前面两篇,我们着重讲解了一下《BeanDefinition的加载》和《bean的实例化》。
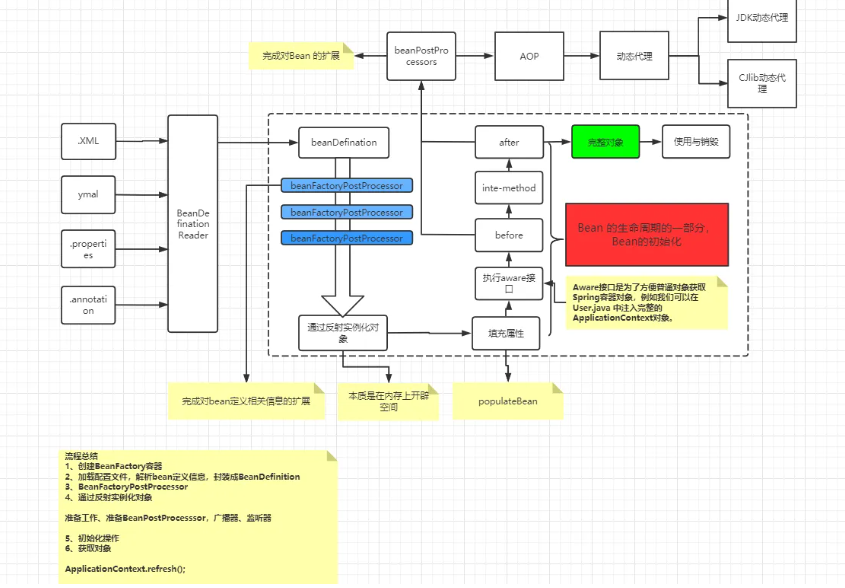
这一篇我们来讲解一下bean的初始化。
我们这里的案例依旧是以SpringBoot3.0、JDK17为前提,案例代码如下:
@Component
public class A {
@Autowired
private B b;
}
@Component
public class B {
@Autowired
private A a;
}
首先,先明确一下这个三级缓存:
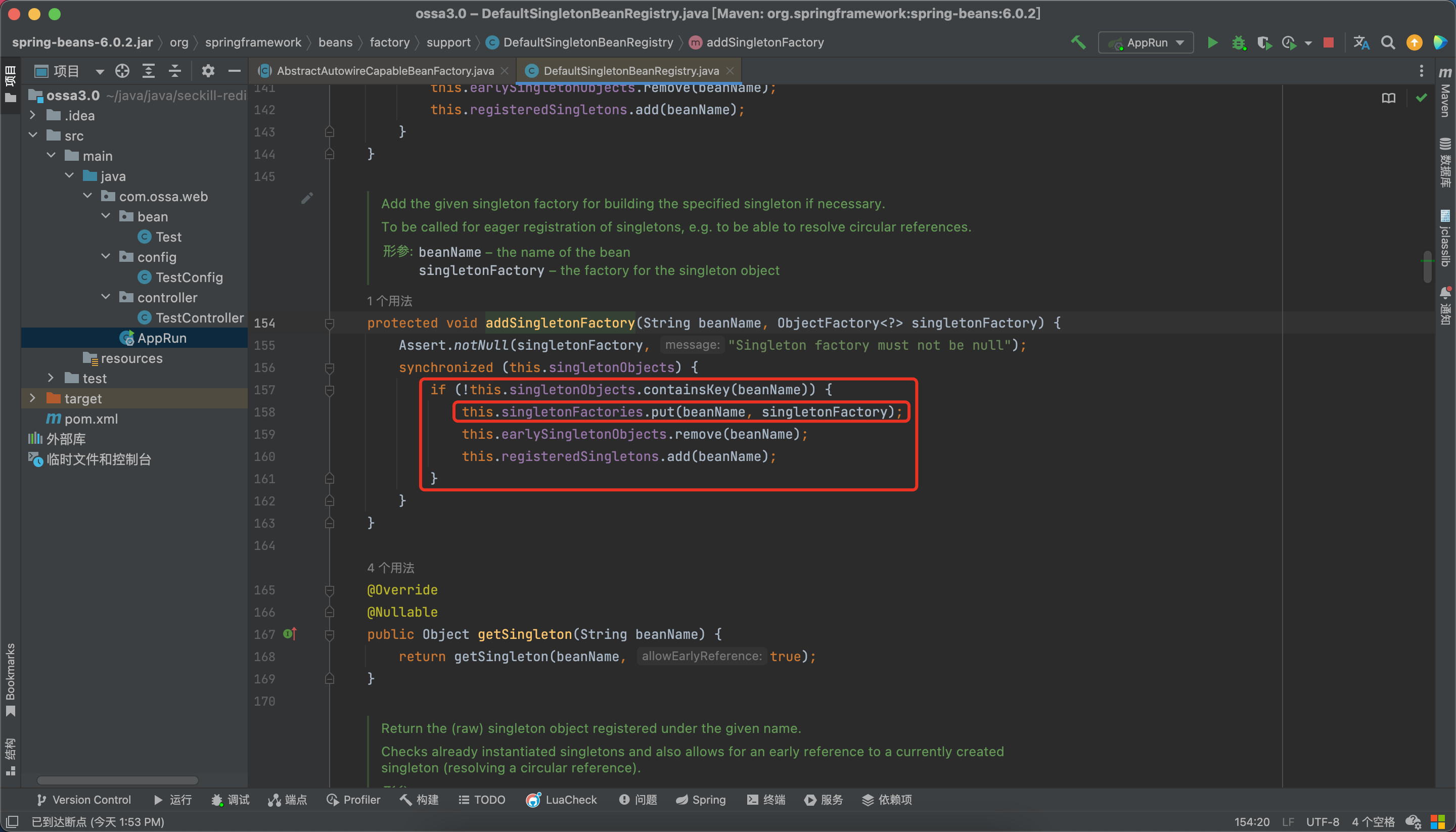
一级缓存 singletonObjects 中存放完全初始化好的 bean 的实例。
二级缓存 earlySingletonObjects中存放早期对象(未完全初始化完成的 bean 实例)。
三级缓存 singletonFactories 中存放 bean 工厂对象。
bean 创建起来比较复杂,所以将bean缓存起来,方便之后使用。
