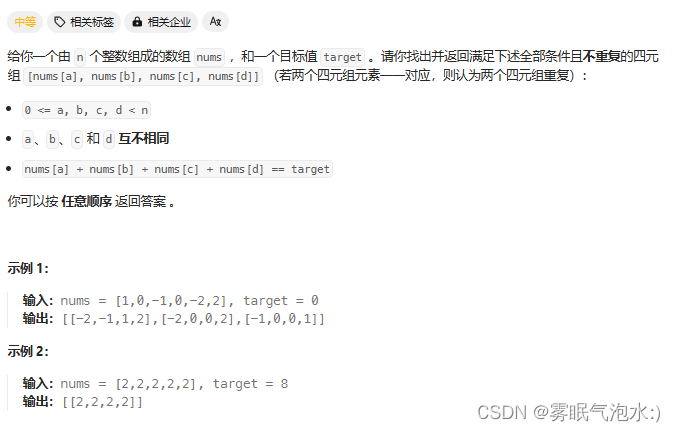
目录
- 一、开发环境
- 二、爬虫的概念
- 三、爬虫与Python
- (一)爬虫常用语言
- (二)python的特点
- 四、爬虫环境依赖
- (一)python第三方库
- (二)第三方库的安装
- 五、爬虫与HTTP
- (一)URL
- (二)HTTP消息(报文)
- (三)响应状态码
- (四)请求方法
- (五)HTTP请求与响应
- 六、python实现HTTP请求
一、开发环境
开发环境:推荐使用Pycharm社区版,或者Python IDLE也是可以的。

二、爬虫的概念
爬虫,也称为网络爬虫(Web Crawler),是一种自动获取网页内容并提取所需信息的程序。简单的来说,就是对网页进行爬取并进行数据分析。
常用的策略有深度优先遍历、广度优先遍历、随机遍历策略等,数据分析方法有对比分析、聚类分析等。另外,这里列出的不局限以上这些方法,具体的爬取环境还需选取不同的爬取策略和后期分析方法。
虽然可以自己开发爬虫程序,但需遵守一定的法律法规。有些网页会提供 robots.txt 文件,定义了爬虫可以访问的页面范围,否则强行爬取可能会造成一定的侵权行为。
三、爬虫与Python
