文章目录
- 快速排序
- 一、递归实现
- 二、非递归实现
- 总结
快速排序
以下均以排升序为最终目的。
一、递归实现
有一个排序能解决所有问题吗?没有!不过,快速排序这种排序适用于大多数情况。
我们前面讨论排序算法一般都是先讨论一趟的情况,对于快速排序,也是可以这么讨论的,特别的是,快速排序的每一趟的代码实现有三种不同的思路:挖坑法、左右指针法、前后指针法。
不管采用哪种思路,其目的都是:将某个选定的key值排到正确位置,然后使得key位置左边的所有值都小于key值,这个位置右边的所有值都大于key值,不过,key位置的左右并不是有序的。key值元素已经排好序了,不需要再参与后续的排序,因而将原序列分割成两个子区间(以排升序为例)。通常key选择序列中的最左边或最右边的元素。
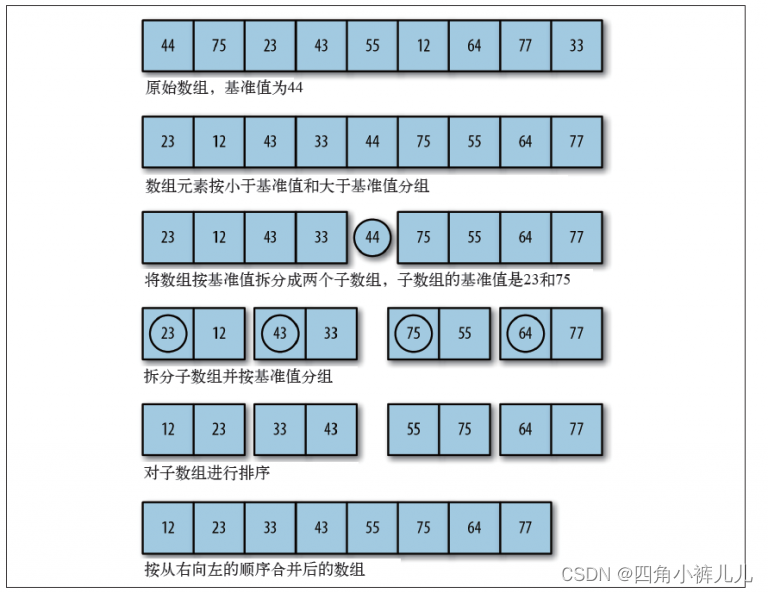
挖坑法
挖坑法选择一个值,放到变量key中,相当于备份了这个值,意味着这个值所在的位置可以被覆盖,称这样一个位置为 “坑”。假设key中存储的是序列最左边的元素,坑在左边,目的是实现升序排列。我们需要从最右边的元素开始遍历,寻找到比key值小的一个元素,用这个元素填坑,填坑后,填坑元素被备份,那么填坑元素的原位置成为新的坑。由于我们开始是从右开始遍历的,所以坑位更新后在右边,所以我们需要从左边开始遍历,寻找比key值大的元素,填坑,更新坑位,以此类推,当从左右遍历的指针相遇时,将它们指向的位置放上key值,此时一趟挖坑法结束。(推荐的思路)
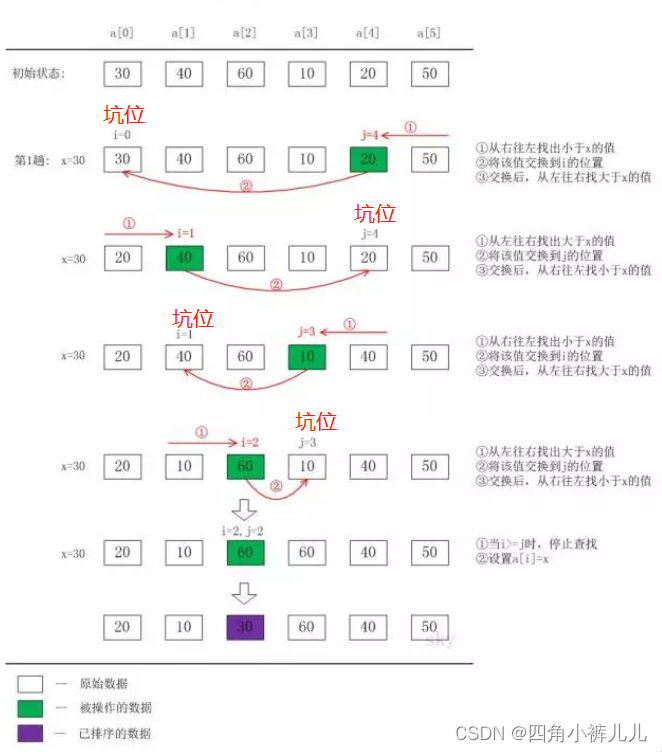
左右指针法
左右指针法与挖坑法类似,选定一个key值,定义两个变量,起始指向序列最左边和最右边,两个指针开始向中间遍历,当左边的指针找到一个大于key的值,右边的指针找到一个小于key的值,则交换这两个位置的值,依次类推,最后将key值放到指定位置。(此方法不推荐,需要注意的细节太多了,很容易写错,掌握思路就好)
前后指针法
前后指针法较为抽象,选定最左边的元素为key,定义两个变量,假设cur、prev,prev初始指向key的的位置,cur初始指向key值后面一个元素,cur负责向右找比key小的值,如果找到了,prev++,然后交换prev和cur指向的两个位置的值,一直重复此过程,当cur要越界的时候停止,将prev指向的位置的值与key位置的值交换。(首推挖坑法,其次就是前后指针法)
以下是三种思路(每趟)的代码实现:
//挖坑法
int PartSort1(int* a, int left, int right)
{
int begin = left;//从左遍历的下标
int end = right;//从右遍历的下标
int pivot = begin;//坑位下标
int key = a[begin];//备份key值,初始坑位(这里选的是序列最左边元素)
while (begin < end)
{
while (begin < end && a[end] >= key)
{
--end;
}
a[pivot] = a[end];
