本文详细介绍了 TiDB 的 Garbage Collection(GC)机制及其在 TiDB 组件中的实现原理和常见问题排查方法。 TiDB 底层使用单机存储引擎 RocksDB,并通过 MVCC 机制,基于 RocksDB 实现了分布式存储引擎 TiKV,以支持高可用分布式事务。 GC 过程旨在清理旧数据,减少其对性能的影响,主要包括四个步骤: 计算 GC safepoint、解析锁(Resolve locks)、连续范围数据删除(Delete ranges)和同步 GC safepoint 至集群其他组件。 文章还讲述了如何定位 GC leader、监控 GC 状态、以及处理 GC 过程中遇到的常见问题。
TiDB 底层使用的是单机存储引擎 RocksDB, 为了实现分布式事务接口,TiDB 又采用 MVCC 机制,基于 RocksDB 实现了高可用分布式存储引擎 TiKV。 也就是当新写入(增删改)的数据覆盖到旧数据时,旧数据不会被替换掉,而是与新写入的数据同时保留,并以时间戳来区分版本。 当这些历史版本堆积越来越多时,就会引出一系列问题,最常见的便是读写变慢。 TiDB 为了降低历史版本对性能的影响,会定期发起 Garbage Collection( https://docs-archive.pingcap.com/zh/tidb/v7.2/garbage-collection-overview GC)清理不再需要的旧数据。
在 上一篇文章 中,我们介绍了 MVCC 版本堆积相关原理及排查手段,当我们发现 MVCC 版本堆积已经对当前集群读写产生了性能影响时,则需要检查当前集群 GC 的状态及相关参数是否需要进行调整。
本文我们将重点介绍 TiDB 组件中 GC 的相关原理及常见排查手段。由于篇幅原因,TiKV 侧的 GC 相关内容我们将在另一篇文章中独立介绍。
GC leader
通过对 TiDB 分布式事务( https://tidb.net/blog/7730ed79 )实现的了解,我们知道 TiDB 集群具体的数据存储在 TiKV 上,集群的元数据信息存在 PD 上,TiDB 要做数据旧版本的回收,则需要有个类似 GC worker 的角色从 PD 拿到元数据信息然后对 TiKV 中的数据做垃圾回收工作。这个角色目前我们放在 TiDB 中,一个就够,所以我们借助 PD 维护选举出一个 GC leader 的角色,来统一协调整个集群的 GC 工作。
GC leader 是 TiDB 中负责推动集群 GC 工作的一个协程(goroutinue), 一个 TiDB 集群中,同一时刻有且只有一个 TiDB 上会有这个 GC leader 角色。
常见排查指导
通常如果怀疑系统 GC 状态可能存在异常,我们可以从 gc leader 所报的日志中查看当前 GC 的详细状态。
- 如何查找 GC leader 在哪个 tidb 上?
mysql> select variable_name,variable_value from mysql.tidb where variable_name = "tikv_gc_leader_desc"\G;
*************************** 1. row ***************************
variable_name: tikv_gc_leader_desc
variable_value: host:172-16-120-219, pid:3628952, start at 2024-01-17 16:34:58.022047311 +0800 CST m=+9.910349289
1 row in set (0.00 sec)- 找到 gc leader 对应的 tidb 实例,在日志中 grep "gc_worker" 关键字即可看到当前 GC 的整体运行状态。关于日志中字段的具体含义,我们可以在后面的章节会详细展开介绍。
tidb@172-16-120-219:~/shirly/tiup$ ps aux | grep 3628952
tidb 3592616 0.0 0.0 8160 2456 pts/2 S+ 15:12 0:00 grep --color=auto 3628952
tidb 3628952 8.2 0.2 10914336 1065168 ? Ssl Jan17 4158:25 bin/tidb-server -P 4005 --status=10080 --host=0.0.0.0 --advertise-address=127.0.0.1 --store=tikv --initialize-insecure --path=127.0.0.1:2379,127.0.0.1:2381,127.0.0.1:2383 --log-slow-query=/DATA/disk4/shirly/tiup/tidb-deploy/tidb-4005/log/tidb_slow_query.log --config=conf/tidb.toml --log-file=/DATA/disk4/shirly/tiup/tidb-deploy/tidb-4005/log/tidb.log
tidb@172-16-120-219:~/shirly/tiup$ grep "gc_worker" /DATA/disk4/shirly/tiup/tidb-deploy/tidb-4005/log/tidb.log | head
