论文标题:An Analysis of Linear Time Series Forecasting Models
作者: William Toner, Luke Darlow
机构:爱丁堡大学(Edinburgh),华为研究中心(爱丁堡)
论文链接:https://arxiv.org/abs//2403.14587
Cool Paper:https://papers.cool/arxiv/2403.14587
TL;DR:本文分析了多种线性时间序列预测模型,发现它们在功能上与标准线性回归等价,且闭式解通常优于梯度下降训练的模型。
关键词:线性模型、时间序列预测、功能等价性、模型比较、闭式解、线性回归、特征归一化、DLinear(AAAI23)、FITS(ICLR24 Spotlight)、RLinear、NLinear(AAAI23)。
注:这篇论文理论推导很多,AI论文速读只能了解冰山一角,笔者能力有限,推导还望各位读者阅读原文细细品鉴。

🌟【紧跟前沿】“时空探索之旅”与你一起探索时空奥秘!🚀
欢迎大家关注时空探索之旅
摘要
尽管线性模型很简单,但即使与更深、更昂贵的模型进行比较,线性模型在时间序列预测中也表现良好。 人们已经提出了线性模型的许多变体,通常包括某种形式的特征归一化,以提高模型的泛化能力。 在本文中,我们分析了使用这些线性模型架构可表达的函数集。 通过这样做,我们证明了用于时间序列预测的线性模型的几种流行变体与标准的无约束线性回归是等效的并且在功能上没有区别。 我们描述每个线性变体的模型类。 我们证明每个模型都可以被重新解释为在适当增强的特征集上的无约束线性回归,因此在使用均方损失函数时允许封闭形式的解决方案。 我们提供的实验证据表明,所检查的模型学习几乎相同的解决方案,并最终证明,在 72% 的测试设置中,更简单的封闭式解决方案是出色的预测器。
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是对线性时间序列预测模型的分析。尽管深度学习模型在许多领域取得了显著的成功,但在时间序列预测方面,简单的线性模型仍然表现出色,有时甚至优于复杂的深度模型。论文中指出,已经提出了多种线性模型的变体,这些变体通常包括某种形式的特征归一化,以提高模型的泛化能力。然而,这些变体之间的实际性能差异并不明显。
论文的主要目标是:
- 从数学角度深入分析几种流行的线性时间序列预测模型。
- 证明这些模型在功能上基本上是等价的,并且与标准的无约束线性回归无法区分。
- 通过实验证据表明这些模型在训练时倾向于学习几乎相同的解。
- 展示在使用均方损失函数时,闭式解(closed-form solutions)通常是优于使用梯度下降训练的模型。
总的来说,论文旨在提供对线性时间序列预测模型的深入数学分析,并证明从功能和性能的角度来看,这些模型之间并没有实质性的差异,它们都可以被视为弱约束的线性回归模型。
Q: 有哪些相关研究?
A: 这篇论文提到了以下相关研究:
- Zeng et al. (2023): 这项工作引入了两种线性模型,DLinear 和 NLinear,它们已经成为时间序列预测领域广泛使用的基准。这项研究表明线性模型在某些情况下与复杂的Transformer架构相当或更优。
- Reversible Instance Normalisation (RevInv): 这是一种特征归一化技术,通常可以提高时间序列预测的性能。它通过对输入特征进行标准化(零均值、单位标准差),然后在模型的最后步骤中逆转这一标准化过程(可选的学习仿射变换)。
- Li et al. (2023): 这项研究重新审视了长期时间序列预测,探讨了RevInv和通道独立性(Channel Independence, CI)对线性模型的影响。他们提出了RLinear模型,该模型使用RevInv,并且测试了CI对一些数据集(通常具有更多通道和/或复杂性)的泛化能力的提升。
- Xu et al. (2023): 最近提出了FITS,这是一个在频域中操作的线性时间序列模型,包括一个可选的高频过滤组件来减小模型的足迹。FITS首先计算实离散傅里叶变换(Real Discrete Fourier Transform, RFT),应用一个复杂的线性映射,然后将结果反转回到时域。FITS的性能令人印象深刻,在最佳超参数设置下达到或接近最先进的性能。
这些研究为论文提供了背景和动机,论文的分析建立在这些相关工作的基础之上,进一步探讨了线性模型在时间序列预测中的表达能力和实际性能。
Q: 论文如何解决这个问题?