上一篇,我们实例化了bean之后,将bean放入了第三级缓存,看一下这个addSingletonFactory方法,如果一级缓存中没有对应的bean,那么会将未初始化的bean放入三级缓存,会将bean提前暴露出来。
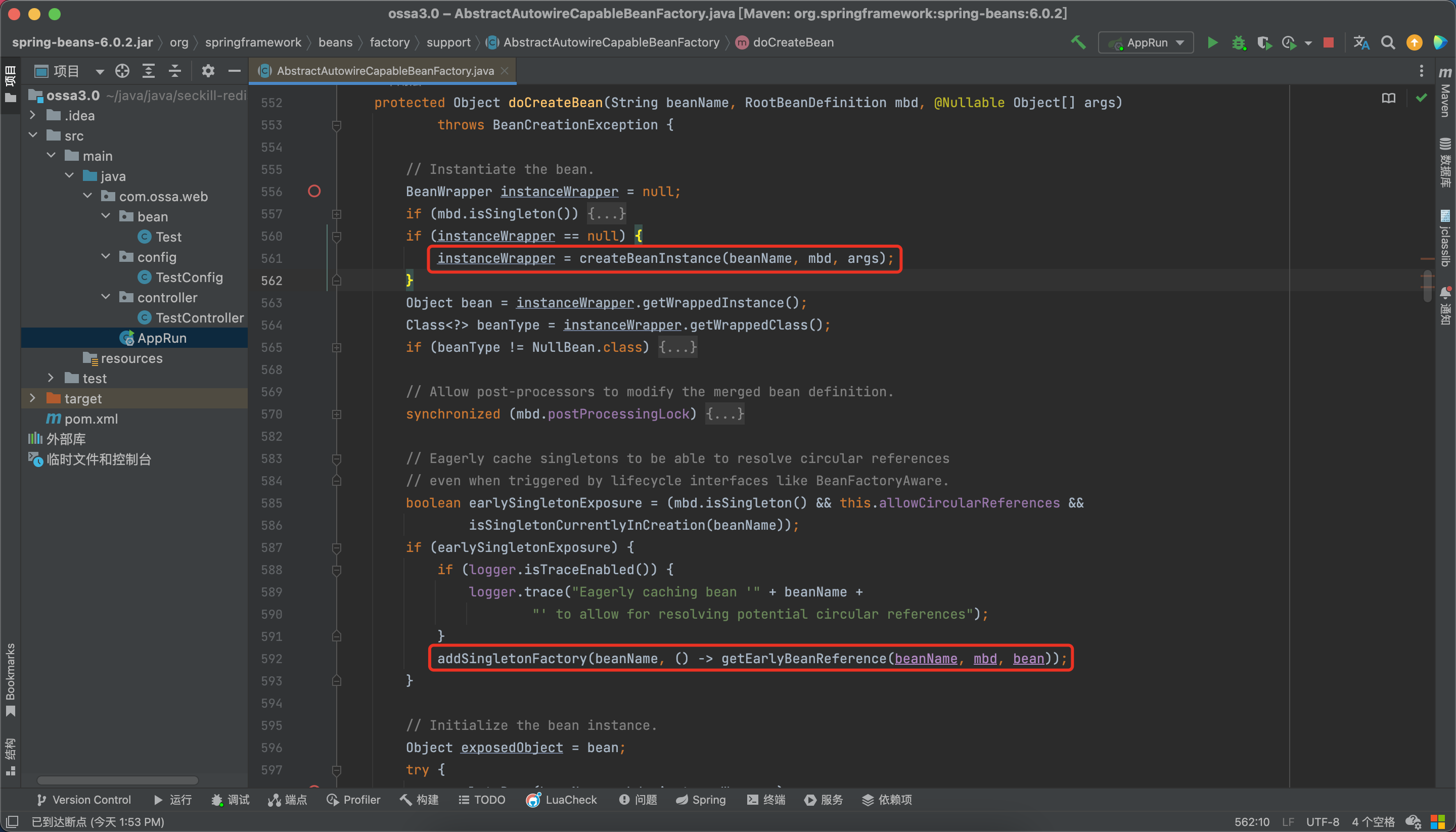
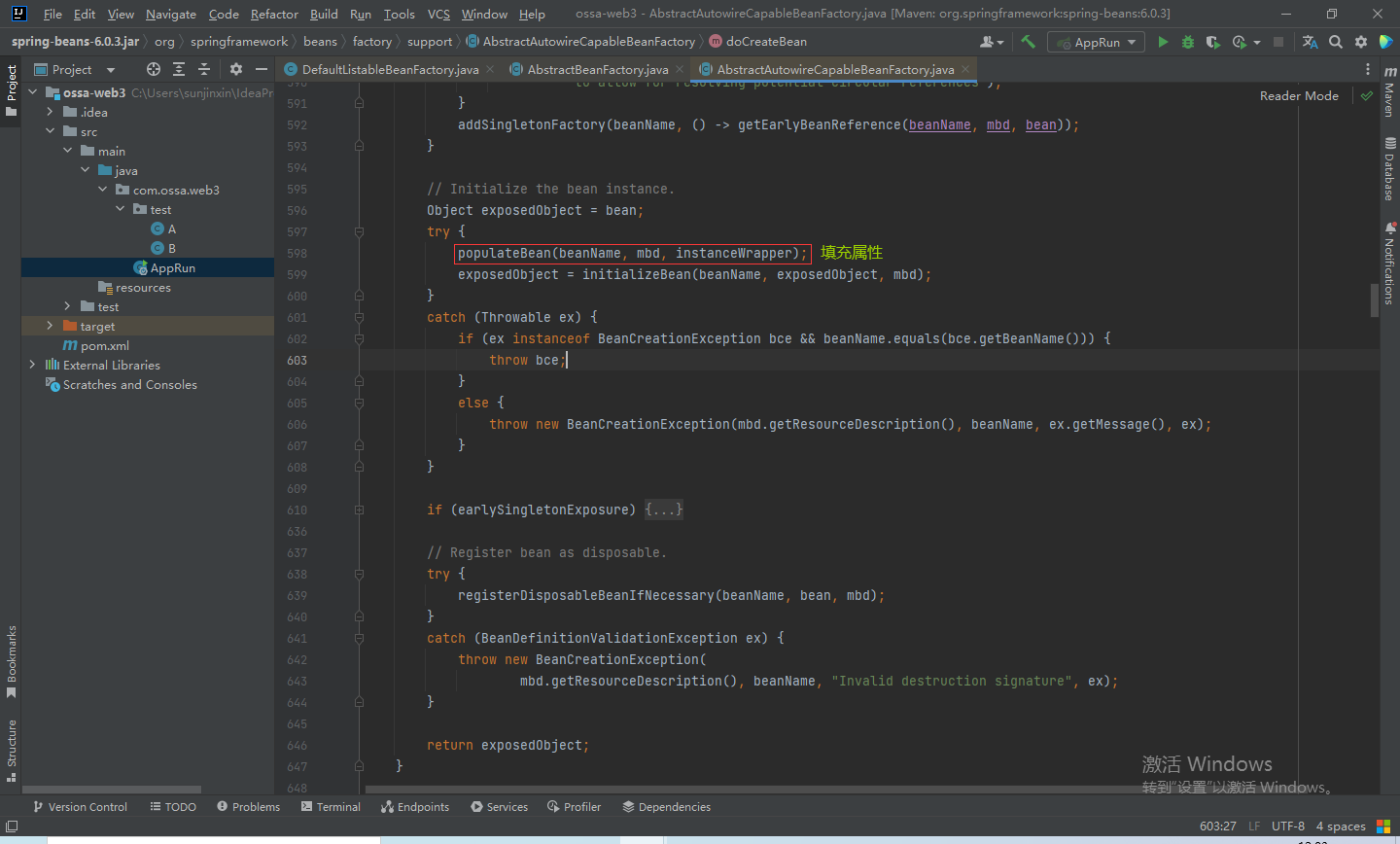
接下来,会通过populateBean()方法对bean的属性进行填充。
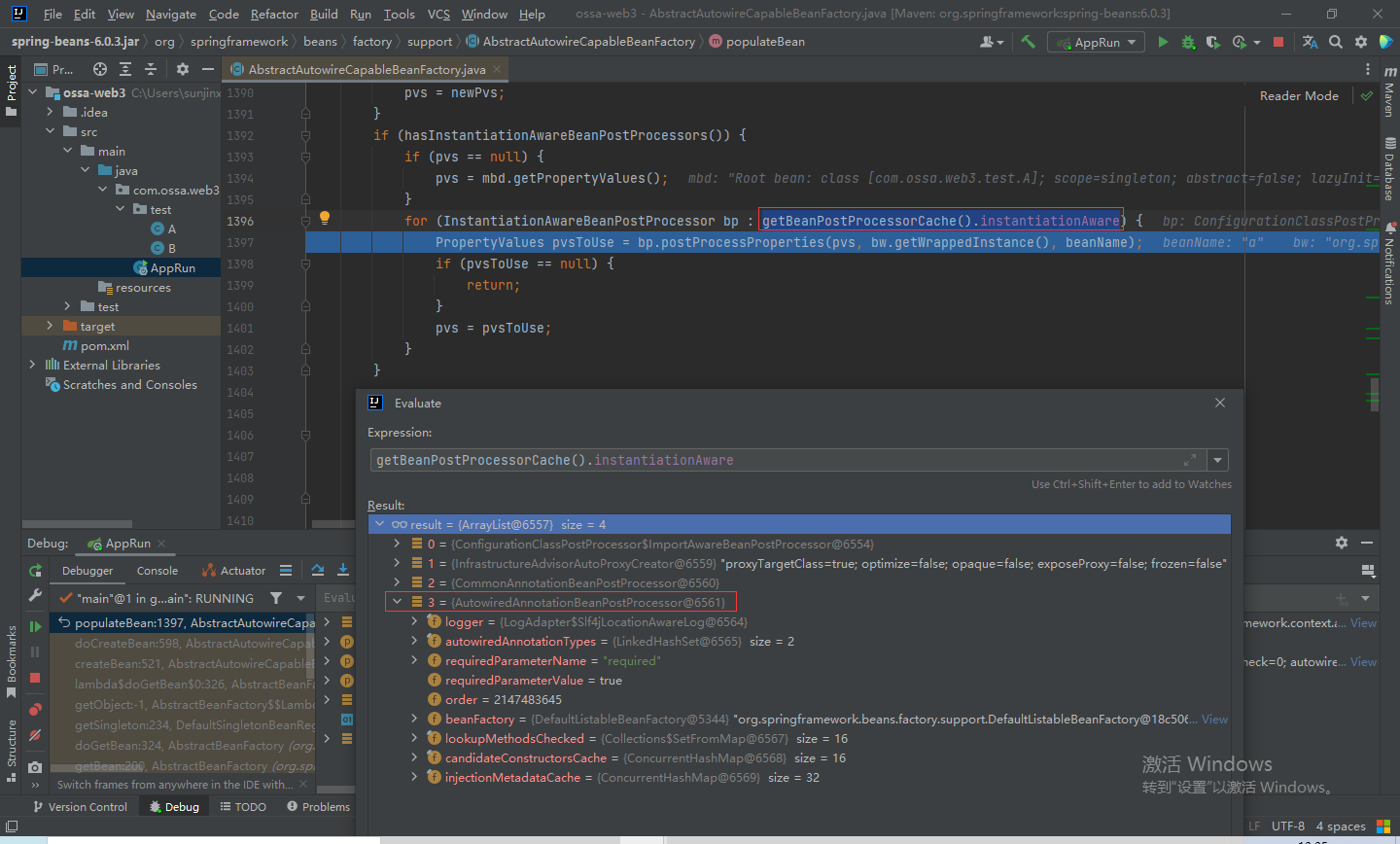
步入populateBean()方法,首先会获取BeanPostProcessors,主要是在bean初始化之前做一些事情,如下,我们总共获取到4个BeanPostProcessors ,最后一个AutowiredAnnotationBeanPostProcessor是本节较为关键的BeanPostProcessor,它主要是用来处理我们@Autowired注解。
我们进入到AutowiredAnnotationBeanPostProcessor#postProcessProperties方法中,首先有个findAutowiringMetadata方法来处理@Autowired
