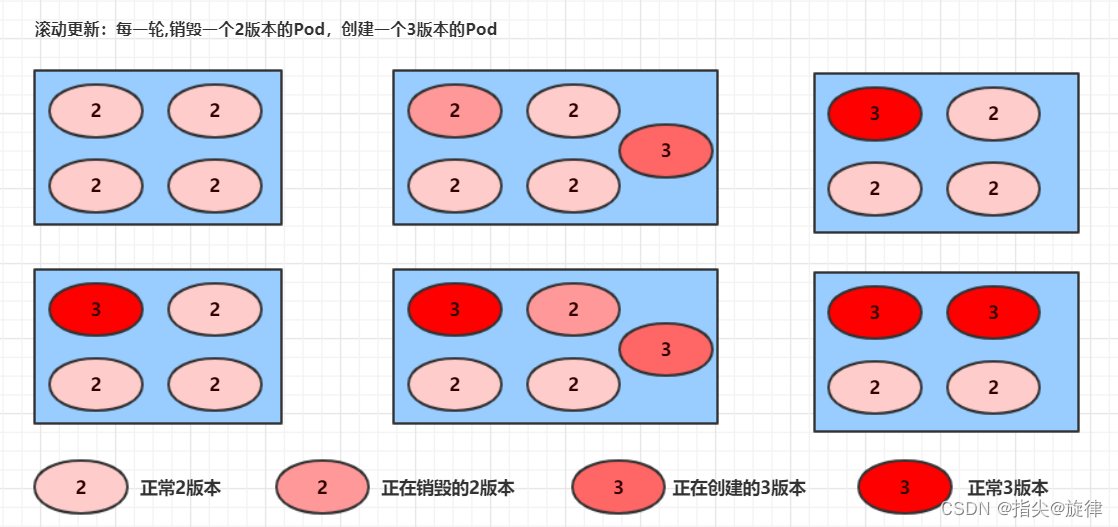
😀大家好,我是白晨,一个不是很能熬夜😫,但是也想日更的人✈。如果喜欢这篇文章,点个赞👍,关注一下👀白晨吧!你的支持就是我最大的动力!💪💪💪

文章目录
- 📘前言
- 📙Trie
- 🧧Trie的定义
- 🎈Trie字符串统计
- 🎆Trie数字储存
- 📗后记
📘前言
大家好呀,我是白晨🕶️。又到了白晨日常摆烂,不定时更新的时间了😂。

本次要带大家认识的的是 Trie ,这是一个便于快速查询字符串等数据出现次数的数据结构,在算法竞赛中也是一个比较好用的结构。虽然使用 unordered_map 也能实现类似功能,但是 Trie 更加节省空间并且在存储数字等结构,它还有 unordered_map 无法代替的优势,这里先买个关子,在下面文章中我会详细讲解。
📙Trie
🧧Trie的定义
Trie字典树又叫前缀树(prefix tree),用以较快速地进行单词或前缀查询。Trie树本质上就是一棵多叉树,用来存储字符串或者其他数据。
- 下图为一棵Trie树:

上图为一棵已经构建好的Trie树,观察可得,Trie树从按单词从左到右,从上到下构建一棵树,每层为一个字母。如果插入的单词有相同的前缀(前面为相同字母),那么相同的前缀只会出现一次,并且在相同前缀的最后一个字母分叉出不同子节点。
从根结点到叶结点就为一个单词,但是,如果我们插入 the 这个单词并且查找该单词,我们应该怎么办呢?
观察得,the 的前缀和 there 前缀无法区分,所以我们可以在每个结点上增设一个数cnt用于保存以该结点结尾的单词数量。
- 查找操作:

上图为一个已经构建好的Trie树,例如,我们要查找 there 这个单词,从根节点开始,t这个子节点存在,跳转到t这个结点,继续查找t结点的子节点h,查找成功继续跳转,如果每个字符都有子节点并且在末尾字母e对应的结点的中cnt数据不为0,那么此节点存在。
如果为查找目标th,虽然每个结点都可以找到,但是结尾字母h的cnt为0,此单词不存在。
- 插入操作

