目录
一 回归损失函数(Bounding Box Regression Loss)
1 Inner-IoU
2 Focaler-IoU:更聚焦的IoU损失
二 改进YOLOv9的损失函数
1 总体修改
① utils/metrics.py文件
② utils/loss_tal_dual.py文件
2 各种机制的使用
① 使用结合InnerIoU的各种损失函数改进YOLOv9
a 使用Inner-GIOU
b 使用Inner-DIOU
② 使用结合Focaler-IoU的各种损失函数改进YOLOv9
a 使用Focaler-GIOU
b 使用Focaler-DIOU
其他
一 回归损失函数(Bounding Box Regression Loss)
1 Inner-IoU
官方论文地址:https://arxiv.org/pdf/2311.02877.pdf
官方代码地址:GitCode - 开发者的代码家园
论文中分析了边界框的回归过程,指出了IoU损失的局限性,它对不同的检测任务没有很强的泛化能力。基于边界框回归问题的固有特点,提出了一种基于辅助边界框的边界框回归损失Inner-IoU。通过比例因子比率(scale factor ratio)控制辅助边界框的生成,计算损失,加速训练的收敛。它可以集成到现有的基于IoU的损失函数中。通过一系列的模拟和烧蚀消融实验验证,该方法优于现有方法。本文提出的方法不仅适用于一般的检测任务,而且对于非常小目标的检测任务也表现良好,证实了该方法的泛化性。
官方的代码给出了2种结合方式,文件如下图:

Inner-IoU的描述见下图:


Inner-IoU的实验效果
CIoU 方法, Inner-CIoU (ratio=0.7), Inner-CIoU (ratio=0.75) and Inner-CIoU (ratio=0.8)的检测效果如下图所示:

SIoU 方法, Inner-SIoU (ratio=0.7), Inner-SIoU (ratio=0.75) and Inner-SIoU (ratio=0.8)的检测效果如下图所示:

2 Focaler-IoU:更聚焦的IoU损失
官方论文地址:https://arxiv.org/pdf/2401.10525.pdf
官方代码地址:https://github.com/malagoutou/Focaler-IoU
论文中分析了难易样本的分布对目标检测的影响。当困难样品占主导地位时,需要关注困难样品以提高检测性能。当简单样本的比例较大时,则相反。论文中提出了Focaler-IoU方法,通过线性区间映射重建原始IoU损失,达到聚焦难易样本的目的。最后通过对比实验证明,该方法能够有效提高检测性能。
为了在不同的回归样本中关注不同的检测任务,使用线性间隔映射方法重构IoU损失,这有助于提高边缘回归。具体的公式如下所示:

将Focaler-IoU应用于现有的基于IoU的边界框回归损失函数中,如下所示:

实验结果如下:
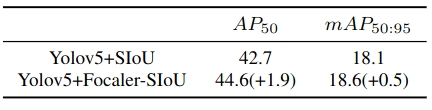

GIoU、DIoU、CIoU、EIoU和MPDIou等的概述见使用MPDIou回归损失函数帮助YOLOv9模型更优秀 点击此处即可跳转
二 改进YOLOv9的损失函数
1 总体修改
① utils/metrics.py文件
首先,我们现将后续会使用到的损失函数集成到项目中。在utils/metrics.py文件中,使用下述代码(替换后的部分)替换掉bbox_iou()函数,如下图所示:

原始代码部分和替换后的部分对比如下:
原始代码部分如下:
def bbox_iou(box1, box2, xywh=True, GIoU=False, DIoU=False, CIoU=False, MDPIoU=False, feat_h=640, feat_w=640, eps=1e-7):
# Returns Intersection over Union (IoU) of box1(1,4) to box2(n,4)
# Get the coordinates of bounding boxes
if xywh: # transform from xywh to xyxy
(x1, y1, w1, h1), (x2, y2, w2, h2) = box1.chunk(4, -1), box2.chunk(4, -1)
w1_, h1_, w2_, h2_ = w1 / 2, h1 / 2, w2 / 2, h2 / 2
b1_x1, b1_x2, b1_y1, b1_y2 = x1 - w1_, x1 + w1_, y1 - h1_, y1 + h1_
b2_x1, b2_x2, b2_y1, b2_y2 = x2 - w2_, x2 + w2_, y2 - h2_, y2 + h2_
else: # x1, y1, x2, y2 = box1
b1_x1, b1_y1, b1_x2, b1_y2 = box1.chunk(4, -1)
b2_x1, b2_y1, b2_x2, b2_y2 = box2.chunk(4, -1)
w1, h1 = b1_x2 - b1_x1, b1_y2 - b1_y1 + eps
w2, h2 = b2_x2 - b2_x1, b2_y2 - b2_y1 + eps
# Intersection area
inter = (torch.min(b1_x2, b2_x2) - torch.max(b1_x1, b2_x1)).clamp(0) * \
(torch.min(b1_y2, b2_y2) - torch.max(b1_y1, b2_y1)).clamp(0)
# Union Area
union = w1 * h1 + w2 * h2 - inter + eps
# IoU
iou = inter / union
if CIoU or DIoU or GIoU:
cw = torch.max(b1_x2, b2_x2) - torch.min(b1_x1, b2_x1) # convex (smallest enclosing box) width
ch = torch.max(b1_y2, b2_y2) - torch.min(b1_y1, b2_y1) # convex height
if CIoU or DIoU: # Distance or Complete IoU https://arxiv.org/abs/1911.08287v1
c2 = cw ** 2 + ch ** 2 + eps # convex diagonal squared
rho2 = ((b2_x1 + b2_x2 - b1_x1 - b1_x2) ** 2 + (b2_y1 + b2_y2 - b1_y1 - b1_y2) ** 2) / 4 # center dist ** 2
if CIoU: # https://github.com/Zzh-tju/DIoU-SSD-pytorch/blob/master/utils/box/box_utils.py#L47
v = (4 / math.pi ** 2) * torch.pow(torch.atan(w2 / h2) - torch.atan(w1 / h1), 2)
with torch.no_grad():
alpha = v / (v - iou + (1 + eps))
return iou - (rho2 / c2 + v * alpha) # CIoU
return iou - rho2 / c2 # DIoU
c_area = cw * ch + eps # convex area
return iou - (c_area - union) / c_area # GIoU https://arxiv.org/pdf/1902.09630.pdf
elif MDPIoU:
d1 = (b2_x1 - b1_x1) ** 2 + (b2_y1 - b1_y1) ** 2
d2 = (b2_x2 - b1_x2) ** 2 + (b2_y2 - b1_y2) ** 2
mpdiou_hw_pow = feat_h ** 2 + feat_w ** 2
return iou - d1 / mpdiou_hw_pow - d2 / mpdiou_hw_pow # MPDIoU
return iou # IoU替换后的部分如下:
# after
def xyxy2xywh(x):
"""
Convert bounding box coordinates from (x1, y1, x2, y2) format to (x, y, width, height) format where (x1, y1) is the
top-left corner and (x2, y2) is the bottom-right corner.
Args:
x (np.ndarray | torch.Tensor): The input bounding box coordinates in (x1, y1, x2, y2) format.
Returns:
y (np.ndarray | torch.Tensor): The bounding box coordinates in (x, y, width, height) format.