(一)爬虫常用语言
爬虫技术以其高效的数据抓取能力,在众多领域中发挥着不可或缺的作用。可以用很多种语言来开发爬虫,例如,python、Java、C#、JavaScript等。
(二)python的特点
而在实现爬虫功能时,python语言因其简洁易懂的语法、强大的库支持和广泛的应用场景,成为了首选的编程语言,其有以下优点:
1、语句简洁易读,易开发
2、内置了强大的网络处理能力,提供网络编程
3、跨平台性,可在Linux、Windows、macOS多平台运行
4、拥有丰富的第三方库,为爬取技术提供支持
5、有一定的安全稳定性,保障爬虫运行
四、爬虫环境依赖
(一)python第三方库
爬虫主要使用python中的库和工具来实现,包括requests、beautisoup、pandas、pyquery、pillow、lxml、正则表达式等。例如,通常结合requests库和beautifulSoup库来爬取网页内容并解析出需要的数据,前者对网页页面发送HTTP请求并返回该页面的HTML内容,后者是用于从爬取的HTML或XML文件中提取数据。
爬取的网页通常获取的是HTML文件。HTML(超文本标记语言)用于创建网页,即用于搭建网页页面的语言,通过代码编写和设计网页的内容,然后,打开浏览器进行解析。这里的浏览器实际上是一个HTML解析器,通过读取HTML文件,解析其中的标签和属性,并根据这些指令来构建和渲染网页。
(二)第三方库的安装
以下以在pycharm中安装为例,命令都是适用的。
上面所列出的第三方库几乎都可以通过 pip install 后跟名称直接在python开发环境中安装。例如,安装requests库,Alt+F12调出控制台,然后输入pip install requests,即可下载安装:
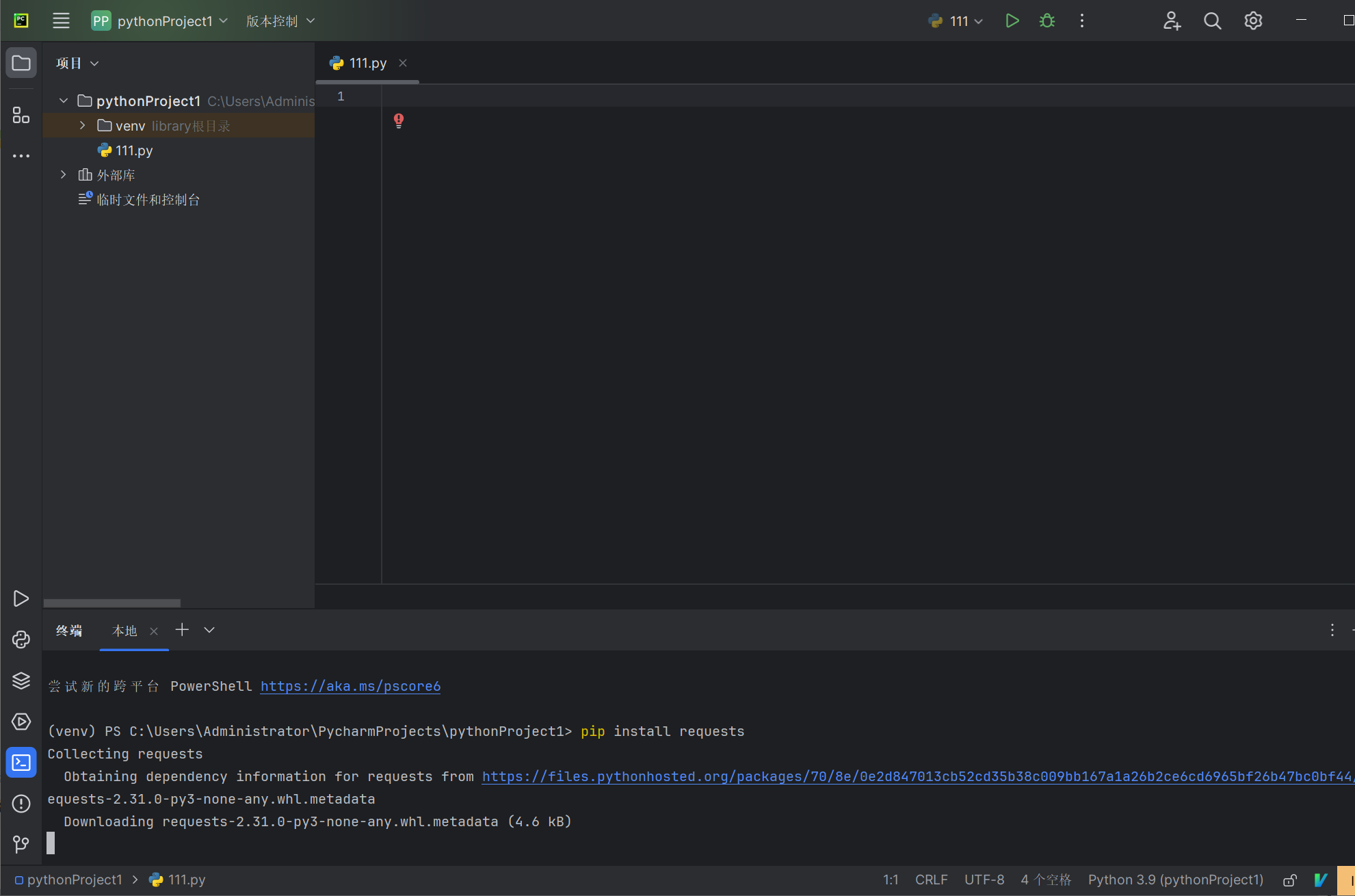
安装成功:
安装beautisoup库,输入pip install bs4:
安装成功:
同样,安装 pymongo、selenium、pytesseract 的命令也是: pip install pymongo、pip install selenium、pip install pytesseract。而 pillow、tesseract 需要在相关的网页中下载,前者需要在 http://www.lfd.uci.edu/~gohlke/pythonlibs/搜索 pillow 并选择版本,然后在控制台通过 pip install 后跟相应的 