A: 论文通过以下步骤解决对线性时间序列预测模型的分析问题:
- 模型分类:首先定义了不同的线性模型架构,包括DLinear、FITS、RLinear和NLinear,并描述了它们的关键特点。
- 数学分析:深入分析了每个模型架构能够表达的函数集合(模型类)。论文展示了这些模型类要么是无约束的线性回归,要么是通过特征增强弱约束的线性回归。
- 等价性证明:通过数学证明,论文表明了几种流行的线性模型变体在功能上是等价的,即它们描述的参数化函数族是相同的(在数据归一化的选择上有所差异)。
- 实验验证:提供了实验证据来支持理论分析,显示在相同的数据上训练时,所有模型都倾向于学习几乎相同的解。这包括比较不同模型学习到的权重矩阵和偏差参数。
- 性能比较:比较了闭式解(ordinary least squares, OLS)和使用随机梯度下降(stochastic gradient descent, SGD)训练的模型的性能。论文发现,在72%的测试设置中,简单的闭式解在预测性能上优于或至少与现有的模型相当。
- 讨论和局限性:论文讨论了分析的局限性,并提出了未来工作的方向,例如探索FITS技术压缩OLS解的可能性。
总的来说,论文通过结合理论分析和实验验证,提供了对线性时间序列预测模型的深入理解,并挑战了关于这些模型性能和复杂性的一些常见假设。
一些结论:





Q: 论文做了哪些实验?
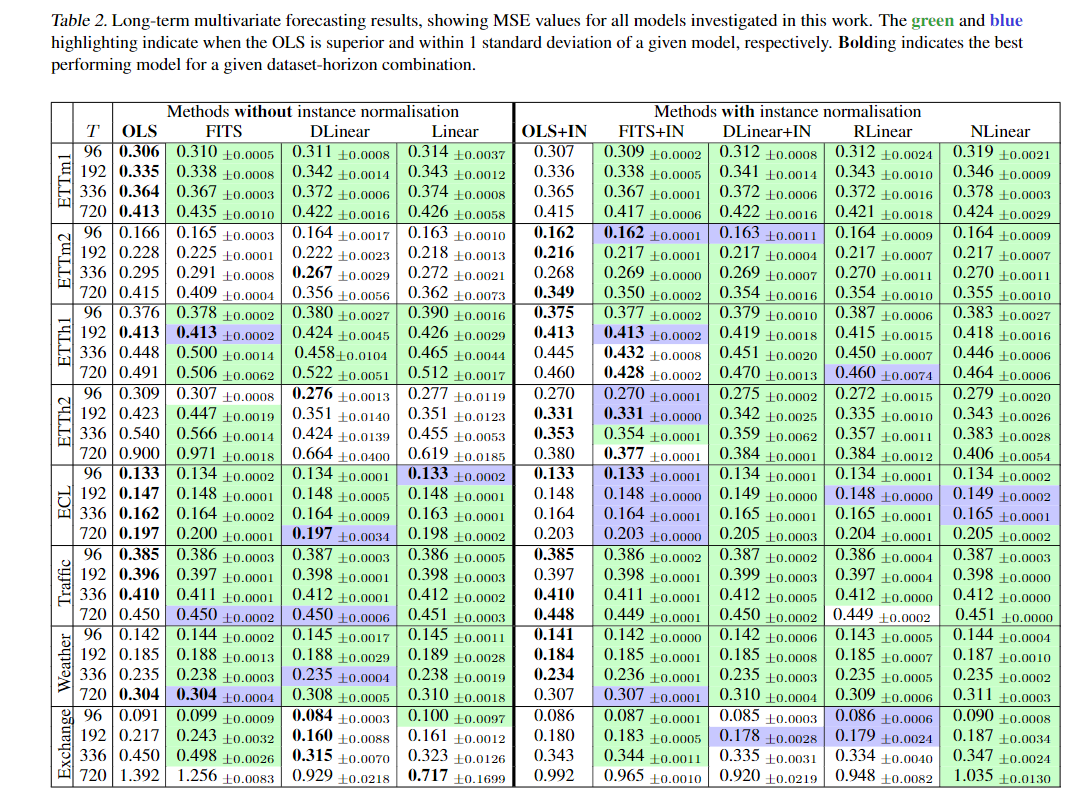
A: 论文进行了以下实验来支持其分析和论点:
- 权重矩阵比较:通过可视化和比较不同训练后的线性模型变体(包括RLinear、NLinear、DLinear+IN和FITS+IN)的内部权重矩阵,论文展示了这些模型在学习过程中趋于相似的权重矩阵。这与论文中提出的假设一致,即不同的模型架构在功能上是等价的。
- 余弦相似度分析:论文追踪了在训练过程中这些模型的权重矩阵与其对应的闭式解(OLS+IN)之间的余弦相似度。这进一步证明了所有模型的权重都趋向于与闭式解相匹配。
- 预测结果比较:展示了这些模型在训练50个周期后在ETTh1数据集上的预测结果,并指出虽然模型之间存在微妙的差异,但预测结果普遍相似。
- 偏差参数比较:比较了不同模型学习到的偏差参数,并发现FITS+IN的偏差参数与其他模型有显著不同,这与论文的理论分析相符。
- 性能基准测试:在8个标准的时间序列基准数据集上评估了DLinear、FITS、RLinear、NLinear和线性模型(Linear)的性能,并包括有无实例归一化(Instance Normalisation)的变体。论文记录了这些模型在不同预测范围(96, 192, 336, 和 720)下的均方误差(Mean Squared Error, MSE)。
- 闭式解与SGD训练模型的性能对比:论文比较了闭式解(OLS)和使用随机梯度下降(SGD)训练的模型在不同数据集和预测范围的性能,发现OLS在72%的设置中性能更好或相当。
这些实验旨在验证论文中的理论发现,即不同的线性时间序列预测模型在实践中表现出相似的性能,并且闭式解通常是一个有效的预测器。
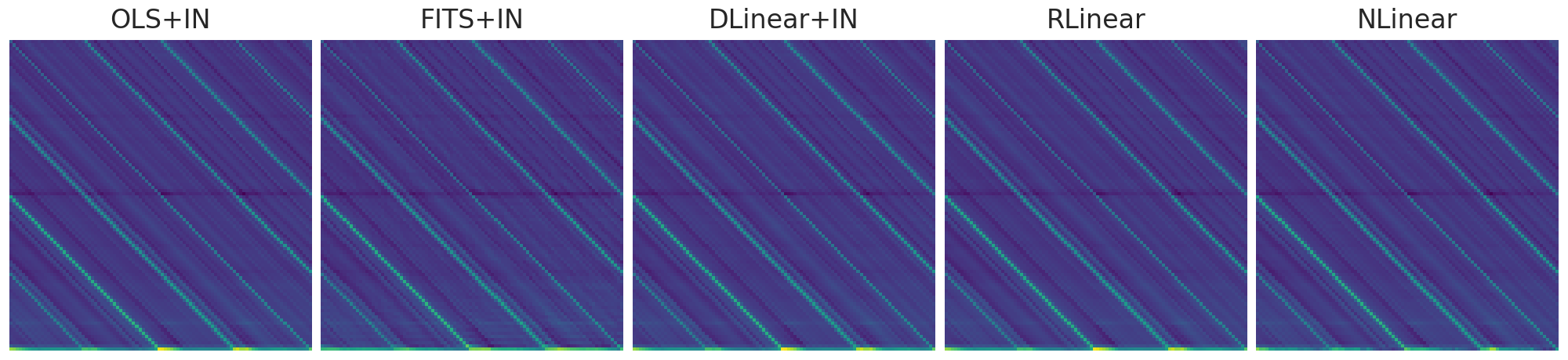
这个图显示了经过50轮训练后,所有四个模型的cropped weight矩阵与实例标准化(instance normalization),并列相应闭式解(最左边)。这些数据显示了基础模型的相似程度。这些细微的差别在一定程度上影响了预测(如下图)。
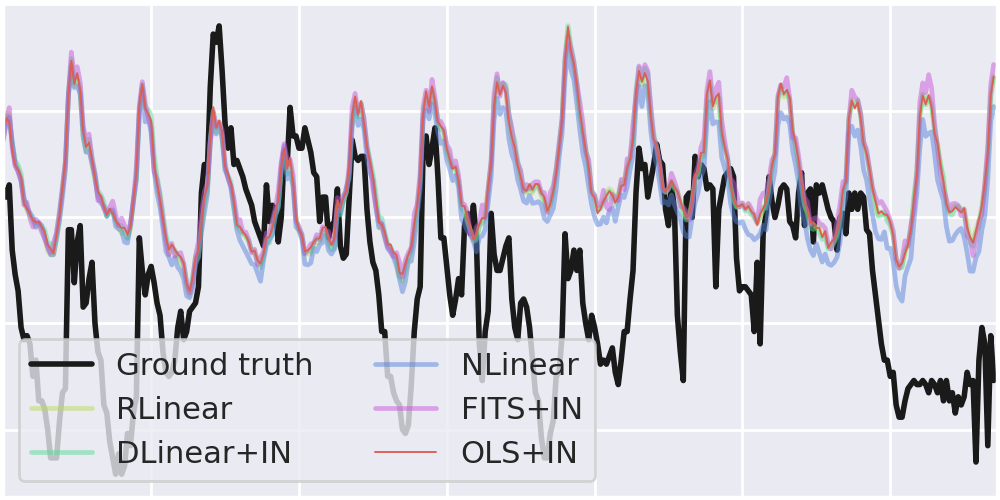
不同模型,预测结果有细微差别
Q: 有什么可以进一步探索的点?
A: 论文在讨论部分提出了一些可以进一步探索的点,包括:
- 模型压缩:FITS模型允许在训练期间通过忽略高频成分来压缩模型。论文提出,可以探索将FITS技术应用于压缩闭式解(OLS)解决方案的可能性,这可能会在保持预测性能的同时减少模型的复杂性。
- 多通道设置下的模型差异:论文提到,尽管在单通道设置中线性+RevIN和线性+IN模型是相同的,但在多通道设置下,如果允许每个通道有单独的仿射参数,那么RevIN可能会为每个通道产生略微不同的偏差。这值得进一步研究。
- 低通滤波器(LPF)的影响:论文中忽略了FITS模型中的LPF,因为它通常会降低性能。未来可以研究在应用LPF时,模型类如何受到限制,以及这是否影响模型的等价性。
- 模型的泛化能力:虽然论文中的实验表明,不同的线性模型在特定的数据集上表现出相似的预测性能,但是这些模型的泛化能力在不同的数据集或领域中可能会有所不同。未来的研究可以探索这些模型在更广泛的应用场景中的表现。
- 模型的可解释性:线性模型的一个优点是它们通常比深度学习模型更易于解释。未来的研究可以探索如何提高线性模型的可解释性,以及如何利用这一点来提高模型的透明度和可信度。
- 模型的优化策略:论文提到,尽管所有模型都使用均方误差(MSE)作为损失函数,但它们的参数化和初始化方式不同,这可能会影响模型的收敛速度和早期停止的影响。未来的研究可以探索不同的优化策略和正则化技术,以进一步提高线性时间序列预测模型的性能。
这些潜在的研究方向可以帮助深化对线性时间序列预测模型的理解,并可能揭示新的方法来改进这些模型的性能和应用范围。
Q: 总结一下论文的主要内容
A: 这篇论文主要分析了线性时间序列预测模型,并探讨了它们的功能等价性和实际性能。以下是论文的主要内容总结:
- 研究背景:尽管深度学习模型在许多领域取得了成功,但在时间序列预测任务中,简单的线性模型仍然非常有效,有时甚至优于复杂的深度模型。近年来,出现了多种线性模型变体,它们通过特征归一化等方式提高了模型的泛化能力。
- 主要目标:论文旨在深入分析几种流行的线性时间序列预测模型,包括DLinear、FITS、RLinear和NLinear,并证明这些模型在功能上与标准线性回归无法区分。
- 理论分析:论文通过数学证明,展示了这些线性模型变体实际上都是等价的,它们的参数化函数族相同,且都可以被重新解释为无约束或弱约束的线性回归。
- 实验验证:论文提供了实验证据,显示这些模型在相同数据上训练时,倾向于学习几乎相同的解。此外,论文还比较了闭式解(如普通最小二乘法,OLS)和使用梯度下降训练的模型的性能,发现在大多数情况下,闭式解表现得更好。
- 研究贡献:论文的主要贡献包括数学证明、实验证据和定量证据,这些证据表明在时间序列预测任务中,不同的线性模型在功能和性能上并没有显著差异。
- 未来工作:论文讨论了其分析的局限性,并提出了未来研究的方向,例如探索FITS技术在压缩OLS解中的应用潜力。
:论文的主要贡献包括数学证明、实验证据和定量证据,这些证据表明在时间序列预测任务中,不同的线性模型在功能和性能上并没有显著差异。
6. 未来工作:论文讨论了其分析的局限性,并提出了未来研究的方向,例如探索FITS技术在压缩OLS解中的应用潜力。
总的来说,这篇论文挑战了关于线性时间序列预测模型性能和复杂性的一些常见假设,并提供了对这些模型的深入理解,这可能有助于改进未来的预测模型和策略。
🌟【紧跟前沿】“时空探索之旅”与你一起探索时空奥秘!🚀
欢迎大家关注时空探索之旅