文章目录
- 1.收集数据集
- 1.1 使用开源已标记数据集
- 1.2 爬取网络图像
- 1.3 自己拍摄数据集
- 1.4 使用数据增强生成数据集
- 1.5 使用算法合成图像
- 2.标注数据集
- 2.1确认标注格式
- 2.2 开始标注
- 3.划分数据集
- 4.配置训练环境
- 4.1获取代码
- 4.2安装环境
- 5.训练模型
- 5.1新建一个数据集yaml文件
- 5.2预测模型
- 5.3训练模型
- 6.验证模型
- 7.导出模型
1.收集数据集
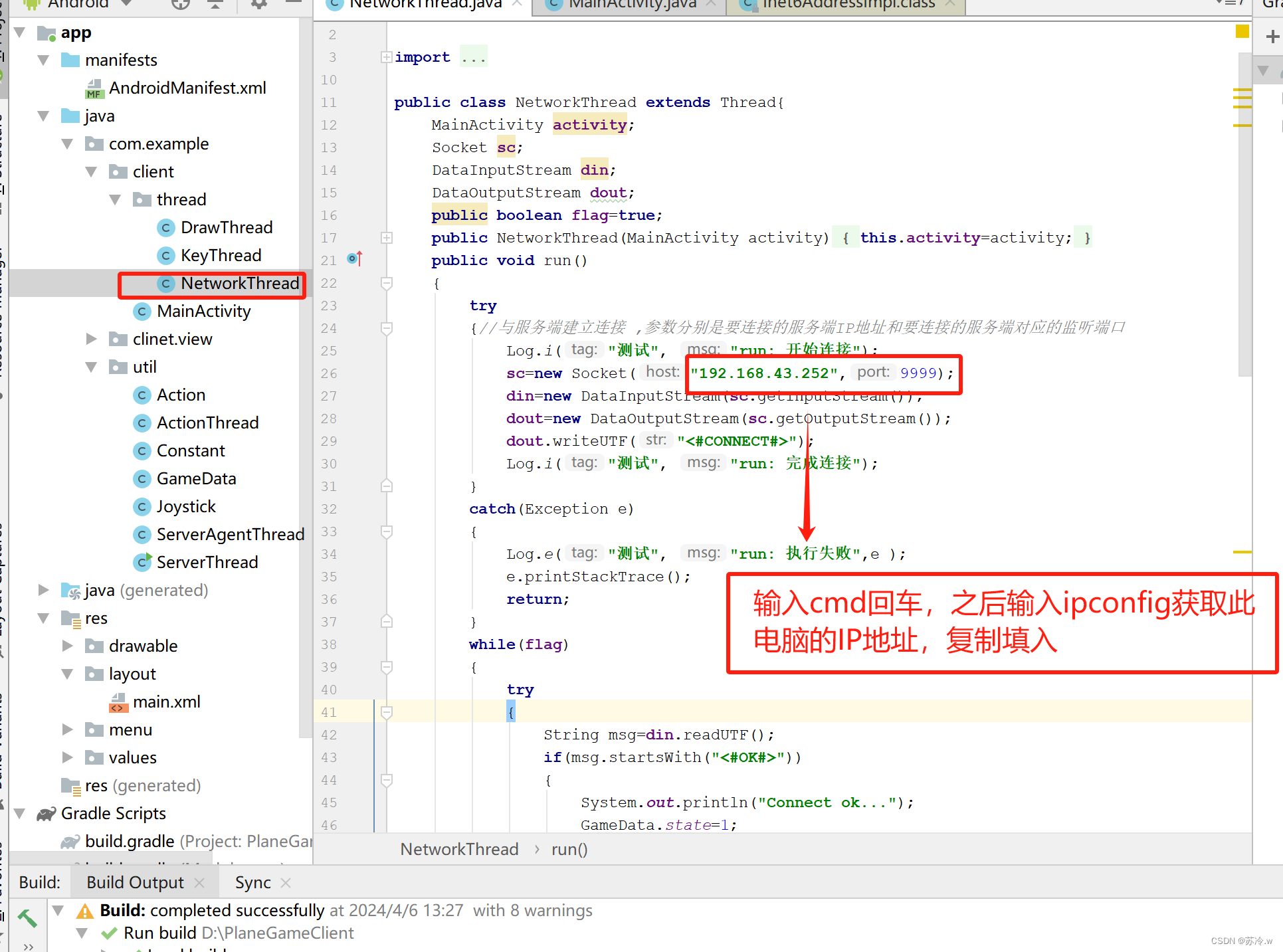
随着深度学习技术在计算机视觉领域的广泛应用,行人检测和车辆检测等任务已成为热门研究领域。然而,实际应用中,可用的预训练模型可能并不适用于所有应用场景。
例如,虽然预先训练的模型可以检测出行人,但它无法区分“好人”和“坏人”,因为它没有接受相关的训练。因此,我们需要为自定义检测模型提供足够数量的带有标注信息的图像数据,来训练模型以区分“好人”和“坏人”
1.1 使用开源已标记数据集
使用开源数据集是收集数据的最简便方式之一。例如,ImageNet 是一个大型图像数据库,包含超过 1400 万张图像,可用于深度学习模型的训练。此外,像 COCO 、PASCAL VOC 这样的数据集也经常用于目标检测模型的训练和评估。但是这些数据库中的图像通常来自不同的领域和应用场景,因此可能无法完全满足特定研究的需求。

1.2 爬取网络图像
另一种选择是通过网络搜索图像,并手动选择要下载的图像。然而,由于需要收集大量数据,因此此方法的效率较低。需要注意的是,网络上的图像可能受到版权保护。在使用这些图像之前,务必检查图像的版权信息。
或者,您可以编写一个程序来爬取网络并下载所需的图像。但是这需要对数据进行清洗。以确保数据质量。同样需要注意检查每个图像的版权信息。
1.3 自己拍摄数据集
对于一些特定的应用场景,如自动驾驶和安防监控等,需要收集特定场景下的数据,这时候就需要进行自主拍摄。可以在实际场景中拍摄图像或视频,并对其进行标注,以获得适用于特定场景的高质量数据集。

1.4 使用数据增强生成数据集
我们知道深度学习模型需要大量的数据。当我们只有一个小数据集时,可能不足以训练一个好的模型。在这种情况下,我们可以使用数据增强来生成更多训练数据。
常见的增强方式就是几何变换,类似翻转、裁剪、旋转和平移这些。

1.5 使用算法合成图像
