目录
- 一、自定义多头注意力机制
- 1. 缩放点积注意力(Scaled Dot-Product Attention)
- ● 计算公式
- ● 原理
- 2. 多头注意力机制框图
- ● 具体代码
- 二、pytorch中的子注意力机制模块
深度学习中的注意力机制(Attention Mechanism)是一种模仿人类视觉和认知系统的方法,它允许神经网络在处理输入数据时集中注意力于相关的部分。通过引入注意力机制,神经网络能够自动地学习并选择性地关注输入中的重要信息,提高模型的性能和泛化能力。
下图 展示了人类在看到一幅图像时如何高效分配有限注意力资源的,其中红色区域表明视觉系统更加关注的目标,从图中可以看出:人们会把注意力更多的投入到人的脸部。文本的标题以及文章的首句等位置。而注意力机制就是通过机器来找到这些重要的部分。

一、自定义多头注意力机制
1. 缩放点积注意力(Scaled Dot-Product Attention)
缩放点积注意力(Scaled Dot-Product Attention)是注意力机制的一种形式,通常在自注意力(self-attention)机制或多头注意力机制中使用,用于模型在处理序列数据时关注输入序列中不同位置的信息。这种注意力机制常用于Transformer模型及其变体中,被广泛用于各种自然语言处理任务,如机器翻译、文本生成和问答系统等。
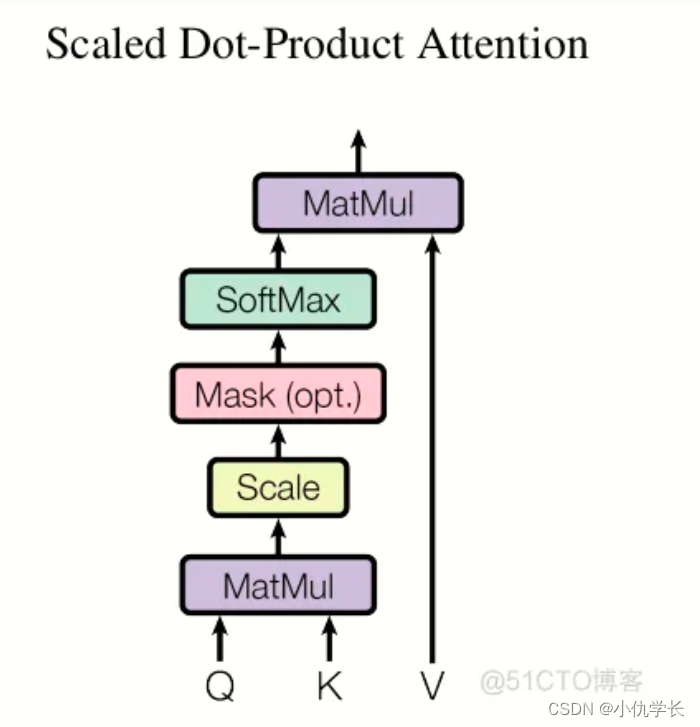
● 计算公式
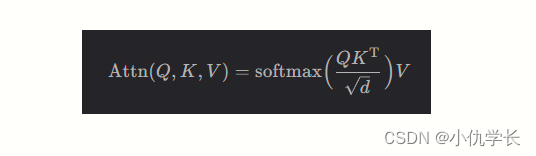
● 原理
假设输入:给定一个查询向量(query)、一组键向量(keys)和一组值向量(values)。
(1)Dot-Product 计算相似度:通过计算查询向量query与键向量keys之间的点积,得到每个查询与所有键的相似度分数。然后将这些分数进行缩放(scale)–除以根号下d_k,以防止点积的值过大,从而导致梯度消失或梯度爆炸。
(2)Mask 可选择性 目的是将 padding的部分 填充负无穷,这样算softmax的时候这里就attention为0,从而避免padding带来的影响.
