完美字符串
题目描述
你可能见过下面这一句英文:
"The quick brown fox jumps over the lazy dog."
短短的一句话就包含了所有 2626 个英文字母!因此这句话广泛地用于字体效果的展示。更短的还有:
"The five boxing wizards jump quickly."
所以你很好奇:还有没有更多这样包含所有 2626 个英文字母的句子?于是你用爬虫在互联网上爬取了许多英文文本,并且提取出了其中的单词。你现在希望从一个很长的单词序列中找出一段连续出现的单词,它满足:
- 所有 2626 个英文字母都至少出现一次;
- 长度尽可能短,即包含的字母总数尽可能少。
输入
输入的第一行包含一个整数 �n,代表单词序列的长度,即单词的数量。
输入的第二行包含 �n 个空格分隔的英文单词(单词仅由小写字母构成)。输入数据保证每个小写英文字母都至少出现一次。
输出
输出一行一个整数,是你找到的单词序列中的字母总数。
样例输入1
13 there is a quick brown fox jumping over the lazy dog and cat
样例输出1
37
提示
最短满足条件的单词序列是 "is a quick brown fox jumping over the lazy dog",共有 3737 个字母。
对于 40%40% 的数据,满足 �≤100n≤100;
对于 100%100% 的数据,满足 1≤�≤100,0001≤n≤100,000。每个单词的长度不超过 1010 个字符,且单词全部由小写英文字母 a-za-z 构成。
# coding=utf-8
n = int(input())
list_string = list(map(str, input().split()))
sum_min = 1000000
for i in range(n - 2):
begin, sum_this = i, 0
dct = {}
while len(dct) < 26 and begin < n:
for j in list_string[begin]:
for index in range(len(j)):
if j[index] in dct.keys():
dct[j[index]] += 1
else:
dct[j[index]] = 1
sum_this += 1
begin += 1
if sum_this < sum_min and len(dct) == 26:
sum_min = sum_this
print(sum_min)扫雷游戏

# coding=utf-8
def the_sum(lst, hang_max, lie_max, index_h, index_l):
sum1 = 0
if 0 <= index_h - 1 < hang_max and lst[index_h - 1][index_l] == '*':
sum1 += 1
if 0 <= index_h + 1 < hang_max and lst[index_h + 1][index_l] == '*':
sum1 += 1
if 0 <= index_l + 1 < lie_max and lst[index_h][index_l + 1] == '*':
sum1 += 1
if 0 <= index_l - 1 < lie_max and lst[index_h][index_l - 1] == '*':
sum1 += 1
if 0 <= index_h - 1 < hang_max and 0 <= index_l + 1 < lie_max and lst[index_h - 1][index_l + 1] == '*':
sum1 += 1
if 0 <= index_h - 1 < hang_max and 0 <= index_l - 1 < lie_max and lst[index_h - 1][index_l - 1] == '*':
sum1 += 1
if 0 <= index_h + 1 < hang_max and 0 <= index_l + 1 < lie_max and lst[index_h + 1][index_l + 1] == '*':
sum1 += 1
if 0 <= index_h + 1 < hang_max and 0 <= index_l - 1 < lie_max and lst[index_h + 1][index_l - 1] == '*':
sum1 += 1
return sum1
n, m = map(int, input().split())
lst_total = []
for i in range(n):
lst_one = input()
lst_total.append(lst_one)
lst_total_print = []
for i in range(n):
lst_one_print = []
for j in range(m):
if lst_total[i][j] == '*':
lst_one_print.append('*')
else:
k = the_sum(lst_total, n, m, i, j)
lst_one_print.append(k)
lst_total_print.append(lst_one_print)
for i in lst_total_print:
for j in i:
print(j, end='')
print()A-B数对

# coding=utf-8
N, C = map(int, input().split())
lst = list(map(int, input().split()))
count = 0
for i in lst:
for j in lst :
if i - j == C and i != j:
count += 1
print(count)赛前准备

