1. Spring是什么?
简单的说,Spring其实指的是Spring Framework(Spring框架),是一个开源框架。
如果要用一句话概括:它是包含众多工具方法的IOC(Inverse of Control控制反转)容器。
容器:
- Tomcat -> Web容器
- ArrayList,HashMap ->数据存储容器
容器,顾名思义是用来装东西的,而Spring这个容器是用来装什么的呢,里面装的是一个个Bean对象,它具备了存储对象和获取对象的能力。
对于什么是控制反转、为什么需要这么一个能够存储对象的容器呢?为了搞懂这两个疑问,这一小节,我们就来通过案例理解一下Spring的核心思想“IOC”和“DI”。
2. IOC控制(权)反转
IOC(控制反转) 是Spring中的核心思想之一,小白看到“控制反转”这四个大字估计脑子都懵了,控制反转是干嘛的,每个字都能看得懂,但为什么脑子就是没懂呢?
简单的概括一下:控制反转的作用是解耦合。我们接下来就来看看控制反转是如何解耦合的。
2.1 解耦合
2.1.1 传统依赖关系代码写法
想象以下场景:甲方需要你交房(House类),这个房子一定是要封顶才可以交房的,因此这个房子就依赖于屋顶(Roof类)的 build() 方法;要想搭建屋顶,一定就需要有柱子作支撑,因此这个屋顶就依赖于柱子(Column类)的 build() 方法;要想搭建柱子,就一定需要一个稳固的地基,因此这个柱子就依赖于地基(Bottom类)的 build() 方法。甲方当前的需求比较单一,也就是地基的面积是100平方米,于是你作为一个程序员创建了以下类,并且采用传统方式来解决类之间的依赖关系。
地基(bottom)的搭建:
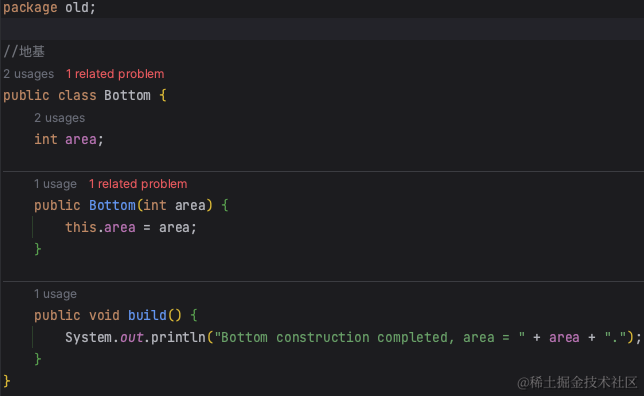
//地基
public class Bottom {
int area = 100;
public void build() {
System.out.println("Bottom construction completed, area = " + area + ".");
}
}
支撑柱(column)的搭建:
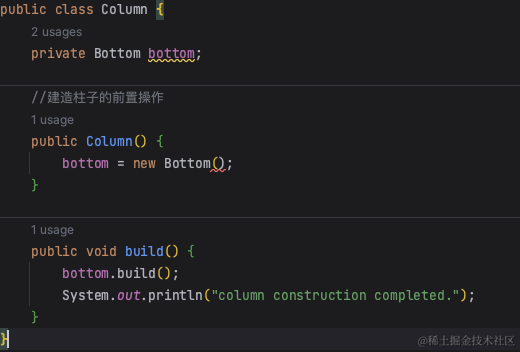
//支撑柱
public class Column {
private Bottom bottom;
//建造柱子的前置操作
public Column() {
bottom = new Bottom();
}
public void build() {
//支撑柱的搭建需要依赖稳固的地基:bottom.build()
bottom.build();
System.out.println("column construction completed.");
}
}
屋顶(roof)的搭建:
//屋顶
public class Roof {
private Column column;
public Roof() {
column = new Column();
}
public void build() {
//屋顶的搭建需要依赖支撑的柱子:column.build()
column.build();
System.out.println("Roof construction completed.");
}
}
房子(house)的搭建:
//构建房子
public class House {
private Roof roof;
public House() {
roof = new Roof();
}
public void build() {
//房子的搭建需要依赖屋顶的构建:column.build()
roof.build();
System.out.println("House construction completed.");
}
//House类中编写的main函数(启动类)代表向甲方交房
//主函数:代表向甲方交房
public static void main(String[] args) {
House house = new House();
house.build();
System.out.println("delivered the property successfully.");
}
}
运行主函数的结果:

目前看是不是没什么毛病。
但是突然甲方需求更新,说是需要根据客户需求改变面积大小,此时我们只能改!