按照单词从左到右,层数从上到下插入字符即可,前缀相同的单词只会被插入一次(见下例)。

接下来,我们用几道例题来讲解Trie树的实现以及使用。
🎈Trie字符串统计

🍬原题链接:Trie字符串统计
🪅算法思想:
按照字典树的结构进行插入和查询即可,主要注意实现。
具体实现见下面代码。
🪆代码实现:
- 树形实现
此种实现较为好理解,我们使用静态结点,每一个结点固定开辟26个子节点指针,方便存储子节点和维护数据结构。
// 使用树形类实现
#include <iostream>
#include <string>
#include <vector>
using namespace std;
// Trie树结点
struct Node
{
Node()
:cnt(0)
{
for (int i = 0; i < 26; ++i) son[i] = nullptr;
}
Node* son[26]; // 0~25 分别对应 a~z
int cnt; // 以当前结点结尾的单词数量
};
// Trie树结构
class Trie
{
public:
Trie()
{
head = new Node;
}
// 插入字符串
void insert(const string& s)
{
// 当前遍历的结点
Node* cur = head;
for (int i = 0; i < s.size(); ++i)
{
// 得到当前字符对应的映射位置
int pos = s[i] - 'a';
// 没有子节点时,插入子节点
if (cur->son[pos] == nullptr) cur->son[pos] = new Node;
cur = cur->son[pos]; // 遍历到对应映射的结点
}
cur->cnt++; // 以当前结点为结尾的单词数++
}
int query(const string& s)
{
// 当前遍历的结点
Node* cur = head;
for (int i = 0; i < s.size(); ++i)
{
int pos = s[i] - 'a';
// 没有子节点时,返回0
if (cur->son[pos] == nullptr) return 0;
cur = cur->son[pos];
}
return cur->cnt;
}
private:
Node* head;
};
int main()
{
ios::sync_with_stdio(false);
cin.tie(nullptr);
int n;
cin >> n;
Trie t;
while (n--)
{
string op, s;
cin >> op >> s;
if (op == "I") t.insert(s);
else cout << t.query(s) << endl;
}
return 0;
}
- 模拟树形结构实现
这种结构比较抽象,是使用数组模拟树形结构,这种实现方法不易理解,但是代码较短,速度更快,更适合算法竞赛使用。
这里我们先来了解一下数组模拟单链表:
#include <iostream>
using namespace std;
const int N = 100010;
int v[N], ne[N]; // v数组存放结点值,ne存放下一个结点的下标
// 相当于把一个单链表结点拆开,前面v数组存储数据,后面ne结点存储子节点的指针
int head, idx; // head为头节点的下标,idx为当前可使用结点的下标
// idx是理解模拟单链表的重点,我们提前开辟了两个数组v和ne,这两个数组可以看为一个结点集合
// 我们应该如何使用结点集合呢?
// 我们可以选择顺序使用,先使用前面的结点,后使用后面的结点,如何确定我们使用到哪一个结点了呢?
// 我们需要一个idx存储当前使用到哪一个结点了,这样可以保证我们使用结点都是顺序使用的
// 初始化
void init()
{
head = -1;
idx = 0;
}
// 在头节点前插入结点
void add_to_head(int x)
{
// idx为使用的新结点下标
v[idx] = x;
ne[idx] = head; // idx结点现在为头结点,所以它的子节点为以前的子节点
head = idx++;// 头节点更新,idx转移到下一个待使用的结点
}
// 在下标为k的结点后面插入
void add(int k, int x)
{
v[idx] = x;
ne[idx] = ne[k]; // 新节点存储k结点原来的孩子
ne[k] = idx++; // k结点的子节点改为idx结点,idx转移到下一个待使用的结点
}
// 删除下标为k节点后面的结点
// 我们是单链表,所以方便寻找k节点的子节点,不方便删除前驱节点
void remove(int k)
{
ne[k] = ne[ne[k]]; // k节点的子节点指向k节点子节点的子节点
}
在上面模拟单链表的基础上再看模拟Trie树:
#include <iostream>
#include <string>
using namespace std;
const int N = 100010;
int Trie[N][26]; // Trie树,利用类似于单链表的方式模拟树形结构,Trie[i]就是一个结点,而Trie[i][26]为每个节点存储的子节点下标,相当于静态节点的26个子节点指针
int cnt[N]; // 统计以Trie树的第N个结点所代表的字母结尾的单词数量
int idx = 0; // 与单链表的idx类似,由于Trie树是利用二维数组模拟的,每一个Trie[i]为一个结点
// 所以要让二维数组表示出树形关系,就得让父节点指向子节点的下标,idx代表当前使用到了哪一个结点,每使用一个结点,idx++。
// 初始除了头结点(Trie[0])以外,其他结点都没有使用,所以idx = 0。
int n;
void insert(const string& s)
{
int p = 0; // 从头结点开始遍历
for (int i = 0; i < s.size(); ++i)
{
int pos = s[i] - 'a'; // 下标映射
// 如果该字母没有被插入到当前结点下,将其插入(启用一个新节点,将新节点的下标保存到父节点)
// 当Trie[p][pos] 的值为0时,代表当前位置没有子节点
if (!Trie[p][pos]) Trie[p][pos] = ++idx;
p = Trie[p][pos]; // 跳转到子节点,从子节点继续插入
}
cnt[p]++; // 以下标为p结点结尾的单词数量加1
}
int query(const string& s)
{
int p = 0;
for (int i = 0; i < s.size(); ++i)
{
int pos = s[i] - 'a';
// 当Trie[p][pos] 的值为0时,代表当前位置没有子节点,也说明当前字母查找失败
if (!Trie[p][pos]) return 0;
p = Trie[p][pos]; // 有子节点,继续查找
}
return cnt[p];
}
int main()
{
ios::sync_with_stdio(false);
cin.tie(nullptr);
cin >> n;
while (n--)
{
string op, s;
cin >> op >> s;
if (op == "I") insert(s);
else cout << query(s) << endl;
}
return 0;
}
🎆Trie数字储存

