.c_dequantize(components[k], factor=factor)
height, width = int(imgh / 2), int(imgw / 2)
else:
comp = self.y_dequantize(components[k], factor=factor)
height, width = imgh, imgw
comp = self.idct(comp)
components[k] = self.merging(comp, height, width)
#
image = self.chroma(components['y'], components['cb'], components['cr'])
image = self.colors(image)
image = torch.min(255 * torch.ones_like(image), torch.max(torch.zeros_like(image), image))
return image / 255
# ------------------------ main DiffJPEG ------------------------ #
class DiffJPEG(nn.Module):
"""This JPEG algorithm result is slightly different from cv2.
DiffJPEG supports batch processing.
Args:
differentiable(bool): If True, uses custom differentiable rounding function, if False, uses standard torch.round
"""
def __init__(self, differentiable=True):
super(DiffJPEG, self).__init__()
if differentiable:
rounding = diff_round
else:
rounding = torch.round
self.compress = CompressJpeg(rounding=rounding)
self.decompress = DeCompressJpeg(rounding=rounding)
def forward(self, x, quality):
"""
Args:
x (Tensor): Input image, bchw, rgb, [0, 1]
quality(float): Quality factor for jpeg compression scheme.
"""
factor = quality
if isinstance(factor, (int, float)):
factor = quality_to_factor(factor)
else:
for i in range(factor.size(0)):
factor[i] = quality_to_factor(factor[i])
h, w = x.size()[-2:]
h_pad, w_pad = 0, 0
# why should use 16
if h % 16 != 0:
h_pad = 16 - h % 16
if w % 16 != 0:
w_pad = 16 - w % 16
x = F.pad(x, (0, w_pad, 0, h_pad), mode='constant', value=0)
y, cb, cr = self.compress(x, factor=factor)
recovered = self.decompress(y, cb, cr, (h + h_pad), (w + w_pad), factor=factor)
recovered = recovered[:, :, 0:h, 0:w]
return recovered
if __name__ == '__main__':
import cv2
from basicsr.utils import img2tensor, tensor2img # 从basicsr.utils模块导入img2tensor和tensor2img函数,这两个函数分别用于将图像转换为张量和将张量转换为图像。
img_gt = cv2.imread('Images/Visible_Images/1.jpg') / 255. # 读取名为’test.png’的图像文件,并将其像素值归一化到0-1之间
# -------------- DiffJPEG -------------- #
jpeger = DiffJPEG(differentiable=False).cuda() # 创建一个DiffJPEG对象,这是一个用于JPEG编码和解码的类,differentiable=False表示该对象不可微分
img_gt = img2tensor(img_gt) # 将图像转换为张量
img_gt = torch.stack([img_gt, img_gt]).cuda() # 创建一个新的张量,该张量由两个img_gt张量堆叠而成,并将其移动到GPU上。
quality = img_gt.new_tensor([10,90]) # 创建一个新的张量,该张量包含两个元素20和40,这两个元素表示JPEG图像的质量参数。
out = jpeger(img_gt, quality=quality) # 使用jpeger对象对图像进行JPEG编码
cv2.imwrite('Result/DiffJpeg/DiffJpeg_Result/pt_JPEG_10.png', tensor2img(out[0]))
cv2.imwrite('Result/DiffJpeg/DiffJpeg_Result/pt_JPEG_90.png', tensor2img(out[1]))
四、压缩效果



五、总结
以上就是图像JPEG压缩的两种方法,OpenCV包中的压缩方法使用不同的软件包生成的结果有差异。学者自行调整质量参数尝试。
总结不易,多多支持,谢谢!
感谢您阅读到最后!关注公众号「视觉研坊」,获取干货教程、实战案例、技术解答、行业资讯!