🌈个人主页:小新_-
🎈个人座右铭:“成功者不是从不失败的人,而是从不放弃的人!”🎈
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
🏆所属专栏: 数据结构与算法欢迎订阅,持续更新中~~~

✨让小新带着你快乐的学习吧~✨

目录
1. 链表的概念及结构
2、单链表的实现
准备工作
1、单链表的插入
1)头插
2)尾插
3)指定位置前插
4)指定位置后插
2、单链表的删除
1)头删
2)尾删
3)删除指定位置节点
4)删除指定位置之后节点
3、单链表的查找
4、单链表的销毁
3、链表的分类
4、 链表经典算法OJ题⽬
3.1 单链表相关经典算法OJ题1:移除链表元素(点击进入题目)
3.2 单链表相关经典算法OJ题2:反转链表(点击进入题目)
3.3 单链表相关经典算法OJ题3:合并两个有序链表(点击进入题目)
3.4 单链表相关经典算法OJ题4:链表的中间结点(点击进入题目)
3.5 循环链表经典应⽤-环形链表的约瑟夫问题(点击进入题目)
3.6 单链表相关经典算法OJ题5:分割链表(点击进入题目)
1. 链表的概念及结构


struct SListNode
{
int data; //节点数据
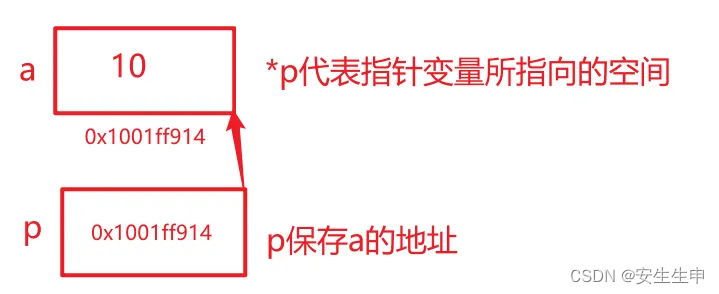
struct SListNode* next; //指针变量⽤保存下⼀个节点的地址
};
2、单链表的实现
准备工作
单链表实现前,有几个小段代码和问题
1、首先,我们来搞懂一个一个概念上的问题,就是节点的实参形参问题,其实就是考验对指针的理解与掌握

2、申请新的节点
代码比较简单,用malloc函数申请新节点的空间,让新节点的的data域置为x,next域为空
SLTNode* SLNewNode(SLDataType x)
{
SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));
newnode->Data = x;
newnode->next = NULL;
return newnode;
}3、打印当前链表

上代码
void SLPrint(SLTNode* phead)
{
SLTNode* pcur = phead;
while (pcur)
{
printf("%d->", pcur->Data);
pcur = pcur->next;
}
printf("NULL");
}4、单链表的声明
typedef int SLDataType;
typedef struct SListNode
{
SLDataType Data;
struct SListNode* next;
}SLTNode;1、单链表的插入
1)头插
分析:

尾删思路比较简单,我们有头结点的指针phead,我们让我们新申请的节点的next指针,指向原来的头结点,就完成了,我们考虑一下特殊情况,如果链表为空,怎么办?那还不简单,直接成为新的节点,代码就跟不是空表一样,so easy!小小头插,拿下拿下。
void SLPushFront(SLTNode** pphead, SLDataType x)
{
assert(pphead);
SLTNode* newnode = SLNewNode(x);
newnode->next = *pphead;
*pphead = newnode;
}2)尾插
分析:

如图,我们想插入一个元素4,如何插入呢?首先,我们得找到原尾节点吧。然后让原尾节点的next指针指向4这个新节点,这样我们的4就成为了尾节点,再让4的next指针指向NULL。但有一个问题,那就是如果链表为空怎么办?那就没有尾节点了。直接将这个节点作为我们的新节点。所以,大体思路就是,先判断链表是否为空,如果是就直接作为新的节点,如果不是,我们就先找到尾节点,然后执行插入操作就可以了。
代码如下:
void SLPushBack(SLTNode** pphead, SLDataType x)
{
assert(pphead);
SLTNode* newnode = SLNewNode(x);
//链表为空,作为结点
if (*pphead == NULL)
{
*pphead = newnode;
return;
}
//链表不为空,寻找尾节点
SLTNode* ptail = *pphead;//寻找尾节点
while (ptail->next)
{
ptail = ptail->next;
}
//ptail就是尾节点
ptail = newnode;
}3)指定位置前插
分析:

我们看到,要想在pos(3)之前插入,我们就要找到pos之前的节点prev,prev的next指向newnode,newnode的next指向pos。考虑特殊情况,当pos是头结点时,就没有prev,怎么办呢?我们可以直接调用头插即可。
代码如下:
void SLTInsert(SLTNode** pphead, SLTNode* pos, SLDataType x)
{
assert(pphead);
assert(pos);
assert(*pphead);
SLTNode* newnode= SLNewNode(x);
//如果pos是头结点
if (pos == *pphead)
{
SLPushFront(newnode, x);
return;
}
SLTNode* prev = *pphead;
while (prev->next != pos)
{
prev = prev->next;
}
prev->next = newnode;
newnode->next = pos;
}4)指定位置后插
分析:

指定位置后插比指定位置前插较为简单,但要注意的是顺序,如果先把pos的next给newnode,newnode中的next保存的是pos的下一个节点地址,然后再将newnode的next指向下一节点,这样导致pos的next不再指向真正的下一节点。而应该先把pos的next赋值给newnode的next,再将pos的next指向newnode.
代码如下:
2、单链表的删除
1)头删
分析:

头删比较简单,将原来的第二个节点作为新链表的第一个节点,并将原来第一个节点释放掉,并将next赋给pphead
代码如下:
void SLPopFront(SLTNode** pphead)//头删
{
assert(pphead);//链表不为空
assert(*pphead);//->指向第一个节点的地址
SLTNode* next = (*pphead)->next;
free(*pphead);
(*pphead) = next;
}2)尾删
分析:

既然要进行删除操作,那么链表至少得有一个节点吧,所以得提前判断一下。要进行尾删,首先,我们要找到尾节点的前一个节点,我们就叫他prev吧,让prv不再指向尾节点的next域,而是NULL,然后将尾节点用free函数将尾节点的内存还给操作系统。但只有一个节点的时候呢?我们只能将该节点释放掉咯(没办法的事,无奈)
void SLPopBack(SLTNode** pphead)
{
assert(pphead);//链表不为空
assert(*pphead);//->指向第一个节点的地址
while ((*pphead)->next==NULL)//如果只有一个节点
{
free(*pphead);
*pphead = NULL;
return;
}
//具有多个节点
SLTNode* ptail = *pphead;
SLTNode* prev = NULL;
while (ptail->next)
{
prev = ptail;
ptail=ptail->next;
}//找到prev了
prev->next = NULL;
free(ptail);
ptail=NULL//别忘了置空,以免疯狗乱咬人(狗头 狗头)
}3)删除指定位置节点
分析:

删除指定位置的节点,我们定义一个指针prev,让prev找到pos之前的节点(寻找prev的循环条件:prev->next !=pos),此时,将prev的next指针指向pos的下一个节点,再将pos释放掉。注意,顺序不能颠倒!!!需要注意的是特殊情况,当pos就是头结点。此时没有prev,我们可以直接执行头删操作。
代码如下:
void SLErase(SLTNode** pphead, SLTNode* pos)
{
assert(pphead);
assert(*pphead);
assert(pos);
if (pos == *pphead)
{
SLPopFront(pphead);
return;
}
SLTNode* prev = *pphead;
while (prev->next != pos)
{
prev = prev->next;
}
(prev->next) = (pos->next);
free(pos);
pos = NULL;
}4)删除指定位置之后节点
分析:
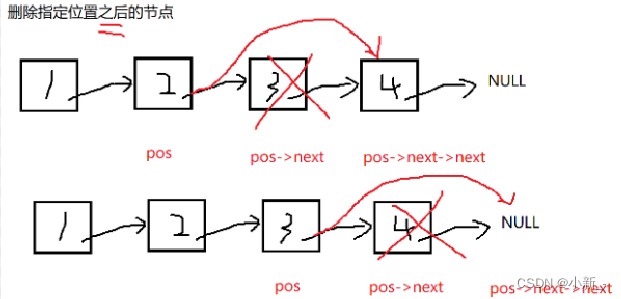
思路比较清晰,看图一目了然,将pos的next指针指向pos下一个节点的下一个节点
代码如下:
void SLEraseAfter(SLTNode* pos)
{
assert(pos);
assert(pos->next);
pos->next = pos->next->next;
free(pos->next);
pos->next = NULL;
}3、单链表的查找
没什么好说的,上代码
SLTNode* SLTFind(SLTNode** pphead, SLDataType x)
{
assert(pphead);
//遍历链表
SLTNode* pcur = *pphead;
while (pcur) //等价于pcur != NULL
{
if (pcur->Data == x) {
return pcur;
}
pcur = pcur->next;
}
//没有找到
return NULL;
}4、单链表的销毁
上代码
void SListDesTroy(SLTNode** pphead)
{
assert(pphead);
assert(*pphead);
SLTNode* pcur = *pphead;
while (pcur)
{
SLTNode* next = pcur->next;
free(pcur);
pcur = next;
}
*pphead = NULL;
}完整代码如下
sqlist.c
#define _CRT_SECURE_NO_WARNINGS 1
#define _CRT_SECURE_NO_WARNINGS 1
#include"SList.h"
void SLPrint(SLTNode* phead)
{
SLTNode* pcur = phead;
while (pcur)
{
printf("%d->", pcur->Data);
pcur = pcur->next;
}
printf("NULL\n");
}
SLTNode* SLNewNode(SLDataType x)
{
SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));
newnode->Data = x;
newnode->next = NULL;
return newnode;
}
void SLPushBack(SLTNode** pphead, SLDataType x)
{
assert(pphead);
SLTNode* newnode = SLNewNode(x);
//链表为空,作为结点
if (*pphead == NULL)
{
*pphead = newnode;
return;
}
//链表不为空,寻找尾节点
SLTNode* ptail = *pphead;
while (ptail->next)
{
ptail = ptail->next;
}
//ptail就是尾节点
ptail = newnode;
}
void SLPushFront(SLTNode** pphead, SLDataType x)
{
assert(pphead);
SLTNode* newnode = SLNewNode(x);
newnode->next = *pphead;
*pphead = newnode;
}
void SLPopBack(SLTNode** pphead)
{
assert(pphead);//链表不为空
assert(*pphead);//->指向第一个节点的地址
while ((*pphead)->next==NULL)//如果只有一个节点
{
free(*pphead);
*pphead = NULL;
return;
}
//具有多个节点
SLTNode* ptail = *pphead;
SLTNode* prev = NULL;
while (ptail->next)
{
prev = ptail;
ptail=ptail->next;
}//找到prev了
prev->next = NULL;
free(ptail);
}
void SLPopFront(SLTNode** pphead)//头删
{
assert(pphead);//链表不为空
assert(*pphead);//->指向第一个节点的地址
SLTNode* next = (*pphead)->next;
free(*pphead);
(*pphead) = next;
}
//在指定位置之前插入数据
void SLTInsert(SLTNode** pphead, SLTNode* pos, SLDataType x)
{
assert(pphead);
assert(pos);
assert(*pphead);
SLTNode* newnode= SLNewNode(x);
//如果pos是头结点
if (pos == *pphead)
{
SLPushFront(newnode, x);
return;
}
SLTNode* prev = *pphead;
while (prev->next != pos)
{
prev = prev->next;
}
prev->next = newnode;
newnode->next = pos;
}
//在指定位置之后插入数据
void SLInsertAfter(SLTNode* pos, SLDataType x)
{
assert(pos);
SLTNode* newnode = SLNewNode(x);
newnode->next = pos->next;
pos->next = newnode;
}
//删除pos节点
void SLErase(SLTNode** pphead, SLTNode* pos)
{
assert(pphead);
assert(*pphead);
assert(pos);
if (pos == *pphead)
{
SLPopFront(pphead);
return;
}
SLTNode* prev = *pphead;
while (prev->next != pos)
{
prev = prev->next;
}
(prev->next) = (pos->next);
free(pos);
pos = NULL;
}
//删除pos之后的节点
void SLEraseAfter(SLTNode* pos)
{
assert(pos);
assert(pos->next);
pos->next = pos->next->next;
free(pos->next);
pos->next = NULL;
}
SLTNode* SLTFind(SLTNode** pphead, SLDataType x)
{
assert(pphead);
//遍历链表
SLTNode* pcur = *pphead;
while (pcur) //等价于pcur != NULL
{
if (pcur->Data == x) {
return pcur;
}
pcur = pcur->next;
}
//没有找到
return NULL;
}
//销毁链表
void SListDesTroy(SLTNode** pphead)
{
assert(pphead);
assert(*pphead);
SLTNode* pcur = *pphead;
while (pcur)
{
SLTNode* next = pcur->next;
free(pcur);
pcur = next;
}
*pphead = NULL;
}slist.h
#pragma once
#define _CRT_SECURE_NO_WARNINGS 1
#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
typedef int SLDataType;
typedef struct SListNode
{
SLDataType Data;
struct SListNode* next;
}SLTNode;
void SLPrint(SLTNode* phead);
SLTNode* SLNewNode(SLDataType x);
void SLPushBack(SLTNode** phead, SLDataType x);
void SLPushFront(SLTNode** phead, SLDataType x);
void SLPopBack(SLTNode** pphead);
void SLPopFront(SLTNode** pphead);
SLTNode* SLFind(SLTNode** pphead, SLDataType x);
//在指定位置之前插入数据
void SLTInsert(SLTNode** pphead, SLTNode* pos, SLDataType x);
//在指定位置之后插入数据
void SLTInsertAfter(SLTNode* pos, SLDataType x);
//删除pos节点
void SLTErase(SLTNode** pphead, SLTNode* pos);
//删除pos之后的节点
void SLTEraseAfter(SLTNode* pos);
//销毁链表
void SListDesTroy(SLTNode** pphead);测试文件这里就不包含了,读者朋友可以自己写代码的时候测试
3、链表的分类

如下:



4、 链表经典算法OJ题⽬
3.1 单链表相关经典算法OJ题1:移除链表元素(点击进入题目)


typedef struct ListNode ListNode;
struct ListNode* removeElements(struct ListNode* head, int val) {
//定义新链表的头尾巴指针
ListNode* newHead,*newTail;
newHead=newTail=NULL;
ListNode* pcur=head;
while(pcur) {
if(pcur->val !=val)//节点值不为val,插入链表尾部
{
if(newHead=NULL)//链表为空
{
newHead=newTail=pcur;
}
else//链表不为空,插入尾部
{
newTail->next=pcur;
newTail=newTail->next;
}
}
//等于val,直接下一个节点
pcur=pcur->next;
}
if(newTail){
newTail->next=NULL;
}
return newTail;
}3.2 单链表相关经典算法OJ题2:反转链表(点击进入题目)

思路一:创建一个新链表,遍历原链表,将原链表元素依次头插在新链表当中。
思路二:定义三个指针变量,分别指向,当前节点,前驱和后继节点,改变节点指向即可。
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
typedef struct ListNode ListNode;
struct ListNode* reverseList(struct ListNode* head) {
if(head==NULL){
return head;
}
ListNode* n1,*n2,*n3;
n1=NULL,n2=head,n3=head->next;
ListNode* pcur;
while(n2){
n2->next=n1;
n1=n2;
n2=n3;
if(n3){
n3=n3->next;
}
}
return n1;
}3.3 单链表相关经典算法OJ题3:合并两个有序链表(点击进入题目)

/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/typedef struct ListNode ListNode;
struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2) {
if(list1==NULL){
return list2;
}
if(list2==NULL){
return list1;
}
ListNode* l1,*l2;
l1=list1,l2=list2;
ListNode* newHead,*newTail;
newHead=newTail=(ListNode*)malloc(sizeof(ListNode));
while(l1&&l2){
if(l1->val<l2->val){
newTail->next=l1;
newTail=newTail->next;
l1=l1->next;
}
else{
newTail->next=l2;
newTail=newTail->next;
l2=l2->next;
}
}
if(l1){
newTail->next=l1;
}
if(l2){
newTail->next=l2;
}
ListNode*ret =newHead->next;
free(newHead);
newHead=NULL;
return ret;
}3.4 单链表相关经典算法OJ题4:链表的中间结点(点击进入题目)

/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
typedef struct ListNode ListNode;
struct ListNode* middleNode(struct ListNode* head) {
ListNode* fast,*slow;
fast=slow=head;
while(fast&&fast->next){
fast=fast->next->next;
slow=slow->next;
}
return slow;
}3.5 循环链表经典应⽤-环形链表的约瑟夫问题(点击进入题目)

/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
typedef struct ListNode ListNode;
struct ListNode* partition(struct ListNode* head, int x){
if(head==NULL){
return head;
}
ListNode* newHeadLess,*newTailLess,*newHeadGreagter,*newTailGreagter;
newHeadLess=newTailLess=(ListNode*)malloc(sizeof(ListNode));
newHeadGreagter=newTailGreagter=(ListNode*)malloc(sizeof(ListNode));
ListNode* pcur=head;
while(pcur){
if(pcur->val<x){
newTailLess->next=pcur;
newTailLess=newTailLess->next;
}else{
newTailGreagter->next=pcur;
newTailGreagter=newTailGreagter->next;
}
pcur=pcur->next;
}
newTailGreagter->next=NULL;
newTailLess->next=newHeadGreagter->next;
ListNode*ret=newHeadLess->next;
free(newHeadGreagter);
free(newHeadLess);
return ret;
}
3.6 单链表相关经典算法OJ题5:分割链表(点击进入题目)

思路:建立大小链表,大于x放大链表,小于x放小链表,最后连接起来
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
typedef struct ListNode ListNode;
struct ListNode* partition(struct ListNode* head, int x){
if(head==NULL){
return head;
}
ListNode* newHeadLess,*newTailLess,*newHeadGreagter,*newTailGreagter;
newHeadLess=newTailLess=(ListNode*)malloc(sizeof(ListNode));
newHeadGreagter=newTailGreagter=(ListNode*)malloc(sizeof(ListNode));
ListNode* pcur=head;
while(pcur){
if(pcur->val<x){
newTailLess->next=pcur;
newTailLess=newTailLess->next;
}else{
newTailGreagter->next=pcur;
newTailGreagter=newTailGreagter->next;
}
pcur=pcur->next;
}
newTailGreagter->next=NULL;
newTailLess->next=newHeadGreagter->next;
ListNode*ret=newHeadLess->next;
free(newHeadGreagter);
free(newHeadLess);
return ret;
}

最后,感谢大家的观看~~