概述
本章利用KVM 及 GlusterFS 技术,结合起来从而实现 KVM 高可用。利用 GlusterFS 分布式复制卷,对 KVM 虚拟机文件进行分布存储和冗余。分布式复制卷主要用于需要冗余的情况下把一个文件存放在两个或两个以上的节点,当其中一个节点数据丢失或者损坏之后,KVM 仍然能够通过卷组找到另一节点上存储的虚拟机文件,以保证虚拟机正常运行。当节点修复之后,GlusterFS 会自动同步同一组卷组里面有数据的节点数据
实验前置知识点
1. Glusterfs简介
GlusterFS 分布式文件系统是由 Gluster 公司的创始人兼首席技术官 Anand Babu Periasamy 编写。一个可扩展的分布式文件系统,可用于大型的、分布式的、对大量数据进行访问的应用。它可运行于廉价的普通硬件上,并提供容错功能;也可以给大量的用户提供 总体性能较高的服务。GlusterFS 可以根据存储需求快速调配存储,内含丰富的自动故障转移功能,且摒弃集中元数据服务器的思想。适用于数据密集型任务的可扩展网络文件系统, 且免费开源。Gluster 于 2011 年 10 月 7 日被 Red Hat 收购
2. Glusterfs特点
- GlusterFS 体系结构,将计算、存储和 I/O 资源聚合到全局名称空间中,每台服务 器都被视为节点,通过添加附加节点或向每个节点添加额外存储来扩展容量。通过在更多节点之间部署存储来提高性能
- GlusterFS 支持基于文件的镜像和复制、分条、负载平衡、故障转移、调度、磁盘缓存、存储配额、卷快照等功能
- GlusterFS 各客户端之间无连接,本身依赖于弹性哈希算法,而不是使用集中式或分布式元数据模型
- GlusterFS 通过各种复制选项提供数据可靠性和可用性,例如复制卷、分布卷
实验环境
1. 实验环境
公司由于大规模使用 KVM 虚拟机来运行业务,为了保证公司虚拟机能够安全稳定运行,决定采用 KVM+GlusterFS 模式,来保证虚拟机存储的分布部署,以及分布冗余。避免当虚拟机文件损坏,或者丢失。从而在损坏或就丢失时有实时备份,保证业务正常运行
本实验环境如图

2. 实验需求
(1)部署GlusterFS文件系统
(2)实现KVM虚拟主机不会因宿主机宕机而宕机
3. 实验实验思路
(1)安装KVM
(2)所有节点部署GlusterFS
(3)客户端挂载GlusterFS
(4)KVM使用挂载的GlusterFS目录创建虚拟机
实验实施
1. 安装部署KVM虚拟化平台
(1)安装KVM虚拟化平台
在 CentOS 的系统光盘镜像中,已经提供了安装 KVM 所需软件。通过部署基于光盘镜像的本地 YUM 源,直接使用 YUM 命令安装所需软件即可,安装 KVM 所需软件具体包含以下几个
[root@kvm01 ~]# yum -y install qemu-kvm qemu-kvm-tools virt-install qemu-img bridge-utils libvirt
(2)验证
重启系统后,把这个勾选上
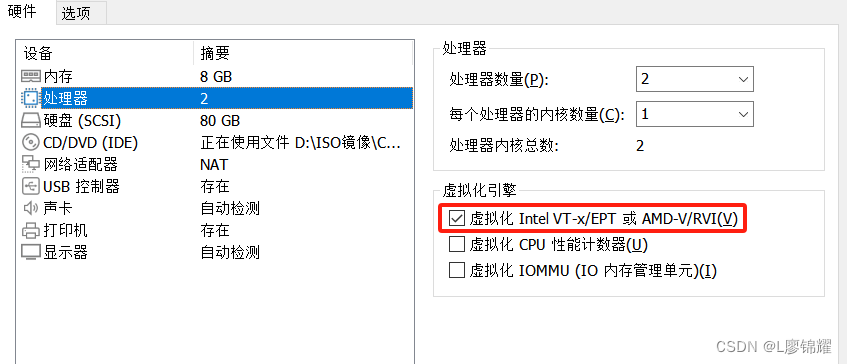
查看 CPU 是否支持虚拟化,对于 Intel 的服务器可以通过以下命令查看,只要有输出就说明 CPU 支持虚拟化;AMD 服务器可用 cat/proc/cpuinfo | grep smv 命令查看
