目录
力扣10. 正则表达式匹配
解析代码
力扣10. 正则表达式匹配
10. 正则表达式匹配
难度 困难
给你一个字符串 s 和一个字符规律 p,请你来实现一个支持 '.' 和 '*' 的正则表达式匹配。
'.'匹配任意单个字符'*'匹配零个或多个前面的那一个元素
所谓匹配,是要涵盖 整个 字符串 s的,而不是部分字符串。
示例 1:
输入:s = "aa", p = "a" 输出:false 解释:"a" 无法匹配 "aa" 整个字符串。
示例 2:
输入:s = "aa", p = "a*" 输出:true 解释:因为 '*' 代表可以匹配零个或多个前面的那一个元素, 在这里前面的元素就是 'a'。因此,字符串 "aa" 可被视为 'a' 重复了一次。
示例 3:
输入:s = "ab", p = ".*" 输出:true 解释:".*" 表示可匹配零个或多个('*')任意字符('.')。
提示:
1 <= s.length <= 201 <= p.length <= 20s只包含从a-z的小写字母。p只包含从a-z的小写字母,以及字符.和*。- 保证每次出现字符
*时,前面都匹配到有效的字符
class Solution {
public:
bool isMatch(string s, string p) {
}
};解析代码
状态表示:
对于两个字符串之间的 dp 问题,一般的思考方式如下:
选取第⼀个字符串的 [0, i] 区间以及第⼆个字符串的 [0, j] 区间当成研究对象,结合题目的要求来定义状态表示。然后根据两个区间上最后一个位置的字符,来进行分类讨论,从而确定状态转移方程。
dp[i][j] 表示:字符串 p 的 [0, j] 区间和字符串 s 的 [0, i] 区间是否可以匹配。
状态转移方程:
根据最后一个位置的元素,结合题目要求,分情况讨论:
- 当 p[j] 不是特殊字符,且不与 s[i] 相等时,无法匹配。
- 当 s[i] == p[j] 或 p[j] == '.' 的时候,此时两个字符串匹配上了当前的一个字符, 只能从 dp[i - 1][j - 1] 中看当前字符前面的两个子串是否匹配。只能继承上个状态中的匹配结果, dp[i][j] = dp[i - 1][j - 1] ;
- b. 当 p[j] == '*' 的时候,和力扣44. 通配符匹配稍有不同的是,上道题 "*" 本身便可匹配 0 ~ n 个字符,但此题是要带着 p[j - 1] 的字符⼀起,匹配 0 ~ n 个和 p[j - 1] 相同的字符。此时,匹配策略有两种选择:
- 一种选择是: p[j - 1]* 匹配空字符串,直接继承状态 dp[i][j - 2] ,此时 dp[i][j] = dp[i][j - 2] ;
- 另一种选择是: p[j - 1]* 向前匹配 1 ~ n 个字符(与力扣44. 通配符匹配不同,此时p[j - 1]与s[i] 要相等 或者 p[j - 1] 为点),直至匹配上整个 s 串。此时相当于从 dp[k][j - 2] (0 < k <= i) 中所有匹配情况中,选择性继承可以成功的情况。此时 dp[i][j] = dp[k][j - 2] (0 < k <= i 且 s[k]~s[i] = p[j - 1]) ;
三种情况加起来,就是所有可能的匹配结果。 综上所述,状态转移方程为:
- 当s[i] == p[j] 或 p[j] == '.' 时: dp[i][j] = dp[i][j - 1] ;
- 当 p[j] == '*' 时,有多种情况需要讨论: dp[i][j] = dp[i][j - 2] ; dp[i][j] = dp[k][j - 1] (0 <= k <= i) ;
这个状态转移方程时间复杂度为O(N^3),要想想优化。
优化:当发现计算一个状态的时候,需要一个循环才能搞定的时候,我们要想到去优化。优化的方向就是用一个或者两个状态来表示这一堆的状态。通常就是把它写下来,然后用数学的方式做一下等价替换:
当 p[j] == '*' 时,状态转移方程为:dp[i][j] = dp[i][j - 2] || dp[i - 1][j - 2] || dp[i - 2][j - 2] ......
发现 i 是有规律的减小的,因此我们去看看 dp[i - 1][j] ,列出 dp[i - 1][j] = dp[i - 1][j - 1] || dp[i - 2][j - 1] || dp[i - 3][j - 1] ......
然后就能发现, dp[i][j] 的状态转移方程里面除了第一项以外,其余的都可以用dp[i -1][j] 替代。因此优化我们的状态转移方程为: dp[i][j] = dp[i][j - 2] || dp[i - 1][j]。
初始化、填表顺序、返回值:
初始化:空串是有研究意义的,因此我们将原始 dp 表的规模多加上一行和一列,表示空串。由于 dp 数组的值设置为是否匹配,为了不与答案值混淆,我们需要将整个数组初始化为false 。由于需要用到前一行和前一列的状态,初始化第一行、第一列即可。
dp[0][0] 表示两个空串能否匹配,答案是显然的, 初始化为 true 。
第一行表示 s 是一个空串, p 串和空串只有一种匹配可能,即 p 串表示为 "任一字符+*" ,此时也相当于空串匹配上空串。所以可以遍历 p 串,把所有前导为 "任一字符+*" 的 p 子串和空串的 dp 值设为 true 。
第一列表示 p 是一个空串,不可能匹配上 s 串,跟随数组初始化成false即可。
填表顺序:从上往下填写每一行,每一行从左往右,最后返回dp[m][n]。
class Solution {
public:
bool isMatch(string s, string p) {
// dp[i][j]表示字符串p的[0, j]区间和字符串s的[0, i]区间是否可以匹配
int m = s.size(), n = p.size();
s = " " + s, p = " " + p;
vector<vector<bool>> dp(m + 1, vector<bool>(n + 1, false));
dp[0][0] = true;
for(int j = 2; j <= n; j += 2)
{
if(p[j] == '*')
dp[0][j] = true;
else
break;
}
for(int i = 1; i <= m; ++i)
{
for(int j = 1; j <= n; ++j)
{
if(s[i] == p[j] || p[j] == '.')