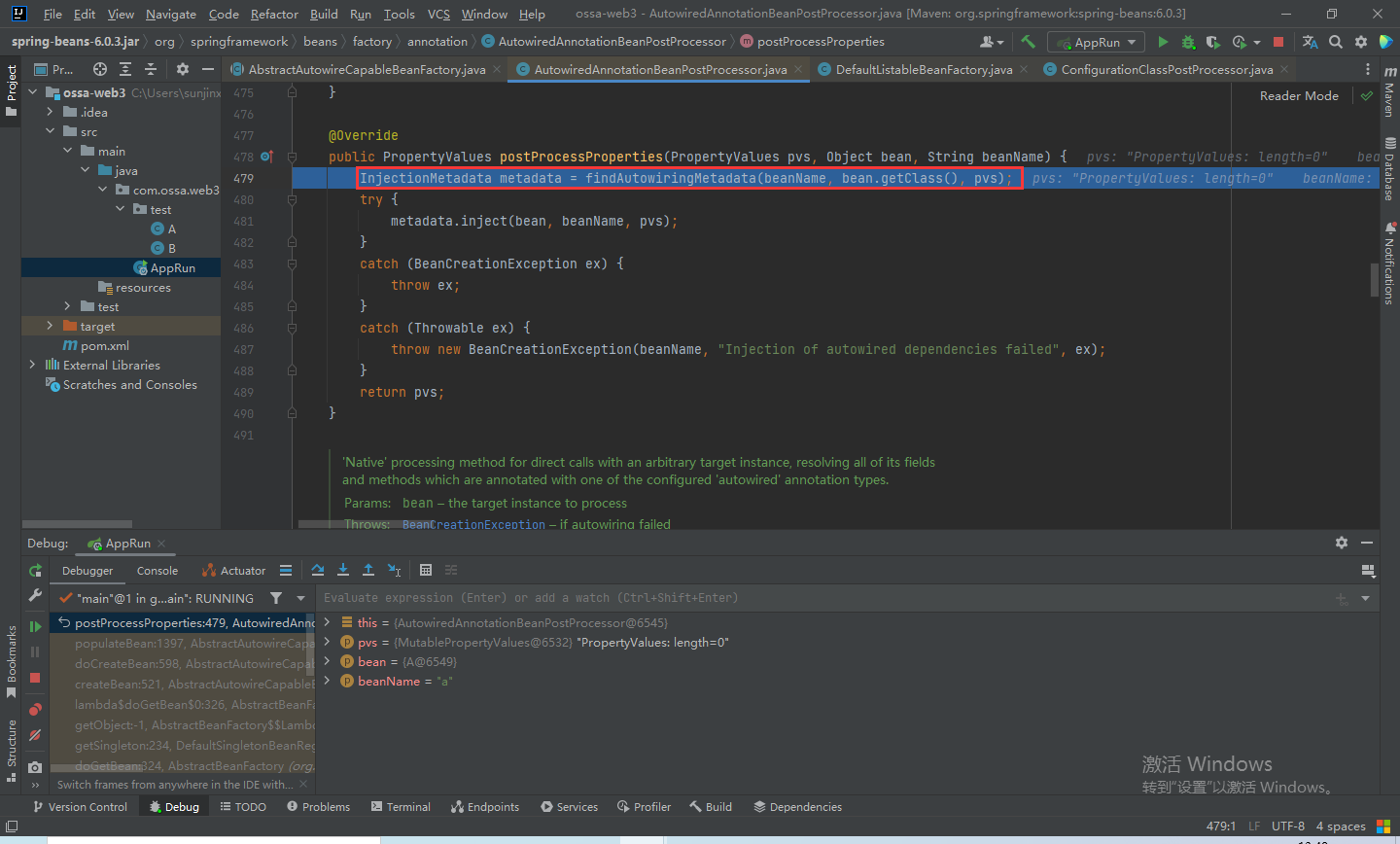
我们步入findAutowiringMetadata方法中,发现会从injectionMetadataCache的map集合中获取。
但是我们没有往这个缓存中put对象啊,所以,这个metadata是null,而后,我们会简单的判断一下:
public static boolean needsRefresh(@Nullable InjectionMetadata metadata, Class<?> clazz) {
return (metadata == null || metadata.needsRefresh(clazz));
}
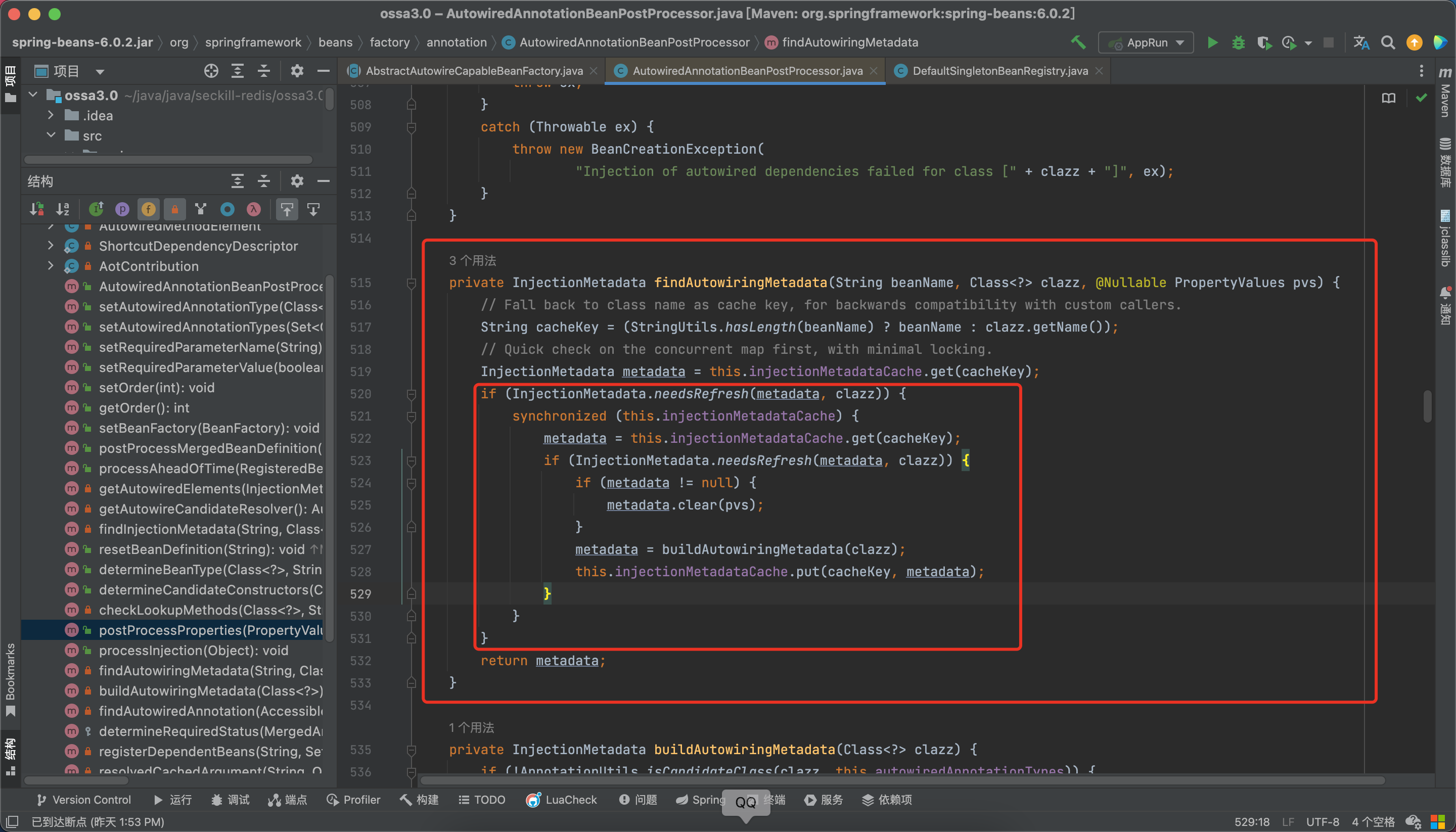
如果为null,我们会调用buildAutowiringMetadata方法,在这里我们会看到很熟悉的设计,就像单例模式一样的双重锁/双重校验锁(DLC,即double-checked locking)
而后会进入buildAutowiringMetadata方法去创建相关信息。
这里主要有两点,一个是针对属性上的注解,一个是针对方法上的注解,大部分的时候会放在属性上,也有时候会放在方法上,比如set方法上。
