一、HTTP超文本传输协议
HTTP全称为Hyper Text Transfer Protocol超文本传输协议,它是基于TCP传输协议构建的应用层协议,作为支撑万维网www的核心协议,为了保证其效率及处理大量事务的能力,因此在设计时,HTTP被制定成为一种无状态协议,也就是说:HTTP本身不会对发送过的请求和相应的通信状态进行持久化处理。
也正因
HTTP的无状态特征,所以在有些需要保持状态的场景中,则需要引入其他技术来实现,比如需要保持“登录状态、授权状态”时,需要配合Cookie来实现记录与管理状态。
HTTP于1990年提出后,经过多年的完善和扩展,目前已经存在多个主流版本的迭代:
目前HTTP主流应用版本还是HTTP/1.1、2.0。
1.1、HTTP协议工作流程
HTTP核心由请求与响应构成,是一种典型基于客户端和服务器模型的协议,在目前的网络中,浏览器作为HTTP协议的主要载体,一般来说,“从浏览器发出请求到服务器返回响应”,这个过程被称为一次HTTP操作,也被称为一个事务,其具体过程如下:
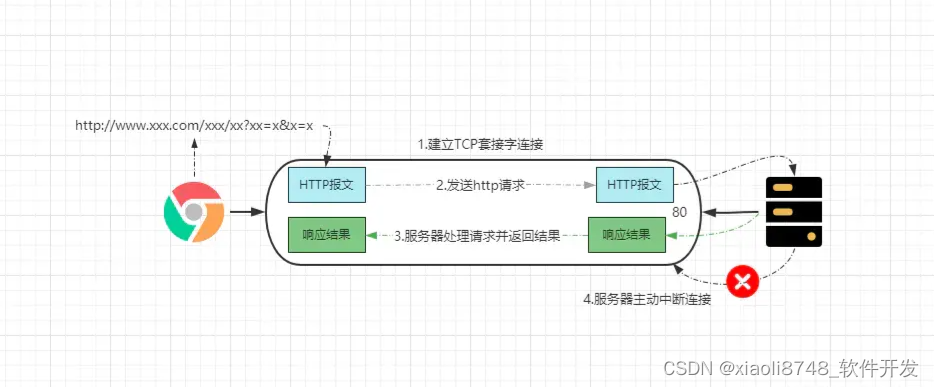
- ①客户端连接
WEB服务器:浏览器与服务器的HTTP/80端口建立一个套接字连接。 - ②发送
HTTP请求:根据用户的URL,通过套接字连接向服务器发送对应的请求报文。 - ③服务器处理请求并返回响应结果:解析请求、定位资源、执行逻辑后将结果写到套接字,客户端从套接字中获取结果。
- ④释放
TCP套接字连接:默认情况下,服务器主动终止套接字连接,客户端被动关闭。
从建立连接发出请求,到服务器处理完成后,返回响应再关闭连接,既代表着一个“事务”就完成了,但客户端接受到响应后,还会存在:解析响应报文、渲染结果数据这两步操作。
接下来我们根据
HTTP工作流程的先后顺序,依次拉开HTTP协议的完整序幕,如下:
- ①、URI资源标识符及URL资源定位符详解
- ②、
HTTP报文-请求报文与响应报文 - ③、
HTTP请求方法分类 - ④、
HTTP请求状态码 - .......
1.2、URI资源标识符及URL资源定位符
一般网络请求的前提是:需要用户在浏览器输入或点击超链接后,得到一个目标网址才会触发,而网址的专业术语为:URL统一资源定位符,而URL又是URI的一部分。
但URI统一资源标识符这个词并没有URL那么普及,因此出现在大众视野中的次数并不多,它的作用是区分网络上不同的资源,主要涵盖了URL和URN两部分。
接下来看看URL的构成,一般来说完整的URL结构如下:

但上述结构使用较少,URL的常用结构如下:
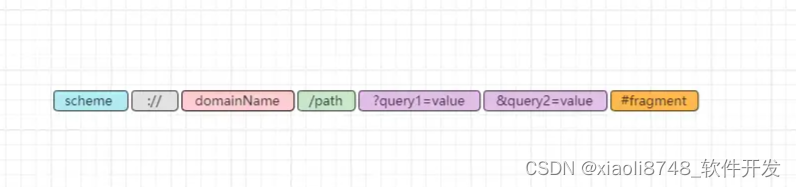
我们依次分析看看:
scheme:表示使用的协议类型,例如http、https、ftp、chrome等。://:协议类型与后续描述符之间的分隔符。domainName:网站域名,经DNS解析后会得到具体服务器IP。/path:请求路径,代表客户端请求的资源所在位置,不同层级目录之间用/区分。?query1=value:请求参数,?后面表示请求的参数,采用K-V键值对形式。&query2=value:多个请求参数,不同的参数之间用&分割。#fragment:表示所定位资源的一个锚点,浏览器可根据这个锚点跳转对应的资源位置。
PS:锚点也被成为片段标识符,
#部分之后的内容,即锚点不会被发送到服务器,锚点的作用仅是在浏览器解析时,跳转指定的位置显示。
对比完整的URL,常用的URL中除开用户名及密码外,还存在一点不同,即host:port主机IP+端口变为了domainName域名,那为什么又要这样做呢?
