频繁项集挖掘可以说是数据挖掘中的重点,下面我们来分析以下频繁项集挖掘的过程和目标
如果对数据挖掘没有概念的小伙伴可以查看上次的文章
https://blog.csdn.net/qq_31236027/article/details/137046475
什么是频繁项集?
在回答这个问题之前,我们可以看一个例子:
小明、小刚、小红三人去同一家商店购物,小明、小刚两人购买了鸡蛋,牛奶和面包,小红购买了鸡蛋和牛奶,这时候一位聪明的店员便推荐小红购买面包,并且说这个面包很适合购买了鸡蛋和牛奶的客户,小红心动了。
在这个例子中,我们可以看到小明、小刚和小红都有去购买商品的行为,而其中的每一个商品可以称为一个项,小明、小刚、小红所购买的商品的集合就成为项集。那么什么是频繁项集呢?所谓的频繁项集理解起来也相对容易了,就是用户频繁购买的商品的集合,也就是说会被大部分用户购买的商品的集合。显而易见,在例子中鸡蛋、牛奶可以称为一个频繁项集。
频繁项集有啥用处?
再次回到之前的那个例子中,那个聪明的店员根据小明和小刚的购买记录进行商品的推荐,这个就利用到了频繁项集的一个优势:允许系统(店员)利用已有的频繁项集(顾客的购买记录) 针对某一客户进行商品推荐。那么为什么可以这么做呢?这么做的依据是什么呢?下面让我们来看一下频繁项集挖掘的过程。
频繁项集挖掘过程
先上个例子(基于Apriori):
已知
用户B收藏了物品A、B、C,
用户C收藏了物品A、D,
用户D收藏了物品A、B、C、D,
用户E收藏了物品A、B、E
用户A收藏了物品A、B,现在需要针对用户A进行物品推荐。
- 首先我们选取一个集合,就设置为{物品A}
- 我们不难发现购买了物品A的用户3/4都收藏了物品B,这时候我们可以设定一个阈值,只有频率(出现次数)超过这个值的项集才会被保留,这个值又称作最小支持度(min_support)。假设最小支持度为0.5, 也就是说物品D不会被推荐,因为只有一个用户在收藏了物品A后收藏了物品D(是用户C), 收藏D的后验概率为1/3 < 0.5。
- 于是集合扩容为{物品A,物品B}
- 之后而我们推出收藏了物品A、B后收藏物品C的概率为 1/2,也就是{用户B,用户D}/ {用户B,用户C,用户D、用户E},而用户收藏A、B、E的概率为1/4 < 0.5 因此不被保留
- 集合扩容为{物品A,物品B,物品C}
- 因为购买物品A,物品B,物品C后购买物品D的项集只出现1次,1/4 < min_support = 0.5 因此,该项集非频繁项集,因此最大频繁项集为{物品A,物品B,物品C}
- 之后针对用户A进行推荐,这时候需要逐层进行筛选,不难得出{物品A,物品B} => {物品A,物品B,物品C} 的概率为2/3,超过了我们设定的第二个阈值,称为最小置信度(也就是最小关联度),而{物品A,物品B} = > {物品A,物品B,物品E} 的概率为1/3 < 0.5 。不推荐。因此会向用户A推荐物品C,
Apriori算法
好了,朋友们,看到了现在这一步可以恭喜你已经初步了解频繁项集的挖掘过程了。
下面我们来看一下Apriori的算法:
package apriori;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
/**
* apriori算法
* @author zygswo
*
*/
public class Apriori {
/**
* 最小支持度
*/
private static final double MIN_SUPPORT = 0.5;
/**
* 最小置信度
*/
private static final double MIN_FAITH = 0.5;
/**
* 算法核心
* @param trainDataSet 训练集
* @param usersCollection 用户喜好
* @return
*/
private static List<String>
getResult(Map<String,String[]> trainDataSet,String[] usersCollection) {
//1.训练集训练
Map<String,Double> res = new ConcurrentHashMap<String,Double>();
res = trainData(res,trainDataSet);
System.out.println(res.toString());
//2.推荐
return recommend(res, usersCollection);
}
/**
* 推荐
* @param res
* @param usersCollection
* @return
*/
private static List<String> recommend(Map<String, Double> res, String[] usersCollection) {
// TODO Auto-generated method stub
String key = "";
List<String> list = new ArrayList<>();
for (String str: usersCollection) {
key += str;
}
double countNb = res.get(key);
for (String str: res.keySet()) {
if (str.length() != key.length() + 1) {
continue;
}
boolean contains = true;
for (char ch : key.toCharArray()) {
if (str.indexOf(ch) == -1) {
contains = false;
break;
}
}
if (contains){