(3)Softmax归一化:对相似度分数进行softmax归一化,得到每个键的权重,这些权重表示了对应值向量的重要程度。
加权求和:使用这些权重对值向量进行加权求和,得到最终的注意力输出。
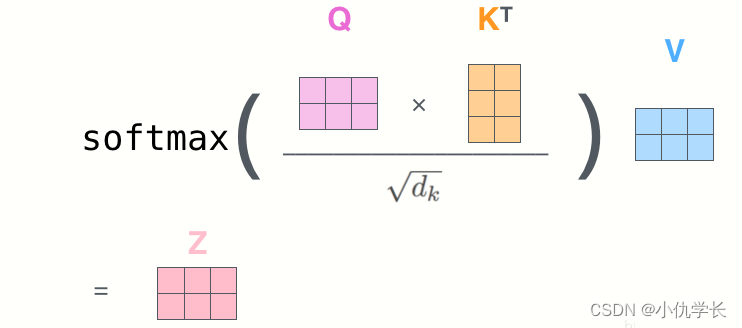
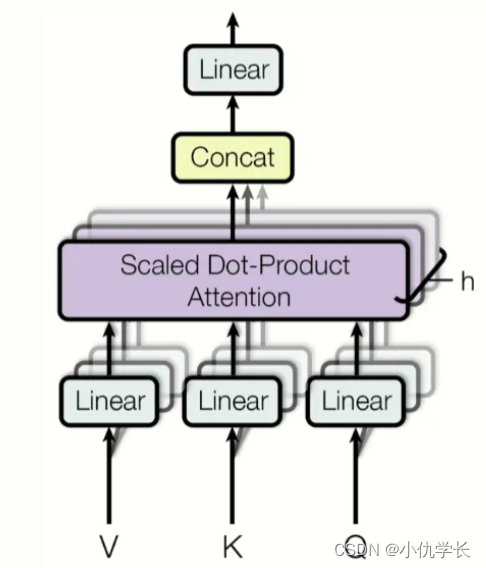
2. 多头注意力机制框图
多头注意力机制是在 Scaled Dot-Product Attention 的基础上,分成多个头,也就是有多个Q、K、V并行进行计算attention,可能侧重与不同的方面的相似度和权重。
● 具体代码
import torch
import torch.nn as nn
import numpy as np
import torch.nn.functional as F
class MultiHeadAttention(nn.Module):
#embedding_dim:输入向量的维度,num_heads:注意力机制头数
def __init__(self, embedding_dim, num_heads):
super(MultiHeadAttention, self).__init__()
self.num_heads = num_heads #总头数
self.embedding_dim = embedding_dim #输入向量的维度
self.d_k= self.embedding_dim// self.num_heads #每个头 分配的输入向量的维度数
self.softmax=nn.Softmax(dim=-1)
self.W_query = nn.Linear(in_features=embedding_dim, out_features=embedding_dim, bias=False)
self.W_key = nn.Linear(in_features=embedding_dim, out_features=embedding_dim, bias=False)
self.W_value = nn.Linear(in_features=embedding_dim, out_features=embedding_dim, bias=False)
self.fc_out = nn.Linear(embedding_dim, embedding_dim)
#输入张量 x 中的特征维度分成 self.num_heads 个头,并且每个头的维度为 self.d_k。
def split_head(self, x, batch_size):
x = x.reshape(batch_size, -1, self.num_heads, self.d_k)
return x.permute(0,2,1,3) #x (N_size, self.num_heads, -1, self.d_k)
def forward(self, x):
batch_size=x.size(0) #获取输入张量 x 的批量(batch size)大小
q= self.W_query(x)
k= self.W_key(x)
v= self.W_value(x)
#使用 split_head 函数对 query、key、value 进行头部切分,将其分割为多个注意力头。
q= self.split_head(q, batch_size)
k= self.split_head(k, batch_size)
v= self.split_head(v, batch_size)
##attention_scorce = q*k的转置/根号d_k
attention_scorce=torch.matmul(q, k.transpose(-2,-1))/torch.sqrt(torch.tensor(self.d_k, dtype=torch.float32))
attention_weight= self.softmax(attention_scorce)
## output = attention_weight * V
output = torch.matmul(attention_weight, v) # [h, N, T_q, num_units/h]
output = out.permute(0,2,1,3).contiguous() # [N, T_q, num_units]
output = out.reshape(batch_size,-1, self.embedding_dim)
output = self.fc_out(output)
return output
二、pytorch中的子注意力机制模块
nn.MultiheadAttention是PyTorch中用于实现多头注意力机制的模块。它允许你在输入序列之间计算多个注意力头,并且每个头都学习到了不同的注意力权重。
创建了一些随机的输入数据,包括查询(query)、键(key)、值(value)。接着,我们使用multihead_attention模块来计算多头注意力,得到输出和注意力权重。
请注意,你可以调整num_heads参数来控制多头注意力的头数,这将会影响到模型的复杂度和表达能力。
import torch
import torch.nn as nn
# 假设我们有一些输入数据
# 输入数据形状:(序列长度, 批量大小, 输入特征维度)
input_seq_length = 10
batch_size = 3
input_features = 32
# 假设我们的输入序列是随机生成的
input_data = torch.randn(input_seq_length, batch_size, input_features)
# 定义多头注意力模块
# 参数说明:
# - embed_dim: 输入特征维度
# - num_heads: 多头注意力的头数
# - dropout: 可选,dropout概率,默认为0.0
# - bias: 可选,是否在注意力计算中使用偏置,默认为True
# - add_bias_kv: 可选,是否添加bias到key和value,默认为False
# - add_zero_attn: 可选,是否在注意力分数中添加0,默认为False
multihead_attention = nn.MultiheadAttention(input_features, num_heads=4)
# 假设我们有一个query,形状为 (查询序列长度, 批量大小, 输入特征维度)
query = torch.randn(input_seq_length, batch_size, input_features)
# 假设我们有一个key和value,形状相同为 (键值序列长度, 批量大小, 输入特征维度)
key = torch.randn(input_seq_length, batch_size, input_features)
value = torch.randn(input_seq_length, batch_size, input_features)
# 计算多头注意力
# 返回值说明:
# - output: 注意力计算的输出张量,形状为 (序列长度, 批量大小, 输入特征维度)
# - attention_weights: 注意力权重,形状为 (批量大小, 输出序列长度, 输入序列长度)
output, attention_weights = multihead_attention(query, key, value)
# 输出结果
print("Output shape:", output.shape)
print("Attention weights shape:", attention_weights.shape)