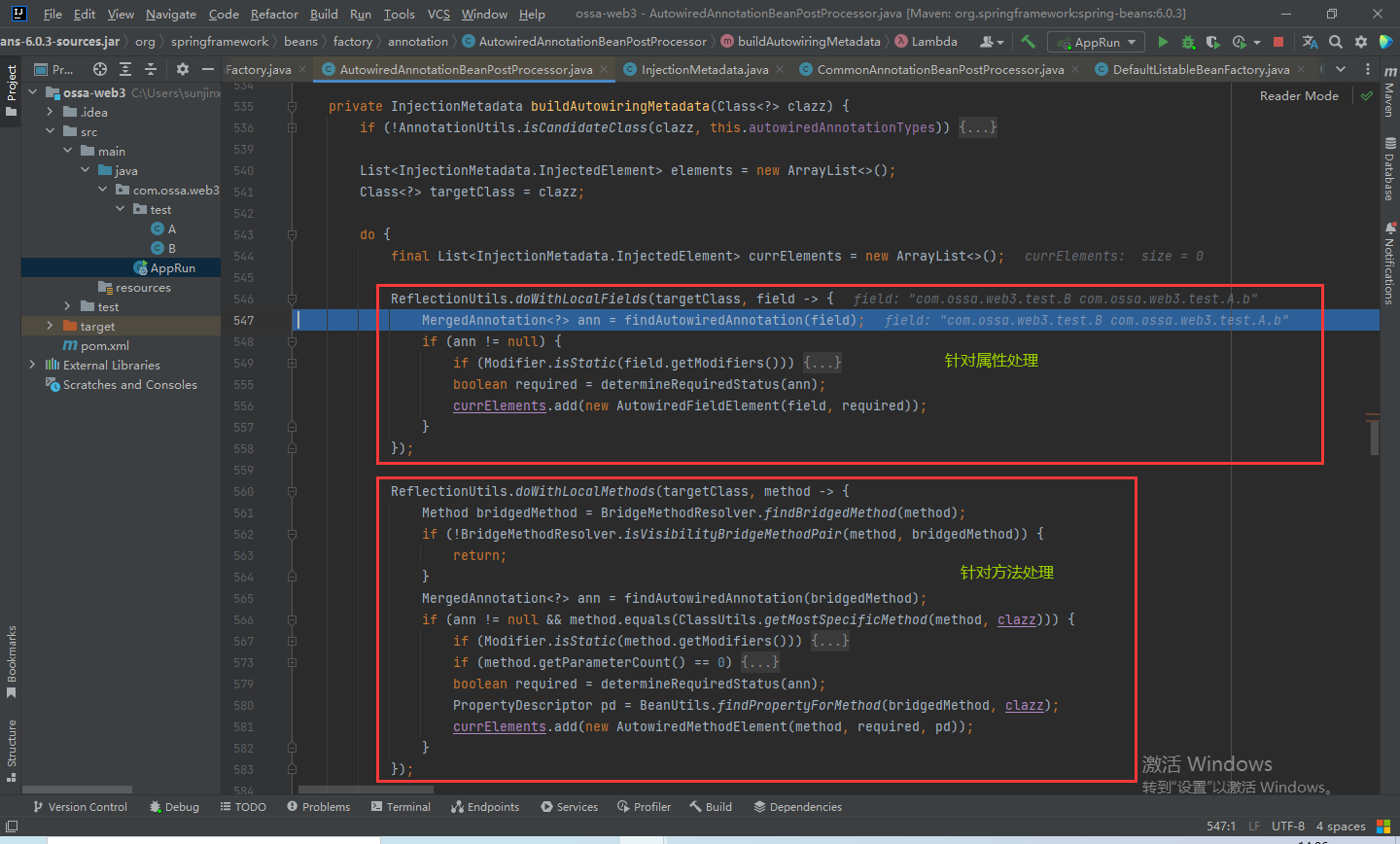
我们来一起看一下这个处理属性的doWithLocalFields方法,首先通过getDeclaredFields方法获取类的属性集合,然后进行遍历调用函数去处理。
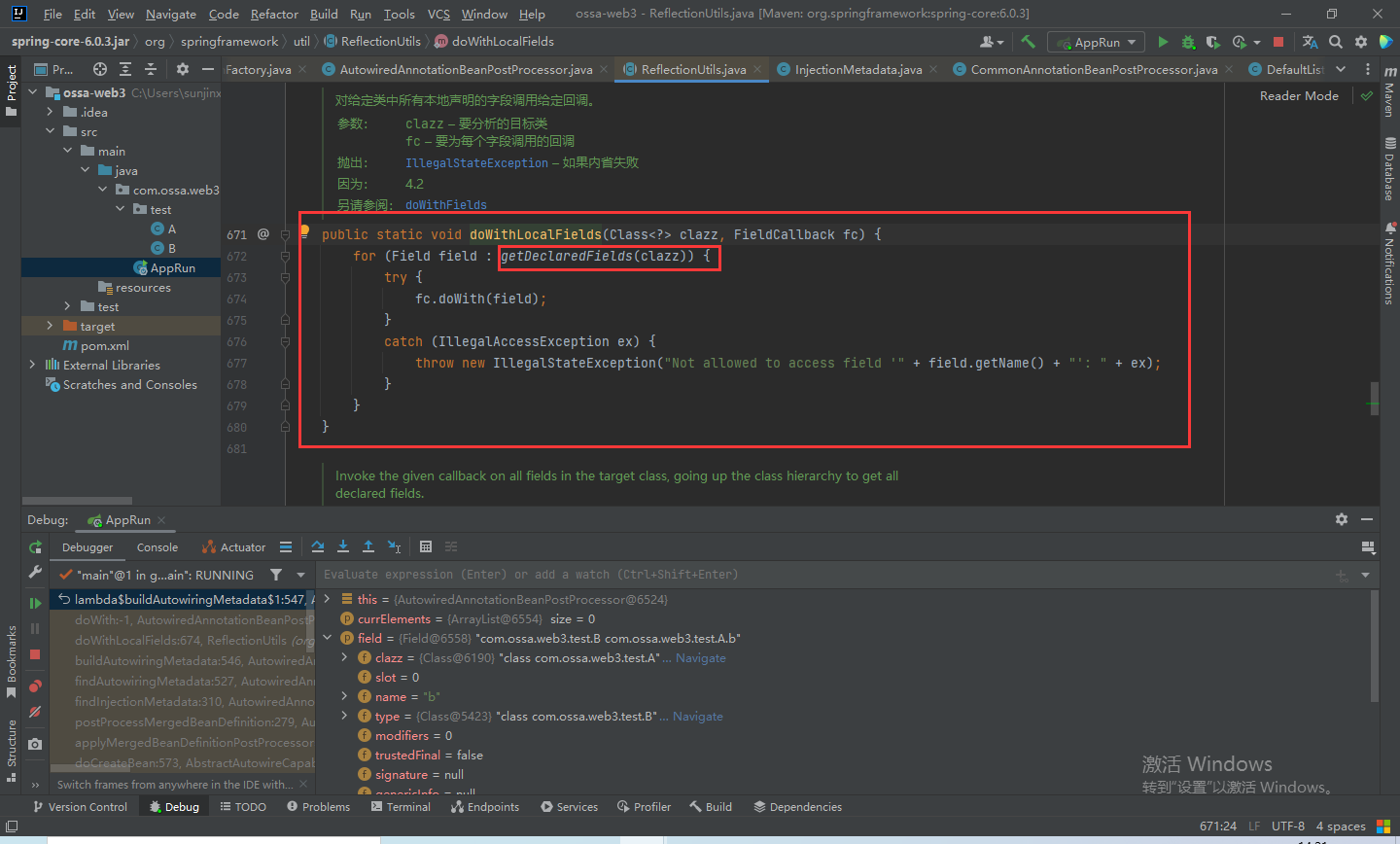
我们来看一下是如何获取类的属性数组的,还用想嘛,当然是反射了,不信你看。第一次从属性缓存中获取,肯定获取不到啊,然后反射获取,在加入缓存中。
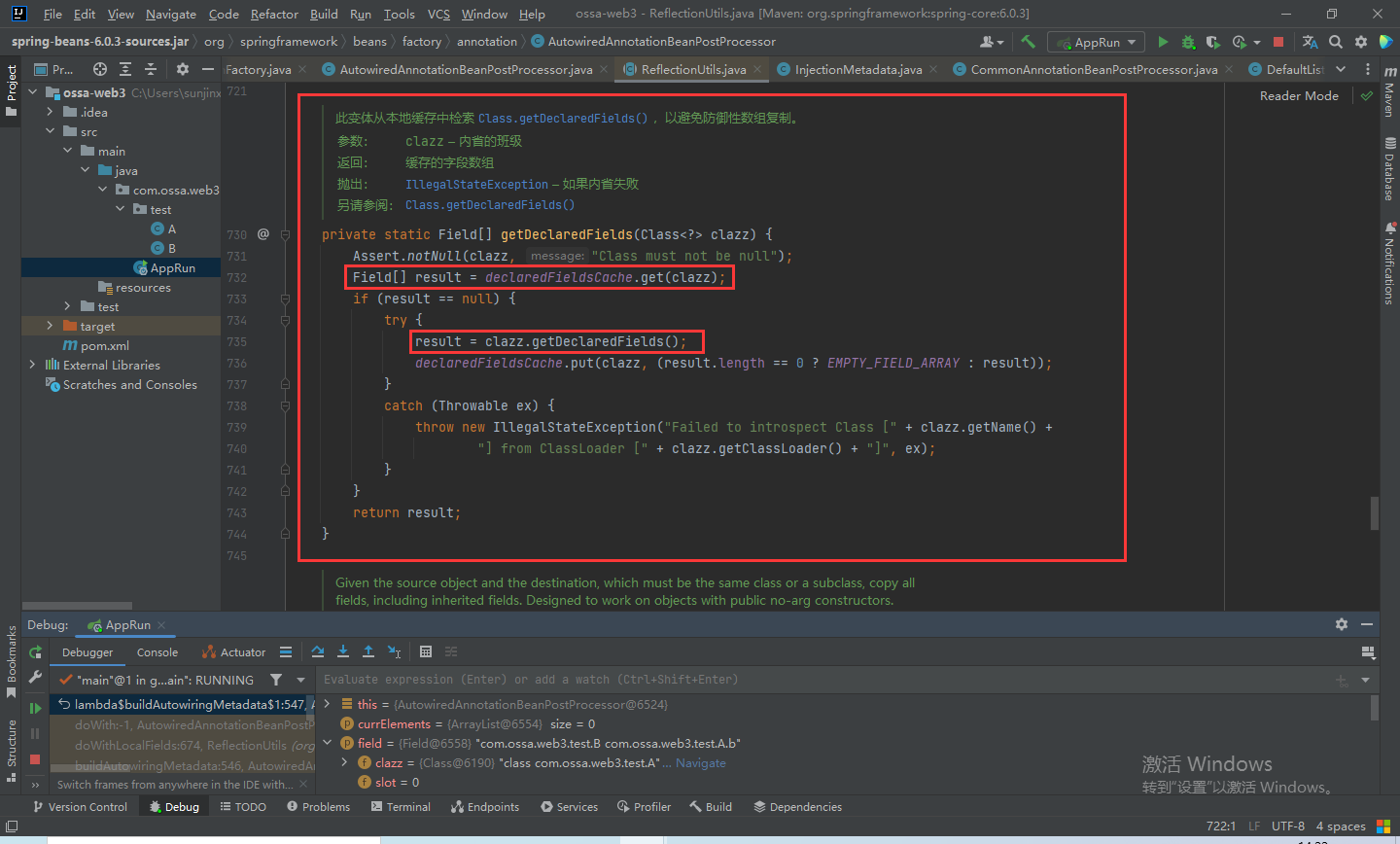
然后包装成AutowiredFieldElement对象,add到currElements列表中,最后在把各个bean的所有元素add到elements列表中。
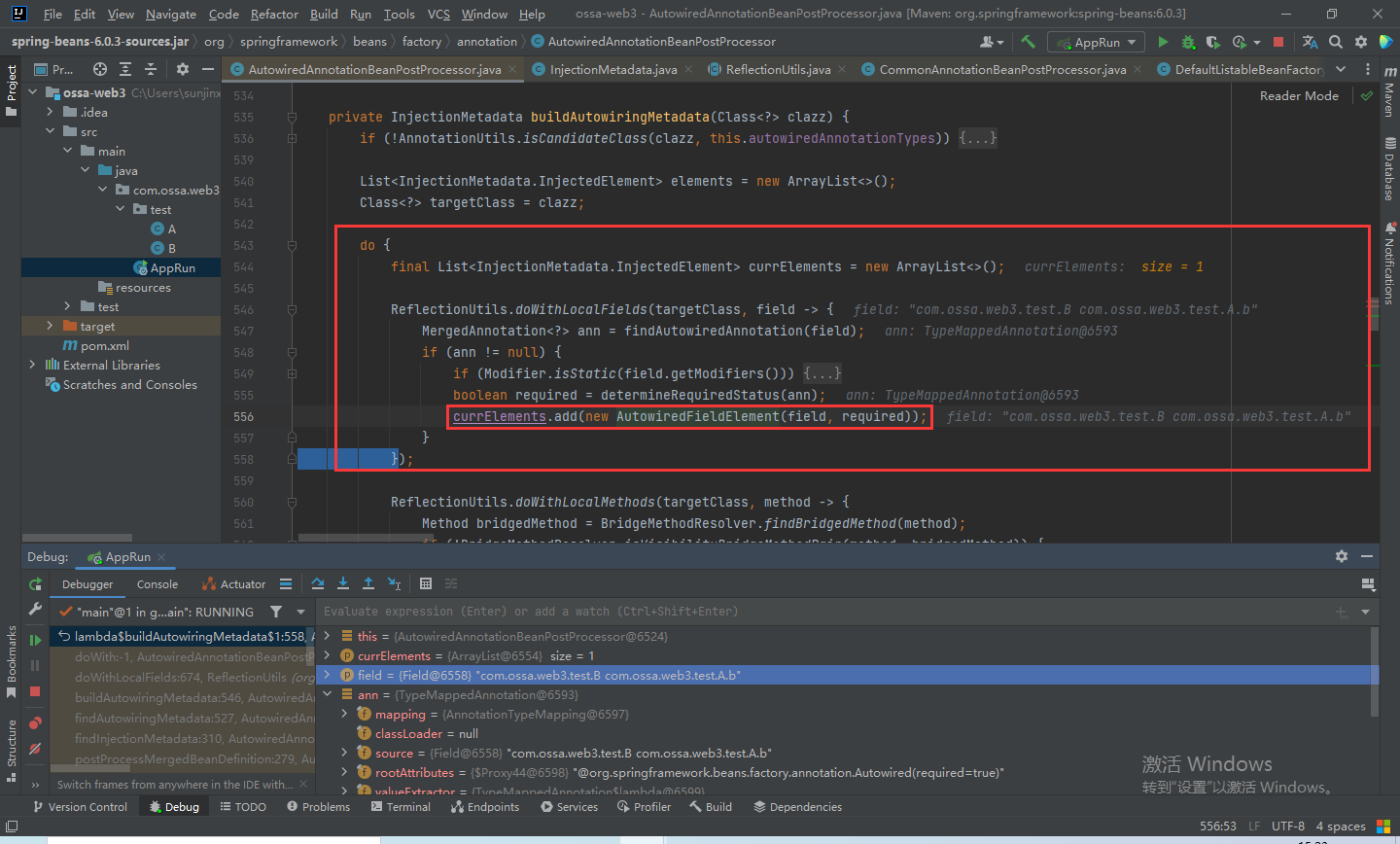
最后会通过InjectionMetadata#forElements方法将所有的元素封装成InjectionMetadata对象返回。
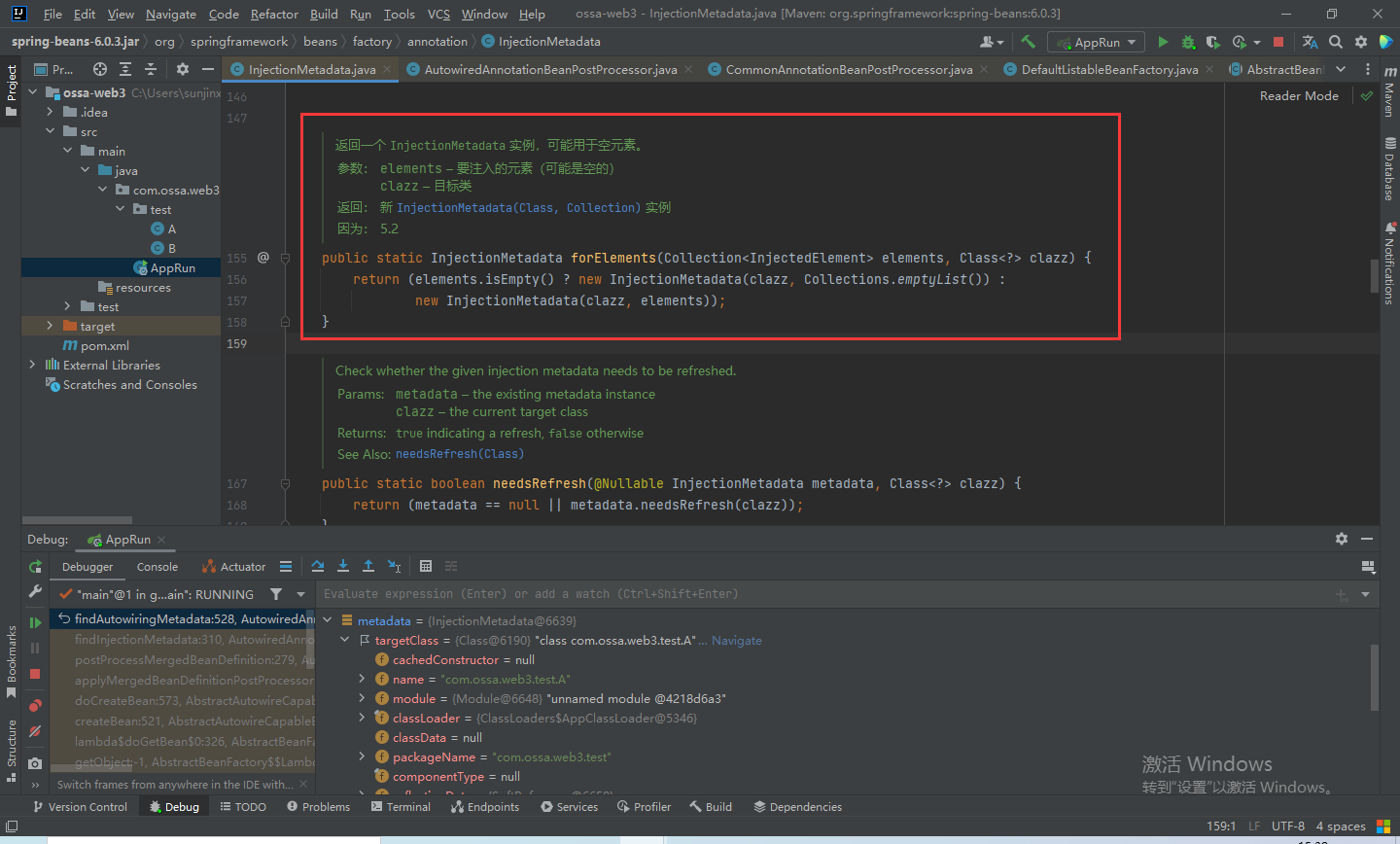
