之前的文章有写如何获取数据、如何补充数据,也有说如何对数据进行清洗、如何使用结构化数据进行训练。但好像没有说如何将训练数据“入库”。这里说的入库不是指 MySQL 数据库,而是指向量检索库 Milvus。
众所周知,人工智能多用向量数据进行训练。数据先做向量处理并入库能有效减少训练时实时转换带来的性能消耗(之前在 Autokeras 训练时是读取 MySQL 结构化数据的,每次取数后都需要通过 Embedding 先做向量处理再训练)。
至于为什么要选择 Milvus ?这跟公司技术栈有关就不详述了。
部署 Milvus
Milvus 我是采用 Docker Compose 来部署的,主要是因为网上已有现成的 docker compose 脚本“milvus-standalone-docker-compose.yml”直接下载开箱即用即可。如下图:
整个脚本唯一值得关注的就是 Minio 管理后台账号和密码(若企业部署建议不要写在脚本中,透过添加 --env-file .env 参数的方式进行传递)。接着就通过以下命令启动就好了:
docker-compose -f milvus-standalone-docker-compose.yml up -d
启动结果如下图:

不得不说的是,Milvus 的 standalone 镜像是非常消耗资源的,为了避免运行过程中出现资源不足的情况,建议在 docker compose 脚本中根据自己机器的实际情况进行资源调整。
接着就可以通过 http://127.0.0.1:9001/login 访问 Minio 的管理后台,如下图:

至于 Minio 要如何使用,这个不是本节的重点就不再叙述了。
此外,按网上说法还需要部署一个名为 attu 的服务用于管理 Milvus 数据,执行下面命令即可:
docker run -d --name=attu -p 8000:3000 -e MILVUS_URL='宿主机ip':'milvus端口' zilliz/attu:v2.2.6
服务启动后通过 http://127.0.0.1:8000/ 访问 attu 的管理后台,如下图:

至此 Milvus 部署完毕。(后面若有空会补全 Milvus 相关的知识点内容,先挖个坑…)
代码实现
下面将讲讲如何用 python 将问答数据向量化并入库的。
- 创建测试入口并构建基础代码
from transformers import AutoTokenizer, AutoModel
from pymilvus import connections, FieldSchema, CollectionSchema, DataType, Collection, utility
# baai 模型名称与 model 实例
baai_model_name = "BAAI/bge-large-zh-v1.5"
baai_model = AutoModel.from_pretrained(baai_model_name)
...
def data_transformer_to_vetor():
# 通过 AutoTokenizer 获取 baai 的 tokenizer 对象
tokenizer = AutoTokenizer.from_pretrained(baai_model_name)
# 创建 milvus 连接
connections.connect(milvus_name, host=milvus_url, port=milvus_port)
# 获取 milvus 中指定的数据集
collection = find_milvus_collection()
try:
while True:
# 根据条件 flag = 0 分页查询 MySQL 的问答数据
db_data = mu.query_by_pagination(mysql_page, mysql_page_size, mysql_table_name, 'FLAG = 0')
if db_data != '':
db_data_json_arr = json.loads(db_data)
vectors = []
ids = []
# 遍历问答数据集将“问题”和“答案”字段重新组装成一条字符串
for db_data_json in db_data_json_arr:
text = f"问题:{db_data_json[1]} 答案:{db_data_json[2]}"
# 使用 baai 模型对字符串进行向量转换
vector = change_to_vetor(tokenizer, text)
# 将向量数据装载到一个数据集中
vectors.append(vector)
# 同时,也将 MySQL 中对应记录的 id 进行记录
ids.append(db_data_json[0])
if len(vectors) > 0:
# 批量插入向量数据到 milvus 数据集中
collection.insert(data=[vectors])
# 更新 MySQL 对应的记录,看 flag 设置为 1,这样在下一个循环时就不会被重新筛选出来了
mu.update_by_ids(mysql_table_name, 'FLAG = 1', ids)
else:
break
except Exception as e:
print(f"Error: {e}")
finally:
# 无论成功与否都释放数据集并关闭 milvus 连接
collection.release()
connections.disconnect(milvus_name)
...