{
dp[i][j] = dp[i - 1][j - 1];
}
else if(p[j] == '*')
{ // j-1为点 或者 和s[i]相等才可以匹配dp[i - 1][j]
if(p[j - 1] == '.' || p[j - 1] == s[i])
dp[i][j] = dp[i][j - 2] || dp[i - 1][j];
else // 匹配空串的
dp[i][j] = dp[i][j - 2];
}
}
}
return dp[m][n];
}
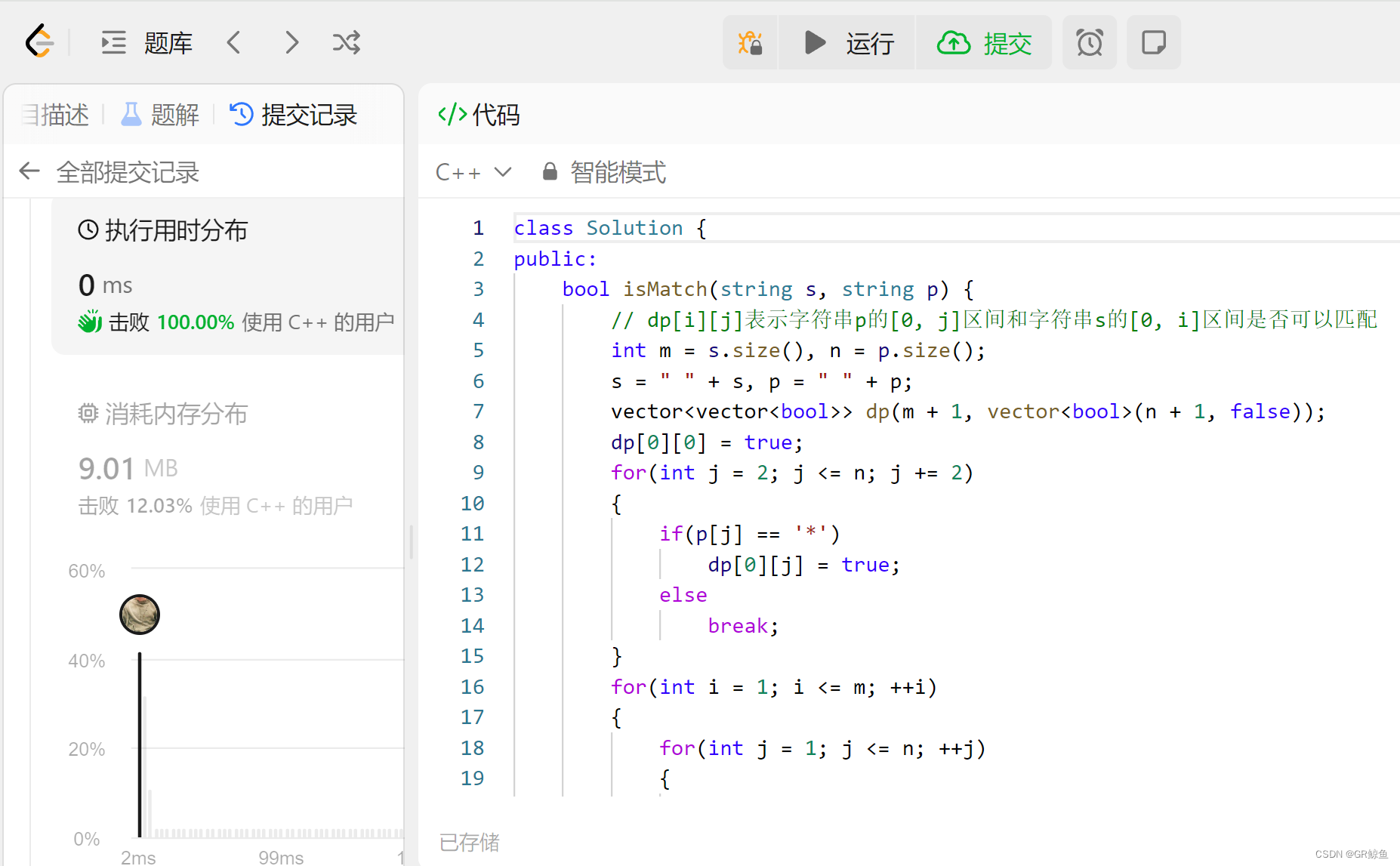
};



![P8602 [蓝桥杯 2013 省 A] 大臣的旅费【树的直径】](https://img-blog.csdnimg.cn/direct/22c20a1e83694aa6a3617dc48b79580b.png)