最后把注入元素的信息放进injectionMetadataCache的map集合中,以便下次就可以从缓存中获取。
到这里,我们就解析完了带有@Autowired注解的属性,接下来进入我们的核心方法inject。
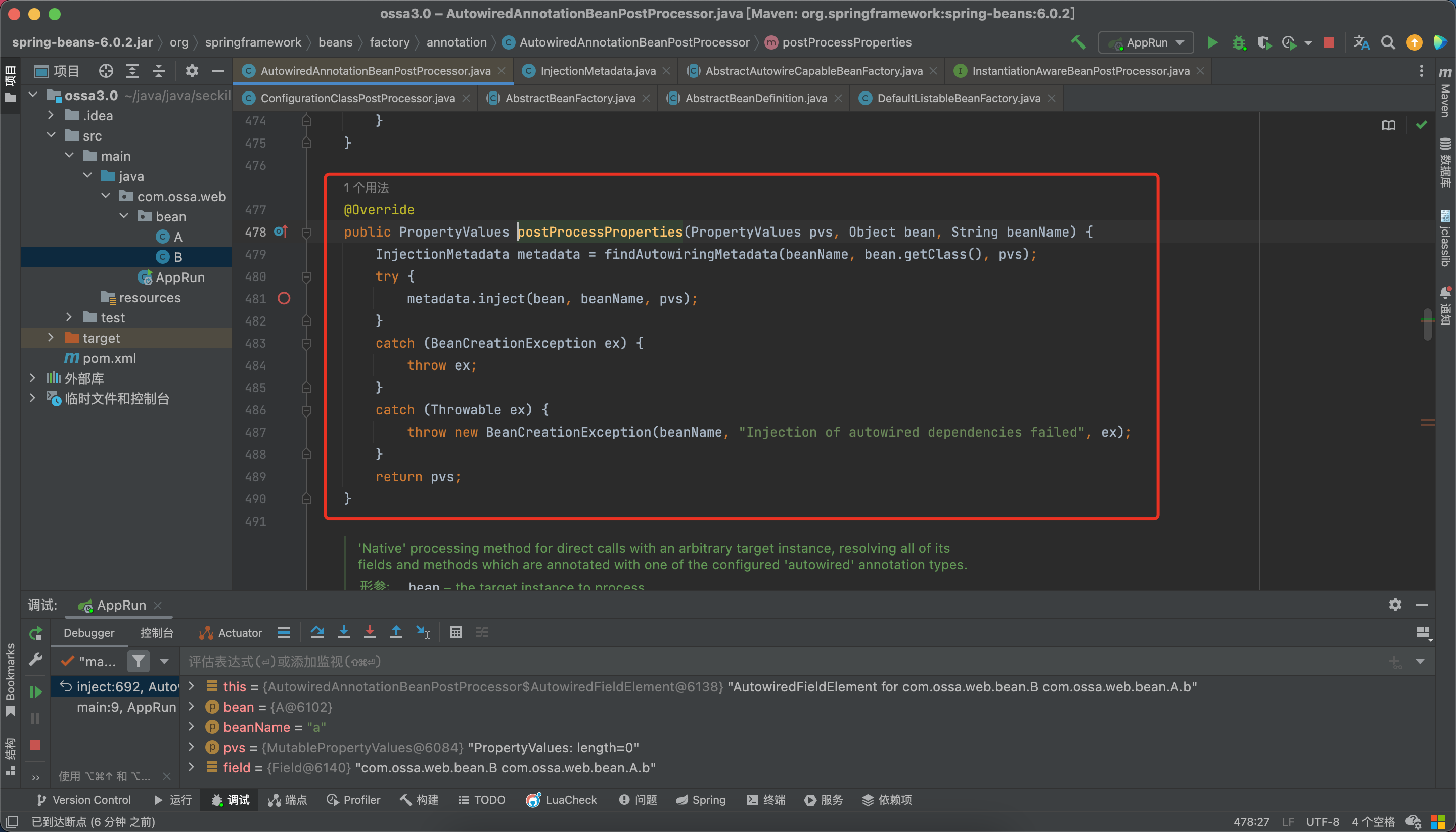
在这里首先会判断bean中是否有属性,如果有,循环遍历属性,调用inject方法。
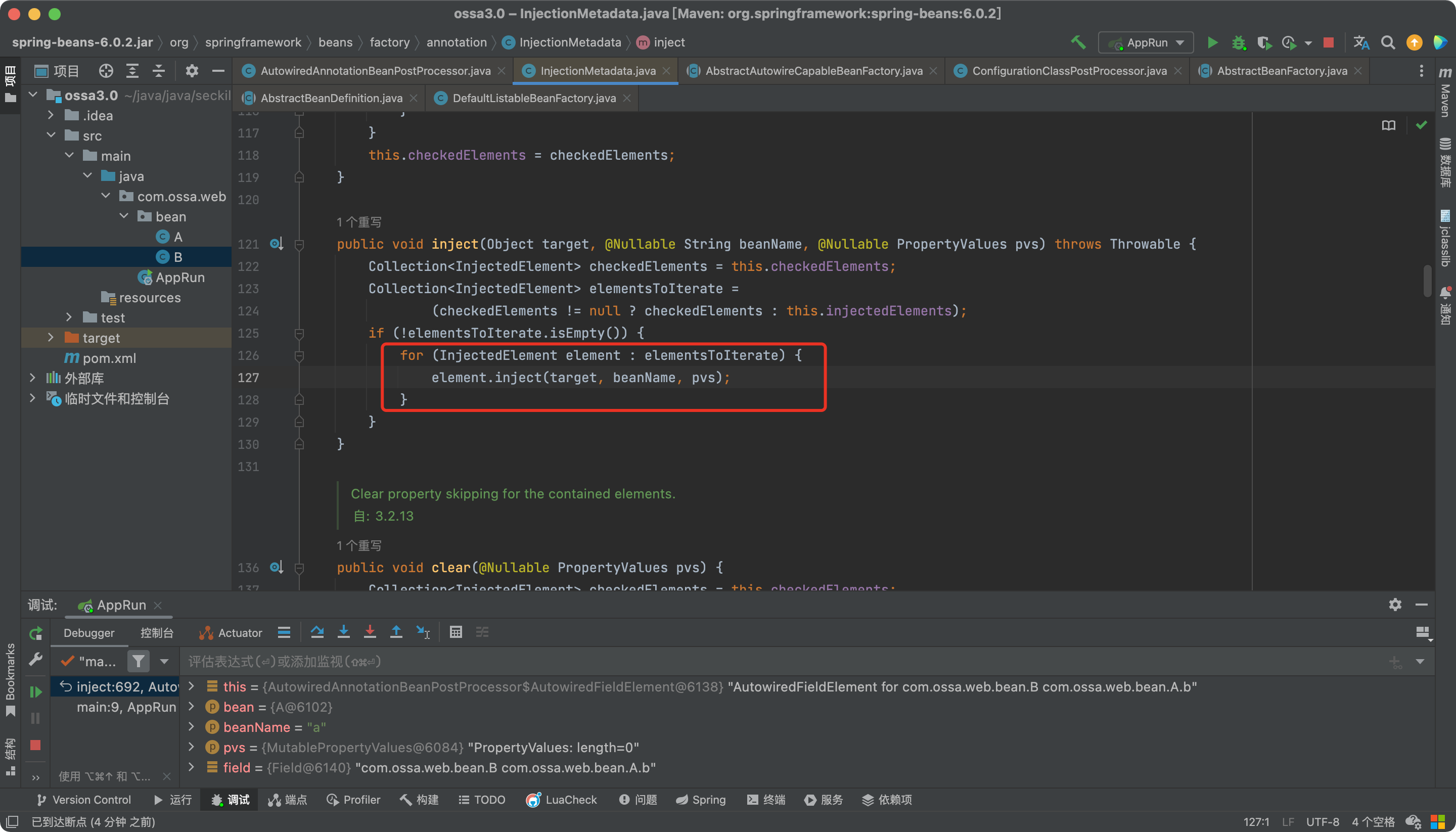
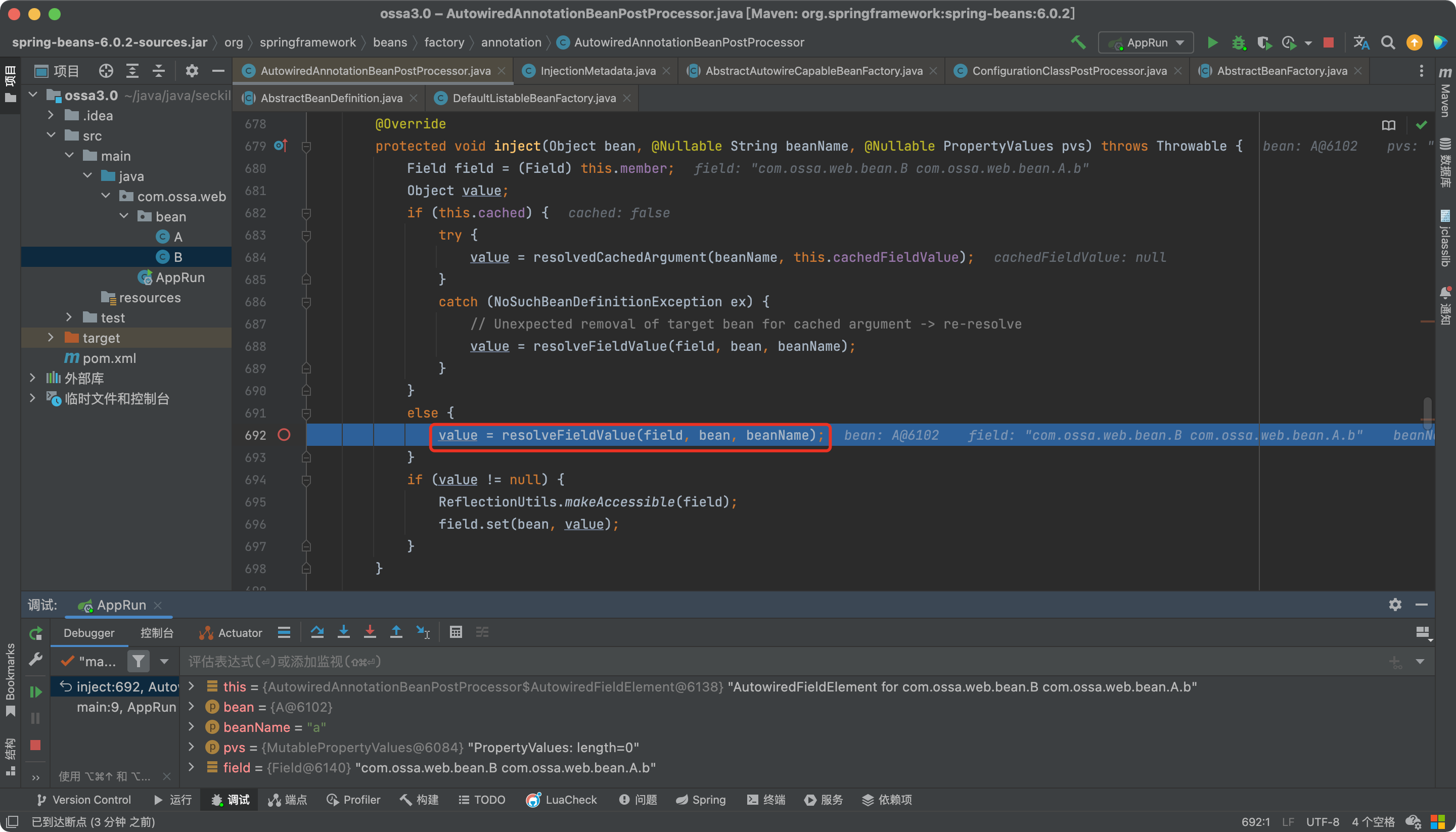
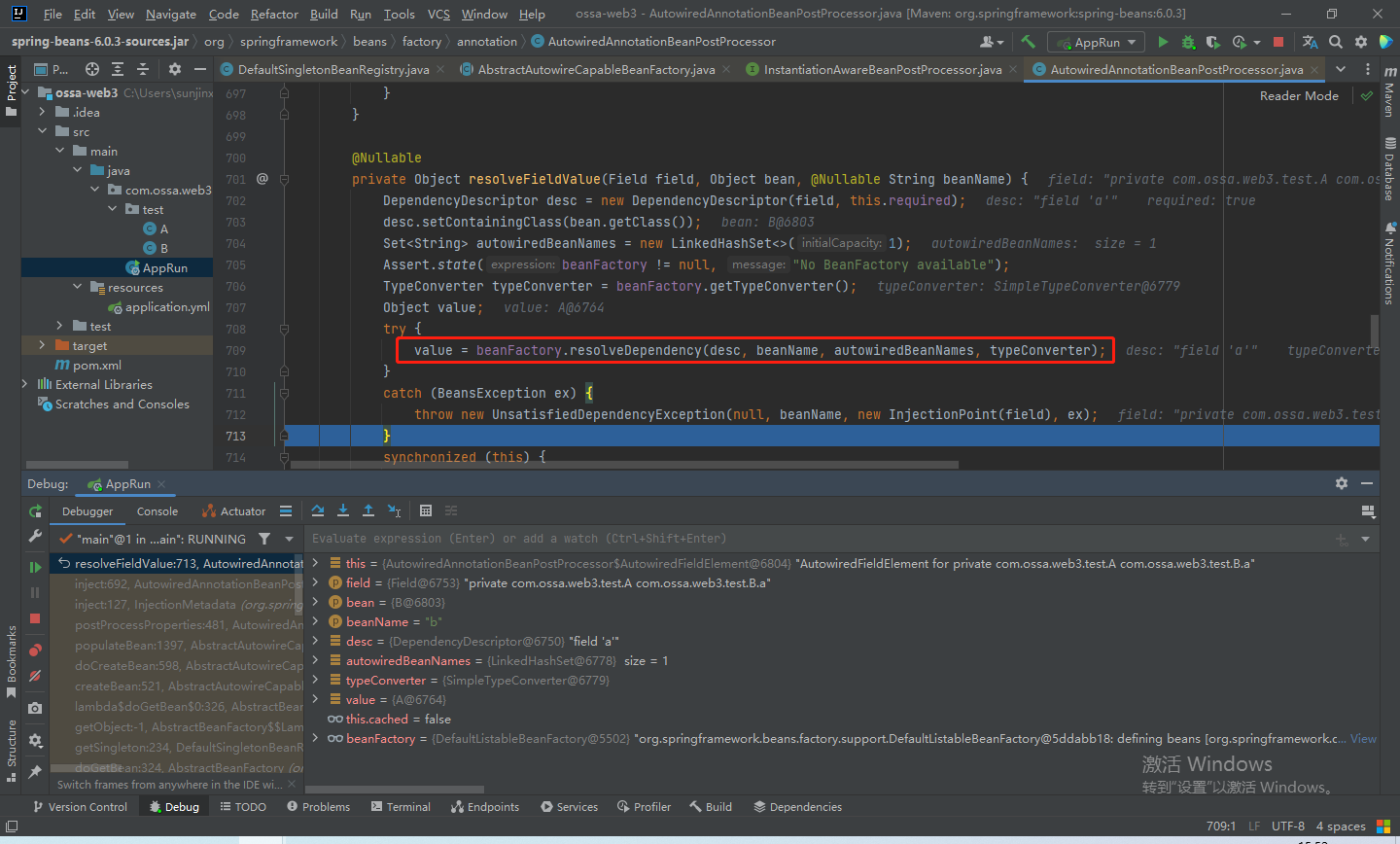
属性准备就绪,着重看一下resolveFieldValue方法
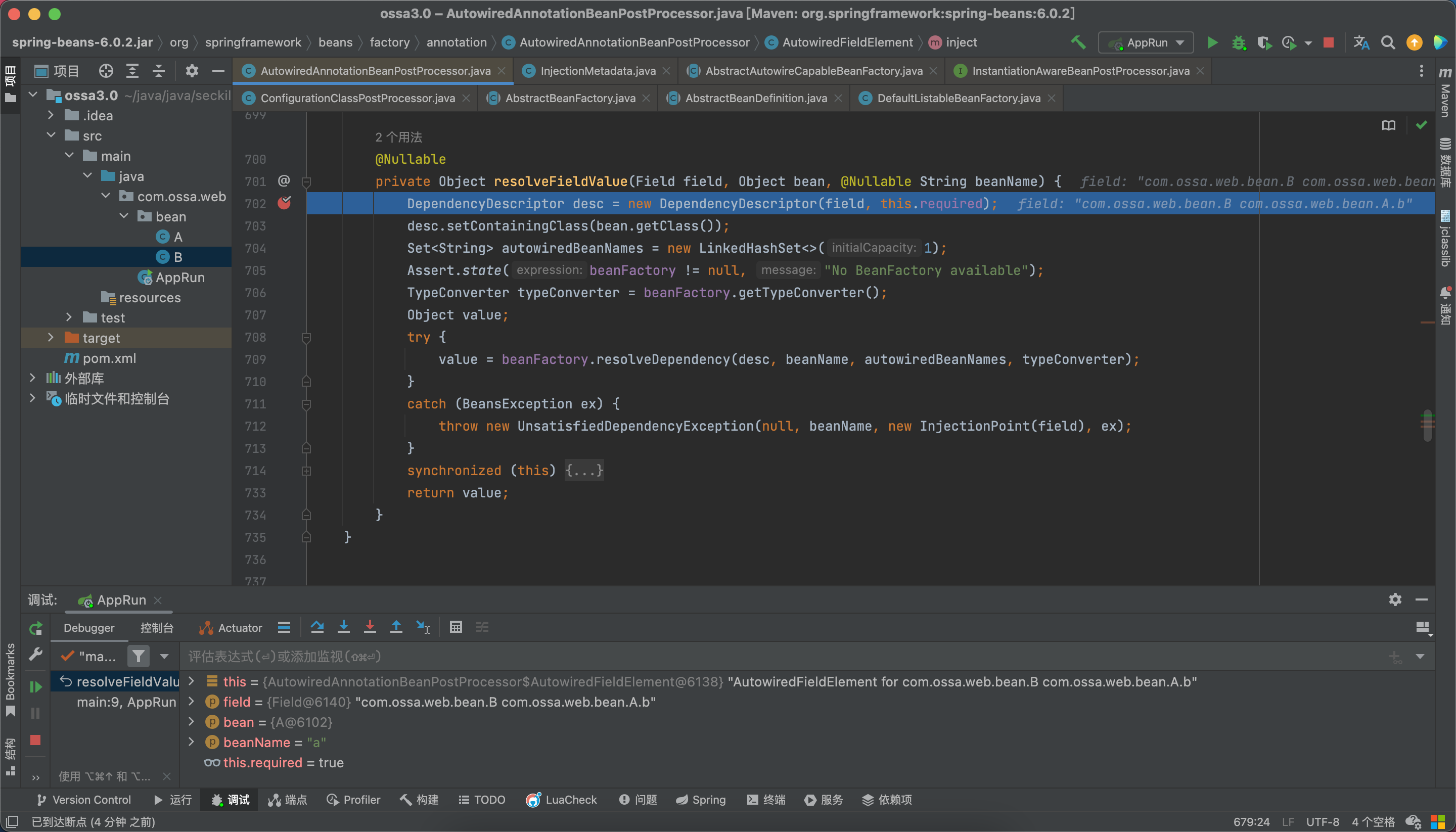
步入上图的789行
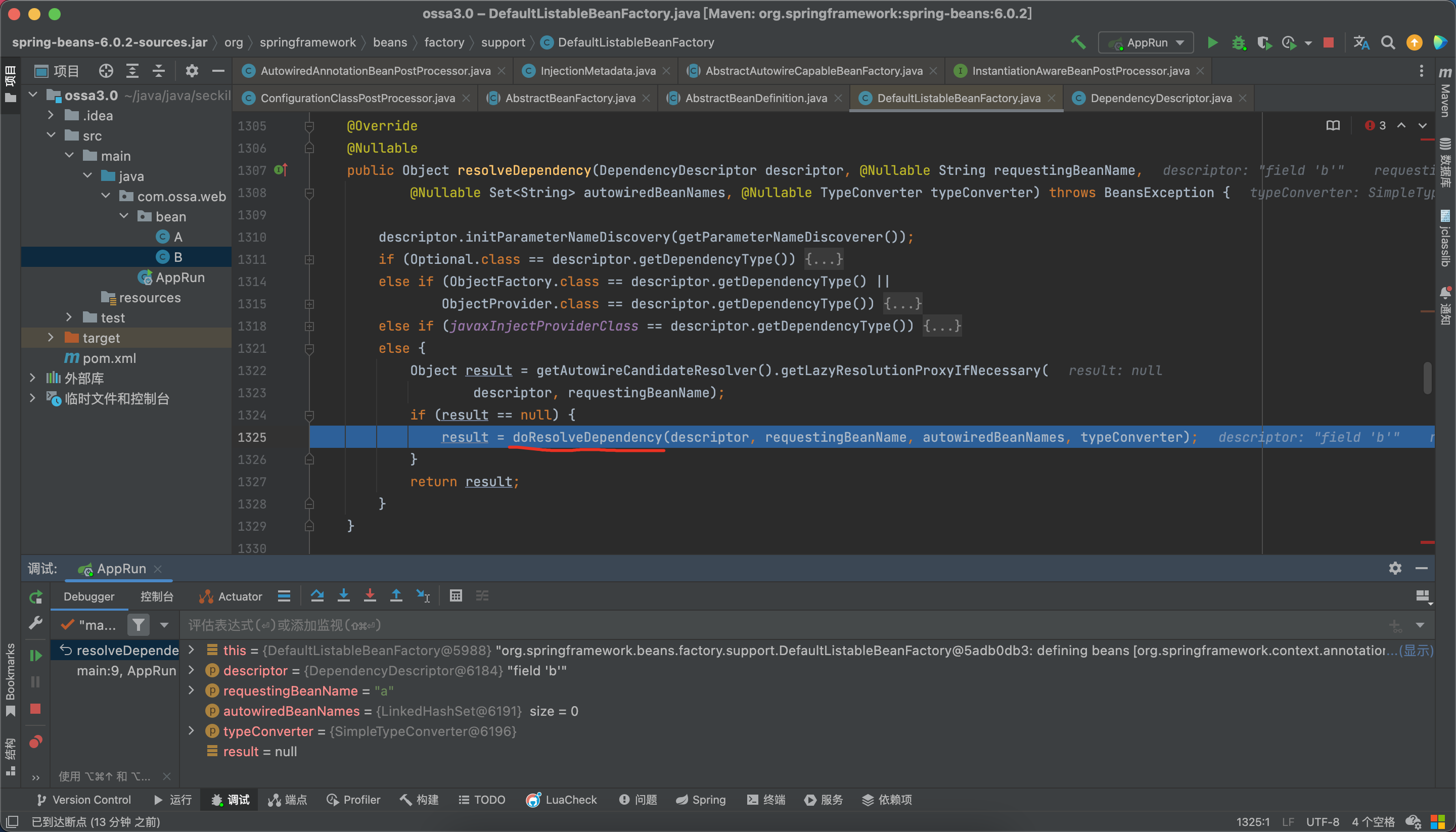
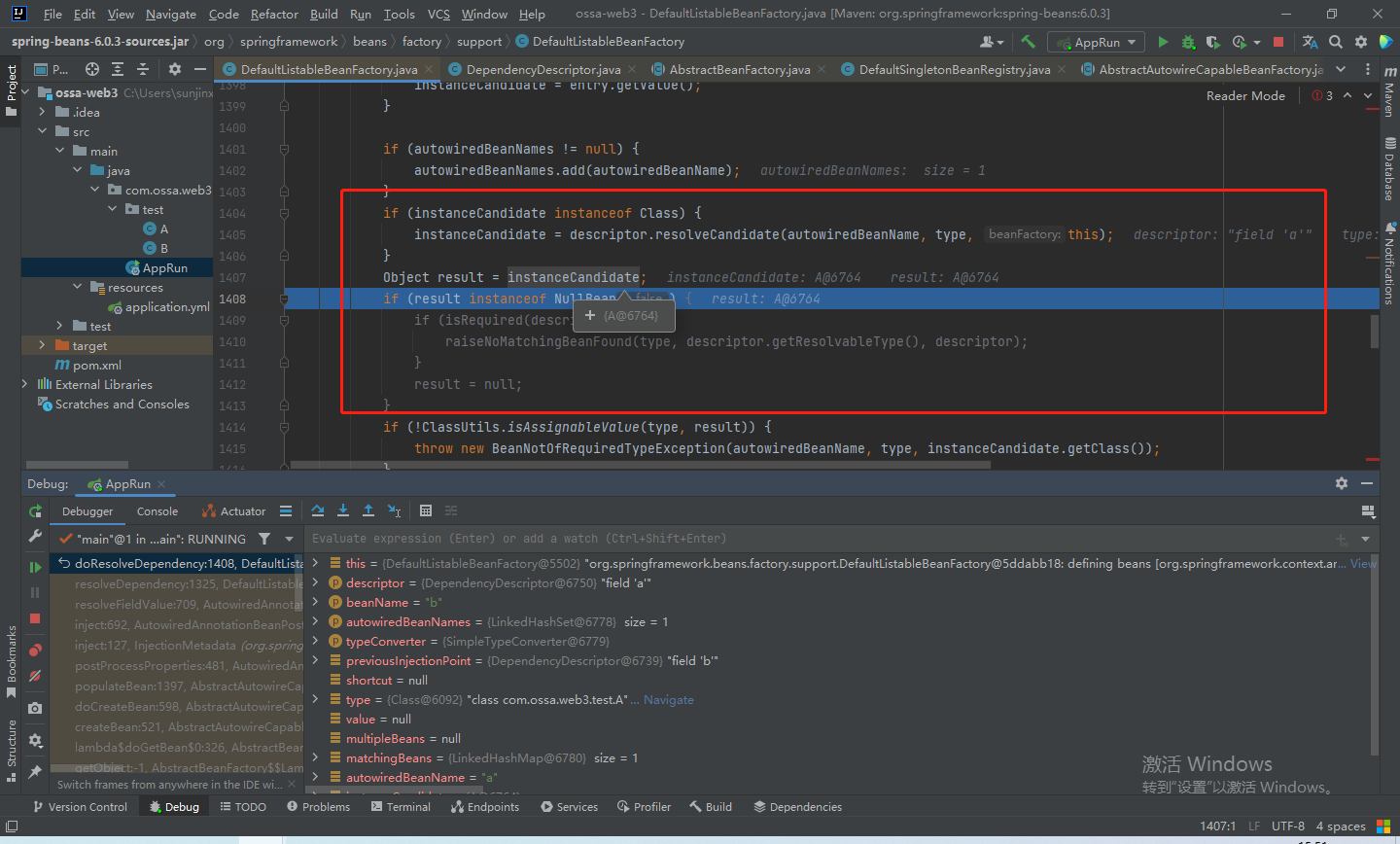
步入doResolveDependency方法,最后会对这个属性B进行解析
