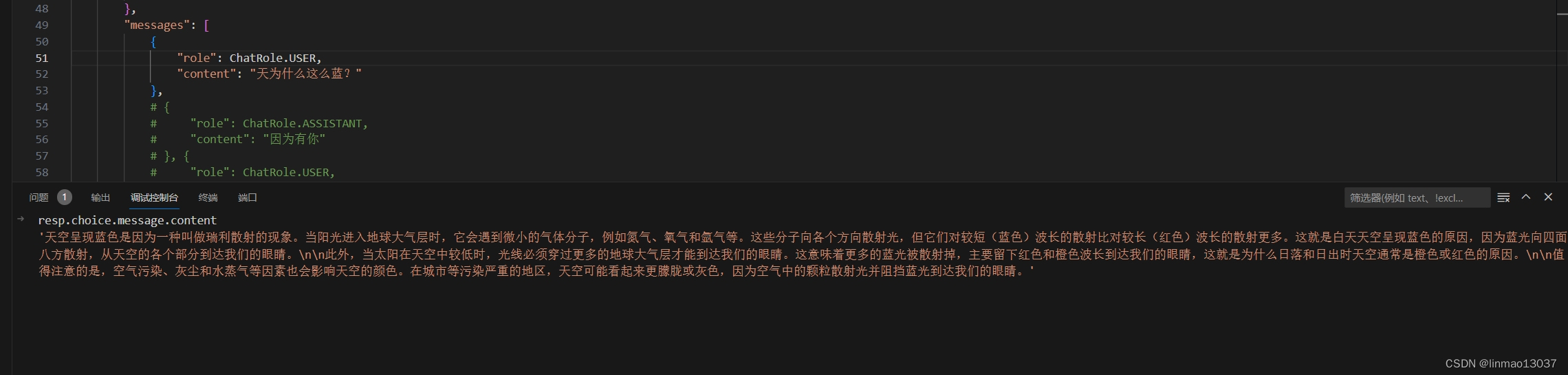
本文基于《python3从入门到精通》进行编写
- python是什么
是一种简单易学的计算机编程语言,有配套的软件工具和库。
是一种开源的语言。因其有许多强大的开源库使得python对与计算、大数据、人工智能都有很强的支持能力。
是一种解释型语言。其代码不需要编译就可以执行,由python解释器直接解释并执行。(C语言是先将源代码编译成机器语言然后转换为二进制可执行文件后执行),python先将源代码转换为字节码,再由python解释器来执行这些字节码。使其不需要任何改动就可以运行在不同的操作系统。
- python基础
2.1输出
Python中使用print(”xxx”)即可输出里面的xxx内容。
例如:输出hello world
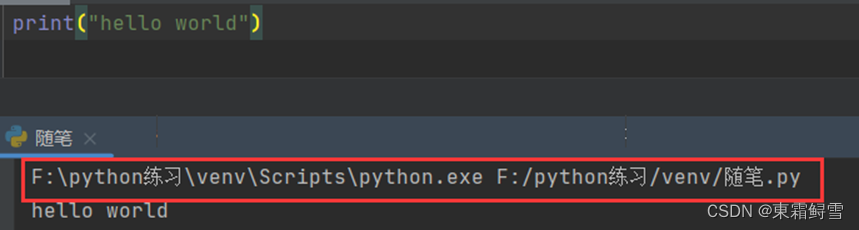
其中红色矩形框圈着部分为当前python文件所在位置。
下方则为输出的内容
不加””则可以进行一些简单的加减乘除计算,加(+)、减(-)、乘(*)、除(/)、幂次方(**)、取余(%)、取整数(//)。
例如:
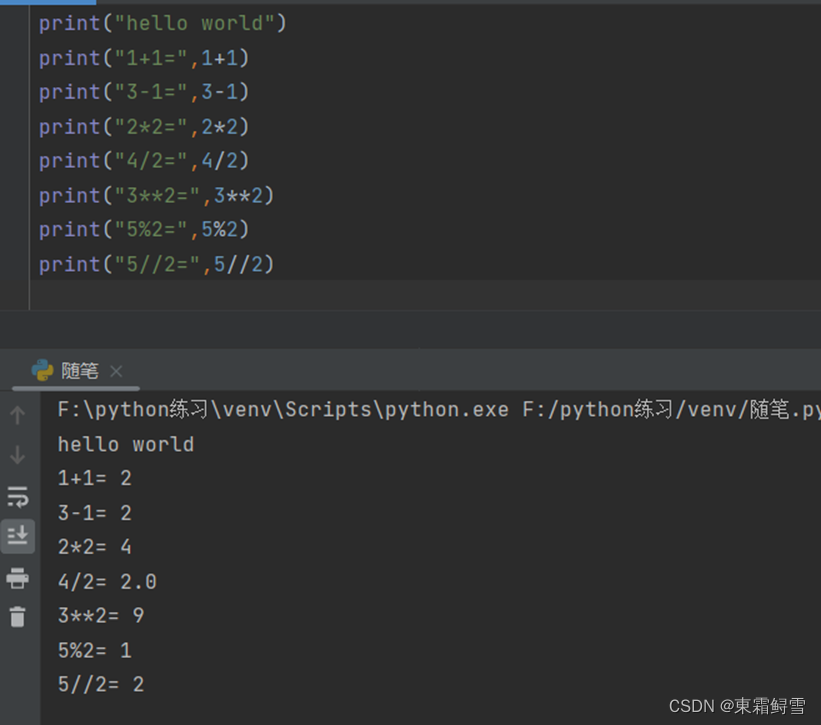
以上用英文逗号可以连续在print里面放置多个内容。在“”中有\n则从这后面换行继续输出
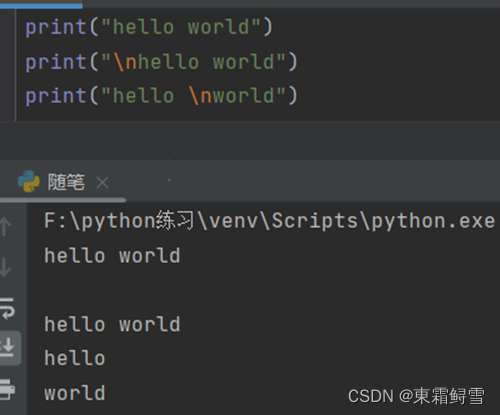
这里包含内容的双引号还可以是单引号’’和三引号””””””

在三引号可以换行写,而其他两个则不行
2.2注释
Python中有单行注释和多行注释两种,单行注释则是在要注释的哪一行内容前使用#,而多行注释则是三引号跟上述可以多行输出的三引号一样,也可以是三个单引号。在代码中使用注释可以使阅读代码更容易且也有备注的作用。
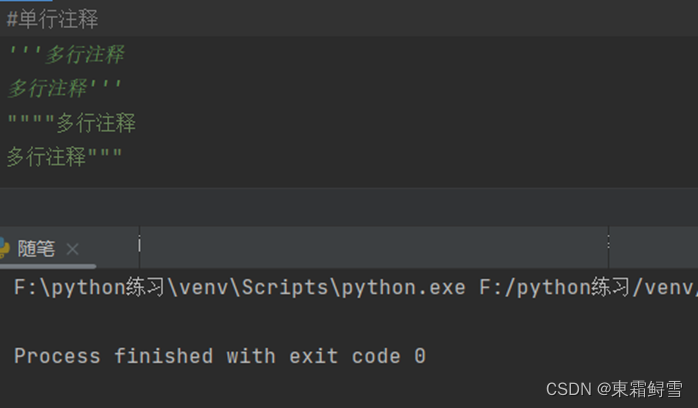
可以看到注释后不会运行注释的内容,对代码无影响。
2.3数字类型
Python数字类型包括整型(int)、浮点型(float)、复数型(complex)、布尔型(bool)四种。
2.3.1整型
整型取值为普通整常数例如1,2,3之类的
常见整型都是十进制,有时为计算需要可能要使用其他进制
例如:

其他进制转换为十进制则是int(n)
2.3.2浮点型
浮点型数(简称浮点数)为带小数点的实数,1.21、0.113、-1.2等
在python中整型数没有上下限,而浮点数有上下限,超出则报错,例如:
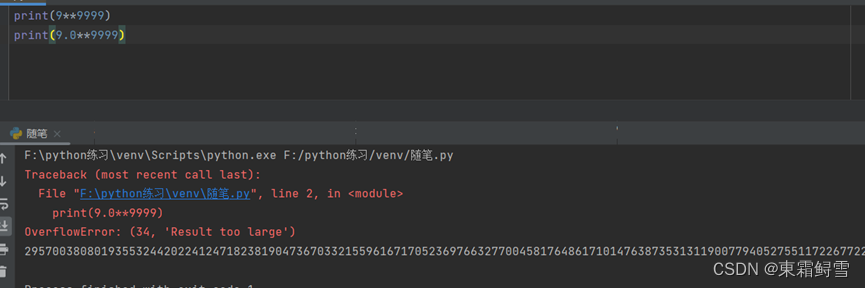
报了一个超出范围的错误。
注意的是python中浮点数的精度不是完全准确的,例如0.1+0.2不是0.3

这种情况是因为浮点数在计算机中使用二进制存储不可避免会带来一些精度丢失的问题。为解决这种问题有一个较好的办法就是使用decimal模块来处理浮点数,如下所示:

引入模块后续会进行说明与示例。
注意的是传入Decimal()函数的参数不能是浮点数,否则误差依然在,因为python中的浮点数本身就不精确。
2.3.3复数型
Python提供了对复数的支持,运算方法跟数学中的复数运算方法基本一样。数学中复数的表示形式是z=a+bi,i为虚数单位,且i2=-1,a,b为任意实数,a为复数的实部,b为复数的虚部,复数的实部a与虚部b都是浮点数。
Python中规定1j来表述-1的平方根,例如:

如果需要获取该复数的实数部分,则使用.real,获取该复数虚数部分则使用.imag,获取该复数共轭复数则使用.conjugate()。
例如:

如果想将一个数转换为复数,可以使用complex()函数。例如:

2.3.4布尔型
布尔型是一个重要的数据类型,其主要运用在分支、循环结构中,其只有1和0,1为True,0为False。可以像整数一样相加。例如:

2.4字符串
2.4.1标识字符串
字符串(String)是python中常见的一种数据类型,由单引号或双引号引起来的文本内容,包括字母、数字、标点符号以及特殊符号等字符。例如’hello world’、”hello world”。用三引号(单引或双引)可以像多行注释一样写多行。
以下是两个错误例子:

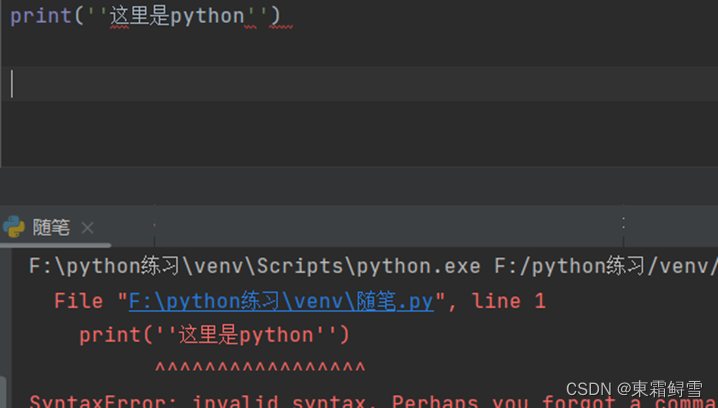
需要注意的是引号的作用范围。
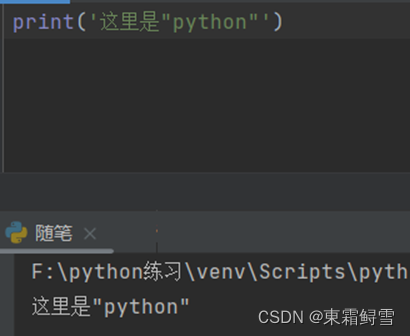
使用转义符“\”也能解决字符串中含有的引号问题,其可以将挨着的后面那个引号的作用消除。例如:
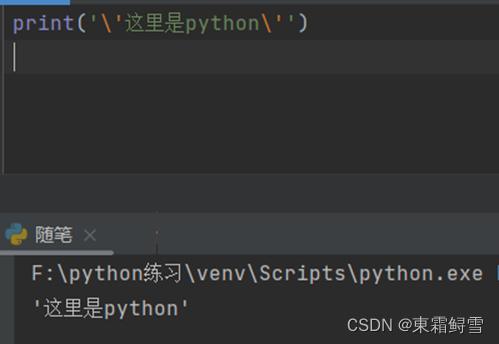
如果不想让里面的转义字符有效果,可以在前面加上r使转义字符失效,使其成为普通的字符。例如:

Python中除“\”之外还有其他的转义字符。
以下表格为python转义符及说明
| 转义符 | \\ | \’ | \” | \b | \n | \000 | \t | \v | \r |
| 说明 | 反斜杠 | 单引号 | 双引号 | 退格符 | 换行符 | 空格符 | 横向制表符 | 纵向制表符 | 回车符 |
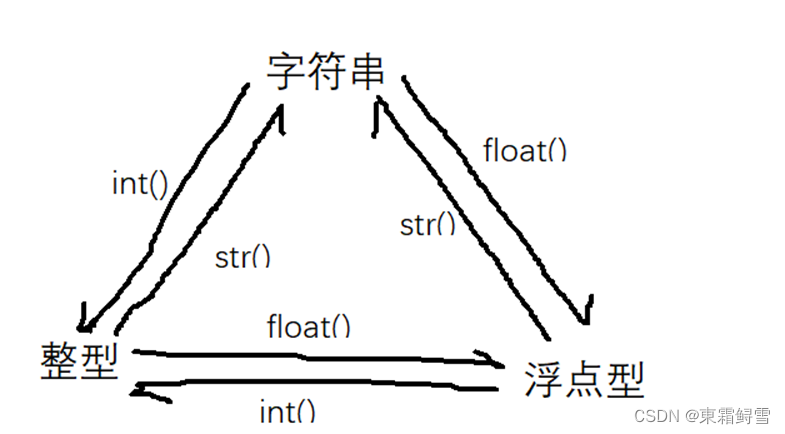
2.5类型转换
Python中常用的三种类型转换函数有三个:int()、float()和str()。整型、字符串、浮点数之间的转换如下图所示:
例如:

浮点数转换为整型除了int()还可以使用round()函数进行四舍五入将浮点数转换为整数。其中的print(round(5.534,2))5后面的2是保留指定的后两位小数。
2.6变量
2.6.1定义变量
变量则是需要赋予值的变量名,其变量名要求能储存值并能运用计算之类的。格式就如同数学中赋予外来变量x=1之类的,变量名=变量值。
在python中赋予变量名值可以一个一个的给也可以一起给相同的值。例如:
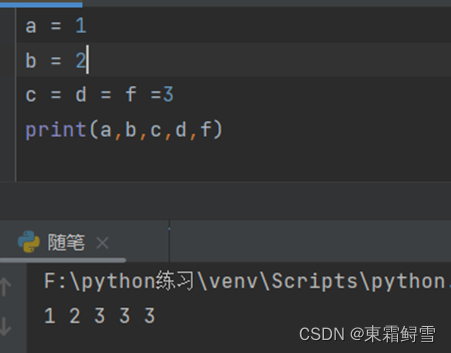
其给的值可以用这些变量名来进行运用,例如
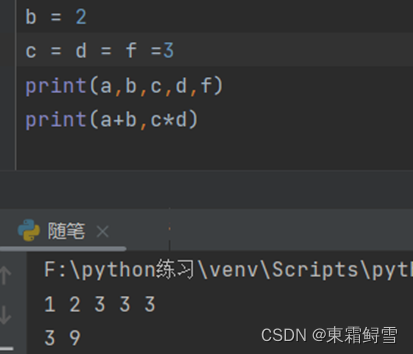
也可以一次给多个变量不同的值,例如:
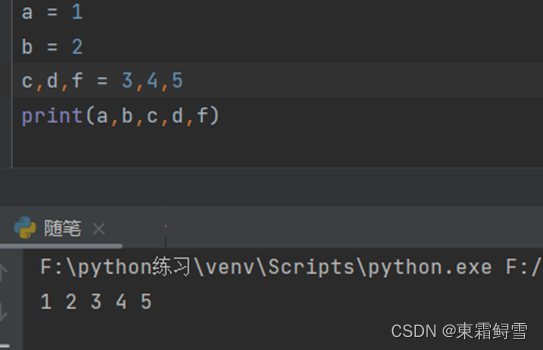
2.6.2类型判断
在python中变量在定义值的时候会自动判断该变量类型,当我们无法判断变量类型时候可以通过type()函数来判断变量类型。(而Java在定义时就需要预先声明变量的类型)。例如:

除了使用type()函数,还可以使用isinstance()函数来判断变量类型是否是自己认为的变量类型,其返回结果为True或False,例如:

变量的类型会跟随着其值的类型而变化,例如:
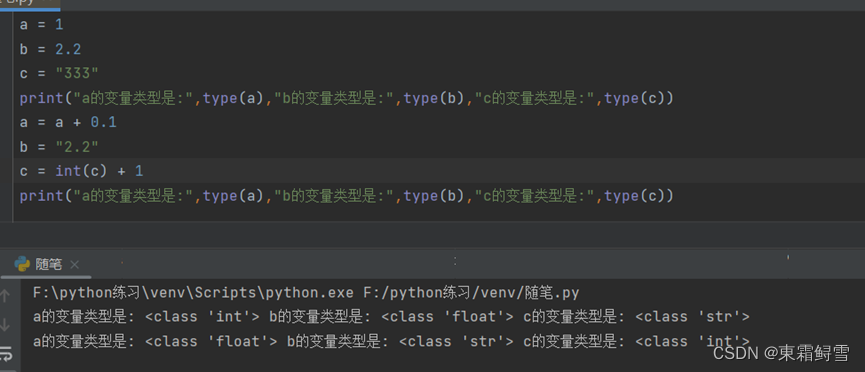
其中c原本就是str类型需要先转换int类型再与新的数字进行加减之类的处理,所以int(c)就是一个类型转换,否则str类型与int类型或float类型一起计算会报错。
2.6.3变量的存储方式
为了更好的使用python变量,我们就需要了解python变量在内存中的存储方式。我们可以通过id()函数来查看变量在内存中的存储地址。例如:

我们就知道了a、b、c这三个变量在内存中的存储地址。
2.7常量
Python中没有专门定义常量的方法,通常使用大写英文字母表示常量,例如:APPLE_MONEY = 5.5
实际上这种常量并不是真正的常量,python中的常量也是一种变量,只不过用大写英文字母提示程序员不要更改它。
2.8 变量的命名规则
任何编程语言为了方便维护和更改都有一定的编码规则,python也不例外,其规则如下:
- 变量名应该尽量通俗易懂,方便后续维护时快速理解其代码含义。
- 变量名只能包含字母、数字和下划线,并且第一个字符不能是数字,必须是字母或下划线,否则会报错,例如:
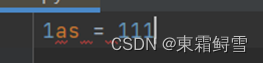 就会提示错误。通常是一个单词,若是混合的例如学生名字就用STUDENT_NAME = 张三,如此之类的。
就会提示错误。通常是一个单词,若是混合的例如学生名字就用STUDENT_NAME = 张三,如此之类的。 - 变量名不能包含空格,如果变量中有多个单词,可以使用下划线分隔,如同上述的学生名字一样。
- 变量名区分大小写,所以写STUDENT_NAME与student_name是两个不一样的变量,即使中文含义一样,这是因为python对字母的大小写非常敏感。
- 变量名不能使用代码中的函数名或python内置的函数名,比如print就不能用来命名变量名,但是Print可以,因为一个开头小写,一个大写。
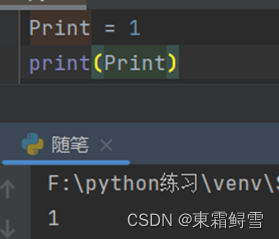
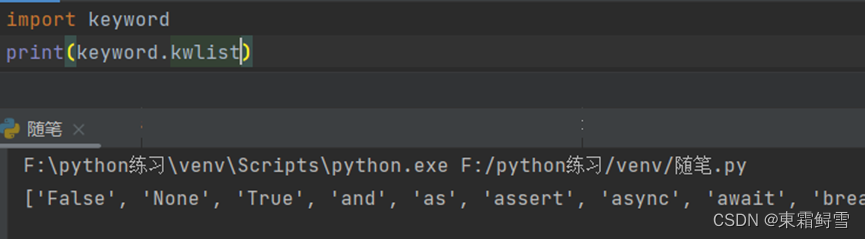
- 变量名不能使用python中的关键字来命名,关键字早已被python编辑工具本身使用,不能用于其他用途的单词,如if来命名变量。
可以通过以下来方法查看python的关键字:
2.9运算符
2.9.1算术运算符
Python中的算术运算符一共有7个:加(+)、减(-)、乘(*)、除(/)、幂次方(**)、取余(%)、取整数(//)、其中除(/)运算返回的结果都是浮点数,即使是两个能整除的数结果也是浮点数。例如:
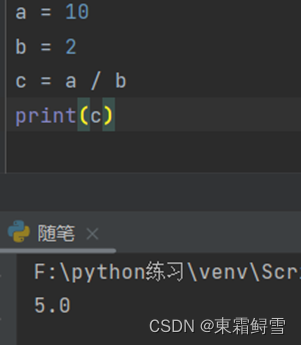
例子上述2.1输出时已讲述故不再继续举例子。其中%可以用在格式化输出字符串中,将在后续讲解。
2.9.2关系运算符
关系运算符运用于分支和循环结构中,结果返回布尔型数据True或False。关系运算符如下表所示:
| 运算符 | == | != | > | < | >= | <= |
| 描述 | 等于 | 不等于 | 大于 | 小于 | 大于等于 | 小于等于 |
例如:
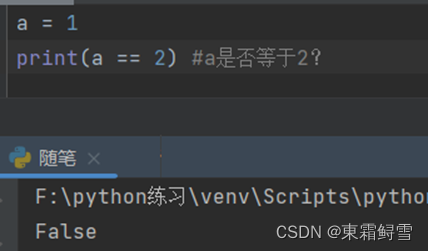
因为a被赋值1在判断a是否等于2之前也没有进行变化使之等于2,所以返回一个False。
2.9.3赋值运算符
赋值运算符就是用来为变量赋值的符号,前面为变量赋值的=就是一个赋值运算符,而赋值运算符不止有=这一种,其他赋值运算符下:
| 运算符 | 描述 | 示例 |
| = | 常用的赋值运算符 | a=1,将1赋值给a |
| += | 加法赋值运算符 | a+=b,等于a=a+b |
| -= | 减法赋值运算符 | a-=b,等于a=a-b |
| *= | 乘法赋值运算符 | a*=b,等于a=a*b |
| /= | 除法赋值运算符 | a/=b,等于a=a/b |
| **= | 幂赋值运算符 | a**=b,等于a=a**b |
| %= | 取余赋值运算符 | a%=b,等于a=a%b |
| //= | 取整赋值运算符 | a//=b,等于a=a//b |

上述例子中的a的值都是从第一个a=1依次得下来的。Python中并没有C语言中的—(自减)和++(自增),但可以用-=和+=来替代自增自减得作用。
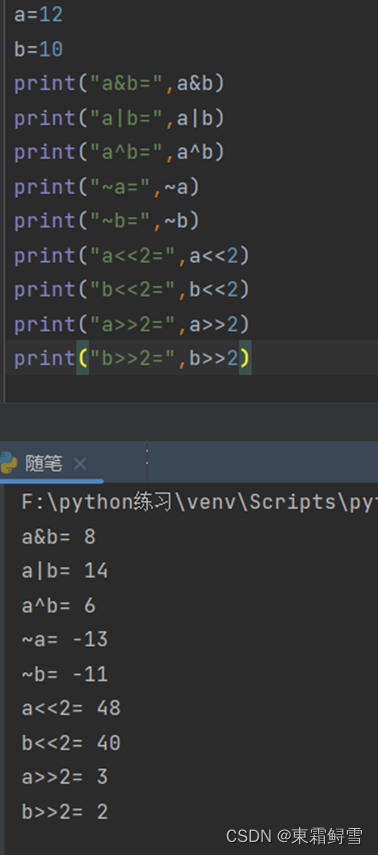
2.9.4位运算符
Python中的位运算符将数字当作二进制来进行运算。下列例子中a=12,b=10,那么它们的二进制表示为a=1100,b=1010。Python的位运算符如下所示:
| 运算符 | 说明 | 示例 |
| & | 按位与运算符:相应的位都为1则为1,否则为0 | a&b=1100&1010=1000=8 |
| | | 按位或运算符:对应的二进制全0为0,否则为1 | a|b=1100|1010=1110=14 |
| ^ | 按位异或运算符:对应的二进制不同为1,相同为0 | a^b=1100^1010=0110=6 |
| ~ | 按位取反运算符:先将每个二进制取反(0与1互换),结果类似于原数取负再减1 | ~a=0011=-13,~b=0101=-11 |
| << | 左移运算符:将二进制全部左移n位 | a<<2=00110000=48,b<<2=00101000=40 |
| >> | 右移运算符:将二进制全部右移n位 | a>>2=0011=3,b>>2=0010=2 |
例子:
2.9.5逻辑运算符
在python中的逻辑运算符有三个:“and(与)”、“or(或)”和“not(非)”。其主要用于布尔型数据的运算。and(与)都为1即真就为1返回True,否则返回False。
or(或)有一个为1即一个真则返回True,否则返回False。
not(非)将真的变为假的,假的变为真的,即结果为True返回False,结果False返回True。
例子:

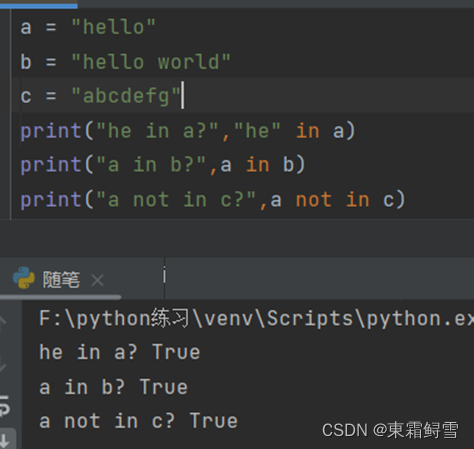
2.9.6成员运算符
成员运算符有两个“in (在)”和“not in(不在)”,主要用于判断一个值是否包含在某个字符串、列表或元组中,包含返回True,不包含返回False。例子如下:
2.9.7身份运算符
身份运算符有两个“is(是)”和“is not(不是)”。主要用于判断两个标识符是否引用同一个对象,例子如下:

可以从例子中看出a与c返回的是true但是并不是他们的值相等而返回的true,而是因为是它们所引用的值是同一个值(在同一个存储地址上),等于号“=”才是比较两个值是否相等。
2.9.8运算符优先级
运算符的优先级决定了运算的顺序先后就跟数学中的先乘除再加减是相似的,乘除的优先级比加减高。想要先运算优先级低的可以用括号()括起来进行运算,python中的各运算符优先级如下:
以下表中运算符优先级从高到低排序。
| 运算符 | 说明 |
| ** | 幂(乘方) |
| ~、+x、-x | 补码、一元加/减 |
| *、/、%、// | 乘、除、取余、取整数 |
| +、- | 加、减 |
| <<、>> | 左移、右移 |
| & | 按位与 |
| ^、| | 按位异或、按位或 |
| <=、<、>、>= | 比较运算符 |
| ==、!= | 等于运算符 |
| =、+=、-=、*=、 /=、//*、%= | 赋值运算符 |
| is、is not | 身份运算符 |
| in、not in | 成员运算符 |
| not、or、and | 逻辑运算符 |
| lambda | lambda表达式 |
2.10字符串的定义和使用
2.10.1定义字符串变量
Python定义字符串变量在上面已经提及,跟定义整型和浮点型变量的方法是一样的,“变量名=字符串内容”例子:
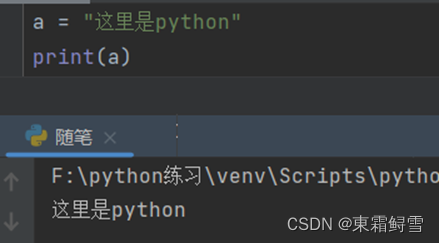
2.10.1获取字符串长度
要获取字符串长度,可以用python内置函数len()函数来进行获取。例子:
2.10.3索引字符串
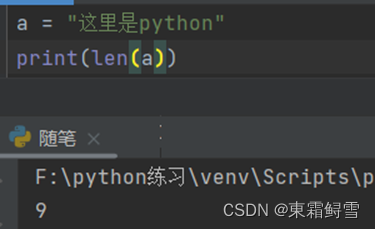
Python的索引字符串跟C语言中的字符数组一样,通过下标索引的方法索引字符串,下标索引顺序为从左到右为0.1.2.3.……,从右到左为-1.-2.-3……。例子:
2.10.4拼接字符串
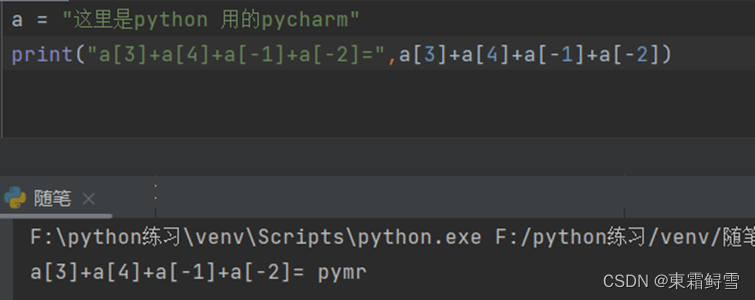
拼接字符串顾名思义将多个字符串拼接在一起,我们可以使用“+”或“*”运算符来进行拼接。例子:

2.10.5字符串切片
当我们只需要获取字符串中一部分的内容时,就需要对该字符串进行切片处理。变量[包含位置:不包含位置:间隔],间隔默认为1
例子

上例中最后的b,split(“:”)[0]就是将b=“这里是:“python””这个字符串以冒号为间隔符将之分离后变为了索引值为0的“这里是”和索引值为1的““python””,后面的数字则是索引值。
2.10.6查找字符串内容
在Python中想要查找字符串的内容可以使用内置的find()函数、rfind()函数、index()函数、rindex()函数。例子:
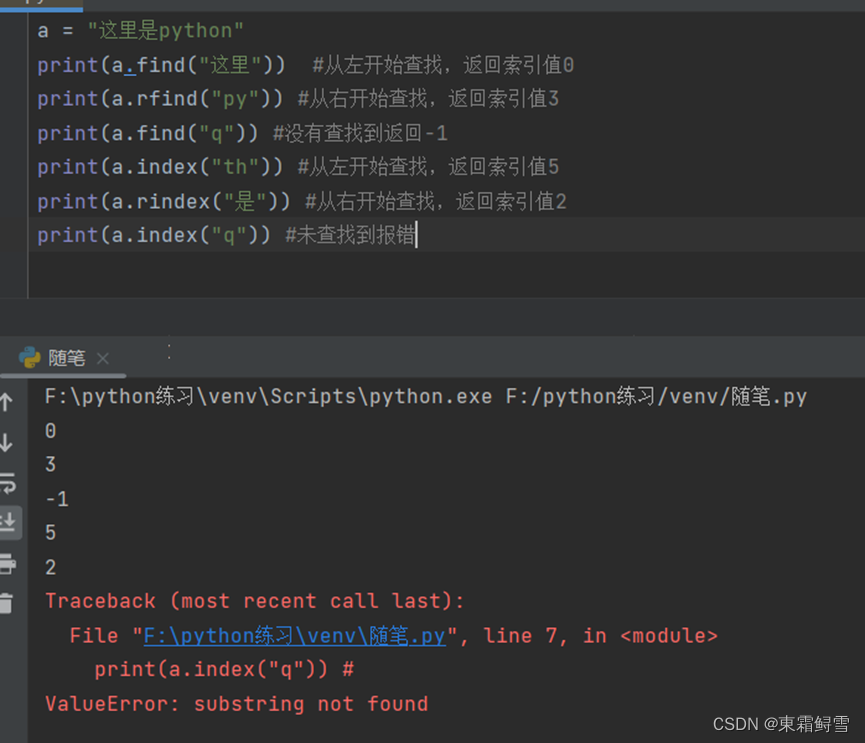
返回的索引值都是从那个位置开始查找到,并不是在那个位置结束。find()函数和index()函数都能用来查找字符串中的内容,且返回其内容索引值,但当内容不存在时,find()函数返回-1而index()函数会报错,因此在需要查找内容时使用find()函数更好点。以上为查找简单内容,在需要查找更复杂的内容时,就需要使用正则表达式了,这个后续会进行讲解。
2.10.7替换字符串
替换字符串可以使用replace()函数,该函数返回一个替换后的新的字符串。例子:

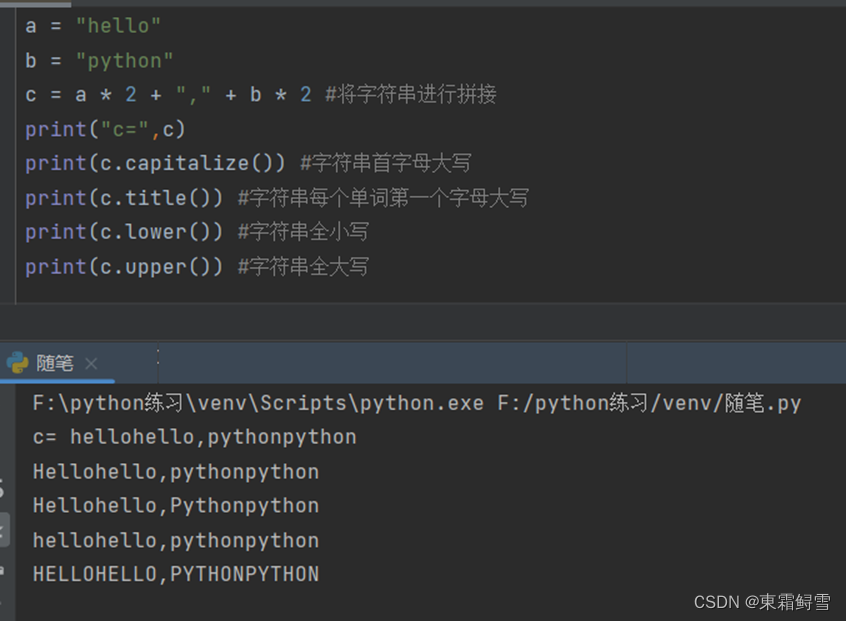
2.10.8转换大小写
Python中转换字符串大小写的函数有:capitalize()函数、title()函数、lower()函数、upper()函数。例子:
2.10.9删除字符串中的空格
Python中删除字符串的空格可以使用lstrip()函数、rstrip()函数、strip()函数。例子:

2.10.10判断字符串是否以某个字符开始或结束
判断字符串是否以某个字符开始可以用startswith()函数,判断其是否以某个字符结束可以用endswith()函数。例子:

下表为python中有关字符串的函数或操作:
| 函数或操作 | 说明 |
| len(string) | 返回字符串string的长度 |
| string[start_index(包含):end_index(不包含):step] | 截取字符串,区间为[start_index:end_index) |
| string[::-1] | 逆置字符串string |
| string.split(sep) | 用分隔符sep对字符串string切片 |
| string.find(str1)、string.index(str1) | 从左开始查找字符str1在字符串string中的索引位置 |
| string.rffind(str1)、string.rindex(str1) | 从右开始查找str1在字符串string中的索引位置 |
| string.replace(str1,str2,times) | 将字符串string中的str1替换为str2,替换次数为times |
| string.capitalize() | 字符串string首字母大写 |
| string.title() | 字符串string中每个单词的第一个字母大写 |
| string.lower() | 字符串string中的字母全小写 |
| string.upper() | 字符串string中的字母全大写 |
| string.lstrip() | 删除字符串string左边的空格 |
| string.rstrip() | 删除字符串string右边的空格 |
| string.strip() | 删除字符串string首位的空格 |
| string.startswith(str1) | 判断字符串string是否以字符str1开始 |
| string.endswith(str1) | 判断字符串string是否以字符串str1结尾 |
2.11字符串编码
字符串编码主要对含有中文字符的字符串进行编码,如果不对字符串中的中文字符进行统一编码,可能会出现各种问题。
在python历代版本中,python2使用ASCII编码,如果要输出中文就必须在代码顶部加一句“#_*_coding:UTF-8_*_”或“#coding=utf-8”。例子:

Python3使用的是Unicode编码,能很好支持中文,因此不用再指定编码方式,可以直接输出中文。
如果需要对字符串编码,可以使用encode()函数。例子:

使用python3内置的bytes()函数也能对字符串编码。例子:

字符串可以被编码就可以被解码,python3中解码字符串的函数就是decode()函数。例子:
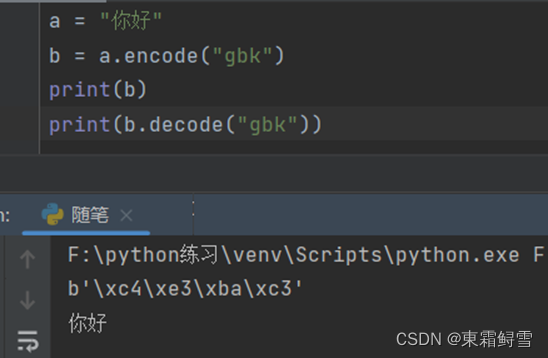
注意的是,字符串编码时使用的什么方式,解码必须得用同样的方式,否则会报错,比如上述例子中,解码方式改为utf-8:

2.12格式化字符串
格式化字符串就是按照一定的格式来输出字符串,好比银行消费短信,在xx时间消费xx元,余额xx元。这里的字符串就是格式化的字符串,字符串中的xx会根据变量改变而改变,其他内容不变,有一个模板只有其中几个变量需要该百年。
在C语言中字符串格式化输出要使用符号“%”。而python中也能使用“%”。例子:
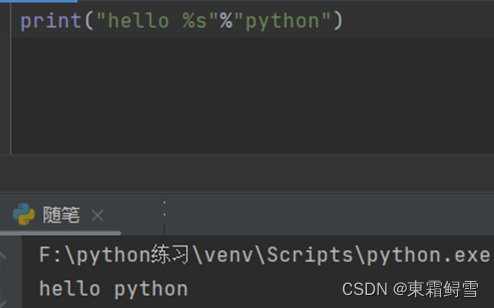
Python也跟C语言一样可以使用“%d”替换整型、“%f”替换浮点数、“%s”替换字符串,还可以使用“%xf”指定保留的小数位数(这里的x是保留的小数位数)。例子:

Python中还可以使用内置函数format()来格式化字符串,其使用方法类似于“%”,不同之处是format()函数使用“{}”和“:”来替代“%”。例子:

format()函数还可以不按初始顺序格式化字符串。例子:

format()函数中的每一个字符串都有一个索引值,上面的第一个{}中的数字是1,代表的是索引值为1的字符串“python”;第二个{}中的数字0代表索引值为0的字符串“hello”。所以输出的是pythonhello。
format()函数还可以通过设置参数来格式化字符串。例子:

- python流程控制
3.1缩进的使用
在python中缩进的空格长度是可变的,一般采用单个制表符(Tab键)或2个空格符或4个空格符作为缩进,但是在python中不同的缩进方式不能混用,一份代码文件只能使用一种缩进方式。例子:

因为前面多了个空格而导致报错。

为什么会是输出a大于b是因为print(“a大于b”)和print(“a小于b”)前面空格符使之受if语句控制(if语句等后续会讲解)。而最后的print(“结束比较”)前面没有空格符定格,不受if语句控制,所以能直接输出出来,不管if语句发什么什么。
pass语句表示程序不执行任何代码,一般用作占位语句。例子:
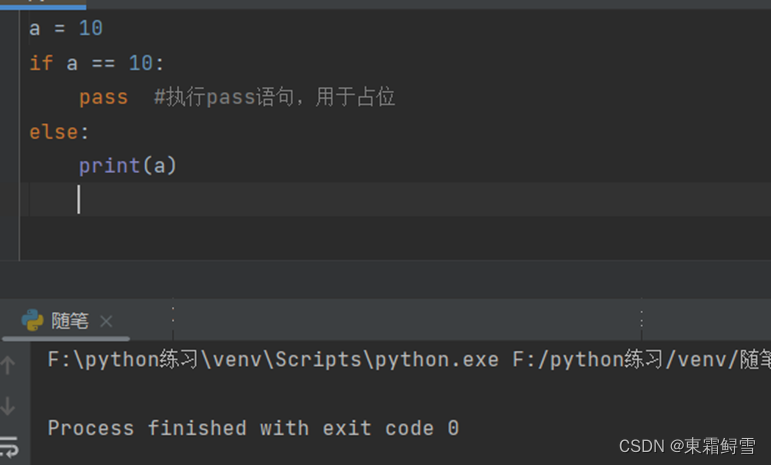
可以看到并没有输出任何东西。是因为if判断出是执行pass而不是下面的print(a),pass不执行任何代码,用作占位,所以不输出任何东西。而pass语句还可以在循环、函数、类中使用,用于保持程序结构的完整性。
3.2标准输出/输出
前面之讲解了输出,都是代码内自动固定好了的而不是我们执行代码后通过外接设备(如键盘鼠标等)输入数据再输出的,现在就讲解怎么通过外接设备进行输入输出。
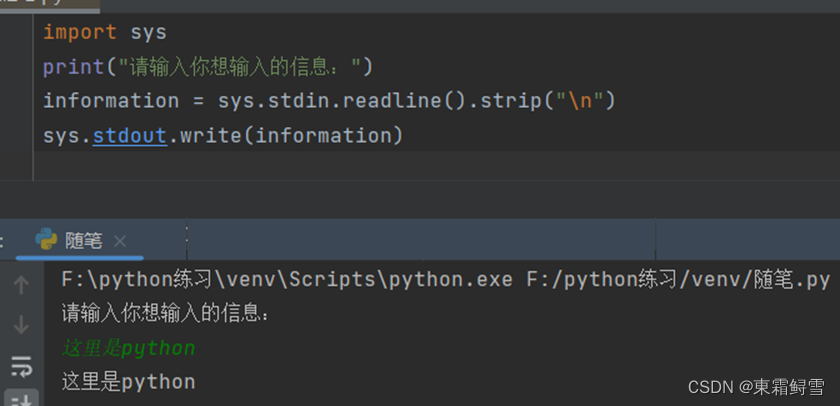
Python提供了内置函数input(str)来接收外接键盘输入的信息(不包括结尾的换行符),并以字符串的形式返回。例子:
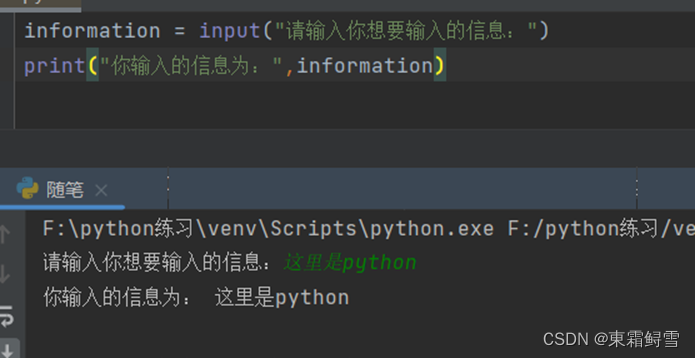
上述例子中首先输出的是input()函数内的提示信息“请输入你想要输入的信息”,然后再接收外接键盘输入的信息,并将其以字符串的形式赋给变量information,这样获取的字符串没有结尾的换行符“\n”(输入完信息后按回车)。实际上python再读取输入信息的时候首先调用print语句中的提示信息,然后调用标准输入(stdin)来获取输入信息,最后删除获取的信息结尾的换行符“\n”并赋值给变量information。
3.2.1标准输入
标准输入(stdin)可以获取从键盘输入的全部信息,包括结尾的换行符“\n”。例子:

执行完后,我们在界面输入我们需要输入的字符串(例子中绿色部分就是),输入完后回车就会在下面输出我们刚输入的字符串,因为包含换行符所以会和最后执行的print(“这里是python”)隔一行输出。
想要删除结尾的换行符可以通过前面讲述的strip()函数或者使用索引。例子:
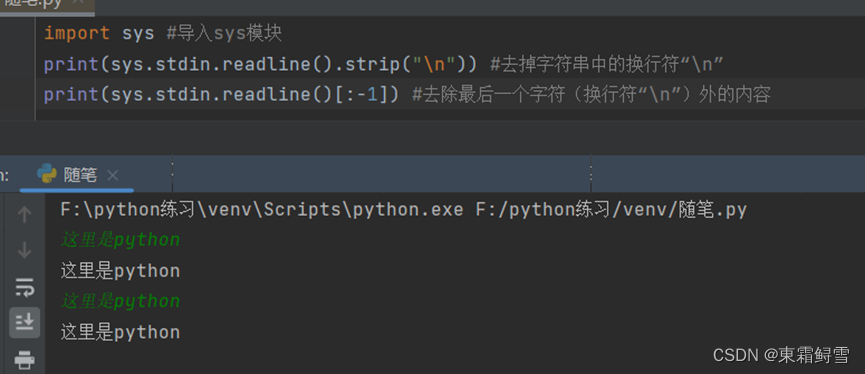
从上面例子中可以看出sys.stdin.readline()函数可以完成和input()函数一样的功能,唯一差别就在于sys.stdin.readline()函数更加灵活,它可以获取输入信息结尾的换行符,另外,想要去除结尾的换行符“\n”可以使用strip()函数。
但也有一个问题,上面例子中sys.stdin.readline()函数一次只能读取一行输入内容,如果我们需要一次读取多行输入内容,就可以使用sys.stdin.readlines()函数。例子:
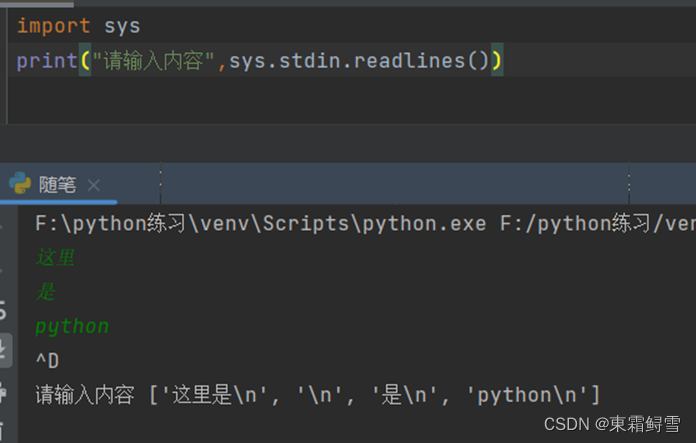
当使用sys.stdin.readlines()函数读取输入内容时,按回车键不会[yy1] [yy2] 结束输入,只是把回车键当作换行符处理。我使用的是pycharm,所以需要按ctrl+d来退出停止输入。(注意:我们需要在一个空行部分来退出,否则退出那行的内容不会输出)。
3.2.2标准输出
标准输入(stduot)是类似于python中的print语句。print语句在执行后会自动换行,而标准输出是先将文本内容输出到控制台后再换行,并输出文本内容的长度。实际上 print就是通过标准输出实现。例子如下:

上面最开始的information输入信息例子中就等效于:
在真实的代码项目中,程序代码是会很多,而且伴随着编写,代码越来越多越来越复杂,维护会更加不容易,为了编写易于维护的程序,我们可以把函数分组,将它们分别放在不同的文件里。这样,每个文件包含的代码就相对较少,很多编程语言都采用这种方式来组织代码。在python里通常把.py后缀的文件成为一个模块(Module)。Python的标准输入/输出都基于sys模块。sys模块是python自带的模块可以直接使用import语句引用。
3.3输出字符串
在python中输出有print语句和sys.stdout.write()函数两种方式,标准输出sys.stdout.write()函数更加灵活,但print语句使用起来更加简单,因为他输出的内容已经包含了一个换行符。
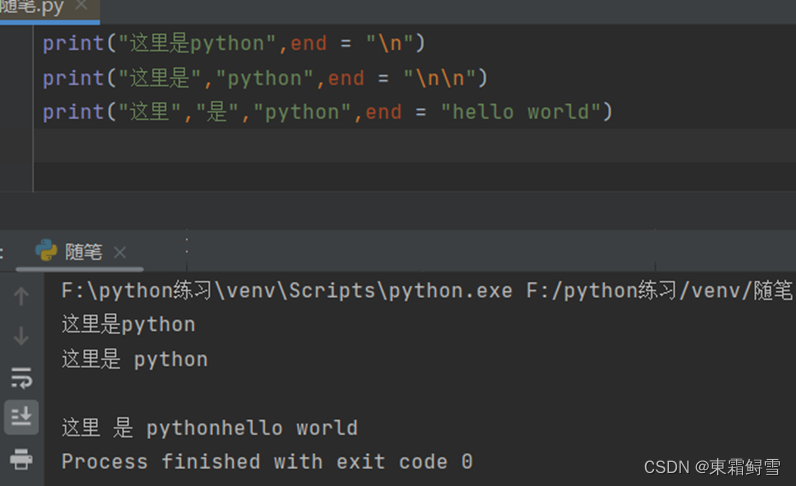
print()的基本语法为:print(*objects,sep=””,end=’\n’,file=sys.stdout)
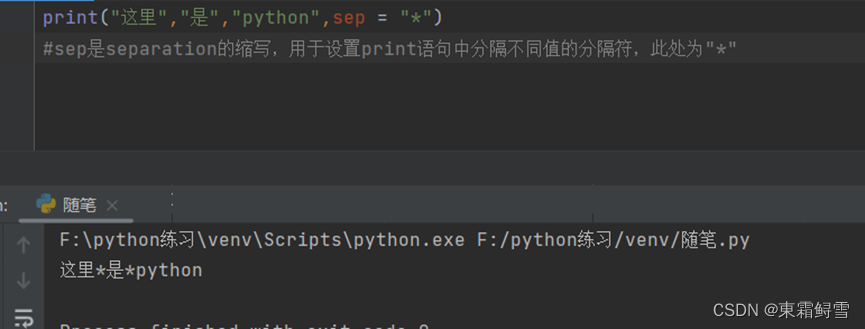
其中参数的含义:objects表示可以一次输出多个对象,输出多个对象时,需要用逗号分隔;sep用来分隔多个对象,默认值是一个空格符;end用来设定以什么结尾,默认值是换行符“\n“,也可以换成其他字符串;file表示要写入的文件对象。(注意:print()语句无返回值)。
使用print语句输出多个字符时,默认用一个空格符作为字符串的分隔符。如果要改变分隔符可以使用以下方法:
前面有提print语句输出字符串时,默认字符串结尾接入一个换行符,所以print语句在默认情况下不能在同一行输出字符串。要想输出的字符串不换行可以使用以下方法:

end可以设置print语句输出结束时最后的字符形式。如设置“”end=””即可达到删除输出字符串结尾的换行符的效果。同理,想要多次换行,可以使用“end=”\n\n””。注意的是,这里如果只用一个换行符其输出结果与不用end是一样的,所以想在字符串结尾加其他内容也可以使用end。例子:
3.4 if判断语句
3.4.1 if语句
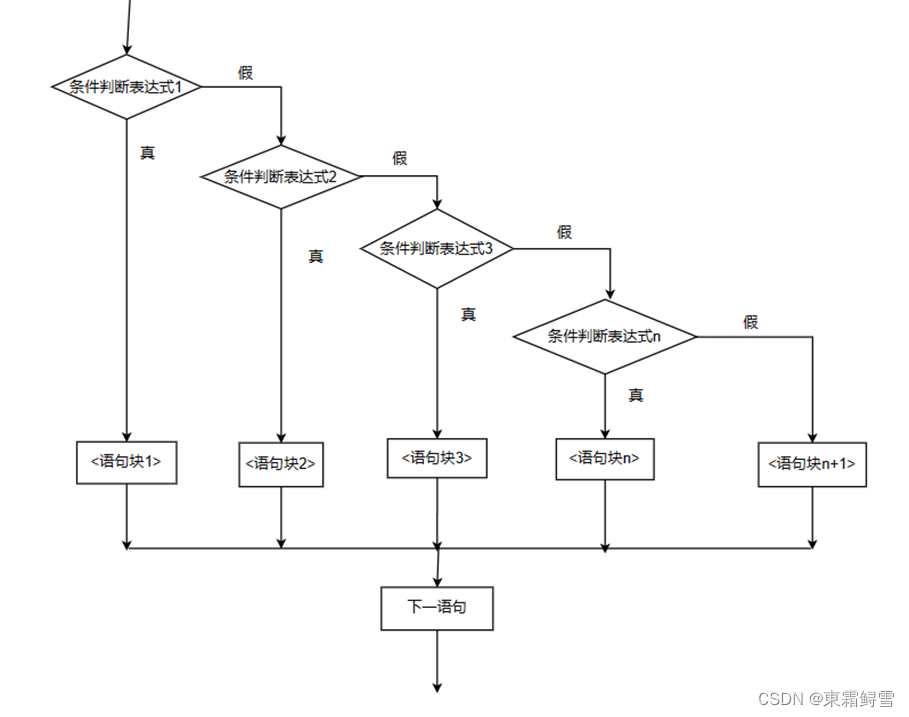
If语句在上面已经小小的提到过。使用if语句能够改变程序的执行流程,使程序在运行时根据不同的条件执行不同的语句块。下图为if语句的执行流程:

如果条件判断表达式的值为真,则执行语句块,否则什么也不执行,直接退出。使用if语句可以根据不同的条件输出不同的内容。登录程序例子:

注意的是if语句后的“:”不能省略,它被用于if语句、while语句、for语句之后,作为语句头的结束标识。另外python中的if条件判断是可以不用括号括起来,括起来也可以,所以上面的if语句等价于下述语句:if (usr_name == “admin”):
3.4.2 if-else语句
上面的if语句不能判断用户不存在的情况。若是要判断用户不存在的情况,就需要使用if-else语句。If-else语句的执行流程如图3-2所示,如果条件判断表达式的值为真,则执行语句块1,否则执行语句块2.下表为if-else语句流程图:

有了if-else语句,就可以正常地判断用户是否存在。例子:

3.4.3 if-elif-if语句
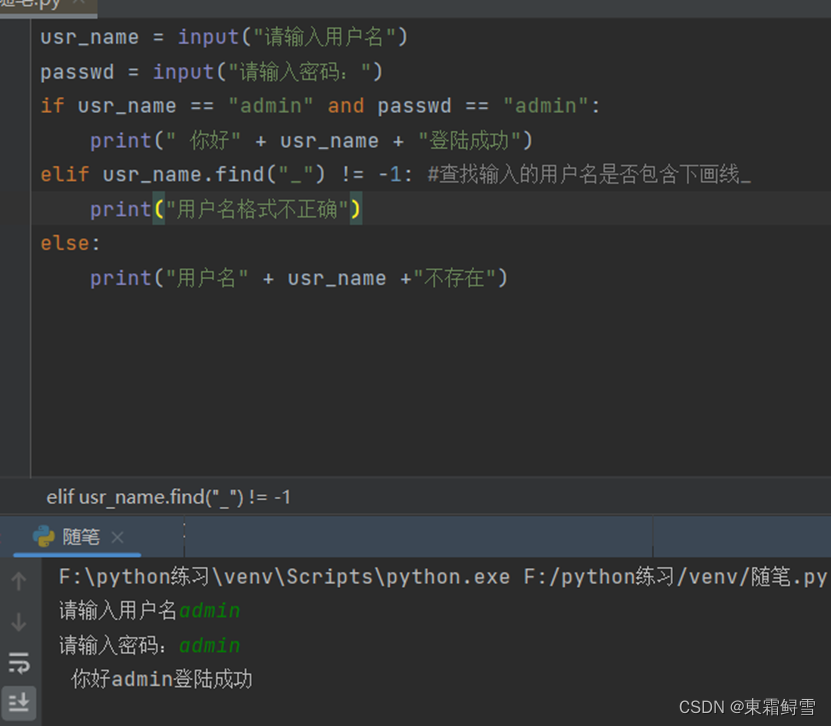
通过上述地if-else语句,我们已经可以判断登录用户是否存在,但有时候用户名不能包含特殊字符,如不能包含下画线,这时就可以使用if-elif-else语句来检查用户名。
If-else-if语句相比于if-else语句,其功能更加细微,使用if-elif-else语句能够根据多个不同的条件执行不同地语句块,语法规则如下:
if 条件判断表达式1:
<语句块1>
elif 条件判断表达式2:
<语句块2>
else:
<语句块3>
If-elif-else语句地执行流程图如下图所示:
掌握if-elif-else语句的执行方法后,就可以开始完善检查用户名的程序:

登录程序的用户名检查完之后就可以开始检查密码。检查密码有两种方式:一种是使用嵌套if-else语句;另一种是使用and运算符同时判断用户名和密码是否正确。
If-else嵌套语句:

使用and运算符:
由于python不支持switch语句,所以用多个条件判断时只能用elif语句来实现。如果需要多个条件同时判断,可以使用or,表示两个条件有一个成立时,判断条件为真;使用and,表示只有两个条件都成立判断条件才为真。
3.4.4 if语句条件表达式
下面通过一个例子来讲述if语句的条件表达式

这就是一个数字比大小程序。第4行代码这样看不懂则转换为以下形式也是一样的:
if num_a > num_b:
max_num = num_a
else:
max_num = num_b

除了上面这种方式外,还有以下方式可以比较两个数的大小:
max_num = [num_b,num_a][num_a > num_b]
这一种方式实际时[num_b,num_a][Flase],因为在python中False的值为0,所以[num_b,num_a][False]可以表示为[3,4][0]

max_num = [num_a > num_b and [num_a] or [num_b]][0]
这种方式里,因为>的优先级高于and和or,因此python先运算num_a>num_b,即4>5,其值为False;之后运算False or [5],气质为[5],所以最终结果为5.0

3.5 while循环
if语句能改变程序的执行流程,使程序根据不同的条件执行不同的代码,但是它并不能让程序返回已执行过的语句。要让程序返回到已执行过的语句并再次执行,就必须使用循环来实现。在python中有两种循环:while循环和for循环。
while循环使用while作为关键字,语法规则如下:
while 条件判断表达式:
<语句块>
注意的是在while的条件判断表达式后必须加上一个英文冒号“:”。
while循环的执行流程图如下所示:
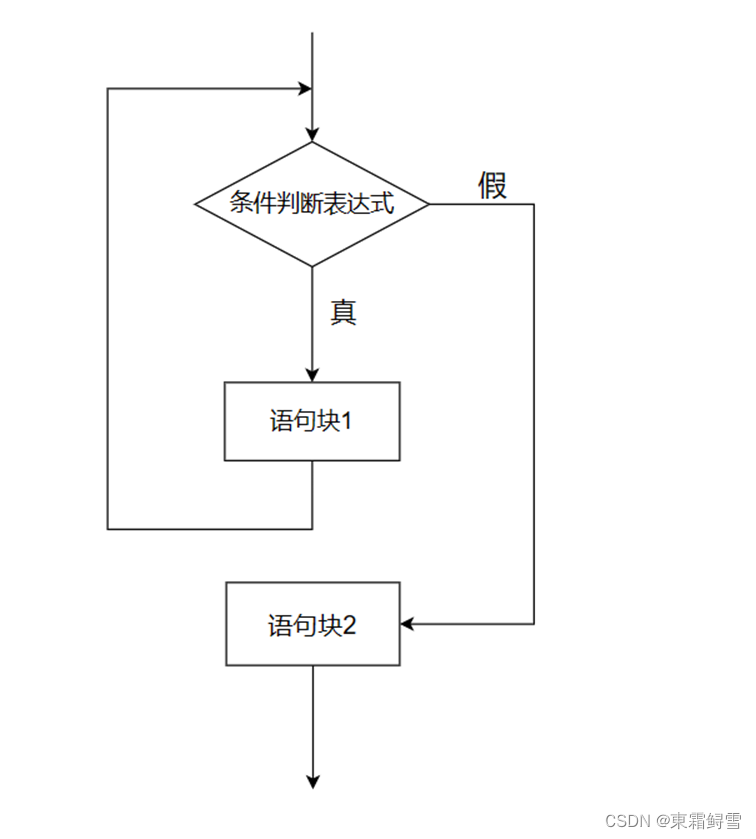
,当条件判断表达式返回的布尔值为True时,程序会一直重复执行while语句内的语句块1,直到该条件判断表达式的布尔值为False时,才跳出循环,执行语句块2。(注意:在python中没有do while循环,也没有C语言中的goto语句)。
下例为一个计算1+2+3+4+……+100的使用while循环的例子:
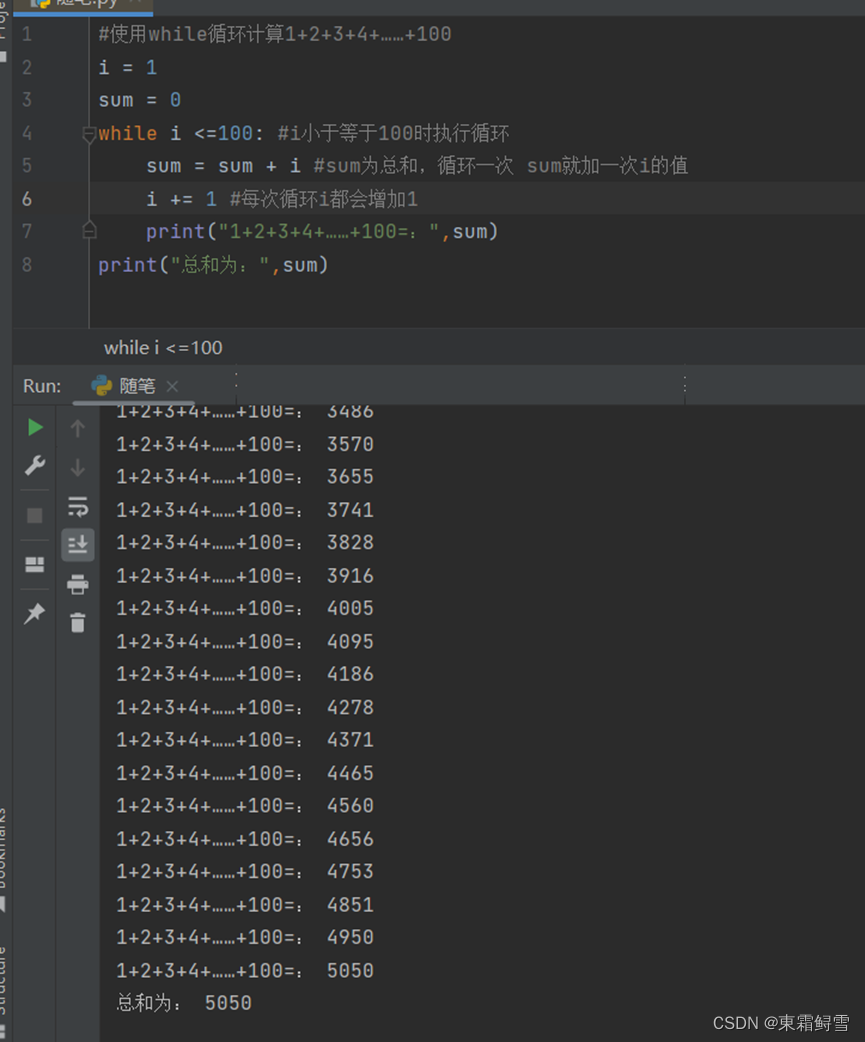
如上述例子,如果将print()语句写在while循环体内,那么循环一次就会执行一次,而写在whil循环体外则只执行while循环之后的最后一次的结果。这个例子的循环流程图如下所示:

上例可从中看出,一个while循环应包括3部分:初始化语句、循环条件和循环体。
其中初始化语句用来初始化循环需要用到的变量等信息,循环条件用于判断循环是否继续,循环体内包含了主体语句和递增语句。虽然几乎所有的while循环都需要以上3部分,但是在python中这并不是严格要求的,while循环也可以没有初始化语句和递增语句。例子:
while True:
printr(“a”)
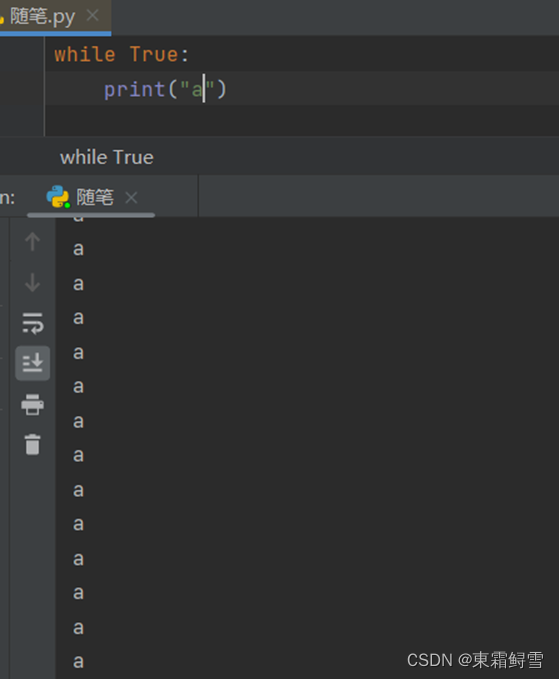
这个程序就没有初始化语句以及递增语句,结果则是一直输出字符串a下去,因此这样的循环也叫做无限循环。要退出这种无限循环可以使用ctrl+c。
有时候,无限循环可以用作一种快速编写循环的方式,但是初学者尽量不要使用无限循环,因为无限循环比有限循环更难理解,且程序在执行过程中也很难排查错误的位置。另外,使用无限循环如果不加跳出循环的条件,可能导致程序占用大量的内存甚至导致操作系统崩溃。
while循环还可以与else搭配。例子:

这种搭配在日常编程中并不常用,因为有的时候有没有else的执行结果都是一样的,实际上只有循环是否正常结束的时候才会用else。
While循环还可以像if语句那样简写,例如上面的无限循环a:
while True: print(“a”)
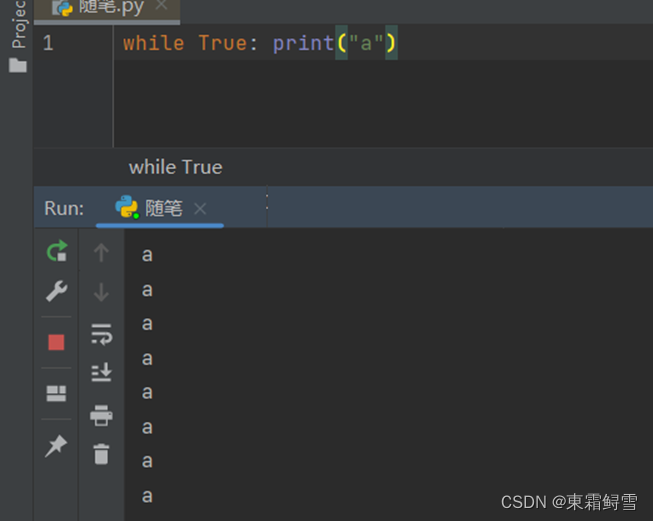
但是注意的是,只有当循环体内只有一条语句的时候才可以简写;当循环体内有多条语句的时候,就必须严格按照while循环的结构来写。
3.6 for循环
for循环相较于while循环更简单,更容易理解,唯一缺点就是没有while循环灵活。
for循环使用for作为关键字,其语法规则如下:
for 循环变量 in 集合:
<语句块>
其中的循环变量一般使用i或item作为变量名,但是当使用循环嵌套(即循环体内还有循环体)时,为了使内层循环的循环变量名不与外层循环的循环变量名相同,一般将j和k用作内层循环中的循环变量名。
for循环的执行流程图如下所示:

当没有遍历完所有元素时,程序会一直重复执行for语句内的语句块,直到遍历完所有元素,跳出循环。
使用for循环可以遍历完字符串里的所有字符,例子:

或是遍历整数序列:

这里的range ()函数代表着是它可以返回一个指定区域的左闭右开的整数序列,range(5)就相当于[0,5)所以是0,1,2,3,4这五个数。这个函数一般用在for循环中,其语法规则如下:
range(start,end,step)
这里的start表示序列从start值开始生成,不填默认为0,end为结束位置,但是不包括end本身这个数,range(1,3)用列表表示为[1,2]。Step为产生的序列的步长,默认为1,如range(0,5)等价于range(0,5,1),range(0,5,2)用列表表示则为[0,2,4]。想要产生倒序的整数序列,可以将补偿修改为-1,如range(5,0,-1)用列表表示为[5,4,3,2,1]。注意的是:range()函数里的参数必须是整数,且步长不能为0,否则就会报错。
range()函数虽然能用列表表示,但是返回的类型并不是列表。使用type查看其返回类型为range。
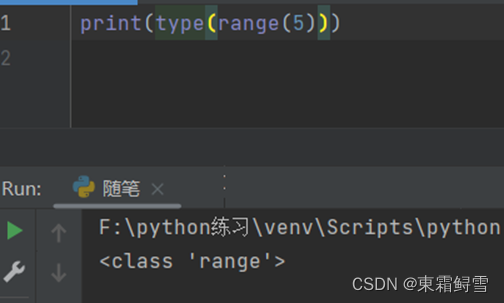
虽然它返回的是一个整数序列的对象,但是可以用list()函数将其转换为列表。
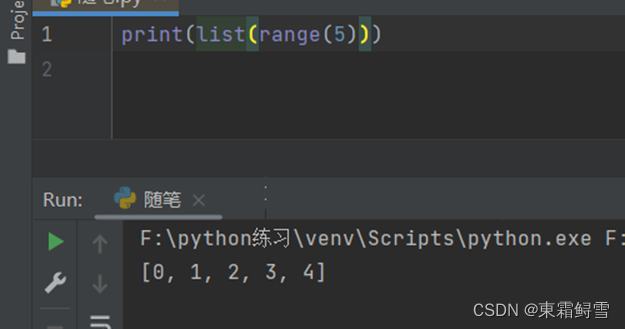
for循环不仅能遍历字符串和整数序列,它还可以遍历列表、集合、元组等。实际上它几乎可以遍历任何序列。
和while循环一样,for循环也可以和else搭配使用。
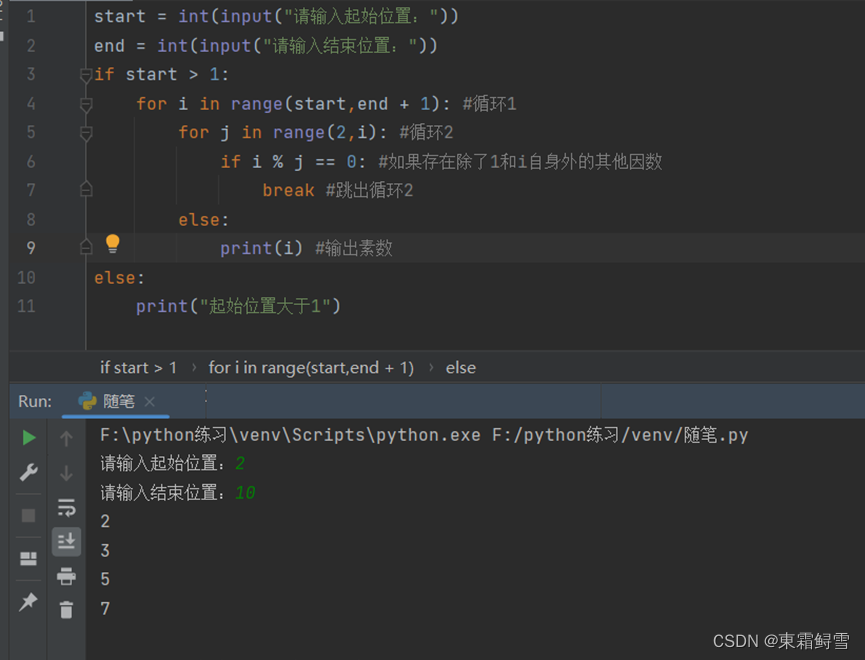
上例中,只有当循环2正常结束时,即没有执行if语句中的break语句时,程序才会执行else中的print语句,输出找到的素数。
for循环虽然比while循环更简单、代码量更少,但是它只适用于直到循环次数的情况。当不知道循环次数时,必须使用while循环。例如计算输入的数字总和:

这个程序的功能则是计算输入的整数总和,当输入-1时结束计算,而对于要输入的整数,并不知道需要输入多少次,所以使用for循环是无法实现的。
3.7break和continue语句
Python中的break语句和continue语句与C语言中的break语句和continue语句是一样的,都能用来跳出循环。break语句和continue语句的唯一区别是break语句跳出的是当前所在的循环,即break当前跳出所在的循环体。而continue语句跳出的是本次循环,即循环体内循环到continue时此次循环之后的语句不执行。
3.7.1 break语句
break语句可以用在for循环0和while循环中,用来终止循环。例子:
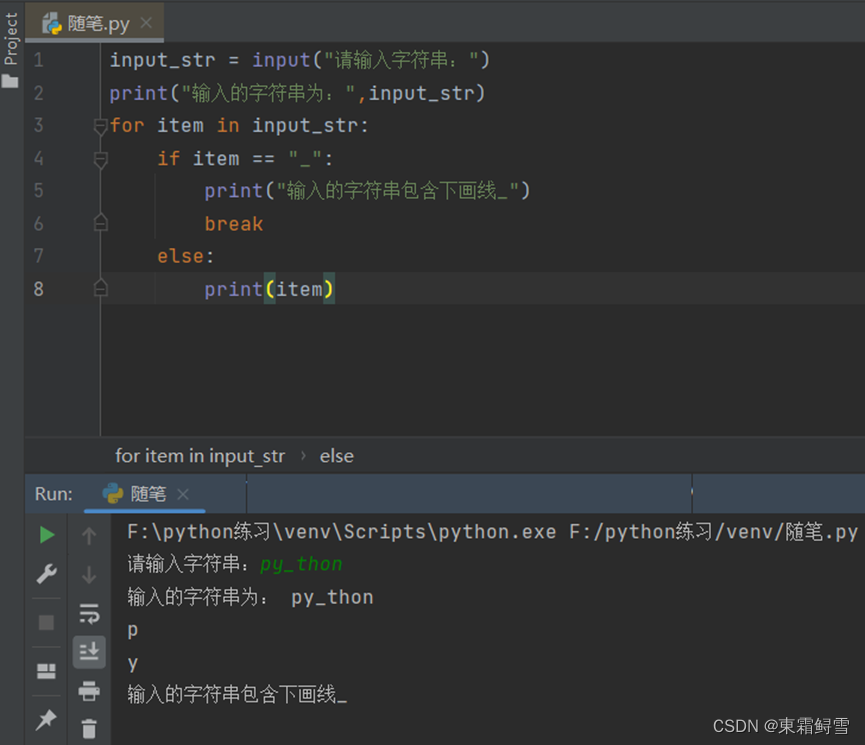
该程序的功能为判断输入的字符串中是否包含下画线_,而当第一次循环检查到包含下画线时,break则终止循环,并通过else输出含有下画线之前遍历到的元素。
当break语句在嵌套循环中使用时,终止的是break当前所在的循环体。例子:

这个程序就可以无限接收键盘输入的字符串,输入一个循环一次判断输入的字符串是否含有下画线,然后break跳出当前循环体,并输出下画线之前遍历到的元素,接着继续接收键盘输入的字符串。
3.7.2 continue语句
Continue语句不像break语句那样直接跳出当前循环体,而是直接跳过continue之后的语句,进入下一次循环,即相当于跳过本回合,但并不影响下一次循环,还在循环体之内。例子:

这个程序的功能为遍历[1,11)的数将奇数输出出来。遍历到偶数执行continue语句后就不用执行print语句将偶数不输出出来。
continue语句还可以起到一个删除的作用,它的存在是为了删除满足循环条件的某些不需要的成分。例子:
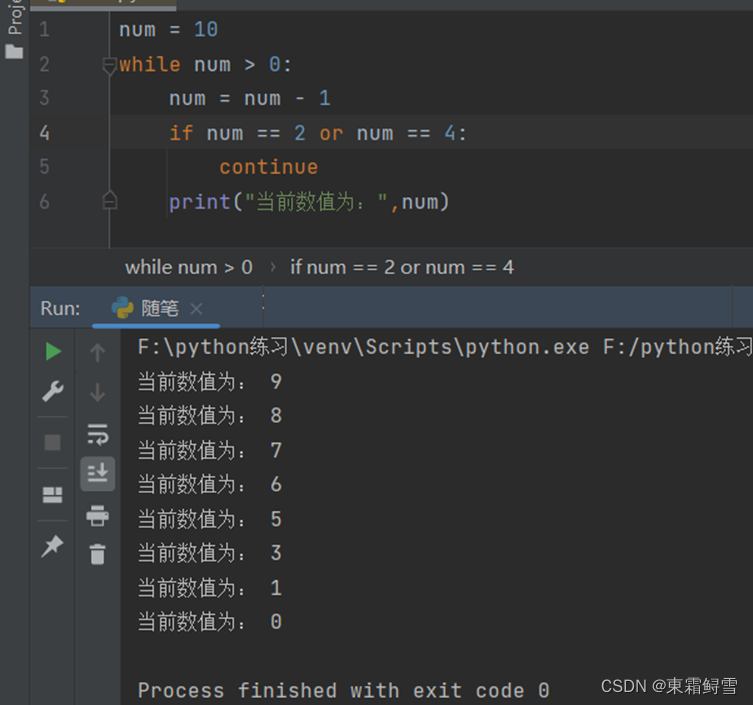
continue将num=2和num=4的值直接剔除出去不执行print语句。
4、列表、元组、字典和集合
4.1列表
列表是python中使用最频繁的数据类型,在上面提及range()函数的时候,以及提到了list()函数将range()函数生成的序列转换为列表。Python中的列表类似于C语言和java中的数组,不同的是数组存储的数据类型必须一致,而列表可以存储不同的数据类型;另外,静态数组在定义的时候必须固定大小,而列表的大小是不固定的。注意的是,python中没有数组,只有与数组类似的列表和元组。
4.1.1 创建和使用列表
创建列表:
列表的创建方法和数组类似,都是使用“[]”将元素括起来,用“,”将元素分隔。例子:

在创建列表时,尽量不要使用字段list作为变量名,虽然在python3里面是可以的,但是可能造成变量名和函数名混淆。跟字符串一样,列表可以使用“+”或“*”拼接生成新的列表。例子:
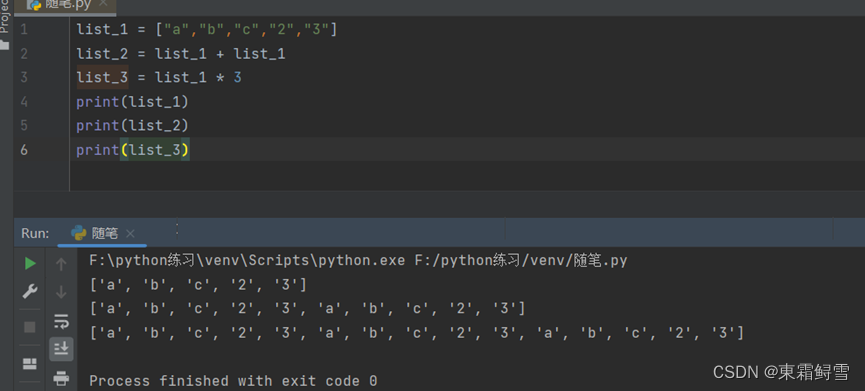
该例子可以看出,列表中的元素是可以重复的。
使用list()函数可以将字符串或range()函数生成的序列转换成列表。例子:

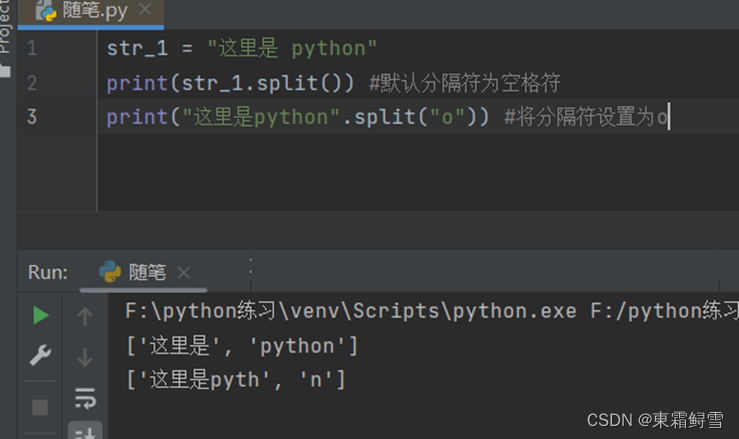
前面讲解过的split()函数也能将字符串转换为列表,只不过它是按照分隔符拆分字符串生成列表。例子:
前面讲解过的循环也可以创建列表。例子:
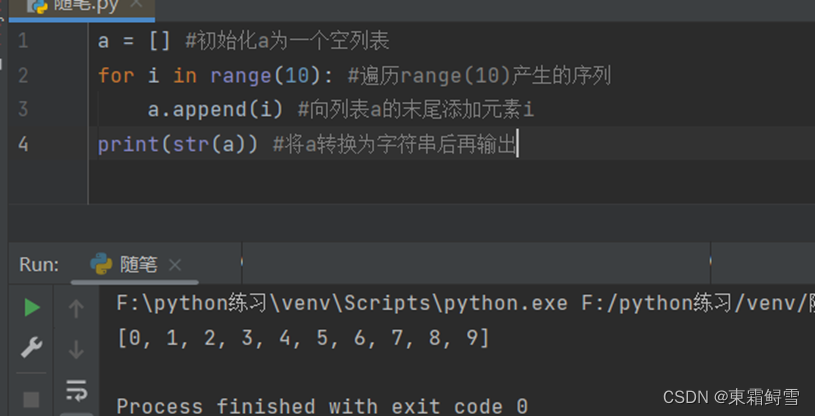
该例子中的append()函数的功能是在列表末尾添加新的对象,其基本语法如下:
list.append(obj)
其中list为目标列表,obj为添加到列表末尾的对象。append()函数修改的是目标列表,没有返回值。例子:

如果想要知道列表中有多少个元素,可以使用len()函数。例子:

使用列表:
- 索引列表元素
和字符串一样,列表的元素也可以通过下表索引的方法来索引。下标索引的顺序从左到右为1,2,3,4,……,len(list)-1。例子:
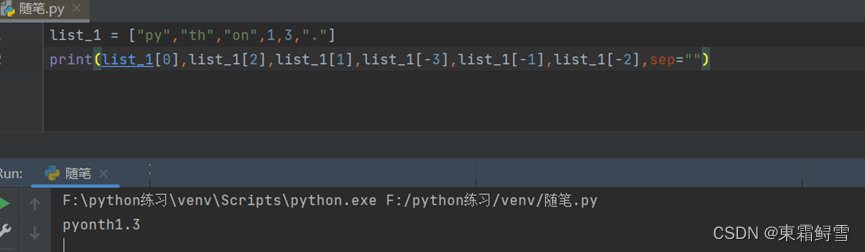
在使用下标索引的方法索引列表的元素时,必须注意越界问题。当索引值超出了范围的时候,会出现报错信息“list index out of range“。例子:
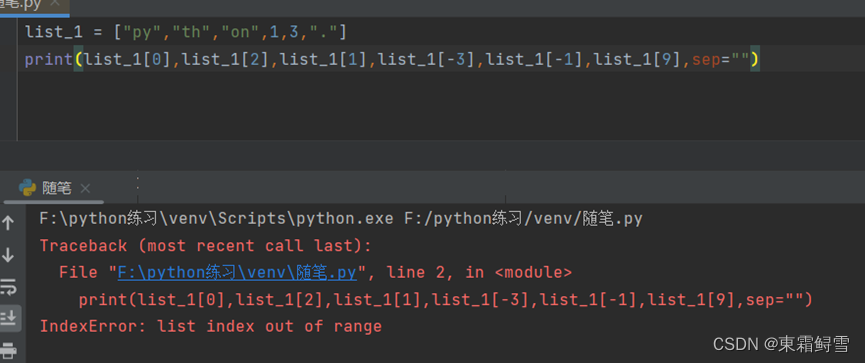
除了使用下标索引的方法来索引列表元素外,还可以使用循环来遍历列表的元素。例子:
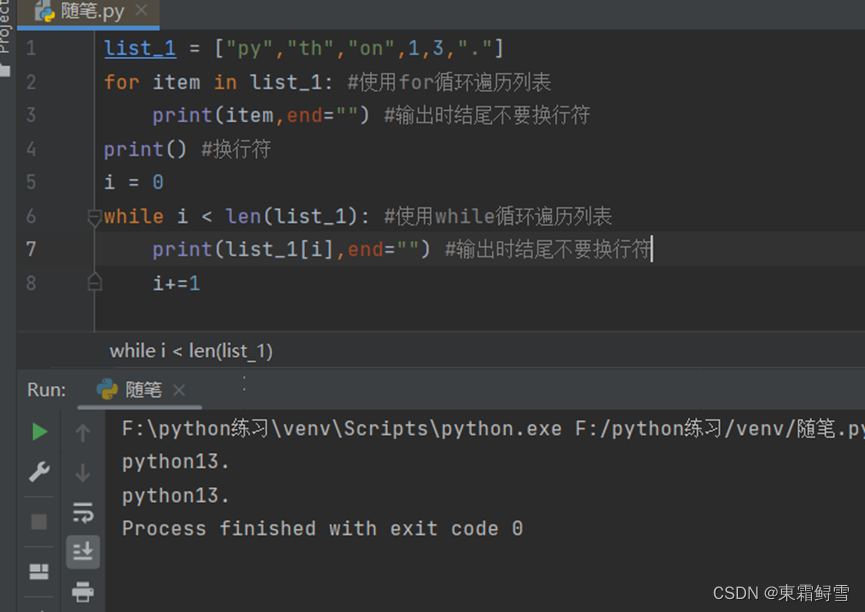
需要注意的是,在使用循环遍历列表的同时,不能修改列表的元素,否则可能出现错位。
- 对列表进行切片
列表也可以像字符串那样进行切片,切片方法如下:
List[start_index(包含):end_index(不包含):step]
其中,起始位置默认值为0,结束位置默认值为列表的长度,切片步长默认值为1。例子:

此外,列表还可以像字符串那样逆置。例子:

- 修改列表元素
列表与字符串、整型和浮点型不一样,它是可变的,列表元素的值可以通过索引值修改。例子:
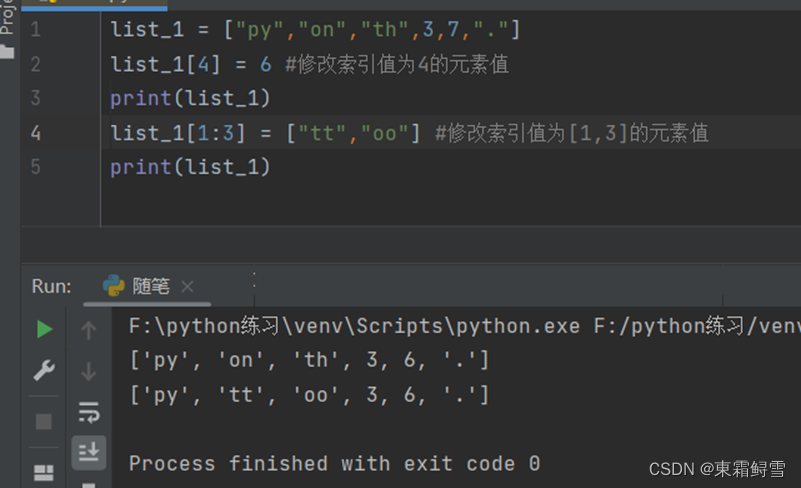
需要注意的是,通过索引值的值的时候,只是将该元素重新指向另一个值。因此这里的元素类型类似于前面讲到的变量,它们的存储机制基本是一样的。例如上述例子各项索引值均指向各自的值,索引值为4的元素的值在修改后,不再指向之前的值7,而是指向修改后的值6。下图所示为例子中的第二行代码的执行原理:

列表里的元素也可以指向另外的列表。例子:
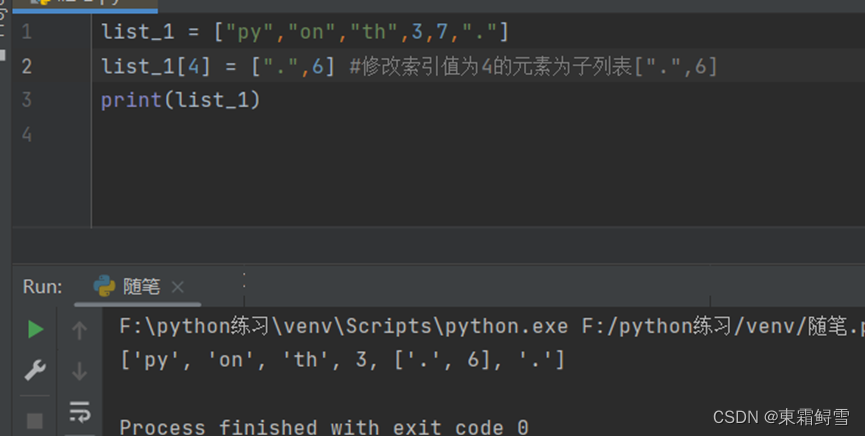
此时想要访问上述列表list_1的子列表[“.”,6]中的元素,可以使用以下方法:
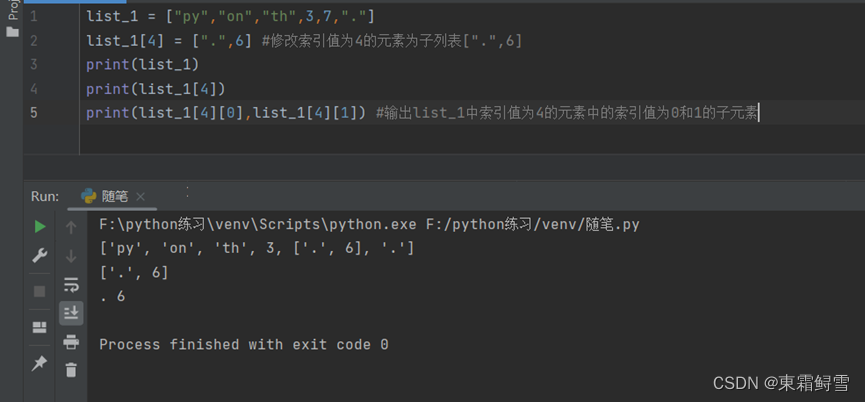
当列表中嵌套有多重列表时一次类推。另外,当列表里的元素指向列表本身时,并不会产生无限输出列表的情况。例子:
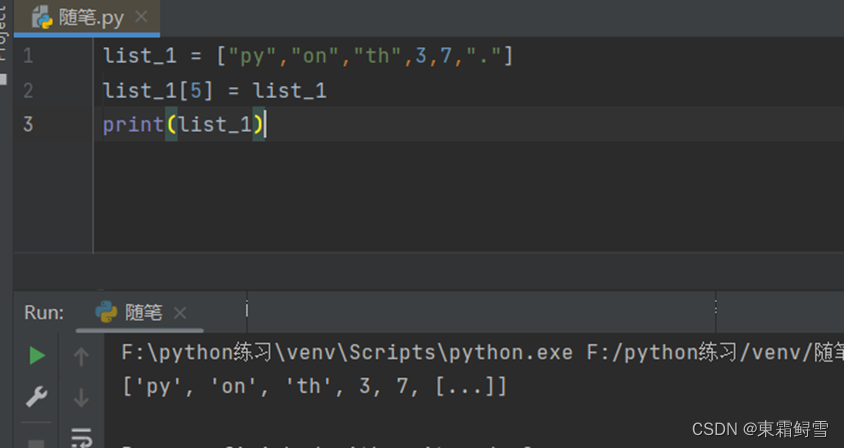
上述例子中可以看到,在修改列表元素时,列表能够自动判断元素指向的是否是列表本身。如果是,就跟上述例子中一样,以[…]代替引用的列表。
- 列表转换为字符串
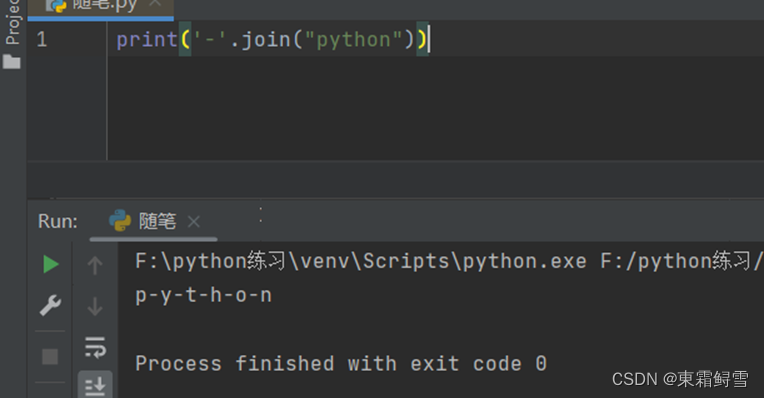
要将列表转换为字符串可以使用join()函数。例子:

上述例子中的“”里可以是任何符号,没有则认为是空符号。例如是“/”:

join()函数还能对字符串进行处理,如将字符串中的每个字符以分隔符“-”分隔。例子:
4.1.2列表进阶
1.添加元素
像列表里添加元素可以使用list.append(obj)函数。例子:

使用list.insert(I,obj)函数也能向列表里添加元素,它比ist.append(obj)函数更加灵活,添加的元素obj添加到索引值为i的元素前面,即添加后的元素的索引值为i。例子:
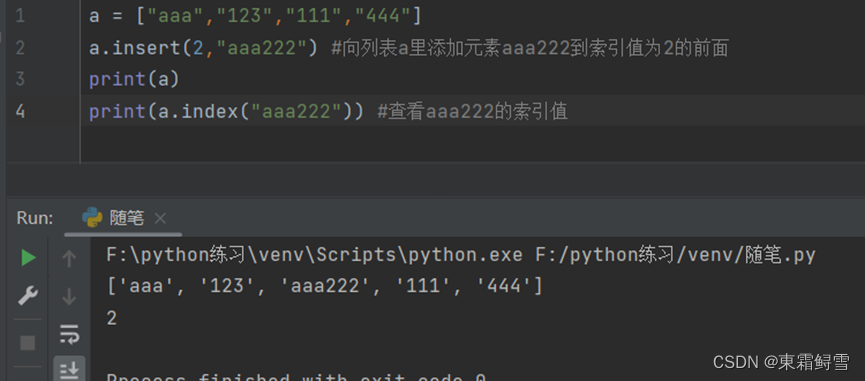
当i为0时,添加的元素是添加到整个列表之前:当i=len(list)的时,添加的元素是添加到整个列表之后相当于list.append(obj)。例子:

当需要将一个列表里的所有元素都添加到另一个列表中时,可以使用list.extend()函数。例子:

上例中将列表b的所有元素全部添加到列表a的末尾,相当于a[len(a):] = b
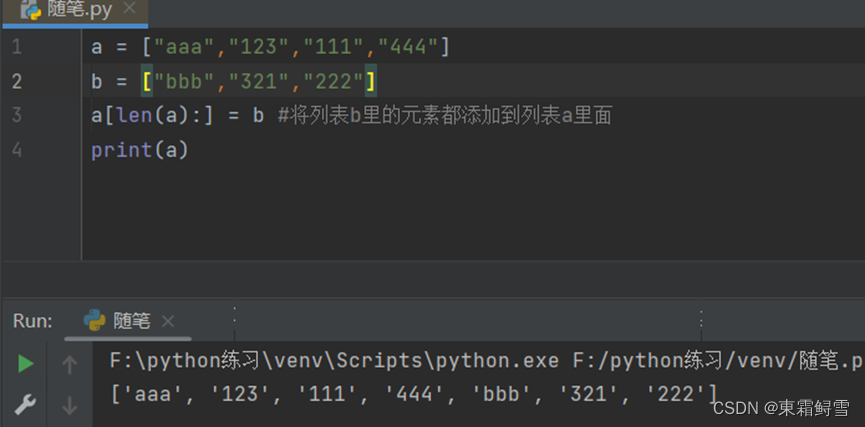
2.删除元素
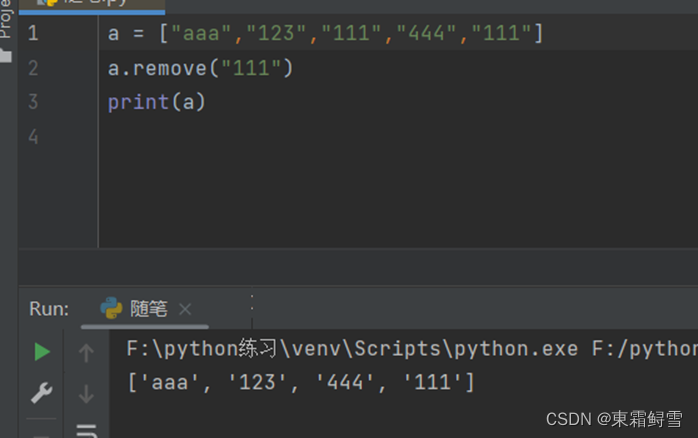
想要删除列表中的元素,可以使用list.remove(obj)函数,该函数的功能是删除值为obj的第一个元素,如果没有元素obj,则报错。例子:

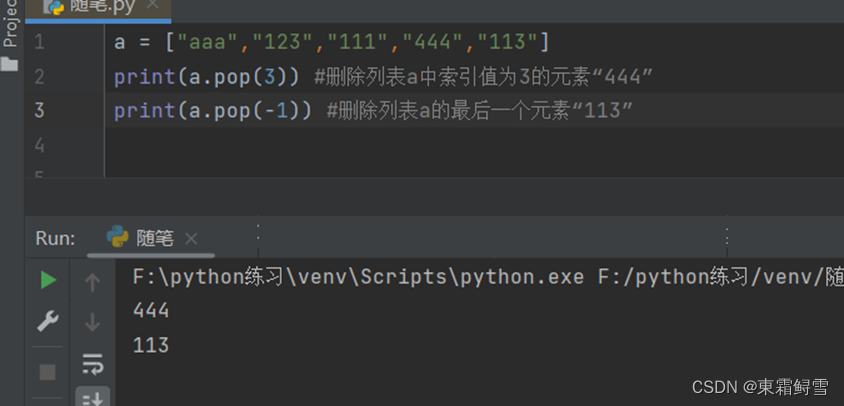
使用list.pop(i)函数也可以删除列表中的元素,该函数的功能是删除列表中索引值为i的元素,并返回删除的元素。比list.remove(obj)函数更灵活。例子:
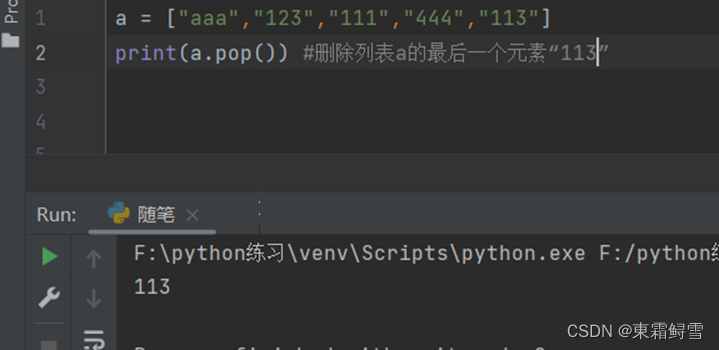
如果没有指定索引值,则删除列表的最后一个元素。例子:
list.pop()函数一次只能删除列表中的一个元素,想要删除多个元素可以使用del语句,用法如下:
del list[i] 或 del list[start:end:step]
del语句比list.pop()函数更灵活。例子:

del语句不仅能清空列表,更能删除整个变量。例子:
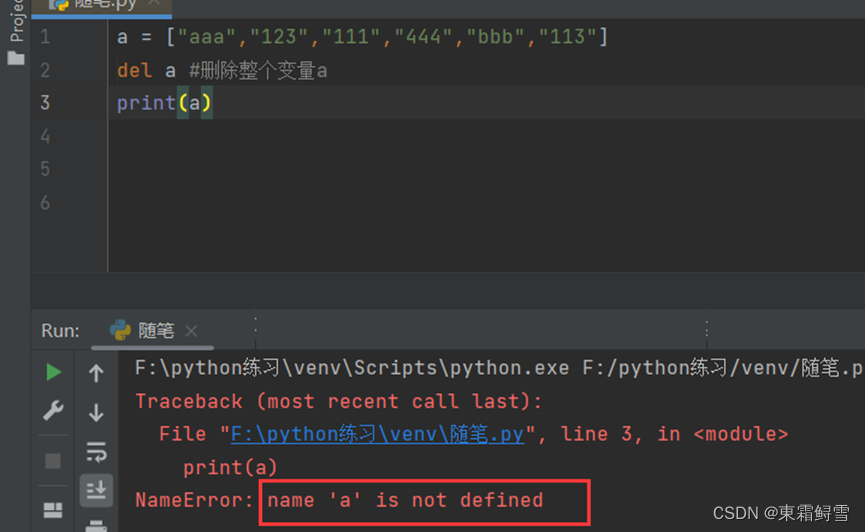
报错找不到名为a的变量。
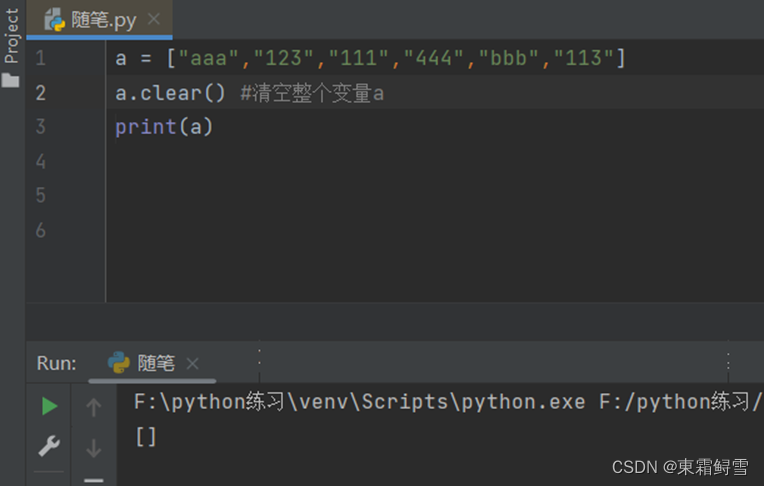
使用list.clear()函数也能清空列表,相当于del list[:]。例子:
3.查找索引值
查找列表中某个值的索引值可以使用list.index(obj)函数,返回的是列表中第一个值为obj的索引值,没有找到则返回错误信息。例子:

统计元素obj在列表中出现的次数,可以使用list.count(obj)函数。例子:

4.逆置函数
逆置列表中的元素,可以使用reverse()函数,相当于前面的list[::-1]。例子:

5,列表排序
Python中专门为列表排序提供了函数sort(),它可以快速的将含有大量元素的列表按顺序排序。其基本语法如下:
List.sort(cmp=None,key=None,reverse=False)
其中,cmp为可选参数,如果指定了该参数,则会使用该参数的方法进行排序。Key是用来进行比较的元素,用于指定可迭代对象中的一个元素来进行排序。reverse为排序规则,当reverse=Ture时,按降序排序;当reverse=False时,按升序排序(默认)。例子:
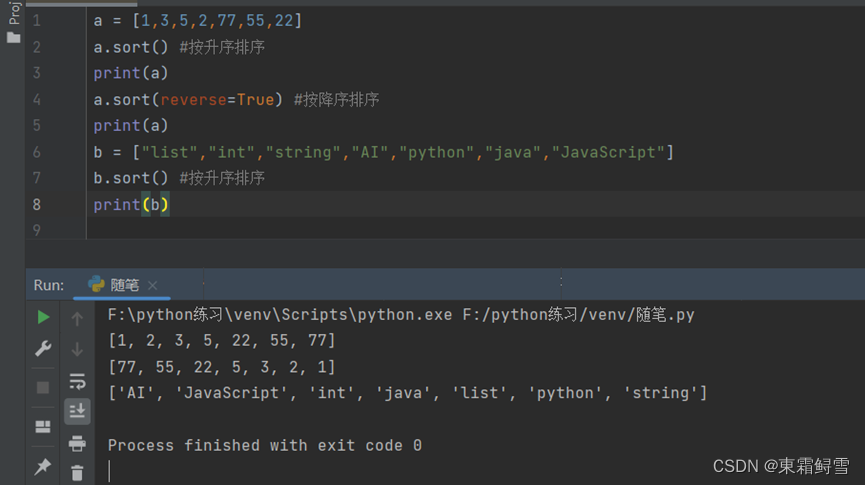
其中对字符串列表排序时,排序规则时按照ASCII码值进行排序,当第一个字符的ASCII码值相等时,则比较第二个字符的ASCII码值,以此类推。
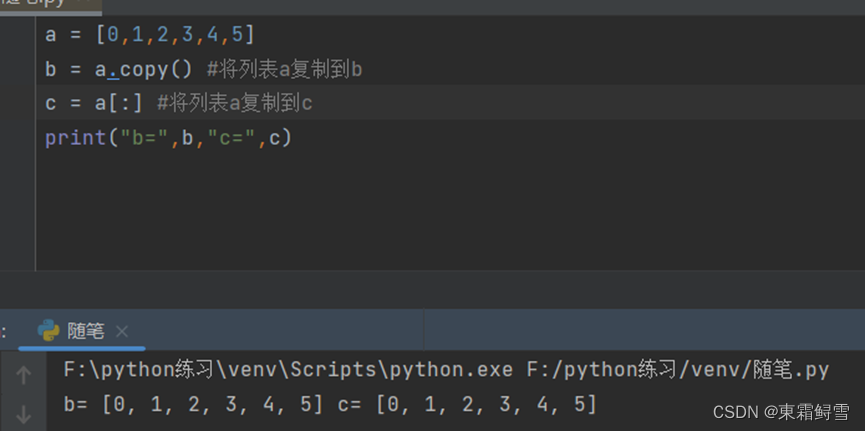
6.复制列表
复制列表,可以使用copy()函数,它返回一个新的列表,类似于list[:]。例子:
注意:这里使用的copy()函数和直接使用=赋值的差别。例子:
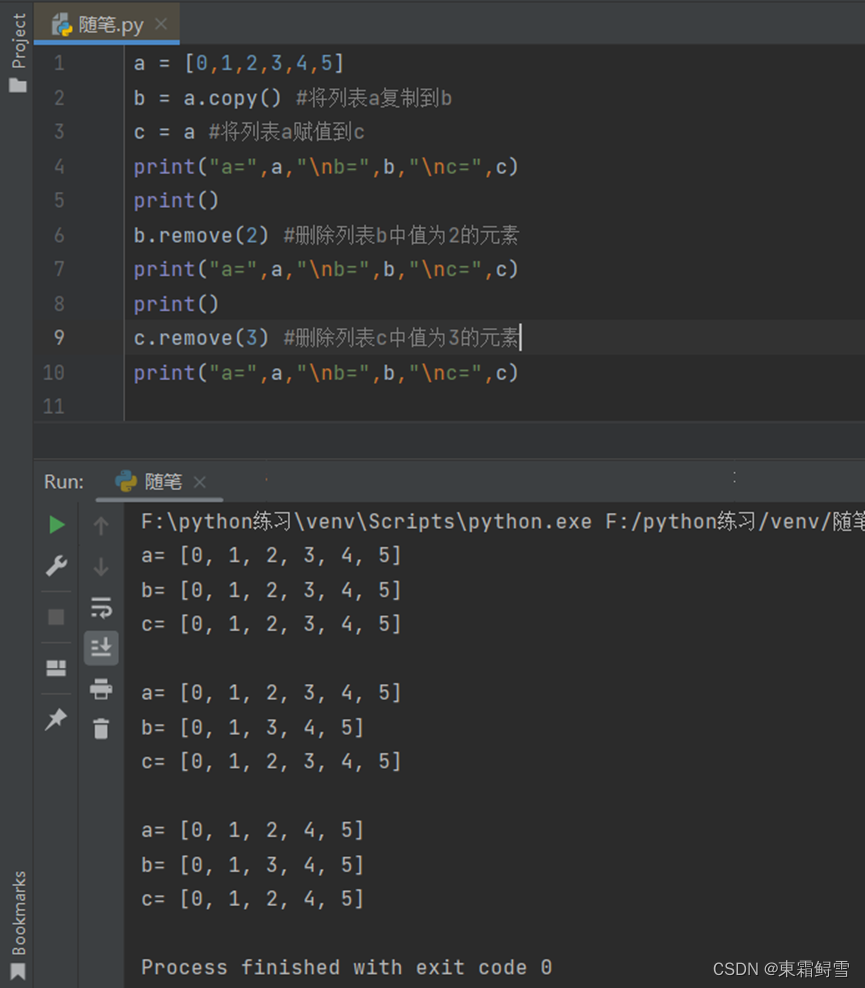
从该例子中可以看出使用copy()函数后更改该列表中的元素,原列表并不会受到改变,而使用=赋值的列表,更改该列表中的元素会使原列表中的元素也发生改变。
下表为列表的函数或语句:
| 函数或语句 | 功能 |
| len(list) | 返回列表元素个数 |
| list.append(obj) | 在列表list的最后一个元素之后添加元素obj |
| list.insert(i,obj) | 将元素obj插入到索引值为i的元素的前面 |
| list.extend(L) | 将列表L内所有的元素添加到列表list末尾 |
| list.remove(obj) | 删除列表第一个值为obj的元素 |
| list.pop(i) | 删除并返回列表list中索引值为i的元素,当pop()内没有i时删除列表list的最后一个元素 |
| del list[i]或 del list[start:end:step] | 删除列表中索引值为i的元素或删除索引值范围为[start,end)、步长为step的元素 |
| del list | 删除变量名为list的列表 |
| list.clear()或del list[:] | 清空列表 |
| list.index(obj) | 查找并返回元素obj在列表list中的元素索引值 |
| list.count(obj) | 统计并返回元素obj在列表list中出现的次数 |
| list.reverse()或list[::-1] | 逆置列表元素 |
| list.sort(cmp=None,key=None,reverse=False) | 对列表元素进行排序 |
| list.copy()或list[:] | 赋值并返回一个同样的列表 |
4.1.3列表解析
列表解析时一种快速创建列表的方法,它能减少创建列表的代码量。
- 使用循环生成列表
例如使用循环:

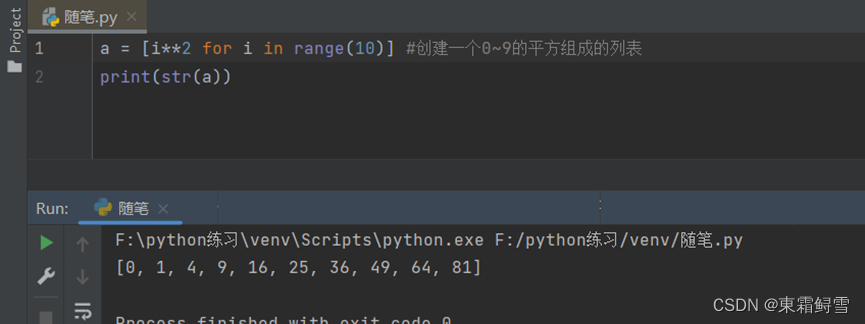
- 使用列表解析创建列表
例如将i的平方添加至列表a:
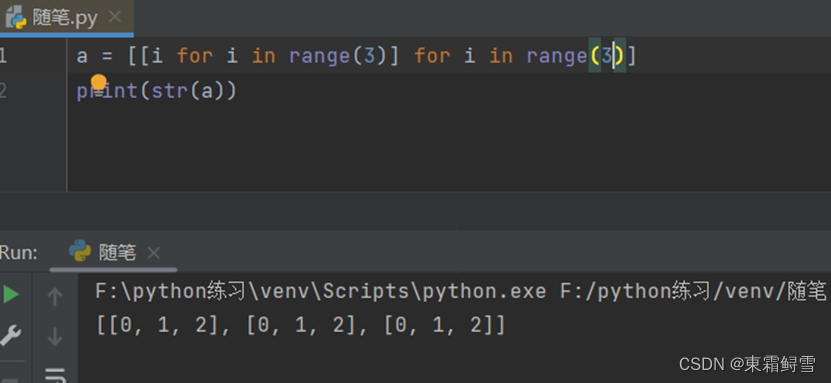
- 嵌套使用列表解析创建列表
例如使用列表解析生成一个二维列表:
列表解析也能将字符串转换成列表。例子:

4.使用列表解析快速修改列表内容
列表解析还可以按照某种方式快速修改列表的内容,例如将列表中所有元素首字母改为大写:

5.使用列表解析筛选列表元素
列表解析还可以根据某种条件筛选出列表中的元素,这在某些时候是十分有用的,例如找出列表a中大于18的元素的程序:

如果不使用列表解析,就会增加代码量。例子:

列表解析还可以用来筛选字符串。例如删除字符串中的数字的程序:
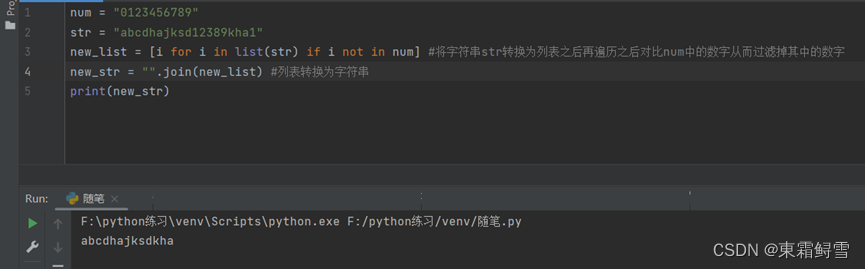
4.2元组
元组是python中与列表类似的一种数据结构,同样也可以通过索引来访问、切片、存储任意元素。但与列表不一样的是,元组的元素是不可变的,在编程时,比列表更安全。这就是元组与列表的最大差别。
4.2.1 创建和使用元组
1.创建元组
创建元组和创建列表的方法类似,不同的是列表使用“[]”作为标识符,而元组使用“()”作为标识符。例子:

和创建列表不同的是,元组对于“()”在大多数清空中并不是强制要求的。因此也可以使用下述方法创建元组;
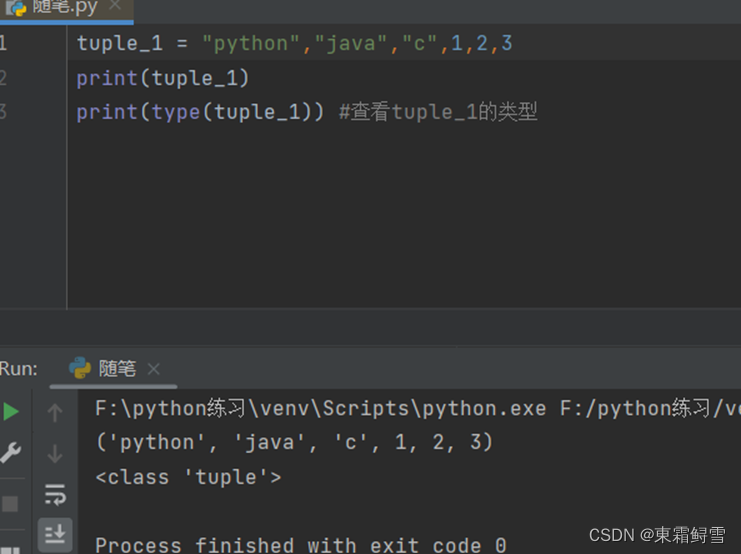
但是当元组为空时,省略“()”会报错,这个时候就必须使用“()”来创建空元组。
还有一种特殊情况就是创建只有一个元素的元组时,必须使用一种特殊的方法来创建元组:
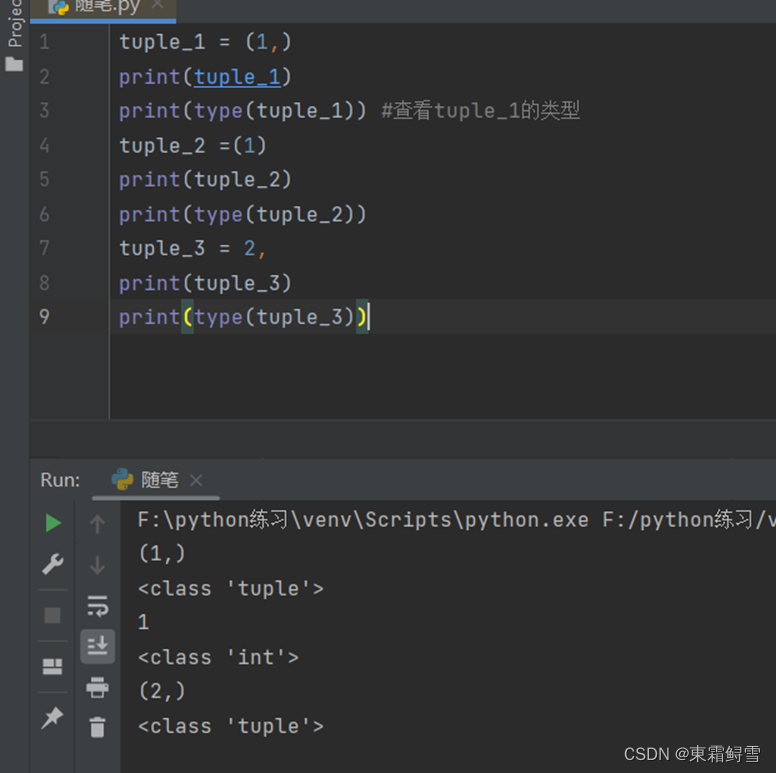
可以看到创建一个元素的元组时,元素后面必须要跟个”,”,“()”都可以省略不写也行,但是“,必须跟”,否则创建的是一个整型变量,而不是元组变量。
元组也可以使用“+”和“*”进行拼接。例子:
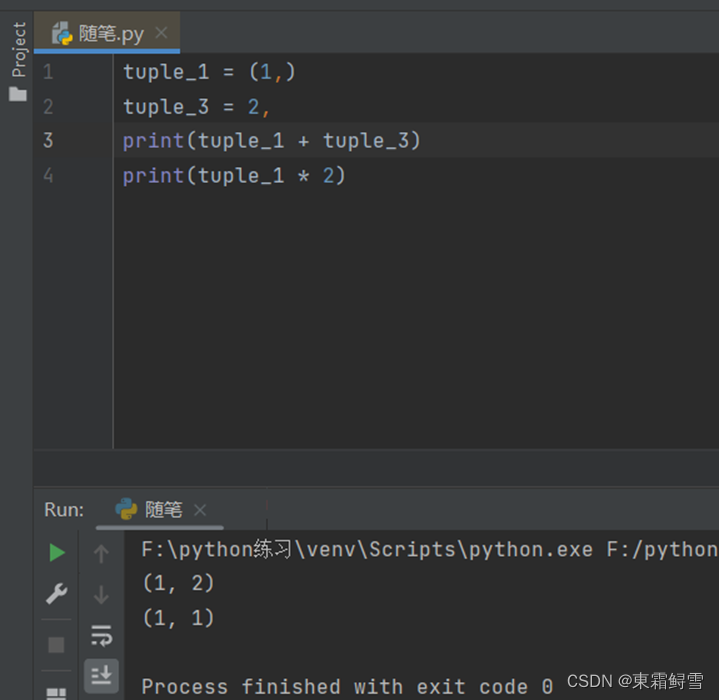
可以看到元组和列表一样,它的元素也可以重复。
如果需要将字符串或 range类型的数据转换为元组,可以使用tuple()函数,例子:
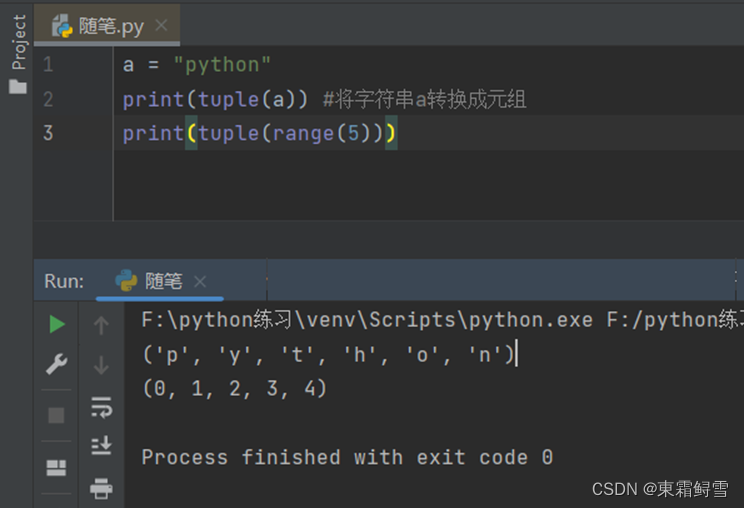
元组创建成功后也可以使用len()函数查看元素个数。例子:

2.使用元组
(1)索引元组元素
元组的元素虽然是不可变的,但是可以通过索引去访问。访问的方法跟列表是一样的。例子:
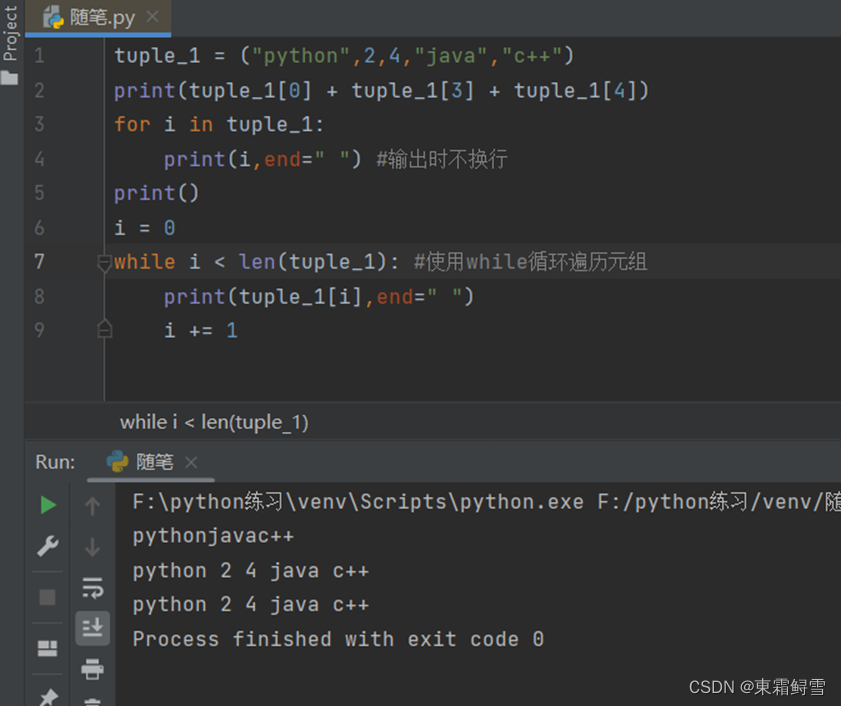
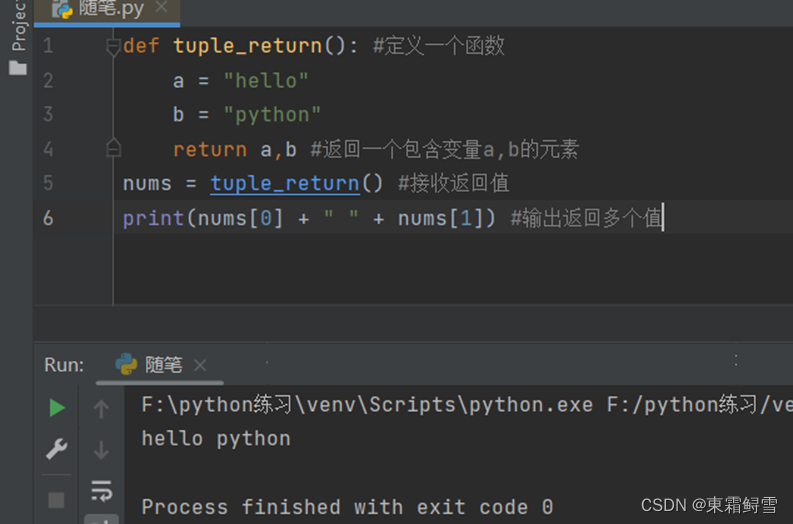
Python解决了在C语言和Java中函数的返回值只能为一个值的问题。使用元组作为返回值,可以一次返回多个值的效果。例子:
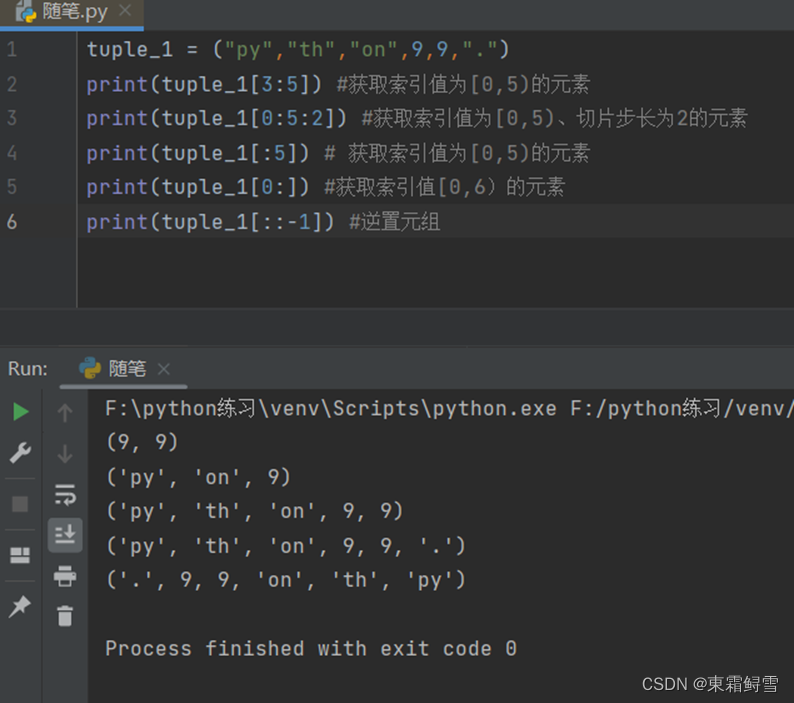
(2)对元组进行切片和逆置
元组也可以使用与列表相似的方法进行切片和逆置。例子:
(3)修改元组
元组的元素是不可变的,所以使用例如索引来改变是不可能的(例如:tuple[i]=0)这种是不可能的也是错误的。元组的元素虽然不可修改,但是如果元组中包含了可变的数据类型时,该可变数据类型的内部是可以修改的。例子:

这种操作看似修改了元组的元素,其实修改的是元组内的列表中的元素,元组内的元素并没有改变,就相当于元组内的元素是一个个的盒子,元组会让这些盒子不会改变,但是盒子内的东西可以修改。
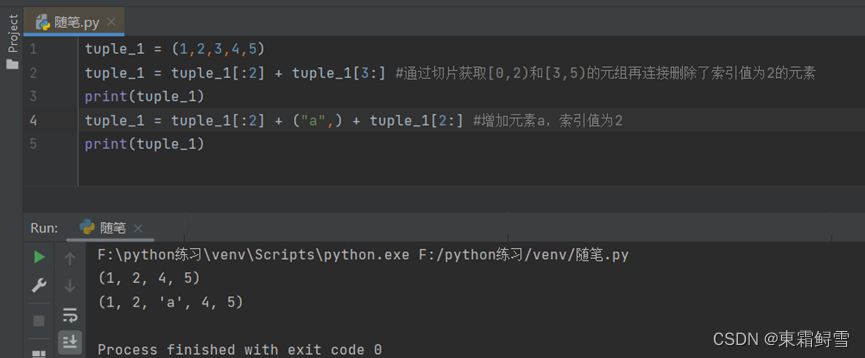
元组中的元素值不允许修改,但是可以对元组进行切片和连接,从而达到增删改查的目的。例子:

- 删除元组
元组的元素是不可删除的,但可以通过del语句删除整个元组。例子:

例如上面例子中通过元组的切片再连接就可以删除指定索引位置的元素:
4.2.2元组进阶
跟列表一样,python也提供了一些内置函数供元组使用,但是元组的函数相比于列表较少。
例如如何查找一个元素在元组中的位置,可以使用index()函数:
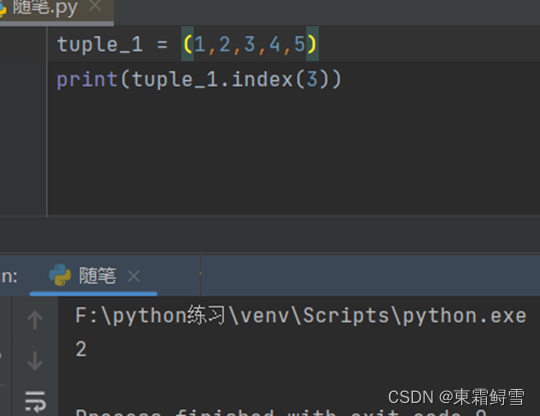
例如统计某个元素在元组中出现的次数,可以使用count()函数:
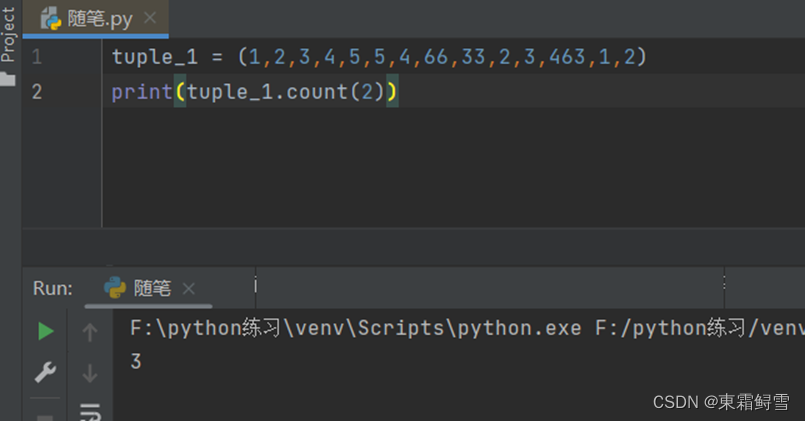
当元组中元素的数据类型全是整型或浮点型时,可以使用max()函数和min()函数查找出元组中元素的最大值和最小值:

元组和列表中之间可以使用list()函数和tuple()函数想换转换:

元组的函数如下表所示
| 函数 | 功能 |
| len(tuple) | 返回元组元素的个数 |
| tuple.index(obj) | 返回元组中值为obj的元素索引位置 |
| tuple.count(obj) | 返回元组中值为obj的元素出现次数 |
| max(tuple) | 返回元组中元素的最大值 |
| min(tuple) | 返回元组中元素的最小值 |
| list(tuple) | 将元组转换为列表 |
| tuple(list) | 将列表转换为元组 |
4.3 字典
字典和列表、元组一样,也能存储任意类型的数据。是一种可变数据结构。不同的是字典使用键值对(key-value)的形式来存储数据,这类似于Java中的Map。
4.3.1 创建和使用字典
1.创建字典
字典使用花括号“{}”作为标识符,键和值之间使用英文冒号“:”分隔,每个键值对之间使用英文逗号“,”分隔。例子:
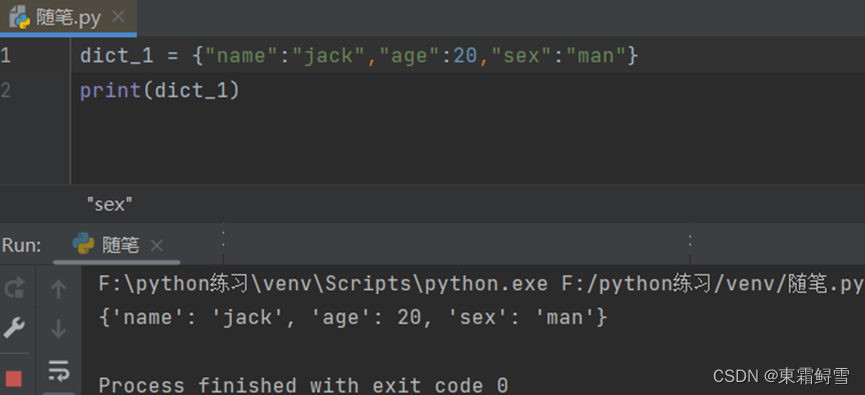
上述例子里创建了字典dict_1,里面包含了三个键值对,分别存储了姓名、年龄和性别。用其中的’name’:’jack’举例,这里的’name’为键名,’jack’为键值。注意这里的键名是字符串类型,必须使用英文引号括起来,且字典中的键名不能重复。例子:
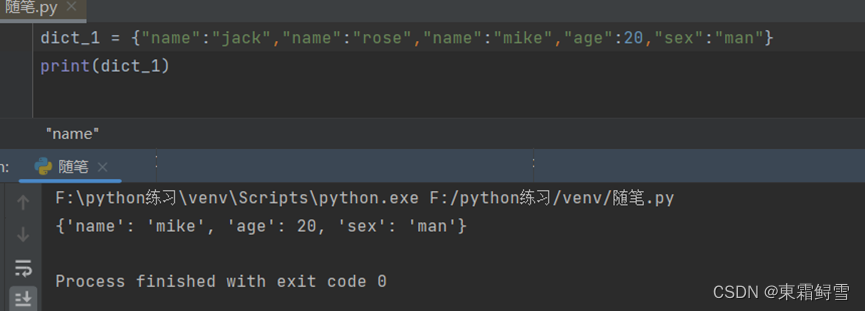
从该例可以看出当字典中有两个及以上的键名时,python只会存储最后一个。因此字典中的键名必须是唯一的。
需要注意的是字典中的键值可以是任何python中的对象(包括标准的对象和用户定义的对象),但键名必须是不可变的数据类型,如字符串、浮点型或元组。例子:
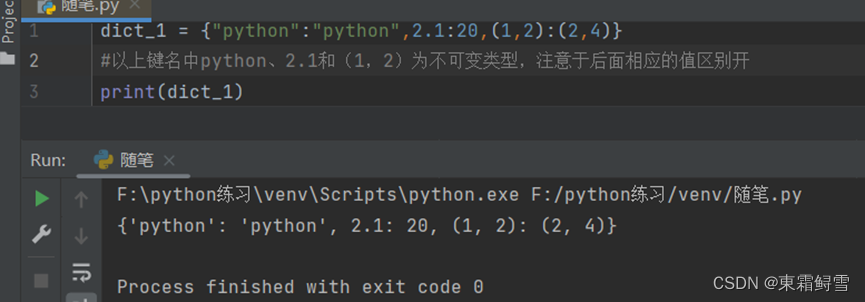
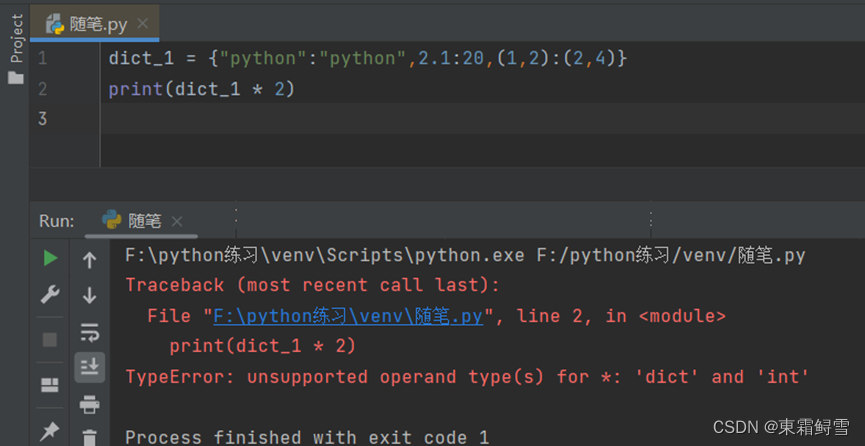
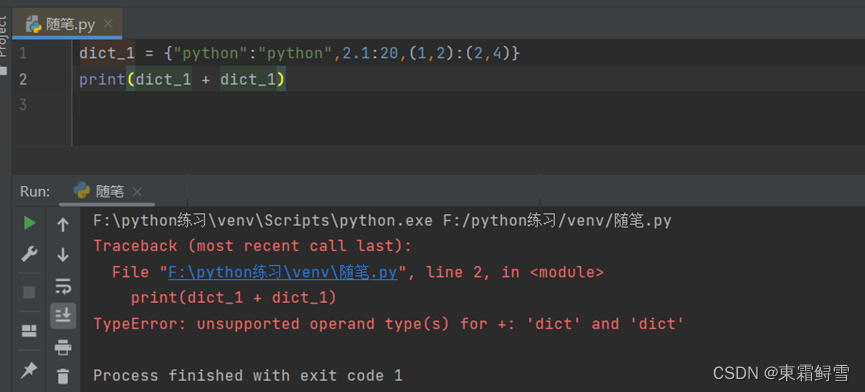
字典的不可重复性使得它不能像列表和元组那样使用“+”和“*”进行拼接,强行使用则会报错
字典可以动态地创建。例子:
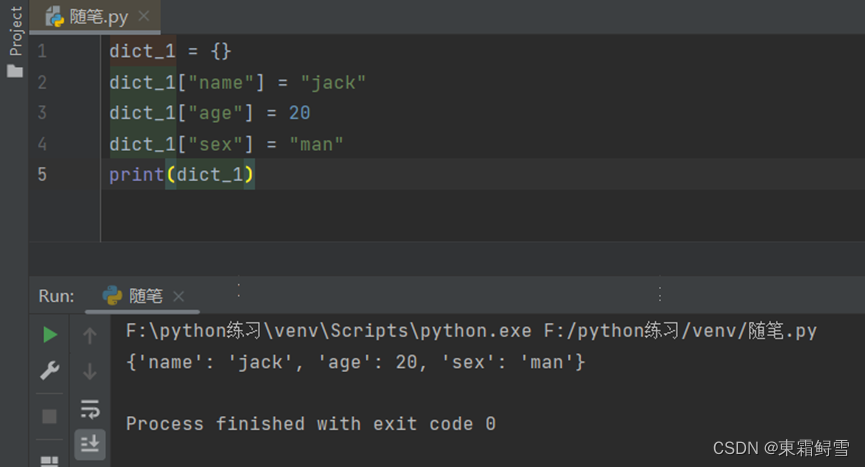
字典创建成功后,同样可以使用len()函数查看键值对的个数。例子:

2.使用字典
(1)索引字典值
字典和列表、元组不一样,它使用键名作为索引。因此要索引一个字典可以如下所示:

在访问字典里的键值时,如果直接用[key]访问(即只用键名查找),那么在没有找到对应的键名的情况下就会报错。例子:

一个更好的替代方法是使用字典内置的get()函数来获取键值,使用get()函数,即使键名不存在也不会报错。例子:
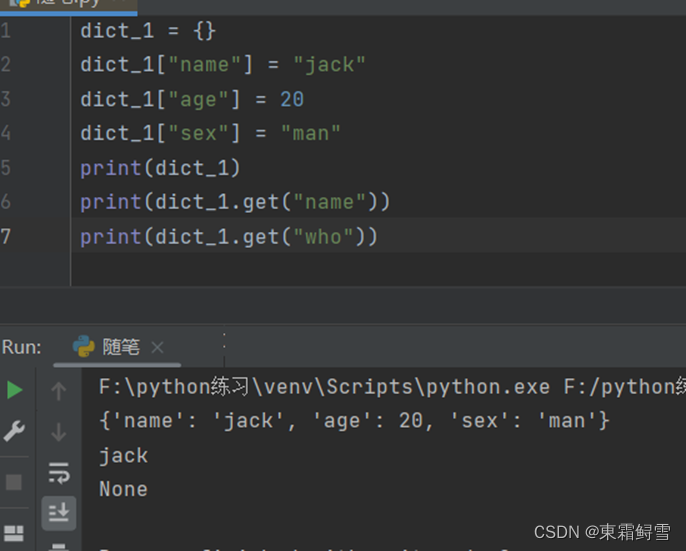
可以看到查找不存在的键名时会返回一个None。
键值对的存储方式极大地提高了字典的使用效率,如同查找汉语字典时通过拼音等方式来查找。Python中的字典在索引的时候会根据键名自动找出键值对的位置,从而快速地从成千上万的键值对中查找所需的信息。
如需判断字典中是否存在某个键值对,可以使用“in”。例子:

字典也可以使用循环来遍历,不过和列表、元组不一样,它只使用for循环来遍历。例子:

(2)修改字典的键值对
字典是可变的,字典的键值可直接根据索引修改。例子:

这种就是根据字典只会存储相同键名的最后一个键值,所以就可以通过这种方法来修改键值。
(3)删除字典的键值对
删除字典的键值对可以使用del语句。例子:
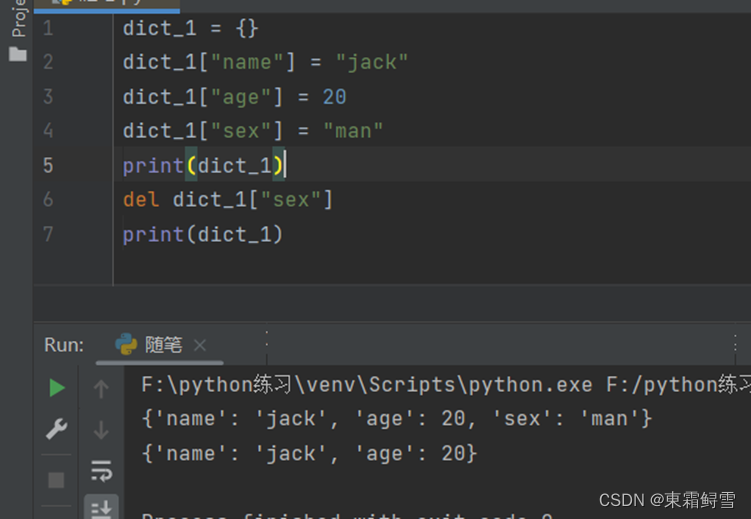
使用del语句也能将整个字典删除。例子:

删除完字典之后就会报错没有找到字典。删除后的字典也不能再使用了,除非重新创建。
4.3.2 字典进阶
1.使用函数创建字典
使用函数创建字典可以提高我们创建字典的速度,但是需要注意前面所讲述的创建字典时需要注意创建的字典的键名必须是字符串、浮点型或元组。例子;
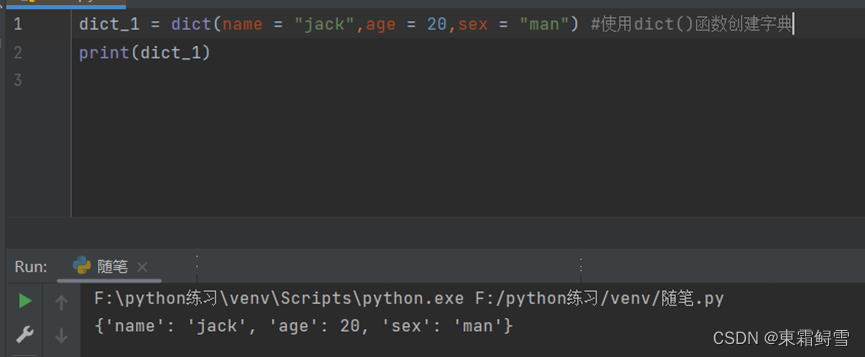
使用dict()函数创建字典时,键名不需要再用引号括起来。
使用dict()函数能直接将存储的键值对的列表转换成字典。例子:
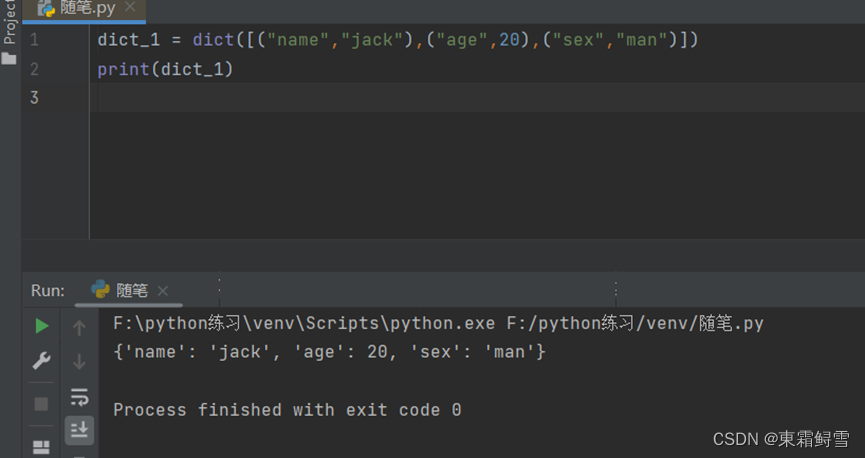
如果以有存储键名的列表或元组,还可以使用dict.fromkeys(keys,values)函数来快速生成字典。这里的key为存储键名的列表或元组,values为存储键值的变量,默认为None。例子:

其中需要注意的是,如果values参数为存储键值的列表或元组时,python并不会自动把键名和键值对应起来,而是让键名对应整个列表或元组。例子:

2.使用函数获取字典元素
Python为字典提供了三个基本的函数:items()、keys()、values()。分别用来获取键值对、键名和键值组成的视图。例子:

使用上例中得到的视图,可以很轻松的遍历字典的键名和键值。例子:

如果需要判断字典中是否存在或不存在某个键名,可以使用“in”和“not in”运算符。例子:

如需将不存在的键值对插入字典,可以使用dict.setdefault(key,value)函数。例子:

3.使用函数操作字典元素
上述提及删除一个字典的键值对时,可以使用del语句。在python中使用函数也可以删除字典的键值对,python专门为字典提供了一个用来删除键值对的dict.pop(key)函数,它在删除键值对后会返回相应的值。例子:
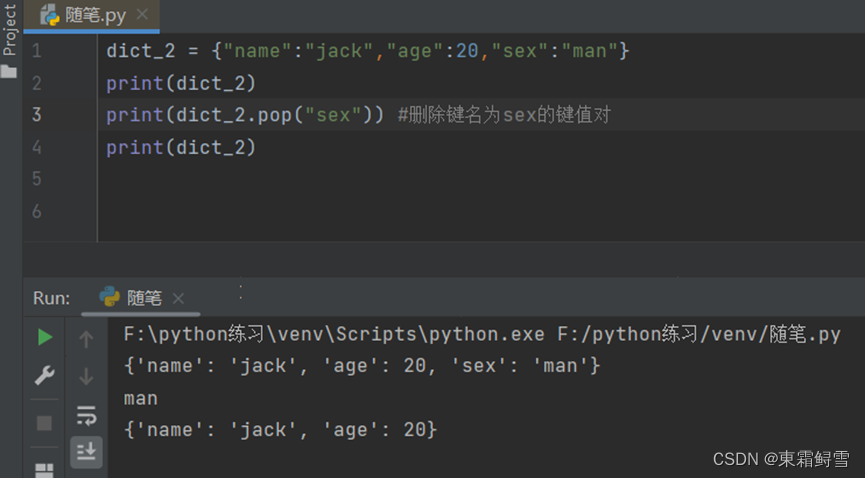
dict.pop(key)函数不仅能删除键值对,还能用来修改键名。例子:

如果要批量删除键值对,则需要用到popitem()函数,它能从字典的末尾开始删除字典的键值对,并且返回删除的键值对。例子:

如需清空字典的键值对,则可以使用clear()函数。例子:
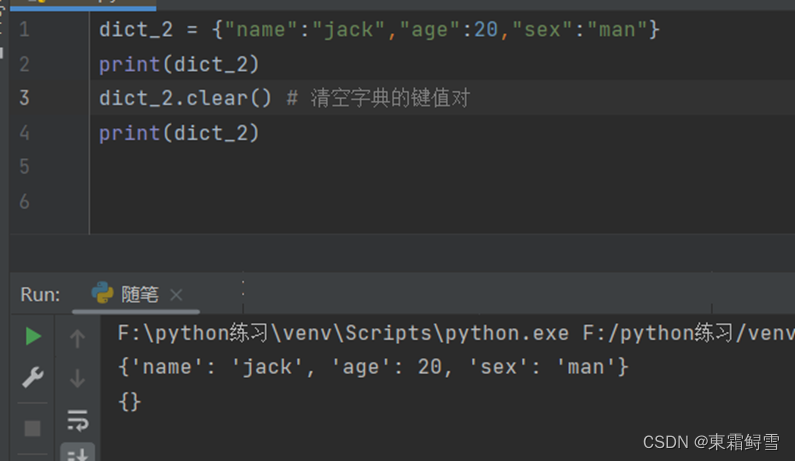
字典也能像列表那样使用copy()函数进行复制。例子:

如需将两个字典合并在一起,则可以使用dict.update(D)函数。例子:

dict.update(D)函数中的D可以是字典,也可以是存储键值对的列表。例子:

字典拥有较多的函数,下表列出了字典的函数:
| 函数 | 功能 |
| len(dict) | 查看键值对的个数 |
| dict(e) | 创建一个字典,其中的e可以是赋值序列,也可以是键值对列表 |
| dict.fromkeys(keys,values) | 创建一个字典,其中的键名来自keys,键值来自values,values的默认值为None |
| dict.items() | 返回键值对视图,一般用在遍历字典时 |
| dict.keys() | 返回键名视图,一般用在遍历字典时 |
| dict.values() | 返回键值视图,一般用来遍历字典时 |
| dict.get(key) | 返回与key对应的键值 |
| dict.setdefault(key,value) | 返回与key对应的键值,如果不存在则将查找的键值对插入字典 |
| dict.pop(key) | 根据键名删除键值对 |
| dict.popitem() | 从字典末尾删除键值对 |
| dict.clear() | 清空字典 |
| dict.update(D) | 将D合并到dict中,其中的D可以是字典,也可以是存储键值对的列表 |
4.4集合
集合类似于上面的字典,都是不可重复的,但是集合有建,没有相应的值,它们在python中用的最多的场景是去重。需要注意的是,集合是不可变的,且它的元素不能通过索引去访问。
4.4.1 创建和使用集合
1.创建集合
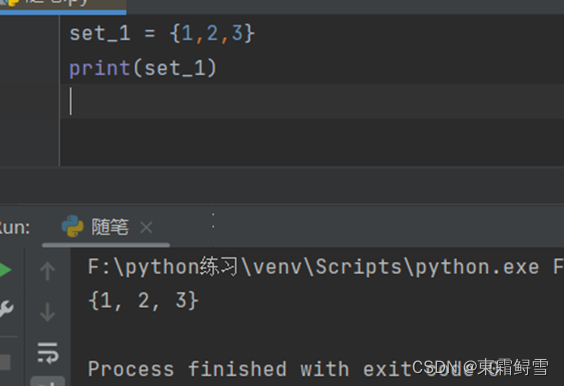
集合使用“{}”作为标识符,创建它的方法和上面讲述的列表、元组、字典是一样的。例子:
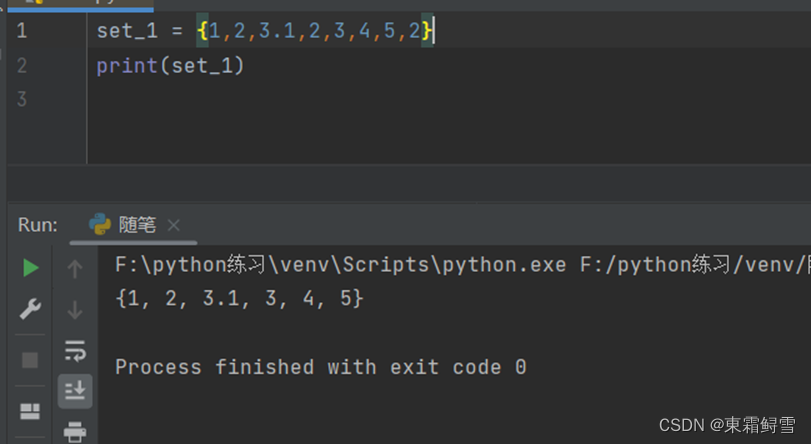
如果创建集合是加入了相同的元素,集合会自动的删除重复的元素。例子:
注意的是,如需创建空集合,只能使用set()函数来创建。例子:
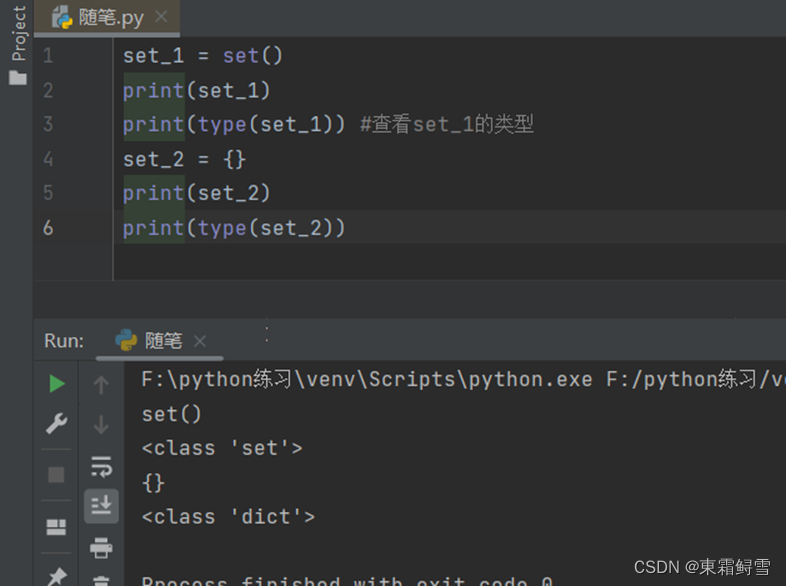
可以看到如果不使用set()函数创建空函数而是直接空的{}那么创建出来的是空字典
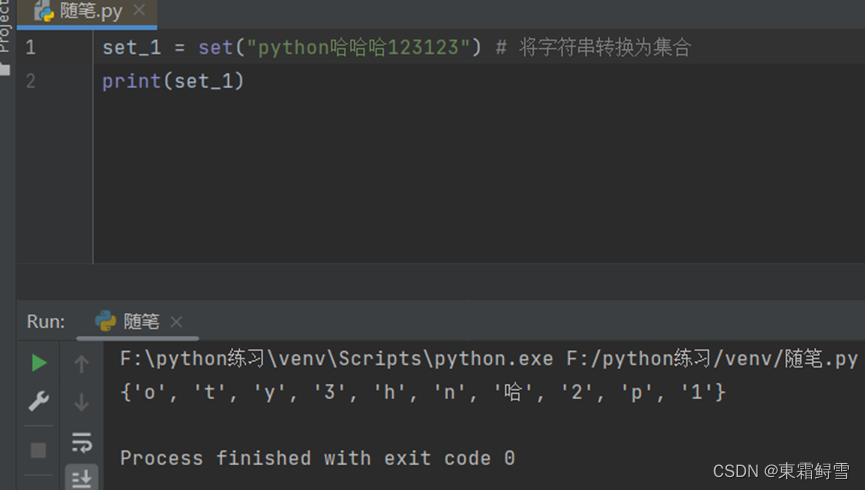
set()函数还能将字符串转换成集合,从而快速删除字符串中重复的字母等元素。例子:
set()函数还能将列表、元组、字典转换为集合。例子:

2.使用集合
集合是不可变的,并且它的元素不能通过索引去访问,但是python中的集合和数学中的集合一样,是可以运算的。Python为集合提供了一些运算符,供集合运算使用,这些运算符的使用如下:

需要注意的是,“&”“|”“-”“^”在集合中的功能是求交集,求并集,求补集和求差集,而在数字的位运算里,“&”“|”“^”的功能分别是按位与运算、按位或运算和按位异或运算,相同的符号在不同场景下的作用不同。
4.4.2 集合进阶
1.新增元素
集合的不可变主要体现在不能修改集合中元素的值,但可以向集合中插入指定元素。如需向集合中插入元素,可以使用set.add(obj)函数。例子:
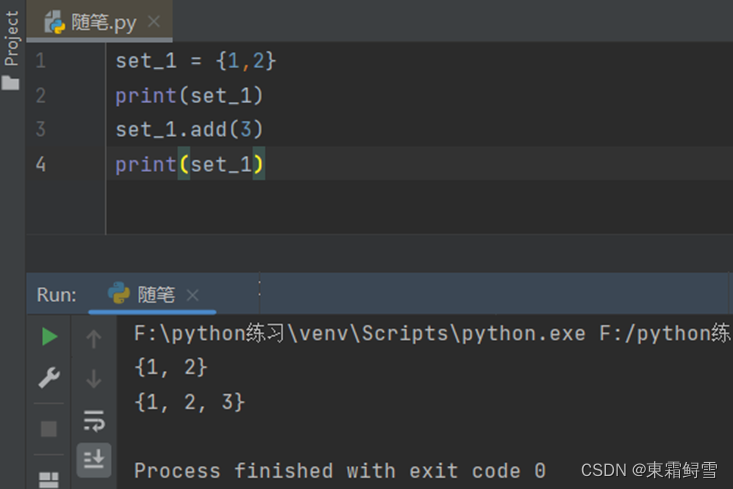
如需一次添加多个元素,则可以使用set.update(s函数),其中s可以为列表、元组、字典等。例子:

2.删除元素
Python中为集合提供了三个函数用来删除元素:set.discard(obj)、set.remove(obj)、set.pop().例子:

下表为关于集合的函数和运算符
| 函数或运算符 | 功能 |
| set() | 创建空集合或将其他类型的数据转化成集合 |
| |、&、-、^ | 集合运算符:求集合的并集、交集、补集、差集 |
| set1.difference(set2) | 找到set1中存在,但set2中不存在的元素,生成新集合并返回 |
| set1.difference_update(set2) | 找到set1中存在,但set2中不存在的元素,覆盖set1集合,并返回None |
| set.add(obj) | 将 元素obj添加到集合set中 |
| set.update(s) | 将s添加到集合set中,s可以为列表、元组、字典等 |
| set.discard(obj) | 删除集合set中的obj元素,元素不存在时不报错 |
| set.remove(obj) | 删除集合set中的obj元素,元素不存在时报错 |
| set.pop() | 随机删除集合set中的一个元素 |
| set.clear() | 清空集合set |
5、函数与模块
5.1 定义和调用函数
函数可以用来拆分一个程序的功能,从而使代码更易读,python中定义函数的方法如下:
def func_name(arg1,arg2,……,argn):
func_body
return expression
其中,def为固定的关键字;func_name为函数名,由用户自定义,但不能为python自带的关键字及内置函数名;arg1,arg2,……,argn为零个、一个或多个传入函数的参数;func_body为函数体,其内容为函数执行的代码;return expression 为函数的返回语句,它会将expression的值返回给调用函数的语句块。在自定义函数时要注意以下规则:函数语句块以def关键字开头,后接函数标识符名称和英文圆括号“()”;任何传入的参数和自变量必须放在圆括号中:函数的第1行语句可以选择性的使用文档字符串,用于存放函数说明;函数内容以冒号起始,并且有缩进;return expression可用于结束函数,可把返回值传给调用方。
函数定义完成之后,只需要使用如下语句即可调用并执行函数,其中arg1,arg2,……,argn为传入函数的参数。示例如下:
Func_name(arg1,arg2,……,argn)
一个定义和调用函数的例子;
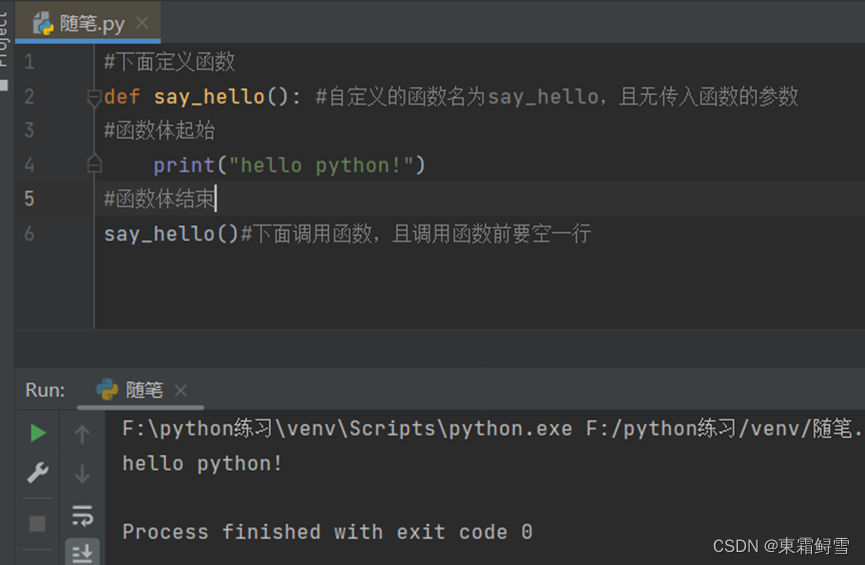
上例定义了一个名为say_hello的函数,并成功调用say_hello()函数,执行了函数中的print(“hello python!”)语句。
需要注意的是,在python中,函数的定义必须在调用之前,否则程序会报错。例子:

会报错,提示say_hello()函数为定义。
当一个项目需要使用很多函数时,可以先将函数定义好,再慢慢地编写函数体。跟画画一样,先确定好框架,再慢慢填充内容细节。
定义一个空函数需要用到pass语句,pass语句通常被视为一个占位符来使用。例子:
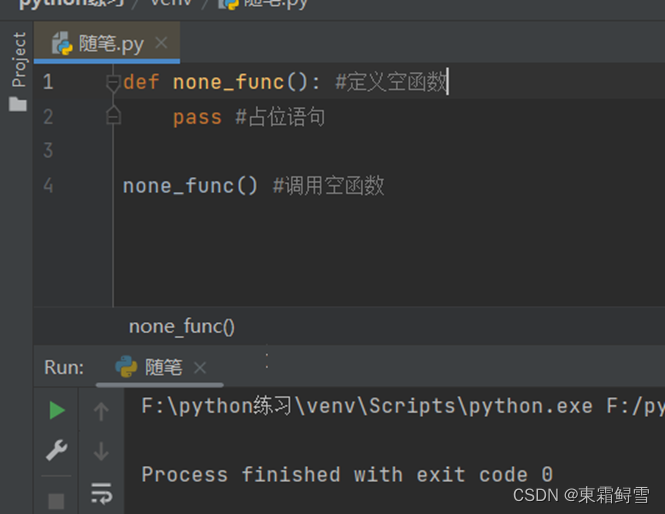
5.2 内置函数
Python中有许多内置函数,这些内置函数无须定义,直接调用即可。它们可以分为3类:数学计算、类型转换、数据处理。
5.2.1 数学计算函数
python中有一些常用于数学计算的函数。下表为常用数学计算函数及其说明:
| 函数 | 说明 |
| abs(a) | 求整数a的绝对值 |
| max(seq) | 求序列seq中的最大值,这里的序列可以是列表、元组和集合 |
| min(seq) | 求序列seq中的最小值,这里的序列可以是列表、元组和集合 |
| sum(seq) | 求序列seq中的所有元素的和,这里的序列可以是列表、元组和集合 |
| sorted(seq) | 对序列aeq进行排序,返回结果为一个列表,这里的序列可以是列表、元组和集合 |
| divmod(a,b) | 返回a/b的商和余数,返回结果为一个有两个元素的元组,第一个元素为商,第二个元素为余数,如divmod(5,2)的返回结果为(2,1) |
| pow(a,b) | 返回a的b次方的计算结果,如pow(2,3)的结果为8 |
| round(a,b) | 采用四舍五入的方法对浮点数a保留b位小数,如round(1.215,2)的结果为1.22 |
5.2.2类型转换函数
类型转换函数常用来转换数据的类型,如 int()、str()、float()、dict()、list()、set()、tuple()等,关于其他的函数及其说明如下表所示:
| 函数 | 说明 |
| bool(a) | 将整数a转换成布尔值,当a=0时转换成False,否则转换成Ture |
| bytes(string,encode_way) | 将字符串string按照encode_way方式进行编码,如bytes(‘hello’,’utf-8’)返回的值为”b’hello” |
| iter(seq) | 将序列seq转换成一个可迭代对象,如iter(1,2,3)返回的值为”<tuple_iterator object at 0x00000127A34C9CC0>”,其遍历输入的值分别为:1、2、3 |
| enumerate(seq) | 将序列seq转换成一个枚举对象,如enumerate(1,2,3)返回的值为“<enumerate object at 0x00000127A34DEC18>”,其遍历输出的值分别为:(0,1)、(1,2)、(2,3) |
| chr(int) | 将整型数字转换成对应的ASCII值,如chr(65)返回的值为”A” |
| ord(str) | 将字符str转换成对应的ASCII值,如ord(‘a’)返回的值为”97” |
5.2.3数据处理函数
Python中有一些功能强大的用于数据处理的函数,如下表所示:
| 函数 | 说明 |
| eval(expression) | 求字符串表达式expression的值,如eval(‘1+2’)的值为“3” |
| exec(code) | 执行python代码code ,如exec(‘print(“python”)’)输出的值为”python” |
| filter(func,seq) | 使用函数func()筛选序列seq元素 |
| map(func,seq1,seq2……) | 将函数func()的执行内容应用于序列seq1,seq2,……的每一个元素 |
| zip(seq1,seq2……) | 将序列seq1,seq2,……合并为一个zip对象,如 zip([1,2,3],[1,2])返回的值为<zip object at 0x00000127A34E1508>,其使用列表的形式为:[(1,1),(2,2)] |
| hash(obj) | 返回对象的obj的哈希值,相同值的对象的哈希值也相同 |
| help(func) | 返回内置函数func()的帮助信息 |
| isinstance(obj,type) | 判断对象obj是否是type类型,如isinstance(1,int)返回的值为Ture |
5.3 函数参数
函数参数是定义函数最重要的步骤之一,参数确定好,函数的接口定义便完成了。在调用函数时,只需要传入对应的参数。Python的函数可以有几种参数:普通参数、缺省参数、关键字参数、不定长参数。
5.3.1 普通参数
普通参数是一种常见的函数参数,它放置在紧跟函数名的一对英文括号中,并通过英文逗号分隔。函数的参数可以有一个或多个,也可以一个都没有。例子:
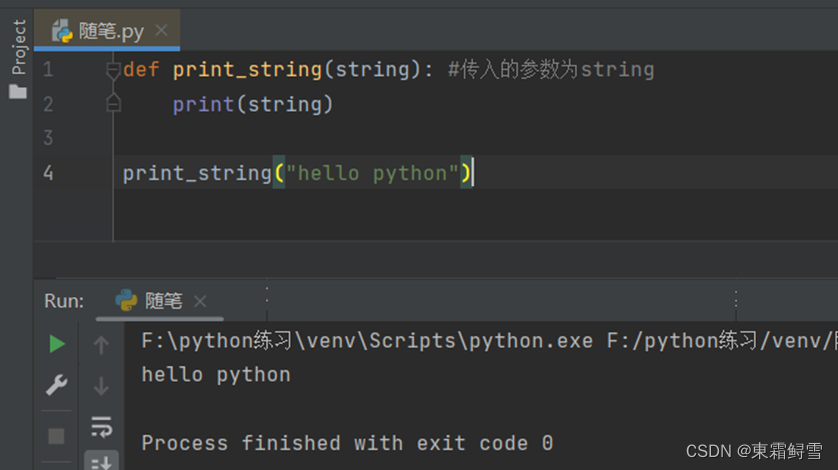
上述函数的功能是输出传入函数的字符串,其参数string就是一个普通参数,可以看到print_string()函数成功地将传入的字符串“hello python”输出了。
普通参数对应的值可以在函数内修改,但是其值只会在函数内修改,函数执行后其值并不会改变。例子:

上例中,变量num的值在执行modify_num()函数之前为1,执行modify_num()函数时为2,执行odify_num()函数后又变成了1.
函数还可以又多个普通参数。例子:

上述例子的程序功能是依次输出两个参数x、y 的和、差、积,其中x、y传入的值都为1.
注意的是,在传递多个普通参数时,函数定义了几个参数,调用时就必须传入几个值,否则会报错。例子:
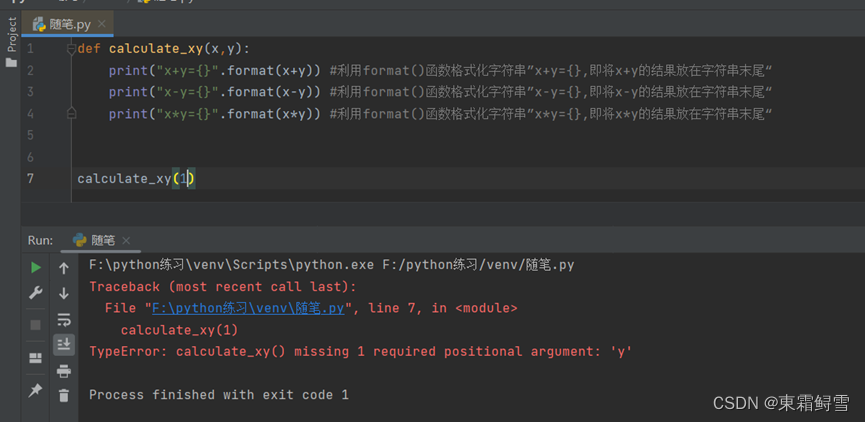
因此,在调用函数时务必按照定义函数时的参数的个数以及类型来传入值。
函数的参数还可以是另一个函数。因为在python里,一切皆对象,函数本身也是对象,所以函数也可以作为参数传入另一个函数并调用。例子:
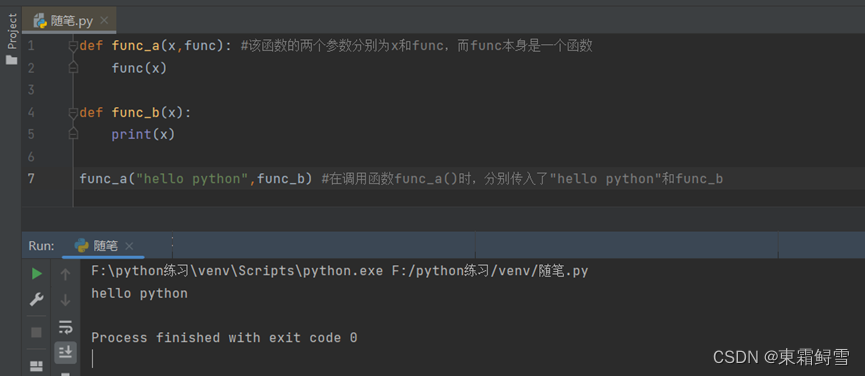
上例中,函数func_a()有两个参数:x和func。在调用函数func_a()时,分别传入了”hello python”和func_b,其中func_b为函数,当函数func_a()调用func()函数时,函数func_a() 将参数x传入了函数func_b(),最终输出了字符串“hello python“。
5.3.2 缺省参数
上面提到,普通函数在调用时要根据函数参数的个数传入值,但是这并不是必需的。在某些情况下,函数的参数还可以是缺省的,这里将这样的参数成为缺省参数。缺省参数的定义时直接在定义函数时,对其赋一个默认值。例子:
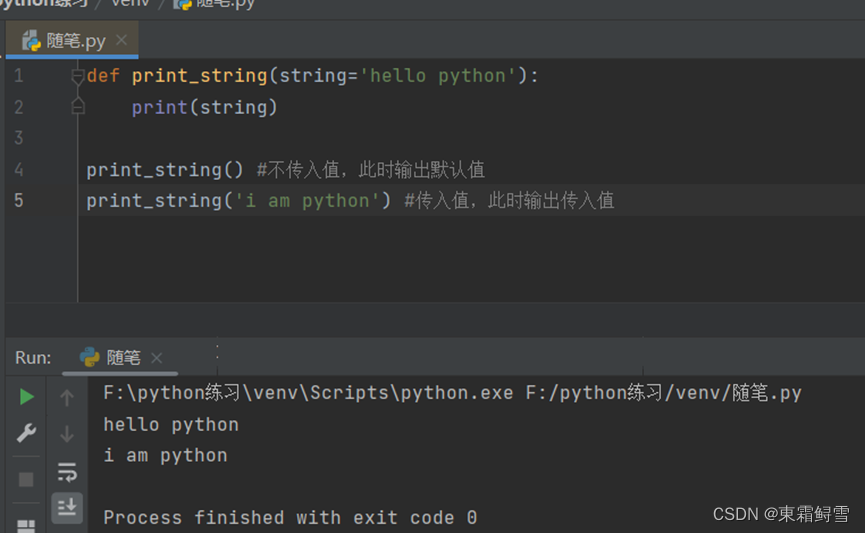
上例中可以看出,调用函数时,如果不传入值,函数会输出默认值,当有传入值,则输出传入值。
需要注意的是,如果一个函数的参数中含有缺省参数,则这个缺省参数后的所有参数都必须是缺省参数,否则程序将报错。例子:

5,3,3关键字参数
缺省参数在传入时必须遵守正确的顺序,就显得不是很灵活。关键字参数便能很好的解决这个问题。关键字参数允许函数调用时,参数的顺序与定义时的顺序不一致,这时因为python解释器能够用参数名匹配参数值。例子:
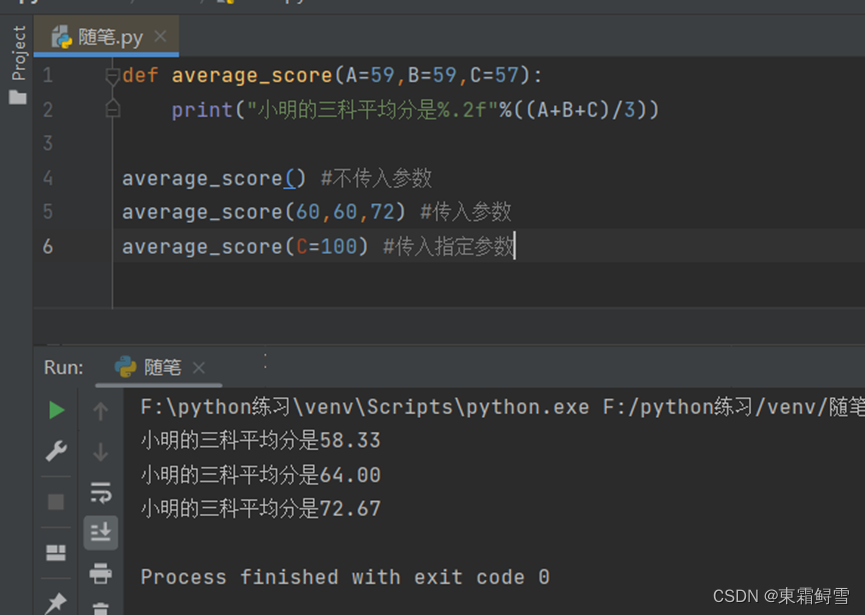
上例中,不传入参数时,函数使用默认值,传入所有参数时,使用传入的值,值传入其中一个参数的值时,则传入参数的参数使用传入值,其他参数使用默认值。
如果使用关键字参数,函数在调用时,传入的参数还可以不按照参数的顺序传入,例如上例中传入参数可以写成average_score(B=99,C=98,A=97)。
需要注意的是,在没指定参数默认值的情况下使用关键字参数时,调用函数仍然需要传入指定个数的参数。只有关键字参数和缺省参数搭配起来使用时,它的优点才能发挥出来。
5.2.4 不定长参数
前面所讲述的参数使用中,函数参数的个数都是已知的,而日常编程中可能还会遇到在调用函数时不知道函数参数个数的情况。与其他语言相比,python的优点在这里就体现出来了,它的函数的参数可以是不定长的。
Python中有两种使用不定长参数的方式,分别是在参数前加“*“和”**“。在参数前加”*“时,函数的参数传入是一个元组。例子:
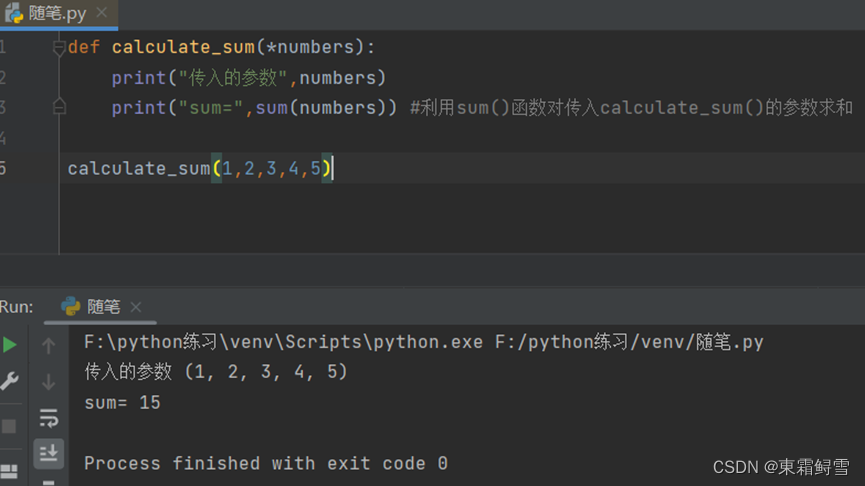
上例中,在调用calculate_sum()函数时,传入了5个参数:1、2、3、4、5.其在calculate_sum()函数内表现为一个元组。
在参数前面加”**”时,传入的参数是一个字典。这里传入的参数必须以关键字参数的形状表示。例子:

上例中可看到,调用函数时,同样传入了五个关键字参数:num1=1、num2=2、num3=3、num4=4、num5=5,其在print_kv()函数内表现为一个字典。
5.3.5 函数返回值
前面讲述的例子都是将参数处理后的结果直接输出。但在实际使用中,函数的结果常常以返回值的形式出现。Python3中的返回值有4中形式:None、一个值、多个值、yield语句。
- None
None是函数没有返回值时默认的返回值,其可以用在逻辑判断中,作用和False类似。例子:
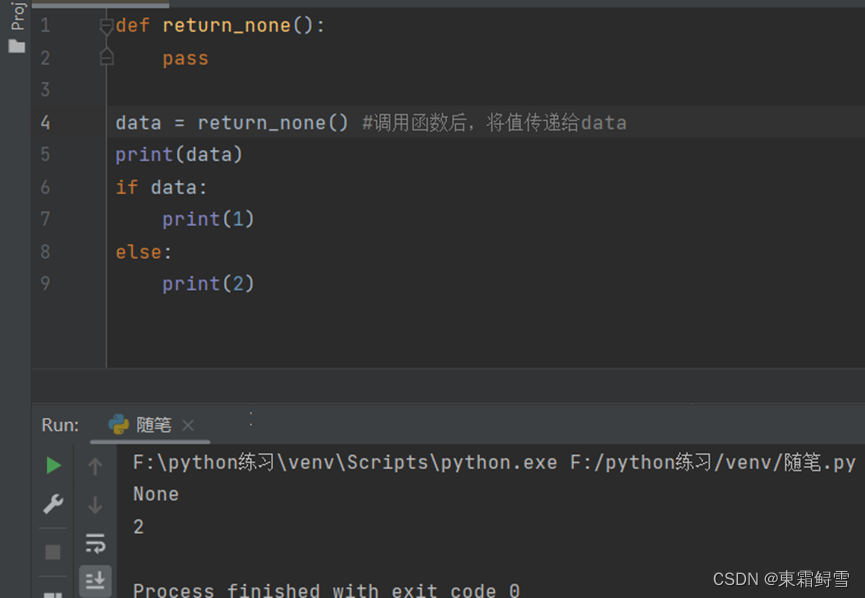
上例中,程序调用return_none()函数后,将其返回值None赋给了变量data,并用其进行逻辑判断,最终程序执行力else中的语句块。
- 一个值
返回一个值的函数是最常见的函数,expression可以为一个变量、常量或表达式。例子:

上例中,程序执行时,先调用了return_one()函数,并将返回值赋给了变量string,然后输出了return_one()函数的返回值“hello python“
- 多个值
和C语言、Java语言不同的是,python的函数可以有多个返回值。其语法规则如下:
return expression1,expression2,……
其中return为固定的关键字,expression1,expression2,……为多个返回值。
需要注意的是,return返回的多个值在调用的语句块处表现为一个元组,即当函数返回多个值时,等价于返回了一个元组。例子:
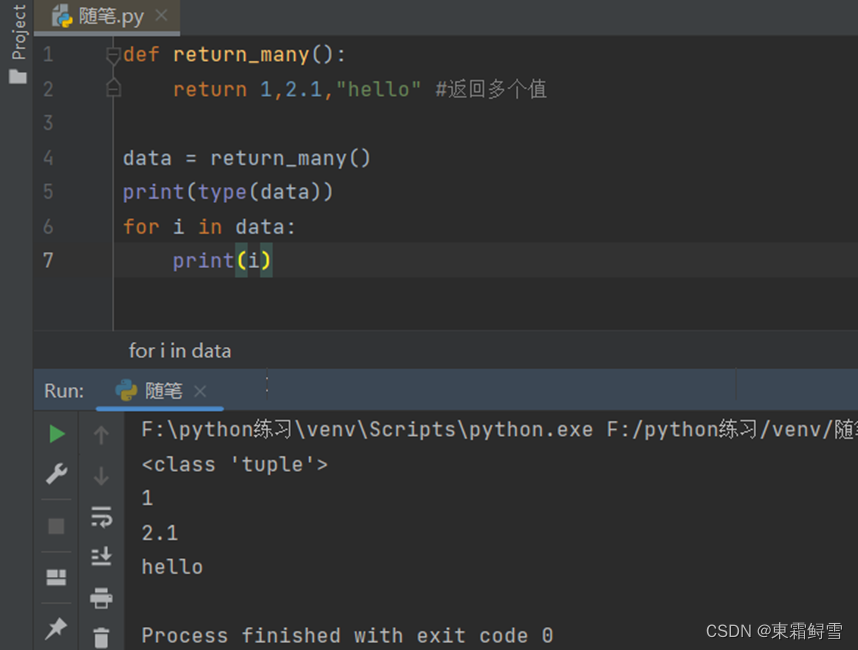
上例可以看出,return_many()函数返回的值为一个元组
- Yield语句
除了return语句外,python还有一种特殊的用于返回值的语句——yield语句。其语法规则与返回一个值的return语句类似。和return语句不同的是,yield语句返回的是一个迭代器对象,带有yield语句的函数在python中被称为生成器(generator)。例子:
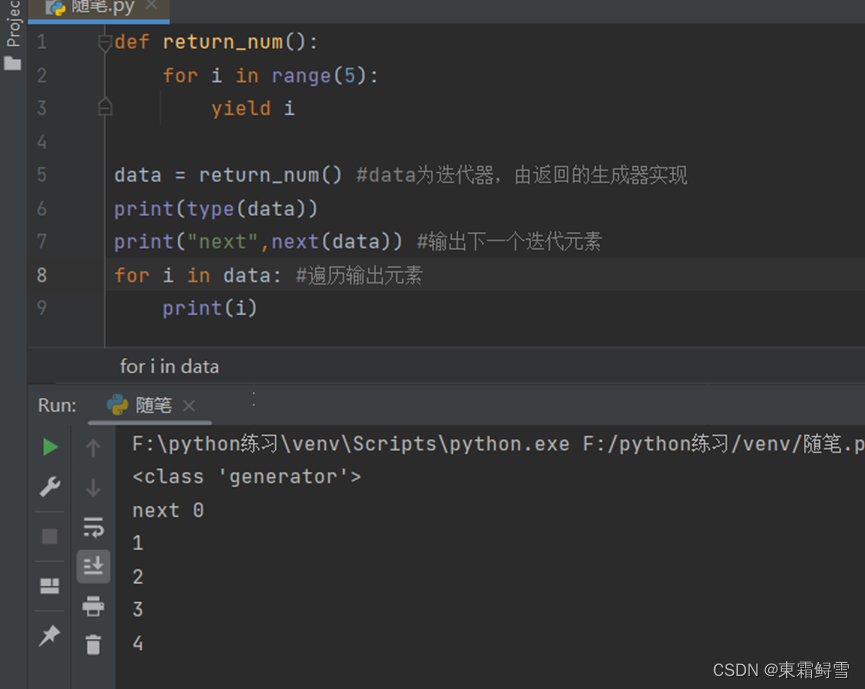
上例可看出。使用yield语句的函数,返回的是一个 generator对象。其中return_num()函数的功能类似下面这个函数:

使用上述方法虽然也可以达到类似的效果,但是当列表data的元素越来越多时,内存的消耗也会越来越大,这时就需要使用yield语句。使用yield语句可以极大地减小内存的消耗,这是因为yield语句返回的是一个迭代器对象。程序在遍历迭代器时,每次会从迭代器中读取一条数据,将其加载进内存,使用完数据就将其销毁,不会出现一次性将大量数据加载进内存、造成内存溢出的现象。因此,在处理大量数据时,如读取大文件时,应尽量使用yield语句来替代return语句。
5.4 高阶函数
高阶函数是python中特有的一种函数,常见的高阶函数由filter()、map()和reduce(),它们常和lambda表达式搭配使用。
5.4.1 filter()函数
在python中,filter()函数可以用来删除序列中的特定元素。其基本语法如下:
filter(func_name,seq)
其中func_name为自定义的函数名,seq为待过滤的序列。
func_name()的定义方式如下:
func_name(x):
函数体
return bool
其中,x为序列seq中的某个元素,函数体负责逻辑处理及判断,return bool表示函数必须返回一个布尔值,如果为True则保留x,否则不保留x。
filter()函数返回的是一个filter对象,为了使其能更直观地表示出来,通常需要使用list()函数将其转换成列表来处理。
使用filter()函数删除列表中的浮点数的示例如下:

filter()函数还可以用来删除列表中的None值。例子:
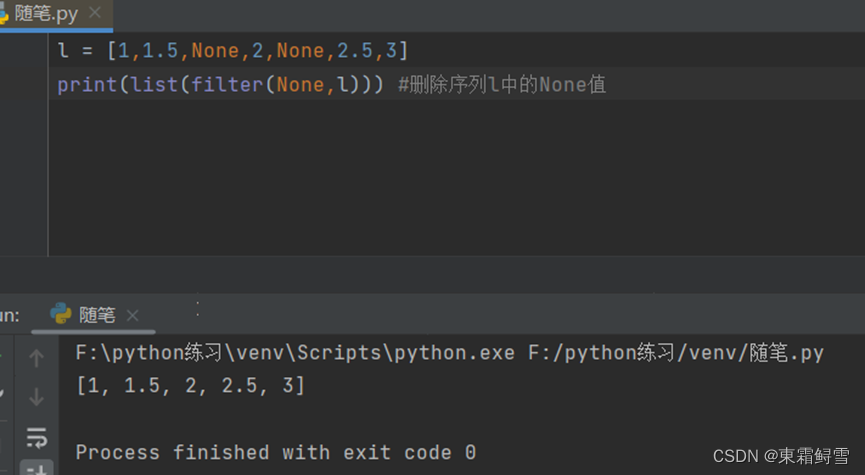
5.4.2 map()函数
在python中,map()函数可以对序列的每一个元素进行处理,生成一个新的序列。其基本语法如下:
map(func_name,seq)
其中func_name为自定义的函数名,seq为待处理的序列。
func_name()的定义方式如下:
func_name(x)
函数体
return new_x
其中x为序列seq中的某个元素,函数体负责逻辑处理及判断,return new_x表示函数返回的是一个新的值,用于替代原有的x。
下例为一个将列表元素自乘:
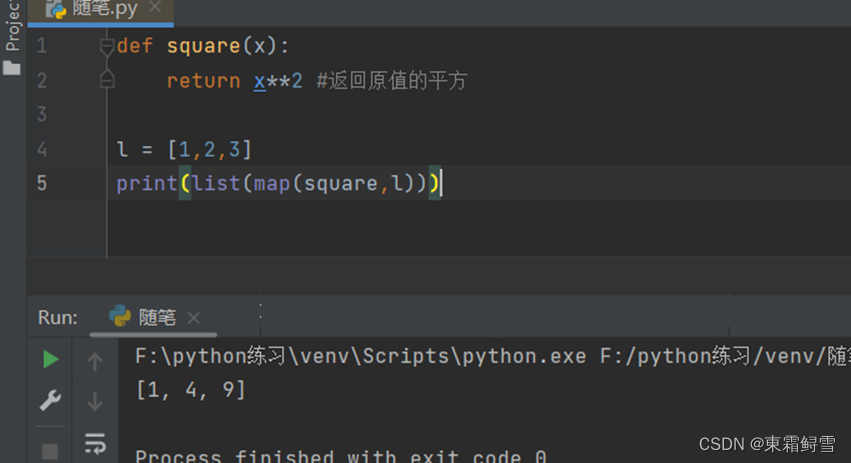
5.4.3 reduce()函数
在python中,reduce()函数可以对序列的值进行累积,其基本语法如下:
reduce(func_name,seq)
其中,func_name为自定义的函数名,seq为待累积的序列。
func_name()的定义方式如下:
func_name(x,y):
函数体
return expression
其中x为序列seq中的当前元素,y为序列中的下一个元素,函数体负责逻辑处理及判断,return expression表示函数返回的是一个表达式,用于累积结果。
需要注意的是,python3中的reduce()函数不是一个内置函数,需使用它必须从functools模块中引用。
下例为一个求列表中所有元素和:

5.4.4 lambda表达式
Python使用lambda表达式来创建匿名函数。匿名指不再使用def语句这样标准形式定义函数。Lambda表达式有以下特点:lambda只是一个表达式,函数体比def语句简单很多:lambda的主体是一个表达式,而不是一个语句块,仅能在lambda表达式中封装有限的逻辑:lambda表达式拥有自己的命名空间,且不能访问自己参数列表之外或全局命名空间里的参数:lambda表达式不等同于C或C++的内联函数,后者是为了在调用函数时不占用栈内存,从而提高执行效率。
lambda表达式的基本语法如下:
lambda *args:expression
其中*args为一个或多个函数参数,expression为函数的返回值。
lambda表达式又等价于以下代码:
def func(*args)
return expression
例子:
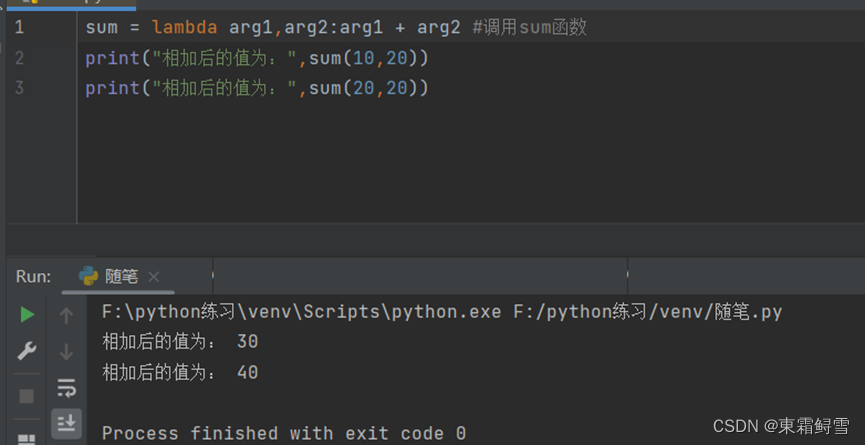
lambda表达式常和filter()、map()、reduce()3个高阶函数搭配在一起使用。例子:

5.5作用域
一个程序中的变量并不是在任意位置都可以访问的,变量的定义位置决定了其在程序中的访问权限。在python中,一个变量可以使用的范围称为这个变量的作用域。Python中的变量根据作用域来区分,可以分为局部变量和全局变量。
5.5.1局部变量
当一个函数的函数体定义变量时,程序在执行完函数后会将其回收,这里的变量就是一种局部变量,不仅在函数内的变量是局部变量,只要是有范围限定的变量都是局部变量。例子:
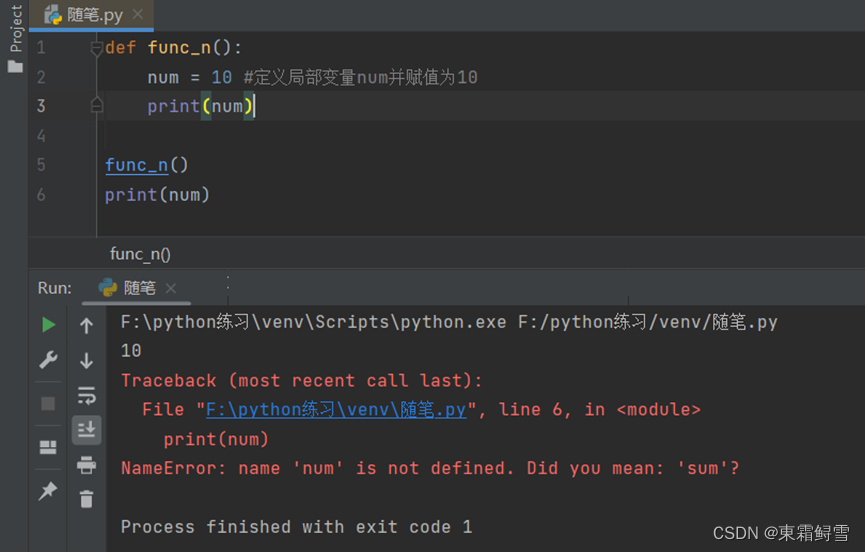
程序会先输入10再报错,提示变量num没有定义,是因为func() 函数内部的变量num是一个局部变量。
当一个参数传递给函数时,其对应的值在函数内改变,但并不会改变其函数外的值。例子:
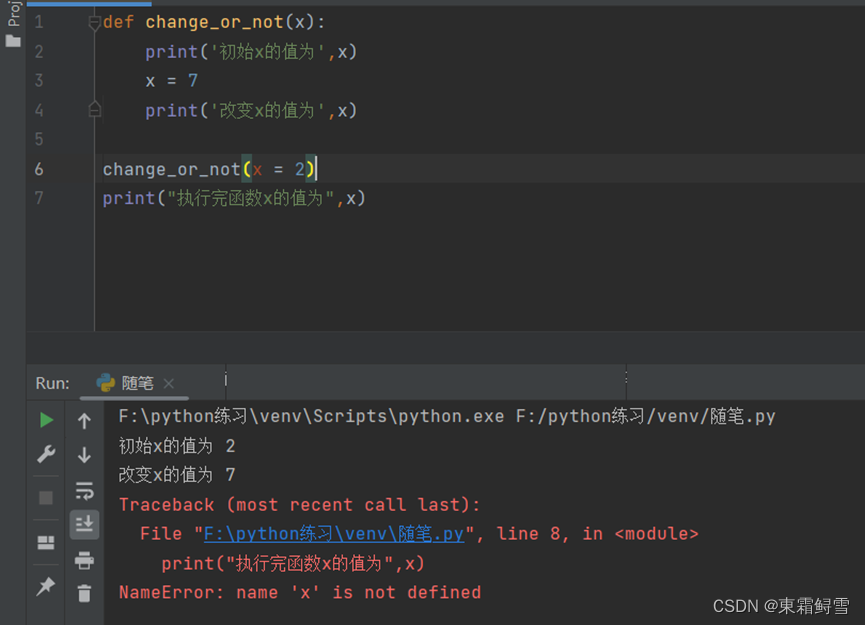
5.5.2 全局变量
局部变量会受到作用域的限制,无法随意访问;而与之相对应的全局变量可以在整个程序范围内被访问。Python的全局变量通常是定义在程序最外部的变量,其可以在整个文件中使用。例子:
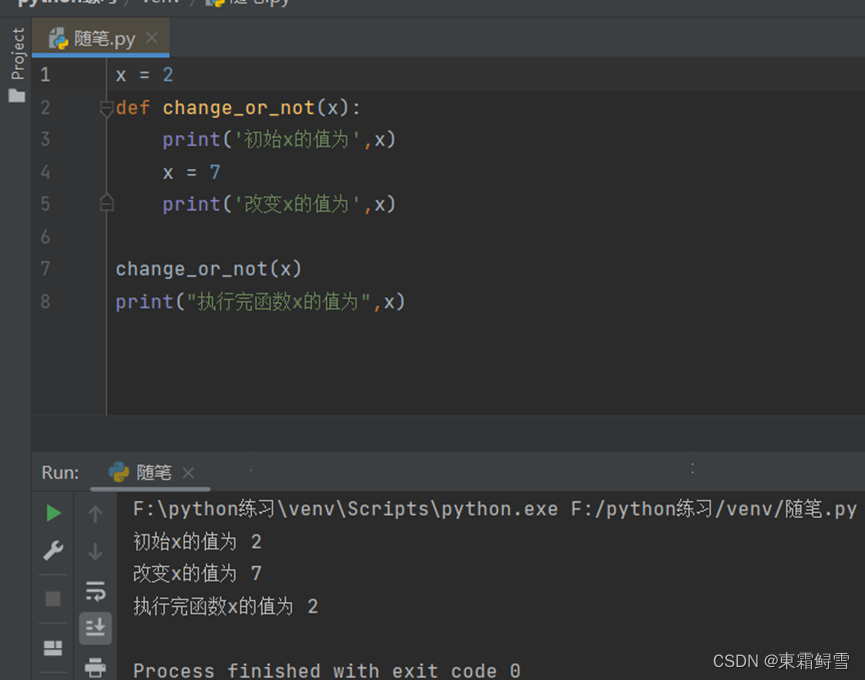
从上例可以看出变量x=2放在了函数的上面,也就是这个程序的最外部,此时的x就成了全局变量,函数内的x也使用此变量值2,而执行完后的变量x的值依然为2与函数内部的x=7毫无关联。
如果需要在函数中修改全局变量,必须先使用global关键字声明变量。例子:
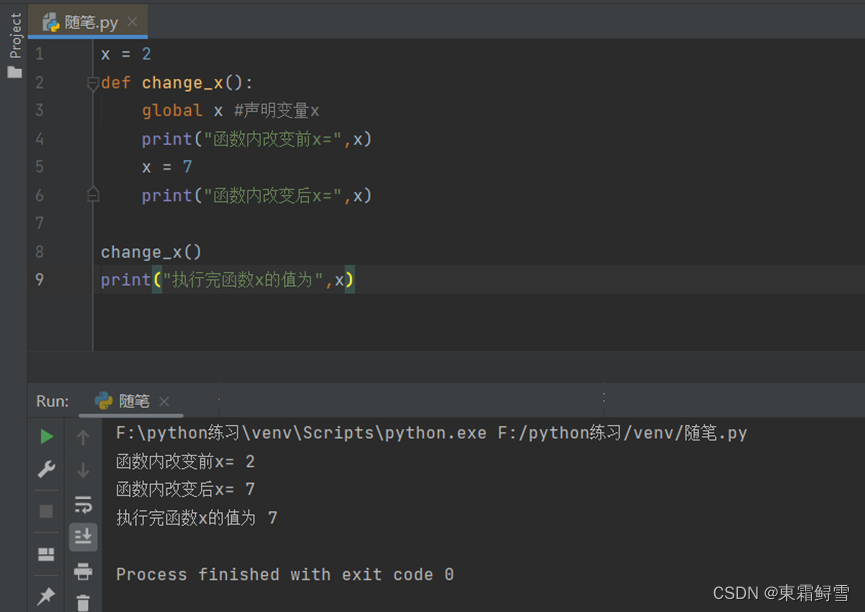
由此可以看出在函数内使用global关键字声明变量后,函数内部修改的变量值也会导致全局变量也跟着改变。
5.6模块
函数可以很好地解决代码复用的问题,但这仅针对是同一代码文件内的解决办法。当程序需要使用其他代码文件中的函数时,就需要使用模块。Python中的模块是处理一类问题的集合,它由一系列变量、函数和类组成。在某些地方,它也被称为库。
Python中的模块分为3种:内置模块、自定义模块和第三方模块。内置模块是python自带的模块,基本能满足日常的简单开发需求;自定义模块是用户自己编写的模块,它可以增强代码的可维护性和复用性;第三方模块是其他用户编写的开源模块,在使用之前必须先下载并安装它们。
5.6.1内置模块
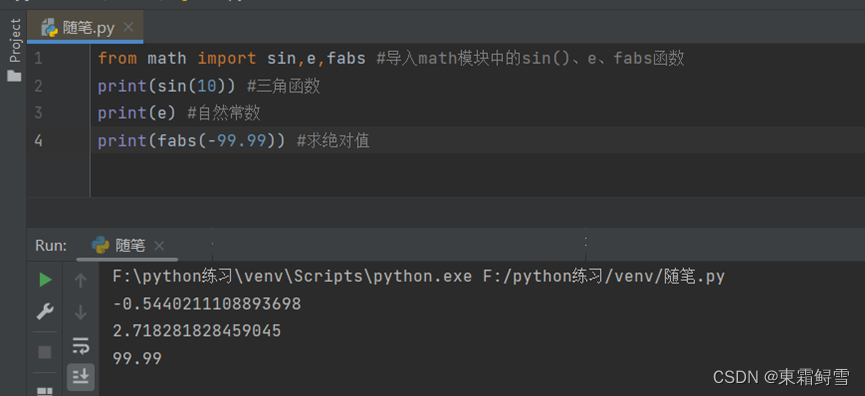
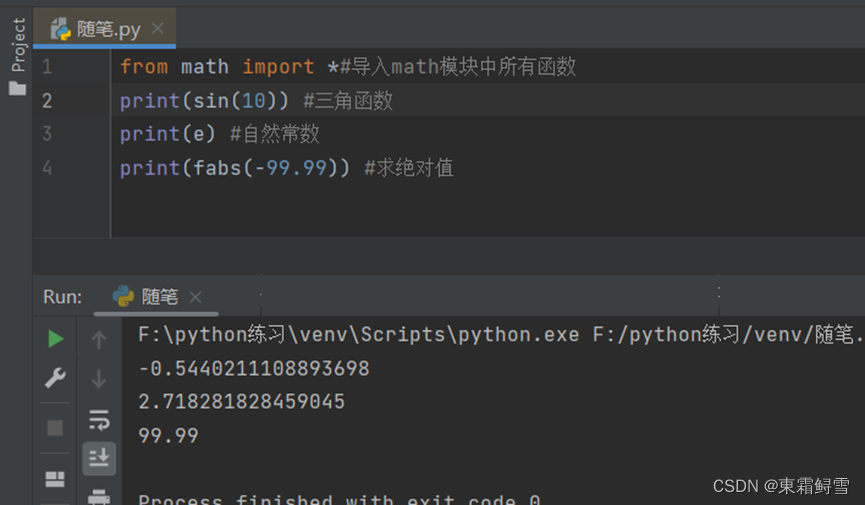
内置模块是python自带的模块,在使用它们之前导入即可,例如前面提到的math模块。当尝试直接调用三角函数sin()来计算弧度制对应的正弦值时,python会报错。例子:

会提示sin()函数未定义,这是因为sin()函数属于math模块,所以使用前需要先导入math模块。例子:

但是仍报错,这是因为sin()函数的使用方法不正确。单纯的使用import语句导入模块时,模块内的函数或变量需要以模块名为前缀来调用。这是为了保证安全而设计的,否则模块内的内容可能会与模块外的内容出现重复命名的问题。例子:

使用import语句导入模块后,使用模块中的函数之前,必须在函数名前加上模块名,如果希望每次使用这些函数时简单一些,可以使用另一种方式导入模块。例子:

可以看到只导入math模块中的sin()函数时,其他函数就会报错。
当一次需要导入一个模块中的多个函数时。例子:
或
当导入的模块中的函数名太长时,可以将长函数名简写。例子:

将sin()函数简写为了s,所以s(2)函数的值和sin(2)函数的值一样。
5.6.2 自定义模块
在编写程序时,我们还可以编写自己的模块,即自定义模块。Python自定义模块的导入分为相同文件夹导入和不同文件夹导入。
- 相同文件夹导入
相同文件夹导入模块是最简单的,直接使用“import 模块名”即可导入模块。如在当前目录下创建一个module.py文件。如下:
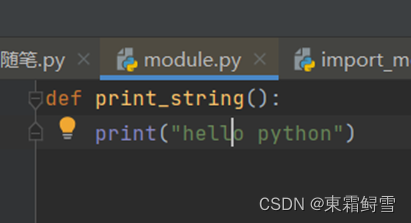
之后再在当前目录下创建一个import_module.py文件用于导入module模块。如下所示;
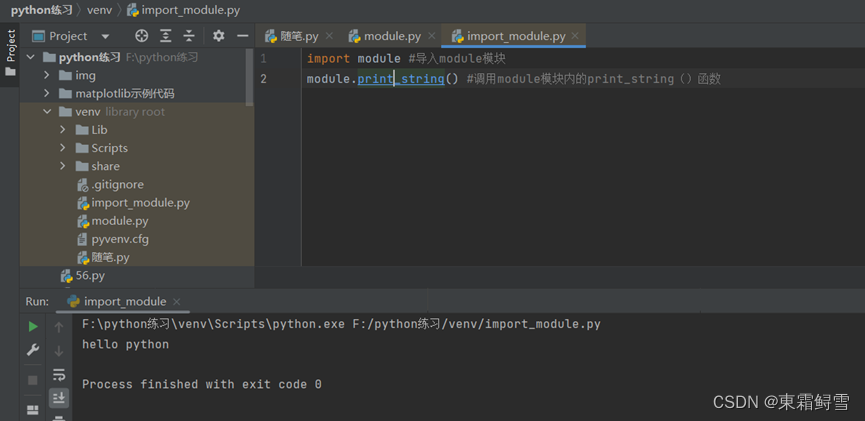
可以看到import_module.py成功导入了module.py中的print_string()函数。
在某些时候,导入的模块中可能含有和当前文件中的代码有冲突的代码。为了解决这个问题,可以将导入的模块中的冲突的代码用下列方法编写。
If __name__==”__main__”
语句块
上述的module.py文件可以改为如下形式。

import_module.py文件调整如下:

可以看到import_module.py文件在导入module模块时。执行了module模块中的print_string(‘module1.py’)语句,而没有执行print_string(‘module2.py’)语句。print_string(‘module2.py’)只有在直接运行module.py文件时才会执行。
- 不同文件夹导入
上面讲述的相同文件夹下导入模块的 情况并不是很常见。在很多时候,需要使用的是其他文件夹下的代码文件中的函数,这时就需要使用不同文件夹下导入模块的方法。

例如我把import_module.py移动到了python练习文件夹下,而module.py在python练习文件夹中的venv文件夹内。
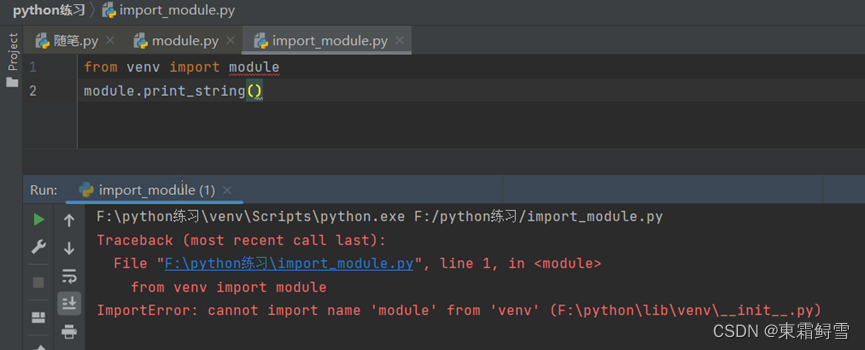
这时候会报错显示不能导入模块module。这是因为此时的venv文件夹中的module模块还不是一个对外开放的模块,如需使用模块,必须在venv目录下创建一个内容为空的__init__.py文件,用于初始化模块。
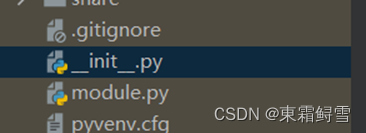

此时再运行import_module.py文件就可以输出了。
5.6.3 安装第三方模块
对于Linux和macos用户而言,安装第三方模块比较轻松。库是相关功能模块的集合,所以只需要知道第三方库的名字,在终端中使用命令“pip3 install”紧接库名即可安装第三方库(python2中使用”pip install”)。例子:

6.文件I/O
前面所讲述的例子都是在程序执行完之后就销毁了所有的数据,程序在下次执行时无法使用上次执行时的数据。而在实际编程中,经常需要将程序中的数据保存在文件中,供下次执行时调用。文件I/O即文件的输入(input)和输出(output),就是向文件里写数据和从文件里读数据。颇有通红拥有一套相对完整的操作文件的应用程序接口。
6.1文件路径
无论是Linux操作系统、macOS还是Windows操作系统,文件总有一个“归属地”这里将其称为文件路径。有了文件路径,便可以定位文件。颇有通红能够识别两种文件路径:绝对路径和相对路径。
6.1.1绝对路径
绝对路劲是指文件在硬盘上从根目录开始的完整路径,它简单易懂,用户基本上不需要其他任何信息就可以根据绝对路径判断出文件的位置。
在Windows操作系统中,绝对路径的表示方式是从盼复开始的。例子:

盘符与冒号后的部分以符号“\”作为分隔,每一个分隔符号前后的两个文件夹(或文件)存在包含关系,如文件夹venv放在python练习中,而文件随笔.py放在文件夹 venv中。需要注意的是,当使用Windows操作系统编写python代码时,绝对路径的分隔符应尽量使用“\\”,否则可能出现找不到文件的错误。
在Linux操作系统中,绝对路劲是从根目录开始的,例如:/usr/local/mysql
Linux操作系统的文件路径分隔符使用的是“/”而不是“\”,第一个符号“/”表示根目录,Linux操作系统的文件结构更像是一棵树,根目录代表整个Linux操作系统的最顶层,在上例中,usr文件夹与根目录直接相连,而文件夹local则与文件夹usr直接相连,与根目录间接相连。根目录就像是树根,文件夹usr是树根的子树,而文件夹local是树根的子树的子树。这里的mysql是一个文件,它在绝对路径末尾,就像是一棵树的末端。
绝对路径能在一定程度上影响python程序的可移植性。因为同一文件在不同的计算机操作系统中可能路径不相同,要使程序能在不同的计算机操作系统上运行,就必须修改绝对路径的位置。因此绝对路径在编程中不常见。
6.1.2相对路径
与绝对枯井对应的是相对路径,相对路径更像是一种路径关系。它表示文件相对于当前所在路径的位置。在使用相对路径之前,需要先知道python中相对路径的如下两种表示方式。
(1)“./“表示当前所在的路径
(2)“../“表示当前所在路径的上一层路径
假设文件test.py当前的绝对路径为D:\test\test.py
则其目录树表示如下:

在test.py文件中访问file_1.txt可以使用如下相对路径。
./file_1.txt
访问file_2.txt可以使用如下相对路径。
../file_2.txt
在python中使用相对路径时,没有具体的脚本文件目录作为当前位置参照,就相当于使用python解释器的当前目录(默认是打开python解释器的路径)。如果需要查看当前程序所在路径,可以使用os模块中的getcwd()函数。例子:

另外,在不同的操作系统中文件路径的分隔符是不同的,编写需要在多个操作系统上运行的程序时,尤其需要注意这个问题。在python中可以使用os模块中的os.sep属性来获取当前操作系统的文件路径分隔符。例子:
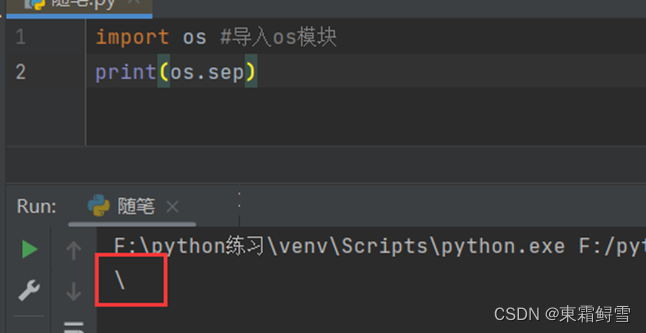
在实际编程中,相对路径比绝对路径更有优势,使用相对路径的程序有很好的可移植性。
6.2文件打开和关系
Python在读取文件时必须执行打开文件和关闭文件的操作。只有打开文件之后才能对文件内容进行读取,读取后必须将文件关闭,否则会出现其他程序无法访问该文件的情况。
6.2.1 open()函数
Python中打开文件用open()函数,其定义如下:
file = open(file_name,mode = r,encoding = ‘cp936’)
其中file为打开的文件对象,后续对文件的操作都需要使用它;file_name为文件名;ode为文件访问模式;encoding为读/写文件时的编码,其在Windows操作系统中默认值为cp936,即GB2312编码方式,常用编码方式还有UTF-8、GBK、ASCII等。下表为文件访问模式。
| 访问模式 | 说明 |
| r | 以只读方式打开文件,文件的指针将会放在文件的开头,为文件打开的默认方式 |
| r+ | 以读/写方式打开文件,文件指针将会放在文件的开头 |
| rb | 以二进制格式打开一个文件,用于只读,文件指针将会放在文件的开头 |
| rb+ | 以二进制格式打开一个文件,用于读/写,文件指针将会放在文件的开头 |
| w | 以只写方式打开文件,如果文件存在则从头开始写文件,原有内容会被删除;如果文件不存在则创建文件 |
| w+ | 以读/写方式打开文件,如果文件存在则从头开始写文件,原有内容会被删除;如果文件不存在则创建文件 |
| wb | 以二进制格式打开一个文件,用于只写,如果文件存在则从头开始写文件,原有内容会被删除;如果文件不存在则创建文件 |
| wb+ | 以二进制格式打开一个文件,用于读/写,如果文件存在则从头开始写文件,原有内容会被删除;如果文件不存在则创建文件 |
| a | 打开一个文件,用于向文件末尾追加数据,如果文件不存在则创建文件 |
| a+ | 打开一个文件,用于读数据和向文件末尾追加数据,如果文件不存在则创建文件 |
| ab | 以二进制打开一个文件,用于向文件末尾追加数据,如果文件不存在则创建文件 |
| ab+ | 以二进制格式打开一个文件,用于读数据和向文件末尾追加数据,如果文件不存在则创建文件 |
有打开文件就有关闭文件。在python中,关闭一个文件只需要调用file对象的close()函数,如下:
file.close() #关闭文件
需要注意的是,在程序未结束且未关闭文件时,其他程序不能对当前被读/写的文件进行操作。
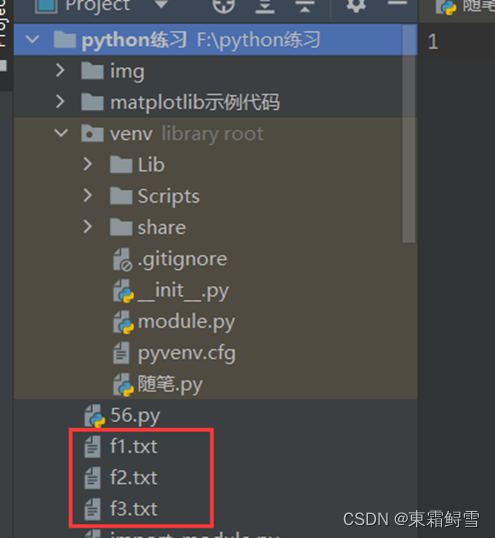
例如我在python练习文件夹里创建了f1.txt、f2.txt、f3.txt三个文件。我在python练习文件夹中的venv中的随笔.py中打开这三个文件:
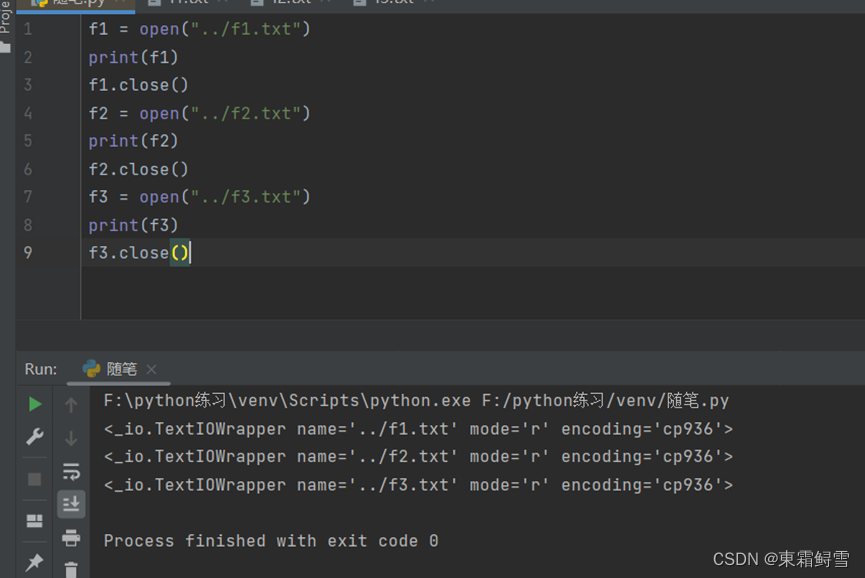
可以看到程序成功的打开和关闭了文件f1.txt、f2.txt、f3.txt,并输出了文件的打开信息。
6.2.2 with open
除了open()函数,在python中还有一种更具特色的方式打开文件,其语法格式如下:
with open(file_name,mode = r,encoding = ‘cp936’) as file:
<语句块>
其中,with和as为固定的关键字,open后括号中参数的作用同上述讲的open()函数参数作用基本一致。
与open()函数相比,使用with open 方式打开文件更加可靠,因为它会在文件打开出错时自动关闭文件。例子:

上述程序如果使用open()函数实现,则为如下形式:

6.3 读文件
在学会打开和关闭文件之后,就可以对文件内容进行读取了。Python为文件提供了一些以便用户对文件进行读取。
6.3.1 read()函数
read()函数能够一次性读取文件的全部内容。当以访问模式r打开文件时,read()函数会从头开始读取文件内容,直到文件结束。Read()函数将读取的文件内容以一个字符串对象的形式保存在内存中,并将其作为返回值返回。
为方便读取内容,下面读取的文件依然为f1.txt、f2,txt、f3.txt,在f1.txt中写入一些内容

接着进行读取内容:

上例调用了file对象的read()函数读取文件中的所有内容,并将这些内容输出,可以发现输出内容与f1.txt文件中存放的内容完全一致。
虽然read()函数简单快捷,但有时并不需要读取文件的全部内容,又或者是文件实在太大,全部读取会超出计算机的内存上限(read()函数读取的内容都将存放在内存中)。考虑到这一问题,read()函数还设置了一个size参数,表示一次从文件中读取的字节数。当用户只想读取f1.txt文件的部分内容时,就可以利用这个size参数。例如从f1.txt文件中一次性读取6字节数的内容:

在计算机中1英文字符占1字节,1空格符也占1字节。所以程序最终输出了6个字符。注意的是,在python中换行符也占1字节,因此在按字节数读取文件时必须要考虑到换行符的问题。
给read()函数一个复数作为参数,它会读取文件的所有内容,与直接read()效果是一样的:

需要注意,在读取文件时应尽量使用异常处理监听错误,否则文件可能无法正常关闭。
6.3.2 readline()函数
虽然read()函数配合其参数使用可以读取指定字节数的文件内容,但在不知道文件内容的情况下,很难准确的通过字节数读取想要的文件内容。于是python提供了一种更便捷的文件读取操作:readline()函数。Readline()函数一次性仅返回文件的一行内容。例子:

上述程序调用了readline()函数读取f1.txt文件中的第一行内容,由于读取的内容本身带有换行符,print语句在输出内容时又会自动添加一个换行符,最终输出了两个换行符。
有时候,我们需要的是文件中的全部内容而不是一行内容,因此在python中还可以使用for循环遍历获取文件中的内容,每遍历一次就输出一行内容。例子:
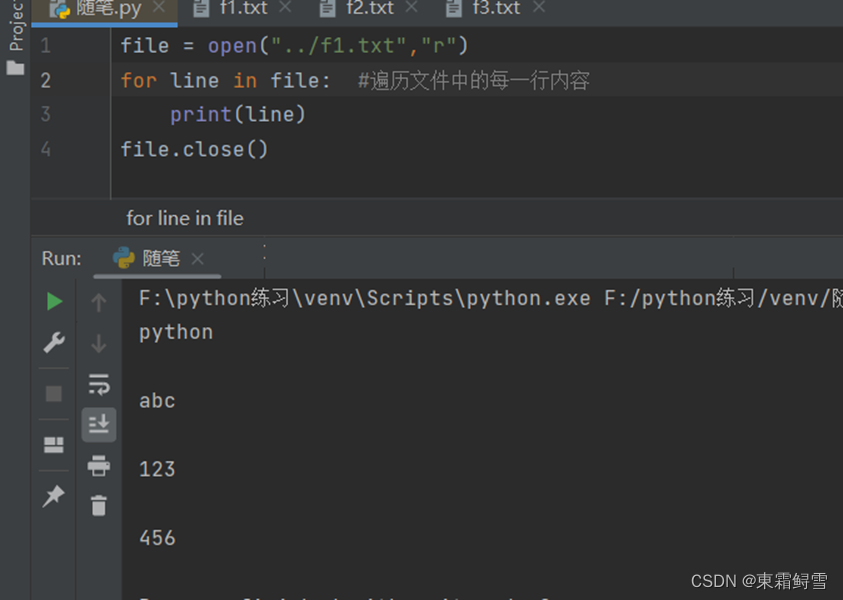
上述函数在实际编程中经常会用到,因为它将文件内容当作一个序列来遍历,程序可直接从序列中读取文件中的内容。
6.3.3 readlines()函数
readlines()函数一次性只能读取一行内容,python还提供了一个一次性读取多行内容的函数——readlines()函数。readlines()函数能够逐行读取文件中的内容,直到文件末尾,并将读取到的内容以列表的形式返回。列表的一个元素为文件中的一行内容。例子:
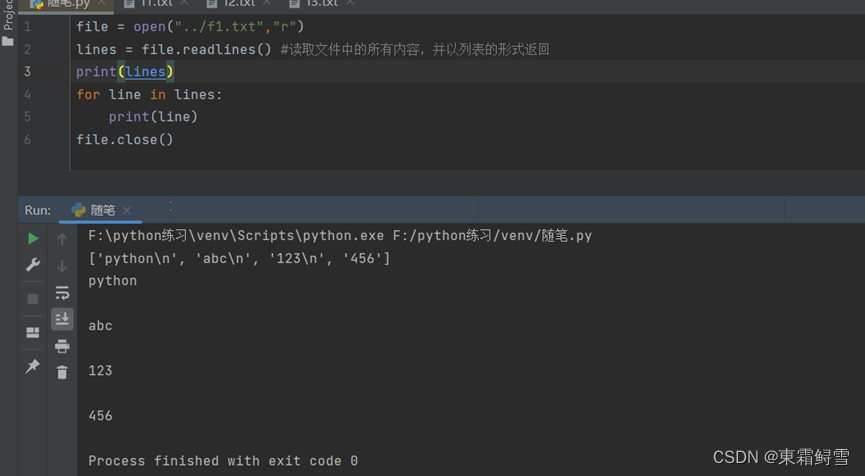
可以看到,readline()函数读取文件时确实是一次性读取文件中的所有内容,并将文件中的每一行内容封装成列表后返回。
6.3.4 大文件读取
读取大文件是一个很难处理的问题,python提供了一个读取大文件的工具——yield生成器。例子:
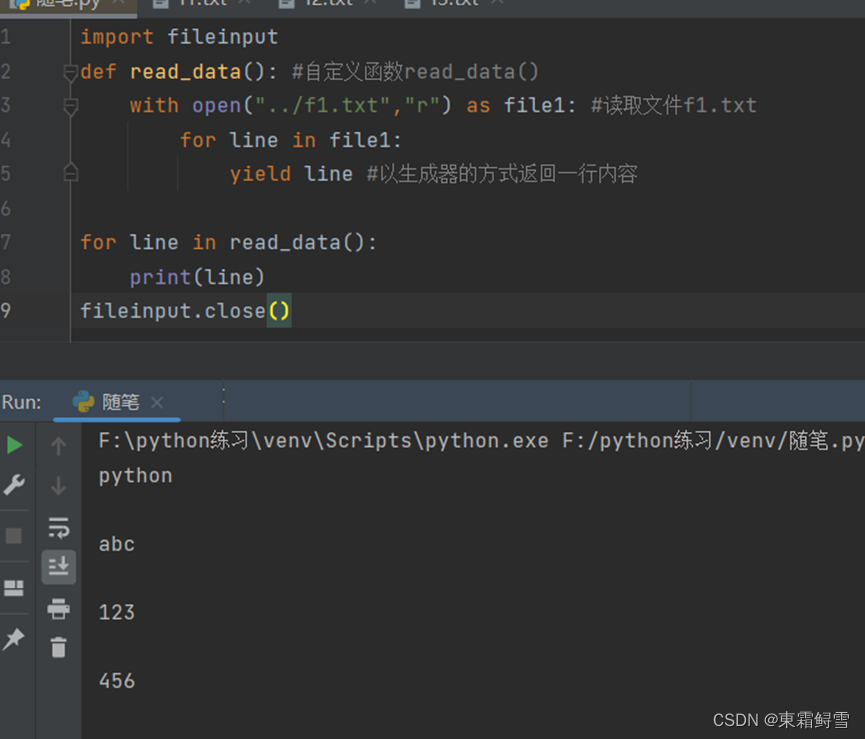
上例中read_data()函数的功能是一次性读取文件的所有内容,并以生成器的方式返回每一行内容,供主程序调用。最终程序输出了f1.txt文件中的所有内容。该函数类似于以下函数:

使用read_data_list()函数读取文件的结果和使用read_data()函数读取文件的结果是类似的,他们的区别就是read_data()函数可以用来读取大文件。比如读取一个比计算机内存容量还大的文件,read_data()函数在遍历时使用的是遍历一次将一行内容加载到内存中的方法;read_data_list()函数则会将文件的所有内容加载到内存中,由于文件过大可能会造成系统内存溢出。
6.3.5 文件指针
上述讲解的readline()函数十分便捷,不过它有个问题,既然readline()函数只读取第一行文件内容,那么python如何确定用户需要返回哪一行的内容?
这就引入了一个新名字——文件指针,访问模式“r”代表从头开始读取文件,python能够正确找到文件开始的位置,一定是根据某种位置标记判断的,这种标记就是文件指针,在使用访问模式“r”创建文件对象后,文件指针便指向文件内容的起始位置,于是当文件对象第一次使用readline()函数时,文件指针就为readline()函数指明了正确的起始位置。而调用了readline()函数后,文件指针便会更新自身位置,由于readline()函数的作用是读取一行文本内容,那么就很容推断出文件指针更新到下一行。当文件指针更新到文件末尾时,如果想要再次从头读取文件内容,可以使用seek()函数将文件指针重置到文件起始位置。例子:
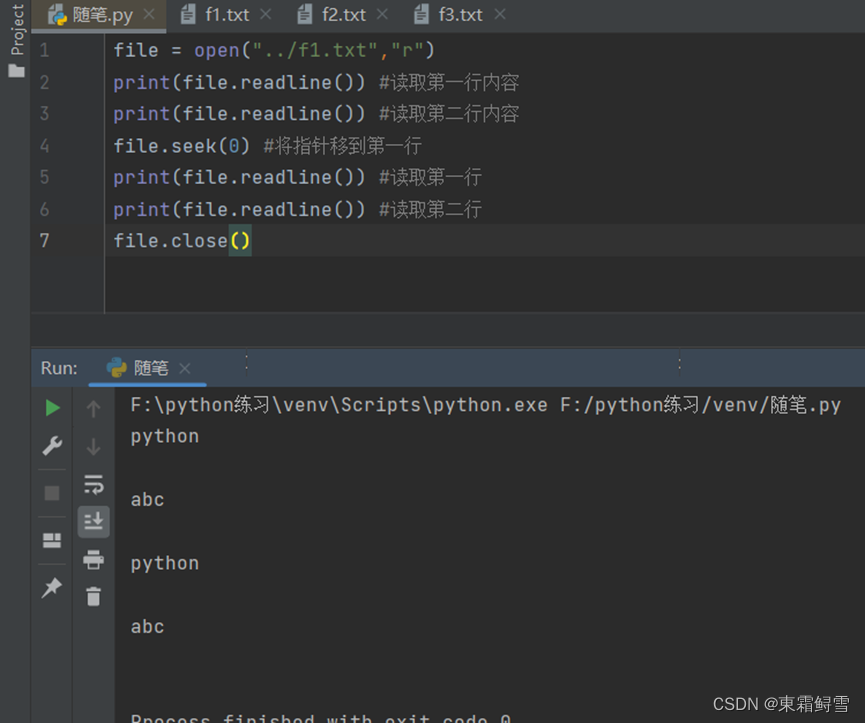
向seek()函数中的传入参数0,文件指针移到第一行。其参数代表着文件内容的初始位置开始所移动的字节数,这个参数必须是一个整数。seek()函数将文件指针重置到与文件起始位置距离参数值个字节的地方,所以参数为0就是将文件指针重置到与文件起始位置距离0个字节的地方也就是开头。再次调用readline()函数就从当前文件指针位置开始读取文件内容。
6.4 写文件
6.4.1 覆盖写
覆盖写的访问模式为“w”,前面讲述的一张表中对访问模式“w“的定义为”以只写方式打开文件,如果文件存在则从头开始写文件,原有内容会被删除;如果文件不存在则创建文件。从定义可以看出,“w”访问模式有一个数据的安全隐患:当使用访问模式“w”创建文件对象后,即使打开文件后不做任何操作就关闭文件,文件内容也会被清空。
下例为覆盖写f1.txt文件,覆盖写内容为hello:
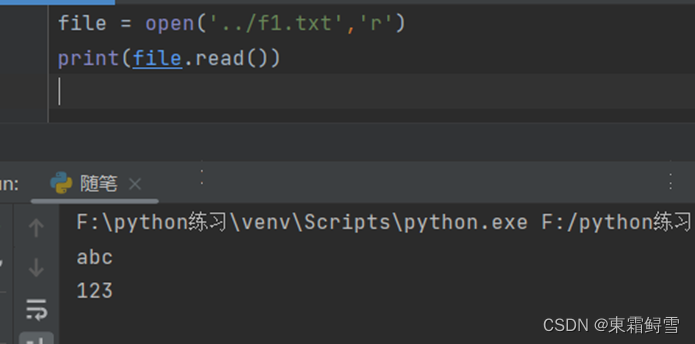
f1.txt中原有内容如上,覆盖写后如下:


原有内容被删除,新输入的hello存在。
6.4.2 追加写
覆盖写在很多时候并不会用到,因为会将原有内容给删除掉,在日常编程中用到的是以追加写的方式写文件。追加写的访问模式为“a”,上面那张表中对访问模式“a”定义为:打开一个文件,用于向文件末尾追加数据,如果文件不存在则创建文件。以上面的f1.txt为例。向文件末尾追加“hello python”和“hello”:


可以看到原有内容并没有被删除而是在末尾追加写了两行内容,注意的是,若是要写入多行内容,务必在分行的前面一起输入“\n”换行符,否则输入的内容全在一行。
7.面向对象编程
7.1 什么是类与对象
类就相当于键盘,键盘有很多种,机械键盘、薄膜键盘等,以及键盘的颜色,形状等属性。这些不同种类属性的键盘就是一个类。类是用来描述具有相同属性和方法的对象的集合,它定义了该集合中每个对象所共有的属性的方法。也就是说类只负责定义这些属性和方法;而对象实际上是类的一个实例:一个类可以引申出多个不同的对象,而每个对象为类所定义的内容赋予各自的值。同一个类的各个对象看起来十分相似,实际上却各不相同。
7.2 使用类与对象
上面7.1已经讲述了类与对象之间的关系。根据此关系,进行面向对象编程时,首先需要创建类,然后通过这个类来创建真正的对象。
创建类需要使用关键字“class”,例子:

7.2.1 类方法
由一个类创建的对象具有相同的方法,可以在keyboard类中添加一些函数,这些函数就是对象的方法。
无论键盘的属性有多少不同,但是都有满足人们打字需求的功能,所以,定义的type()方法属于每一个有keyboard类创建的对象。例子:
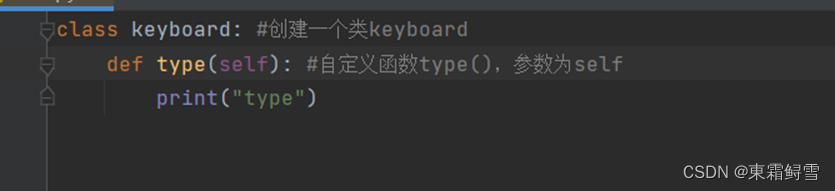
type()方法中带有一个self参数,然而在方法中并没有使用到它,这就是类中定义的方法与一般方法的不同之处,类方法拥有一个额外的参数变量self,这个参数是指类创建的对象本身。只需暂时记住,在python中定义类方法时,都应该将self设置为第一个参数就行。
虽然类方法是通用的,但是属性不是。人都可以做很多相同的事情,但是世界上找不出两个一摸一样的人。即使是双胞胎,它们有很多共同之处,也一定有各自的特殊之处,作为python的对象也是如此。例如每个键盘的颜色、重量不可能完全相同,但是每个键盘在出厂时的使用时间一定为0。像键盘出场时间这样无差别的对象属性称为类变量,而每个键盘特有的颜色、重量等对象属性被称为实例变量,因为它们仅描述了单个具体对象的属性。
7.2.2 类变量
定义类变量的方式类似函数定义局部变量。例子:

由于类变量是共享的,上述例子中的useage_time可以属于keyboard类的所有对象访问,并且它只拥有一个副本,所以只要任何一个对象对类变量做出改变,所有keyboard类对象中的类变量都会改变。
7.2.3 类的实例——对象
在下面的内容中,我们将由类创建出来的具体对象称为对象实例,它既是一个对象,也是类的一个实例。
创建一个对象实例可以采用如下方法:

其中keyboard1和keyboard2分别代表了两个不同的对象实例,它们都是由keyboard类实例化得来的,就目前的设计来看,这两个对象实例具有相同的类方法。无论类有多么复杂,实例化后的对象实例都具有相同的类变量和类方法。
调用一个对象实例的类变量和类方法需要使用点运算符。例子:
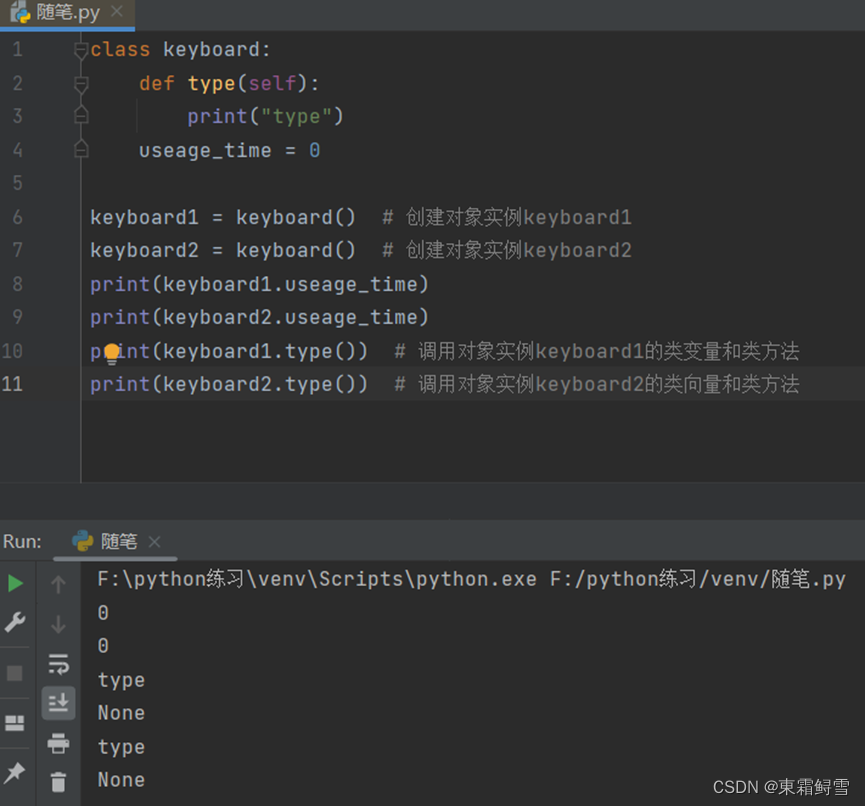
7.2.4 实例变量
对象之间的差异性,需要由实例变量来体现。在实际应用中,可以将实例变量分为两种。
1.第一种实例变量
第一种实例变量用于在类中的定义共同的属性,然后对每一个对象实例的属性分别赋值。
使用python在描述键盘的颜色时,采用类变量当然不行。虽然每一个键盘的颜色都属于“颜色”这一属性,但是键盘的颜色不可能是一成不变的,于是现在我们需要键盘类有“颜色”这个属性,但不能像类变量那样直接为其赋予具体的颜色。
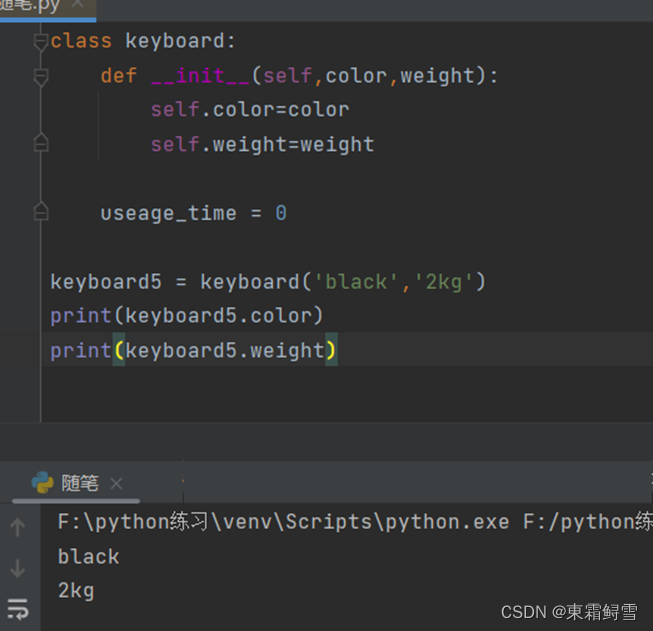
为实现这个功能,需要使用特定的方法:__init__()方法。Init前后各有两条下画线,总共是四条下画线。取自英文单字“initializing”,表示初始化,这个方法会在类创建对象实例时率先执行,而且是自动执行,无须用户调用。所以通常将它写在类的起始位置。例子:

如上例,使用类创建对象实例的时候可以给变量赋值。所创建的keyboard3和keyboard4都没有出现错误,并且注意,为他们传递的参数是__init__()方法的第二个参数color,并不需要为对象实例传递self参数。self参数参数代表当前的对象实例,那么在__init__()方法中出现的self.color就可以理解为当前对象实例的color变量,而等号之后的color代表的是__init__()方法的color参数。所以对于keyboard3实例而言,创建时将字符串black作为参数传递给 __init__()方法,然后将参数值black传递给keyboard3自身的实例变量color。
既然实例变量是每个对象实例特有的,若不使用self约束,那么python如何确定变量color属于哪一个对象实例。若不区分每个实例变量所属的对象实例,那实例变量就和类变量没有区别了。
以keyboard4对象实例的创建过程为例,在创建对象实例时自动调用__init__()方法,字符串red作为参数值传递给keyboard4对象实例的实例变量color。至此,使用__init__()方法初始化对象实例的实例变量过程结束。测试对象实例中的类变量、实例变量和类方法是否和预期一样:

实际情况中,一个对象实例可以拥有不止一个实例变量,所以__init__()方法也可以拥有不止一个参数。例子:
使用__init__()方法的目的在于初始化属性,这些属性都是类中所有对象实例所拥有的,但其实际值不同,正如每个键盘都有颜色属性,但并不是所有键盘都有相同的颜色。所以一旦使用__init__()方法定义了实际变量,那么在创建对象实例时就必须传递相应的参数,否则python将会给出参数缺失的错误提示。
2.第二种实例变量
第一种实例变量用于描述同一个类的对象实例都具有的属性,而这些属性的实际值对于每个对象而言又是不同的;而类变量用于描述同一个类的对象实例具有的共同的属性,并且所有对象实例拥有相同的属性值。
再以键盘keyboard为例,具有灯光特效,按键音效的键盘并不是每一个键盘都带有这些属性,这些属性既然不能作为类变量,那么它们只有可能是实例变量。若使用__init__()方法初始化这些实例变量,那么一旦要定义不带这些功能的键盘对象实例,由于不传递相应的参数,python就会报错误信息。所以这些属性虽然是实例变量,但是并不能使用__init__()方法初始化。这便是第二种实例变量。
第二种实例变量会在创建对象实例之后,使用对象实例名和点运算符为实例变量指明归属对象实例,而实例变量的值可以直接传递。例子:

虽然上述两种实例变量的定义方法有所不同,但由于实例变量的作用范围是在对象实例内部,所以无论使用哪一种方法定义变量,都不会影响其他对象实例的实例变量。需要注意的是,只要不是每个对象实例都具备的属性,就不应在类中使用__init__()方法定义,而是应该在对象实例创建后单独定义,否则那些没有该属性的对象实例就无法正常创建。
7.2.5 再谈self参数
除了在__init__()方法使用self参数,前面所定义的type()方法也同样使用了它。实际上,所有类方法都应当设置这个参数,并且无须在调用时为它赋值。Self参数代表当前对象实例本身,所以在各种自定义的类方法中,它也能发挥作用。例子:

上面的程序重新设计了keyboard类,为其新增了一个describe()方法,与type()方法类似,它也只有唯一的参数——self。实例变量color和weight的值都是在创建对象实例时传递的,每一个对象实例都拥有各自的实例变量color和weight,对象实例之间的实例变量是独立不相关的。在describe()方法中,self参数指明了color和weight属于当前的对象实例,于是python正确输出了keyboard7对象实例的颜色和重量。即使调用的类方法都是相同的,但仍然需要使用self参数,使得对象实例调用的是属于自身对象实例方法。
7.3私有变量
通过上述讲解中,一个类可以有类方法、类变量和实例变量。类能让这些变量和方法建立联系,并且类与类之间相互独立。对于以及定义的类变量和实例变量,它们的值能够被轻易修改,并且类变量的值一旦在一处有修改,所有的对象实例中相应的类变量都会被修改。这样看,即使类将这些变量进行了封装,就像是把它们装到一个“盒子”中,但外部代仍然能直接打开“盒子”,这造成了极大的安全隐患。
要解决这种安全隐患,最简单有效的方法是对类中的变量设置访问权限,使得外部代码无法访问它们。Python也正是这样设计的;为那些不应被外部代码直接访问的类变量、实例变量设置访问权限,使得只有类中的代码能够访问它们。而实现访问限制,仅需在定义的变量名称前加两个下画线就可以了,这样以双下画线为前缀定义的变量称为私有变量。
下述例子将keyboard类的类变量和实例变量都改为私有变量。例子:
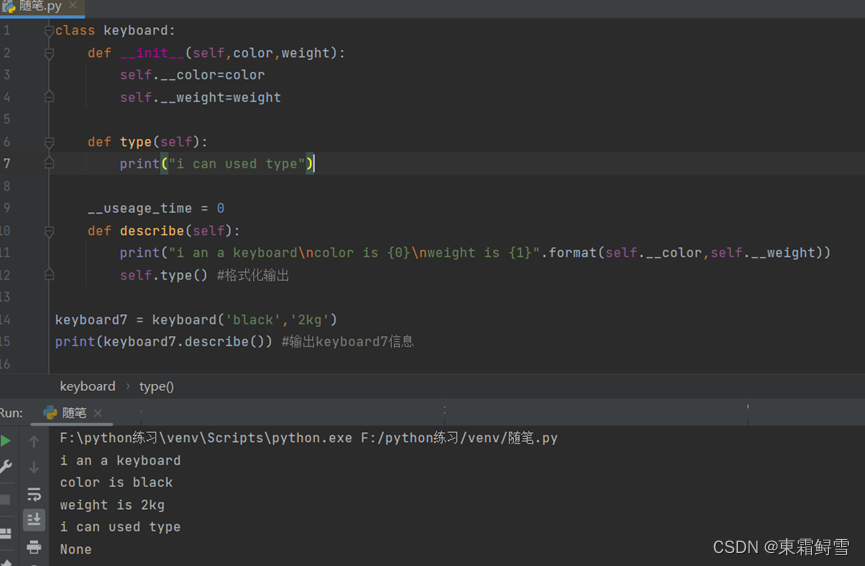
注意上例中__init__()方法中的参数并不需要设置为私有变量,因为它们的作用是初始化真正的私有变量,当该方法结束时,这些参数也就消失了。由于将这些变量改为了私有变量,那么在类方法中调用变量的时候就需要使用私有变量的新名字了。
私有变量的设置确保了外部代码不能随意修改对象实例内部的状态,这种访问限制的保护使得对象实例中的数据更安全,增强了程序的鲁棒性。
若是需要从外部获取私有变量的值,从前面讲述中的describe()方法可以看出,类方法是能够访问私有变量的。于是,可以分为私有变量设置一个方法专门用于获取其值。例子:

分别为私有变量__color和__weight设置了访问的类方法。通过各自的类方法就能够正确访问它们了。如果要对私有变量进行修改,可以增加一个类方法,专门用于修改私有变量的值。
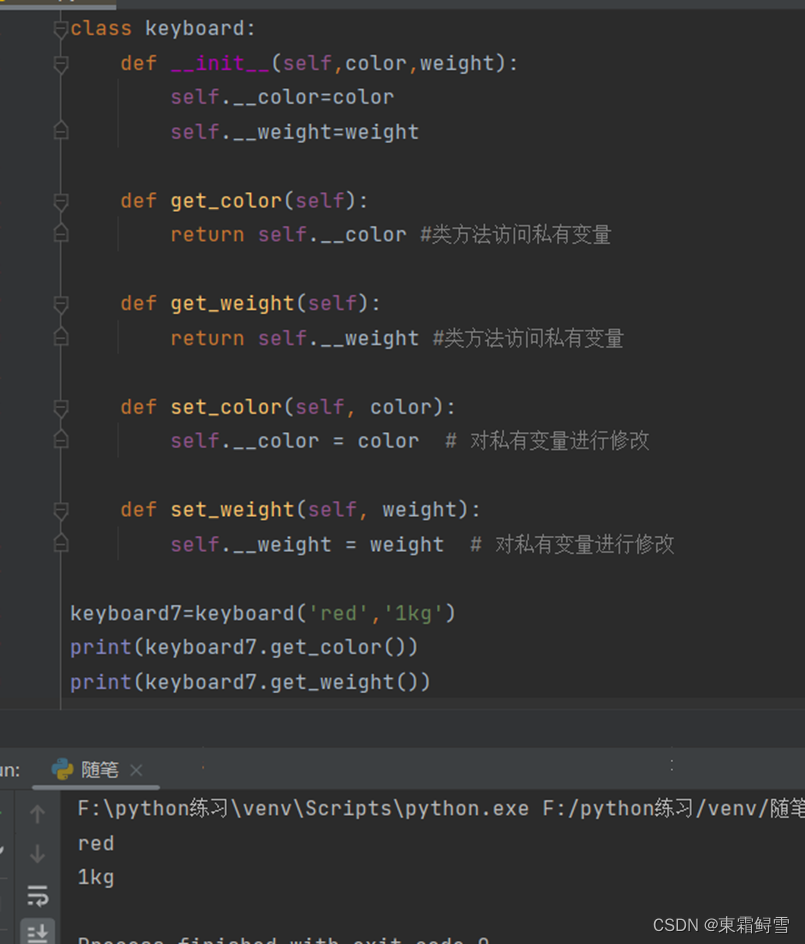
分别设置set_color()和set_weight()方法用于修改私有变量的值,即为类方法传入新修改的值,通过类方法在内部对私有变量进行修改。例子:
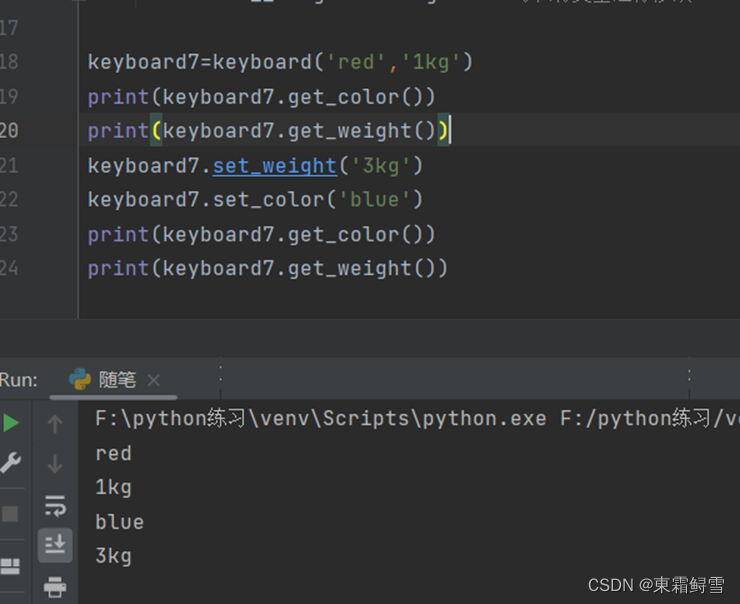
也可以通过一个类方法修改好几个私有变量。例子:

调用该类方法只需要传递两个参数到一个类方法中,完全可以得到相信相同的结果。使用哪种形式,关键在于是否需要同时修改这些私有变量。
如果使用私有变量,那么对私有变量的操作就必须使用类方法实现。实例变量上述提到划分为两种,第一种实例变量是在定义类的时候在__init__()方法中定义的,所以在定义类方法时能够直接使用这种实例变量。第二种实例变量是在对象实例创建之后定义的,所以在定义类方法时没有这种实例变量存在,也就无法对它进行良好的封装。
7.4 继承
在定义类时就将实例变量设置好,所以若要定义台式计算机keyboard类和笔记本计算机keyboard类,就应当定义两个不同的类,这两个类具有极大的相似度,分别定义这两个类会有大量代码重复,为解决和减少代码量,就需要用到继承机制。面向对象编程的优势之一是代码的重用,实现这种重用的方法之一就是采用继承机制。
7.4.1属性继承
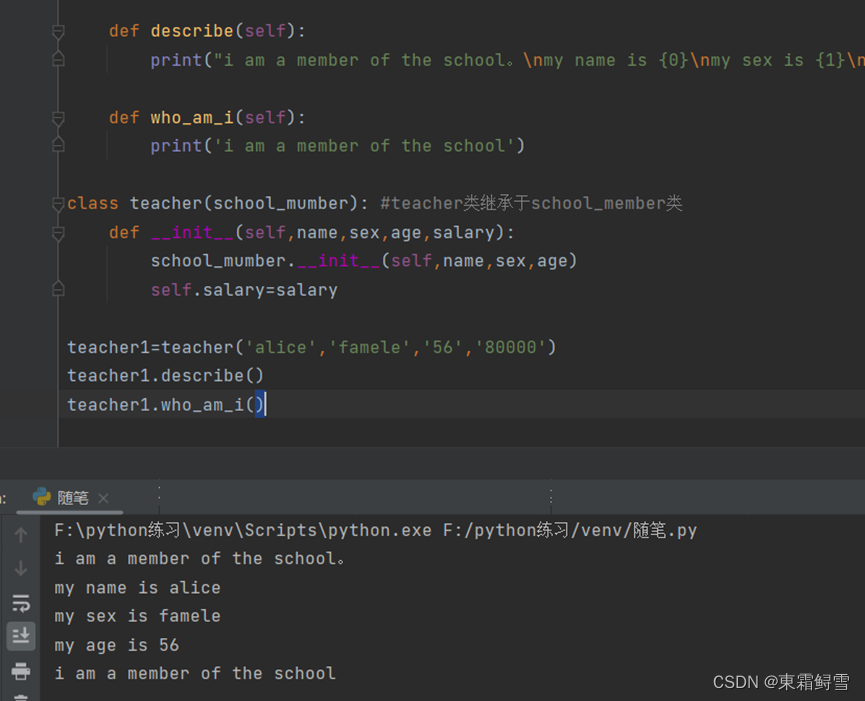
继承针对的目标是两个类,而这两个类是具有一定联系的,可以理解为它们不完全相同。如对于同一所大学的老师和学生而言,他们就具有很高的相似度,属于人这一物种,且处于相同的社会环境下。但是说老师和学生是同一类群体又不可行。如果以学校为参考范围,先考虑老师和学生相似的地方,如姓名、性别、年龄等信息,可以把老师和学生都放到同一个类中。例子:

上例定义了school_member类,显然老师和学生都属于这个类。但是老师和学生又有各自的特点,以老师为例,除了上述school_member类中的属性和方法外,teacher类还定义了薪水、职称等信息,使用继承机制,就无须重新定义所有的属性和方法,而是可以借助已经定义的school_member类,在其基础上添加teacher类独有的属性和方法。这样teacher类就继承了school_member类,继承的类称为子类或派生类,而被继承的类称为父类或基类。判断一个类是否是子类只需要看它在定义时有没有参数,父类会通过参数的形式传递给子类以进行判断。例子:teacher类的参数就是school_member类。

上例中,出现了两次__init__()方法,一次在teacher类中使用初始化方法,还有一次是调用school_member类的初始化方法。通常情况下类的方法无须调用,python自动为我们调用了它,这称为隐式调用。而在定义子类时,以父类名和点运算符调用__init__()方法称为显示调用。因为当子类和父类都拥有初始化方法时,python就无法判断应该隐式调用哪一个初始化方法。所以,python只会隐式调用当前类的初始化方法,父类的初始化方法就需要进行显式调用。而子类新增加的实例变量就以正常方式定义在子类的__init__()方法之中。
7.4.2 方法重写
在类的继承中,由于实例变量需要使用__init__()方法进行初始化操作,所以显得较为特别;子类新增的实例变量需要在子类的初始化方法中定义,而父类与子类相同的实例变量需要在子类的初始化方法中调用父类的初始化方法来进行定义。但是对于方法而言,继承就显得较为简单了。
子类若要用父类的方法,无须进行方法定义或方法调用。上面提到的例子teacher类中只定义了自己的__init__()方法,以继承school_member类的实例变量和新建自己的实例变量。然而,teacher类在继承父类时就拥有了父类的所有方法。例子:
以上例子并没有在子类中定义方法,但是仍然能够使用父类的方法,这便是方法的继承。如果在子类中新增了其他方法,一般情况下,只需要正常定义新增的方法就可以了。如在teacher类中新增加一个方法,为老师提高薪水。例子:
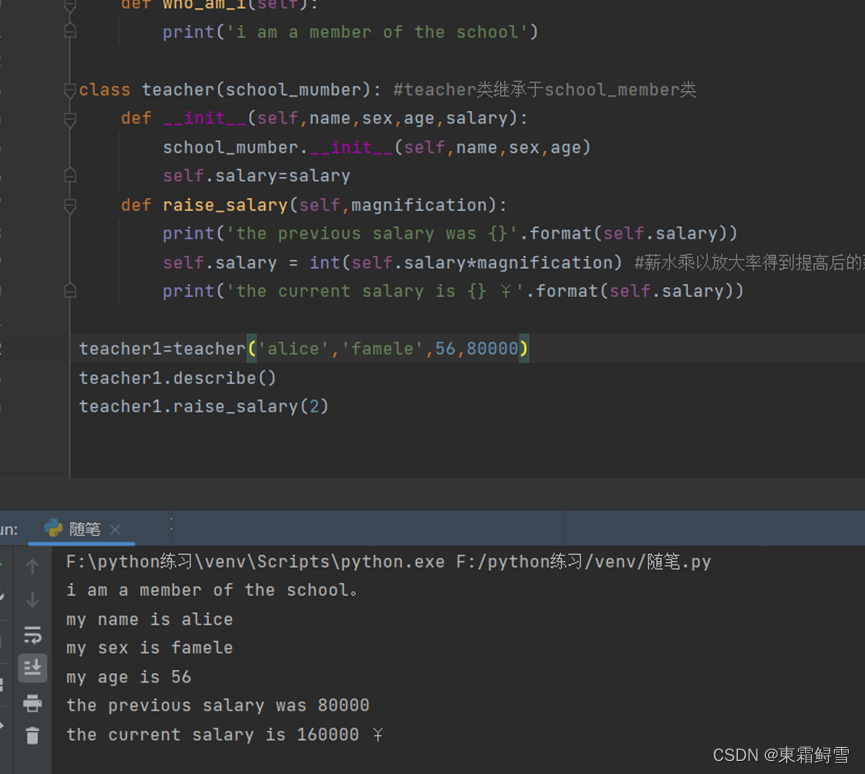
上例中,子类新定义的方法与继承于父类的方法能够共存。但是这仅限于子类于父类之间不存在同名的新增方法的情况。
还有一种情况是子类的新增于父类的方法名相同,这就需要进行方法重写。如在school_member类中有一个函数:

但是在teacher类中,还有必要用who_am_i()方法说明自己是学校的老师,所以父类的who_am_i()方法就有些不妥。子类的新方法与父类的方法同名,直接将父类的方法重写就可以。例子:
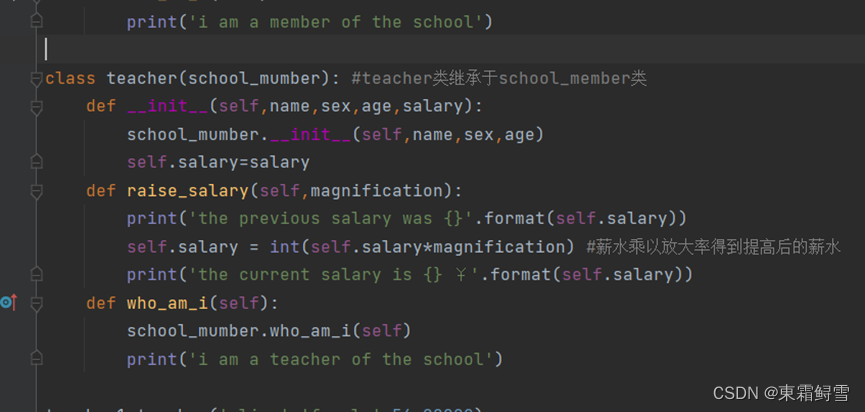
可以看到在teacher类中又定义了一次who_am_i()方法,这与初始化实例变量时是类似的,先使用父类名和点运算符在子类的方法中调用父类方法中的内容,然后执行子类新写入方法的内容。子类的方法怎么写,需不需要父类同一个方法的内容都是由用户决定的,这里知识为了举一个较为全面的例子而已。进行方法重写后的teacher类的一个对象实例例子如下:

Python并不会在方法重写时主动将父类同名方法的内容继承下来,假如在子类的who_am_i()方法中删去对父类方法的调用,只保留新增内容,那么它的执行结果也就只有在子类中新写入的内容了。例子:

7.4.3 多态
在有了继承和重写的基础之后,学会多态的调用技巧,能增加代码的调用灵活度,并且不会影响类的内部设计。
多态的含义是:子类对象实例可以向上转型看作父类对象实例。也就是说,当一个子类创建了对象实例时,那么这个对象实例不仅可以看作子类,还可以看作父类;但如果是父类创建的对象实例,就只能看作父类。如teacher类是school_member的子类,那么创建的teacher类对象实例是一位老师,同时它是学校的成员;但是反过来,学校的成员并不一定是老师。
关于多态的应用将以示例的形式体现出来。这里依然需要使用school_member类和它的子类teacher类和student类。对他们定义如下:
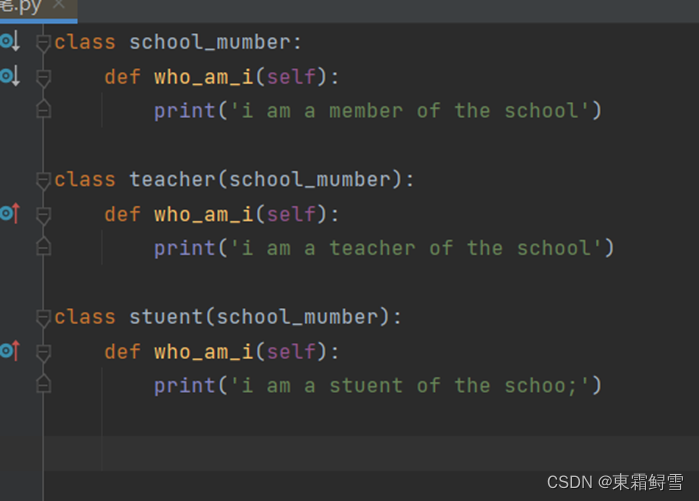
父类school_member类和子类student、子类teacher均只有一个方法,且子类都重写了父类的该方法。所以当子类调用与父类同名的方法时,将调用自身的重写方式。例子:

在python中,经常说“一切皆为对象”,在传递函数参数时,python无须知道究竟传递的是何种类型的参数,只需要知道其是对象就可以了。而类所创建的对象实例也能作为参数传递。下例为自定义一个函数,它接收一个对象实例。由于在定义参数列表时,并不需要考虑参数的类型,所以参数任意取一个别名就行。例子:

pardon()函数接收一个对象实例参数,然后调用对象实例参数的who_am_i()方法。可以从上例看出,为pardon()函数传递对象实例时,分别执行了不同对象的方法。也就是说参数member可以接收school_member类的对象实例,也可以接收其子类teacher类。Student类的对象实例,这就是多态的体现。对于类对象实例而言,子类对象实例可以向上转型看作父类对象实例,只要父类对象实例满足参数的条件,那么子类对象实例也一定能满足,因为子类拥有父类的所有属性和方法。接着再为school_member类创建一个子类:
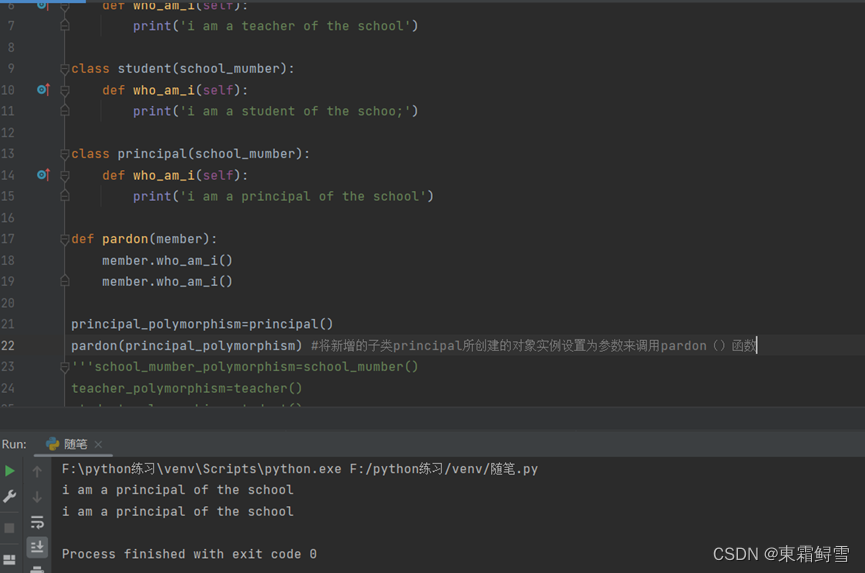
上例中可看出,pardon()函数和school_member类并未做任何改动,新增的子类principal所创建的对象实例就能够作为参数调用pardon()函数。这就是多态的优势,新增的子类无须重新设计父类使用的方法,从而提高代码的复用率,也使得类的逻辑设计更加结构化。
8.错误和异常
在我们进行程序测试的时候,会遇到一些python的红字警告,即报错信息。如调用函数或变量把名字写错,或向函数传入了不正确的参数,又或者尝试打开一个不存在的文件,这些情况都是不正确的。在python中并不能直接将所有不正确的情况统称为错误,这些不正确的情况被分为两类,即错误和异常。
8.1 区分错误和异常
1.错误
在python中,错误主要分为两类:语法错误和逻辑错误。
- 语法错误指编写代码不符合python语法。如使用错误的函数名称:由于在math模块中存在pi变量,math.pi可以正确调用:但是math模块中并不存在pi变量或函数,所以尝试调用不存在的函数或变量math.pii时,python将直接给出报错信息。例子:
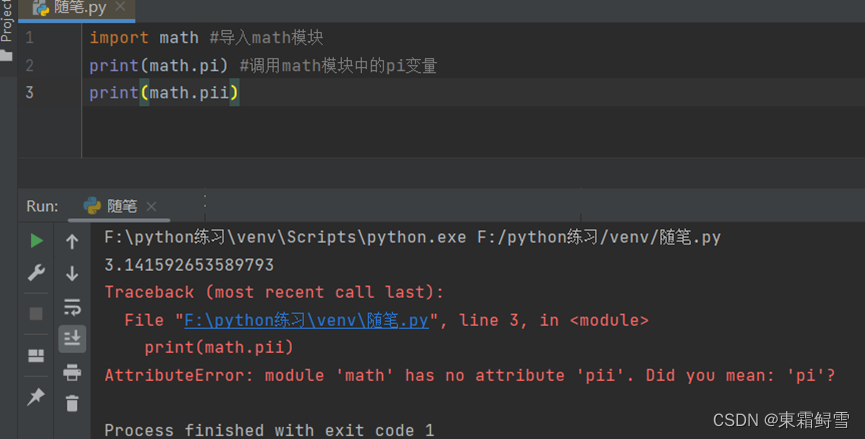
出现语法错误的情况也可能是在使用if后没有加上必要的符号“:”,例子:

这类语法错误在代码执行前就被错误处理器发现并指出,所以也被称为解析错误。
- 逻辑错误指代码执行结果与预期不符。也就是说python能够正常运行,没有产生语法错误,但是程序的执行结果是不正确的。如变量使用错误,在应该使用A变量的情况下使用了B变量。GetA()函数的功能是根据参数B的值来确定返回A的值,正确的GetA()函数及其调用结果例子如下:

但是如果将返回A的值写成返回B也不会报错:

程序可以正确的运行,但结果错误。这种逻辑错误从语法上看是正确的,但这并不是我们设计这个程序的正确写法,也就是我们常说的“bug”,这种错误不容易被发现,因为python只负责运行程序,它无法告诉我们要实现这个功能怎么写代码,它只负责提醒那些不符合语法规范的错误。所以在我们写程序解决问题的时候应当确保思路明确,逻辑清晰。
2.异常
含有语法错误的程序无法正常运行,含有逻辑错误的程序可以正常运行,却得到错误结果。除开这两种情况,还有一种不正确的情况就是程序在运行过程中遇到错误导致意外退出,这种运行时产生的错误就是异常。如试图打开的文件不存在,除法计算中的除数为0等情况都是异常。程序没有能力自行处理这些异常,若不对发生的异常进行处理,程序就会终止,并且将异常以错误信息的形式展现出来。例子:

上例中,这个异常看上去和错误很相似,都是直接提示了错误信息。实际上,语法错误被找到时,程序并没有真正运行,语法错误是由错误处理器发现的;但是异常必定是程序运行之后才发现的。当定义函数A_Error()时,python并没有提示错误任何信息,而只有调用该函数,执行到“7/0”处时,python才遇到这个异常,从而终止程序运行并给出错误信息,例子:
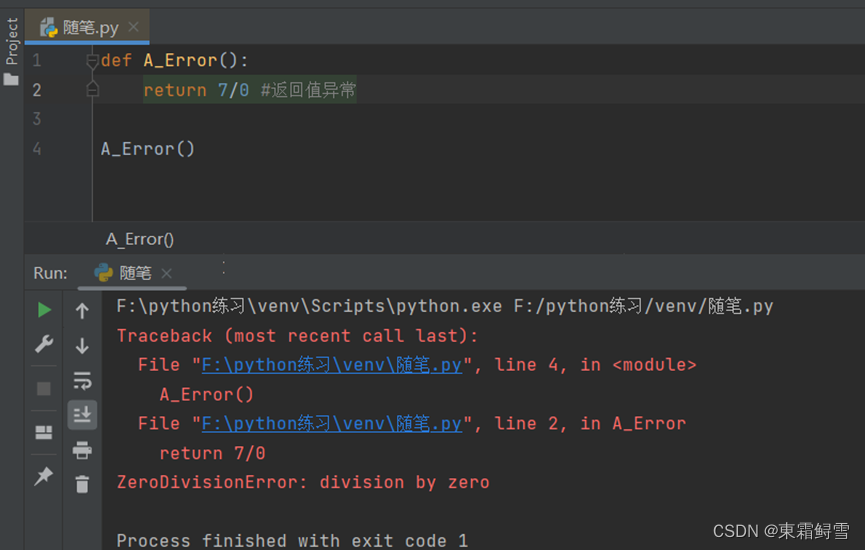
可以从上例中发现,异常相比语法错误和逻辑错误要难以处理得多,因为它必须要在程序被运行后才有机会被发现。但python内置了一套异常处理机制,来帮助用户进行这种不正确情况的处理。
8.2 处理异常
实际上,异常是一个事件,如果程序运行时发生了异常事件,那么python将判断针对这个事件是否提前有处理方案。如果有,那么执行提前设置好的处理方案;如果没有,则终止程序并提示错误信息。例如上例中的7/0,除数为0报异常错误,是因为我们没有提前设置除数为0得情况下得解决方案。实际上,当有这种异常情况输入时,我们的程序就需要有相信的解决方案,否则直接报异常错误对于用户的体验也是糟糕的,我们就可以先判断除数是否为0,为0则提示用户除数不能为0请重新输入。对于很多刚上手编程的小白可能就第一时间想到了使用if语句去解决这个问题,但是对于真正的项目而言,异常情况是很多的,若是一直都用if语句去处理,不断地为程序加入if语句,会使程序可读性变得很差,也为程序员增加了极大的负担。但是python提供了专门的异常处理机制,我们可以使用异常处理机制,这样有几个优点:把错误处理和真正的工作分开;代码更易组织、更清晰,复杂得工作任务更容易实现;程序更加安全。
“将错误处理和真正的工作分开”,表示异常处理的语句块与可能发生异常的语句是分开的。在设计异常处理的时候,首先需要确定范围,明确哪些代码可能出现异常;其次,针对每个异常,需要考虑其被捕获后做何种处理。有了以上分析,就可以对异常处理的模式做一个推断;检查指定范围的代码是否出现异常;如果出现异常则调用相应异常处理代码,否则不做处理并终止程序。事实上python和大多数编程语言都是这样做的。Python提供了相当便捷的异常处理“模板”:try…except…else…finally组合语句,使用这种组合语句能逻辑清晰地捕获并处理异常,其语法结构如下。
try:
<语句块> #可能引发异常的语句块
except BaseException: #BaseException表示异常种类
<语句块> #发生except指定的异常后执行的语句块
else:
<语句块> #未发生异常时执行的语句块
finally:
<语句块> #是否发生异常都执行的语句块
8.2.1 try-except语句
在try-exzept语句中,将可能出现异常的代码放在try语句块里,实际上只是为随后的异常检测限定了范围,真正捕获异常的关键在于except。except后紧接需要捕获的异常种类BaseException,它可以代表所有的异常。实际上,异常是类,而异常的基类,即各种异常类的父类就是BaseException类,其余所有内置异常或是用户自定义的异常都是基于它的。例如前面提到的除数为0会引发的异常类是ZeroDivisionError。为了捕获除数为0的异常处理如下:
try:
<语句块> #可能引发异常的语句块
except ZeroDivisionError: #捕获除数为0异常
<语句块> #发生ZeroDivisionError异常后执行的语句块
根据关键字except后提供的异常种类,python可以知道在try语句块中捕获了何种异常。假如发生指定异常,就不再执行原有的try语句块,而是开始执行except语句块中的异常处理代码。例子:

在上例中就可以发现,当捕获到ZeroDivisionError异常后,程序不再执行try语句块,而是跳转到except语句块。前面提到使用异常处理机制能够在异常发生时做一定的补救措施,但事实上异常被捕获后,便不再执行剩余的try语句块,所以需要在exceot语句块中提前写好“处理方案”。下述例子中,将x视为用户输入的数据,当用户输入正常数据时,不会发生异常;当用户将x定义为0时,继续执行除法运算就会导致ZeroDivisionError异常,于是此时就将x定义为默认值1(实际情况下应提示用户重新输入x,这里是为了便于理解),以解决除数为0导致的程序中断问题。
例子:正常情况除数不为0;
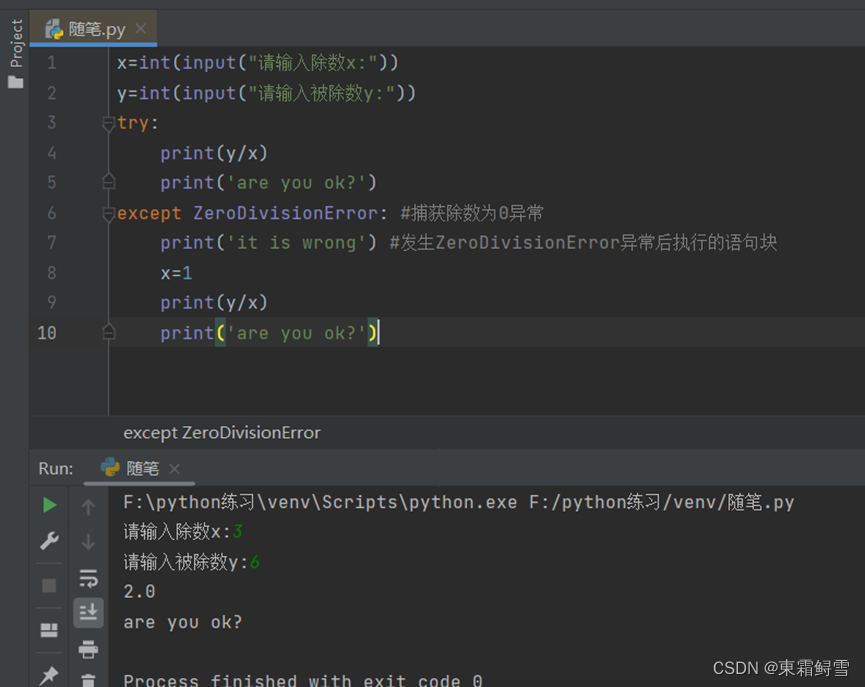
除数为0;
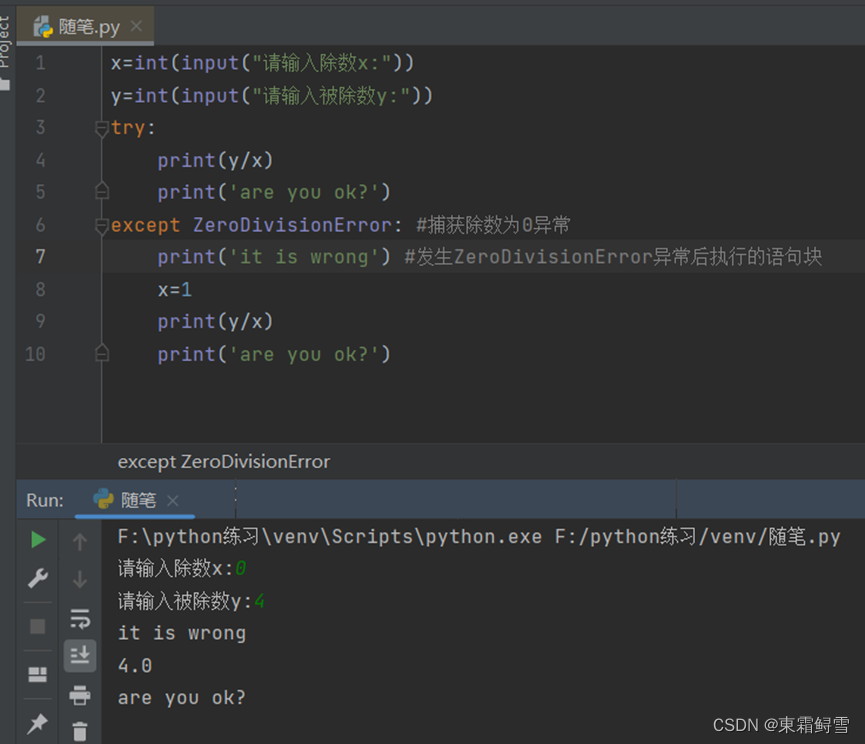
也许这样的处理机制对于初学者来说过于烦琐,但是对于一个实际的程序而言,异常处理机制仅需要添加少量的代码就能增强程序的安全性,这其实是十分有益的。并且,明确可能发生异常的代码会让异常处理变得更加简单。例如上例中输出字符串“are you ok?”是不会出现异常的,于是可以缩小try语句块的范围,例如将其写在异常处理之外的区域。
8.2.2 未发生异常——else子句
上述中,讲解到try-except语句会捕获所有发生的异常,我们不能通过该程序识别出具体的异常信息,为此引进else子句,其逻辑与if-else中的else语句类似。例如将上例中加入else子句:
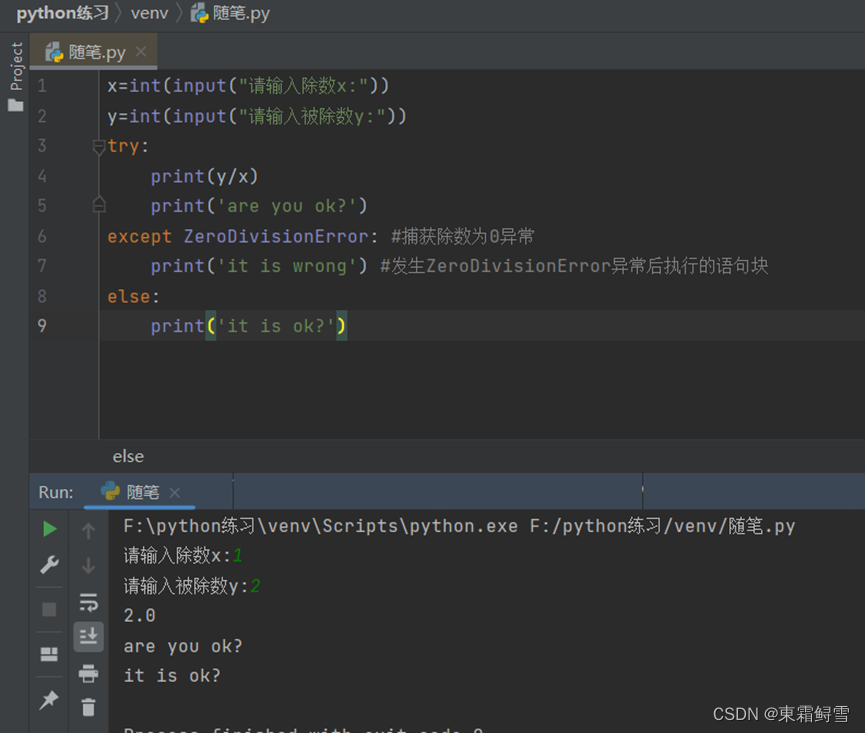
可以看出,x的值不是0并不会发生除数为0的异常,所以程序没有进入except语句块,而是在执行完所有的try语句块后正常进入else语句块的执行语句。
8.2.3 巧用finally清理子句
在异常处理机制中,finally语句定义的是在任何情况下都要执行的功能,也就是说,不管有没有发生异常,finally语句都一定会被执行。这就包括未发生异常的情况,异常发生并捕获的情况甚至异常发生但未被捕获的情况。例子:
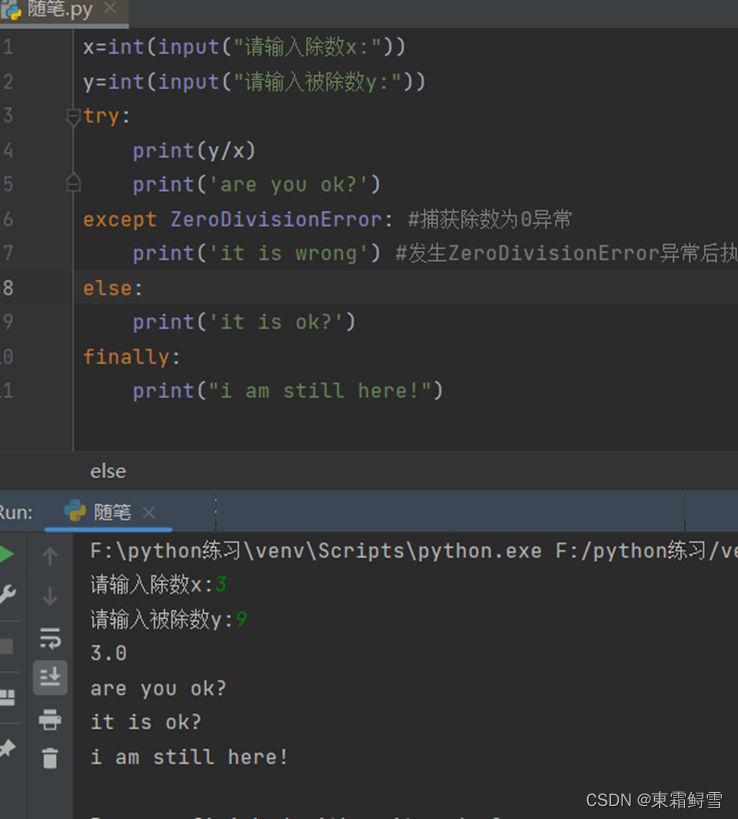
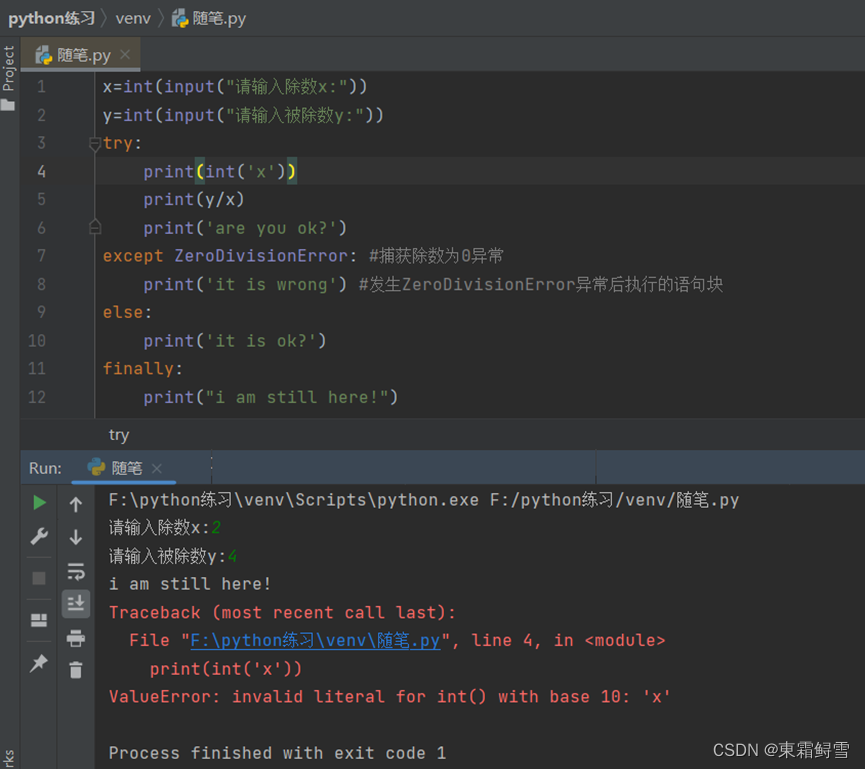
可以看到不管有没有报错finally的语句块都会被执行,即使ValueError导致了程序终止,但在错误信息输出之前,finally语句仍然被执行了。Finally语句的作用体现在实际的应用程序中,它常被用于释放外部资源(文件或网络连接等),无论程序的执行过程中是否出错。
在前面讲解文件时,讲过打开文件后始终要关闭文件。但如果发生了异常,怎么确保文件对象正确关闭,常见的文件操作代码分为三部分;打开文件、操作文件、关闭文件:
file_object=open(‘file.txt’) #打开文件
操作文件
file_object.close() #关闭文件
最简单的finally语句能够解决这样的问题:自动调用close()方法将打开的文件关闭。例子:

不论是否发生异常,finally语句都将判断文件是否打开。如果判定文件打开,则将其关闭,并输出相应信息。从这个例子中就可以看出,使用finally语句能够很好的实现文件自动关闭的功能。在实际的应用中,使用finally语句也能解决其他许多资源释放的问题。
8.2.4 处理多种异常
通过上述讲解中,对于try…except…else…finally组合语句的用法已经有了一定程度的掌握。它是python异常处理机制的核心。当try语句块中发生异常时,try语句块未执行的内容将不再执行,并立即转到except后匹配异常名称,若二者匹配则执行相应的except语句块,最后执行finally语句块;当try语句块内未发生异常时,会执行完try语句块后将执行else语句块,最后执行finally语句块。
并非每一处的异常处理都需要else和finally语句,可以视具体情况使用它们;不过设置异常处理时至少需要设置一个except语句块和try语句块匹配。加入只有try语句块而没有except语句块,就相当于把代码放到一个毫无意义的命名空间中;而若只有except没有try,python就无处可捕获异常。
注意的一点是,允许为一个try语句块设置不止一个except语句块,因为一段代码可能出现多个异常。为try语句块中可能出现的多个异常设置多个except语句块是一个重点。例子:

在这个例子中,虽然没有出现除数为0的异常,但是存在着一个试图将字符串x转换为整数的操作,这当然是一个异常,然而except语句块只能够捕获指定的ZeroDivisionError异常,于是程序在展示异常信息之后就终止了。通过前面的学习中,我们已经知道了所有的异常都是类,所以要解决问题,首先要知道究竟是什么异常类能够捕获这种“错误的类型转换”问题。可以直接通过提示信息看到异常类名为ValueError,并且错误信息已经将异常原因描述的十分清楚了。但是我们依然要对各种异常类进行一个了解,一种异常只属于一个异常类,但一个异常类能够包含多种异常情况。下表为一些常见异常类以及相应的描述:
| 异常类名称 | 说明 |
| BaseException | 所有异常的基类 |
| SystemExit | 解释器请求退出 |
| KeyboardInterrupt | 用户中断运行(通常是输入了“^C”) |
| GeneratorExit | 生成器异常 |
| Exception | 常规异常的基类 |
| FloatingPointError | 浮点数计算错误 |
| OverflowtError | 数值运算超出最大限制 |
| ZeroDivisionError | 除数(或模)为0(所有数据类型) |
| AttributeError | 对象没有这个属性 |
| EOFError | 没有内建输入,到达文件结束符(End Of File,EOF) |
| IOError | 输入/输出操作失败 |
| ImportError | 导入模块/对象失败 |
| RuntimeError | 一般的运行时错误 |
| NotImplementedError | 尚未实现的方法 |
| IndentationError | 缩进错误 |
| TabError | 制表符和空格符混用 |
| SystemError | 一般的解释器系统错误 |
| TypeError | 对类型无效的操作 |
| ValueError | 传入无效的参数 |
通过上表可以找到对“错误的类型转换”引发的异常ValueError的描述——传入无效的参数。不难理解,因为类型转换时的int实际上充当了函数的角色,需要转换的内容对它而言便是参数。确定了捕获类型转换错误应当使用的异常类名称ValueError之后,就可以改写前面例子中except语句块指定匹配的异常类。例子:

只有恰当的使用异常类,才能捕获可能发生的异常,使得程序能够正常运行。如果x=0,使得try语句块中存在两个异常,那么except语句块应该匹配哪一个异常这一问题,异常处理机制提供了两种解决方式。为了简化代码,此处就不考虑else子句和finally语句。
- 一个except多个异常
用一个except子句处理多个异常的例子如下:

用一个except子句处理多个异常,仅需要将这些异类放在一个元组里就可以了。不过对于放在except子句中的多个异类而言,它们拥有相同的处理方法。可以解决存在多个异常的问题,凡是无法确定是其中的哪一种异常。例子:

- 多个except多个异常
用多个except子句处理多个异常的示例如下:

为语句块设置多个except子句以匹配异常,这样的处理方法非常具有逻辑性,可以对于不同的异常给出不同的处理方案。当异常发生时,python将该异常依次与except指定的异常名称进行匹配,如果匹配成功,则执行相应的except语句块。但python只会处理第一个发生的异常。因为当第一个异常发生后,剩余的try语句块就不再执行,即使里面还含有可能发生的异常。例子:

当7/0发生除数为0异常时,python便依次访问except语句块以匹配对应的ZeroDivisionError异常。匹配成功后便直接进入except语句块,剩余的try语句块不再执行。
正确的处理各种各样的异常,我们需要了解一些常见的异常类,并运用组合语句设计恰当的异常处理结构,这样才能真正发挥异常处理的作用。
8.3 抛出异常
Python的异常处理机制和内置的异常类已经能够解决绝大多数的问题,但是仍然存在这样的一种情况:用户输入了不符合程序逻辑的数据。例如用户为记录年龄的函数传入了非正数,此时应当指出这个错误,但这不足以引发python的异常处理机制,因为python不会自动检测程序的逻辑问题,这时就需要手动产生这个异常,这种设置被称为抛出异常。
一个最简单的抛出异常如下例,由于使用raise语句抛出异常是强制行为,raise后紧跟异常名就能够使程序抛出异常并提示信息,即使程序中并没有发生任何异常:
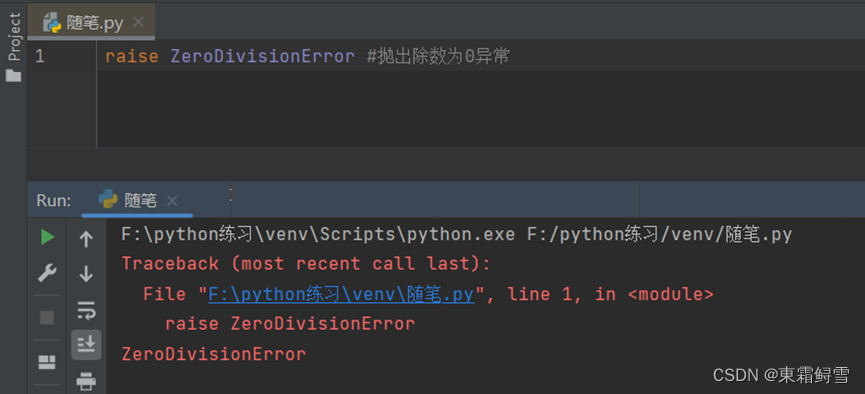
但抛出除数为0的异常提示错误信息与python自动抛出除数为0异常的错误信息有所不同,如下为自动抛出的错误信息:

Python自动抛出的错误信息多出的一段字符串内容是对错误信息的描述。由于python中所有异常都是类,所以每个异常类中都有初始化方法、变量,以及方法,其中有一个变量叫做args,它存储了关于异常的简短描述,而对于手动抛出异常的raise()方法而言,args是它的一个参数,代表用户自己提供的异常参数。如果要输出对错误信息的描述,在抛出异常时为异常类传递一个字符串参数就行了。例子:
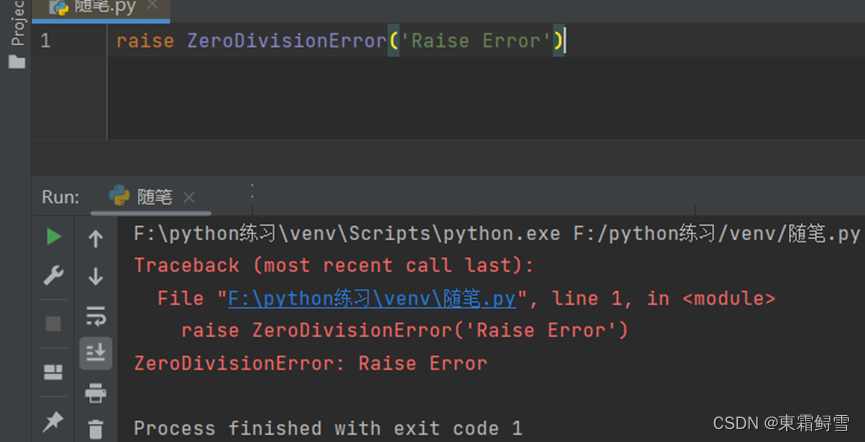
为异常类传入的字符串参数将在异常被抛出后,作为错误信息输出在屏幕上。
下面介绍对不符合程序逻辑的输入数据抛出异常的方法。
首先,定义一个含单个参数的GetAge()函数,传入的参数代表年龄。函数要求传入的年龄参数不能为负数或0,但python无法自动检测这种逻辑错误,于是需要使用raise语句手动抛出这种异常。例子:

手动抛出异常圆满地解决了这样的逻辑问题,但错误信息不完整。这时因为虽然手动抛出了异常,但是异常的处理方案始终在except语句块中。如果想要达到类似python自动抛出异常的效果,可以在except语句块中添加一条raise语句,此处仅需要raise关键字。例子:

上例中可看出,最终提示地错误信息来自try语句块中抛出的异常,except语句块中不带参数的raise语句会保持当前错误不改动并且抛出。except语句块中raise语句抛出的异常也可以有所改动,如可以为抛出的异常添加新的提示信息。例子:
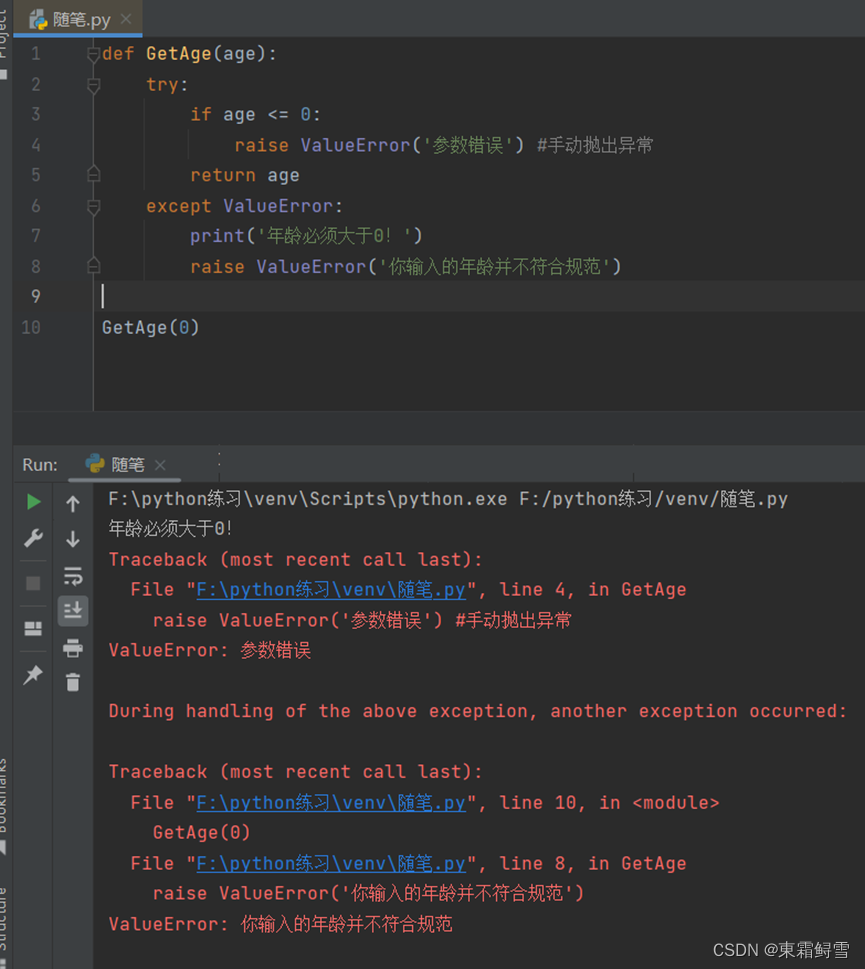
根据错误信息中的“During handling of the above exception, another exception occurred:”,可以得知在except语句块中抛出的异常相当于抛出了第二个异常,这样便会显得错误信息十分冗长,所以使用raise语句抛出异常,尽量只抛出一次异常就完成工作。并且,except语句块中使用raise语句还可能会出现抛出不恰当的异常的情况。例子:
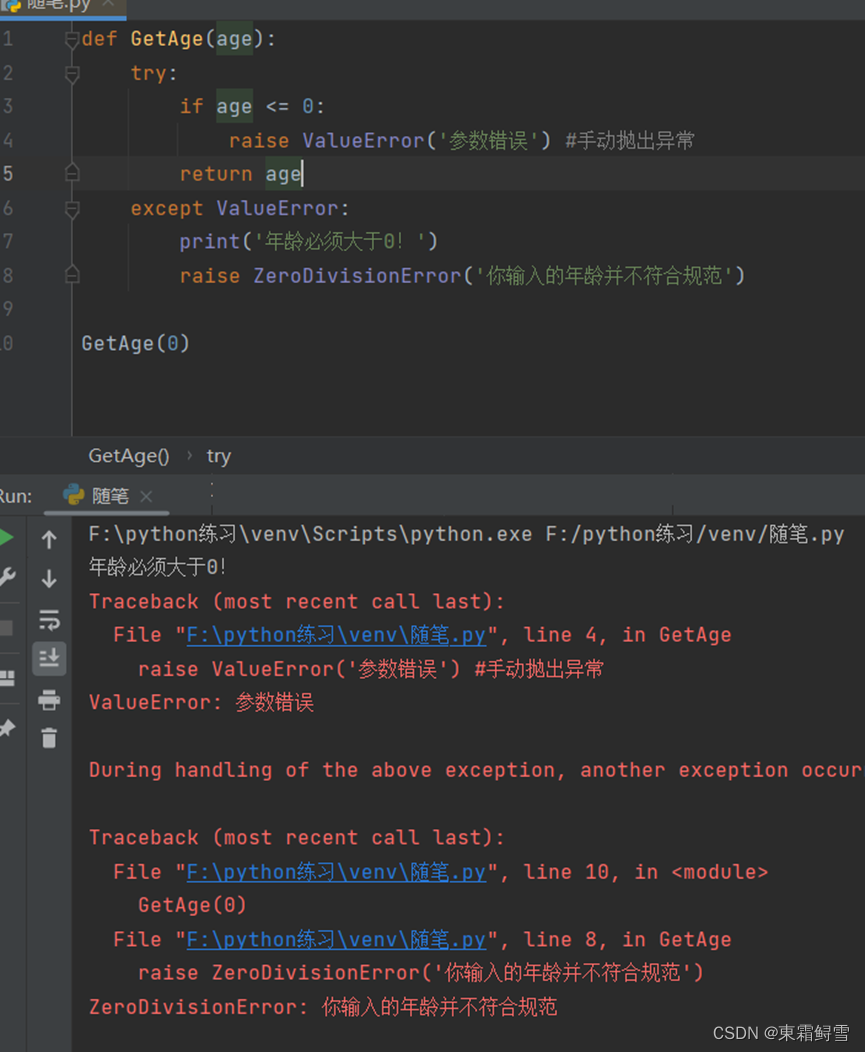
按照异常类的定义,传入无效的参数应当抛出ValueError,上例还抛出了ZeroDivisionError。但即使在处理中抛出其他的异常类也会正确提示错误信息,因为python不能处理程序中人为的逻辑问题。这并不是告诫我们要尽量少用这些会出现问题的语句,而是提醒我们在编写程序时应当思路清晰。使用异常处理机制而不是大量的if语句处理信息也能够帮助我们提高处理代码逻辑的能力。
8.4 自定义异常
虽然python提供的异常类已经十分全面了,但是程序员仍然会有抛出异常的需求。Python无法内置每位程序员可能用到的异常类。所谓“授人以鱼不如授人以渔”,当程序员需要为自己的程序设计一个异常类,以便处理运行时发生的错误时,就可以自己定义一个异常类。这样定义出来的异常类并不能被python自动识别,所以想要使用自定义的异常类,就需要在出错的位置使用上述讲解到的raise语句抛出一个自定义的异常类对象。前文提及BaseException类是所有异常的基类,它和其他异常类的关系如下图所示:
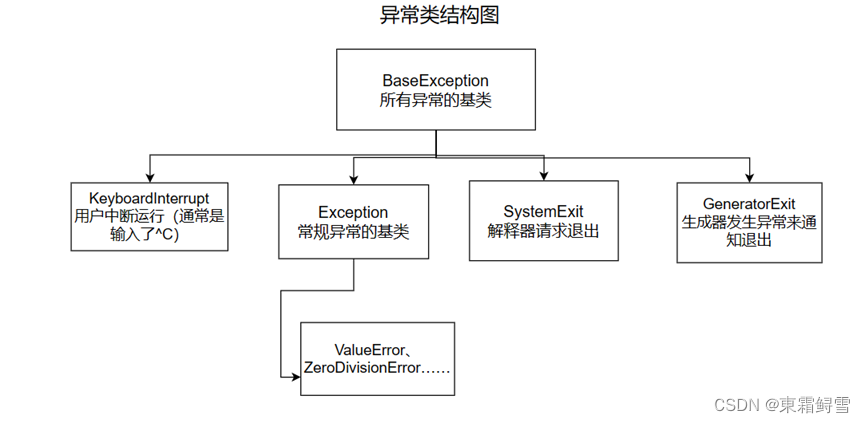
上图可以发现,常见的异常类几乎都继承了BaseException类的子类Exception。所以自定义异常通常就是定义一个类继承Exception类,当然也可以继承其他异常类。这里建议直接继承Exception,毕竟它是所有常见异常的基类。例子:

可以看到自定义的异常类被成功抛出,虽然我们没有为它添加任何内容,但是继承机制自动继承了Exception类的各种方法,其中也包括初始化方法。例子:

可以发现,自定义异常除了只能通过raise语句抛出以外,在使用方法上它与python内置的标准异常类没有区别。建议仅在必要的时候才定义自己的异常类。Python内置的异常类已经足够丰富,在可以选择python内置异常类的情况下,尽量使用python内置的异常类。
之后的就是模块的应用之类的,这些就可以在需要的时候查看怎么应用即可。

![[挖坟]如何安装Shizuku和LSPatch并安装模块(不需要Root,非Magisk)](https://img-blog.csdnimg.cn/direct/00ba67dd82014123b99265c133e5afaf.png)