"""
assert x.shape[-1] == 4, f"input shape last dimension expected 4 but input shape is {x.shape}"
y = torch.empty_like(x) if isinstance(x, torch.Tensor) else np.empty_like(x) # faster than clone/copy
y[..., 0] = (x[..., 0] + x[..., 2]) / 2 # x center
y[..., 1] = (x[..., 1] + x[..., 3]) / 2 # y center
y[..., 2] = x[..., 2] - x[..., 0] # width
y[..., 3] = x[..., 3] - x[..., 1] # height
return y
def bbox_iou(box1, box2, xywh=True, GIoU=False, DIoU=False, CIoU=False, MDPIoU=False, Inner=False, Focaleriou=False,
ratio=0.7, feat_h=640,
feat_w=640, eps=1e-7, d=0.00, u=0.95, ):
# 计算box1(1,4)与box2(n,4)之间的Intersection over Union(IoU)
# 获取bounding box的坐标
if Inner:
if not xywh:
box1, box2 = xyxy2xywh(box1), xyxy2xywh(box2)
(x1, y1, w1, h1), (x2, y2, w2, h2) = box1.chunk(4, -1), box2.chunk(4, -1)
b1_x1, b1_x2, b1_y1, b1_y2 = x1 - (w1 * ratio) / 2, x1 + (w1 * ratio) / 2, y1 - (h1 * ratio) / 2, y1 + (
h1 * ratio) / 2
b2_x1, b2_x2, b2_y1, b2_y2 = x2 - (w2 * ratio) / 2, x2 + (w2 * ratio) / 2, y2 - (h2 * ratio) / 2, y2 + (
h2 * ratio) / 2
# 计算交集
inter = (b1_x2.minimum(b2_x2) - b1_x1.maximum(b2_x1)).clamp_(0) * \
(b1_y2.minimum(b2_y2) - b1_y1.maximum(b2_y1)).clamp_(0)
# 计算并集
union = w1 * h1 * ratio * ratio + w2 * h2 * ratio * ratio - inter + eps
else:
if xywh: # 从xywh转换为xyxy格式
(x1, y1, w1, h1), (x2, y2, w2, h2) = box1.chunk(4, -1), box2.chunk(4, -1)
w1_, h1_, w2_, h2_ = w1 / 2, h1 / 2, w2 / 2, h2 / 2
b1_x1, b1_x2, b1_y1, b1_y2 = x1 - w1_, x1 + w1_, y1 - h1_, y1 + h1_
b2_x1, b2_x2, b2_y1, b2_y2 = x2 - w2_, x2 + w2_, y2 - h2_, y2 + h2_
else: # x1, y1, x2, y2 = box1
b1_x1, b1_y1, b1_x2, b1_y2 = box1.chunk(4, -1)
b2_x1, b2_y1, b2_x2, b2_y2 = box2.chunk(4, -1)
w1, h1 = b1_x2 - b1_x1, b1_y2 - b1_y1 + eps
w2, h2 = b2_x2 - b2_x1, b2_y2 - b2_y1 + eps
# 交集
inter = (torch.min(b1_x2, b2_x2) - torch.max(b1_x1, b2_x1)).clamp(0) * \
(torch.min(b1_y2, b2_y2) - torch.max(b1_y1, b2_y1)).clamp(0)
# 并集
union = w1 * h1 + w2 * h2 - inter + eps
# IoU
iou = inter / union
if Focaleriou:
iou = ((iou - d) / (u - d)).clamp(0, 1) # default d=0.00,u=0.95
if CIoU or DIoU or GIoU:
cw = torch.max(b1_x2, b2_x2) - torch.min(b1_x1, b2_x1) # 最小外接矩形的宽度
ch = torch.max(b1_y2, b2_y2) - torch.min(b1_y1, b2_y1) # 计算最小外接矩形的高度
if CIoU or DIoU:
c2 = cw ** 2 + ch ** 2 + eps # 最小外接矩形对角线的平方