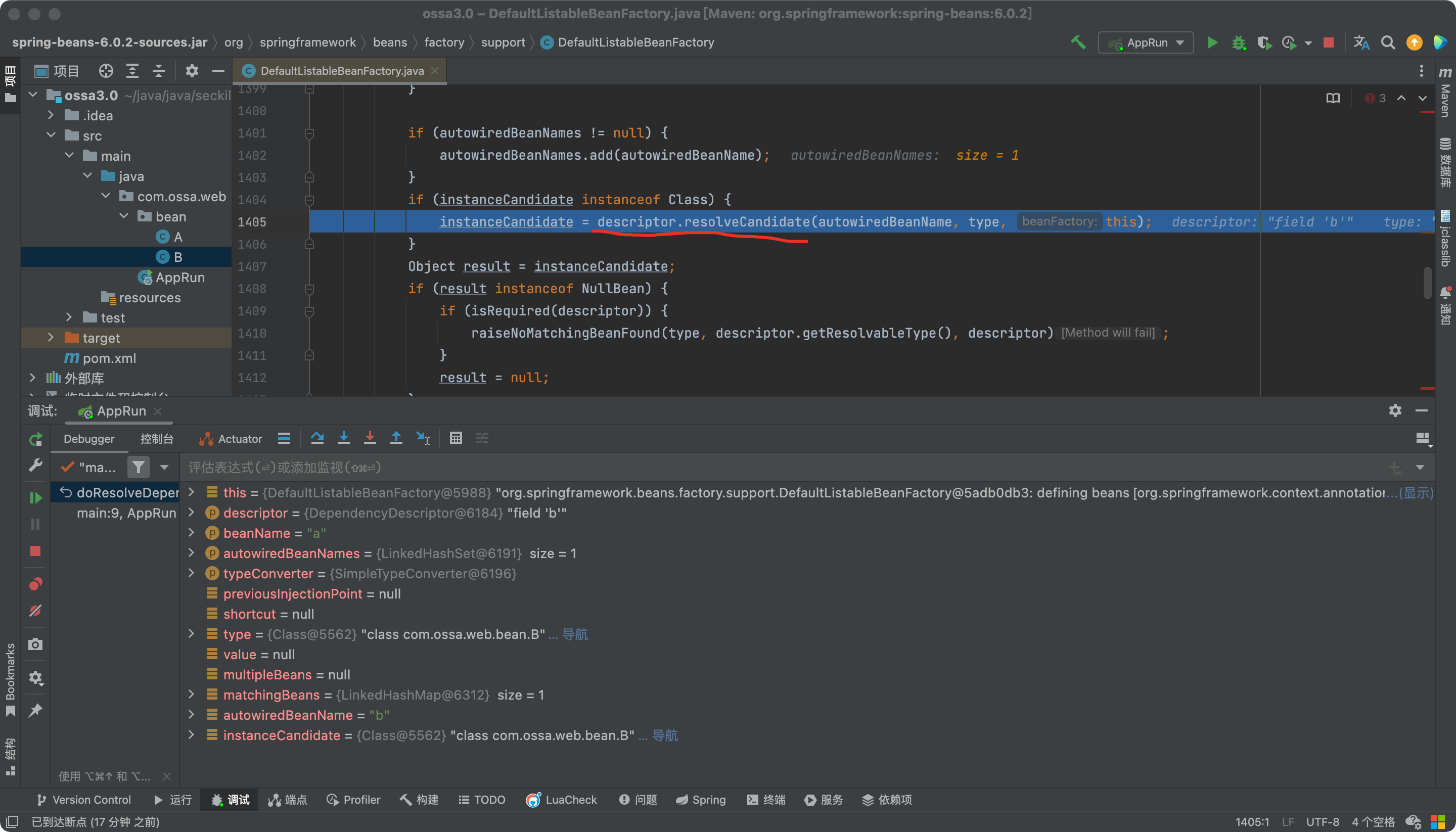
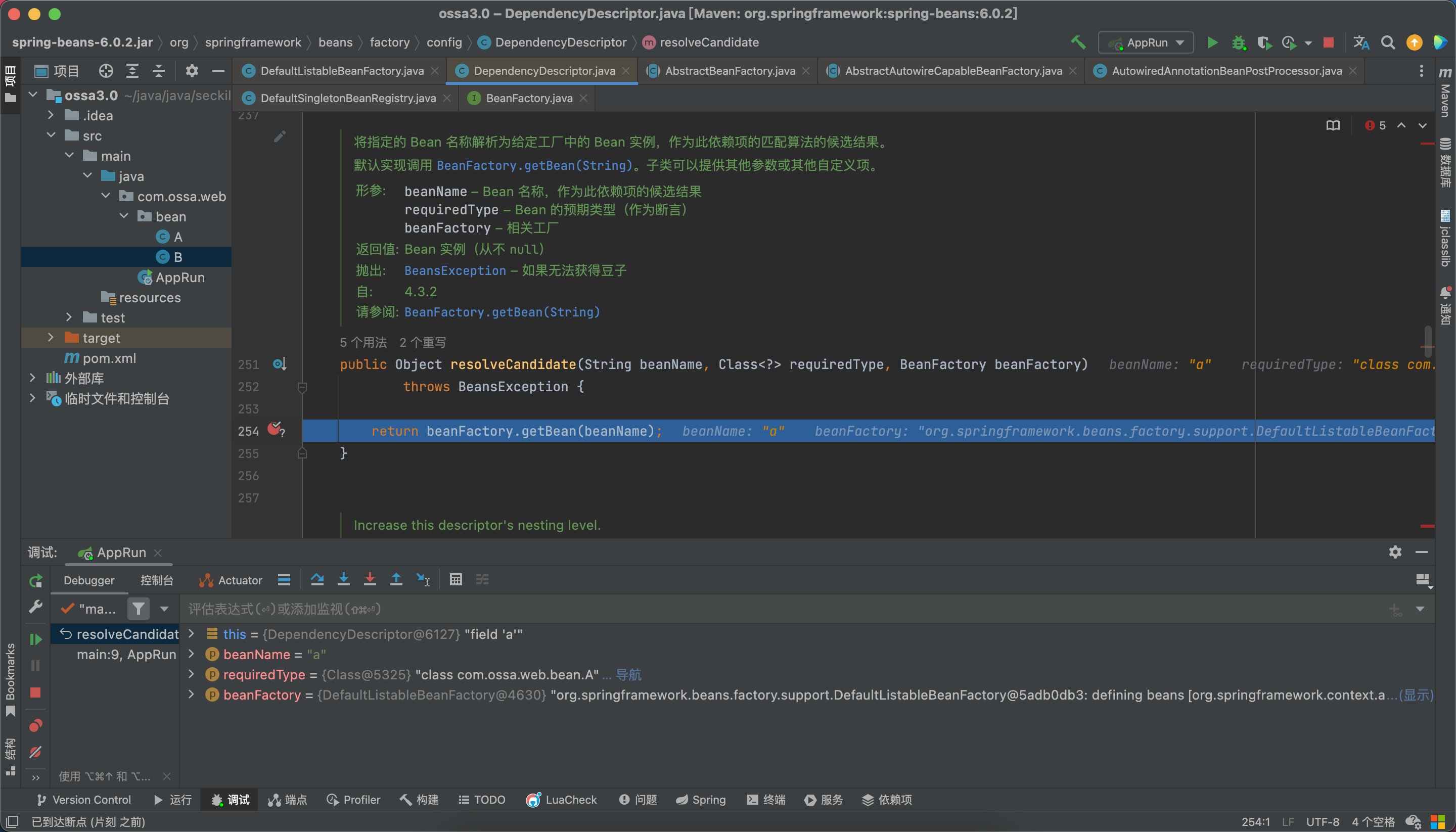
步入resolveCandidate方法,这不是beanFactory么,真巧,来了老弟。
这不是想去缓存里找么,嘿嘿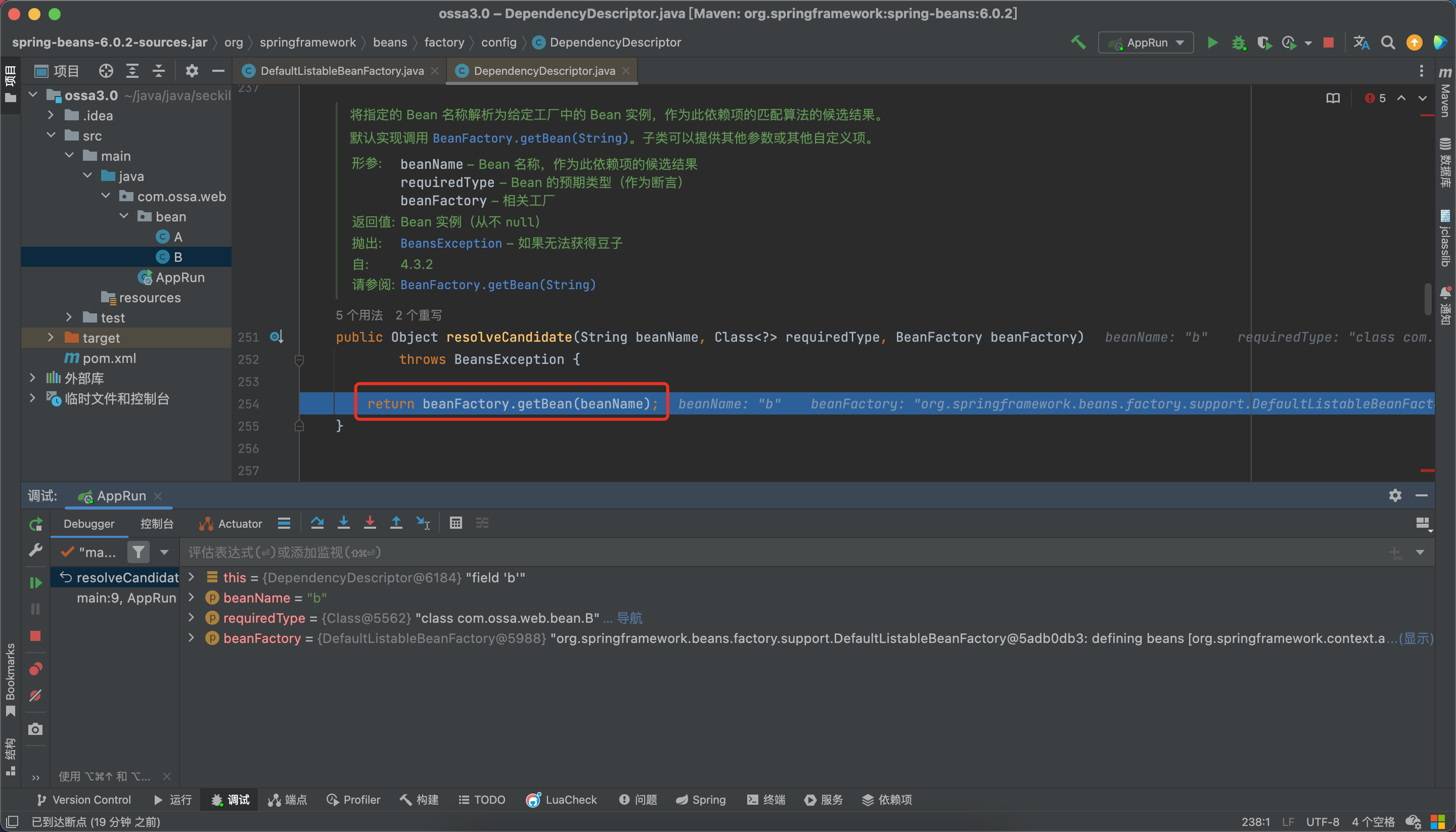
此时b还没有实例化,缓存中肯定找不到啊。
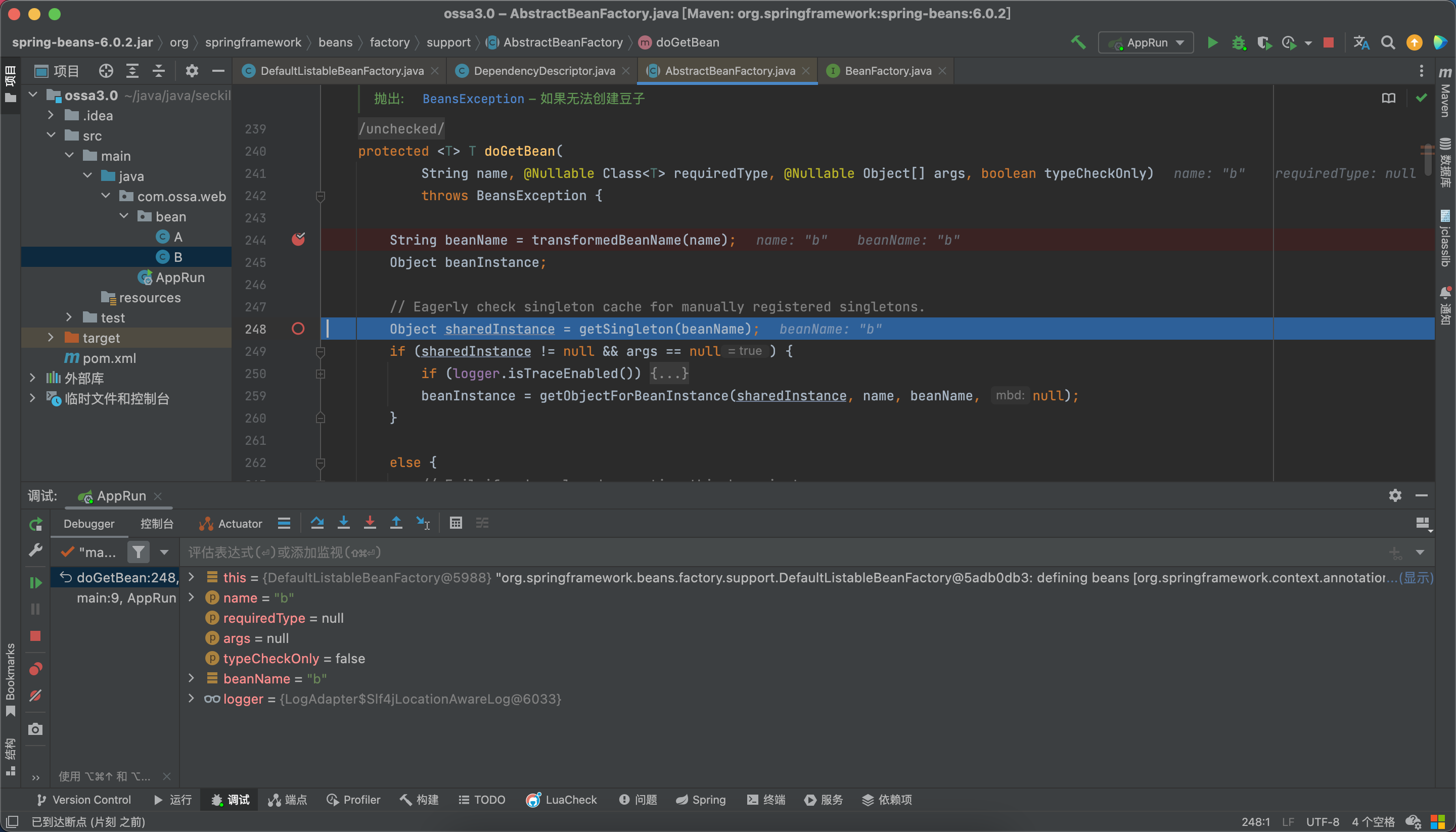
找不到就去创建吧
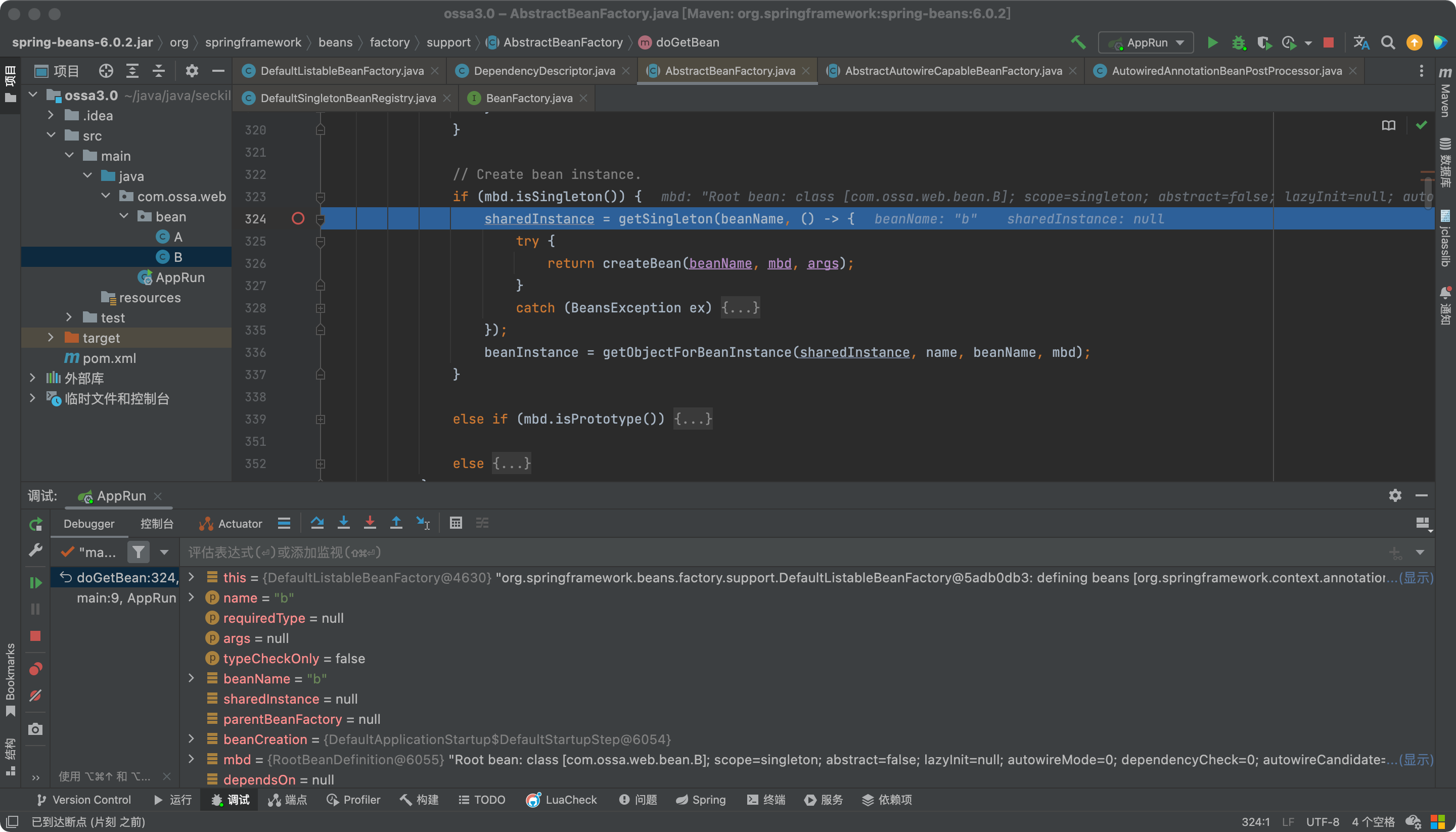
嗖,创建完了。
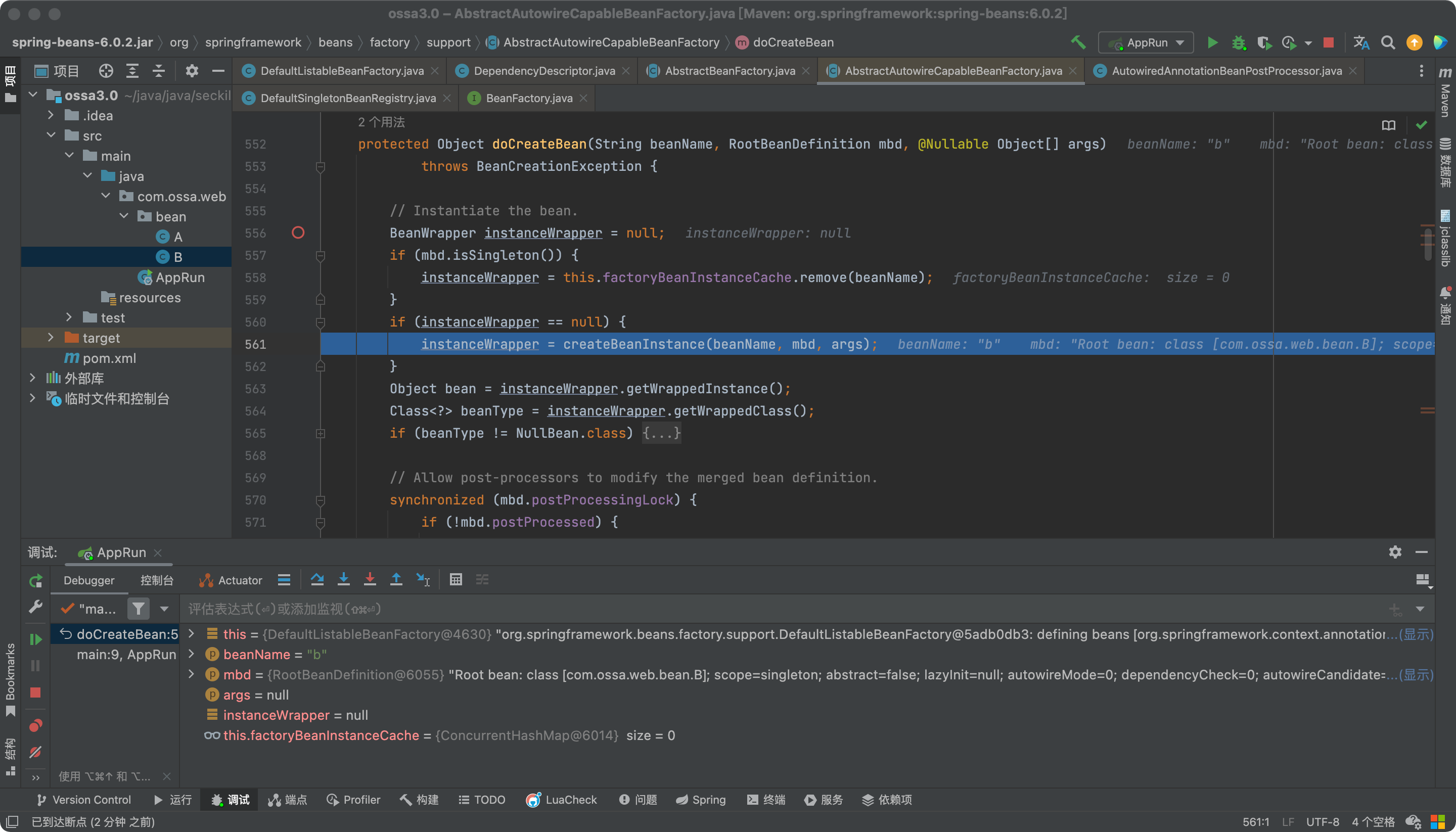
创建完又要填充属性了,B的属性是A,来吧,在走一圈。
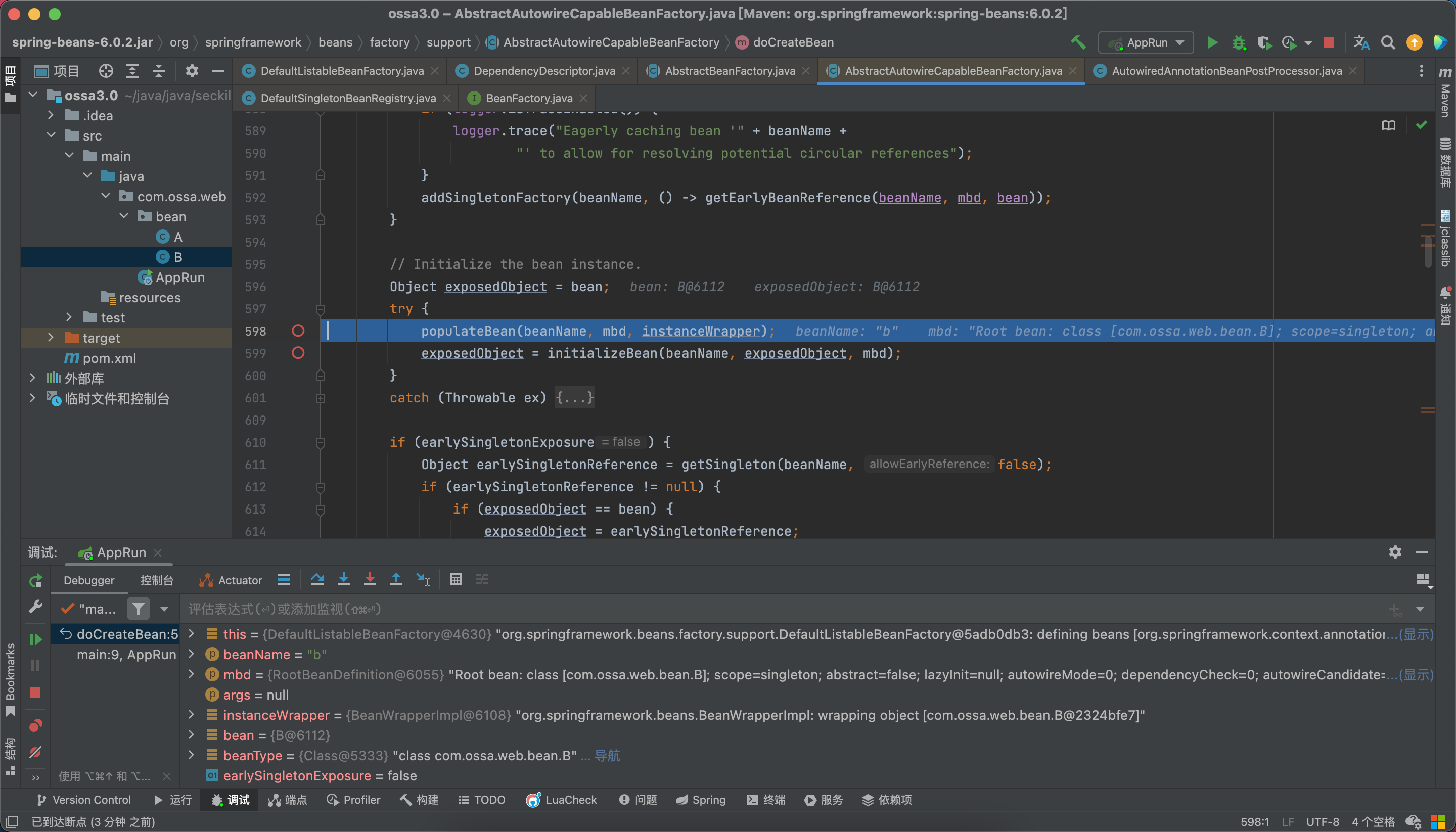
最后还是要去beanFactory中去找,因为在a填充属性的时候,a就已经实例化过了,也已经put进三级缓存暴漏出来了,我们来看看是如何处理的。
老样子,看看248行代码。
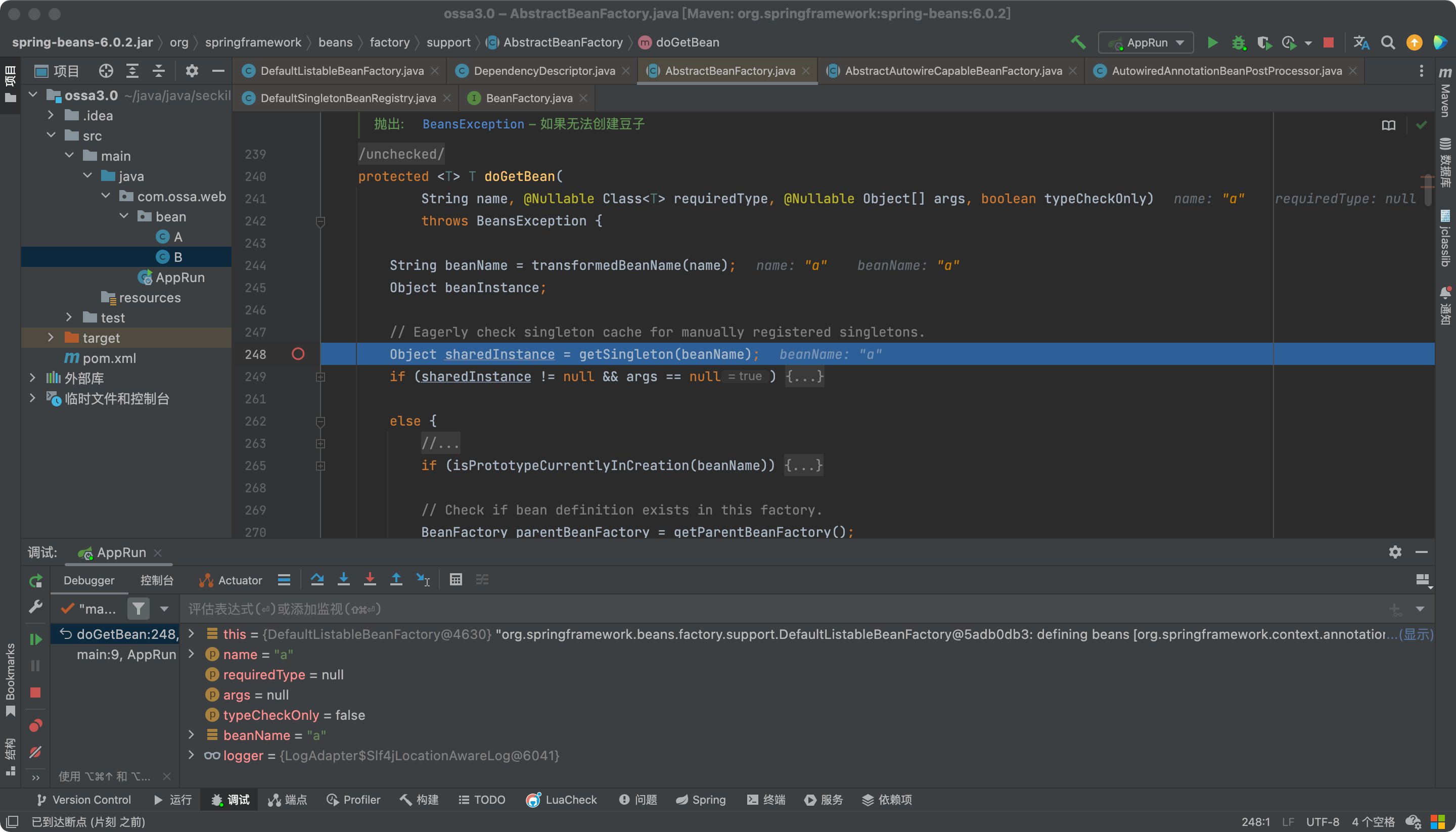