①
IP不方便记忆,对于普通用户而言,一串数字远比不了“拼音缩写”,好比www.baidu.com任何人都能记住,但14.215.177.38却不行。
②服务器的IP是动态多变,当网关宕机后换机部署时,IP又不相同了,但域名却是固定的,就算服务器IP再怎么变,域名都不会更换。
用户请求的域名又是如何变成具体IP的呢?这里面就得提及另一个概念:DNS解析。
1.2.1、DNS域名解析系统
在计算机网络中,每个主机都存在一个IP地址,但由于IP是一串数字不方便人类记忆,因此出现了一种协议名为DNS,它可以把生涩的IP地址转换为便于人类记忆的域名,例如百度的:www.baidu.com。
DNS(Domain Name System)中文的意思是域名系统,每个互联网企业WEB网站都可以看作是它自己在网上的门户,那么每个网站的域名就类似于“门牌号”,通常情况下,为了方便正常人记忆,域名都会使用公司的名称或简称,例如www.taobao.com、www.baidu.com、www.jd.com等,因此当你要访问一个Web网站,但又不知道其确切域名时,那么你首先可以输入其公司名称试试看。
趣事:因为一个公司域名大部分情况下都是由其名称或简称构成,因此有些人会大量注册域名,然后再高价转卖给这些公司,以此牟利。比如美图秀秀的
Boss蔡文胜,就以转卖域名为起点,从而跃身百亿富豪。
因特网最开始仅由几百台计算机组成,因此最初的域名与IP映射关系都是被保存在本地的Hosts.txt文件中,每台因特网中的机器都从服务器上下载Hosts文件,然后发送请求时就从本地查询IP信息,但随着接入因特网的设备越来越多,因此原有的这种方式无法满足日益增长的因特网需求。
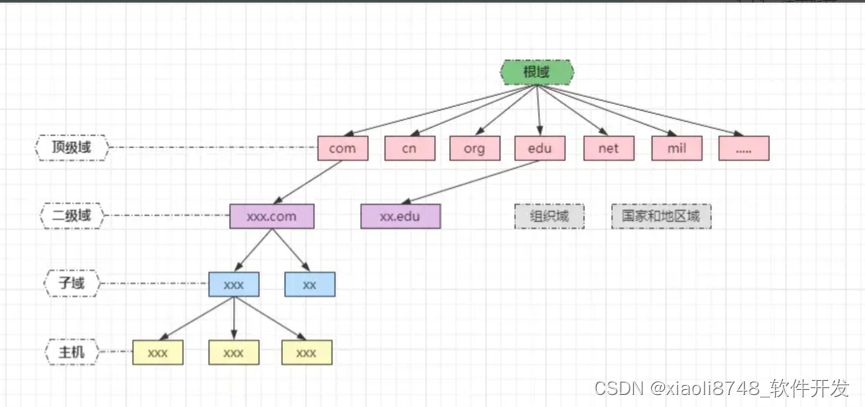
毕竟全球的设备都在不断的接入因特网,上网时都在使用域名访问,不过世界上并不存在一台DNS服务器可以映射所有的IP,所以域名系统最终被设计成了一个:带有层次结构的分布式K-V数据库,整个DNS由很多服务器共同组成的,大体结构如下:
PS:比如
www.baidu.com,实际上完整的域名为:www.baidu.com.,根域则是最后的.,系统做了兼容,不需要用户手动写出。
因特网上的域名服务系统也是按照域名的层次来划分的,每一个域名服务器都只对域名体系中的一部分进行管辖,DNS服务器主要分为三类:
- ①根域名服务器
- ②
TLD顶级域名服务器 - ③授权域名(子域)服务器
除此之外,还存在一种本地DNS服务器,但这个并不归纳在域名系统的分层结构中,不过本地DNS服务器却是DNS至关重要的一环。
DNS域名查询
DNS中主要分为递归查询、迭代查询两种方式:
- ①全递归查询:
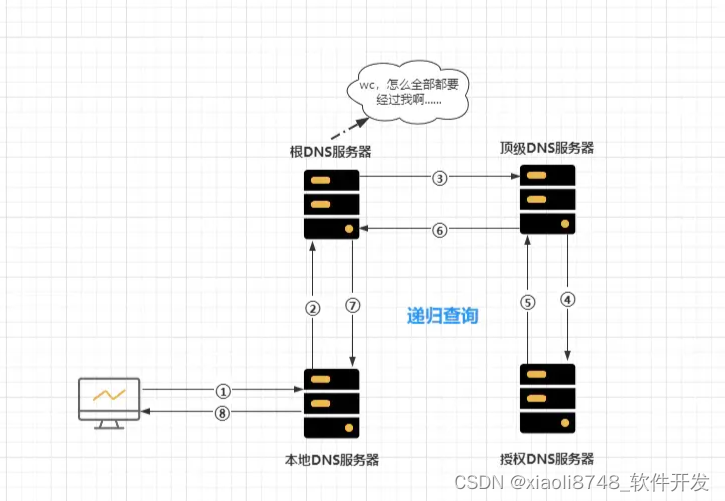
递归查询的意思是指:客户端只需发出一次请求,就能得到相应的解析结果。
- ②先递归+后迭代查询:
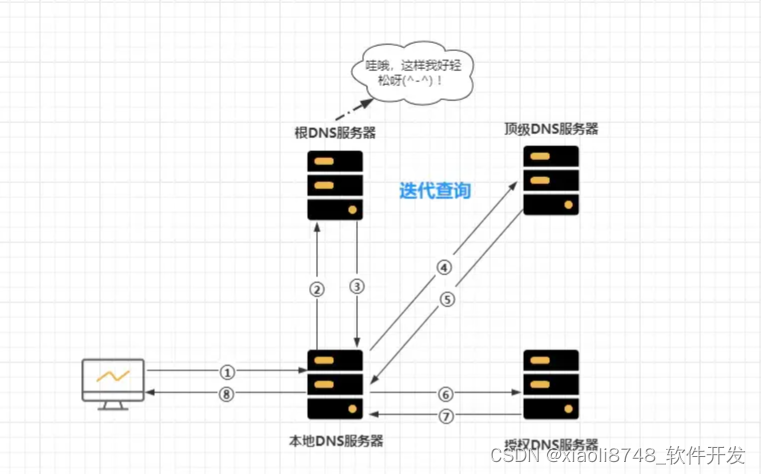
迭代查询的意思是指:客户端需经过多次请求查询,才能得到相应的解析结果。
当然,上述过程无论是迭代还是递归查询,对于上层DNS服务器而言,全球的访问压力都足以让其瘫痪,因此DNS中还存在一个重要的概念:DNS缓存:
- 本地
DNS/非授权服务器缓存:各大运营商或大公司都有自己的DNS服务器,一般部署在距离用户较近地方,代替用户访问核心DNS系统,同时这些DNS服务器可以缓存之前的查询结果,下次出现相同的DNS解析请求时,可直接返回已缓存的IP。 - 本地计算机
DNS缓存:计算机本地缓存主要分为操作系统缓存与浏览器缓存两种:- 浏览器缓存一般会有时间限制,如
Chrome浏览器默认是1min,一分钟内请求该域名,都会直接从本地缓存中获取IP。 - 操作系统缓存是指本地的
