目录
前言
一、概述
二、Conversation Buffer
三、Conversation Buffer Window
四、Conversation Summary
五、Conversation Summary Buffer
总结
前言
大模型技术在理解和生成自然语言方面表现出了惊人的能力。因此,为了实现长期的记忆保持和知识累积,有效地管理历史对话数据变得至关重要。Langchain框架中的Memory模块便是为此设计的核心组件,它不仅增强了模型的记忆能力,还确保了知识的持续保留。接下来,我们将深入探讨该模块的架构和功能特性。
一、概述
在AI大模型应用开发中,Langchain框架的Memory模块扮演着至关重要的角色。作为模型记忆增强与知识保留的关键,它通过一系列高效的机制来管理和存储历史对话内容,为未来的查询和分析提供了便利。
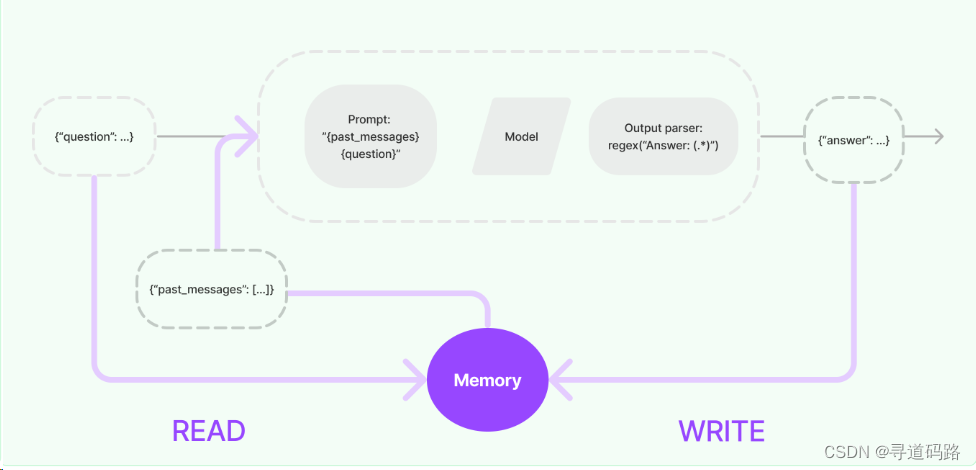
总体流程架构涉及以下几个关键步骤:
- READ-查询对话:在接收到初始用户输入后,但在执行核心逻辑之前,Langchain将从其内存系统中检索并整合用户输入的信息。
- WRITE-存储对话:在执行核心逻辑之后,但在返回答案之前,Langchain会将当前运行的输入和输出写入内存,以便在未来的运行中引用它们。
Memory模块支持多种记录类型,包括但不限于:
Conversation Buffer:将之前所有的对话历史记录存储在内存中。
Conversation Buffer Window:仅存储最近k组的对话历史记录。
Conversation Summary:对之前的历史对话进行摘要总结后存储。
Conversation Summary Buffer:基于token长度决定何时进行摘要总结并存储。
Conversation Token Buffer:根据token长度决定存储多少对话历史记录。
Backed by a Vector Store:基于向量的数据记录,实现持久化存储。
二、Conversation Buffer
基于内存缓存冲区进行所有对话记忆管理。
1.直接从内存缓存区中存取
from langchain.memory import ConversationBufferMemory
#初始化记忆管理模式
memory = ConversationBufferMemory()
memory.save_context({"input": "hi"}, {"output": "whats up"})
#%%
memory.load_memory_variables({})
#输出:{'history': 'Human: hi\nAI: whats up'}2.以消息列表的形式输出return_messages=True
memory = ConversationBufferMemory(return_messages=True)
memory.save_context({"input": "hi"}, {"output": "whats up"})
memory.load_memory_variables({})
#输出:{'history': [HumanMessage(content='hi'), AIMessage(content='whats up')]}3.在Chain链中运用
from langchain_openai import ChatOpenAI
from langchain.chains import ConversationChain
llm = ChatOpenAI(model_name="gpt-3.5-turbo-0125",temperature=0)
conversation = ConversationChain(
llm=llm,# 传入语言模型
verbose=True,# verbose参数为True,表示在控制台输出详细信息
memory=ConversationBufferMemory()# 初始化了对话的记忆管理方式,基于内存缓存区记忆
)
conversation.predict(input="Hi there!")
打印输出:
Current conversation:
Human: Hi there!
AI:
> Finished chain.
'Hello! How can I assist you today?'聊天对话
I'm doing well! Just having a conversation with an AI.
conversation.predict(input="I'm doing well! Just having a conversation with an AI.")
打印输出:
Current conversation:
Human: Hi there!
AI: Hello! How are you today?
Human: I'm doing well! Just having a conversation with an AI.
AI:
> Finished chain.
"That's great to hear! I'm here to chat with you and provide any information or assistance you may need. What would you like to talk about?"聊天对话
Tell me about yourself.
conversation.predict(input="Tell me about yourself.")
打印输出:
Current conversation:
Human: Hi there!
AI: Hello! How can I assist you today?
Human: I'm doing well! Just having a conversation with an AI.
AI: That's great to hear! I'm here to chat with you and provide any information or assistance you may need. What would you like to talk about?
Human: Tell me about yourself.
AI:
> Finished chain.
'I am an artificial intelligence designed to interact with humans and provide information and assistance. I have access to a vast amount of data and can answer a wide range of questions. My goal is to help you with whatever you need, so feel free to ask me anything!'三、Conversation Buffer Window
基于内存缓存区进行记忆管理,但是记忆K条对话记录
1.直接从内存缓存区中存取
from langchain.memory import ConversationBufferWindowMemory
## 定义一个内存,只能存储最新的一个数据
memory = ConversationBufferWindowMemory( k=1)
memory.save_context({"input": "hi"}, {"output": "whats up"})
memory.save_context({"input": "not much you"}, {"output": "not much"})
#%%
## 加载内存里的数据
memory.load_memory_variables({})
#输出:{'history': 'Human: not much you\nAI: not much'}2.以消息列表的形式输出return_messages=True
## 用消息对象的方式
memory = ConversationBufferWindowMemory( k=1, return_messages=True)
memory.save_context({"input": "hi"}, {"output": "whats up"})
memory.save_context({"input": "not much you"}, {"output": "not much"})
## 打印当前内存里的信息
memory.load_memory_variables({})
#输出:{'history': [HumanMessage(content='not much you'),
AIMessage(content='not much')]}3.在Chain链中运用
from langchain_openai import ChatOpenAI
from langchain.chains import ConversationChain
## 里面使用了一个内存,只能存储最新的1条数据
conversation_with_summary = ConversationChain(
llm=ChatOpenAI(model_name="gpt-3.5-turbo-0125",temperature=0),
memory=ConversationBufferWindowMemory(k=1),
verbose=True
)第一次调用,结果中没有对话的记忆
## 第一次调用,结果中没有对话的记忆
result = conversation_with_summary.predict(input="Hi, what's up?")
print(result)
打印输出:
Current conversation:
Human: Hi, what's up?
AI:
> Finished chain.
Hello! I'm just here, ready to chat and answer any questions you may have. How can I assist you today?第二次调用,结果中有第一次对话的记忆
## 第二次调用,结果中有第一次对话的记忆
result = conversation_with_summary.predict(input="Is it going well?")
print(result)
打印输出:
Current conversation:
Human: Hi, what's up?
AI: Hello! I'm just here, ready to chat and answer any questions you may have. How can I assist you today?
Human: Is it going well?
AI:
> Finished chain.
Yes, everything is going well on my end. I'm fully operational and ready to help with any inquiries you may have. How can I assist you today?第三次调用,结果中只有第二次对话的记忆
## 第三次调用,结果中只有第二次对话的记忆
result = conversation_with_summary.predict(input="What's the solution?")
print(result)
打印输出:
Current conversation:
Human: Is it going well?
AI: Yes, everything is going well on my end. I'm fully operational and ready to help with any inquiries you may have. How can I assist you today?
Human: What's the solution?
AI:
> Finished chain.
The solution to what specific problem are you referring to? Please provide me with more details so I can better assist you.四、Conversation Summary
对之前的历史对话,进行摘要总结后存储在内存中
1.直接简单的存取
from langchain.memory import ConversationSummaryMemory, ChatMessageHistory
from langchain_openai import OpenAI
memory = ConversationSummaryMemory(llm=OpenAI(temperature=0))
memory.save_context({"input": "hi"}, {"output": "whats up"})
memory.load_memory_variables({})
# 采用消息列表的格式进行返回
memory = ConversationSummaryMemory(llm=OpenAI(temperature=0), return_messages=True)
memory.save_context({"input": "hi"}, {"output": "whats up"})
memory.load_memory_variables({})2.使用现有的消息进行总结摘要
history = ChatMessageHistory()
history.add_user_message("hi")
history.add_ai_message("hi there!")
memory = ConversationSummaryMemory.from_messages(
llm=OpenAI(temperature=0),
chat_memory=history,
return_messages=True
)
#查看缓存
memory.buffer
#放入本地消息,再总结
memory = ConversationSummaryMemory(
llm=OpenAI(temperature=0),
buffer="The human asks what the AI thinks of artificial intelligence. The AI thinks artificial intelligence is a force for good because it will help humans reach their full potential.",
chat_memory=history,
return_messages=True
)3.在Chain中使用
from langchain_openai import OpenAI
from langchain.chains import ConversationChain
llm = OpenAI(temperature=0)
conversation_with_summary = ConversationChain(
llm=llm,
memory=ConversationSummaryMemory(llm=OpenAI()),
verbose=True
)
#第一次调用
conversation_with_summary.predict(input="Hi, what's up?")
#第二次调用
conversation_with_summary.predict(input="Tell me more about it!")五、Conversation Summary Buffer
对之前的历史对话,进行摘要总结后存储在内存中;并且通过token长度来决定何时进行总结
1.直接简单的存取
from langchain.memory import ConversationSummaryBufferMemory
from langchain_openai import OpenAI
llm = OpenAI()
#存储的内容超过token阀值了才进行总结
memory = ConversationSummaryBufferMemory(llm=llm, max_token_limit=10)
memory.save_context({"input": "hi"}, {"output": "whats up"})
memory.save_context({"input": "not much you"}, {"output": "not much"})
memory.load_memory_variables({})
#%%
# 采用消息列表的格式进行输出
memory = ConversationSummaryBufferMemory(
llm=llm, max_token_limit=10, return_messages=True
)
memory.save_context({"input": "hi"}, {"output": "whats up"})
memory.save_context({"input": "not much you"}, {"output": "not much"})2.在Chain中使用
from langchain.chains import ConversationChain
conversation_with_summary = ConversationChain(
llm=llm,
memory=ConversationSummaryBufferMemory(llm=OpenAI(), max_token_limit=10),
verbose=True,
)
#第一次调用
conversation_with_summary.predict(input="Hi, what's up?")
#第二次调用
conversation_with_summary.predict(input="Just working on writing some documentation!")六、 Conversation Token Buffer
将之前所有的对话历史记录,存储在内存中; 并且通过token长度来决定缓存多少内容
1.直接简单存取
from langchain.memory import ConversationTokenBufferMemory
from langchain_openai import OpenAI
llm = OpenAI()
# 通过max_token_limit决定缓存多少内容
memory = ConversationTokenBufferMemory(llm=llm, max_token_limit=10)
memory.save_context({"input": "hi"}, {"output": "whats up"})
memory.save_context({"input": "not much you"}, {"output": "not much"})
memory.load_memory_variables({})
# 以消息列表的格式返回
memory = ConversationTokenBufferMemory(
llm=llm, max_token_limit=10, return_messages=True
)
memory.save_context({"input": "hi"}, {"output": "whats up"})
memory.save_context({"input": "not much you"}, {"output": "not much"})2.在Chain中使用
from langchain.chains import ConversationChain
conversation_with_summary = ConversationChain(
llm=llm,
#配置token限制
memory=ConversationTokenBufferMemory(llm=OpenAI(), max_token_limit=10),
verbose=True,
)
#第一次调用
conversation_with_summary.predict(input="Hi, what's up?")
#第二次调用
conversation_with_summary.predict(input="Just working on writing some documentation!")
#第三次调用
conversation_with_summary.predict(input="For LangChain! Have you heard of it?")总结
Langchain框架的Memory模块通过其多样化的记录类型和智能化的存储机制,为AI大模型提供了强大的历史对话管理和知识保留能力。这些功能不仅优化了模型的记忆效率,还为未来的查询和分析奠定了坚实的基础,进一步推动了AI大模型在实际应用中的广泛落地。
探索未知,分享所知;点击关注,码路同行,寻道人生!