[2024/02/02 19:29:59.062 +08:00] [INFO] [gc_worker.go:1073] ["[gc worker] start resolve locks"] [uuid=6345a3cad480026] [safePoint=0] [try-resolve-locks-ts=447446541678411803] [concurrency=3]
[2024/02/02 19:29:59.291 +08:00] [INFO] [gc_worker.go:1095] ["[gc worker] finish resolve locks"] [uuid=6345a3cad480026] [safePoint=0] [try-resolve-locks-ts=447446541678411803] [regions=1236]
[2024/02/02 19:30:59.065 +08:00] [INFO] [gc_worker.go:1073] ["[gc worker] start resolve locks"] [uuid=6345a3cad480026] [safePoint=0] [try-resolve-locks-ts=447446557407051824] [concurrency=3]
[2024/02/02 19:30:59.283 +08:00] [INFO] [gc_worker.go:1095] ["[gc worker] finish resolve locks"] [uuid=6345a3cad480026] [safePoint=0] [try-resolve-locks-ts=447446557407051824] [regions=1236]
[2024/02/02 19:31:59.060 +08:00] [INFO] [gc_worker.go:1073] ["[gc worker] start resolve locks"] [uuid=6345a3cad480026] [safePoint=0] [try-resolve-locks-ts=447446573135691804] [concurrency=3]
[2024/02/02 19:31:59.297 +08:00] [INFO] [gc_worker.go:1095] ["[gc worker] finish resolve locks"] [uuid=6345a3cad480026] [safePoint=0] [try-resolve-locks-ts=447446573135691804] [regions=1236]
[2024/02/02 19:32:59.072 +08:00] [INFO] [gc_worker.go:347] ["[gc worker] starts the whole job"] [uuid=6345a3cad480026] [safePoint=447446510221131776] [concurrency=3]
[2024/02/02 19:32:59.074 +08:00] [INFO] [gc_worker.go:1073] ["[gc worker] start resolve locks"] [uuid=6345a3cad480026] [safePoint=447446510221131776] [try-resolve-locks-ts=447446588864331831] [concurrency=3]
[2024/02/02 19:32:59.305 +08:00] [INFO] [gc_worker.go:1095] ["[gc worker] finish resolve locks"] [uuid=6345a3cad480026] [safePoint=447446510221131776] [try-resolve-locks-ts=447446588864331831] [regions=1236]
[2024/02/02 19:33:59.057 +08:00] [INFO] [gc_worker.go:307] ["[gc worker] there's already a gc job running, skipped"] ["leaderTick on"=6345a3cad480026]TiDB GC 整体流程及常见问题
TiDB GC 整体流程主要分四个步骤,本章我们将逐一展开介绍。
目前我们 TiDB 侧的 GC 流程主要分为四个步骤:
- 计算 GC safepoint, 即 TiDB GC 时需要知道具体删除哪个时间点之前的旧版本。
- 清理 GC safepoint 之前事务留下的锁,即旧版本数据在被清理前,需要明确残留锁所在事务的状态。
- Delete-ranges 连续范围数据删除,即对于 truncate table 等这类在 TiKV 中连续保存的数据,直接在此阶段进行物理删除以优化性能。
- 将最新 safepoint 同步到集群其他组件(TiKV)
TiDB 中 GC worker 以上行为的发生频率我们可以在 grafana 监控中 tikv-details->GC->TiDB GC worker actions 看到。

下面我们逐一介绍每个步骤的原理、相关监控、配置及常见问题。
Step 1 计算 GC safepoint
根据 文章 对数据写入的简单介绍,我们知道当对同一个 key 进行多次增删改后,会在 raftstore 层留下所有的历史版本,随着这些版本的堆积,整体的读写性能将受到影响。TiDB 会定期触发 GC 工作对这些历史版本进行回收,那每次 GC 具体回收哪些旧版本数据呢?TiDB 在每次发生 GC 时,都会根据当前配置参数计算出一个 safepoint , 来决定具体回收哪些旧版本数据。
GC safepoint 的定义
- Safepoint 是一个时间戳,对应一个具体的物理时间。
- TiDB GC 会保证 ts >safepoint 的所有快照数据的安全性。

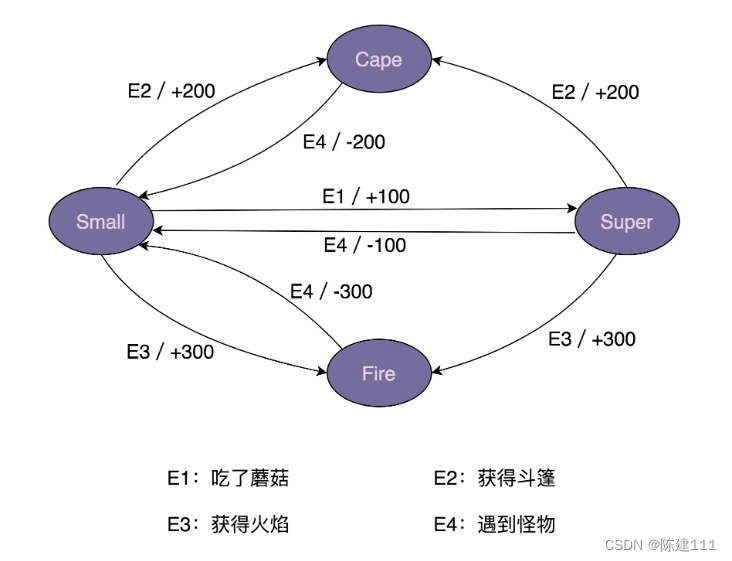
如上图,当前 key 一共有四个版本,
- 如果 gc safepoint 是 5:00, 则 GC 后只会保留 key_4:00 这条数据。
- 如果 gc safepoint 是 2:30, 则 GC 后会保留 key_4:00,key_3:00,key_02:00 这三条数据。以确保读 2:30 这一时刻的快照时,能读到 key_02:00 这条数据。
另外,当前系统的 gc safepoint 我们也可以在系统表 mysql.tidb 中看到:

GC safepoint 的计算过程及常见问题
了解了 GC safepoint, 我们知道其对集群数据的安全性非常重要,算错了 safepoint, 就可能将还需要的旧版本数据提前永久删除掉。所以在计算 safepoint 的时候,我们考虑到了多种情况。
以下是当前 gc worker 计算 safepoint 的主要过程:
1. 根据 GC lifetime 配置计算
GC lifetime ( https://docs.pingcap.com/tidb/stable/system-variables#tidb_gc_life_time-new-in-v50 )的定义:这个变量用于指定每次 GC 时需要保留的数据时限,默认为 10 分钟,即一般情况下,只保证十分钟以内的数据快照安全性即可。
GC safepoint = Current time - GC lifetime (10min by default)- 常见问题
当我们调整 gc lifetime 时,比如调大 gc lifetime 时,在 lifetime 符合要求之前会跳过几次 GC,相关 gc_worker 的日志如下
tidb_172.26.55.107_4000.log:[2024/01/16 09:06:52.689 +08:00] [Info] [gc_worker.go:1613] ["[gc worker] sent safe point to PD"] [uuid=6342b1728dc000d] ["safe point"=447035326078648378]
tidb_172.26.55.107_4000.log:[2024/01/16 09:15:11.099 +08:00] [Info] [gc_worker.go:731] ["[gc worker] there's another service in the cluster requires an earlier safe point. gc will continue with the earlier one"] [uuid=6342b1728dc000d] [ourSafePoint=447035555467755520] [minSafePoint=447035326078648378]对于这种情况符合预期,无绪介入。
2. 检查长时间运行且未提交的事务
检查当前集群所有 session 里面中,是否存在未提交的事务,且该事务 begin 时间早于上一步算出来的 gc safepoint
GC safepoint = min(GC safepoint,min_start_ts among all sessions)也就是说,gc safepoint 不应晚于当前正在执行中的事务的开始时间。
为了降低长时间运行的未提交事务对 GC 的影响,我们在 v6.1.0 中引入了参数 tidb_gc_max_wait_time( https://docs.pingcap.com/tidb/dev/system-variables#tidb_gc_max_wait_time-new-in-v610 ) (默认 24 小时),也就是当某个事务执行时间超过 24 小时后,该事务不会再卡住 gc safepoint 的推进。
- 常见问题
GC 在这一步卡住,可以从 gc_worker 日志中看到具体卡住的事务详情:
[gc_worker.go:359] ["[gc worker] gc safepoint blocked by a running session"] [uuid=609099af5940005] [globalMinStartTS=437144990507073574] [safePoint=2022/11/04 23:29:59.969 +08:00]Workaround: 检查 processlist 定位卡住的那个事务,咨询业务侧是否可以对该事务进行清理:
select * from INFORMATION_SCHEMA.CLUSTER_PROCESSLIST where TIMESTAMPDIFF(minute, now(), concat("2021-", substring_index(txnstart, "(", 1) )) < -10;3. 检查当前工具需要保留的快照版本
在实际业务集群中,用户可能使用了 CDC/BR 等备份工具,这些备份工具可能需要更早的一个快照进行备份,也就意味着这部分数据不能被 GC 掉。
GC safepoint = min(GC safepoint, min_service_gc_safe_points)- 常见问题
如果 GC 被这部分卡住了,一般可以通过 gc_worker 的日志类似如下:
[2022/02/24 17:18:01.444 +05:30] [INFO] [gc_worker.go:411] ["[gc worker] gc safepoint blocked by a running session"] [uuid=5f56cf29bac008e] [globalMinStartTS=431397745740742701] [safePoint=431398894023213056]
[2022/02/24 17:18:01.450 +05:30] [INFO] [gc_worker.go:581] ["[gc worker] there's another service in the cluster requires an earlier safe point. gc will continue with the earlier one"] [uuid=5f56cf29bac008e] [ourSafePoint=431397745740742701] [minSafePoint=431337131664474119] 在确认了是这一步卡住的后,就可以通过 PD 查看一下具体是哪个服务卡住了 GC 并介入处理了。
// 通过 pd-ctl 查看 service_gc_safe_points 下面的服务需要的最旧快照对应的 safepoint
tidb@172-16-120-219:~/shirly/tiup$ tiup ctl:v7.5.0 pd -u http://127.0.0.1:2379 service-gc-safepoint
Starting component `ctl`: /home/tidb/.tiup/components/ctl/v7.5.0/ctl pd -u http://127.0.0.1:2379 service-gc-safepoint
{
"service_gc_safe_points": [
{
"service_id": "gc_worker",
"expired_at": 9223372036854775807,
"safe_point": 447873652897873920 // 这个是在当前这一步上传的 gc safepoint.
},
{
"service_id": "ticdc-default-157...",
"expired_at": 9223372036854645313,
"safe_point": 447873653919043430
}
],
"gc_safe_point": 447873652897873920 // 这个是 TiDB GC 最后一步上传的 safepoint, 用于通知 tikv 用。
}
// 计算每个 service safepoint 实际对应的时间。
tidb@172-16-120-219:~/shirly/tiup$ tiup ctl:v7.5.0 pd -u http://127.0.0.1:2379 tso 447873652897873920
Starting component `ctl`: /home/tidb/.tiup/components/ctl/v7.5.0/ctl pd -u http://127.0.0.1:2379 tso 447873652897873920
system: 2024-02-21 15:59:59.055 +0800 CST
logic: 0
tidb@172-16-120-219:~/shirly/tiup$ tiup ctl:v7.5.0 pd -u http://127.0.0.1:2379 tso 447873653919043430
Starting component `ctl`: /home/tidb/.tiup/components/ctl/v7.5.0/ctl pd -u http://127.0.0.1:2379 tso 447873653919043430
system: 2024-02-21 16:00:02.95 +0800 CST
logic: 118630Step 2 : Resolve locks
为什么要清理锁
在有了 gc safepoint 之后,意味着在本轮 GC 中,我们在保证所有 tso >= safepoint 版本的快照安全性的基础上,可以开始删除旧版本了, 那么在删除旧版本之前,如果遇到了锁怎么办呢?根据我们之前对分布式事务的理解,用户在 commit 一个事务之后,TiKV 内部还是有可能留下锁的,而这些锁的提交状态则是存在 primary-key 上,试想以下情况:

- 事务 1:
- 事务 ID 即 start_ts 是 t1, commit_ts 为 t2。
- 更新 A,B,C 三个 key, 客户端 commit 且返回成功。
- 当前分布式事务 primary_key 是 A , 也就是事务的状态存在 A 上 。
- B,C 上有当前 t1 所在事务的残留 lock 。
- 事务 2:
- 事务 ID 即 start_ts 为 t3, commit_ts 为 t4。(t1<t2<t3<t4)。
- 更新 A, D 两个 key, 客户端 commit 且返回成功。
- A,**D** 新版本写入成功,无残留锁。
现在假设我们算出来的 GC safepoint 是 t4 , 也就是保证能读到 t4 这一时刻的快照数据一致即可。对于 A , 当前 t4 可见的数据为 A_t4=>t3,A_t3=>12, 也就是 A 在 t4 这个时刻快照读到的数据是 12。
对于比这个版本更旧的版本 A_t2=>t1 我们认为在当前 gc safepoint 下是可以删除的。那我们可以直接删除 A_t2=>t1 这个版本吗?
假设我们直接删除,删除之后,如果用户要读 t4 这个快照里面 B 的值,发现 B 上有个指向 (A,t1) 的这个 lock, 我们开始从 A 上确认事务 t1 的状态,但是在 TiKV 中找不到 (A,t1) 这个事务,也就无法确认其状态。
以上,就是我们为什么要在真正清理旧版本数据之前,要先对 gc safepoint 之前启动的事务所在残留锁进行清理的原因,这个过程我们定义为 Resolve locks。
Resolve locks 具体过程

知道了 Resolve locks 的原因后,我们很容易就理解,resolve locks 这一步简单理解,就是对 tikv 中的 Lock CF 进行扫描,并清理掉 lock.ts <= gc safepoint 的锁即可。在实际操作中,我们操作步骤如下:
- 将请求发给每个 region 的 leader 获取到 lock
- 根据 lock 状态,逐个 resolve lock:
- 向 PD 定位当前 lock 里面 primary-key 所在的 region 信息
- 向对应的 TiKV 发送获取当前 (primary-key,事务 ID ) 对应的事务状态
- 根据 (primary-key,事务 ID) 对应的状态:
- 事务已提交,向 tikv 提交 lock。
- 事务已 rollback, 向 tikv 发送回滚该 lock 的消息。
相关配置
既然是按照 region 查找锁并进行清理,这个过程完全可以是并发的,针对这一步,目前 TiDB 提供了以下参数:
- tidb_gc_concurrency( https://docs.pingcap.com/tidb/v6.5/system-variables#tidb_gc_concurrency-new-in-v50 )Resolve locks 步骤中的线程数,默认 -1 表示使用 TiKV 实例的个数作为并发数。一般情况下不用去调整这个值。
相关监控
在 grafana 上 tikv-details/gc/resolveLocks Progress 面板中,可以看到这一步骤以 region 为单位的执行进度。

常见问题
这一步是否可能卡住 GC?
一般的 resolveLocks 不应该卡住 GC,当这一步骤出现问题时,数据可能存在一致性问题,如果数据比较重要的话,应立即联系官方协助恢复。同样的,这一步骤出现问题需要通过 gc worker 的日志进行判断,可以参考 GC leader 章节的方式定位相关日志。
历史上 v5.1.3 有个 bug( https://github.com/pingcap/tidb/issues/26359 )会导致数据一致性的问题而导致 Resolve Locks 失败。错误日志类似长这样:
[gc_worker.go:621]["[gc worker] resolve locks returns an error"]..Resolve locks 对性能的影响
对于比较空闲的集群,GC 期间 resolve locks 是会对 TiKV 产生性能影响的,主要原因为 resolve lock 需要对集群中所有 region 读取 lock 信息而导致静默 region 被唤醒,从而导致 raftstore/TiKV CPU 出现抖动。具体影响如下:
- 不 hibernate 但 GC。一个 tikv 维护 1w 个 region 需要消耗 15% cpu 的开销。
- 不 hibernate 不 GC。一个 tikv 维护 1w 个 region 需要消耗 10% cpu 的开销。
- hibernate 不 GC。一个 tikv 维护 1w 个 region 需要消耗 1% cpu 的开销。
- hibernate 定期 GC。一个 tikv 维护 1w 个 region 需要消耗 1% cpu 的开销外加 GC 期间达到 10-15% 的开销。
所以 4 相比 1 于就会有类似的尖刺现象,因为平常的 baseline 更低
Step 3 : Delete Ranges
在上一步骤中,我们已经将锁清理完毕,也就是所有 gc safepoint 之前的事务状态已经明确。所以,从这一步开始,我们可以真正地开始清理数据了。在正常情况下,因为我们底层用的是 rocksdb, 在我们明确一个版本可以清理以后,会直接调用 rocksdb 的 delete 接口去清理该 key. 但我们知道,rocksdb 本身使用的是 LSM 架构,也就是说它也有 mvcc, 它的一次删除,最终也是转化成了一次写入。那数据什么时候会真正清理呢?就需要等我们 rocksdb 的。compaction 操作来清理了,这个过程就十分漫长了,后续我们还会继续谈论这个话题。
现在从 TiDB 视角看,有一些数据清理操作,如:
- Drop table/index
- Truncate table
- Drop partition
- ...
以上操作在 GC 时需要将连续的大片数据进行删除。对于这部分数据,我们认为在过了 GC safepoint 之后,可以直接清理,不需要跟普通的 GC 一样对历史版本一边读一边删除的过程。Delete Ranges 就是我们针对这种连续的大块删除的优化。在这一步骤中,我们会直接对数据进行物理回收,空间会立刻被释放出来,极大地减少这一块 GC 对系统读写的压力。
具体步骤如下:
- 执行 SQL 阶段:这些符合 delete-range 要求的 SQL 会在执行 时,记录在系统表 mysql.gc_delete_range,并标记其删除的时间 ts:

- GC 阶段:根据上表中删除时间 ts 与当前 gc safepoint 进行比对,对于符合删除条件的数据,调用 tikv 的 unsafeDestroyRange 接口对所有 tikv 发送。TiKV 在收到这个请求后,会直接绕过 raft 对本地的 rocksdb 进行 destroyRange 操作。同时,做完以后,我们会将结果记录在系统表 gc_delete_range_done 里面:

常见问题
这一步也很少出问题,但是不排除短期内需要删除大量数据时,这一步执行比较慢而导致 GC 看似被卡住的情况。对于这种情况不需要做太多介入,耐心等待其完成即可。
Step 4 : Sync gc safepoint
最后,我们会将 GC safepoint 存储到 PD 上,以通知 tikv 进行 GC。TiKV 定期会从 PD 上拿 gc safepoint, 如果发生了变更,则会拿当前的 gc safepoint 开始 tikv 本地的 GC 工作。
相关监控
我们可以从 grafana 上的 tikv-details->GC->TiKV auto GC safepoint 观察 gc safepoint 推进是否符合预期:
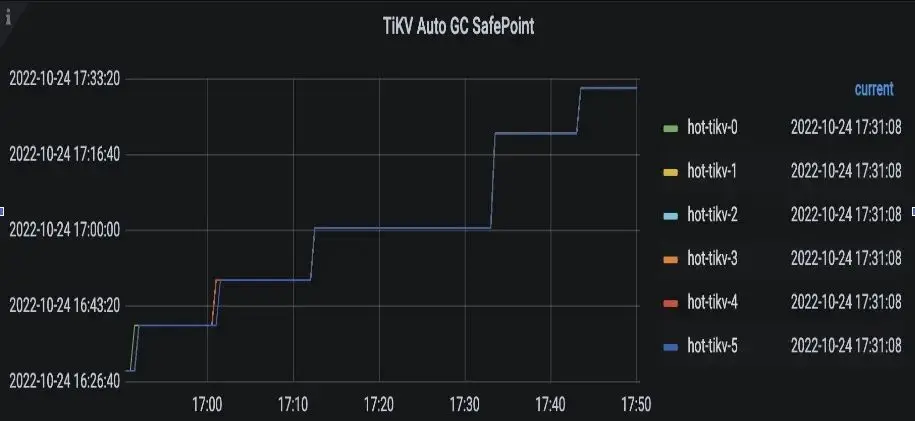
常见问题
PD 一共提供了两个接口来存 gc_safepoint, 分别为:
- UpdateServiceGCSafepoint:在 计算 GC safepoint 那一步调用,这步调用成功,意味着TiDB侧 GC 正式开始
- UpdateGCSafepoint 在最后这一步“ save gc safepoint toPD ”执行,这一步调用成功,意味着TiDB侧 GC 正式结束。
一般情况下这两个接口的 safepoint 应该是保持一致的,当不一致时,一般是
updateGCSafepoint< UpdateServiceGCSafepoint
也就是 GC 在 TiDB 这一侧某一步卡住了。生产情况下有些卡住是符合预期的,如下面这种情况:
- 在工具卡住 gc safepoint 之后,两接口的 gc safepoint 出现不一致。如果此时又正好调大了 gc lifetime, 那么在下一次 gc 成功执行完成之前,这两个接口对应的值会一直不一致。
具体影响:无。