rho2 = ((b2_x1 + b2_x2 - b1_x1 - b1_x2) ** 2 + (b2_y1 + b2_y2 - b1_y1 - b1_y2) ** 2) / 4 # 中心点距离的平方
if CIoU:
v = (4 / math.pi ** 2) * torch.pow(torch.atan(w2 / h2) - torch.atan(w1 / h1), 2)
with torch.no_grad():
alpha = v / (v - iou + (1 + eps))
return iou - (rho2 / c2 + v * alpha) # CIoU
return iou - rho2 / c2 # DIoU
c_area = cw * ch + eps # convex area
return iou - (c_area - union) / c_area # GIoU
elif MDPIoU:
d1 = (b2_x1 - b1_x1) ** 2 + (b2_y1 - b1_y1) ** 2
d2 = (b2_x2 - b1_x2) ** 2 + (b2_y2 - b1_y2) ** 2
mpdiou_hw_pow = feat_h ** 2 + feat_w ** 2
return iou - d1 / mpdiou_hw_pow - d2 / mpdiou_hw_pow # MPDIoU
return iou # 返回计算的IoU值② utils/loss_tal_dual.py文件
需要在utils/loss_tal_dual.py文件中进行修改。因为将MPDIou也集成在项目里了,所这个文件的修改有四处处,如下面的两个图所示。
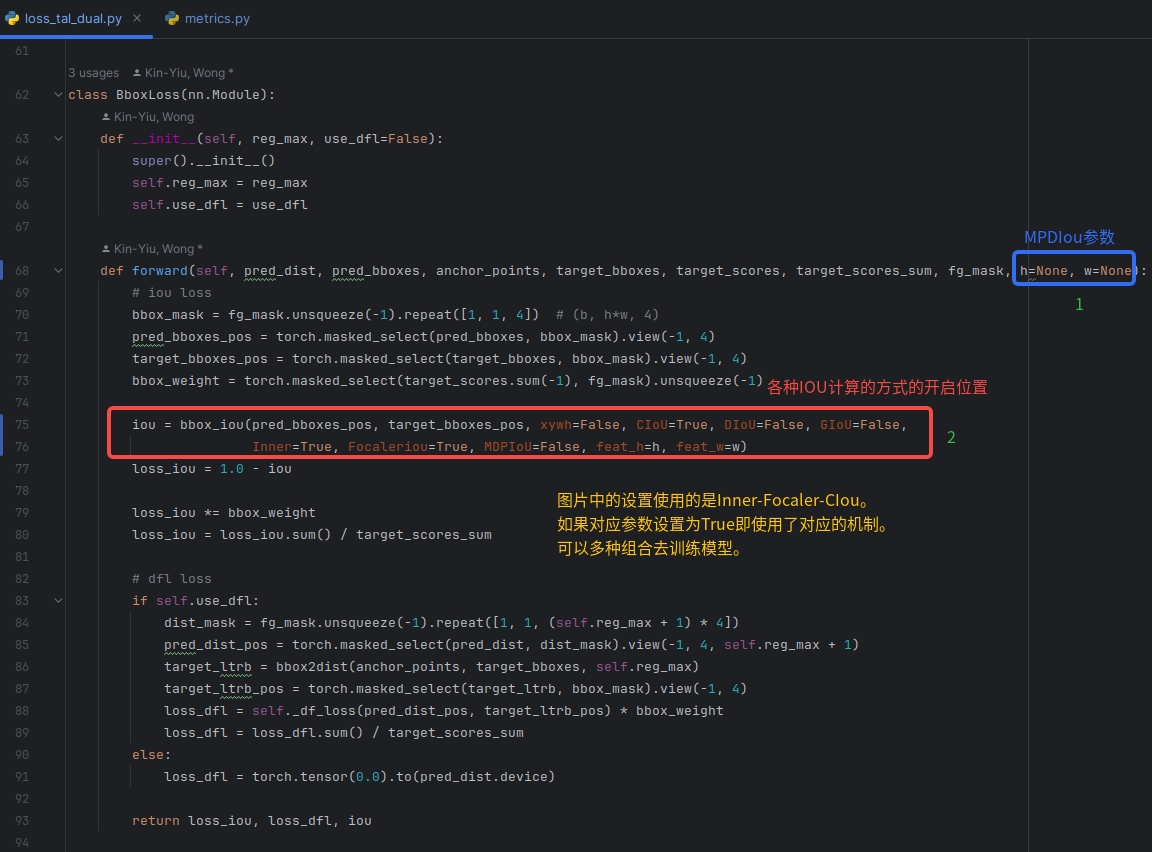
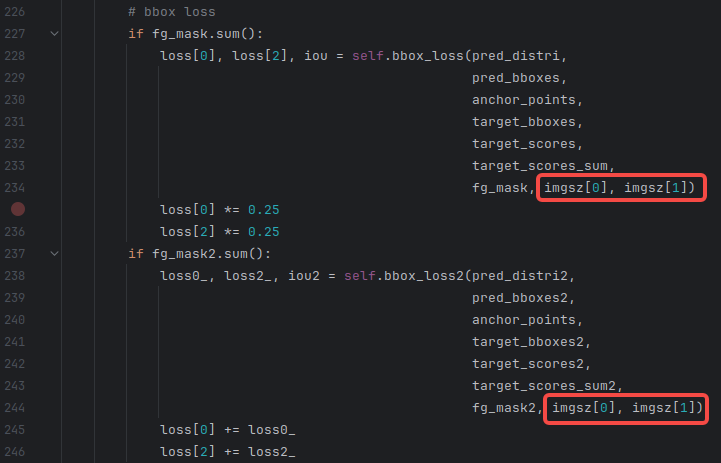
2 各种机制的使用
① 使用结合InnerIoU的各种损失函数改进YOLOv9
各种损失函数的开启方式均需要在utils/loss_tal_dual.py文件中进行修改。因为将MPDIou也集成在项目里了,所这个文件的修改有两处。
a 使用Inner-GIOU
utils/loss_tal_dual.py文件中进行的修改如下图:

接下来,就可以开始训练了!!! 🌺🌺🌺
b 使用Inner-DIOU
utils/loss_tal_dual.py文件中进行的修改如下图:

接下来,就可以开始训练了!!!🌺🌺🌺
② 使用结合Focaler-IoU的各种损失函数改进YOLOv9
a 使用Focaler-GIOU
utils/loss_tal_dual.py文件中进行的修改如下图:
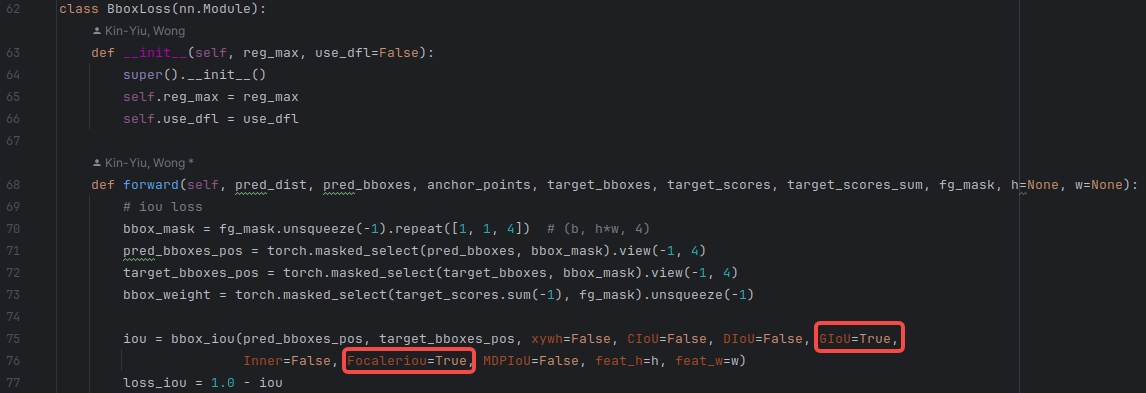
接下来,就可以开始训练了!!! 🌺🌺🌺
b 使用Focaler-DIOU
utils/loss_tal_dual.py文件中进行的修改如下图:
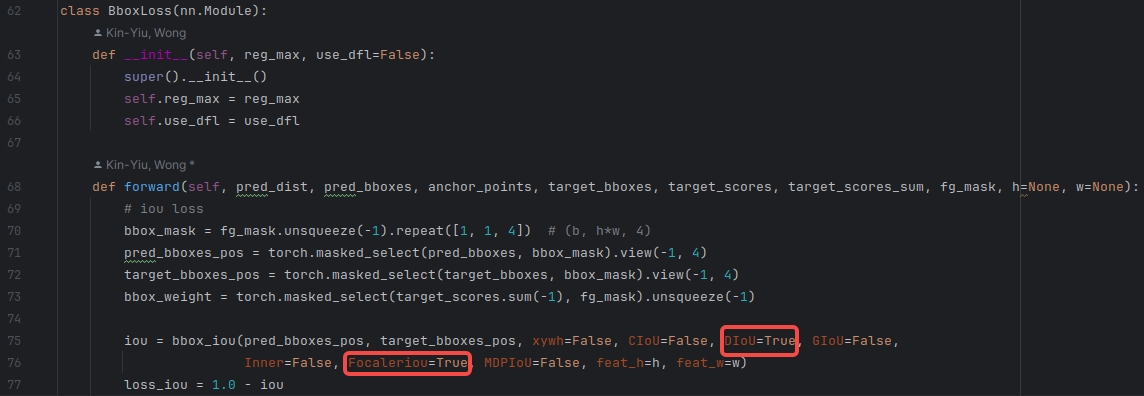
接下来,就可以开始训练了!!! 🌺🌺🌺
其他
如果觉得替换部分内容不方便的话,可以直接复制下述文件对应替换原始py文件的内容:
- 修改后的utils/metrics.py
import math
import warnings
from pathlib import Path
import matplotlib.pyplot as plt
import numpy as np
import torch
from utils import TryExcept, threaded
def fitness(x):
# Model fitness as a weighted combination of metrics
w = [0.0, 0.0, 0.1, 0.9] # weights for [P, R, mAP@0.5, mAP@0.5:0.95]
return (x[:, :4] * w).sum(1)
def smooth(y, f=0.05):
# Box filter of fraction f
nf = round(len(y) * f * 2) // 2 + 1 # number of filter elements (must be odd)
p = np.ones(nf // 2) # ones padding
yp = np.concatenate((p * y[0], y, p * y[-1]), 0) # y padded
return np.convolve(yp, np.ones(nf) / nf, mode='valid') # y-smoothed
def ap_per_class(tp, conf, pred_cls, target_cls, plot=False, save_dir='.', names=(), eps=1e-16, prefix=""):
""" Compute the average precision, given the recall and precision curves.
Source: https://github.com/rafaelpadilla/Object-Detection-Metrics.