感觉这道题的检测机制有点问题,可能是随机情况太多了,不可能和测试案例一模一样吧,尝试了很久都通过不了,不过还是有学到东西的
知识点:
1.对于range()函数,如果想生成逆序,必须是这种格式range(11,1,-1),不然无法正常生成
2.对于不在意的变量,就是我们不需要用到该变量名的时候可以用_代替
3.列表推导式可以直接生成(这道题不生成列表也可以,只是这样更直观)
解题思路如注释所示
t = int(input())
for i in range(t): # for _ in range(t):
n, k = map(int, input().split())
# n=6
# 6 5 4 3 2 1
# k=2
# 1 2 6 5 4 3
lst = [x for x in range(n, 0, -1)]
if k != 0:
for head in range(0, k):
print(lst[n - head - 1], end=' ')
for yuan in range(0, n - k):
print(lst[yuan], end=' ')
else:
for one in lst:
print(one, end=' ')
print()精密计时
事实证明使用long long int 不会超过范围

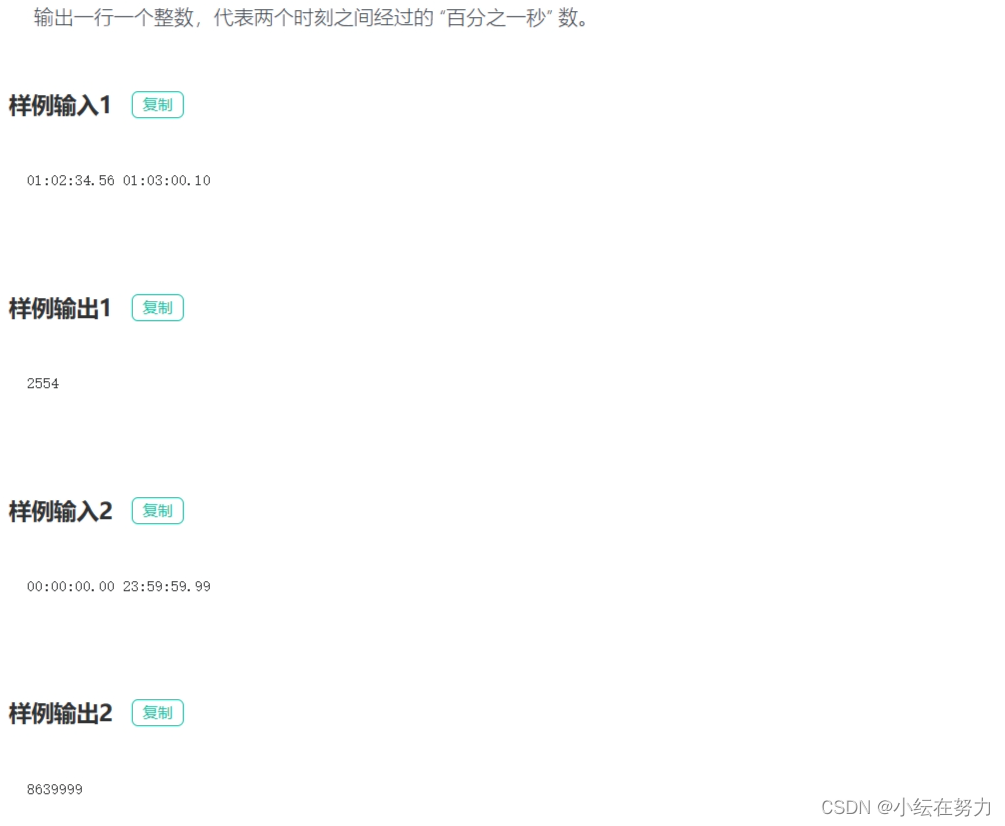

#include<stdio.h>
long long int the_sum(int a1, int b1, int c1){
long long int sum;
//总共有多少秒
sum=c1+b1*60+a1*3600;
return sum;
}
int main(){
int a1,b1,c1,d1,a2,b2,c2,d2;
long long int sum1,sum2,total;
scanf("%d:%d:%d.%d %d:%d:%d.%d",&a1,&b1,&c1,&d1,&a2,&b2,&c2,&d2);
sum1=the_sum(a1,b1,c1);
sum2=the_sum(a2,b2,c2);
total=(sum2-sum1)*100+(d2-d1);
printf("%lld",total);
return 0;
}