pillow 版本即可安装;后者在 https://tesseract-ocr.googlecode.com/files/tesseract-ocr-setup-3.02.02.exe 中下载安装即可。
五、爬虫与HTTP
HTTP称为超文本传送协议,属于计算机网络架构中应用层的一个重要协议,通常适用HTML、CSS、JavaScript等来设计互联网页面。
(一)URL
统一资源定位符(URL)是为了标识互联网资源的地址,即互联网上的所有资源都有唯一确定的URL。例如,下面显示的即是当前网址“https://cn.bing.com/”的URL:
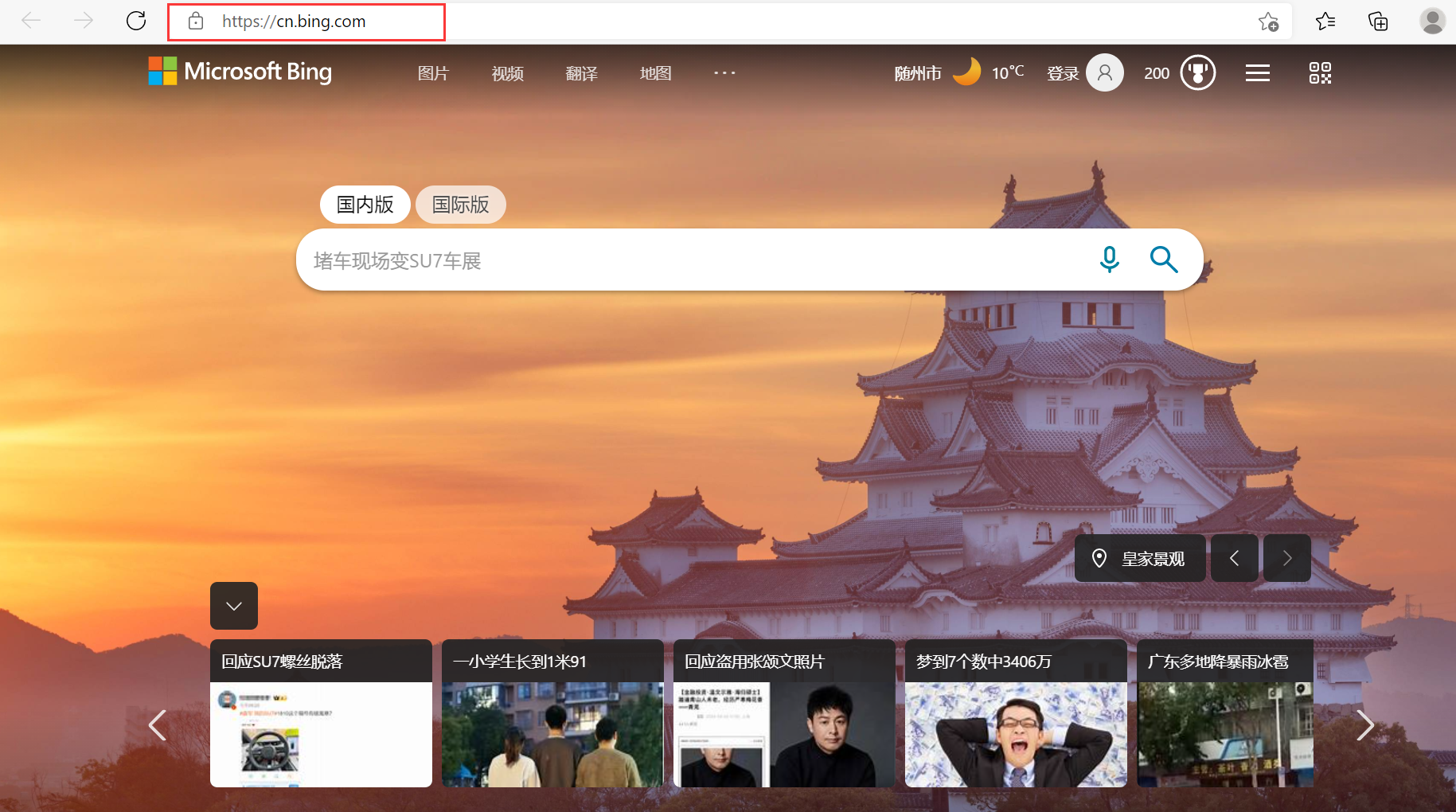
URL的一般形式为:<协议>://<主机>:<端口>/<路径>。常用的协议有http、https、ftp等。
(二)HTTP消息(报文)
HTTP消息包括请求消息和响应消息,数据在服务器与客户端之间交换,HTTP请求消息是客户端向服务器发送的,而HTTP响应消息是服务器向客户端发送的。请求头和响应头分别是请求消息和响应消息中的组成部分,请求头描述客户端的信息,响应头描述服务器的信息以及返回内容。
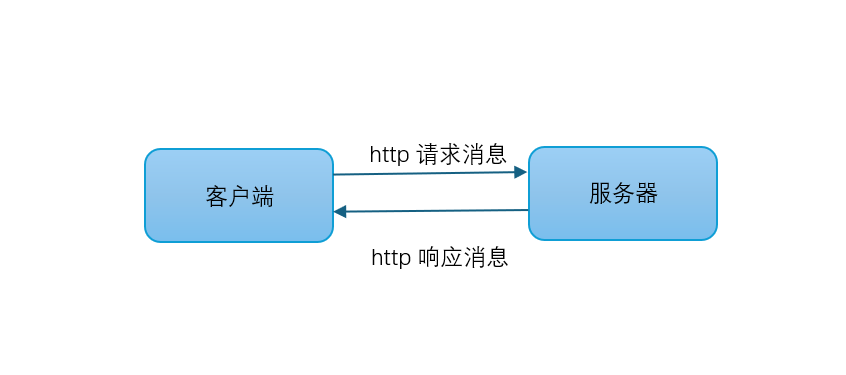