最后一种获取目标检测数据集的方法是使用合成图像。合成图像是通过使用图像处理软件(例如 Photoshop)在图像中添加对象、更改背景或合成多个图像以创建新的图像。这种方法可以提供一些特殊情况或无法通过其他方式获得的图像,但是合成图像通常无法完全代替真实场景的数据,可能会对模型的准确性产生一定的影响
或者我们可以使用生成对抗网络 (GAN )来生成数据集,

值得注意的是,收集训练数据集只是我们训练自定义检测模型的第一步。。。接下来我们要个绍如何标注数据集。当然这一步是假设你的图片已经准备完成。
本次案例使用我个人的 月饼数据集
链接: https://pan.baidu.com/s/1-DwTH6roNDSqW4NyqoA3BQ?pwd=25rt 提取码: 25rt
2.标注数据集
为什么要标注数据集?标注好的数据集有什么作用呢?答:为了让计算机学会正确地识别物体,我们需要提供大量的标注数据集,这些数集包含了图像或视频中物体的位置和类别信标注数据集的作用在干,它可以帮助计算机学习到如何识别不同种类的物体,并且能够正确地定位它们的位置。通过标注数据集我们可以让计算机逐渐学会如何识别和分类不同种类的物体,例如人、车、动物等等。这些数据集可以被用来训练深度学习模型让模型学会如何识别新的图像或视频中的物体。
举个简单例子:比如说,我们想要让计算机自动识别图像中的猫和狗。为了让计算机学会如何识别这两个物体,我们需要提供一些图像样本,并在这些样本上标注猫和狗的位置。如果我们没有标注数据集,计算机就无法学习到如何识别猫和狗。即使我们给计算机提供了大量的图像,它也无法准确地区分这两个物体。但是,如果我们有了标注数据集,计算机就可以通过学习这些数据来理解猫和狗之间的差异,并且可以在新的图像中准确地识别它们。
(当然这个例子指的是监督学习)
2.1确认标注格式
YOLOv8 所用数据集格式与 YOLOv5 YOLOv7 相同,采用格式如下:
<object-class-id> <x> <y> <width> <height>
常用的标注工具有很多,比如LabeLImg 、LabeUMe 、VIA等,但是这些工具都需要安装使用,我这里给大家介绍一款在线标注数据集的工具 Make Sense,打开即用,非常的便捷,在标注之前,我们来看一下一般情况下遵循的标注规则:
1.目标框必须框住整个目标物体,不能有遗漏和重叠。
2.目标框应该与目标物体尽可能接近,但不能与目标物体重合
3.目标框的宽度和高度应该为正数,不能为零或负数。
4.如果一张图片中有多个目标物体,每个目标物体应该用一个独立的目标框进行标注,不允许多个目标共用一个框.