哎,卧槽,怎么直接跳到下面来了?bean工厂里没有?那不对啊,按理来说应该可以从三级缓存中找到啊。服了,看看吧。
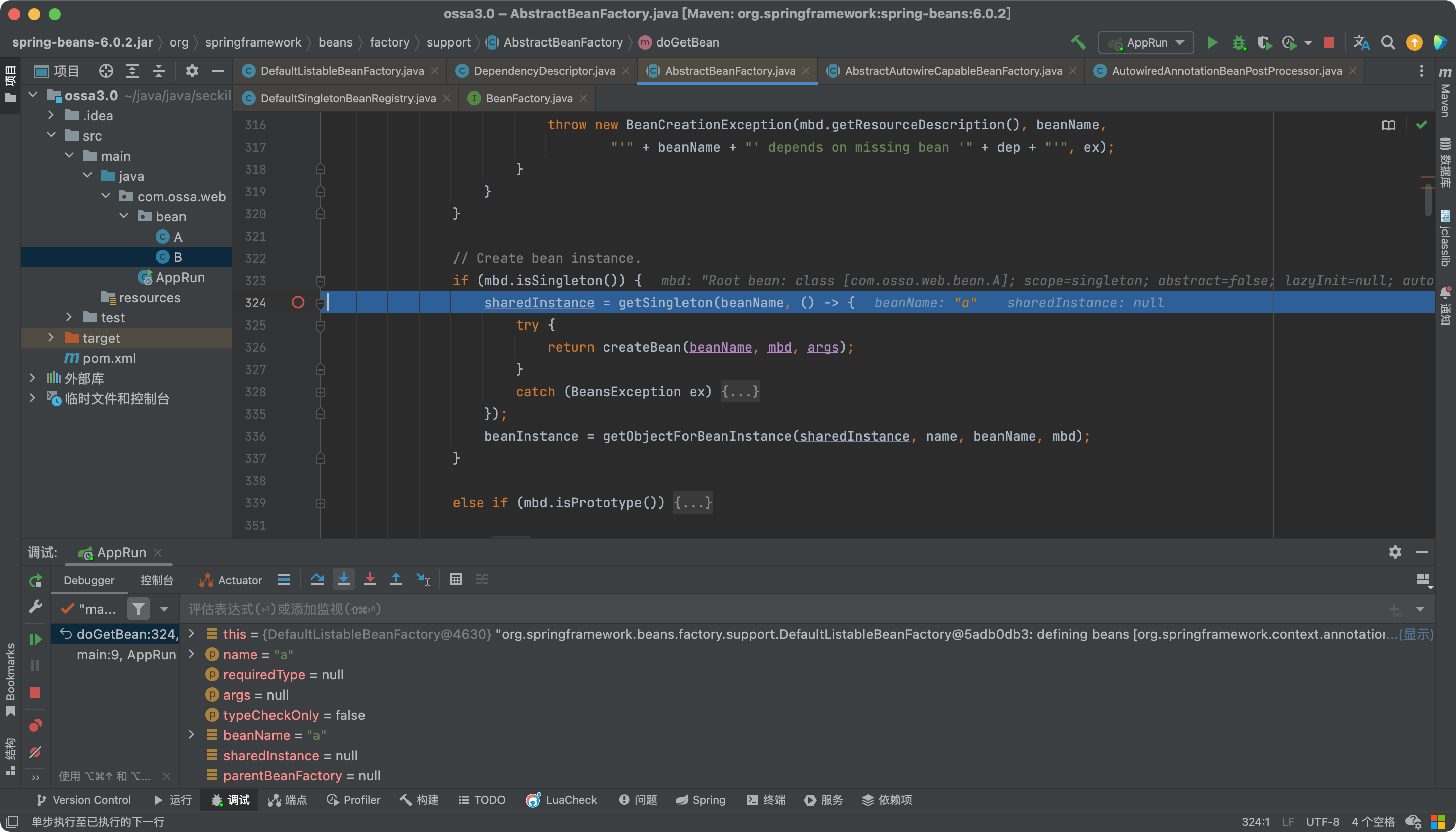
经过再一次的debug发现,这个allowCircularReferences属性默认是false,在SpringBoot2.6.x之前都是默认为true。
如果需要开启循环依赖需要在配置文件配置:
spring:
main:
allow-circular-references: true
坑,SpringBoot2.6.x默认禁用循环依赖。
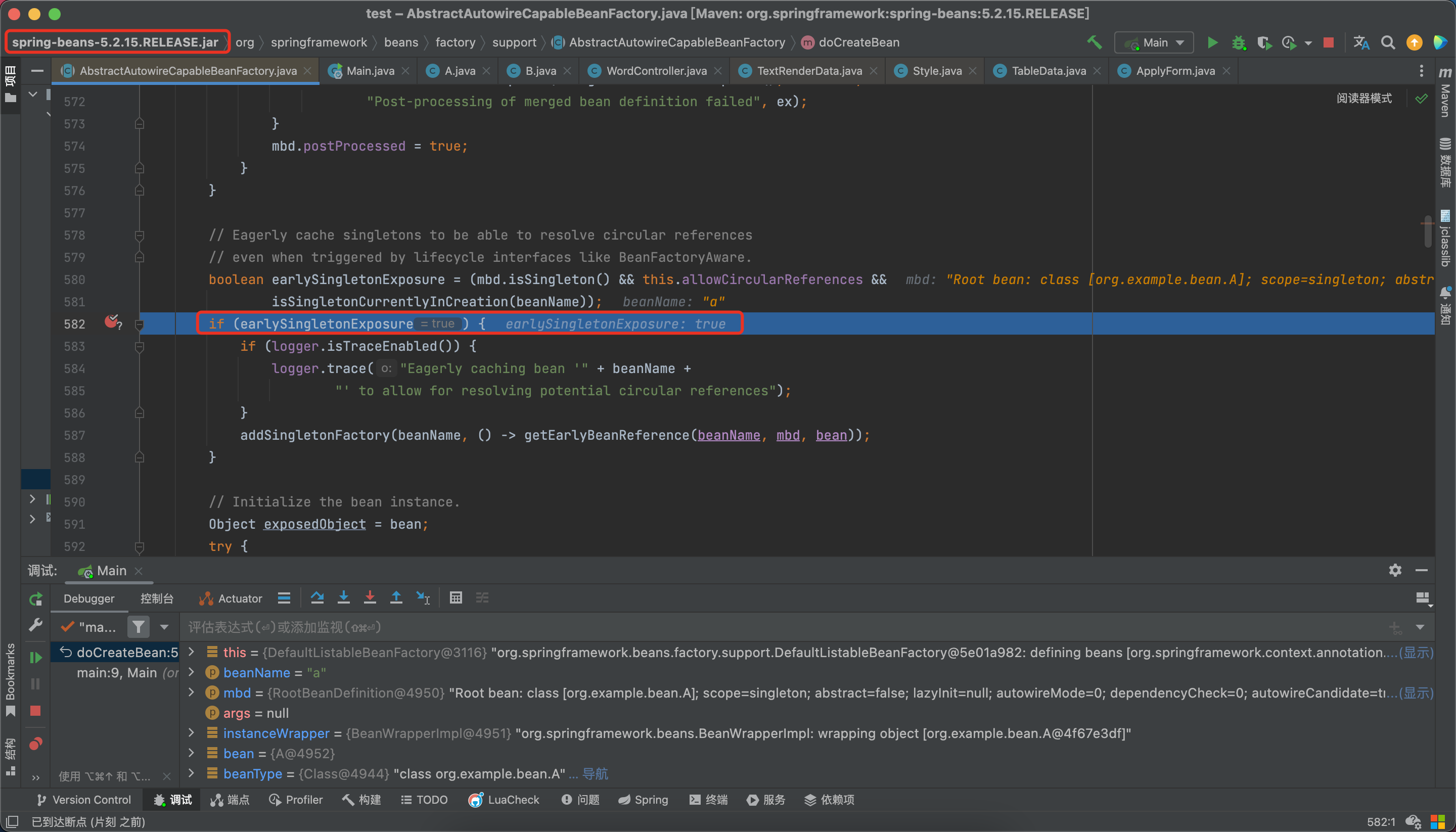
开启之后,再来一遍吧。
获取a —》先去缓存中取,结果都没有—》创建,a实例化—》添加进三级缓存beanFactory—》填充属性b—》获取b—》先去缓存中取,缓存中也没有—》创建,b实例化—》添加进三级缓存beanFactory—》填充属性a—》先去缓存中找,这下肯定有了,不信我们看看
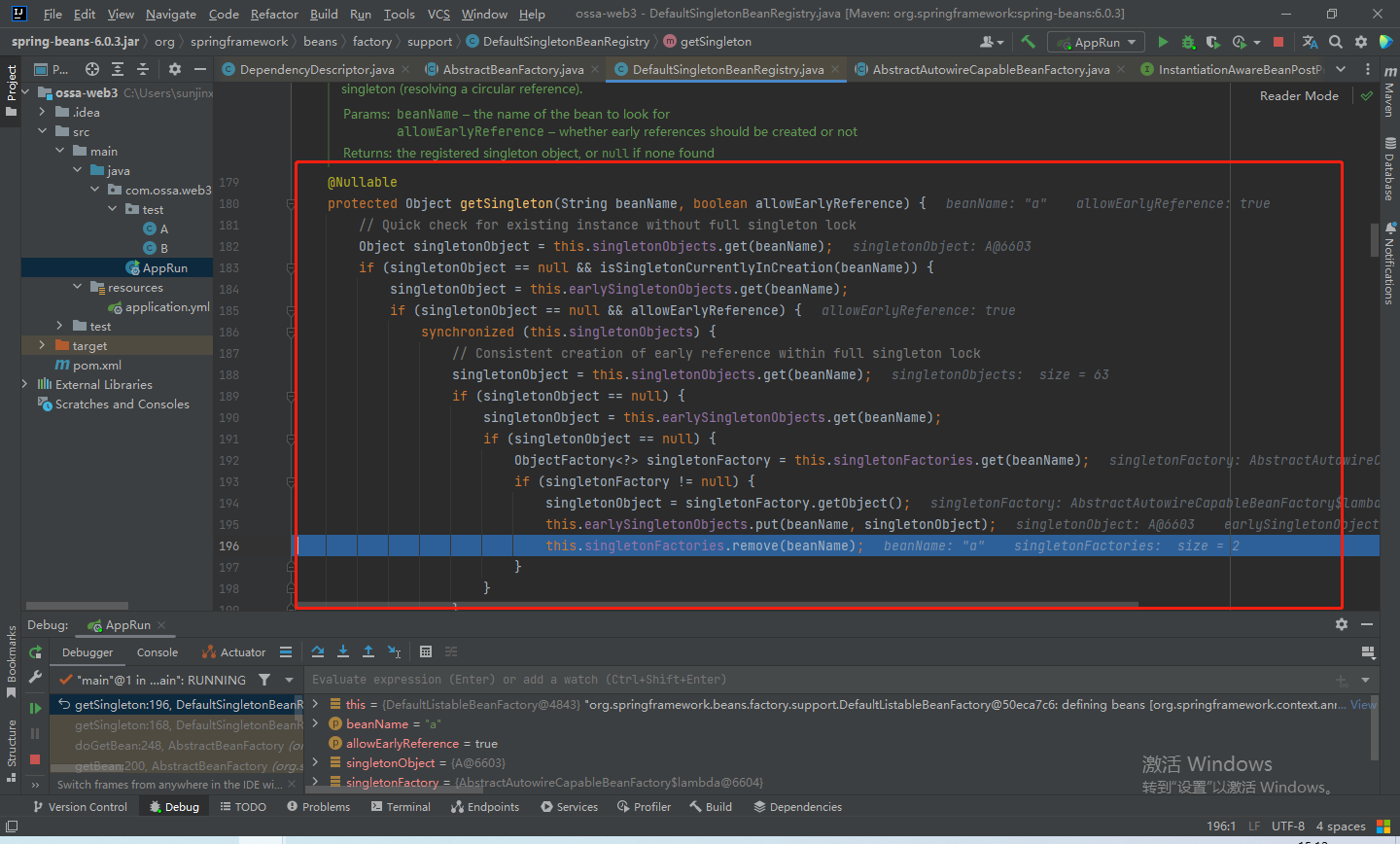