(三)响应状态码
在HTTP协议中,每个响应都含有一个服务器返回的状态码(status code),是一个三位数的数字,用于表示请求的处理结果。通过返回的状态码,可以了解请求的网页是否成功以及诊断失败的原因。
| 状态码数字 | 备注 |
|---|---|
| 1XX | 信息状态码 |
| 2XX | 成功状态码 |
| 3XX | 重定向状态码 |
| 4XX | 客户端错误状态码 |
| 5XX | 服务器错误状态码 |
例如,下面点击一个请求,查看其详细信息,可以看到“200”,这里代表的就是请求成功,如下:
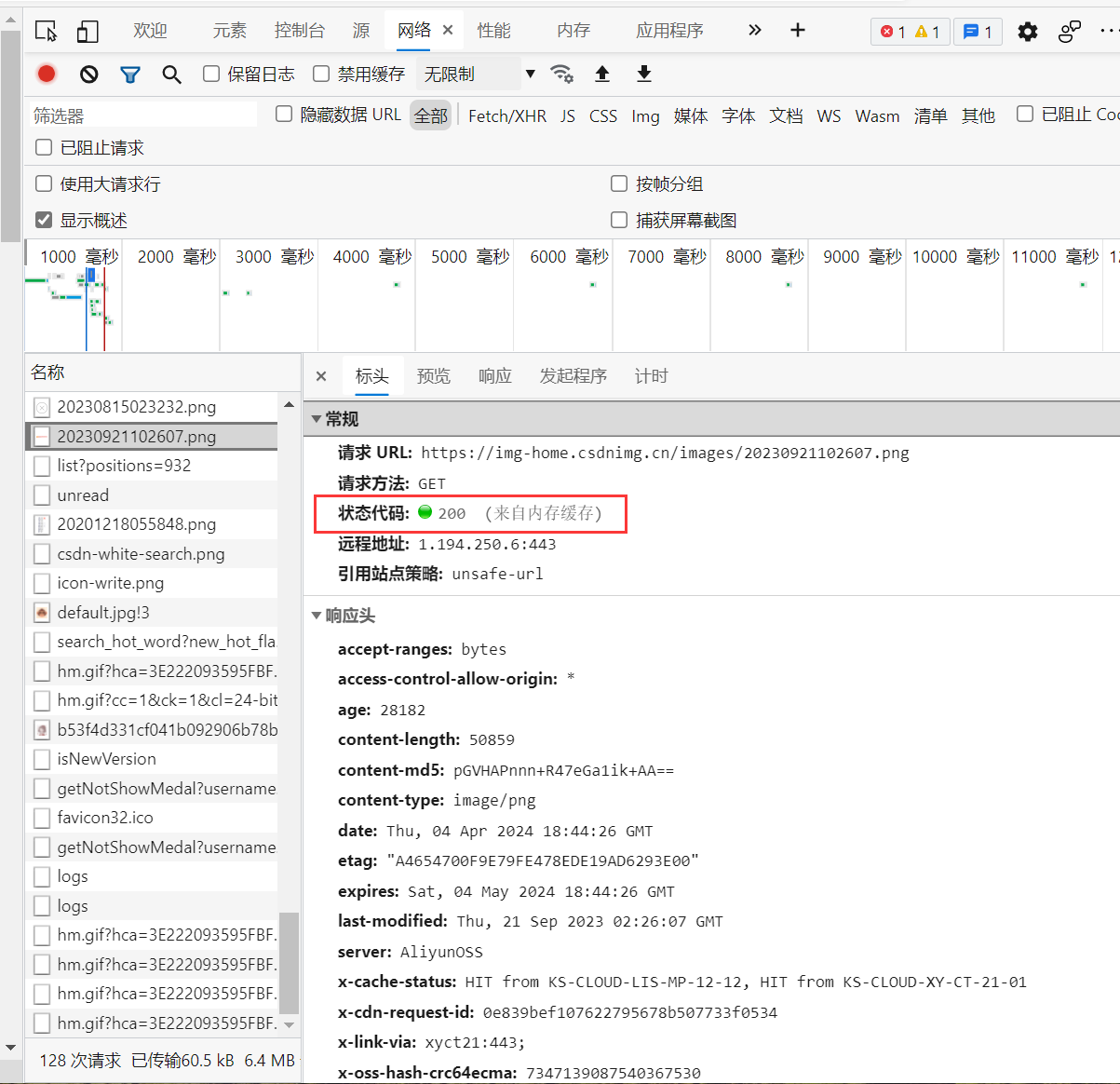
在request库中,response对象的属性status_code即为状态码,可以直接通过response.status_code进行调用。另外,response对象还有其他属性和方法如下表:
| 名称 | 备注 |
|---|---|
| status_code | 状态码 |
| headers | 头部信息 |
| text | 内容 |
| url | url地址 |
| content-type | 内容的文件类型 |