pivot = end;
while (begin < end && a[begin] <= key)//注意&&左边的语句,如果没有的话,可能会出现将一趟排序结果打乱的情况
{
++begin;
}
a[pivot] = a[begin];
pivot = begin;
}
a[pivot] = key;
return pivot;
}
//左右指针法
int PartSort2(int* a, int left, int right)
{
int begin = left;//左指针
int end = right;//右指针
int key = begin;
while (begin < end)
{
while (begin < end && a[end] >= a[key])
{
--end;
}
while (begin < end && a[begin] <= a[key])
{
++begin;
}
Swap(&a[begin], &a[end]);//交换函数
}
Swap(&a[begin], &a[key]);
return begin;
}
//前后指针法
int PartSort3(int* a, int left, int right)
{
int cur = left + 1;
int prev = left;
int key = left;
while (cur <= right)
{
if (a[cur] < a[key] && ++prev != cur)
{
Swap(&a[prev], &a[cur]);
}
cur++;
}
Swap(&a[prev], &a[key]);
return prev;
}
当结束一趟排好一个元素后,这个位置将序列分为了两个子区间,我们只要将这两个子区间排好序,那么就排序完毕。
对于每个子区间,采用相同的方式(挖坑法、前后指针法、左右指针法)排序,再将此子区间分割成两个新的子区间,基于这一特点,我们可以采用分治递归的方式解决。
以下每趟排序采用的是挖坑法。
void QuickSort(int* a, int left, int right)
{
if (left >= right)
return;
int begin = left;
int end = right;
int key = a[begin];
int pivot = begin;
while (begin < end)
{
while (begin < end && a[end] >= key)
{
--end;
}
a[pivot] = a[end];
pivot = end;
while (begin < end && a[begin] <= key)
{
++begin;
}
a[pivot] = a[begin];
pivot = begin;
}
a[pivot] = key;
QuickSort(a, left, pivot - 1);
QuickSort(a, pivot + 1, right);
}
快速排序什么情况下最坏?时间复杂度是多少?