5.如果目标物体的形状不规则,可以使用多个框进行标注,但必须框住整个目标物体。
6.目标框的坐标必须在数据集中统一。
2.2 开始标注
确认好标注格式后我们就可以开始标注了,进入网页后点击 Get started 开始使用。
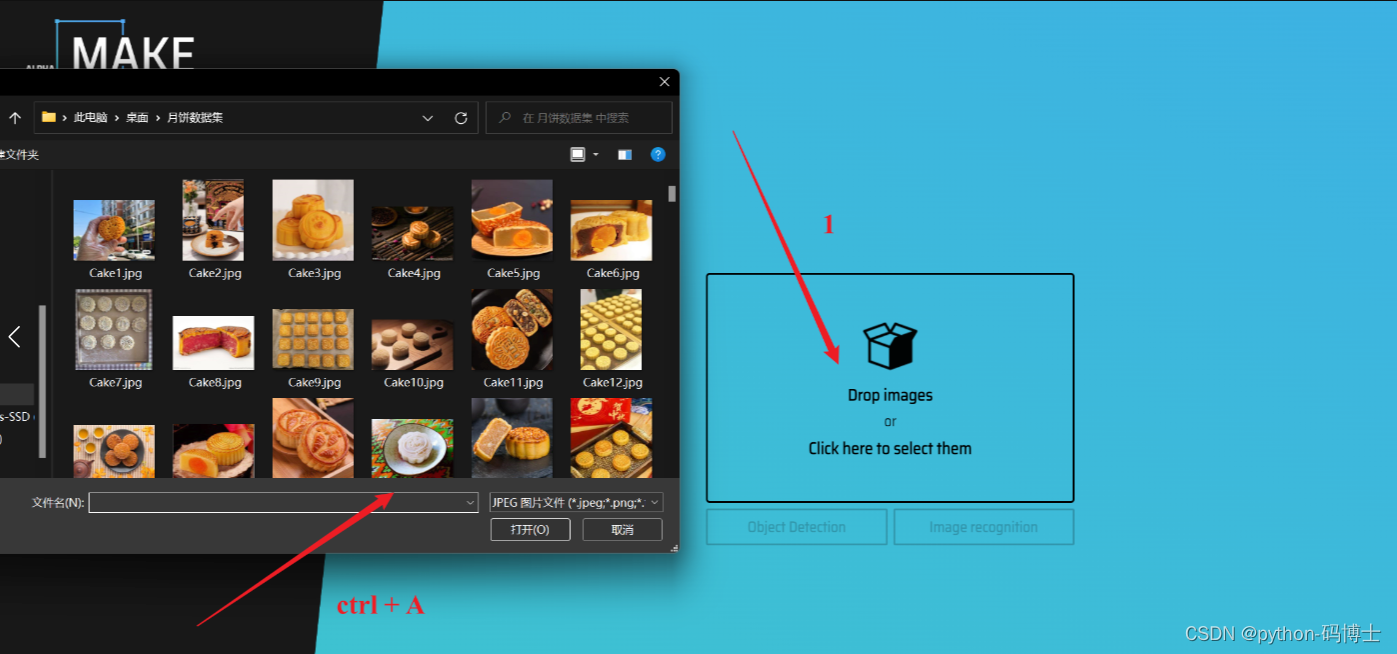
首先点击 Drop images 然后 ctrl+A 选中整个数据集里面的图片。
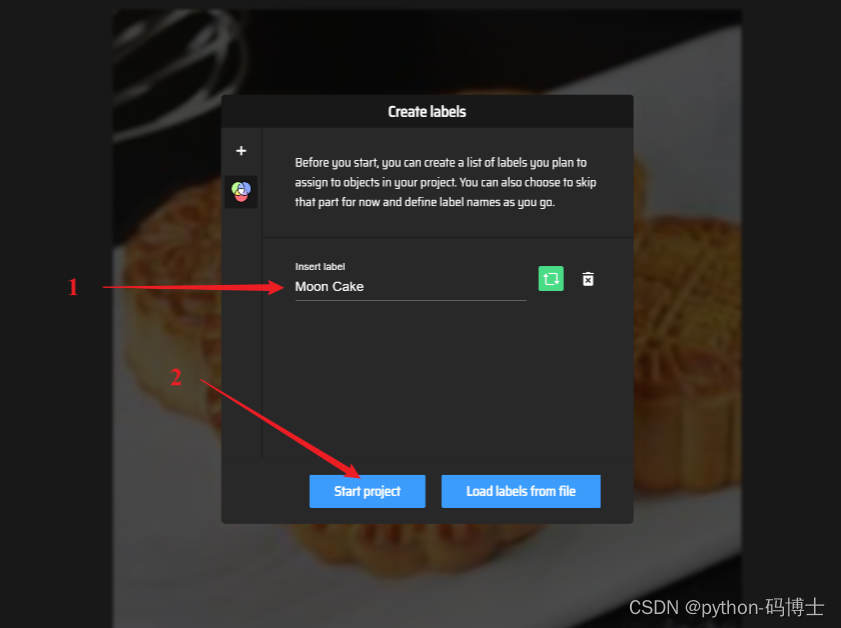
随后添加标签信息,有几类就添加几个,因为我这里只检测月饼一类,所以只添加一个标签 Moon Cake.