于是我们将底座(bottom类)的代码修改成下面这样:
代码开始飘红了… 原因是column类依赖bottom类,因此colum在new Bottom()时,也需要传参数:
于是就这样改啊改,终于把所有类的参数都给加上了:
//支撑柱
public class Column {
private Bottom bottom;
//建造柱子的前置操作
public Column(int area) {
bottom = new Bottom(area);
}
public void build() {
bottom.build();
System.out.println("column construction completed.");
}
}
//屋顶
public class Roof {
private Column column;
public Roof(int area) {
column = new Column(area);
}
public void build() {
column.build();
System.out.println("Roof construction completed.");
}
}
//构建房子
public class House {
private Roof roof;
public House(int area) {
roof = new Roof(area);
}
public void build() {
roof.build();
System.out.println("House construction completed.");
}
//主函数:代表向甲方交房
public static void main(String[] args)
//客户终于可以设置想要的房屋面积了。。
House house = new House(999);
house.build();
System.out.println("delivered the property successfully.");
}
}
只是添加了这一个需求,所有依赖于bottom的类都进行了修改。
如果甲方还需要加需求,如:底座的材质啊,柱子的粗细啊或者说是屋顶是要用瓦还是砌砖啊。。
作为开发人员的你的内心一定是这样的:

上面的写法所有代码都得跟着一起改,这样代码的耦合性太高了!
机智的我们该思考,怎样才能不需要在类中不传参数呢?
2.1.2 改进写法(控制反转)
于是乎我们做了一个决定:要求必须将自己上一层的依赖传递给我做构造函数的参数,而这个类就不需要再去new对象了,因此也不需要管上一层所需要的参数了,也就是把控制权交出去了。
于是出现了下面这种控制反转的思想:
public class BottomV2 {
int area = 100;
public void build() {
System.out.println("BottomV2 construction completed, area = " + area + ".");
}
}
public class ColumnV2 {
private BottomV2 bottomV2;
//改动1
public ColumnV2(BottomV2 bottomV2) {
this.bottomV2 = bottomV2;
}
public void build() {
bottomV2.build();
System.out.println("columnV2 construction completed.");
}
}
public class RoofV2 {
private ColumnV2 columnV2;
//改动2
public RoofV2(ColumnV2 columnV2) {
this.columnV2 = columnV2;
}
public void build() {
columnV2.build();
System.out.println("RoofV2 construction completed.");
}
}
public class HouseV2 {
private RoofV2 roofV2;
//改动3
public HouseV2(RoofV2 roofV2) {
this.roofV2 = roofV2;
}
public void build() {
roofV2.build();
System.out.println("House construction completed.");
}
public static void main(String[] args) {
BottomV2 bottomV2 = new BottomV2();
ColumnV2 columnV2 = new ColumnV2(bottomV2);
RoofV2 roofV2 = new RoofV2(columnV2);
HouseV2 houseV2 = new HouseV2(roofV2);
houseV2.build();
}
}
此时的业务是bottom类的area属性写死在100,我们现在要让它改变为根据客户的需求任意改变area的大小,此时只需要改变两个地方:
public class BottomV2 {
int area;
//改动1
public void build(int area) {
System.out.println("BottomV2 construction completed, area = " + area + ".");
}
}
public class HouseV2 {
private RoofV2 roofV2;
public HouseV2(RoofV2 roofV2) {
this.roofV2 = roofV2;
}
public void build() {
roofV2.build();
System.out.println("House construction completed.");
}
public static void main(String[] args) {
//改动2:也是客户自定义面积的地方
BottomV2 bottomV2 = new BottomV2(999);
ColumnV2 columnV2 = new ColumnV2(bottomV2);
RoofV2 roofV2 = new RoofV2(columnV2);
HouseV2 houseV2 = new HouseV2(roofV2);
houseV2.build();
}
}
浅浅一运行,就得到了想要的结果:
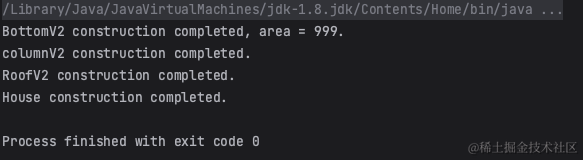
2.1.3 理解Spring IOC
对比上面两种写法,我们应该能理解IOC的控制反转到底是啥意思了吧?其实就是将某个类new对象的权利反转给其所依赖的上一级对象,从而成功起到了相互依赖的类与类之间解耦合的作用。
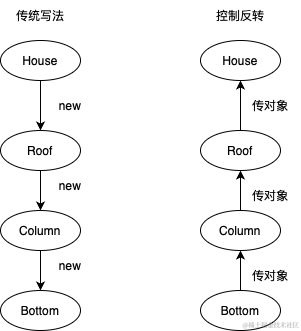
大家可以发现,new对象这个参数的操作从类中转移到了main函数中从而实现了解耦合,这一系列的new操作在Spring中我们都可以不需要管,这就不得不提到DI了
3. DI(依赖注入)
DI 是 Dependency Injection的缩写,也就是“依赖注入的意思”。其实学习Spring最核心的功能,就是学如何将对象存到Spring中,再从Spring中获取对象的过程
3.1 依赖注入的解释
因为Spring是一个IOC容器,说的是将 Bean 的创建和销毁的权利都交给 Spring 来管理了,它本身又具备了存储对象和获取对象的能力。
依赖注入是在bean生成后进行属性赋值,也就是存储的对象获取出来再动态地将某种依赖关系注入到对象之中。(后面的小节会演示怎么操作)
3.2 Spring管理Bean的生命周期
这样做有什么好处呢?作为程序员,我不需要去理会那些对象的生命周期,而是将生命周期交给Spring来托管,减少了程序员的开发成本。
给大家举个例子,正如2.1.2中提到的改进写法,我们是在main函数中自行管理bean对象,不管是少new了一个对象还是new的顺序不对,都不好使,如下:
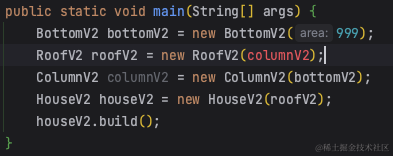
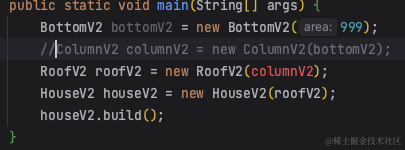
将Bean交给Spring帮你托管,Spring会先通过反射实例化所有Bean对象,再通过DI通过类型或名称来判断将不同的对象注入到不同的属性中。
比如 House 类依赖 Roof 类,Roof 类又依赖 Column 类,Column 类又依赖 Bottom 类,将这些Bean对象都交给Spring后,我们就不需要关心里面的依赖关系,Spring 的 DI 就像是做了下面这些事(为了好理解,下面的代码直接用new的方式实例化对象):
//模拟Spring底层的DI
public class BeanFactory {
public static HouseV2 getBean() {
BottomV2 bottomV2 = new BottomV2(999);
ColumnV2 columnV2 = new ColumnV2(bottomV2);
RoofV2 roofV2 = new RoofV2(columnV2);
HouseV2 houseV2 = new HouseV2(roofV2);
return houseV2;
}
}
我们在测试代码中需要写的代码只有这些:
public static void main(String[] args) {
HouseV2 houseV2 = BeanFactory.getBean();
houseV2.build();
}
这就是使用Spring托管对象的方便之处。
3.3 DI的单例模式
Spring中托管的bean对象默认都是单例的,单例模式大家都明白,只会在第一次被使用到的时候创建实例,之后再需要使用bean对象的时候只要去仓库取就好,减少了创建实例的开销,性能较高。
4. 总结(IOC和DI的关系)
依赖注入(DI)和控制反转(IOC)是从不同角度描述同一件事,IOC是思想,可以把它当作一种指导方案,而DI就是这个指导方案的具体实现。DI通过引入Spring(IOC容器),利用依赖关系注入的方式,实现对象之间的解耦。