(四)请求方法
HTTP请求方法是指客户端对资源执行的操作类型,常用的方法有GET和POST,另外还有DELETE、PUT、TRACE、HEAD、PATCH、OPTIONS等。
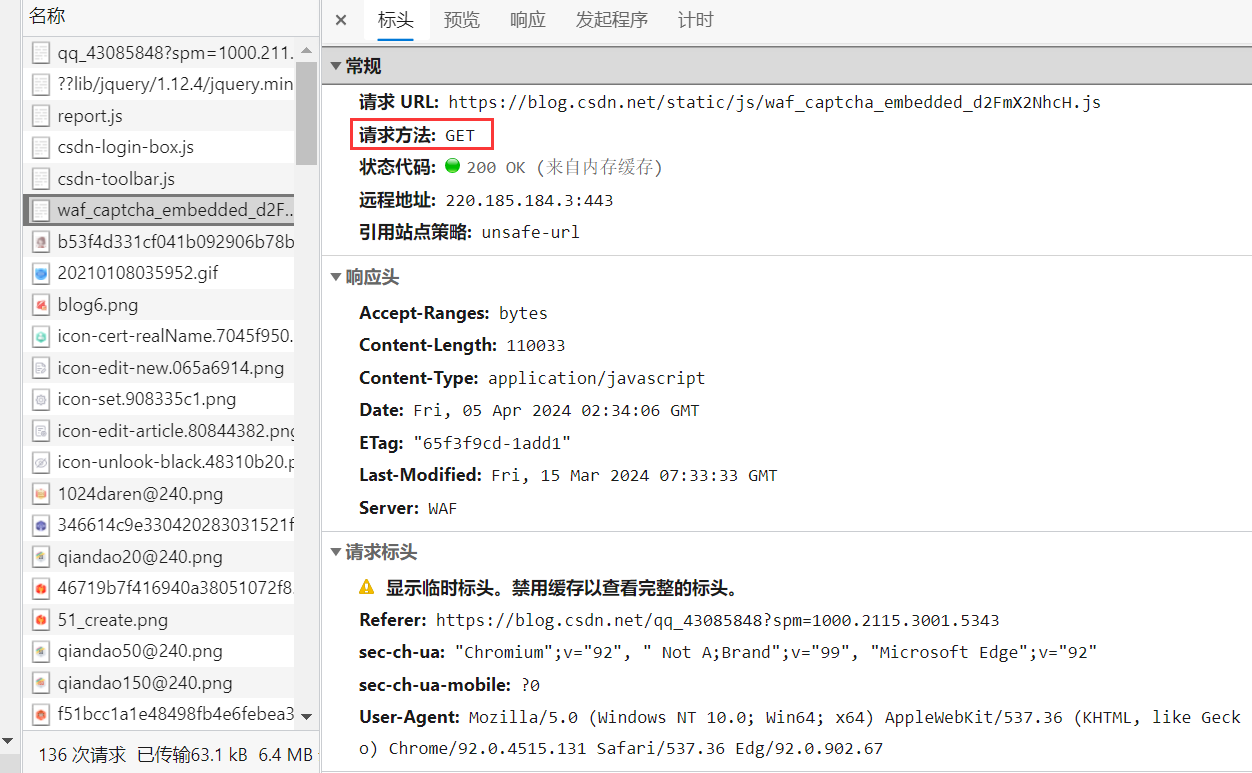
1、GET方法
GET方法是对页面请求该页面信息。如下图,可以看到对该资源使用的请求方法:
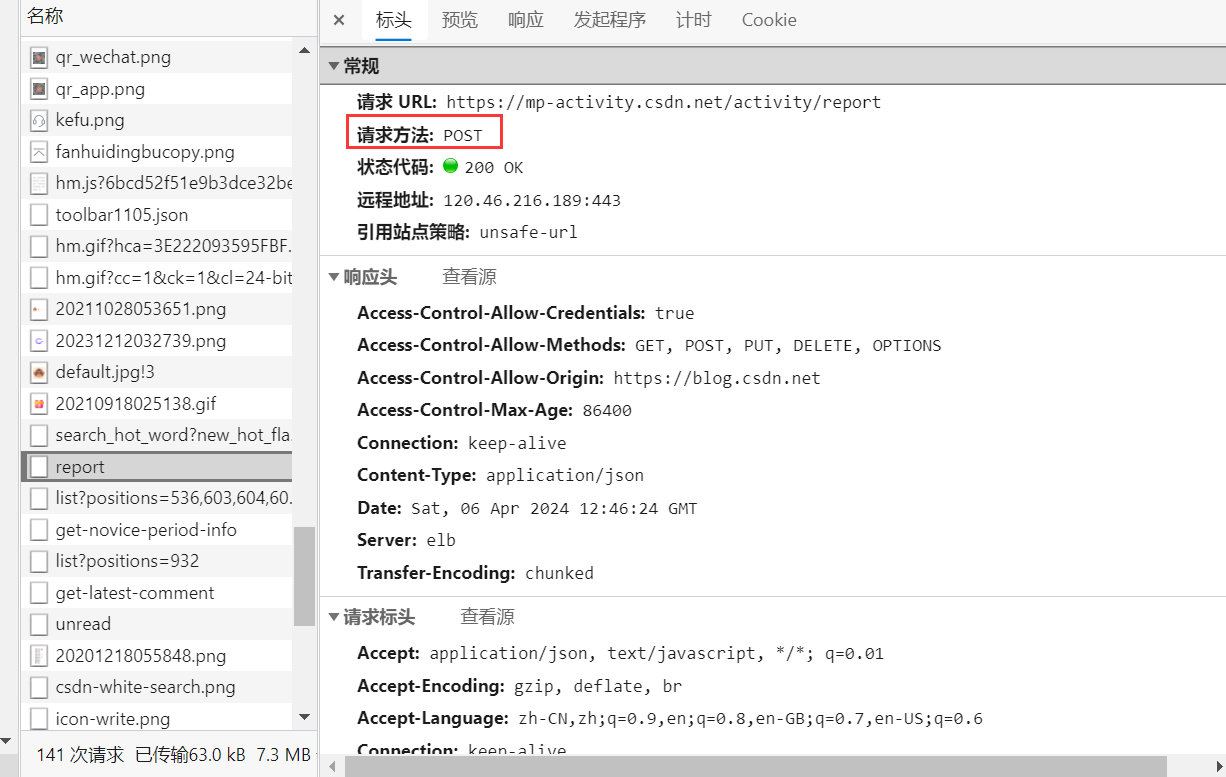
2、POST方法
POST方法通常用于提交数据或上传文件等,提交的东西包含在请求体中。如下图,可以看到对该资源使用的请求方法:
3、OPTIONS方法
OPTIONS方法可以查看服务器的性能。如下图,可以看到对该资源使用的请求方法:
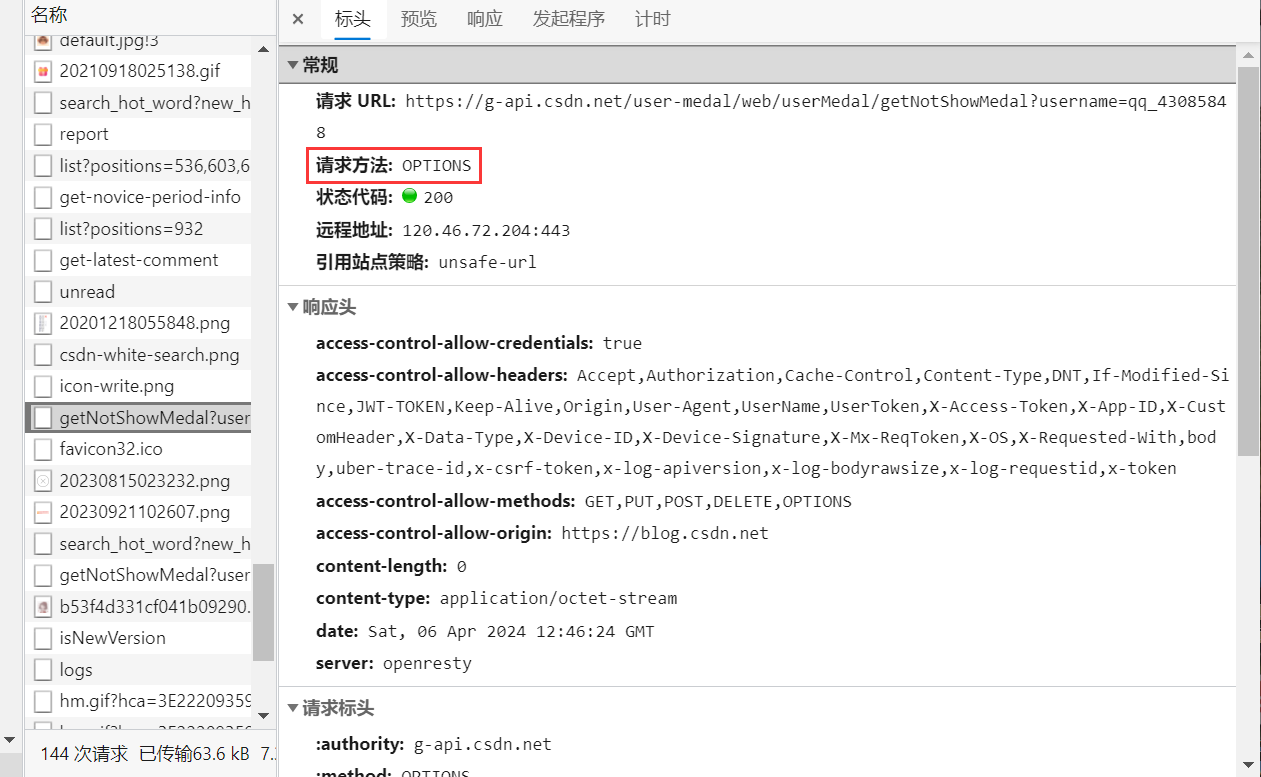
(五)HTTP请求与响应
爬虫的实现过程中包括一定的HTTP请求与响应,通过向目标网站发送HTTP请求,然后接受并解析服务器返回的HTTP响应。爬虫实现过程主要包括以下步骤:
1、确定目标网页URL,并发送HTTP请求
2、服务器返回HTTP响应,包含了该网页的HTML内容
3、解析HTML内容,提取数据
4、对数据进行分析和处理,并保存