随后就进入了漫长的标注环节,这里大家一定要认真标注,不然对最终模型的影响还是很大的。
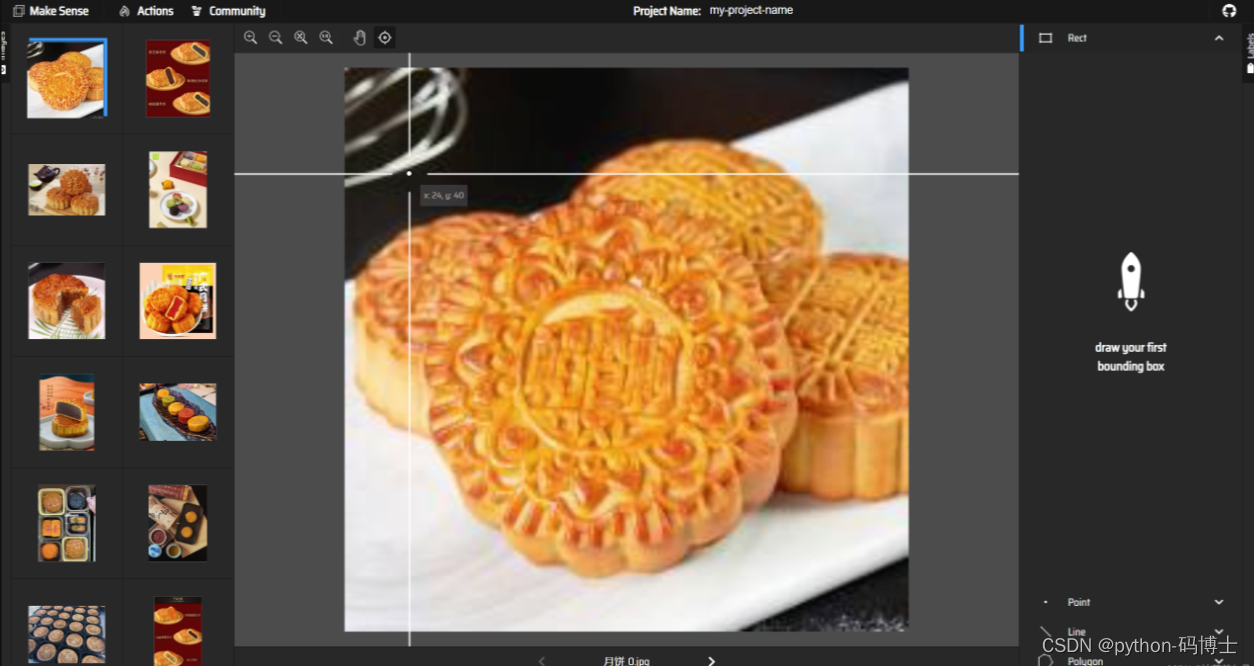
标注完成后我们点击 Action -> Export Annotation 导出 yolo 格式的标签文件。
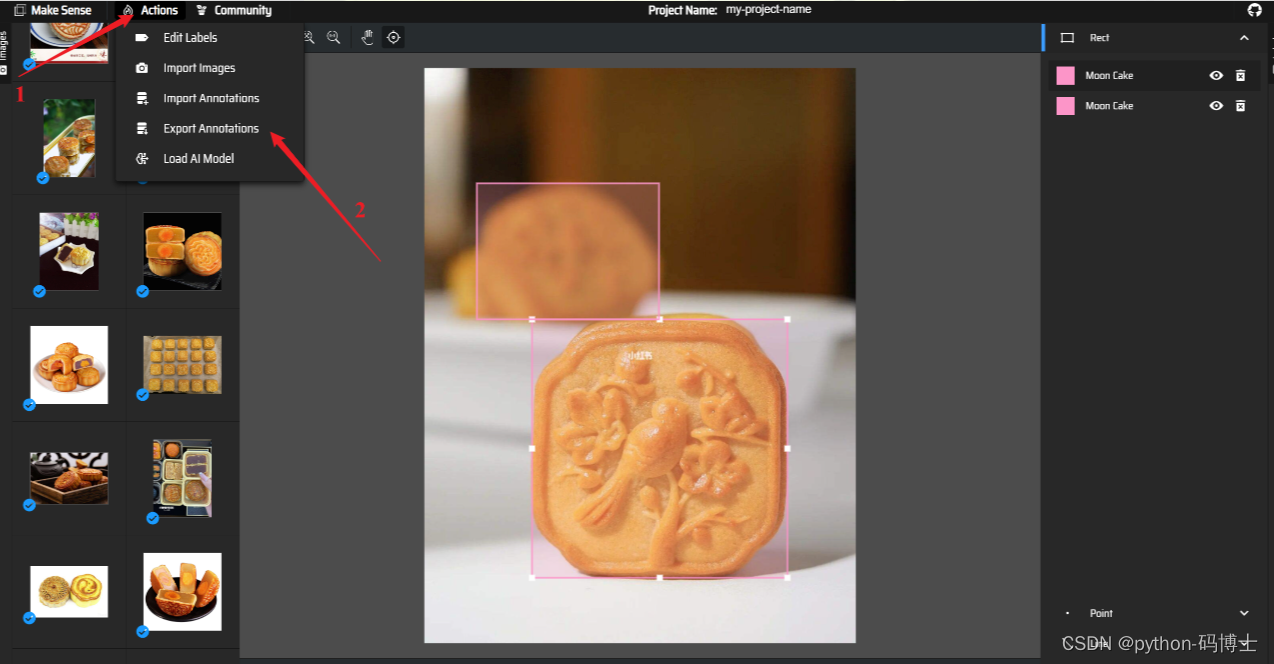
导出之后的标签文件就是这个样子的,我们可以随机抽查几个看看有没有问题。

3.划分数据集
也就是说,我们现在导出后的图片和标签是这个样子的:
Moon_Cake
├─images
└─all
└─labels
└─all
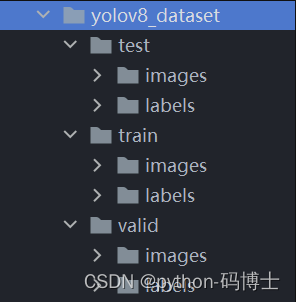
但是 YOLO8 所需要的数据集路径的格式是下面这样子的(YOLOv8 支持不止这一种格式),我们接下来要通过脚本来来划分一下数据集。
├── yolov8_dataset
└── train
└── images (folder including all training images)
└── labels (folder including all training labels)
└── test
└── images (folder including all testing images)
└── labels (folder including all testing labels)
└── valid
└── images (folder including all testing images)
└── labels (folder including all testing labels)
具体其实只要修改路径就行了,代码我都做了注释。
import os
import random
import shutil
def copy_files(src_dir, dst_dir, filenames, extension):
os.makedirs(dst_dir, exist_ok=True)
missing_files = 0
for filename in filenames:
src_path = os.path.join(src_dir, filename + extension)
dst_path = os.path.join(dst_dir, filename + extension)
# Check if the file exists before copying
if os.path.exists(src_path):
shutil.copy(src_path, dst_path)
else:
print(f"Warning: File not found for {filename}")
missing_files += 1
return missing_files
def split_and_copy_dataset(image_dir, label_dir, output_dir, train_ratio=0.7, valid_ratio=0.15, test_ratio=0.15):
# 获取所有图像文件的文件名(不包括文件扩展名)
image_filenames = [os.path.splitext(f)[0] for f in os.listdir(image_dir)]
# 随机打乱文件名列表
random.shuffle(image_filenames)
# 计算训练集、验证集和测试集的数量
total_count = len(image_filenames)
train_count = int(total_count * train_ratio)
valid_count = int(total_count * valid_ratio)
test_count = total_count - train_count - valid_count
# 定义输出文件夹路径
train_image_dir = os.path.join(output_dir, 'train', 'images')
train_label_dir = os.path.join(output_dir, 'train', 'labels')
valid_image_dir = os.path.join(output_dir, 'valid', 'images')
valid_label_dir = os.path.join(output_dir, 'valid', 'labels')
test_image_dir = os.path.join(output_dir, 'test', 'images')
test_label_dir = os.path.join(output_dir, 'test', 'labels')
# 复制图像和标签文件到对应的文件夹
train_missing_files = copy_files(image_dir, train_image_dir, image_filenames[:train_count], '.jpg')
train_missing_files += copy_files(label_dir, train_label_dir, image_filenames[:train_count], '.txt')
valid_missing_files = copy_files(image_dir, valid_image_dir, image_filenames[train_count:train_count + valid_count], '.jpg')
valid_missing_files += copy_files(label_dir, valid_label_dir, image_filenames[train_count:train_count + valid_count], '.txt')
test_missing_files = copy_files(image_dir, test_image_dir, image_filenames[train_count + valid_count:], '.jpg')
test_missing_files += copy_files(label_dir, test_label_dir, image_filenames[train_count + valid_count:], '.txt')
# Print the count of each dataset
print(f"Train dataset count: {train_count}, Missing files: {train_missing_files}")
print(f"Validation dataset count: {valid_count}, Missing files: {valid_missing_files}")
print(f"Test dataset count: {test_count}, Missing files: {test_missing_files}")
# 使用例子
image_dir = 'datasets/coco128/images/train2017'
label_dir = 'datasets/coco128/labels/train2017'
output_dir = './my_dataset'
split_and_copy_dataset(image_dir, label_dir, output_dir)
运行完脚本后我们的数据集就会划分成这个格式了,现在数据准备工作就彻底完成了,接下来我们开始着手训练模型。
4.配置训练环境
4.1获取代码
git clone https://github.com/ultralytics/ultralytics
针对网络不好的同学,我这里上传了一份:
链接: https://pan.baidu.com/s/1crFGhcmvik-sZJfXY3ixkw?pwd=xma5 提取码: xma5
4.2安装环境
cd ultralytics
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
5.训练模型
5.1新建一个数据集yaml文件
这个是我新建的,里面写绝对路径 (主要是怕出错):
# moncake
train: D:\Pycharm_Projects\ultralytics\ultralytics\datasets\mooncake\train # train images (relative to 'path') 128 images
val: D:\Pycharm_Projects\ultralytics\ultralytics\datasets\mooncake\valid # val images (relative to 'path') 128 images
test: D:\Pycharm_Projects\ultralytics\ultralytics\datasets\mooncake\test # test images (optional)
# Classes
names:
0: MoonCake
这个是自带的,里面写相对路径,和我们的写法不同,但是都可以使用,据我所只还有很多种数据集读取方式:
# coco128
path: ../datasets/coco128 # dataset root dir
train: images/train2017 # train images (relative to 'path') 128 images
val: images/train2017 # val images (relative to 'path') 128 images
test: # test images (optional)
# Classes
names:
0: person
1: bicycle
2: car
'''
'''
79: toothbrush
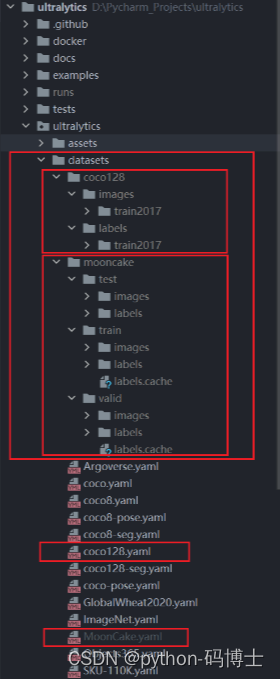
相应的数据集位置就在这里,我们可以和 coco128 对比一下,这两种划分格式都可以的,这里一定要注意路径问题!
5.2预测模型
python 指令推理方式
from ultralytics import YOLO
# Load a model
model = YOLO('yolov8n.pt') # load an official model
model = YOLO('path/to/best.pt') # load a custom model
# Predict with the model
results = model('https://ultralytics.com/images/bus.jpg') # predict on an image
终端中直接键入以下指令就可以实现对图进行推理了,推理后如果不指定文件夹,就会默认保存到 runs/detect/predict下。
yolo task=detect mode=predict model=yolov8n.pt source=data/images device=0 save=True

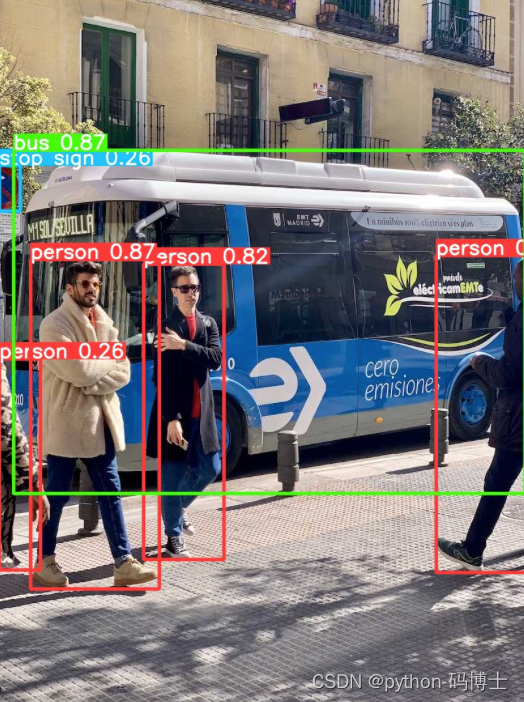
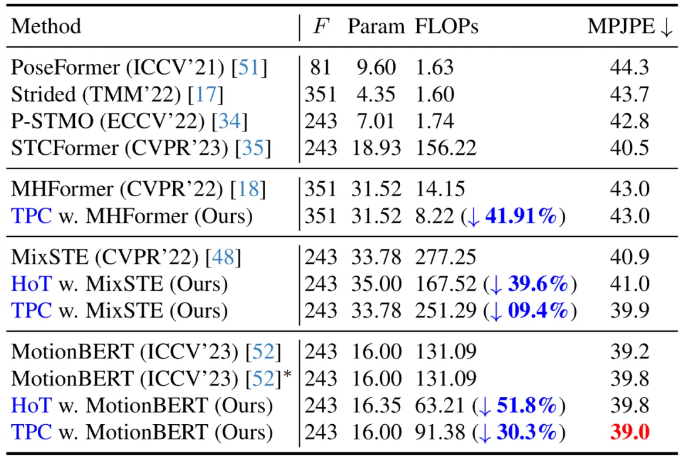
就这张图来说,v8 确实比v5 牛左上角的标志都检测出来了,但是阳台上的自行车还是没检测出来。
YOLOv8 关于模型的各种参数其实都写到了一起,在ultralytics/yolo/cfg/default.yaml,这些指令我们就可以实现各种我们所需的操作。

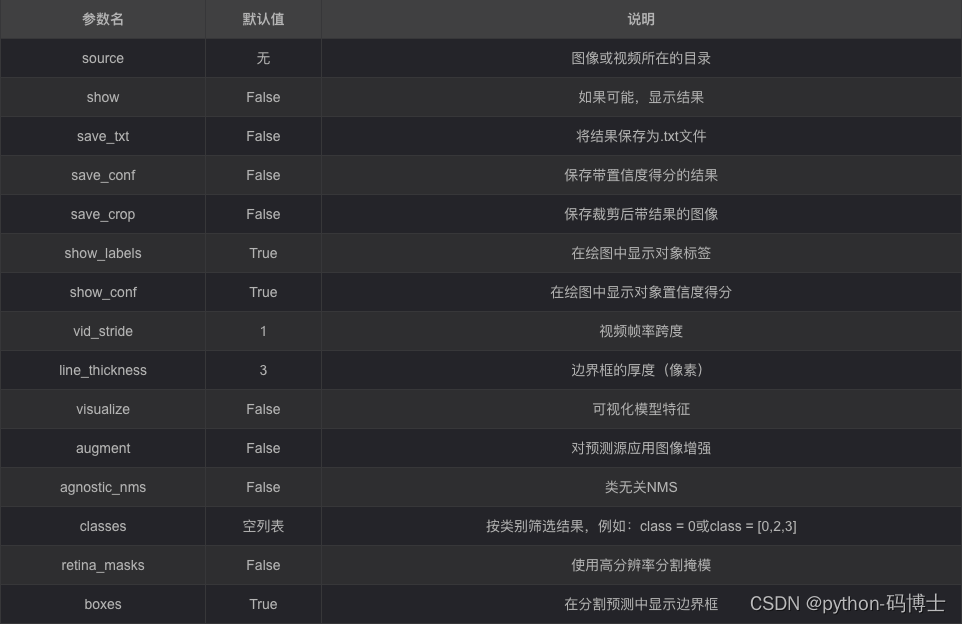
5.3训练模型
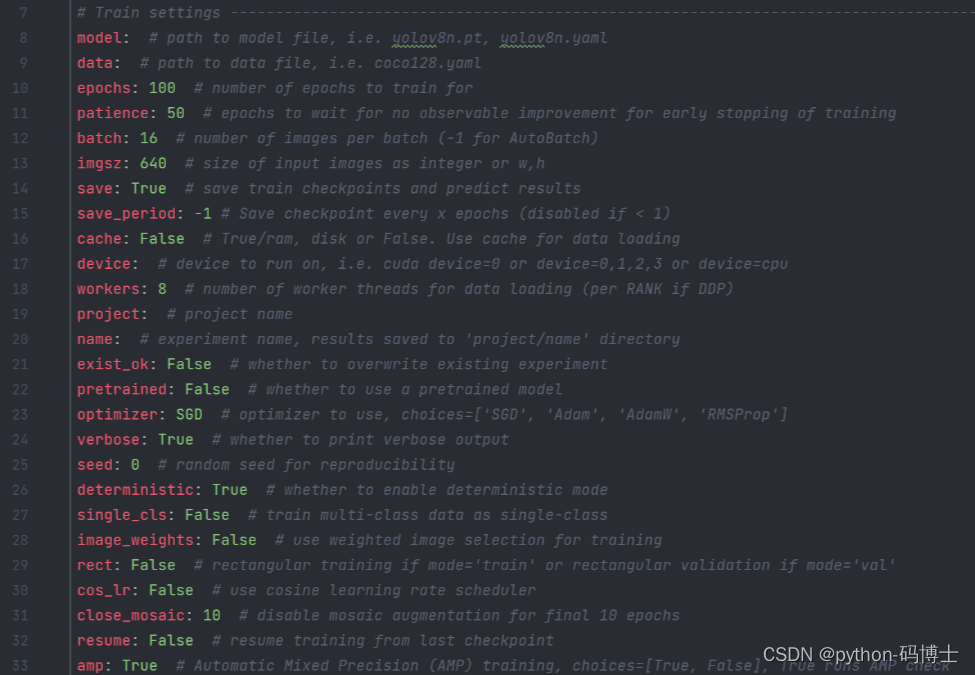
模型训练阶段的原理和预测步骤一致,都可以直接通过命令行搞定,关于这部分参数依然在ultralytics/yolo/cfg/default,yanl中,但我们要训练自己的数据集时记得在 data 参数后指定我们自己的数据集 yamL 文件路径哦。
以下提供两种指令,分别对应了不同的需求。(这里有一点值得注意,我直接写 data=MoonCake.yal 是报错的! 这个涉及到一个坑的问题,没遇到的同学暂且忽略)
python指令训练方式
from ultralytics import YOLO
# Load a model
model = YOLO('yolov8n.yaml') # build a new model from YAML
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
model = YOLO('yolov8n.yaml').load('yolov8n.pt') # build from YAML and transfer weights
# Train the model
model.train(data='coco128.yaml', epochs=100, imgsz=640)
在训练过程中(训练结束后也可以看》我们可以通过 Tensorboard实时查看模型的训练进度,只需要在终端中键入如下的指令,这个在我们每次训练时候都会有提示:
tensorboard --logdir runs\detect\train2
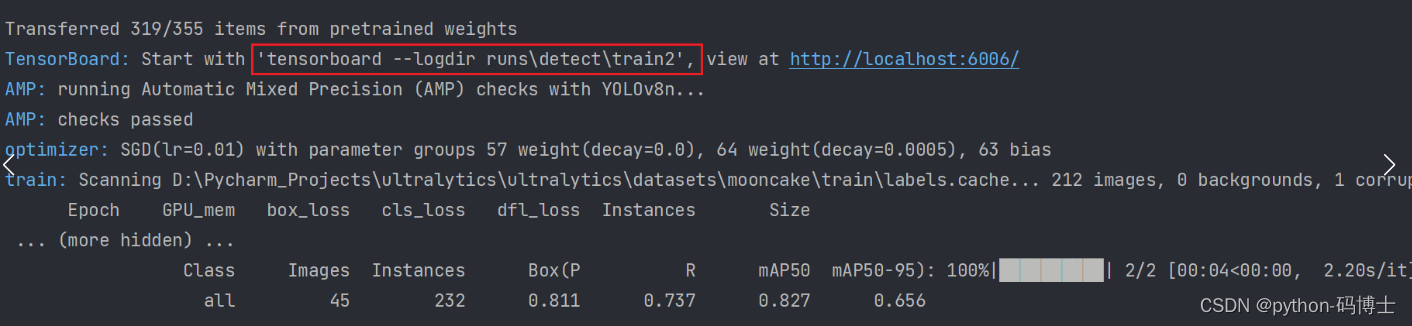
训练结束后我们可以查看得到的一些指标数据:

我这里展示一张 PR 曲线图。
6.验证模型
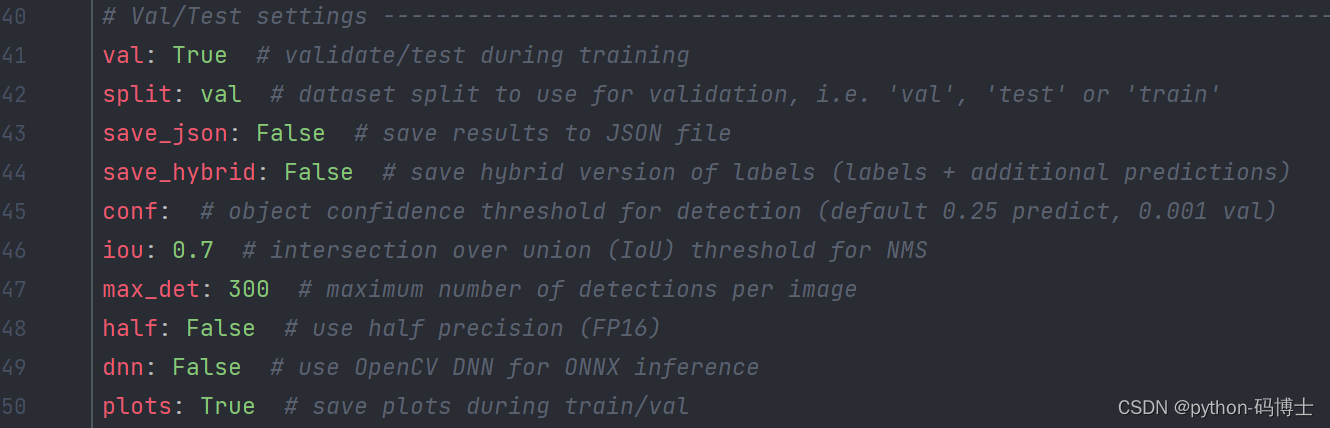
验证模型同样是简单命令行即可实现,如果没有修改中的 ultralytics/yolo/cfg/default,yamL 默认值,同样别忘了指定自己数据集的 yaml ,即 data=ultralytics/datasets/MoonCake.yaml
python 指令验证方式
from ultralytics import YOLO
# Load a model
model = YOLO('yolov8n.pt') # load an official model
model = YOLO('path/to/best.pt') # load a custom model
