一、算法+数据结构=程序
提出这一公式并以此作为其一本专著的书名的瑞士计算机科学家尼克劳斯·沃思(Niklaus Wirth)由于发明了多种影响深远的程序设计语言,并提出结构化程序设计这一革命性概念而获得了1984年的图灵奖。他是至今惟一获此殊荣的瑞士学者。
顺便在这里说一下什么是图灵奖。图灵奖(Turing Award),全称A.M.图灵奖(ACM A.M Turing Award),是由美国计算机协会(ACM)于1966年设立的计算机奖项,名称取自艾伦·麦席森·图灵(Alan M. Turing),旨在奖励对计算机事业作出重要贡献的个人 。图灵奖对获奖条件要求极高,评奖程序极严,一般每年仅授予一名计算机科学家。图灵奖是计算机领域的国际最高奖项,被誉为“计算机界的诺贝尔奖”。2000年,中国科学家姚期智获图灵奖,这是中国人第一次也是唯一一次获得图灵奖。
1971年,沃思基于其开发程序设计语言和编程的实践经验,在4月份的 Communications of ACM上发表了论文“通过逐步求精方式开发程序’(Program Development by Stepwise Refinement),首次提出了“结构化程序设计”(structure programming)的概念。这个概念的要点是:不要求一步就编制成可执行的程序,而是分若干步进行,逐步求精。第一步编出的程序抽象度最高,第二步编出的程序抽象度有所降低…… 最后一步编出的程序即为可执行的程序。用这种方法编程,似乎复杂,实际上优点很多,可使程序易读、易写、易调试、易维护、易保证其正确性及验证其正确性。结构化程序设计方法又称为“自顶向下”或“逐步求精”法,在程序设计领域引发了一场革命,成为程序开发的一个标准方法,尤其是在后来发展起来的软件工程中获得广泛应用。有人评价说沃思的结构化程序设计概念“完全改变了人们对程序设计的思维方式”,这是一点也不夸张的。1983年1月,ACM在纪念 Communications of ACM创刊 25周年时,从其 1/4个世纪发表的大量论文中评选出有“里程碑意义的研究论文” 25篇,每年1篇,沃思的这篇论文就是其中之一。
早期的程序员喜欢滥用goto语句,也就是从代码一个地方跳转到另一个地方,goto语句虽然方便,但用的多了就无法理清头绪。Goto 语句在社区的讨论中经常被人诟病,认为其破坏了结构化编程和程序的抽象,是有害的,可怕的,是一种糟粕。最早的观点来源于 1968 年,Edsger Dijkstra 写了一封信《Go To Statement Considered Harmful》,来表达其是有害的观念。

Goto 的危害所带来的一个经典名称是:Spaghetti code(意大利面条代码),指的是对非结构化和难以维护的源代码的贬义词。这样的代码具有复杂而纠结的控制结构,导致程序流程在概念上就像一碗意大利面,扭曲和纠结。