# Arguments
tp: True positives (nparray, nx1 or nx10).
conf: Objectness value from 0-1 (nparray).
pred_cls: Predicted object classes (nparray).
target_cls: True object classes (nparray).
plot: Plot precision-recall curve at mAP@0.5
save_dir: Plot save directory
# Returns
The average precision as computed in py-faster-rcnn.
"""
# Sort by objectness
i = np.argsort(-conf)
tp, conf, pred_cls = tp[i], conf[i], pred_cls[i]
# Find unique classes
unique_classes, nt = np.unique(target_cls, return_counts=True)
nc = unique_classes.shape[0] # number of classes, number of detections
# Create Precision-Recall curve and compute AP for each class
px, py = np.linspace(0, 1, 1000), [] # for plotting
ap, p, r = np.zeros((nc, tp.shape[1])), np.zeros((nc, 1000)), np.zeros((nc, 1000))
for ci, c in enumerate(unique_classes):
i = pred_cls == c
n_l = nt[ci] # number of labels
n_p = i.sum() # number of predictions
if n_p == 0 or n_l == 0:
continue
# Accumulate FPs and TPs
fpc = (1 - tp[i]).cumsum(0)
tpc = tp[i].cumsum(0)
# Recall
recall = tpc / (n_l + eps) # recall curve
r[ci] = np.interp(-px, -conf[i], recall[:, 0], left=0) # negative x, xp because xp decreases
# Precision
precision = tpc / (tpc + fpc) # precision curve
p[ci] = np.interp(-px, -conf[i], precision[:, 0], left=1) # p at pr_score
# AP from recall-precision curve
for j in range(tp.shape[1]):
ap[ci, j], mpre, mrec = compute_ap(recall[:, j], precision[:, j])
if plot and j == 0:
py.append(np.interp(px, mrec, mpre)) # precision at mAP@0.5
# Compute F1 (harmonic mean of precision and recall)
f1 = 2 * p * r / (p + r + eps)
names = [v for k, v in names.items() if k in unique_classes] # list: only classes that have data
names = dict(enumerate(names)) # to dict
if plot:
plot_pr_curve(px, py, ap, Path(save_dir) / f'{prefix}PR_curve.png', names)
plot_mc_curve(px, f1, Path(save_dir) / f'{prefix}F1_curve.png', names, ylabel='F1')
plot_mc_curve(px, p, Path(save_dir) / f'{prefix}P_curve.png', names, ylabel='Precision')
plot_mc_curve(px, r, Path(save_dir) / f'{prefix}R_curve.png', names, ylabel='Recall')
i = smooth(f1.mean(0), 0.1).argmax() # max F1 index
p, r, f1 = p[:, i], r[:, i], f1[:, i]
tp = (r * nt).round() # true positives
fp = (tp / (p + eps) - tp).round() # false positives
return tp, fp, p, r, f1, ap, unique_classes.astype(int)
def compute_ap(recall, precision):
""" Compute the average precision, given the recall and precision curves
# Arguments
recall: The recall curve (list)
precision: The precision curve (list)
# Returns
Average precision, precision curve, recall curve
"""
# Append sentinel values to beginning and end
mrec = np.concatenate(([0.0], recall, [1.0]))
mpre = np.concatenate(([1.0], precision, [0.0]))
# Compute the precision envelope
mpre = np.flip(np.maximum.accumulate(np.flip(mpre)))
# Integrate area under curve
method = 'interp' # methods: 'continuous', 'interp'
if method == 'interp':
x = np.linspace(0, 1, 101) # 101-point interp (COCO)
ap = np.trapz(np.interp(x, mrec, mpre), x) # integrate
else: # 'continuous'
i = np.where(mrec[1:] != mrec[:-1])[0] # points where x axis (recall) changes
ap = np.sum((mrec[i + 1] - mrec[i]) * mpre[i + 1]) # area under curve
return ap, mpre, mrec
class ConfusionMatrix:
# Updated version of https://github.com/kaanakan/object_detection_confusion_matrix
def __init__(self, nc, conf=0.25, iou_thres=0.45):
self.matrix = np.zeros((nc + 1, nc + 1))
self.nc = nc # number of classes
self.conf = conf
self.iou_thres = iou_thres
def process_batch(self, detections, labels):
"""
Return intersection-over-union (Jaccard index) of boxes.
Both sets of boxes are expected to be in (x1, y1, x2, y2) format.
Arguments:
detections (Array[N, 6]), x1, y1, x2, y2, conf, class
labels (Array[M, 5]), class, x1, y1, x2, y2
Returns:
None, updates confusion matrix accordingly
"""
if detections is None:
gt_classes = labels.int()
for gc in gt_classes:
self.matrix[self.nc, gc] += 1 # background FN
return
detections = detections[detections[:, 4] > self.conf]
gt_classes = labels[:, 0].int()
detection_classes = detections[:, 5].int()
iou = box_iou(labels[:, 1:], detections[:, :4])
x = torch.where(iou > self.iou_thres)
if x[0].shape[0]:
matches = torch.cat((torch.stack(x, 1), iou[x[0], x[1]][:, None]), 1).cpu().numpy()
if x[0].shape[0] > 1:
matches = matches[matches[:, 2].argsort()[::-1]]
matches = matches[np.unique(matches[:, 1], return_index=True)[1]]
matches = matches[matches[:, 2].argsort()[::-1]]
matches = matches[np.unique(matches[:, 0], return_index=True)[1]]
else:
matches = np.zeros((0, 3))
n = matches.shape[0] > 0
m0, m1, _ = matches.transpose().astype(int)
for i, gc in enumerate(gt_classes):
j = m0 == i
if n and sum(j) == 1:
self.matrix[detection_classes[m1[j]], gc] += 1 # correct
else:
self.matrix[self.nc, gc] += 1 # true background
if n:
for i, dc in enumerate(detection_classes):
if not any(m1 == i):
self.matrix[dc, self.nc] += 1 # predicted background
def matrix(self):
return self.matrix
def tp_fp(self):
tp = self.matrix.diagonal() # true positives
fp = self.matrix.sum(1) - tp # false positives
# fn = self.matrix.sum(0) - tp # false negatives (missed detections)
return tp[:-1], fp[:-1] # remove background class
@TryExcept('WARNING ⚠️ ConfusionMatrix plot failure')
def plot(self, normalize=True, save_dir='', names=()):
import seaborn as sn
array = self.matrix / ((self.matrix.sum(0).reshape(1, -1) + 1E-9) if normalize else 1) # normalize columns
array[array < 0.005] = np.nan # don't annotate (would appear as 0.00)
fig, ax = plt.subplots(1, 1, figsize=(12, 9), tight_layout=True)
nc, nn = self.nc, len(names) # number of classes, names
sn.set(font_scale=1.0 if nc < 50 else 0.8) # for label size
labels = (0 < nn < 99) and (nn == nc) # apply names to ticklabels
ticklabels = (names + ['background']) if labels else "auto"
with warnings.catch_warnings():
warnings.simplefilter('ignore') # suppress empty matrix RuntimeWarning: All-NaN slice encountered
sn.heatmap(array,
ax=ax,
annot=nc < 30,
annot_kws={
"size": 8},
cmap='Blues',
fmt='.2f',
square=True,
vmin=0.0,
xticklabels=ticklabels,
yticklabels=ticklabels).set_facecolor((1, 1, 1))
ax.set_ylabel('True')
ax.set_ylabel('Predicted')
ax.set_title('Confusion Matrix')
fig.savefig(Path(save_dir) / 'confusion_matrix.png', dpi=250)
plt.close(fig)
def print(self):
for i in range(self.nc + 1):
print(' '.join(map(str, self.matrix[i])))
class WIoU_Scale:
''' monotonous: {
None: origin v1
True: monotonic FM v2
False: non-monotonic FM v3
}
momentum: The momentum of running mean'''
iou_mean = 1.