有序的情况下最差,这种情况下,每趟挖坑认为只能排好一个元素。
最坏的时间复杂度为O(N^2)
假如我们每次挖坑选择第一个元素为key,那么有序情况下,一趟挖坑分割的左子区间为空,所以只对右子区间执行挖坑法,每趟挖坑分割后的左子区间都是空,如果是排升序,那么从右找比key小的数要一直从右遍历到左边(因为原序列已经有序)。
针对这样的情况,采用三数取中
三数取中就是拿出序列中位置最左、最右和中间的三个元素,比较它们的大小,选出大小排序后为中间的元素。
这个元素将在后面被选定为key。
三数取中优化后的快速排序:
//三树取中
int GetmidIndex(int* a, int left, int right)
{
int mid = (left + right) >> 1;
if (a[left] > a[mid])
{
if (a[mid] > a[right])
{
return mid;
}
else if (a[left] > a[right])
{
return right;
}
else
return left;
}
else//a[mid] > a[left]
{
if (a[mid] < a[right])
{
return mid;
}
else if (a[left] > a[right])
{
return left;
}
else
return right;
}
}
void QuickSort(int* a, int left, int right)
{
if (left >= right)
{
return;
}
int index = GetmidIndex(a, left, right);/拿到中间大的元素的下标
Swap(&a[left], &a[index]);//为了不影响后续最左边元素为key的逻辑,我们将三数取中得到的下标位置的值和序列最左边的值交换
int begin = left;
int end = right;
int pivot = begin;
int key = a[begin];
while (begin < end)
{
while (begin < end && a[end] >= key)
{
--end;
}
a[pivot] = a[end];
pivot = end;
while (begin < end && a[begin] <= key)
{
++begin;
}
a[pivot] = a[begin];
pivot = begin;
}
a[pivot] = key;
QuickSort(a, left, pivot - 1);
QuickSort(a, pivot + 1, right);
}
我们还能继续优化吗?
对于数据总量庞大的情况,从头到尾递归快速排序,需要大量的递归调用,栈区空间占用较多。
不考虑其他情况,第一次挖坑为第一层;之后会出现两个子区间,这是第二层;接着4个子区间,第三层……我们发现越到后面,子区间越多,递归调用越多。
假如现在有100w(约等于2 ^ 20个数据,说明有20层,从后往前数2 ^ 19(50w)、2 ^ 18(25w)……我们发现大多数的函数调用都发生在后面的几层,而后面的几层处理的每个子区间的元素个数相对数据总量很少。
基于此,我们采用小区间优化消除后面几层的递归调用。
对小区间采用其他的排序方式,而不是继续递归调用,一般采用直接插入排序。
不过,小区间优化的效果并不明显,且要注意的是,到什么程度不递归,需要结合数据总量考虑,下面代码给的10。
三数取中、小区间优化后的快速排序:
int GetmidIndex(int* a, int left, int right)
{
int mid = (left + right) >> 1;
if (a[left] > a[mid])
{
if (a[mid] > a[right])
{
return mid;
}
else if (a[left] > a[right])
{
return right;
}
else
return left;
}
else//a[mid] > a[left]
{
if (a[mid] < a[right])
{
return mid;
}
else if (a[left] > a[right])
{
return left;
}
else
return right;
}
}
void QuickSort(int* a, int left, int right)
{
if (left >= right)
{
return;
}
int index = GetmidIndex(a, left, right);
Swap(&a[left], &a[index]);
int begin = left;
int end = right;
int pivot = begin;
int key = a[begin];
while (begin < end)
{
while (begin < end && a[end] >= key)
{
--end;
}
a[pivot] = a[end];
pivot = end;
while (begin < end && a[begin] <= key)
{
++begin;
}
a[pivot] = a[begin];
pivot = begin;
}
a[pivot] = key;
if (pivot - 1 - left < 10)//判断区间是否为小区间
{
InsertSort(a + left, pivot - 1 - left + 1);//插入排序
}
else
QuickSort(a, left, pivot - 1);//递归
if (right - pivot - 1 < 10)
{
InsertSort(a + pivot + 1, right - pivot - 1 + 1);
}
else
QuickSort(a, pivot + 1, right);
}
二、非递归实现
递归的缺陷: 栈帧深度太深,栈空间不够用,可能会溢出
递归改非递归:
- 直接改循环
- 借助数据结构栈模拟递归过程
非递归实现快速排序需要用到栈。
想清楚,递归建立栈帧,栈帧存储局部变量,我们函数调用时存储的是区间,也就是 left 和 right,我们考虑用栈来模拟递归,存储left和right的值。
思路
每次将区间的左右下标入栈,每趟排序从栈顶拿取,这一过程要考虑栈的先入后出属性。
由于C语言限制,其库函数没有现成的栈,我们需要独立去实现一个栈。
独立实现的栈:
//Stack.h
#pragma once
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
#include <stdbool.h>
typedef int STDataType;
typedef struct StackNode
{
STDataType* a;
int top;
int capacity;
}ST;
void StackInit(ST* ps);
void StackPush(ST* ps, STDataType x);
void StackPop(ST* ps);
void StackDestory(ST* ps);
STDataType StackTop(ST* ps);
bool StackEmpty(ST* ps);
int StackSize(ST* ps);
//Stack.c
#include "Stack.h"
void StackInit(ST* ps)
{
assert(ps);
STDataType* tmp = (STDataType*)malloc(sizeof(STDataType) * 4);
if(NULL == tmp)
{
printf("malloc fail\n");
exit(-1);
}
else
{
ps->a tmp;
ps->capacity = 4;
ps->top = 0;
}
}
void StackPush(ST* ps, STDataType x)
{
assert(ps);
if(ps->capacity == ps->top)
{
STDataType* tmp = (STDataType*)realloc(ps->a, sizeof(STDataType) * ps->capacity * 2);
if(NULL == tmp)
{
printf("realloc fail\n");
exit(-1);
}
else
{
ps->a = tmp;
ps->capacity *= 2;
ps->a[ps->top] = x;
ps->top++;
}
}
}
void StackPop(ST* ps)
{
assert(ps);
assert(ps->top > 0);
ps->top--;
}
void StackDestory(ST* ps)
{
assert(ps);
free(ps->a);
ps->a = NULL;
ps->top = ps->capacity = 0;
}
STDataType StackTop(ST* ps)
{
assert(ps);
assert(ps->top > 0);
return ps->a[ps->top-1];
}
bool StackEmpty(ST* ps)
{
assert(ps);
return ps->top == 0;
}
int StackSize(ST* ps)
{
assert(ps);
return ps->top;
}
基于上面栈的实现,我们实现一下非递归快速排序。
void QuickSortNonr(int* a, int len)
{
ST st;
StackInit(&st);
StackPush(&st, len - 1);//第一趟排序区间入栈
StackPush(&st, 0);
while (!StackEmpty(&st))//栈为空则排序证明所有子区间排序完毕
{
int left = StackTop(&st);
StackPop(&st);
int right = StackTop(&st);
StackPop(&st);
int index = GetmidIndex(a, left, right);
Swap(&a[left], &a[index]);
int end = right;
int begin = left;
int pivot = begin;
int key = a[begin];
while (begin < end)
{
while (begin < end && a[end] >= key)
{
--end;
}
a[pivot] = a[end];
pivot = end;
while (begin < end && a[begin] <= key)
{
++begin;
}
a[pivot] = a[begin];
pivot = begin;
}
a[pivot] = key;
if (right > pivot + 1)//子区间不存在或只有一个元素不入栈
{
StackPush(&st, right);
StackPush(&st, pivot + 1);
}
if (left < pivot - 1)
{
StackPush(&st, pivot - 1);
StackPush(&st, left);
}
}
StackDestory(&st);
}
总结
1. 快速排序整体的综合性能和使用场景都是比较好的,所以才敢叫快速排序。
2. 时间复杂度:O(N*logN)
最坏情况下:O(N^2)
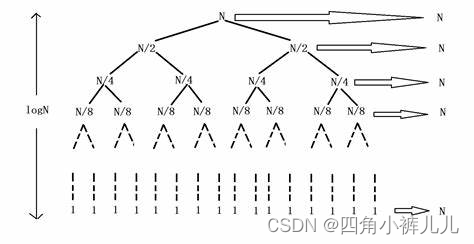
3. 空间复杂度:O(logN)
4. 稳定性:不稳定

![[C语言]——柔性数组](https://img-blog.csdnimg.cn/direct/521b330c86b04340acc704ef78aab17a.png)