例如,通过Microsoft Edge打开一个网页,并按下F12快捷键打开网页调试工具:
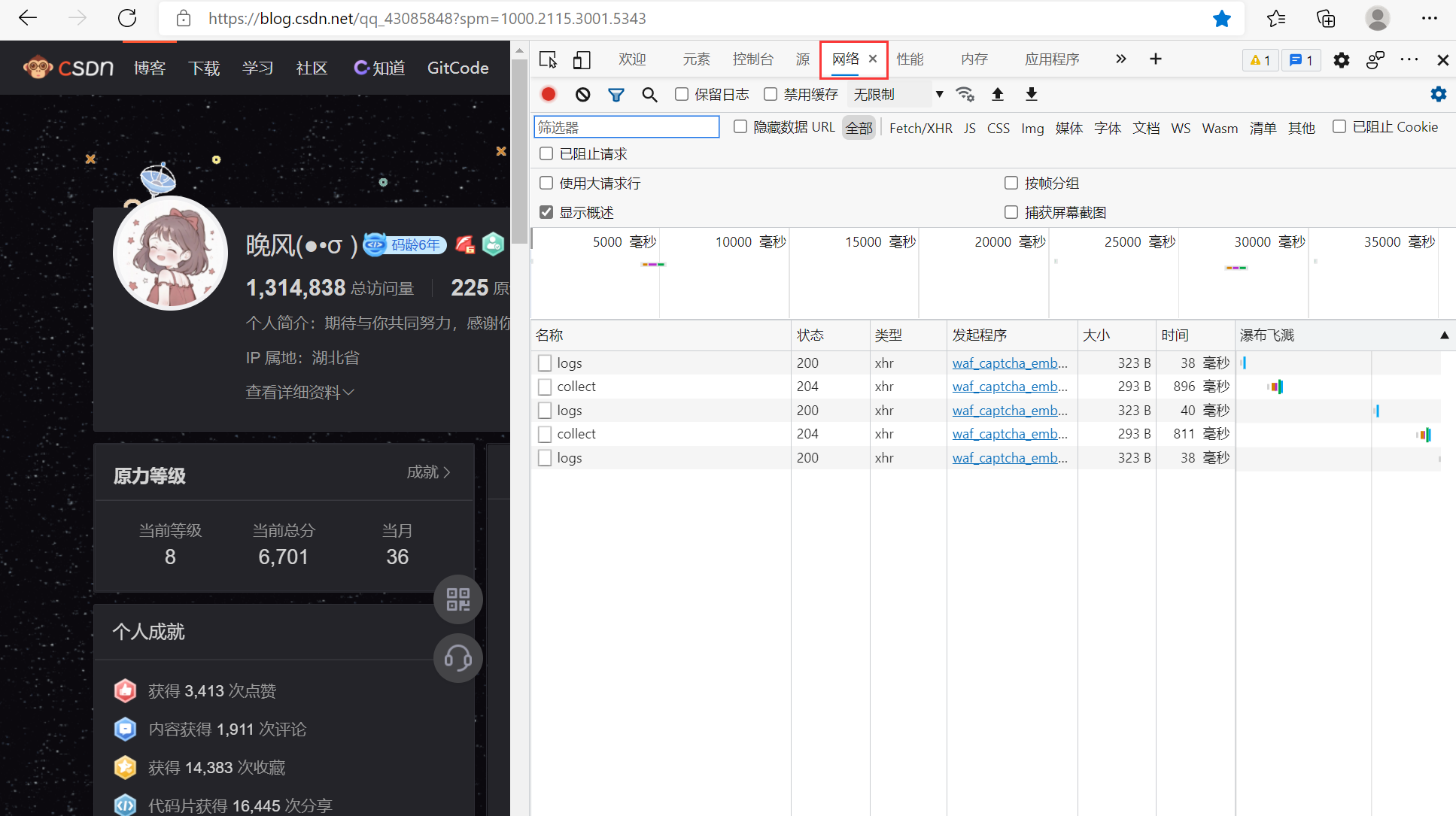
并选择“网络/network”选项卡,这里会显示网页加载时所有网络请求和响应列表:
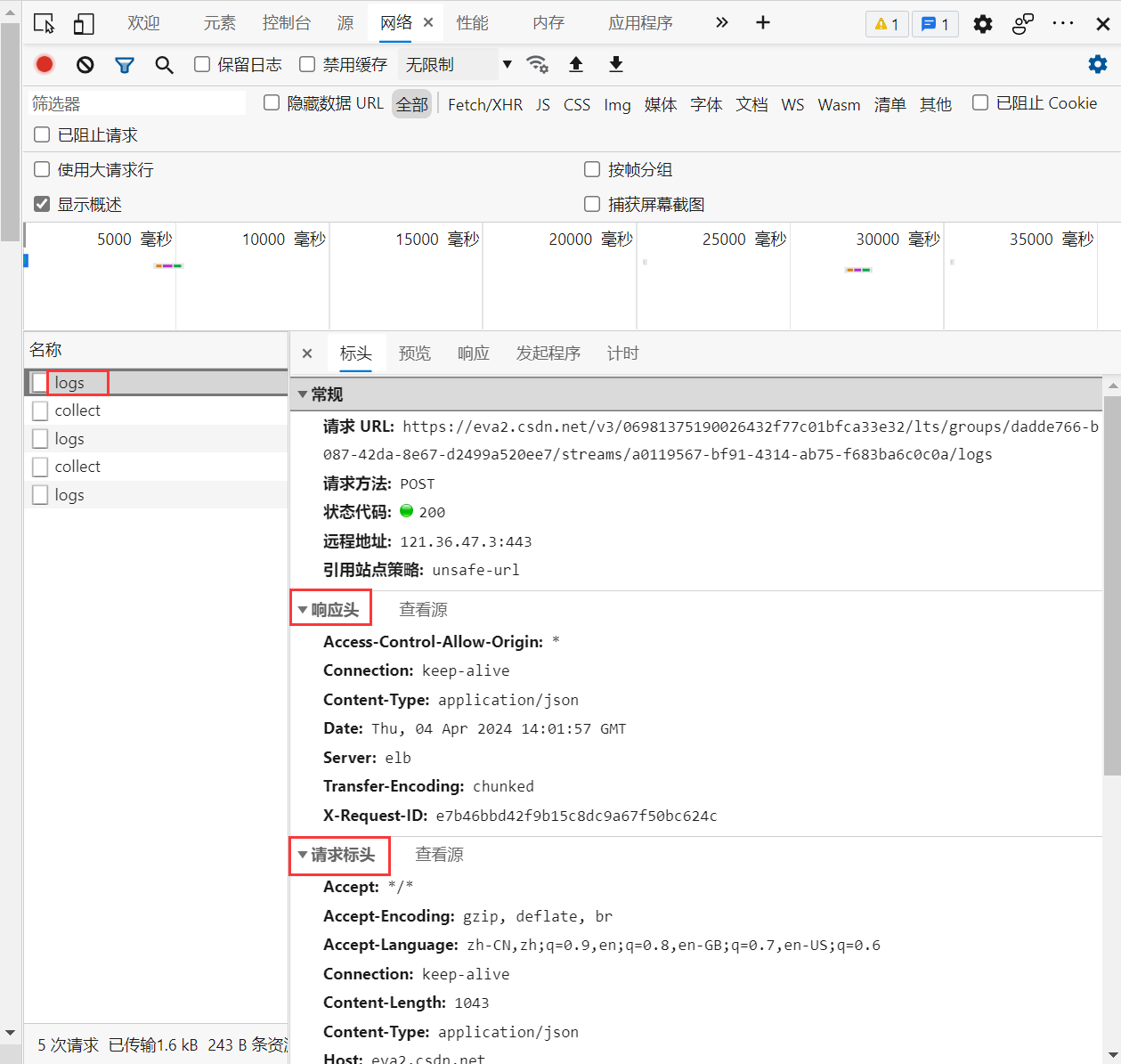
点击一个名称,即可看到其详细信息,包括请求头和响应头:
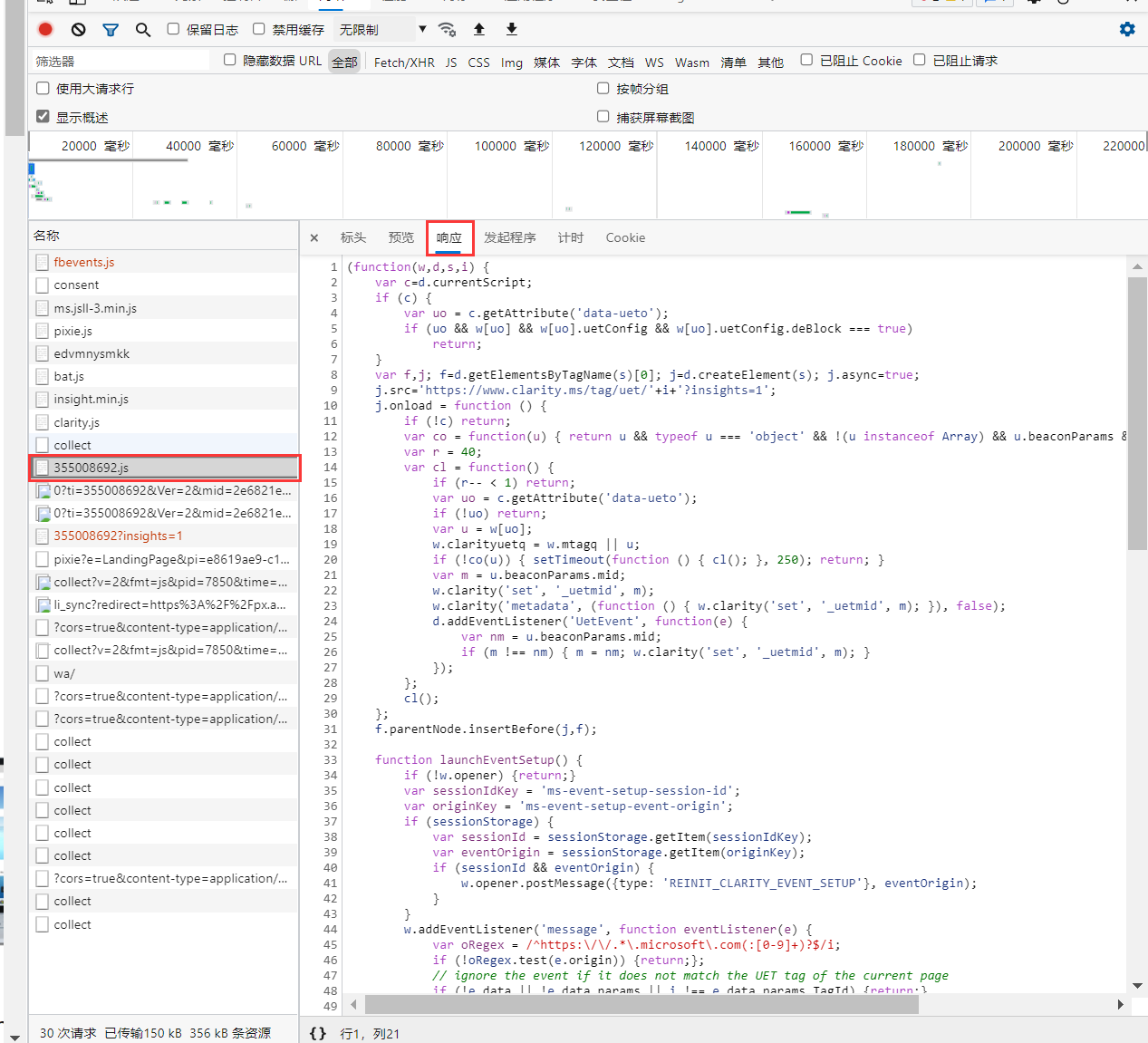
点击名称355008692.js,再选择“响应”,可以看到响应主体,即一个 javascript 文件内容:
六、python实现HTTP请求
下面例子中通过python实现HTTP请求,需要提前安装request库。
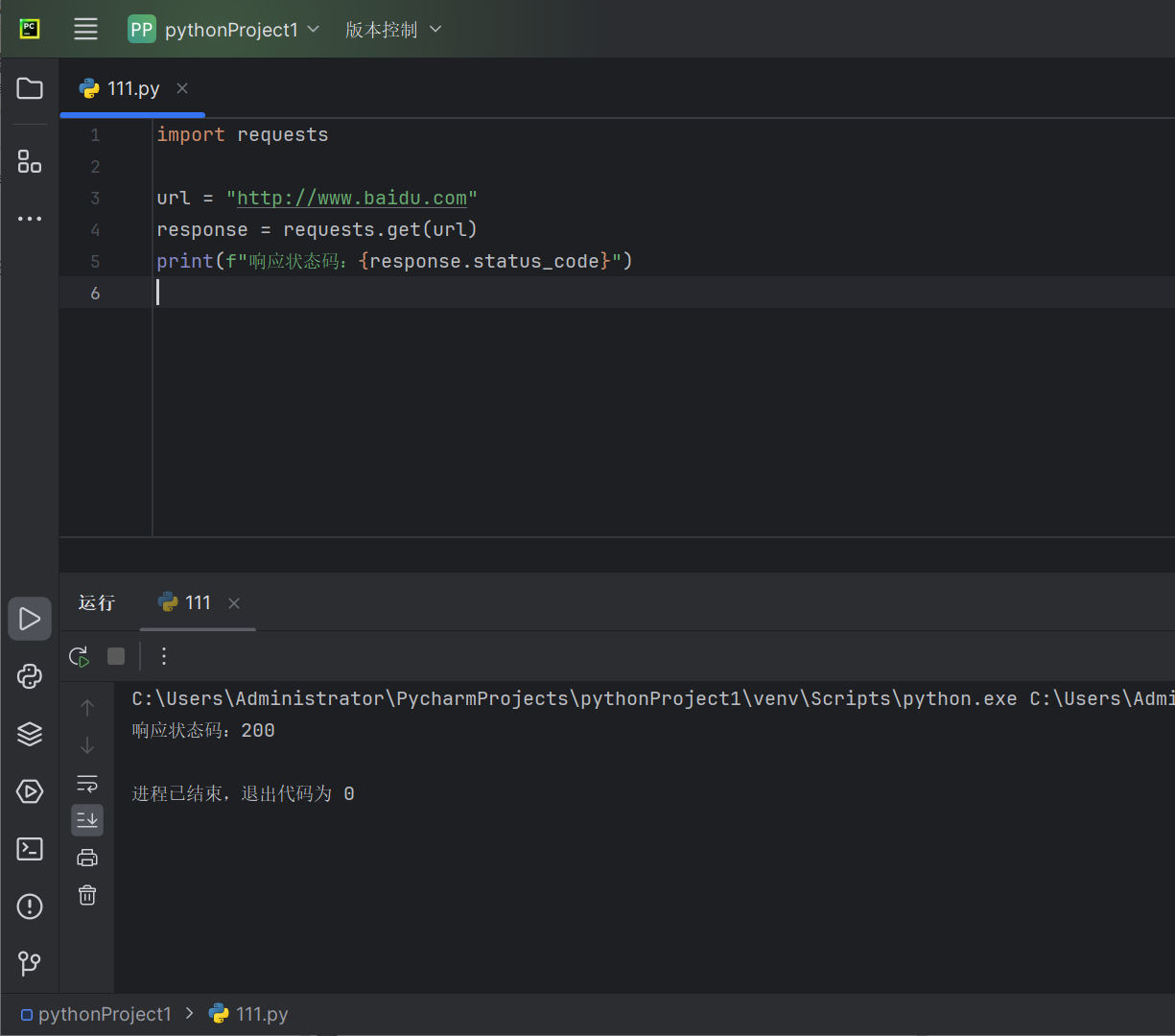
例如,对百度网址www.baidu.com实现一个HTTP请求,代码如下:
import requests
url = "http://www.baidu.com"
response = requests.get(url)
print(f"响应状态码:{response.status_code}")