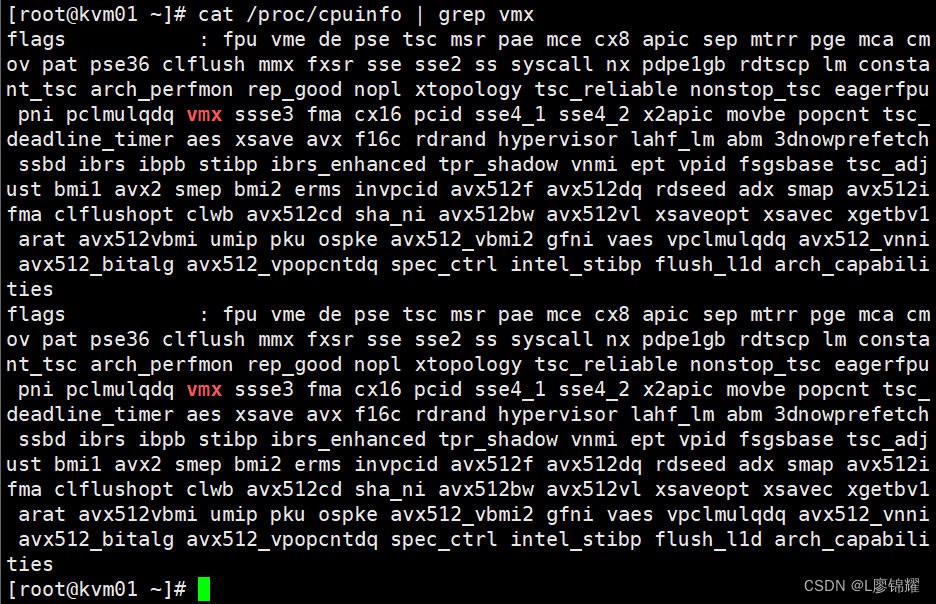
检查KVM模块是否安装
[root@kvm01 ~]# lsmod | grep kvm
kvm_intel 183621 0
kvm 586948 1 kvm_intel
irqbypass 13503 1 kvm(3)开启libvirtd服务
[root@kvm01 ~]# systemctl start libvirtd
[root@kvm01 ~]# systemctl enable libvirtd(4) 设置KVM网络为桥接模式
[root@kvm01 ~]# cd /etc/sysconfig/network-scripts/
[root@kvm01 network-scripts]# cp ifcfg-ens33 ifcfg-br0
[root@kvm01 network-scripts]# vim ifcfg-ens33
TYPE="Ethernet"
UUID="8b7a6370-b54d-428f-bab7-104c308715e3"
PROXY_METHOD="none"
BROWSER_ONLY="no"
BOOTPROTO="none"
DEFROUTE="yes"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_FAILURE_FATAL="no"
IPV6_ADDR_GEN_MODE="stable-privacy"
NAME="ens33"
DEVICE="ens33"
ONBOOT="yes"
IPV6_PRIVACY="no"
BRIDGE=br0
[root@kvm01 network-scripts]# vim ifcfg-br0
NAME=br0
DEVICE=br0
ONBOOT=yes
IPADDR=192.168.161.200
NETMASK=255.255.255.0
GATEWAY=192.168.161.2
DNS1=202.96.128.86
DNS2=119.29.29.29
TYPE=Bridge(5)重启网络服务查看IP地址
[root@kvm01 network-scripts]# systemctl restart network
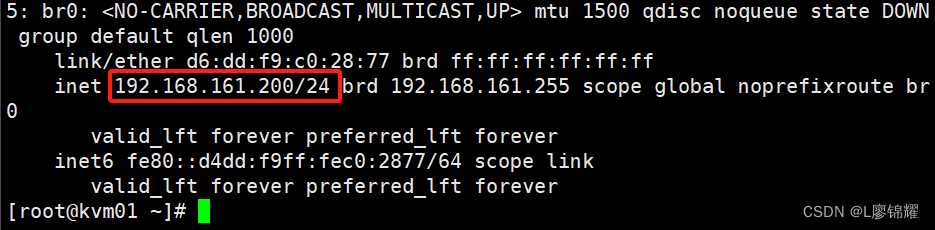
2. 部署GlusterFS
在所有节点上执行如下命令
(1)关闭防火墙、SELinux,将四台服务器的主机名分别改为node1、node2、node3、node4。下面以node1为例进行操作
[root@node1 ~]# systemctl status firewalld.service
● firewalld.service - firewalld - dynamic firewall daemon
Loaded: loaded (/usr/lib/systemd/system/firewalld.service; disabled; vendor preset: enabled)
Active: inactive (dead)
Docs: man:firewalld(1)
[root@node1 ~]# cat /etc/sysconfig/selinux | grep disabled
# disabled - No SELinux policy is loaded.
SELINUX=disabled
[root@node1 ~]#
(2)编写hosts文件
[root@node1 ~]# vim /etc/hosts
192.168.161.10 node1
192.168.161.11 node2
192.168.161.12 node3
192.168.161.13 node4
192.168.161.200 kvm01(3)安装软件
[root@node1 ~]# yum -y install centos-release-gluster
[root@node1 ~]# yum -y install glusterfs glusterfs-server glusterfs-fuse glusterfs-rdma --skip-broken
(4)启动GlusterFS
[root@node1 ~]# systemctl start glusterd
[root@node1 ~]# systemctl enable glusterd(5)在node1上添加所有节点
[root@node1 ~]# gluster peer probe node2
peer probe: success
[root@node1 ~]# gluster peer probe node3
peer probe: success
[root@node1 ~]# gluster peer probe node4
peer probe: success
[root@node1 ~]# (6)查看群集状态
[root@node1 ~]# gluster peer status
Number of Peers: 3
Hostname: node2
Uuid: bf0fafed-a1fd-4830-b36d-fe6719c33a7d
State: Peer in Cluster (Connected)
Hostname: node3
Uuid: 9d9ac472-2bf6-4a9c-8fcc-193ed83728ef
State: Peer in Cluster (Connected)
Hostname: node4
Uuid: 3e842864-cda8-4247-931f-114ec8569168
State: Peer in Cluster (Connected)
[root@node1 ~]#
3. 创建GlusterFS分布式复制卷
当前一共有四个节点,设置为 2x2=4,就是 2 个节点为一组,一个卷组两个节点会有相同的数据。从而达到虚拟机数据分布式存储并有冗余备份
(1)给每台服务器加一块硬盘
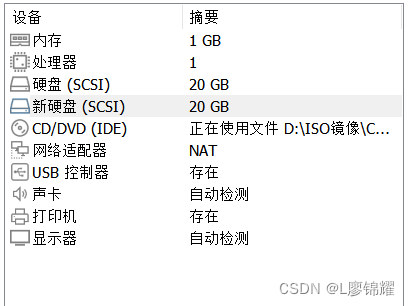
(2)进行分区格式化
[root@node1 ~]# fdisk /dev/sdb
[root@node1 ~]# mkfs.xfs /dev/sdb1
(3)创建目录并挂载
[root@node1 ~]# mkdir /data
[root@node1 ~]# mount /dev/sdb1 /data/
[root@node1 ~]# df -Th
文件系统 类型 容量 已用 可用 已用% 挂载点
/dev/sda3 xfs 18G 4.7G 14G 26% /
devtmpfs devtmpfs 471M 0 471M 0% /dev
tmpfs tmpfs 487M 0 487M 0% /dev/shm
tmpfs tmpfs 487M 8.3M 479M 2% /run
tmpfs tmpfs 487M 0 487M 0% /sys/fs/cgroup
/dev/sda1 xfs 1014M 164M 851M 17% /boot
tmpfs tmpfs 98M 8.0K 98M 1% /run/user/42
tmpfs tmpfs 98M 0 98M 0% /run/user/0
/dev/sdb1 xfs 20G 33M 20G 1% /data
(4)创建分布式复制卷
[root@node1 ~]# gluster volume create aaa replica 2 node1:/data node2:/data node3:/data node4:/data force
volume create: aaa: success: please start the volume to access data
(5)启动并查看卷
[root@node1 ~]# gluster volume start aaa
volume start: aaa: success
[root@node1 ~]# gluster volume info aaa