if __name__ == '__main__':
data_transformer_to_vetor()
在上面的代码中提到了 find_milvus_collection 和 change_to_vetor 函数,下面让我先对 change_to_vetor 函数进行解释。
- change_to_vetor 函数(baai 模型转换向量数据)
def change_to_vetor(tokenizer, text):
# 定义输入内容
inputs = tokenizer(text, return_tensors="pt",max_length=512, padding=True, truncation=True)
# 调用 baai_model 并以 inputs 作为入参
outputs = baai_model(**inputs)
# outputs 转换成向量数据返回
return outputs.last_hidden_state.mean(dim=1).squeeze().detach().numpy()
这个 3 行代码将非常有用,它不仅存储的时候需要使用,在后面做数据取回时也需要先将字符串向量化后,再提供给 Milvus 进行数据筛选的。因此有必要独立成一个函数,方便后面使用。
- find_milvus_collection 函数(获取 milvus 数据集)
def find_milvus_collection():
# 使用 utility.has_collection 来判断在 milvus 中是否存在指定的数据集
if utility.has_collection(milvus_collection_name, using=milvus_name):
# 如果有直接获取
collection = Collection(milvus_collection_name, using=milvus_name)
else:
# 没有则需要调用 create_milvus_collection 函数创建数据集
collection = create_milvus_collection()
# 加载数据到内存
collection.load()
return collection
这个函数首先使用了 pymilvus 的 utility.has_collection 进行判断,这里需要注意的是如果 Milvus 连接是自定义的情况下,必须加上 using 参数指向自定义连接,不然系统会使用默认“default”连接并报以下错误:
pymilvus.exceptions.ConnectionNotExistException: <ConnectionNotExistException: (code=1, message=should create connection first.)>
同理,在创建数据集时也需要用 using 参数指向自定义连接。
在获取到数据集之后需要将其加载到内存里面,不然在点击 attu 的 data preview 选项卡时会看到以下错误:
Failed to search: collection not loaded[collection=448914542771864105]
需要注意的是,加载大型集合可能需要一些时间,具体取决于集合的大小和系统资源。如果不再需要对集合进行操作,建议使用 collection.release() 方法将其从内存中释放,以节省资源。
- create_milvus_collection 函数(创建 Milvus 数据集)
def create_milvus_collection():
# 创建 id 字段作为主键
id_field = FieldSchema(name="id", dtype=DataType.INT64,is_primary=True, auto_id=True)
# 创建向量数据存储字段
vector_field = FieldSchema(name="vector_qa", dtype=DataType.FLOAT_VECTOR, dim=milvus_dim)