上述代码是通过get()方法发送一个GET请求到http://www.baidu.com,并返回一个response对象,并print打印出响应状态码,可以看到,返回的状态码是200,是成功的:
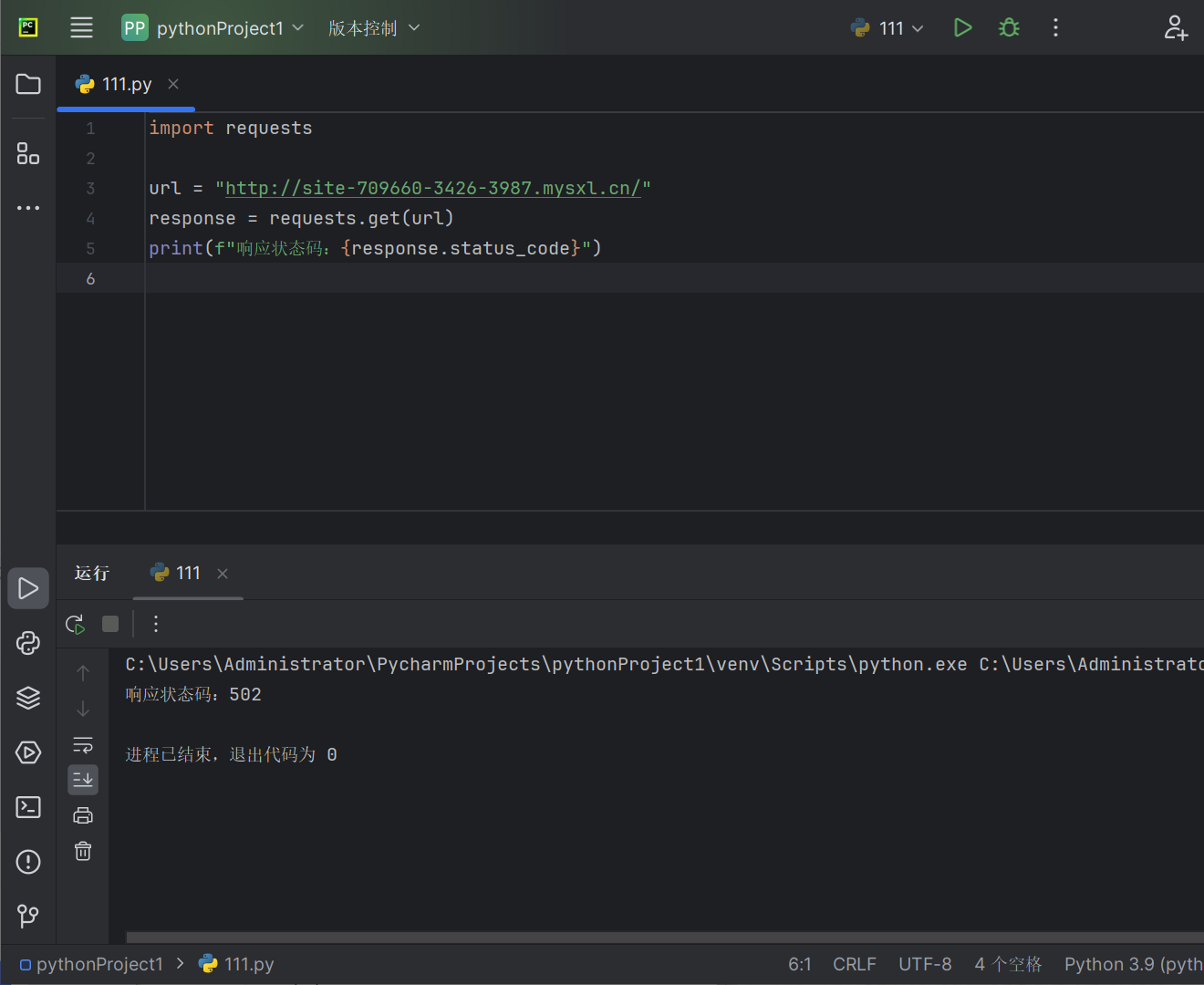
而下面这个网页所返回的状态码是“502”,则有可能是服务器获取网页内容错误或者其他问题:
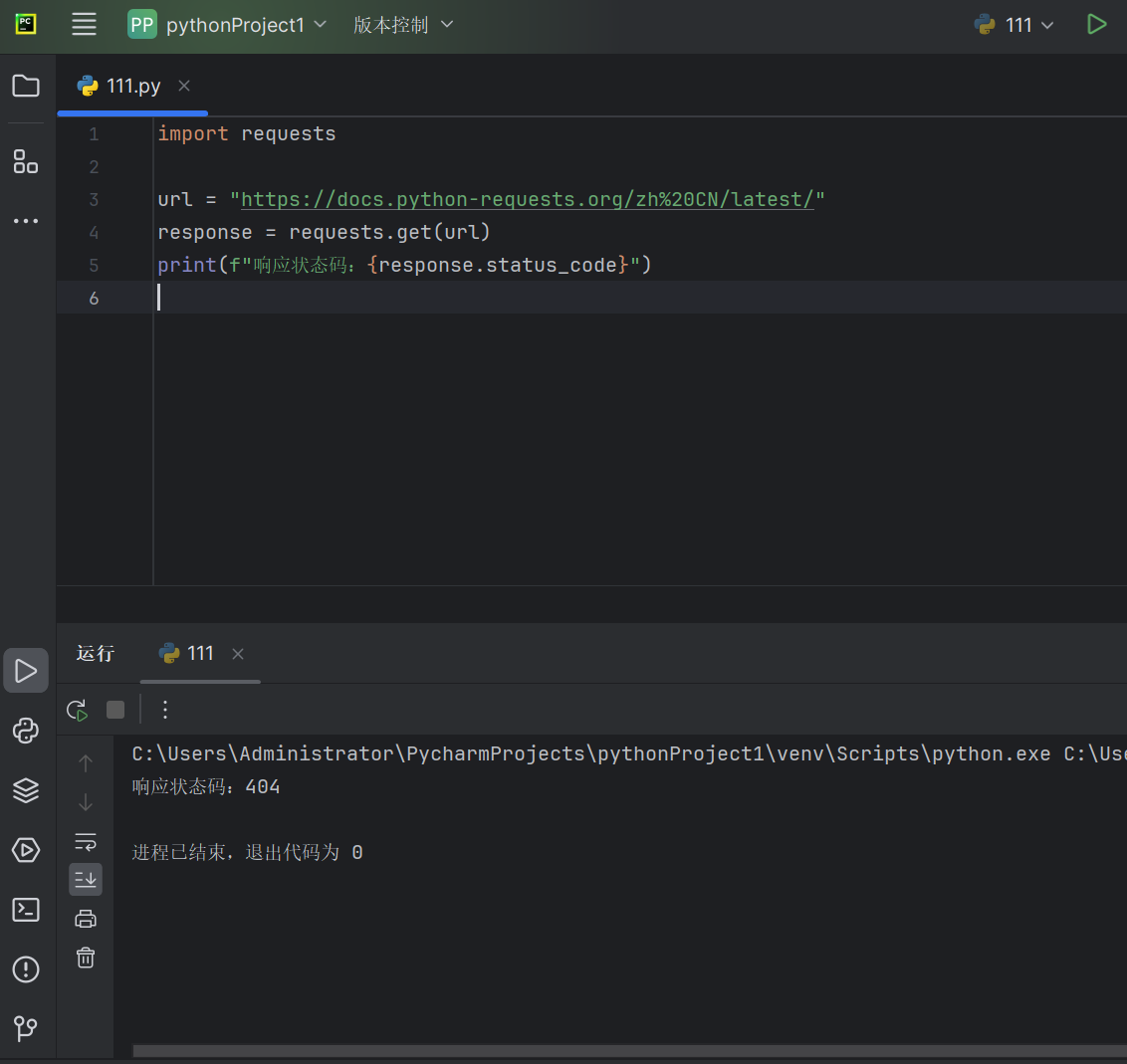
如果访问的网页已经不存在或者网页被开发者删除等,则会显示404代码,如下访问了一个已经不存在的网页,则会有以下状态码显示:
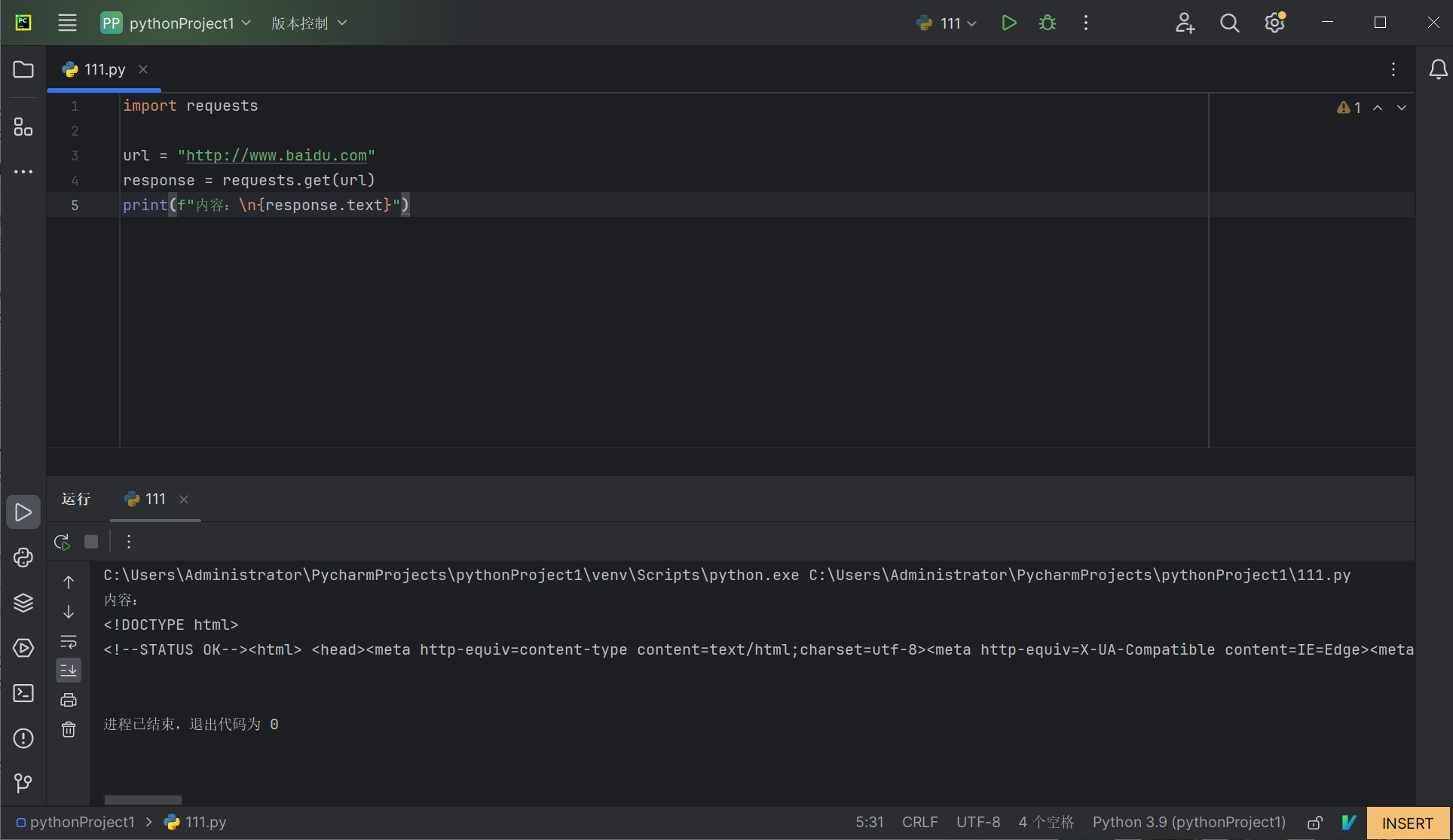
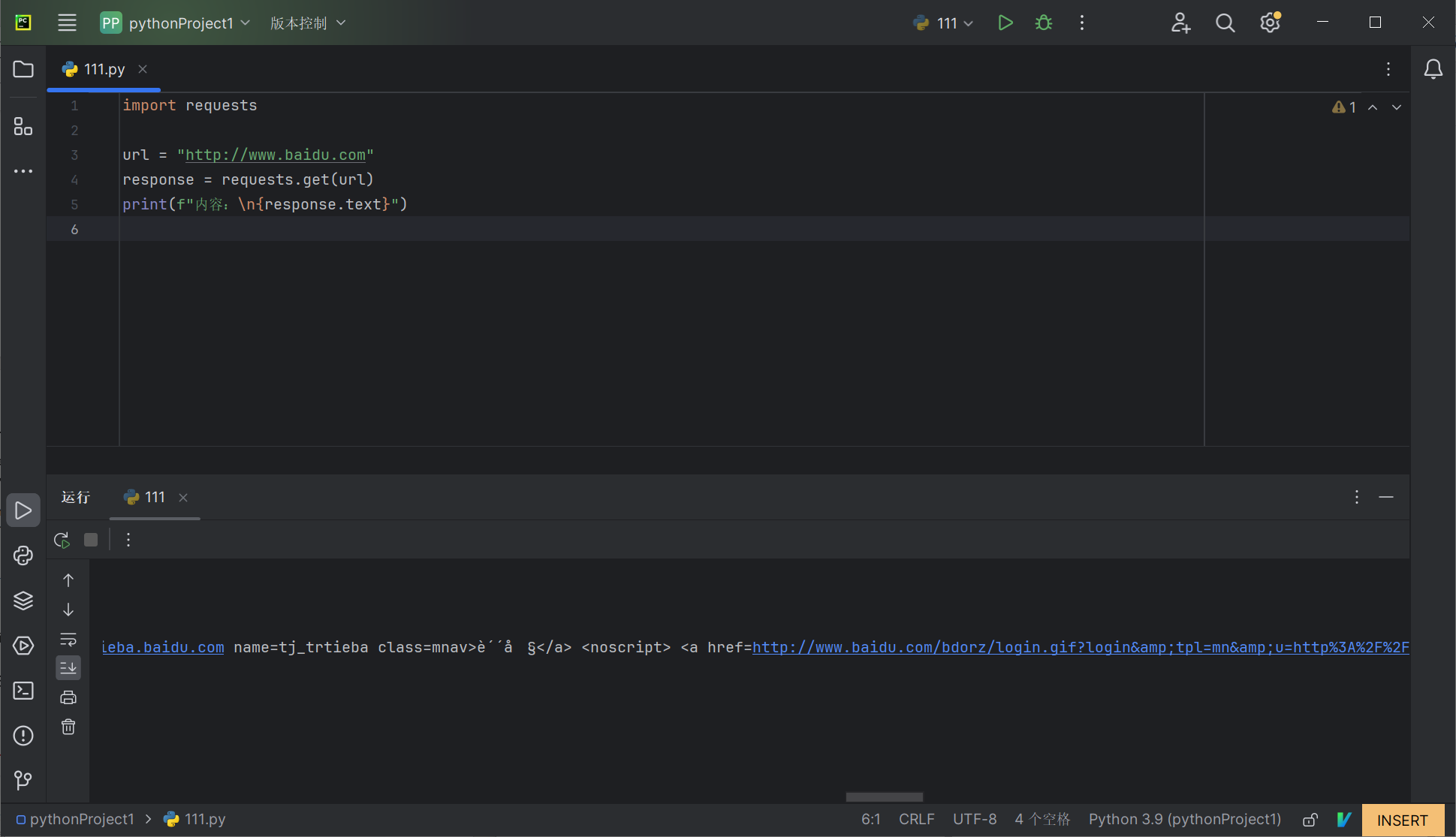
另外,也可以查看响应的文本内容,通过requests的text属性查看,代码如下:
import requests
url = "http://www.baidu.com"
response = requests.get(url)
print(f"内容:\n{response.text}")
返回了HTML内容,这就是获取的HTML源码,如下图: