什么是布隆过滤器?
布隆过滤器(Bloom Filter)是一种数据结构,用于判断一个元素是否属于一个集合。它的特点是高效地判断一个元素是否可能存在于集合中,但是存在一定的误判率。
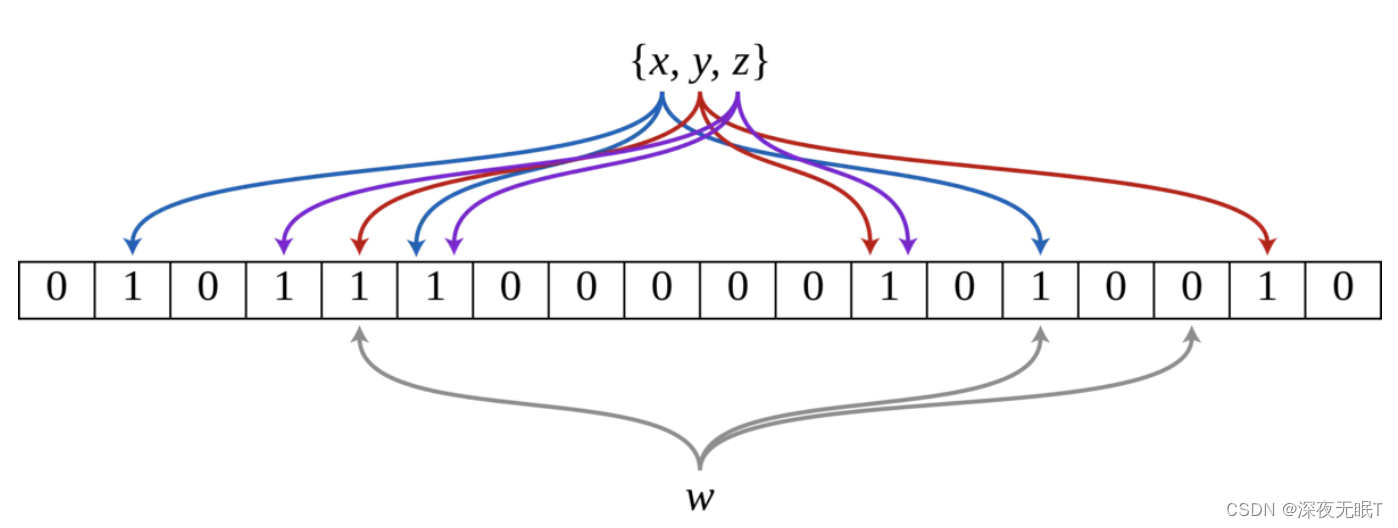
布隆过滤器的基本原理是使用一个位数组(Bit Array)和多个哈希函数。初始时,所有位都被置为0。当添加一个元素时,会使用多个哈希函数计算出多个哈希值,并将对应的位数组位置置为1。当判断一个元素是否存在于集合时,同样使用多个哈希函数计算哈希值,并检查对应的位数组位置是否都为1,若有任意一位不为1,则可以确定该元素一定不在集合中;若所有位都为1,则可能存在于集合中,存在一定的误判率。总结来说就是: 布隆过滤器说某个元素存在,小概率会误判。布隆过滤器说某个元素不在,那么这个元素一定不在。
应用场景
-
缓存系统: 布隆过滤器可以用于缓存系统中,用于快速判断一个数据是否存在于缓存中。在查询之前,可以先使用布隆过滤器进行判断,如果判断不存在,则不需要查询缓存系统,从而减少了查询时间。
-
大型数据库系统: 在数据库系统中,布隆过滤器可以用于快速判断一个元素是否存在于数据库中。对于一些经常被访问的热点数据,可以先使用布隆过滤器进行判断,如果判断不存在,则可以避免进行实际的数据库查询操作。
-
URL去重: 在网络爬虫中,布隆过滤器可以用于URL的去重。当爬取一个新的URL时,可以先使用布隆过滤器判断该URL是否已经存在于已爬取的URL集合中,从而避免重复爬取相同的URL。
代码实现
下面用java来实现一个简单的布隆过滤器
public class BloomFilter {
private static final int DEFAULT_SIZE = 2 << 24; // 布隆过滤器的比特长度
private static final int[] seeds = {3, 5, 7, 11, 13, 31, 37, 61}; // 哈希种子,用于产生多个哈希函数
private BitSet bits = new BitSet(DEFAULT_SIZE);
private SimpleHash[] func = new SimpleHash[seeds.length]; // 存储多个哈希函数
public BloomFilter() {
for (int i = 0; i < seeds.length; i++) {
func[i] = new SimpleHash(DEFAULT_SIZE, seeds[i]);
}
}
public void add(String value) {
if (value != null) {
for (SimpleHash f : func) {
bits.set(f.hash(value), true);
}
}
}
public boolean contains(String value) {
if (value == null) {
return false;
}
boolean result = true;
for (SimpleHash f : func) {
result = result && bits.get(f.hash(value));
}
return result;
}
public static class SimpleHash {
private int cap;
private int seed;
public SimpleHash(int cap, int seed) {
this.cap = cap;
this.seed = seed;
}
public int hash(String value) {
int result = 0;
int len = value.length();
for (int i = 0; i < len; i++) {
result = seed * result + value.charAt(i);
}
return (cap - 1) & result;
}
}
public static void main(String[] args) {
BloomFilter filter = new BloomFilter();
filter.add("test");
filter.add("hello");
System.out.println(filter.contains("test")); // true
System.out.println(filter.contains("hello")); // true
System.out.println(filter.contains("world")); // false
}
}、