饿了,想吃,哈哈~当然,造成早期代码凌乱不堪的不只有goto这一个祸害,还有很多因素,比如早期的程序员缺乏工程意识,在对代码的设计之初就存在问题等。所以结构化的程序思想彻底的改变了人们写代码的方式。我们将要从算法+数据结构=程序这个角度认识结构化代码。
二、什么是算法
算法(Algorithm)是指解题方案的准确而完整的描述,是一系列解决问题的清晰指令,算法代表着用系统的方法描述解决问题的策略机制。也就是说,能够对一定规范的输入,在有限时间内获得所要求的输出。如果一个算法有缺陷,或不适合于某个问题,执行这个算法将不会解决这个问题。不同的算法可能用不同的时间,空间或效率来完成同样的任务。一个算法的优劣可以用空间复杂度与时间复杂度来衡量。
算法中的指令描述的是一个计算,当其运行时能从一个初始状态和(可能为空的)初始输入开始,经过一系列有限而清晰定义的状态,最终产生输出并停止于一个终态。一个状态到另一个状态的转移不一定是确定的。随机化算法在内的一些算法,包含了一些随机输入。
算法具有以下五个特性:
1、有穷性,算法必须能在执行有限个步骤之后终止;
2、确切性,算法的每一步骤必须有确切的定义;
3、输入项,一个算法有0个或多个输入;
4、输出项,一个算法有一个或多个输出;
5、可行性,每个计算步骤都可以在有限时间内完成。
算法一般用伪代码表示,伪代码指的是不依赖于任何一种编程语言的,只是用来表示计算过程的代码,伪代码没有明确的标准,你可以用任何自己能理解的方式写伪代码,甚至用中文都没问题。
伪代码通常包含程序开始、变量、指令、表达式、计算与赋值、条件判断、循环、程序结束等基本内容。
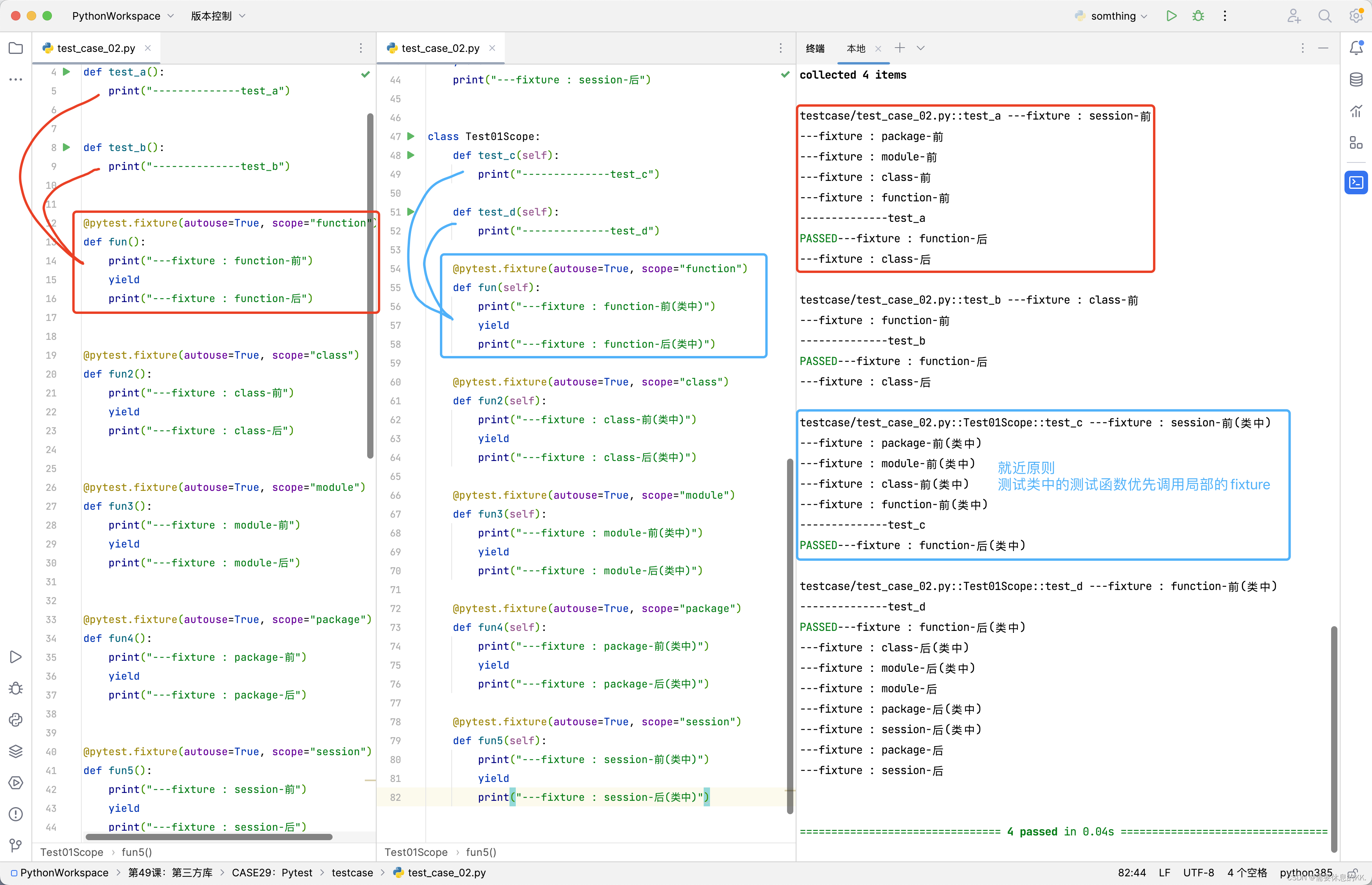
我们来看一个例子:输入3个数,打印输出其中最大的数。
| Plain TextBegin(算法开始)输入 A,B,CIF A>B 则 A→Max否则 B→MaxIF C>Max 则 C→MaxPrint MaxEnd (算法结束) |
|---|
是不是很简单很明了啊。
衡量一个算法的好坏有两个标准,一个是它所用的时间,一个是它所用的空间。时间复杂度和空间复杂度都依赖于输入的规模,正常来说,输入规模越大,所需时间和空间自然会更多。我们考虑当输入规模趋于无穷时的状态,来比较不同算法的优劣。
时间当然不能直接测量,同一个算法在不同计算机上运行都有可能会有很大的差异。我们以算法中最常用的操作次数来作为衡量的标准,比如下面的伪代码(这段代码并不解决什么实际问题,只是写着玩)中,很显然out次数是最多的,比if判断中的要多,for循环都是从0开始,到a - 1结束,所以out要被执行a^3 + a ^2 + a + 5次,在算法的时间复杂度计算中,我们取式子中最高的,就是a^3,因为当a无穷大的时候,a^3肯定要比a^2和a以及常数5增长的快得多,在时间上占据主导地位,所以我们说这个算法时间复杂度为a^3。以后专门讲算法的时候会讲到更复杂的计算方法。
| Plain Textinput avar b = 0var c = 0var d = 0if (a > 10){ a = a * 5}else if (a < 5){ a = a * 3}for (b = 0; b < a; b++){ for (c = 0; c < a; c++) { for (d = 0; d < a; d++) { out a * b * c * d } }}for (b = 0; b < a; b++){ for (c = 0; c < a; c++) { out a * b * c * d }}for (c = 0; c < a; c++){ out a * b * c * d}for (c = 0; c < 5; c++){ out a * b * c * d} |
|---|
算法的空间复杂度就是指算法用了多少变量,占据多少内存,对内存的使用有时候依赖于输入,有时候不依赖于输入,看算法具体情况。很古老的机器计算很慢,内存也很少,所以算法必须是最优的,现在很多情况下内存是用不完的,所以会采取用空间换时间的策略,就是哪怕我多使用一些变量,也要保证时间复杂度更低。
常见的算法有:递归法、穷举法、贪心法、分治法、动态规划法、分支界限法等等,以后都会慢慢给你介绍哒~衡量一个程序员水平高低,有很大一部分就是看他对算法的掌握程度。
三、什么是数据结构
数据结构是计算机存储、组织数据的方式。数据结构是指相互之间存在一种或多种特定关系的数据元素的集合。通常情况下,精心选择的数据结构可以带来更高的运行或者存储效率。数据结构往往同高效的检索算法和索引技术有关。
数据结构(data structure)是带有结构特性的数据元素的集合,它研究的是数据的逻辑结构和数据的物理结构以及它们之间的相互关系,并对这种结构定义相适应的运算,设计出相应的算法,并确保经过这些运算以后所得到的新结构仍保持原来的结构类型。简而言之,数据结构是相互之间存在一种或多种特定关系的数据元素的集合,即带“结构”的数据元素的集合。“结构”就是指数据元素之间存在的关系,分为逻辑结构和存储结构。
简单的说一些吧。直观的说,数据结构就是对数据的一种排布方式,类似的就像我们做脑图一样。
思维导图,英文是The Mind Map,又名心智导图,是表达发散性思维的有效图形思维工具 ,它简单却又很有效同时又很高效,是一种实用性的思维工具。这就是一个脑图,用一种结构化的方式来组织数据,按照一定的规律排布这些点。

我觉得这篇文章讲的很好理解,所以下面的内容就从这篇文章来的。
https://blog.csdn.net/Bb15070047748/article/details/119208588
- 数据结构基础模型
- 集合
集合:数据结构中的元素之间除了“同属一个集合” 的相互关系外,别无其他关系;

- 线性结构
线性结构:数据结构中的元素存在一对一的相互关系;

- 树形结构
树形结构:数据结构中的元素存在一对多的相互关系;

- 图形结构
图形结构:数据结构中的元素存在多对多的相互关系;

2. 常用的数据结构实现

- 数组(Array)
数组是一种聚合数据类型,它是将具有相同类型的若干变量有序地组织在一起的集合。数组可以说是最基本的数据结构,在各种编程语言中都有对应。一个数组可以分解为多个数组元素,按照数据元素的类型,数组可以分为整型数组、字符型数组、浮点型数组、指针数组和结构数组等。数组还可以有一维、二维以及多维等表现形式。
数组是有序元素的序列,在内存中的分配是连续的,数组会为存储的元素都分配一个下标(索引),此下标是一个自增连续的,访问数组中的元素通过下标进行访问;数组下标从0开始访问;
数组的优点是:查询速度快;

数组的缺点是:删除增加、删除慢;由于数组为每个元素都分配了索引且索引是自增连续的,因此一但删除或者新增了某个元素时需要调整后面的所有元素的索引;
新增一个元素40到3索引下标位置:

删除2索引元素:

总结:数组查询快,增删慢,适用于频繁查询,增删较少的情况;
- 栈( Stack)
栈是一种特殊的线性表,它只能在一个表的一个固定端进行数据结点的插入和删除操作。栈按照先进后出或后进先出的原则来存储数据,也就是说,先插入的数据将被压入栈底,最后插入的数据在栈顶,读出数据时,从栈顶开始逐个读出。栈在汇编语言程序中,经常用于重要数据的现场保护。栈中没有数据时,称为空栈。
一种特殊的线性表,仅能在线性表的一端操作,栈顶允许操作,栈底不允许操作。 栈的特点是:先进后出从栈顶放入元素的操作叫入栈(压栈),取出元素叫出栈(弹栈)。
入栈操作:

出栈操作:

栈的特点:先进后出,与队列不同,队列是先进先出;
- 队列(Queue)
队列和栈类似,也是一种特殊的线性表。和栈不同的是,队列只允许在表的一端进行插入操作,而在另一端进行删除操作。一般来说,进行插入操作的一端称为队尾,进行删除操作的一端称为队头。队列中没有元素时,称为空队列。
队列与栈一样,也是一种线性表,其限制是仅允许在表的一端进行插入,而在表的另一端进行删除。队列的特点是先进先出,从一端放入元素的操作称为入队,取出元素为出队;

队列的特点:先进先出;
- 链表( Linked List)
链表是一种数据元素按照链式存储结构进行存储的数据结构,这种存储结构具有在物理上存在非连续的特点。链表由一系列数据结点构成,每个数据结点包括数据域和指针域两部分。其中,指针域保存了数据结构中下一个元素存放的地址。链表结构中数据元素的逻辑顺序是通过链表中的指针链接次序来实现的。
链表是由一系列节点Node(也可称元素)组成,数据元素的逻辑顺序是通过链表的指针地址实现,通常情况下,每个节点包含两个部分,一个用于存储元素的内存地址,名叫数据域,另一个则指向下一个相邻节点地址的指针,名叫指针域;根据链表的指向不同可分为单向链表、双向链表、循环链表等;我们本章介绍的是单向链表,也是所有链表中最常见、最简单的链表;
链表的节点(Node):

完整的链表:

链表的优点:新增节点、删除节点快;
在链表中新增一个元素:

在单向链表中,新增一个元素最多只会影响上一个节点,比在数组中的新增效率要高的多;
在链表中删除一个元素:

链表的缺点:
1)查询速度慢,查询从头部开始一直查询到尾部,如果元素刚好是在最尾部那么查询效率势必非常低;
2)链表像对于数组多了一个指针域的开销,内存相对占用会比较大;
总结:数据量较小,需要频繁增加,删除操作的场景,查询操作相对较少;
- 树( Tree)
树是典型的非线性结构,它是包括,2个结点的有穷集合K。在树结构中,有且仅有一个根结点,该结点没有前驱结点。在树结构中的其他结点都有且仅有一个前驱结点,而且可以有两个后继结点,m≥0。树是图以外最复杂的数据结构,有很多很多应用都是基于树的,以后专门学数据结构课一定要好好学呀~以后学数据结构我会教你用c实现的,不是python,因为只有用c或者c++,你才能够真正理解数据结构最底层的逻辑和物理道理。
树是一种数据结构,它是由n(n>=1)个有限节点组成一个具有层次关系的集合。把它叫做 “树” 是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。它具有以下的特点:
1)每个节点有0个或多个子节点;
2)没有父节点的节点称为根节点;
3)每一个非根节点有且只有一个父节点;
4)除了根节点外,每个子节点可以分为多个不相交的子树;
5)右子树永远比左子树大,读取顺序从左到右;
树的分类有非常多种,平衡二叉树(AVL)、红黑树RBL(R-B Tree)、B树(B-Tree)、B+树(B+Tree)等,但最早都是由二叉树演变过去的;
二叉树的特点:每个结点最多有两颗子树

- 堆(Heap)
堆是一种特殊的树形数据结构,一般讨论的堆都是二叉堆。堆的特点是根结点的值是所有结点中最小的或者最大的,并且根结点的两个子树也是一个堆结构。
堆可以看做是一颗用数组实现的二叉树,所以它没有使用父指针或者子指针。堆根据“堆属性”来排序,“堆属性”决定了树中节点的位置。