# 定义schema
schema = CollectionSchema(fields=[id_field, vector_field], description="TCM Question and Answer Dataset", enable_dynamic_field=True)
# 创建数据集
collection = Collection(name=milvus_collection_name,schema=schema, using=milvus_name)
# 给向量数据字段添加索引
collection.create_index(field_name="vector_qa", index_params={"metric_type": "L2", "index_type": "IVF_PQ", "params": {"nlist": milvus_dim}})
return collection
这个创建数据集的函数其实也比较好理解,就像 MySQL 的表创建一样。
需要注意的是,在网上的例子中向量字段(本例子为:vector_field)会被创建成一个维度为 768 的 FLOAT_VECTOR 类型字段,但问答数据在经过 baai 模型转换后的默认维度为 1024,在数据保存的时候就会出现以下错误:
RPC error: [batch_insert], <ParamError: (code=1, message=Collection field dim is 768, but entities field dim is 1024)>, <Time:{'RPC start': '2024-04-07 16:02:07.393036', 'RPC error': '2024-04-07 16:02:07.393106'}>
Error: <ParamError: (code=1, message=Collection field dim is 768, but entities field dim is 1024)>
这时只需要将 dim 参数从 768 改为 1024 即可(可以简单理解为 MySQL 字段内容过长,那就加大字段长度呗)。如果维度一定要保持在 768,那么可以使用 PCA 进行降维处理。
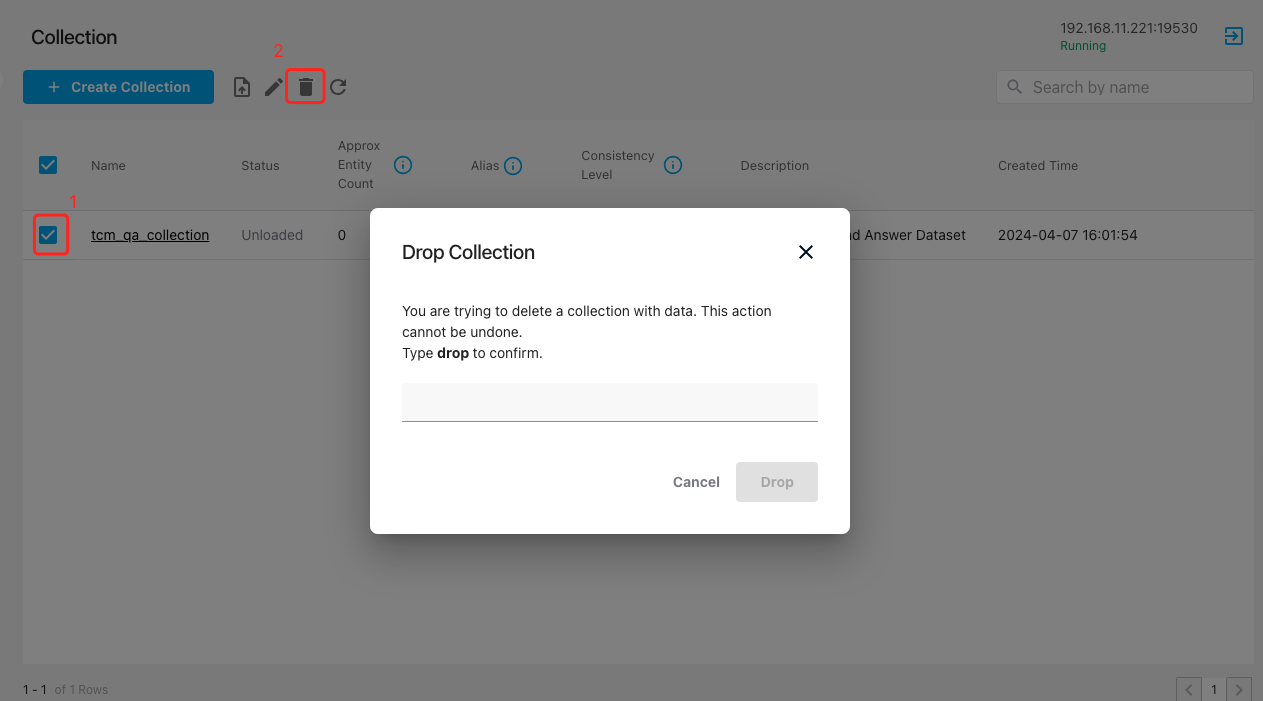
既然需要重建数据集,那么如何将已有的数据集删除呢?
除了通过代码的方式删除外,我们还可以通过 attu 界面删除,如下图:

先确认是否当前的数据集,之后在上一页的可视化界面中删除即可。
至此,所有代码都已经编写完成了。噢,还有一件事儿。我这边在启动代码时会报这个警告:
/Users/yuanzhenhui/anaconda3/envs/transformer/lib/python3.11/site-packages/torch/_utils.py:831: UserWarning: TypedStorage is deprecated. It will be removed in the future and UntypedStorage will be the only storage class. This should only matter to you if you are using storages directly. To access UntypedStorage directly, use tensor.untyped_storage() instead of tensor.storage()
return self.fget.__get__(instance, owner)()
这个警告信息是由 PyTorch 库引发的,它提示 TypedStorage 类已经被弃用,在未来的版本中将被移除,届时只会保留 UntypedStorage 类。这个警告主要与直接使用 storage 有关。TypedStorage 和 UntypedStorage 是 PyTorch 中用于存储张量(tensor)数据的底层存储类。TypedStorage 是针对特定数据类型(如 Float、Double、Int 等)的存储,而 UntypedStorage 是一种通用的存储类型。
这个警告并不影响代码的使用,暂时忽略即可,但如果有条件的可以按照提示进行切换。