monotonous = False
_momentum = 1 - 0.5 ** (1 / 7000)
_is_train = True
def __init__(self, iou):
self.iou = iou
self._update(self)
@classmethod
def _update(cls, self):
if cls._is_train: cls.iou_mean = (1 - cls._momentum) * cls.iou_mean + \
cls._momentum * self.iou.detach().mean().item()
@classmethod
def _scaled_loss(cls, self, gamma=1.9, delta=3):
if isinstance(self.monotonous, bool):
if self.monotonous:
return (self.iou.detach() / self.iou_mean).sqrt()
else:
beta = self.iou.detach() / self.iou_mean
alpha = delta * torch.pow(gamma, beta - delta)
return beta / alpha
return 1
def xyxy2xywh(x):
"""
Convert bounding box coordinates from (x1, y1, x2, y2) format to (x, y, width, height) format where (x1, y1) is the
top-left corner and (x2, y2) is the bottom-right corner.
Args:
x (np.ndarray | torch.Tensor): The input bounding box coordinates in (x1, y1, x2, y2) format.
Returns:
y (np.ndarray | torch.Tensor): The bounding box coordinates in (x, y, width, height) format.
"""
assert x.shape[-1] == 4, f"input shape last dimension expected 4 but input shape is {x.shape}"
y = torch.empty_like(x) if isinstance(x, torch.Tensor) else np.empty_like(x) # faster than clone/copy
y[..., 0] = (x[..., 0] + x[..., 2]) / 2 # x center
y[..., 1] = (x[..., 1] + x[..., 3]) / 2 # y center
y[..., 2] = x[..., 2] - x[..., 0] # width
y[..., 3] = x[..., 3] - x[..., 1] # height
return y
def bbox_iou(box1, box2, xywh=True, GIoU=False, DIoU=False, CIoU=False, MDPIoU=False, Inner=False, Focaleriou=False,
ratio=0.7, feat_h=640,
feat_w=640, eps=1e-7, d=0.00, u=0.95, ):
# 计算box1(1,4)与box2(n,4)之间的Intersection over Union(IoU)
# 获取bounding box的坐标
if Inner:
if not xywh:
box1, box2 = xyxy2xywh(box1), xyxy2xywh(box2)
(x1, y1, w1, h1), (x2, y2, w2, h2) = box1.chunk(4, -1), box2.chunk(4, -1)
b1_x1, b1_x2, b1_y1, b1_y2 = x1 - (w1 * ratio) / 2, x1 + (w1 * ratio) / 2, y1 - (h1 * ratio) / 2, y1 + (
h1 * ratio) / 2
b2_x1, b2_x2, b2_y1, b2_y2 = x2 - (w2 * ratio) / 2, x2 + (w2 * ratio) / 2, y2 - (h2 * ratio) / 2, y2 + (
h2 * ratio) / 2
# 计算交集
inter = (b1_x2.minimum(b2_x2) - b1_x1.maximum(b2_x1)).clamp_(0) * \
(b1_y2.minimum(b2_y2) - b1_y1.maximum(b2_y1)).clamp_(0)
# 计算并集
union = w1 * h1 * ratio * ratio + w2 * h2 * ratio * ratio - inter + eps
else:
if xywh: # 从xywh转换为xyxy格式
(x1, y1, w1, h1), (x2, y2, w2, h2) = box1.chunk(4, -1), box2.chunk(4, -1)
w1_, h1_, w2_, h2_ = w1 / 2, h1 / 2, w2 / 2, h2 / 2
b1_x1, b1_x2, b1_y1, b1_y2 = x1 - w1_, x1 + w1_, y1 - h1_, y1 + h1_
b2_x1, b2_x2, b2_y1, b2_y2 = x2 - w2_, x2 + w2_, y2 - h2_, y2 + h2_
else: # x1, y1, x2, y2 = box1
b1_x1, b1_y1, b1_x2, b1_y2 = box1.chunk(4, -1)
b2_x1, b2_y1, b2_x2, b2_y2 = box2.chunk(4, -1)
w1, h1 = b1_x2 - b1_x1, b1_y2 - b1_y1 + eps
w2, h2 = b2_x2 - b2_x1, b2_y2 - b2_y1 + eps
# 交集
inter = (torch.min(b1_x2, b2_x2) - torch.max(b1_x1, b2_x1)).clamp(0) * \
(torch.min(b1_y2, b2_y2) - torch.max(b1_y1, b2_y1)).clamp(0)
# 并集
union = w1 * h1 + w2 * h2 - inter + eps
# IoU
iou = inter / union
if Focaleriou:
iou = ((iou - d) / (u - d)).clamp(0, 1) # default d=0.00,u=0.95
if CIoU or DIoU or GIoU:
cw = torch.max(b1_x2, b2_x2) - torch.min(b1_x1, b2_x1) # 最小外接矩形的宽度
ch = torch.max(b1_y2, b2_y2) - torch.min(b1_y1, b2_y1) # 计算最小外接矩形的高度
if CIoU or DIoU:
c2 = cw ** 2 + ch ** 2 + eps # 最小外接矩形对角线的平方
rho2 = ((b2_x1 + b2_x2 - b1_x1 - b1_x2) ** 2 + (b2_y1 + b2_y2 - b1_y1 - b1_y2) ** 2) / 4 # 中心点距离的平方
if CIoU:
v = (4 / math.pi ** 2) * torch.pow(torch.atan(w2 / h2) - torch.atan(w1 / h1), 2)
with torch.no_grad():
alpha = v / (v - iou + (1 + eps))
return iou - (rho2 / c2 + v * alpha) # CIoU
return iou - rho2 / c2 # DIoU
c_area = cw * ch + eps # convex area
return iou - (c_area - union) / c_area # GIoU
elif MDPIoU:
d1 = (b2_x1 - b1_x1) ** 2 + (b2_y1 - b1_y1) ** 2
d2 = (b2_x2 - b1_x2) ** 2 + (b2_y2 - b1_y2) ** 2
mpdiou_hw_pow = feat_h ** 2 + feat_w ** 2
return iou - d1 / mpdiou_hw_pow - d2 / mpdiou_hw_pow # MPDIoU
return iou # 返回计算的IoU值
def box_iou(box1, box2, eps=1e-7):
# https://github.com/pytorch/vision/blob/master/torchvision/ops/boxes.py
"""
Return intersection-over-union (Jaccard index) of boxes.
Both sets of boxes are expected to be in (x1, y1, x2, y2) format.