下面说到大小堆,铺垫一下,你要是看不明白没关系,以后会仔细学的。
堆的特性:如果一个结点的位置为k,则它的父结点的位置为[k/2],而它的两个子结点的位置则分别为2k和2k+1。这样,在不使用指针的情况下,我们也可以通过计算数组的索引在树中上下移动:从arr[k]向上一层,就令k等于k/2,向下一层就令k等于2k或2k+1。
堆的定义如下:n个元素的序列{k1,k2,ki,…,kn}当且仅当满足下关系时,称之为堆;
(ki <= k2i,ki <= k2i+1)或者(ki >= k2i,ki >= k2i+1)满足前者的表达式的成为小顶堆(小根堆),满足后者表达式的为大顶堆(大根堆),很明显我们上面画的堆数据结构是一个大根堆;
大小根堆数据结构图:

一般来说将根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小堆或小根堆。常见的堆有二叉堆、斐波那契堆等。
- 散列表(Hash)
散列表源自于散列函数(Hash function),其思想是如果在结构中存在关键字和T相等的记录,那么必定在F(T)的存储位置可以找到该记录,这样就可以不用进行比较操作而直接取得所查记录。
散列表(Hash),也叫哈希表,是根据键和值 (key和value) 直接进行访问的数据结构,通过key和value来映射到集合中的一个位置,这样就可以很快找到集合中的对应元素。它利用数组支持按照下标访问的特性,所以散列表其实是数组的一种扩展,由数组演化而来。
散列表首先需要根据key来计算数据存储的位置,也就是数组索引的下标;
HashValue=hash(key)
散列表就是把Key通过一个固定的算法函数既所谓的哈希函数转换成一个整型数字,然后就将该数字对数组长度进行取余,取余结果就当作数组的下标,将value存储在以该数字为下标的数组空间里,这种存储空间可以充分利用数组的查找优势来查找元素,所以查找的速度很快。

在散列表中,左边是个数组,数组的每个成员包括一个指针,指向一个链表的头,当然这个链表可能为空,也可能元素很多。我们根据元素的一些特征把元素分配到不同的链表中去,也是根据这些特征,找到正确的链表,再从链表中找出这个元素。
简单的理解,散列表就像座位表,没有座位表,你要找一个人要从第一个位置挨个去看,有了座位表,你可以快速的定位到那个人。
- 图(Graph)
图是另一种非线性数据结构。在图结构中,数据结点一般称为顶点,而边是顶点的有序偶对。如果两个顶点之间存在一条边,那么就表示这两个顶点具有相邻关系。
哎,图的复杂程度就算是资深程序员,也没有多少人能真正彻底吃透。
图(Graph):图是一系列顶点(元素)的集合,这些顶点通过一系列边连接起来组成图这种数据结构。顶点用圆圈表示,边就是这些圆圈之间的连线。顶点之间通过边连接。
图分为有向图和无向图:
有向图:边不仅连接两个顶点,并且具有方向;
无向图:边仅仅连接两个顶点,没有其他含义;

例如,我们可以把图这种数据结构看做是一张地图:
地图中的城市我们看做是顶点,高铁线路看做是边;很显然,我们的地图是一种无向图,以长沙到上海为例,经过的城市有长沙、南昌、杭州、上海等地;那么从上海也可以按照原有的路线进行返回;

图的算法和各种问题太多太多了,在这里你可以先了解一下最基础的两种搜索算法,广度优先(bfs,Breadth First Search)和深度优先(dfs,Depth First Search)
广度优先:搜索到一个顶点时,先将此顶点的所有子顶点全部搜索完毕,再进行下一个子顶点的子顶点搜索;

例如上图:以武汉为例进行广度搜索,
1)首先搜索合肥、南昌、长沙等城市;
2)通过合肥搜索到南京;
3)再通过南昌搜索到杭州、福州,
4)最终通过南京搜索到上海;完成图的遍历搜索;
不通过南京搜索到杭州是因为已经通过南昌搜索到杭州了,不需要再次搜索;
深度优先搜索到一个顶点时,先将此顶点某个子顶点搜索到底部(子顶点的子顶点的子顶点…),然后回到上一级,继续搜索第二个子顶点一直搜索到底部;

例如上图:以武汉为例进行深度搜索,
1)首先搜索合肥、南京、上海等城市;
2)回到武汉,进行第二子顶点的搜索,搜索南昌、杭州等地;
3)回到南昌,搜索福州;
4)回到武汉,搜索长沙;
四、总结
算法和数据结构是很复杂很复杂的东西,软件工程专业要单独开两门课来讲这两个,加油慢慢理解!