# Validate the model
metrics = model.val() # no arguments needed, dataset and settings remembered
metrics.box.map # map50-95
metrics.box.map50 # map50
metrics.box.map75 # map75
metrics.box.maps # a list contains map50-95 of each category
同样的,我们验证完后依然可以得到一个文件夹:
我们可以看一下检测效果:

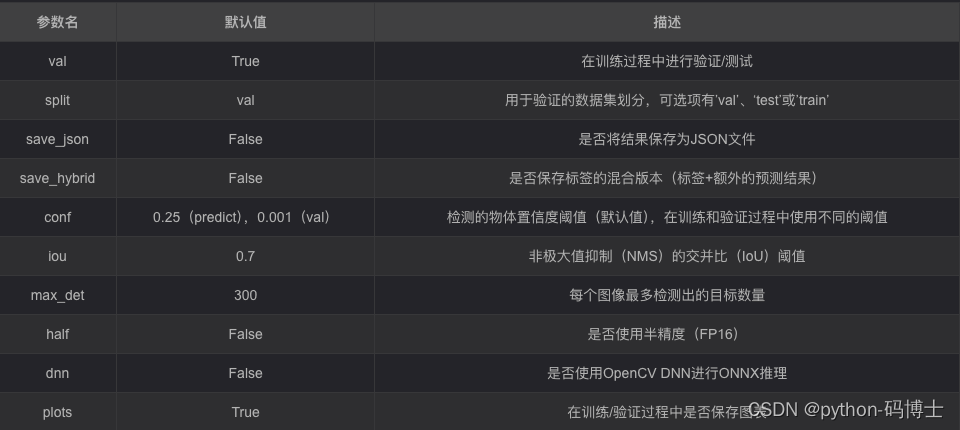
7.导出模型
python指令方式导出
from ultralytics import YOLO
# Load a model
model = YOLO('yolov8n.pt') # load an official model
model = YOLO('path/to/best.pt') # load a custom trained
# Export the model
model.export(format='onnx')
导出有关的具体参数如下:

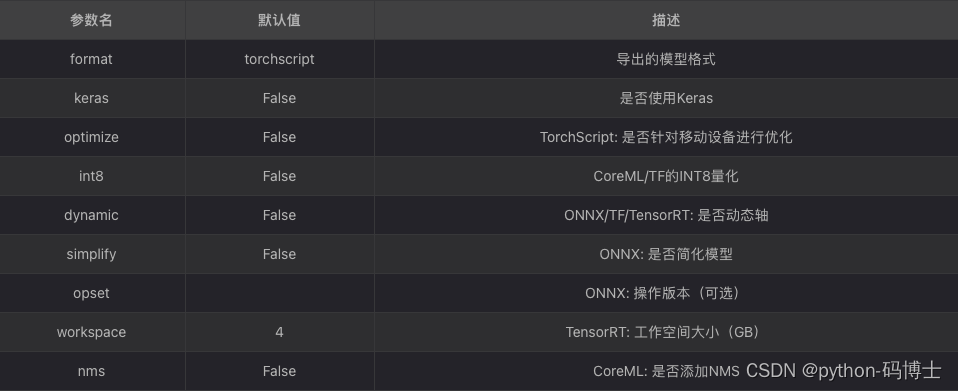
注: TorchScript是PVTorch的模型导出工具。INT8(8位整数量化)是一种量化方法,可将神经网络参数表示为8位整数,以降低存储和计算
成本。ONNX(Open NeuralNetwork Exchange) 是一种跨平台、开放式的机器学习框架。TensorRT是一种用于加速深度学习推理的高性能
引擎。CoreML是苹果公司推出的机器学习框架。Keras是一种流行的深度学习框架。
至此使用 YOLOv8 训练自己的目标检测数据集七大步完结撒花!!!





——实操演示](https://img-blog.csdnimg.cn/direct/742f58c929d8415cb9830b0c829944e4.png)