if (res.get(str) /countNb * 1.0 >= MIN_FAITH) {
System.out.println(key + " -->" + str + " faith = " + res.get(str) / countNb * 1.0);
list.add(str.replace(key, ""));
}
}
}
return list;
}
/**
* 训练训练集
* @param res
* @param trainDataSet
* @return
*/
private static Map<String, Double> trainData(
Map<String, Double> res,
Map<String, String[]> trainDataSet) {
res.putAll(trainData(trainDataSet.size(),0, res, trainDataSet));
return res;
}
/**
* 训练训练集
* @param initSize 初始数组长度
* @param roundNb 轮数
* @param res 结果map
* @param trainDataSet 训练数据集
* @return
*/
private static Map<String, Double> trainData(
int initSize,
int roundNb,
Map<String,Double> res,
Map<String,String[]> trainDataSet
) {
//统计
// System.out.println("roundNb = " + roundNb);
for (String[] itemArr : trainDataSet.values()) {
//获取当前用户的收藏item集合,也就是获取项集
String tempStr = "";
for (String item:itemArr) {
tempStr += item;
}
//针对项集统计频率
if (roundNb == 0) {
for (String item:itemArr) {
if (res.get(item) == null) {
res.put(item, 1.0);
} else {
res.put(item, res.get(item) + 1.0);
}
}
} else {
for (String resStr : res.keySet()) {
//如果字符串长度不为roundNb+1就说明不是当前的那层项集
if (resStr.length() != roundNb + 1) {
continue;
}
boolean contains = true;
for (char ch : resStr.toCharArray()) {
if (tempStr.indexOf(ch) == -1) {
contains = false;
break;
}
}
if (contains){
res.put(resStr, res.get(resStr) + 1.0);
}
}
}
}
//筛选
for (String str:res.keySet()) {
if (res.get(str) < MIN_SUPPORT * initSize) {
res.remove(str);
}
}
//新增
Map<String,Double> newRes = new ConcurrentHashMap<String, Double>();
for (String str:res.keySet()) {
if (str.length() != roundNb + 1) {
continue;
}
for (String substr:res.keySet()) {
//每次获取一位,之后叠加
if (substr.length() != 1) {
continue;
}
String lastChar = str.charAt(str.length() - 1) + "";
//判断大小,只允许字符串递增排列,如AC,AB,AD,CD
if(substr.compareTo(lastChar) > 0) {
newRes.put(str+substr, 0.0);
}
}
}
if (newRes.isEmpty()) {
return res;
} else {
res.putAll(newRes);
return trainData(initSize,roundNb+1,res,trainDataSet);
}
}
public static void main(String[] args) {
Map<String,String[]> trainDataSet = new ConcurrentHashMap<>();
trainDataSet.put("userB", new String[]{"A","B","C"});
trainDataSet.put("userC", new String[]{"A","D"});
trainDataSet.put("userD", new String[]{"A","B","C","D"});
trainDataSet.put("userE", new String[]{"A","B","E"});
trainDataSet.put("userF", new String[]{"A","B","C","E"});
System.out.println("推荐结果为" + getResult(trainDataSet,new String[]{"A","B"}));
}
}
运行截图
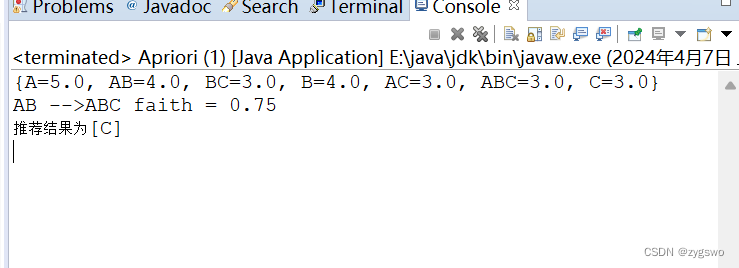
—————————————未完待续,代码解析之后再讲—————————————————————