🍬原题链接:最大异或对
🪅算法思想:
- 类比字符串存储,一个int类型的整数为32位,规定存储的顺序为
数字二进制高位对应树中上层,低位对应树下层。
以二进制为8位的数举例,存储如下图:

-
异或要获得最大值,两个数字二进制最好每一位都是相反的,这样就是全1,但是可能没有完美符合条件的数对,所以我们要找到高位尽量不同,低位可以相同的数对。
翻译成Trie树的操作就是:确定一个数
x,从高位开始遍历这个数的二进制,如果该节点存在和 该数二进制位逻辑取反的子节点对应的数 的子节点,那么跳转到该子节点继续重复上述逻辑;如果没有,跳转到存在的子节点继续按上述逻辑遍历。
🪆代码实现:
- 树形结构实现
#include <iostream>
#include <string>
#include <vector>
using namespace std;
struct Node
{
Node()
{
for (int i = 0; i < 2; ++i) son[i] = nullptr;
}
Node* son[2];
};
class Trie
{
public:
Trie()
{
head = new Node;
}
void insert(int x)
{
Node* cur = head;
// 按位保存,高位为父节点
for (int i = 30; i >= 0; --i)
{
int pos = x >> i & 1;
if (!cur->son[pos]) cur->son[pos] = new Node;
cur = cur->son[pos];
}
}
int query(int x)
{
Node* cur = head;
int ret = 0;
// 按位保存,高位为父节点
for (int i = 30; i >= 0; --i)
{
int pos = x >> i & 1;
// 找尽量与x每一位相反的数
if (cur->son[!pos])
{
ret += 1 << i;
cur = cur->son[!pos];
}
else cur = cur->son[pos];
}
return ret;
}
private:
Node* head;
};
int main()
{
ios::sync_with_stdio(false);
cin.tie(nullptr);
int n;
cin >> n;
Trie t;
vector<int> v(n);
int ans = 0;
for (int i = 0; i < n; ++i) cin >> v[i], t.insert(v[i]);
for (int i = 0; i < n; ++i) ans = max(t.query(v[i]), ans);
cout << ans << endl;
return 0;
}
- 模拟树形结构实现
// 模拟实现
#include <iostream>
using namespace std;
const int N = 100010;
const int M = N * 32; // 一个数要31个结点,为了保险,一个数算32个结点,最多要用 32 * N个结点
int Trie[M][2], idx = 0; // Trie[i][2]是因为每个节点的子节点只有 0 和 1 两种,每个节点开辟两个空间存储对应子节点即可
int a[N]; // 存储输入的数据
void insert(int x)
{
int p = 0;
for (int i = 30; i >= 0; --i)
{
int pos = x >> i & 1;
if (!Trie[p][pos]) Trie[p][pos] = ++idx;
p = Trie[p][pos];
}
}
int query(int x)
{
int p = 0, ret = 0;
for (int i = 30; i >= 0; --i)
{
int pos = x >> i & 1;
if (Trie[p][!pos])
{
ret += 1 << i;
p = Trie[p][!pos];
}
else p = Trie[p][pos];
}
return ret;
}
int main()
{
int n, ans = 0;
scanf("%d", &n);
for (int i = 0; i < n; ++i) scanf("%d", &a[i]), insert(a[i]);
for (int i = 0; i < n; ++i) ans = max(ans, query(a[i]));
printf("%d", ans);
return 0;
}
📗后记
如果想了解哈希算法在于字符串上的应用,可以参考【算法】哈希表这篇文章,不同于Trie对于字符串的存储,哈希算法在处理字符串前缀时又是另外一种思路,两个思路分别有不同的的独特用处。
哈希算法除了可以处理字符串前缀以外,还可以快速查找字符串,时间复杂度可以达到O(1),比Trie快的多。但是,Trie的思想是很重要的,未来我们将会在更复杂的数据结构和算法中常常看到Trie的思想,还请大家一定要体会Trie结构中的前缀思想。
如果解析有不对之处还请指正,我会尽快修改,多谢大家的包容。
如果大家喜欢这个系列,还请大家多多支持啦😋!
如果这篇文章有帮到你,还请给我一个大拇指 👍和小星星 ⭐️支持一下白晨吧!喜欢白晨【算法】系列的话,不如关注👀白晨,以便看到最新更新哟!!!
我是不太能熬夜的白晨,我们下篇文章见。