Arguments:
box1 (Tensor[N, 4])
box2 (Tensor[M, 4])
Returns:
iou (Tensor[N, M]): the NxM matrix containing the pairwise
IoU values for every element in boxes1 and boxes2
"""
# inter(N,M) = (rb(N,M,2) - lt(N,M,2)).clamp(0).prod(2)
(a1, a2), (b1, b2) = box1.unsqueeze(1).chunk(2, 2), box2.unsqueeze(0).chunk(2, 2)
inter = (torch.min(a2, b2) - torch.max(a1, b1)).clamp(0).prod(2)
# IoU = inter / (area1 + area2 - inter)
return inter / ((a2 - a1).prod(2) + (b2 - b1).prod(2) - inter + eps)
def bbox_ioa(box1, box2, eps=1e-7):
"""Returns the intersection over box2 area given box1, box2. Boxes are x1y1x2y2
box1: np.array of shape(nx4)
box2: np.array of shape(mx4)
returns: np.array of shape(nxm)
"""
# Get the coordinates of bounding boxes
b1_x1, b1_y1, b1_x2, b1_y2 = box1.T
b2_x1, b2_y1, b2_x2, b2_y2 = box2.T
# Intersection area
inter_area = (np.minimum(b1_x2[:, None], b2_x2) - np.maximum(b1_x1[:, None], b2_x1)).clip(0) * \
(np.minimum(b1_y2[:, None], b2_y2) - np.maximum(b1_y1[:, None], b2_y1)).clip(0)
# box2 area
box2_area = (b2_x2 - b2_x1) * (b2_y2 - b2_y1) + eps
# Intersection over box2 area
return inter_area / box2_area
def wh_iou(wh1, wh2, eps=1e-7):
# Returns the nxm IoU matrix. wh1 is nx2, wh2 is mx2
wh1 = wh1[:, None] # [N,1,2]
wh2 = wh2[None] # [1,M,2]
inter = torch.min(wh1, wh2).prod(2) # [N,M]
return inter / (wh1.prod(2) + wh2.prod(2) - inter + eps) # iou = inter / (area1 + area2 - inter)
# Plots ----------------------------------------------------------------------------------------------------------------
@threaded
def plot_pr_curve(px, py, ap, save_dir=Path('pr_curve.png'), names=()):
# Precision-recall curve
fig, ax = plt.subplots(1, 1, figsize=(9, 6), tight_layout=True)
py = np.stack(py, axis=1)
if 0 < len(names) < 21: # display per-class legend if < 21 classes
for i, y in enumerate(py.T):
ax.plot(px, y, linewidth=1, label=f'{names[i]} {ap[i, 0]:.3f}') # plot(recall, precision)
else:
ax.plot(px, py, linewidth=1, color='grey') # plot(recall, precision)
ax.plot(px, py.mean(1), linewidth=3, color='blue', label='all classes %.3f mAP@0.5' % ap[:, 0].mean())
ax.set_xlabel('Recall')
ax.set_ylabel('Precision')
ax.set_xlim(0, 1)
ax.set_ylim(0, 1)
ax.legend(bbox_to_anchor=(1.04, 1), loc="upper left")
ax.set_title('Precision-Recall Curve')
fig.savefig(save_dir, dpi=250)
plt.close(fig)
@threaded
def plot_mc_curve(px, py, save_dir=Path('mc_curve.png'), names=(), xlabel='Confidence', ylabel='Metric'):
# Metric-confidence curve
fig, ax = plt.subplots(1, 1, figsize=(9, 6), tight_layout=True)
if 0 < len(names) < 21: # display per-class legend if < 21 classes
for i, y in enumerate(py):
ax.plot(px, y, linewidth=1, label=f'{names[i]}') # plot(confidence, metric)
else:
ax.plot(px, py.T, linewidth=1, color='grey') # plot(confidence, metric)
y = smooth(py.mean(0), 0.05)
ax.plot(px, y, linewidth=3, color='blue', label=f'all classes {y.max():.2f} at {px[y.argmax()]:.3f}')
ax.set_xlabel(xlabel)
ax.set_ylabel(ylabel)
ax.set_xlim(0, 1)
ax.set_ylim(0, 1)
ax.legend(bbox_to_anchor=(1.04, 1), loc="upper left")
ax.set_title(f'{ylabel}-Confidence Curve')
fig.savefig(save_dir, dpi=250)
plt.close(fig)
修改后的utils/loss_tal_dual.py
import os
import torch
import torch.nn as nn
import torch.nn.functional as F
from utils.general import xywh2xyxy
from utils.metrics import bbox_iou
from utils.tal.anchor_generator import dist2bbox, make_anchors, bbox2dist
from utils.tal.assigner import TaskAlignedAssigner
from utils.torch_utils import de_parallel
def smooth_BCE(eps=0.1): # https://github.com/ultralytics/yolov3/issues/238#issuecomment-598028441
# return positive, negative label smoothing BCE targets
return 1.0 - 0.5 * eps, 0.5 * eps
class VarifocalLoss(nn.Module):
# Varifocal loss by Zhang et al. https://arxiv.org/abs/2008.13367
def __init__(self):
super().__init__()
def forward(self, pred_score, gt_score, label, alpha=0.75, gamma=2.0):
weight = alpha * pred_score.sigmoid().pow(gamma) * (1 - label) + gt_score * label
with torch.cuda.amp.autocast(enabled=False):
loss = (F.binary_cross_entropy_with_logits(pred_score.float(), gt_score.float(),
reduction="none") * weight).sum()
return loss
class FocalLoss(nn.Module):
# Wraps focal loss around existing loss_fcn(), i.e. criteria = FocalLoss(nn.BCEWithLogitsLoss(), gamma=1.5)
def __init__(self, loss_fcn, gamma=1.5, alpha=0.25):
super().__init__()
self.loss_fcn = loss_fcn # must be nn.BCEWithLogitsLoss()
self.gamma = gamma
self.alpha = alpha
self.reduction = loss_fcn.reduction
self.loss_fcn.reduction = "none" # required to apply FL to each element
def forward(self, pred, true):
loss = self.loss_fcn(pred, true)
# p_t = torch.exp(-loss)
# loss *= self.alpha * (1.000001 - p_t) ** self.gamma # non-zero power for gradient stability
# TF implementation https://github.com/tensorflow/addons/blob/v0.7.1/tensorflow_addons/losses/focal_loss.py
pred_prob = torch.sigmoid(pred) # prob from logits
p_t = true * pred_prob + (1 - true) * (1 - pred_prob)
alpha_factor = true * self.alpha + (1 - true) * (1 - self.alpha)
modulating_factor = (1.0 - p_t) ** self.gamma
loss *= alpha_factor * modulating_factor
if self.reduction == "mean":
return loss.mean()
elif self.reduction == "sum":
return loss.sum()
else: # 'none'
return loss
class BboxLoss(nn.Module):
def __init__(self, reg_max, use_dfl=False):
super().__init__()
self.reg_max = reg_max
self.use_dfl = use_dfl
def forward(self, pred_dist, pred_bboxes, anchor_points, target_bboxes, target_scores, target_scores_sum, fg_mask, h=None, w=None):
# iou loss
bbox_mask = fg_mask.unsqueeze(-1).repeat([1, 1, 4]) # (b, h*w, 4)
pred_bboxes_pos = torch.masked_select(pred_bboxes, bbox_mask).view(-1, 4)
target_bboxes_pos = torch.masked_select(target_bboxes, bbox_mask).view(-1, 4)
bbox_weight = torch.masked_select(target_scores.sum(-1), fg_mask).unsqueeze(-1)
iou = bbox_iou(pred_bboxes_pos, target_bboxes_pos, xywh=False, CIoU=False, DIoU=False, GIoU=False,
Inner=False, Focaleriou=False, MDPIoU=True, feat_h=h, feat_w=w)
loss_iou = 1.0 - iou
loss_iou *= bbox_weight
loss_iou = loss_iou.sum() / target_scores_sum
# dfl loss
if self.use_dfl:
dist_mask = fg_mask.unsqueeze(-1).repeat([1, 1, (self.reg_max + 1) * 4])
pred_dist_pos = torch.masked_select(pred_dist, dist_mask).view(-1, 4, self.reg_max + 1)
target_ltrb = bbox2dist(anchor_points, target_bboxes, self.reg_max)
target_ltrb_pos = torch.masked_select(target_ltrb, bbox_mask).view(-1, 4)
loss_dfl = self._df_loss(pred_dist_pos, target_ltrb_pos) * bbox_weight
loss_dfl = loss_dfl.sum() / target_scores_sum
else:
loss_dfl = torch.tensor(0.0).to(pred_dist.device)
return loss_iou, loss_dfl, iou
def _df_loss(self, pred_dist, target):
target_left = target.to(torch.long)
target_right = target_left + 1
weight_left = target_right.to(torch.float) - target
weight_right = 1 - weight_left
loss_left = F.cross_entropy(pred_dist.view(-1, self.reg_max + 1), target_left.view(-1), reduction="none").view(
target_left.shape) * weight_left
loss_right = F.cross_entropy(pred_dist.view(-1, self.reg_max + 1), target_right.view(-1),
reduction="none").view(target_left.shape) * weight_right
return (loss_left + loss_right).mean(-1, keepdim=True)
class ComputeLoss:
# Compute losses
def __init__(self, model, use_dfl=True):
device = next(model.parameters()).device # get model device
h = model.hyp # hyperparameters
# Define criteria
BCEcls = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h["cls_pw"]], device=device), reduction='none')
# Class label smoothing https://arxiv.org/pdf/1902.04103.pdf eqn 3
self.cp, self.cn = smooth_BCE(eps=h.get("label_smoothing", 0.0)) # positive, negative BCE targets
# Focal loss
g = h["fl_gamma"] # focal loss gamma
if g > 0:
BCEcls = FocalLoss(BCEcls, g)
m = de_parallel(model).model[-1] # Detect() module
self.balance = {3: [4.0, 1.0, 0.4]}.get(m.nl, [4.0, 1.0, 0.25, 0.06, 0.02]) # P3-P7
self.BCEcls = BCEcls
self.hyp = h
self.stride = m.stride # model strides
self.nc = m.nc # number of classes
self.nl = m.nl # number of layers
self.no = m.no
self.reg_max = m.reg_max
self.device = device
self.assigner = TaskAlignedAssigner(topk=int(os.getenv('YOLOM', 10)),
num_classes=self.nc,
alpha=float(os.getenv('YOLOA', 0.5)),
beta=float(os.getenv('YOLOB', 6.0)))
self.assigner2 = TaskAlignedAssigner(topk=int(os.getenv('YOLOM', 10)),
num_classes=self.nc,
alpha=float(os.getenv('YOLOA', 0.5)),
beta=float(os.getenv('YOLOB', 6.0)))
self.bbox_loss = BboxLoss(m.reg_max - 1, use_dfl=use_dfl).to(device)
self.bbox_loss2 = BboxLoss(m.reg_max - 1, use_dfl=use_dfl).to(device)
self.proj = torch.arange(m.reg_max).float().to(device) # / 120.0
self.use_dfl = use_dfl
def preprocess(self, targets, batch_size, scale_tensor):
if targets.shape[0] == 0:
out = torch.zeros(batch_size, 0, 5, device=self.device)
else:
i = targets[:, 0] # image index
_, counts = i.unique(return_counts=True)
out = torch.zeros(batch_size, counts.max(), 5, device=self.device)
for j in range(batch_size):
matches = i == j
n = matches.sum()
if n:
out[j, :n] = targets[matches, 1:]
out[..., 1:5] = xywh2xyxy(out[..., 1:5].mul_(scale_tensor))
return out
def bbox_decode(self, anchor_points, pred_dist):
if self.use_dfl:
b, a, c = pred_dist.shape # batch, anchors, channels
pred_dist = pred_dist.view(b, a, 4, c // 4).softmax(3).matmul(self.proj.type(pred_dist.dtype))
# pred_dist = pred_dist.view(b, a, c // 4, 4).transpose(2,3).softmax(3).matmul(self.proj.type(pred_dist.dtype))
# pred_dist = (pred_dist.view(b, a, c // 4, 4).softmax(2) * self.proj.type(pred_dist.dtype).view(1, 1, -1, 1)).sum(2)
return dist2bbox(pred_dist, anchor_points, xywh=False)
def __call__(self, p, targets, img=None, epoch=0):
loss = torch.zeros(3, device=self.device) # box, cls, dfl
feats = p[1][0] if isinstance(p, tuple) else p[0]
feats2 = p[1][1] if isinstance(p, tuple) else p[1]
pred_distri, pred_scores = torch.cat([xi.view(feats[0].shape[0], self.no, -1) for xi in feats], 2).split(
(self.reg_max * 4, self.nc), 1)
pred_scores = pred_scores.permute(0, 2, 1).contiguous()
pred_distri = pred_distri.permute(0, 2, 1).contiguous()
pred_distri2, pred_scores2 = torch.cat([xi.view(feats2[0].shape[0], self.no, -1) for xi in feats2], 2).split(
(self.reg_max * 4, self.nc), 1)
pred_scores2 = pred_scores2.permute(0, 2, 1).contiguous()
pred_distri2 = pred_distri2.permute(0, 2, 1).contiguous()
dtype = pred_scores.dtype
batch_size, grid_size = pred_scores.shape[:2]
imgsz = torch.tensor(feats[0].shape[2:], device=self.device, dtype=dtype) * self.stride[0] # image size (h,w)
anchor_points, stride_tensor = make_anchors(feats, self.stride, 0.5)
# targets
targets = self.preprocess(targets, batch_size, scale_tensor=imgsz[[1, 0, 1, 0]])
gt_labels, gt_bboxes = targets.split((1, 4), 2) # cls, xyxy
mask_gt = gt_bboxes.sum(2, keepdim=True).gt_(0)
# pboxes
pred_bboxes = self.bbox_decode(anchor_points, pred_distri) # xyxy, (b, h*w, 4)
pred_bboxes2 = self.bbox_decode(anchor_points, pred_distri2) # xyxy, (b, h*w, 4)
target_labels, target_bboxes, target_scores, fg_mask = self.assigner(
pred_scores.detach().sigmoid(),
(pred_bboxes.detach() * stride_tensor).type(gt_bboxes.dtype),
anchor_points * stride_tensor,
gt_labels,
gt_bboxes,
mask_gt)
target_labels2, target_bboxes2, target_scores2, fg_mask2 = self.assigner2(
pred_scores2.detach().sigmoid(),
(pred_bboxes2.detach() * stride_tensor).type(gt_bboxes.dtype),
anchor_points * stride_tensor,
gt_labels,
gt_bboxes,
mask_gt)
target_bboxes /= stride_tensor
target_scores_sum = max(target_scores.sum(), 1)
target_bboxes2 /= stride_tensor
target_scores_sum2 = max(target_scores2.sum(), 1)
# cls loss
# loss[1] = self.varifocal_loss(pred_scores, target_scores, target_labels) / target_scores_sum # VFL way
loss[1] = self.BCEcls(pred_scores, target_scores.to(dtype)).sum() / target_scores_sum # BCE
loss[1] *= 0.25
loss[1] += self.BCEcls(pred_scores2, target_scores2.to(dtype)).sum() / target_scores_sum2 # BCE
# bbox loss
if fg_mask.sum():
loss[0], loss[2], iou = self.bbox_loss(pred_distri,
pred_bboxes,
anchor_points,
target_bboxes,
target_scores,
target_scores_sum,
fg_mask, imgsz[0], imgsz[1])
loss[0] *= 0.25
loss[2] *= 0.25
if fg_mask2.sum():
loss0_, loss2_, iou2 = self.bbox_loss2(pred_distri2,
pred_bboxes2,
anchor_points,
target_bboxes2,
target_scores2,
target_scores_sum2,
fg_mask2, imgsz[0], imgsz[1])
loss[0] += loss0_
loss[2] += loss2_
loss[0] *= 7.5 # box gain
loss[1] *= 0.5 # cls gain
loss[2] *= 1.5 # dfl gain
return loss.sum() * batch_size, loss.detach() # loss(box, cls, dfl)
class ComputeLossLH:
# Compute losses
def __init__(self, model, use_dfl=True):
device = next(model.parameters()).device # get model device
h = model.hyp # hyperparameters
# Define criteria
BCEcls = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h["cls_pw"]], device=device), reduction='none')
# Class label smoothing https://arxiv.org/pdf/1902.04103.pdf eqn 3
self.cp, self.cn = smooth_BCE(eps=h.get("label_smoothing", 0.0)) # positive, negative BCE targets
# Focal loss
g = h["fl_gamma"] # focal loss gamma
if g > 0:
BCEcls = FocalLoss(BCEcls, g)
m = de_parallel(model).model[-1] # Detect() module
self.balance = {3: [4.0, 1.0, 0.4]}.get(m.nl, [4.0, 1.0, 0.25, 0.06, 0.02]) # P3-P7
self.BCEcls = BCEcls
self.hyp = h
self.stride = m.stride # model strides
self.nc = m.nc # number of classes
self.nl = m.nl # number of layers
self.no = m.no
self.reg_max = m.reg_max
self.device = device
self.assigner = TaskAlignedAssigner(topk=int(os.getenv('YOLOM', 10)),
num_classes=self.nc,
alpha=float(os.getenv('YOLOA', 0.5)),
beta=float(os.getenv('YOLOB', 6.0)))
self.bbox_loss = BboxLoss(m.reg_max - 1, use_dfl=use_dfl).to(device)
self.proj = torch.arange(m.reg_max).float().to(device) # / 120.0
self.use_dfl = use_dfl
def preprocess(self, targets, batch_size, scale_tensor):
if targets.shape[0] == 0:
out = torch.zeros(batch_size, 0, 5, device=self.device)
else:
i = targets[:, 0] # image index
_, counts = i.unique(return_counts=True)
out = torch.zeros(batch_size, counts.max(), 5, device=self.device)
for j in range(batch_size):
matches = i == j
n = matches.sum()
if n:
out[j, :n] = targets[matches, 1:]
out[..., 1:5] = xywh2xyxy(out[..., 1:5].mul_(scale_tensor))
return out
def bbox_decode(self, anchor_points, pred_dist):
if self.use_dfl:
b, a, c = pred_dist.shape # batch, anchors, channels
pred_dist = pred_dist.view(b, a, 4, c // 4).softmax(3).matmul(self.proj.type(pred_dist.dtype))
# pred_dist = pred_dist.view(b, a, c // 4, 4).transpose(2,3).softmax(3).matmul(self.proj.type(pred_dist.dtype))
# pred_dist = (pred_dist.view(b, a, c // 4, 4).softmax(2) * self.proj.type(pred_dist.dtype).view(1, 1, -1, 1)).sum(2)
return dist2bbox(pred_dist, anchor_points, xywh=False)
def __call__(self, p, targets, img=None, epoch=0):
loss = torch.zeros(3, device=self.device) # box, cls, dfl
feats = p[1][0] if isinstance(p, tuple) else p[0]
feats2 = p[1][1] if isinstance(p, tuple) else p[1]
pred_distri, pred_scores = torch.cat([xi.view(feats[0].shape[0], self.no, -1) for xi in feats], 2).split(
(self.reg_max * 4, self.nc), 1)
pred_scores = pred_scores.permute(0, 2, 1).contiguous()
pred_distri = pred_distri.permute(0, 2, 1).contiguous()
pred_distri2, pred_scores2 = torch.cat([xi.view(feats2[0].shape[0], self.no, -1) for xi in feats2], 2).split(
(self.reg_max * 4, self.nc), 1)
pred_scores2 = pred_scores2.permute(0, 2, 1).contiguous()
pred_distri2 = pred_distri2.permute(0, 2, 1).contiguous()
dtype = pred_scores.dtype
batch_size, grid_size = pred_scores.shape[:2]
imgsz = torch.tensor(feats[0].shape[2:], device=self.device, dtype=dtype) * self.stride[0] # image size (h,w)
anchor_points, stride_tensor = make_anchors(feats, self.stride, 0.5)
# targets
targets = self.preprocess(targets, batch_size, scale_tensor=imgsz[[1, 0, 1, 0]])
gt_labels, gt_bboxes = targets.split((1, 4), 2) # cls, xyxy
mask_gt = gt_bboxes.sum(2, keepdim=True).gt_(0)
# pboxes
pred_bboxes = self.bbox_decode(anchor_points, pred_distri) # xyxy, (b, h*w, 4)
pred_bboxes2 = self.bbox_decode(anchor_points, pred_distri2) # xyxy, (b, h*w, 4)
target_labels, target_bboxes, target_scores, fg_mask = self.assigner(
pred_scores2.detach().sigmoid(),
(pred_bboxes2.detach() * stride_tensor).type(gt_bboxes.dtype),
anchor_points * stride_tensor,
gt_labels,
gt_bboxes,
mask_gt)
target_bboxes /= stride_tensor
target_scores_sum = target_scores.sum()
# cls loss
# loss[1] = self.varifocal_loss(pred_scores, target_scores, target_labels) / target_scores_sum # VFL way
loss[1] = self.BCEcls(pred_scores, target_scores.to(dtype)).sum() / target_scores_sum # BCE
loss[1] *= 0.25
loss[1] += self.BCEcls(pred_scores2, target_scores.to(dtype)).sum() / target_scores_sum # BCE
# bbox loss
if fg_mask.sum():
loss[0], loss[2], iou = self.bbox_loss(pred_distri,
pred_bboxes,
anchor_points,
target_bboxes,
target_scores,
target_scores_sum,
fg_mask)
loss[0] *= 0.25
loss[2] *= 0.25
if fg_mask.sum():
loss0_, loss2_, iou2 = self.bbox_loss(pred_distri2,
pred_bboxes2,
anchor_points,
target_bboxes,
target_scores,
target_scores_sum,
fg_mask)
loss[0] += loss0_
loss[2] += loss2_
loss[0] *= 7.5 # box gain
loss[1] *= 0.5 # cls gain
loss[2] *= 1.5 # dfl gain
return loss.sum() * batch_size, loss.detach() # loss(box, cls, dfl)
到此,本文分享的内容就结束啦!遇见便是缘,感恩遇见!!!💛💙 💜 ❤️ 💚