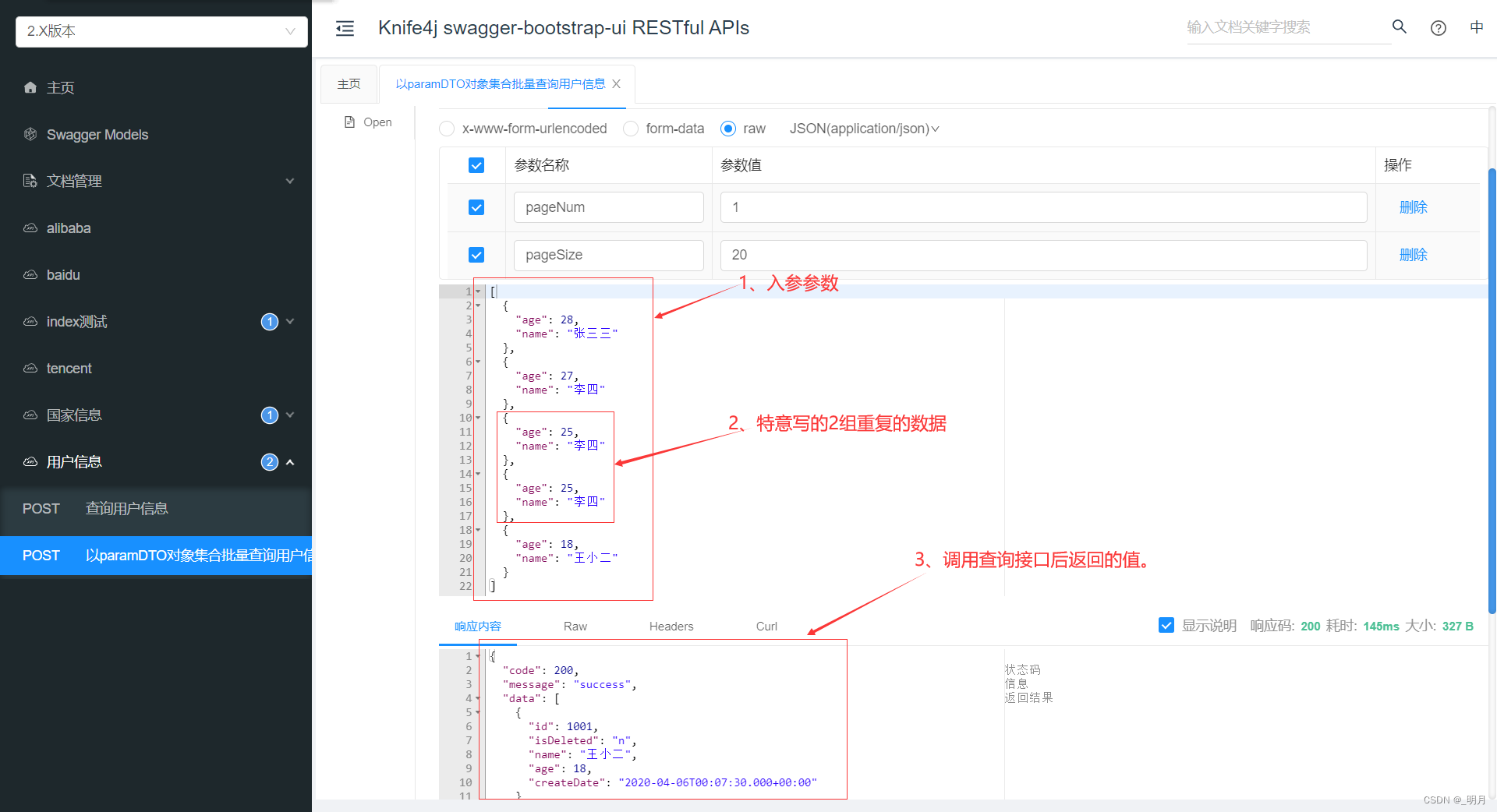
整除的总数
难度:白银
时间限制:1秒
巴占用内存:64M
输入正整数N和M,其中N<=M。求区间[N,M]中可被K整除的总数。
格式
输入格式:输入正整数N,M和K,空格分隔。
输出格式:输出整型
#include <bits/stdc++.h>>
using namespace std;
int main(){
int n,m,k;
cin >>n >>m >>k;
int num =0;
for (int i=n /k * k;i <=m;i = i+k)
if (i >= n) num++;
cout << num;
return 0;
}一切就绪后,服务器将从端口8000启动,你可以直接转到http://localhost:8000访问它!
有了这个,你就可以尝试GPT-2探测器模型了!
识别神经假新闻
探测器模型的接口非常简单。我们只需复制粘贴一段文本,它就会告诉我们它是“真的”还是“假的”,这取决于它是否由机器(GPT-2模型)生成。
以下是我使用Transformers 2.0库从GPT-2生成的文本:
如你所见,尽管文本看起来很有说服力和连贯性,但模型直接将其归类为“假的”,准确率为99.97%。
这是一个非常有趣的工具使用,我建议你去尝试不同的例子,生成和未生成的文本,看看它如何执行!
在我的例子中,我通常注意到这个模型只能很好地识别GPT-2模型生成的文本。这与Grover完全不同,Grover是我们将在下一节中学习的另一个框架。Grover可以识别由各种语言模型生成的文本。
你可以在Facebook的博客上关于RoBERTa的架构和训练方法。如果你对如何实现检测器模型感到好奇,可以在GitHub上检查代码。
Grover
Grover是我在本文讨论的所有选项中最喜欢的工具。与GLTR和GPT-2检测器模型仅限于特定模型不同,它能够将一段文本识别为由大量多种语言模型生成的伪文本。
作者认为,检测一段文本作为神经假新闻的最佳方法是使用一个模型,该模型本身就是一个能够生成此类文本的生成器。用他们自己的话说:
“生成器最熟悉自己的习惯、怪癖和特性,也最熟悉类似人工智能模型的特性,特别是那些接受过类似数据训练的人工智能模型。”–Zellers等人
乍一看听起来有违直觉,不是吗?为了建立一个能够检测出神经假新闻的模型,他们继续开发了一个模型,这个模型一开始就非常擅长生成这样的假新闻!
听起来很疯狂,但背后有自己的一个科学逻辑。
Grove是怎么工作的?
问题定义
Grover将检测神经假新闻的任务定义为一个具有两个模型的对抗游戏:
设置中有两个模型用于生成和检测文本
对抗模型的目标是产生虚假的新闻,这些新闻可以是病毒性传播的,或者对人类和验证模型都有足够的说服力
验证器对给定文本是真是假进行分类:
验证者的训练数据包括无限的真实新闻,但只有一些来自特定对手的假新闻
这样做是为了复制真实世界的场景,在真实世界中,对手提供的虚假新闻数量与真实新闻相比要少得多
这两种模式的双重目标意味着,攻击者和捍卫者之间在“竞争”,既产生虚假新闻,又同时发现虚假新闻。随着验证模型的改进,对抗模型也在改进。
神经假新闻的条件生成
神经假新闻的最明显特征之一是它通常是“有针对性的”内容,例如点击诱饵或宣传,大多数语言模型(例如BERT等)都不允许我们创建这种受控文本。
Grover支持“受控”文本生成。这仅仅意味着除了模型的输入文本之外,我们可以在生成阶段提供额外的参数。这些参数将引导模型生成特定的文本。
但这些参数是什么?考虑一下新闻文章——有助于定义新闻文章的结构参数是什么?以下是Grover的作者认为生成文章所必需的一些参数:
领域:文章发布的地方,它间接地影响样式
日期:出版日期
作者:作者姓名
标题:文章的标题,这影响到文章的生成
正文:文章的正文
结合所有这些参数,我们可以通过联合概率分布对一篇文章进行建模:
现在,我将不再深入讨论如何实现这一点的基础数学,因为这超出了本文的范围。但是,为了让你了解整个生成过程的样子,这里有一个示意图:
下面是流程:
在a行中,正文由部分上下文生成(缺少作者字段)
在b行中,模型生成作者
在c行中,该模型重新生成提供的标题,使之更为真实
————————————————
版权声明:本文为CSDN博主「磐创 AI」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/fendouaini/article/details/106744426