MYSQL锁机制与优化以及MVCC底层原理
锁分类
乐观锁,悲观锁
从性能上分为乐观锁(版本对比,版本一致就更新,不一致就不更新或CAS机制)和悲观锁(锁住资源等待),乐观锁适合读比较多的场景,悲观锁适合写比较多的场景;如果在写操作比较多的场景,用乐观锁会导致对比次数过多,影响性能,因为每次查询到的版本号,和更新时的版本号就很容易不一致,就会cpu空转;
表锁,页锁,行锁
从数据操作的粒度上来说,分为表锁,页锁,行锁;
表锁每次锁住一张表,开销小,因为在表层面直接添加锁标记,不用一条一条查找记录,锁粒度大,发生锁冲突概率高,并发度低,一般在整张表数据迁移的时候,才会用;
手动增加表锁
Lock table 表名称 read(或者write);
查看表上加过的锁
Show opentables;
删除表锁
Unlock tables;
行锁的锁粒度小,但是因为它需要进行数据查找,所以开销相对表锁大,行锁其实不是添加到哪一行数据上的,它是添加到它的索引上的,如果我们添加锁时,条件字段没有索引,那么就可能锁整张表(RR会升级为表锁,RC不会);
关于RR级别行锁升级为表锁的原因
因为在RR的隔离级别下,需要解决不可重复读和幻读的问题,如果没有通过索引加锁,那么就会遍历所有的聚簇索引时,都会添加锁,为了防止扫描过的索引被其它事务修改,或间隙(主键为整数1,3之间的间隙就是2)被其它事务插入(幻读),从而导致数据不一致,所以它是把所有的索引记录和间隙都锁上;
页锁只有BDB的存储引擎才支持,页锁就是锁定的资源比行锁要多;页锁介于行锁和表锁之间;有点类似分段锁;
读锁,写锁,意向锁
从数据的操作类型上分为读锁和写锁;
读锁(共享锁)
针对同一数据,多个事务中的读操作可以同时进行,不会相互影响;
写锁
当前操作没有玩,其它的读锁和写锁都会被阻塞;数据的修改(insert,update,delete)操作都会添加写锁,查询也可以通过
Select * from table1 where id=1 for update;
来添加写锁;
意向锁
主要是为了提升增加表锁的效率,比如A表中又一行数据添加了行锁,但是这时另一个事务要添加表锁,正常情况下,添加表锁前要去遍历所有数据判断,是否存在行锁,但是为了效率,只要添加了行锁,这这张表添加一个标识,表示A表已经有行锁了,这样它就可以直接判断到底能不能加锁了;
间隙锁,临键锁
间隙锁本质是一个写锁,但它锁的不是索引值,而是两个索引值之间的空隙范围,间隙锁是一个开区间,只要锁了间隙内的一条数据,那么它就会锁住整个间隙,也就是范围锁;在可重复读级别才会生效,它主要就是用来解决幻读;
比如表中数据
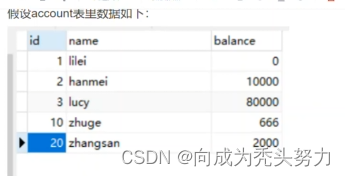
我现在锁住一个间隙,
Select * from account where id =15 for update; id=15的数据添加写锁
但是这时我添加10,20之间的任意一条数据都不行会被锁住,当然10和20可以操作;这就是间隙锁;
幻读就是A事务读取到了B事务在间隙中新插入的数据,这个时候我们只要在间隙区间添加一个间隙锁,让它在这个区间不能插入,就能解决幻读的问题;
临键锁
间隙锁和行锁的结合,就是把间隙锁的开区间变成闭区间,这里就是3到10的区间有锁,然后10这行真实存在的数据也有锁;

锁等待分析
查看当前锁等待的情况
Show status like ‘innodb_row_lock%‘ ch

查看库中当前所有的具体锁等待,事务,锁
查看事务
Select * from INFOMATION_SCHEMA.INNODB_TRX;

查看锁
Select * from INFOMATION_SCHEMA.INNODB_LOCKS;
![]()
查看锁等待
Select * from INFOMATION_SCHEMA.INNODB_LOCK_WAITS;

释放锁,trx_mysql_thread_id可以从INNODB_TRX表里查看到;
Kill trx_mysql_thread_id;
查看锁等待详细信息(锁日志)这个排查生产问题很重要
Show engine innodb status;
锁优化实践
RR级别隔离级别,不通过索引来加锁,会升级为表锁;

MVCC多版本并发控制机制 1:52:45
Undo日志版本链,
在并发的情况下,或者说多个事务都在修改同一条数据的时候,会生成日志版本链,它是为了数据进行回滚的,当所有事务都完成提交后,关于当前数据的日志版本链就是被删除;新增的数据版本链会马上删除,当同时有修改进来,新增的操作不提交,就没有数据进行修改,所以在新增提交后,修改的会新生成日志版本链,;
RR隔离级别,
为了能解决不可重复读的情况,它在第一次读取数据时,会记录当前已存在事务的状态,如果当前为已提交,则可读,当前为未提交则不可读,根据它的undo日志链一层一层找,直到找到这条数据此时已经提交的那条日志记录;

具体可见性算法逻辑如下
针对某一行数据的事务,
最小活跃事务ID:当前还没有提交的最小事务ID
最大事务id+1:关于当前数据,未来要开启的新事务
活跃事务id列表:当前数据,版本链上事务还没有提交的事务
1.小于最小活跃事务ID,小于肯定就是已经提交了,可见
2,如果数据行的事务id>=Read View中记录的当前出现的最大事务id+1,则跳转步骤5执行。
3,事务id列表为空,则该行数据可见,也就是当前查询的数据行没有事务。
4,如果数据行的事务id大于等于Read View(一致性视图)最小事务id,并且
小于Read View中记录的当前出现的最大事务id+1。
判断若存在于活跃事务id列表,则不可见。
判断若不存在于活跃事务id列表,则可见。
5,根据回滚指针在undo log中取出一条记录,从1步骤重复判断,直到找到满足条件的记录,否则返回空。

RC隔离级别
它与RR隔离级别不同的是,RR隔离级别第一次查询后,生成的read view就不会变了,而RC则会在每一次查询的时候,重新生成read view;