hosts文件,在浏览器中无法获取映射IP时,会尝试从hosts文件中获取。
- 浏览器缓存一般会有时间限制,如
注意:主机和本地域名服务器之间的查询方式是递归查询,本地域名服务器和其他域名服务器之间的查询方式是迭代查询,防止根域名服务器压力过大,也就是代表着:一般情况下
DNS解析请求都采用先递归+后迭代方式。
当用户在浏览器向一个域名发出请求后,DNS解析请求具体查询过程如下:
- ①客户端输入域名准备访问网站。
- ②先查询「浏览器的
DNS缓存」,命中直接向IP发起访问,未命中继续往下。 - ③继续查询「
OS的hosts文件」,如果仍然未命中,则向「本地域名服务器」发起「递归查询」请求。 - ④「本地域名服务器」先查询自身缓存,未命中则向「根域名服务器」进行「迭代查询」:
- A.「根域名服务器」返回「顶级域名服务器」的地址
- B.「本地域名服务器」再根据地址向「顶级域名服务器」发起查询
- C.「顶级域名服务器」返回负责该「域名」的「授权域名服务器」地址
- D.「本地域名服务器」再根据地址向「授权域名服务器」发起查询
- E.「授权域名服务器」返回「域名」的具体
IP地址
- ⑤「本地域名服务器」将
IP返回给客户端并将「域名/IP映射」缓存起来。 - ⑥「浏览器」得到
IP后,向其发出具体的「用户请求」,并将「域名/IP映射」缓存。
至此URL这块的内容已经分析明白了,接着继续往下看看。
1.3、HTTP报文的组成结构
浏览器访问服务器的过程中,解析域名得到具体IP后,会将用户的请求组装成HTTP报文,HTTP报文主要分为请求报文与应答(响应)报文两类。
1.3.1、请求报文
用户请求服务器时,发送的报文被称为请求报文,大体结构如下:

请求报文主要由请求行、请求头、空行、请求主体四部分组成。
请求行
请求行也被称为起始行,主要包含请求方法、资源路径以及协议版本三部分,具体如下:
GET /index.html HTTP/1.1
注意:报文中每个不同的部位之间必须要用SP空格隔开,末尾需要有一个CRLF回车换行符,遵循ABNF语法规范。
请求头
不管是请求头亦或是响应头,都可以算是HTTP报文中最复杂的内容,因为其中可选字段是非常多的,一般来说头部字段遵循如下规范:
- 每个字段名与字段值以
K-V键值对形式传递。 - 字段名不区分字母的大小写。
- 字段名中不允许出现非法字符,如空格、
/、&、^、_、@、}..... - 字段名与字段值之间必须以
:分割。
后续《
HTTP报文字段》章节再详细分析。
空行
必须存在,主要作用是用于区分请求头部和请求主体,也就是一个CRLF回车换行符,用于告知服务器剩下的报文中不再含有头信息。
请求主体
也被称为HTTP实体,在请求报文中被称为请求主体,这里主要描述用户的请求数据,可以是二进制数据,也可以是请求参数等等。
1.3.2、应答报文
服务器响应用户请求时,返回的报文被称为应答报文,大体结构如下:
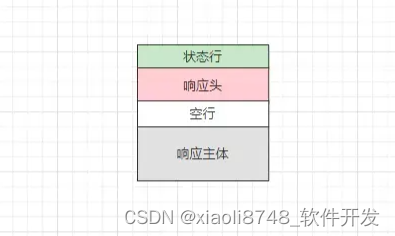
应答报文主要由状态行、响应头、空行、响应主体四部分组成。
状态行
应答报文中的状态行主要由协议版本、状态码、状态描述三部分构成,如下:
HTTP/1.1 200 OK
响应状态码也被称为HTTP状态,同样存在多种,因此放在后续分析。
响应头
和请求头类似,遵循相同的字段规范,唯一不同点在于字段类型不同。
空行
作用与请求报文中的空行类似,主要用于分割响应头和响应主体,用于通知客户端剩下的报文中没有响应头信息。
响应主体
根据用户请求中的资源路径,返回对应的资源数据,可以是HTML、XML、JSON、String、Bytes等各种数据类型。
1.3.3、HTTP报文字段
在前面分析报文头部时,提到头部存在很多可选字段,而HTTP报文字段主要可分为五大类:
- 请求报文字段:支持
HTTP请求的报文字段,用于请求头中。 - 应答报文字段:支持
HTTP响应的报文字段,用于响应头中。 - 实体首部字段:描述
HTTP实体内容的报文字段,可应用在请求主体与响应主体中。 - 通用报文字段:同时支持
HTTP请求与响应的字段,即可用于请求头,也可用于响应头。 - 其他报文字段:并非在
HTTP协议中定义的报文字段,但实际过程中经常使用的字段。
请求报文字段
客户端请求目标服务器时,可在请求报文头部中添加的字段:
Accept:代表客户端支持的数据类型,可选项如下:- 文本类型:
text/html:希望服务器返回HTML类型的数据。text/plain:希望服务器返回普通文本类型的数据。text/css:希望服务器返回CSS类型的数据。application/xml:希望服务器返回XML类型的数据。application/json:希望服务器返回JSON类型的数据。
- 图片类型:
iamge/jpeg:表示希望返回.jpg格式的图片。image/gif:表示希望返回.gif格式的图片。image/png:表示希望返回.png格式的图片。image/webp:表示希望返回.webp格式的图片。
- 视频类型:
video/mpeg:希望服务器返回视频数据。video/quicktime:希望服务器返回MAC电脑的视频类型数据。
- 字节类型:
application/octet-stream:希望返回字节流数据。application/zip:希望返回ZIP压缩字节数据。
*/*:表示接受所有类型的数据返回。Accept字段可设置多个值,服务器会依次进行匹配,会返回最先匹配到的数据类型。- 也可以通过参数
q来设置权重,权重越高,优先级越高,取值范围0.000~1,默认为1。 - 例如
text/html,application/xml;q=0.9,*/*,优先匹配HTML数据,当服务器先匹配到XML数据时,因HTML权重高一些,因此会依然继续匹配HTML数据。
- 文本类型:
Accept-Charset:表示客户端支持的字符集,如GB2312,ISO-8859-1,UTF-8等。Accept-Encoding:表示客户端支持的内容编码格式,常用格式如下:gzip:由gzip压缩算法生成的压缩数据编码格式。compress:由compress压缩算法生成的压缩数据编码格式。deflate:由zlib+deflate压缩算法生成的压缩数据编码格式。identity:默认的编码格式,表示不压缩数据。
Accept-Language:表示客户端支持的语言语种,如zh-cn,en,zh等。Authorization:表示客户端的认证信息。Host:表示客户端访问的目标资源所在的主机,即域名,如www.baidu.com。Referer:资源引用链,也称为防盗链,表示获取资源的请求来自哪个页面。If-Match:实体标记,该值与请求的目标资源ETag值一致时,服务器才受理该请求。If-Modified-Since:效验客户端本地资源的时效性,如果本地的缓存资源没有超时则不处理请求。If-None-Match:和If-Match作用相反,该值与ETag值不一致时才处理请求。If-Range:If-Match的升级版,访问的资源ETag值或时间一致时,服务器处理此请求。If-Unmodified-Since:If-None-Match的升级版,与If-Range作用相反。Max-Forwards:最大传输逐跳数,也就是请求允许被转发的最大次数,转发一次就-1。Proxy-Authorization:客户端提供给代理服务器的认证信息。Range:表示获取部分资源,如Range:bytes=50-800,代表获取第50~800字节之间的数据。User-Agent:客户端程序的信息,一般情况为当前浏览器的简略信息。TE:传输编码的优先级。..........
应答报文字段
客户端请求服务器后,服务器响应客户端时,应答报文中可出现的字段:
Accept-Ranges:表示服务器是否接受按字节范围获取数据的请求。Age:表示服务器创建响应资源的时间。ETag:实体的标识,资源的匹配信息。Location:告诉客户端资源的重定向位置/(URL)路径。Proxy-Authenticate:将代理服务器需要的认证信息返回给客户端。Retry-After:请求失败后,告诉客户端多久后重试。Server:告知客户端目前服务端的HTTP服务器信息,一般为Nginx。WWW-Authenticate:客户端请求资源失败时,告知其目标资源所需的认证方案,如Basic、Digest,一般配合401使用。status:客户端请求后的响应状态。Vary:代理服务器的缓存管理信息。
实体首部字段
实体也就是指请求的目标资源,任何一个数据在HTTP协议中都可被称为HTTP实体:
Allow:告知客户端所请求的资源支持的HTTP方法,如请求方法错误会以405状态返回。Content-Encoding:告知客户端资源(实体)数据所采用的编码方式。Content-Language:告知客户端资源所采用的自然语言,即zh-ch、en-US等。Content-Length:告知客户端资源的大小(字节长度)。Content-MD5:告知客户端资源的报文摘要。Content-Location:告知客户端资源所在的位置。Content-Range:告知客户端资源接受按字节区域获取的范围。Content-Type:告知客户端资源的数据类型。Expires:告知客户端资源的过期时间。Last-Modified:告知客户端资源最后一次的修改时间。
通用报文字段
通用报文字段是指可用于请求报文、应答报文、实体首部等多处位置的共享字段:
Cache-Control:控制浏览器缓存的行为,常用选项如下:max-age=N:请求到资源后将其缓存在本地,有效期为N秒。no-cache:协商式缓存,请求到资源后缓存到本地,后续每次请求资源时先与服务器确认是否更新过,更新则重新请求,否则从缓存中读取资源。no-store:禁用浏览器本地缓存,每次从服务器上获取资源。max-age=N,must-revalidate:请求到资源后将其缓存,有效期为N秒,到期后再与服务器协商确认资源是否更新,未更新则延长有效期,否则重新获取。
Connection:是否开启长连接,设为Keep-Alive代表开启长连接。Date:HTTP报文的创建时间,使用格林威治标准格式。Pragma:1.1版本之前的历史遗留字段,为了兼容而设计的。Transfer-Encoding:指定了报文主体传输时的编码格式,如Transfer-Encoding: chunked。Upgrade:用于检测协议版本,是否有其他更高的版本可用。Via:追踪客户端和服务端之间的报文的传输路径,一般在使用代理服务器时必须要用的字段。Warning:告知客户端一些与缓存相关的警告信息。
其他报文字段
其他报文字段是指并非在HTTP协议中定义的字段,但依旧使用频率较为频繁的字段:
Cookie:由于HTTP是一种无状态协议,因此通常使用Cookie也实现一些需要保持状态的功能,如身份Token、登录信息等,一般用于请求报文中。Set-Cookie:一般用于应答报文中,实现服务器给客户端传递Cookie信息,常用属性如下:Key=Value:往客户端的Cookie中写入值。expires=N:设置客户端Cookie的有效期。domin:指定Cookie生效的域名,只有请求该域名时才会携带Cookie。path:指定Cookie生效的具体资源路径,只有访问该路径时才会携带。Secure:设置该属性后,只有安全连接(HTTPS)情况下才会保存Cookie。SameSite:在跨域时是否携带Cookie:Strict:跨域时严禁携带本站Cookie。Lax:默认值,通过GET方式访问之后可允许携带。None:在设置了Secure属性情况下,所有请求都允许携带。
HttpOnly:使Cookie不能被JS脚本访问。
Content-Disposition:主要用于文件上传与下载时指定操作和名称:- 上传时:
form-data:以表单形式提交multipart数据。
- 下载时:
inline:将文件内容直接在网页上显示。attachment:下载文件时弹出对话框让用户确认下载。
filename:下载/上传时指定文件的名称。
- 上传时:
OK~,大致清楚
HTTP重的报文字段后,接着再来看看HTTP状态码。
1.3.4、HTTP状态码
在咱们做程序开发时,通过URL访问某个网站,通常都会在开发者调试工具重看到各式各样的“数字”,例如常见的200、403、404、500等,这些数字在HTTP协议中专业称呼为:HTTP状态码。RFC中规定了状态码必须要为三位数,其中第一个数代表了响应状态的类别,HTTP中所有的状态码共被分为五大类别:
1xx/(Informational):信息性状态码,代表请求被成功接受,正在处理请求。2xx/(Success):成功状态码,客户端的请求被成功处理并返回。3xx/(Redirection):重定向状态码,请求的资源位置发生变动,需重新请求。4xx/(ClientError):客户端错误状态码,客户端请求出现错误导致请求失败。5xx/(ServerError):服务端错误状态码,请求的服务端内部错误导致请求无法处理。
牢记如上规则后,之后再看见状态码时,不管见没见过,都可以根据其首位数字推断出一个请求的大体状态,例如:
200:以2开头,代表请求成功,服务端正常接受并处理了该请求。301:以3开头,代表请求的资源位置发生变动,请求会被重定向,重新请求新位置。404:以4开头,代表客户端出现错误,请求的路径不正确导致服务端无法定位资源。500:以5开头,代表服务端出现错误,服务端在处理请求的目标资源时,执行过程出现错误。.......
1.4、HTTP请求方法分类
同时,HTTP协议中发送请求的方法存在多种,HTTP/1.0中提供了三个请求方法,HTTP/1.1中新增六个请求方法:
GET:一般用于获取资源数据,如获取用户信息、商品信息、首页数据等。POST:一般用于传输/提交资源数据,如提交表单数据、提交字节数据等。HEAD:向服务器发送类似于GET方式的请求,但只要求返回头信息,不返回主体数据。PUT:一般用于修改数据,向指定路径上的资源提交最新数据并将其全量替换。PATCH:和PUT方法类似,PUT是全量更新,PATCH可以只修改部分数据。DELETE:一般用于删除资源/数据,如移除服务器上某文件资源等。OPTIONS:列出请求的目标资源所支持的请求方法,用来跨域请求。TRACE:追踪客户端请求/服务端响应路径,用于测试或诊断出错。CONNECT:在与代理服务器通信时建立连接隧道,使用隧道进行TCP通信。
其中最常用的是GET/POST两种方式,其他的方法相对比而言,正常业务用的频率并不高。
面试题:HTTP中Get和Post方法的区别
- ①
HTTP中功能的定义不同,GET用来获取数据,POST用于提交数据。 - ②传输数据的方式不同,
GET直接在URL拼接参数显式传输,POST则是隐式传输。 - ③允许传输数据时的长度不同,
GET通常情况下受到浏览器和服务器的限制,因此可传输的参数有限,而POST则没有限制。 - ④
GET总体而言,执行的效率远高于POST方式,GET也是form表单的默认方法。 - ⑤支持的数据传输格式不同,
GET仅支持ASCII字符,而POST支持整个ISO10646字符集。 - ⑥安全性不同,
GET由于是显式传输,数据被放在URL中,因此安全性远低于POST方式。 - ⑦浏览器缓存方面支持性不同,
GET请求的资源默认会被浏览器缓存,下次请求相同资源会直接从本地中读取,而POST请求的资源默认情况下不会缓存。 - ⑧一次请求产生的数据包数量不同,
GET只会发出一个TCP包,POST会将头信息和主体信息分成两个包发送。 - ⑨当浏览器回退或前进时,
GET方式获取的资源可直接使用,而POST则会重新请求服务器获取资源(因为GET可以从本地缓存中读取资源)。
1.5、HTTP中的其他常用核心知识
在HTTP协议中,还存在一些其他常用技术,如长连接、隧道技术、代理技术、缓存技术等,接下来再来看看这些核心内容。
1.5.1、持久连接/长连接
前面曾谈到过:HTTP是基于“请求/响应”模型所构建的协议,每次请求时,客户端和服务端之间都要新建立一个连接,服务端响应完成后又会立马断开连接。这种方式带来的缺点很明显,频繁的创建/销毁TCP连接造成的开销较大,资源浪费较多。
在HTTP中为了解决频繁创建/销毁TCP连接造成的开销,从而设计了一种Keep-Alive(长连接/持久连接)模式,开启这种模式的情况下,可以复用已建立的TCP连接,普通模式与长连接模式对比如下:
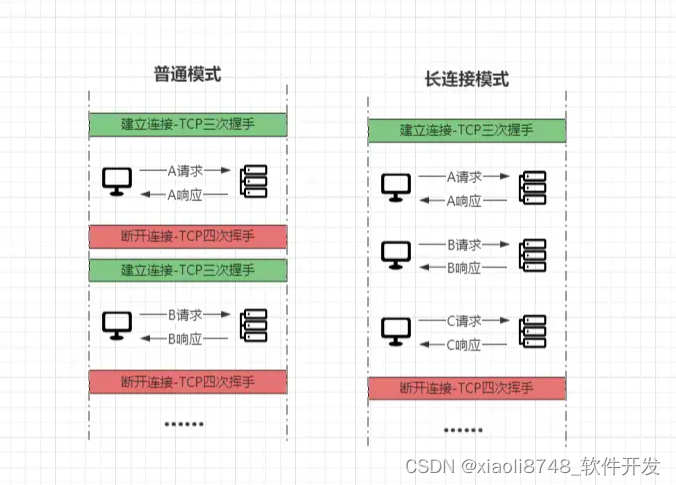
长连接模式下,当一个客户端的请求与服务端建立连接后,这个连接并不会在服务端响应结果后立马关闭,而是会持续有效,后续新的请求获取服务器资源时,可以通过这个TCP连接发送多个请求与接收多个响应。
HTTP/1.0中默认关闭,需要手动在请求头中添加Connection: Keep-Alive才可开启,HTTP/1.1默认开启,可以手动添加Connection: close关闭。
对于长连接模式,听起来确实很美好的样子,这点无可厚非,但这种模式对于服务器而言,会造成很大的并发压力,同时还存在一个经典问题:队头阻塞。
1.5.2、HTTP队头阻塞
因为HTTP协议事务处理机制中,要求对于请求的处理必须为“一求一应/一发一收”,所以HTTP本质上会将请求串行化,所有的请求会被放入到一个队列中依次交由服务器处理,那么假设前面的请求任务执行时间过长,最终就会导致后面的所有请求全部被阻塞,因此这个问题就被称为队头阻塞。
解决队头阻塞问题的方案有两种:并发连接与域名分片。
- 并发连接:
一个连接中的请求会被串行化后依次递交给服务器处理,那么假设我们客户端同时建立多个连接,是不是就会有多个串行化的通道呢?也就是多个队列,这答案是必然的,因此在客户端建立多个连接,可以增加队列数量,一个队列中的请求阻塞,并不会影响其他队列中的请求。
不过在
RFC2616中规定了一个客户端的并发连接不允许超过2个,但实际的浏览器设计中并不遵循该标准,如Chrome内核中默认允许一个域名下的并发连接值是6个,Firefox则是8个。
但就算是增加到了
6个,万一其中4个连接中,都出现了执行时间过长的请求导致阻塞怎么办呢?哪此时可以多上几个域名,既采用域名分片方案。
- 域名分片:
前面提及过,一个域名可以支持多个并发连接,但如果开到了客户端的上限后,依旧无法满足需求会出现一定程度上的请求阻塞,此时我们可以多上几个域名,也就是可以多准备几个域名,然后域名配置的
IP映射都指向同一台服务器,这样就可以支持更多的连接了,例如www.baidu.com:
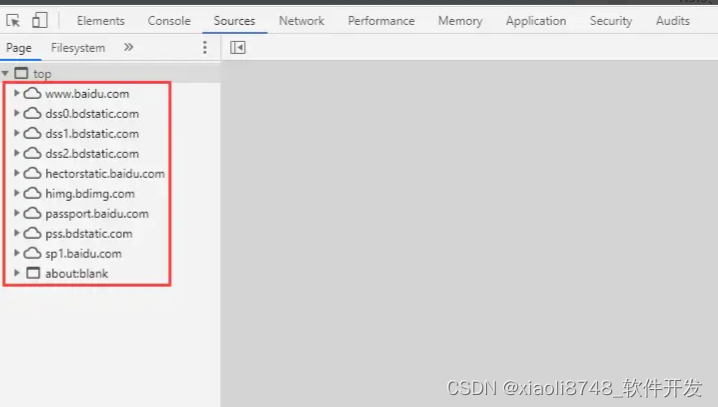
经过这个分析之后,你应该也大致清楚了为什么你做的网站访问速度慢的主要原因之一,因为你的请求出现了队头阻塞,服务器串行处理的速度过长,导致了你网页加载速度过慢。
1.5.3、HTTP代理技术
一般情况下,客户端和服务端之间的通信都是采用直连模式,即客户端解析域名后直接根据IP请求后端服务器,然后服务器处理客户端请求。但这种模式下,假设后端节点出现故障宕机,那么整个系统则会陷入瘫痪。同时这种模式,也无法解决部署后端节点的服务器性能瓶颈问题,因此为了确保系统更高的可用性和稳定拓展性,此时则可以加入 HTTP代理。HTTP代理大家听的次数应该也不算少,代理的主要含义是指:在客户端与服务端之间假设一个节点,从而能够满足开发过程中的更多需求,如动静分离、负载均衡、服务高可用、网站安全等,大体示意图如下:
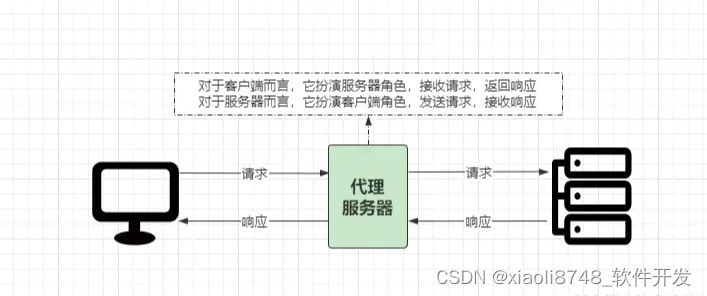
代理服务器目前市面上也存在多种选择,如Varnish、Squid、Nginx等,这些代理服务器的工作模式又可被分为正向代理和反向代理。
正向代理
正向代理与反向代理,这也是面试过程中常遇的一个面试题,先来谈谈何谓正向代理。
正向代理是指客户端可以感知到“代理角色”的存在,客户端发送请求时需要指定目标服务端,然后代理服务器会将客户端的请求发送到目标服务器处理,服务端处理完成后,代理服务器会接收响应结果并将其返回给客户端。
这样理解起来可能会存在些许抽象,那么例举生活中的例子:“竹子喊熊猫去楼下小卖部买包烟”,这个例子中“竹子”是客户端,“熊猫”是代理服务器,“小卖部”是服务端。
“竹子”显然知道有“代理人”的存在,并且明确指定了目标,但“小卖部”却无法知道具体要买烟的人是谁,这就可以理解为“正向代理”。
反向代理
反向代理的含义是指:代理服务器的存在对于客户端而言,是无法感知的。简单来说,就是指用户在访问代理服务器就跟直接访问服务器一样。
当用客户端根据域名解析IP访问时,其实解析得到的是反向代理服务器所在的机器IP,当客户端请求发送到反向代理服务器时,代理服务器会将请求分发到具体的“服务端机器”上处理,服务端处理完成后会将数据返回给反向代理服务器,然后由代理服务器将结果响应给客户端。
在这种“反向代理”的过程中,客户端对于“代理服务器”是无感知的,并且具体处理请求的服务器对于用户而言也是“黑箱”的。当然,为了便于理解,咱们再举个例子讲解:
竹子创业做xx业务,需要一批货,竹子找到当地供应商熊猫,熊猫收到竹子的拿货需求后,转手交给了X工厂,工厂完成货物生产后,交给“供应商熊猫”,再由熊猫交给“创业者竹子”。
上述案例里,竹子依旧是“客户端”,而熊猫依旧是“代理人”,工厂则是“服务端”,但这个过程中,“创业者竹子”是无法感知出“供应商熊猫”是代理人的角色,同时负责真正货物提供的“服务商工厂”对于竹子而言也是不可见的,这个案例就是一个典型的“反向代理”。
代理服务器这方面的内容会在下一篇中详细阐述。
1.5.4、HTTP隧道代理
前面分析的正向代理也好,反向代理也罢,其实都属于普通代理,在此之外还存在一种叫做隧道代理 的概念。
为什么需要隧道代理的存在呢?因为之前的普通代理模式中,代理服务器是“中间人”的角色,此时假设需要传输HTTPS流量,因为HTTPS需要认证,但代理显然不可能有网站的私钥证书,最终就会导致客户端和代理之间的TLS无法建立,证书校验无法通过。
HTTP tunnel以及CONNECT机制就主要解决了这个问题,代理服务器不再作为中间人,不再改写浏览器的请求,通过CONNECT方法让客户端与任意目标服务器的IP和端口建立一条TCP连接,创建成功后,隧道代理在其中只负责将浏览器和服务器之间通信的数据原样透传,这样客户端就可以直接和远端服务器进行TLS握手并传输加密的数据。
1.6、HTTP各版本中的缺陷与改进
HTTP/0.9:仅支持GET方式的纯文本请求。HTTP/1.0:- 特点:无状态、无连接,支持多类请求方式,任意数据都可以传输。
- 缺点:每次请求时无法复用连接,需重新建立连接。
HTTP/1.1:- 改进:
- 支持长连接(
Connection: keep-alive)。 - 支持管道化请求。
- 支持缓存管理,分为强缓存和协商缓存两种。
- 支持断点续传。
- 支持一个
WEB服务器创建多个站点(Host)。 - 增加多个请求方法。
- 支持长连接(
- 不足:
- 传输性能有限,请求会发生阻塞(队头阻塞)。
- 改进:
HTTP/2.0:- 改进:
- 引入新的二进制协议,应用层与传输层之间数据支持二进制分帧。
- 引入多路复用机制,提高连接可用性。
- 优化请求头,使用
HPACK头部压缩算法避免传输重复头。 - 支持服务器主动向客户端推送资源。
- 不足:
- 因基于
TCP协议构建,出现丢包时,整个会话需等待重传,后面数据会被阻塞。
- 因基于
- 改进:
HTTP/3.0:- 改进:
- 抛弃
TCP协议,转至基于UDP协议构建的QUIC协议(又称HTTP/3.0)。 - 新增
0-RTT机制:缓存当前回话上下文,下次恢复会话将缓存传给服务器验证后,即可传输数据。 - 优化多路复用机制:会话的多个流间不存在依赖,丢包只需重发包,无需重传整个连接。
- 针对移动端应用优化:由于之前基于
TCP协议,因此对于移动端的IP多变而言,非常影响传输,3.0通过ID识别连接,ID不变,即可快速连接。 - 更好的安全性:
3.0中几乎所有报文都要经过认证,主体经过加密,有效防窃听、注入和篡改。 - 提供向前纠错机制:每个数据包中携带部分其他数据包的数据,少量丢包可通过其他包的冗余数据直接恢复,无需丢包重传。
- 抛弃
- 改进:









——实操演示](https://img-blog.csdnimg.cn/direct/742f58c929d8415cb9830b0c829944e4.png)