Volume Name: aaa
Type: Distributed-Replicate
Volume ID: 668e2a4d-b464-4817-90b6-308a6d0eef3e
Status: Started
Snapshot Count: 0
Number of Bricks: 2 x 2 = 4
Transport-type: tcp
Bricks:
Brick1: node1:/data
Brick2: node2:/data
Brick3: node3:/data
Brick4: node4:/data
Options Reconfigured:
cluster.granular-entry-heal: on
storage.fips-mode-rchecksum: on
transport.address-family: inet
nfs.disable: on
performance.client-io-threads: off
4. 客户端挂载glusterfs卷
(1)安装glusterfs客户端软件
[root@kvm01 ~]# yum -y install centos-release-gluster
[root@kvm01 ~]# yum -y install glusterfs glusterfs-fuse(2)编写hosts文件
[root@kvm01 ~]# vim /etc/hosts
192.168.161.10 node1
192.168.161.11 node2
192.168.161.12 node3
192.168.161.13 node4
192.168.161.200 kvm01(3)创建挂载目录,并挂载aaa卷
[root@kvm01 ~]# mkdir /kvmdata
[root@kvm01 ~]# mount -t glusterfs node1:aaa /kvmdata/
[root@kvm01 ~]# df -Th
文件系统 类型 容量 已用 可用 已用% 挂载点
/dev/sda3 xfs 74G 5.3G 69G 8% /
devtmpfs devtmpfs 3.9G 0 3.9G 0% /dev
tmpfs tmpfs 3.9G 0 3.9G 0% /dev/shm
tmpfs tmpfs 3.9G 13M 3.9G 1% /run
tmpfs tmpfs 3.9G 0 3.9G 0% /sys/fs/cgroup
/dev/sda1 xfs 1014M 164M 851M 17% /boot
tmpfs tmpfs 797M 8.0K 797M 1% /run/user/42
tmpfs tmpfs 797M 60K 797M 1% /run/user/0
/dev/sr0 iso9660 11G 11G 0 100% /run/media/root/CentOS 7 x86_64
node1:aaa fuse.glusterfs 40G 475M 40G 2% /kvmdata
5. KVM使用卷创建虚拟机
(1)先把需要的镜像文件上传
[root@kvm01 ~]# cd /kvmdata/
[root@kvm01 kvmdata]# mkdir iso
[root@kvm01 kvmdata]# cd iso
[root@kvm01 iso]# ls
CentOS-7-x86_64-Minimal-1810.iso
(2)创建虚拟机
[root@kvm01 ~]# virt-install -n test01 -r 1024 --vcpus=1 --disk path=/kvmdata/test01.qcow2,size=10 -w bridge:br0 --virt-type=kvm --accelerate --autostart -c /kvmdata/iso/CentOS-7-x86_64-Minimal-1810.iso --vnc --vncport=5901 --vnclisten=0.0.0.0
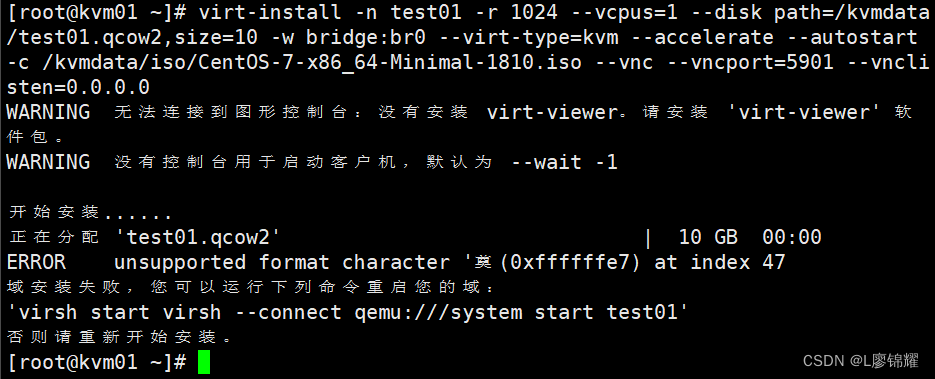
(3)使用vnc进行连接

这里就是正常的装Centos了
(4)查看创建的虚拟机状态
[root@kvm01 ~]# virsh list --all
Id 名称 状态
----------------------------------------------------
1 test01 running
实验验收
验证存储,在四台节点上查看目录里是否存在虚拟机文件。可以看到虚拟机文件已经存放到node3、node4里面了
[root@node3 ~]# ls /data/
iso test01.qcow2
[root@node4 ~]# ls /data/
iso test01.qcow2
从上面结果看,虚拟机文件已同步到卷组 node3、node4 当中,再发生宿主机宕机后,将不会影响虚拟机正常使用