你看,有了吧,啥都有了。也能从三级缓存中取到,并且把这个bean放进二级缓存earlySingletonObjects中。
然后就会进入如下这个if判断中,getObjectForBeanInstance方法中会做一些判断如果是当前实例,则会直接返回该实例。
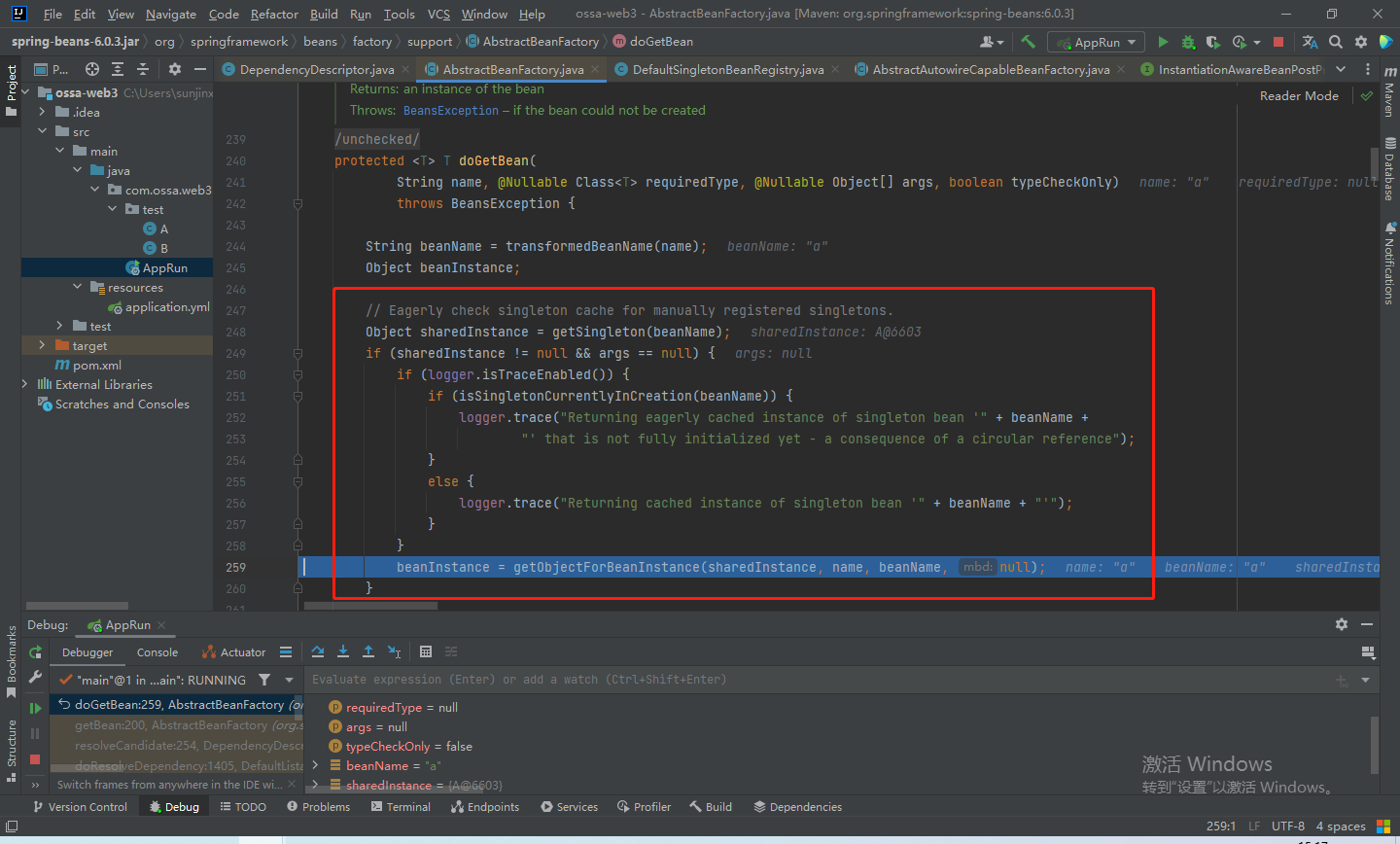
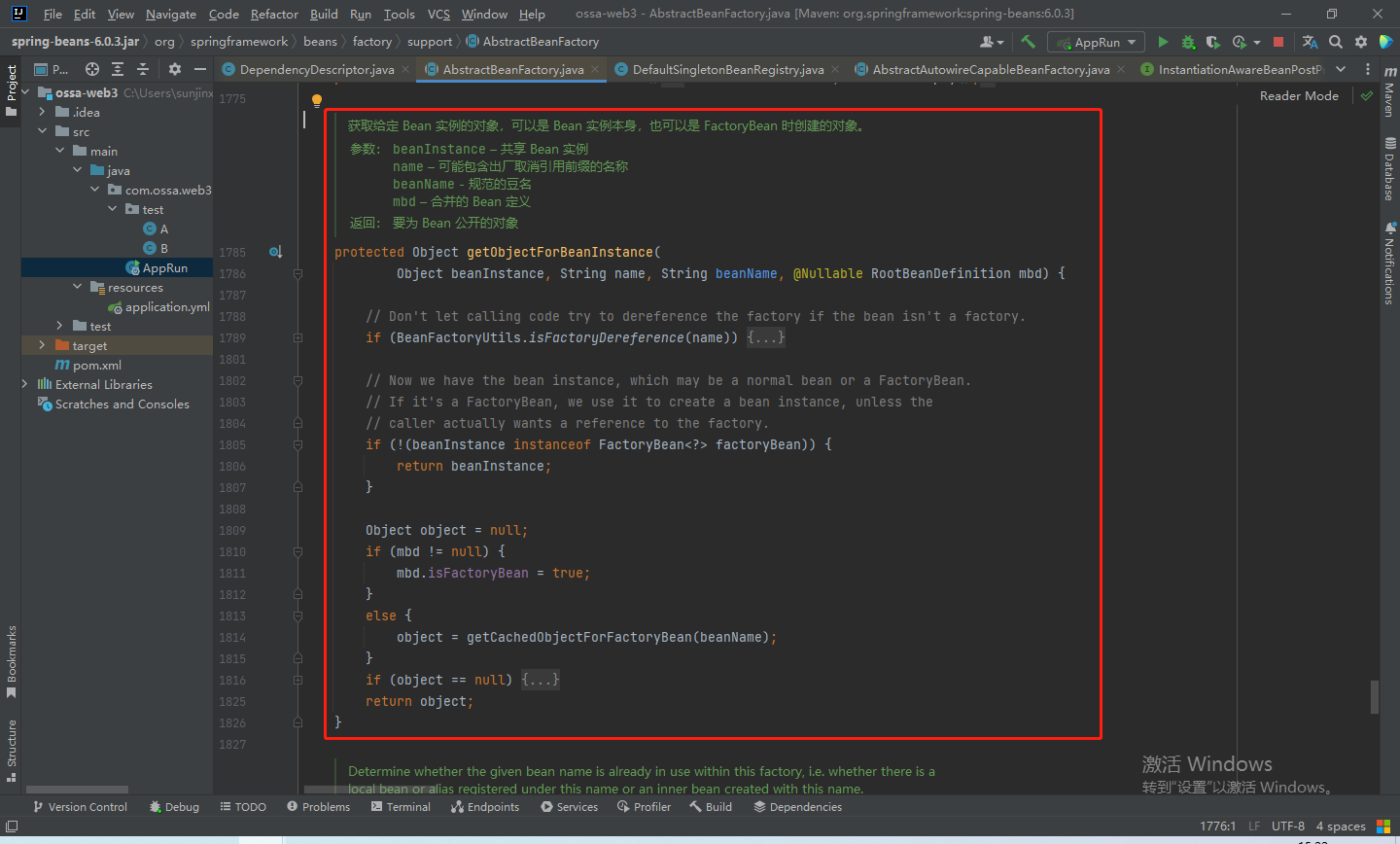
最后得到a,退出解析方法
然后将这个属性值放进缓存中
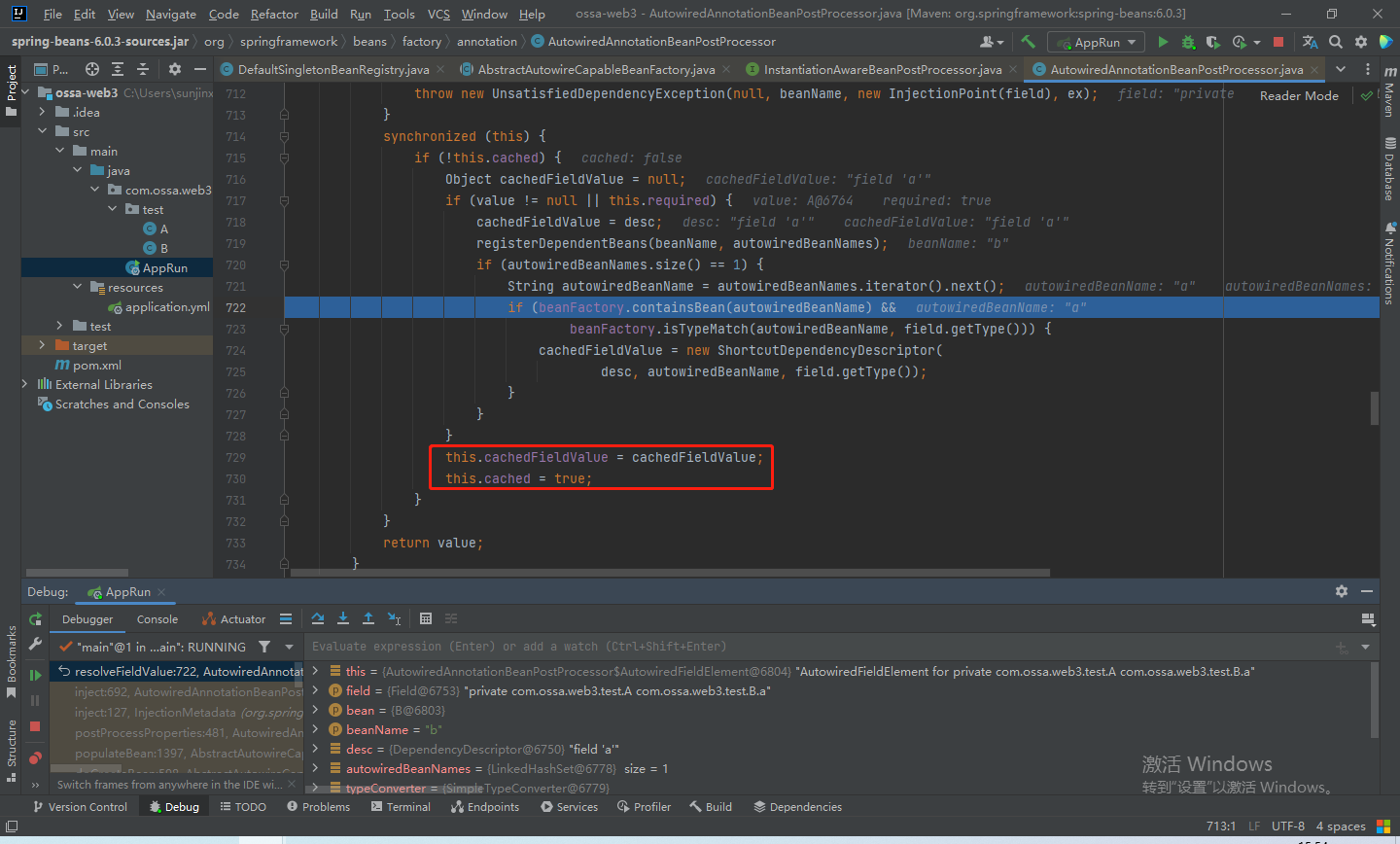
退出该方法
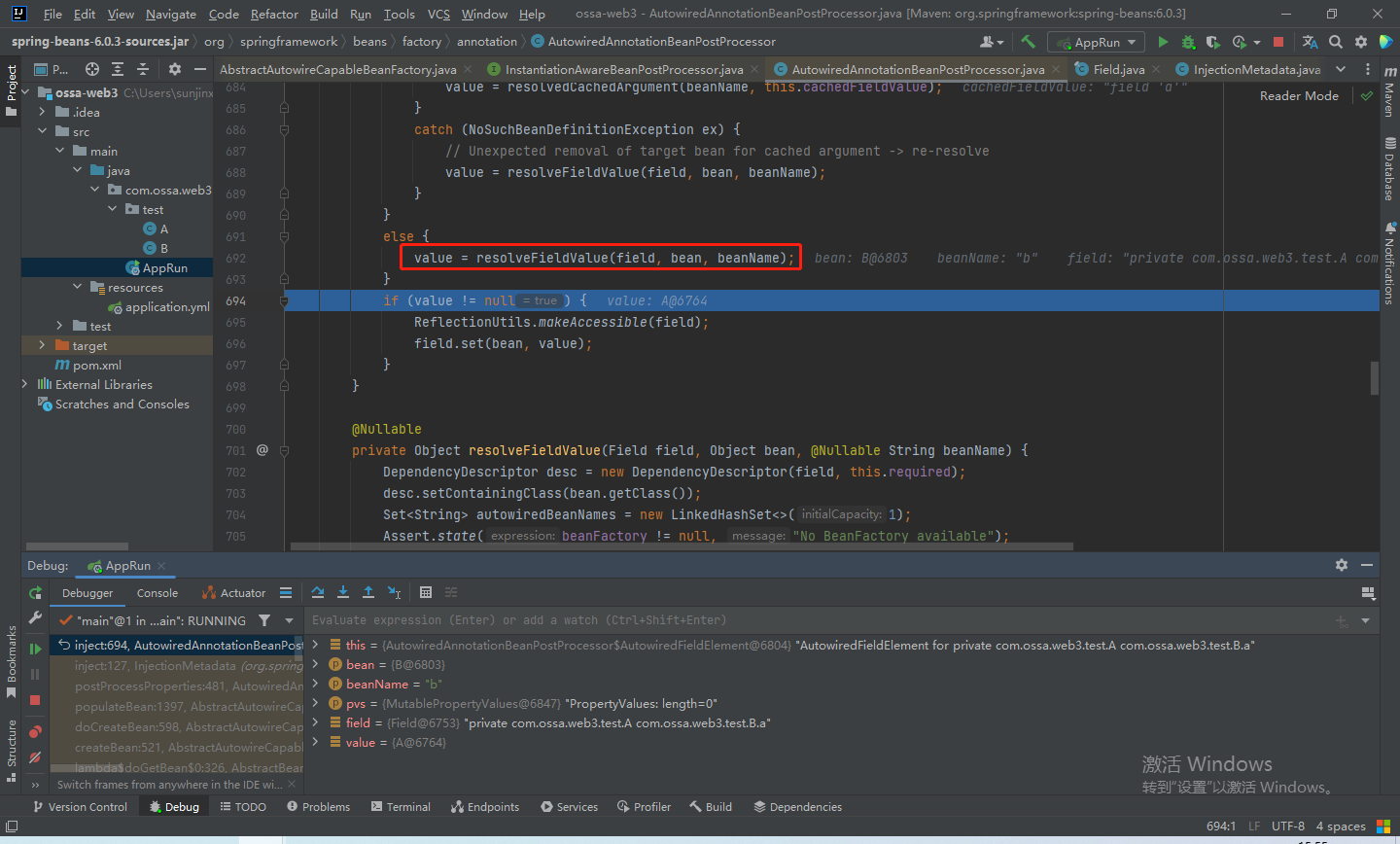
然后把得到的A赋值给B的属性
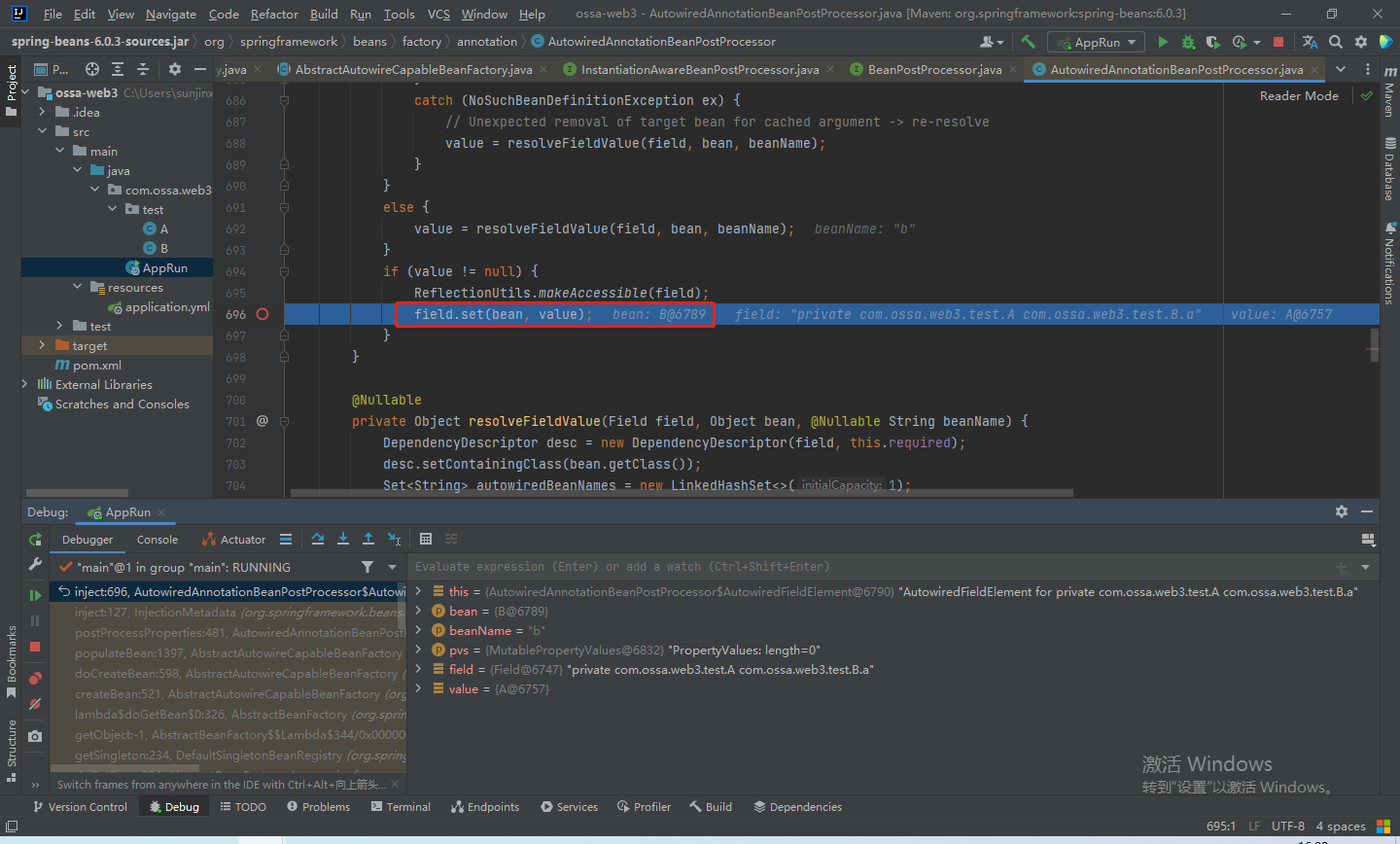
就此,B的属性A赋值结束。此时可以看到B是有值的,属性A也是有值的,可是A的属性B还没有赋值呢。
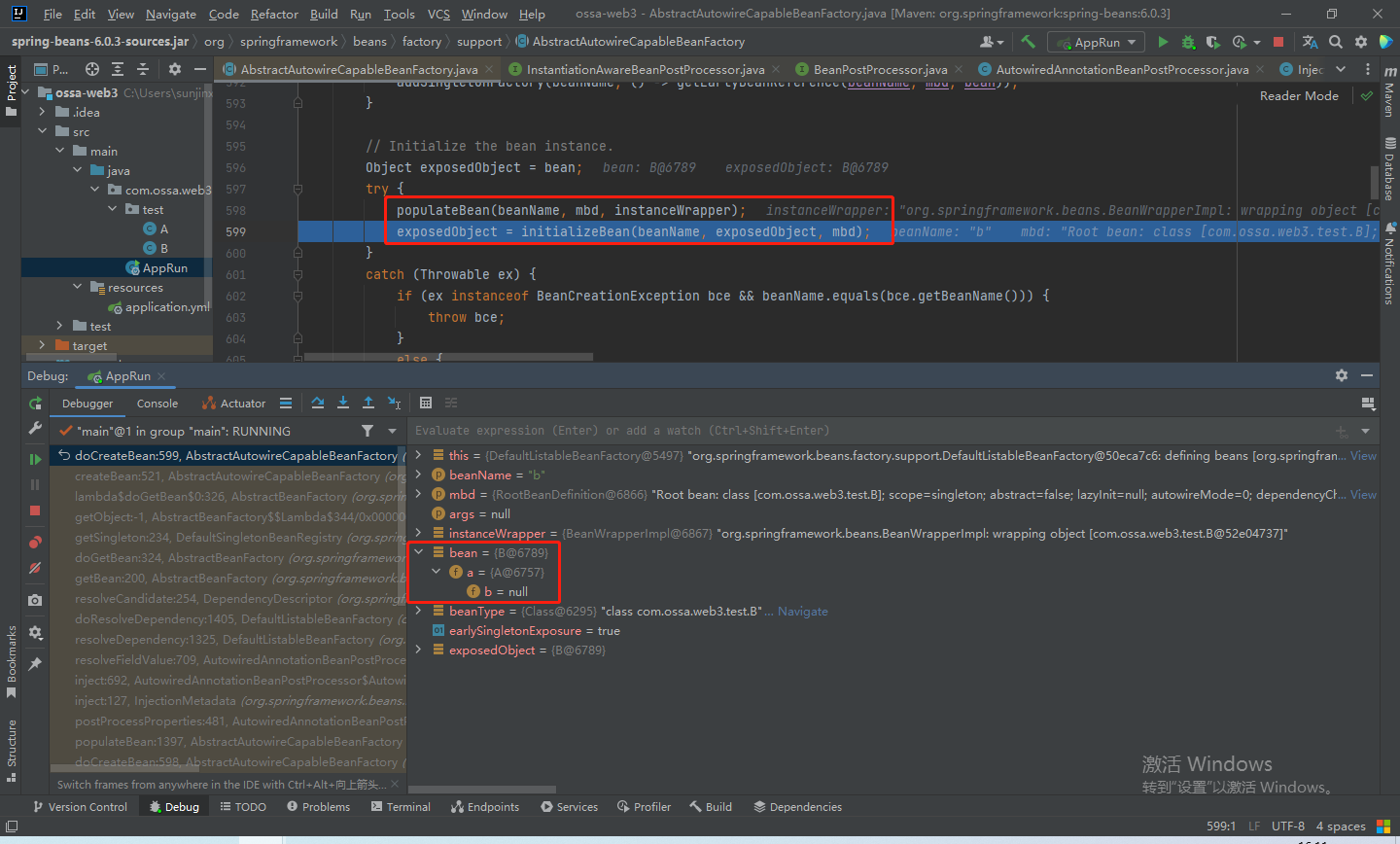
此时我们已经创建完b,也就是说已经调完了上述的那个lambda函数,紧接着会调用addSingleton方法,将bean放进一级缓存。
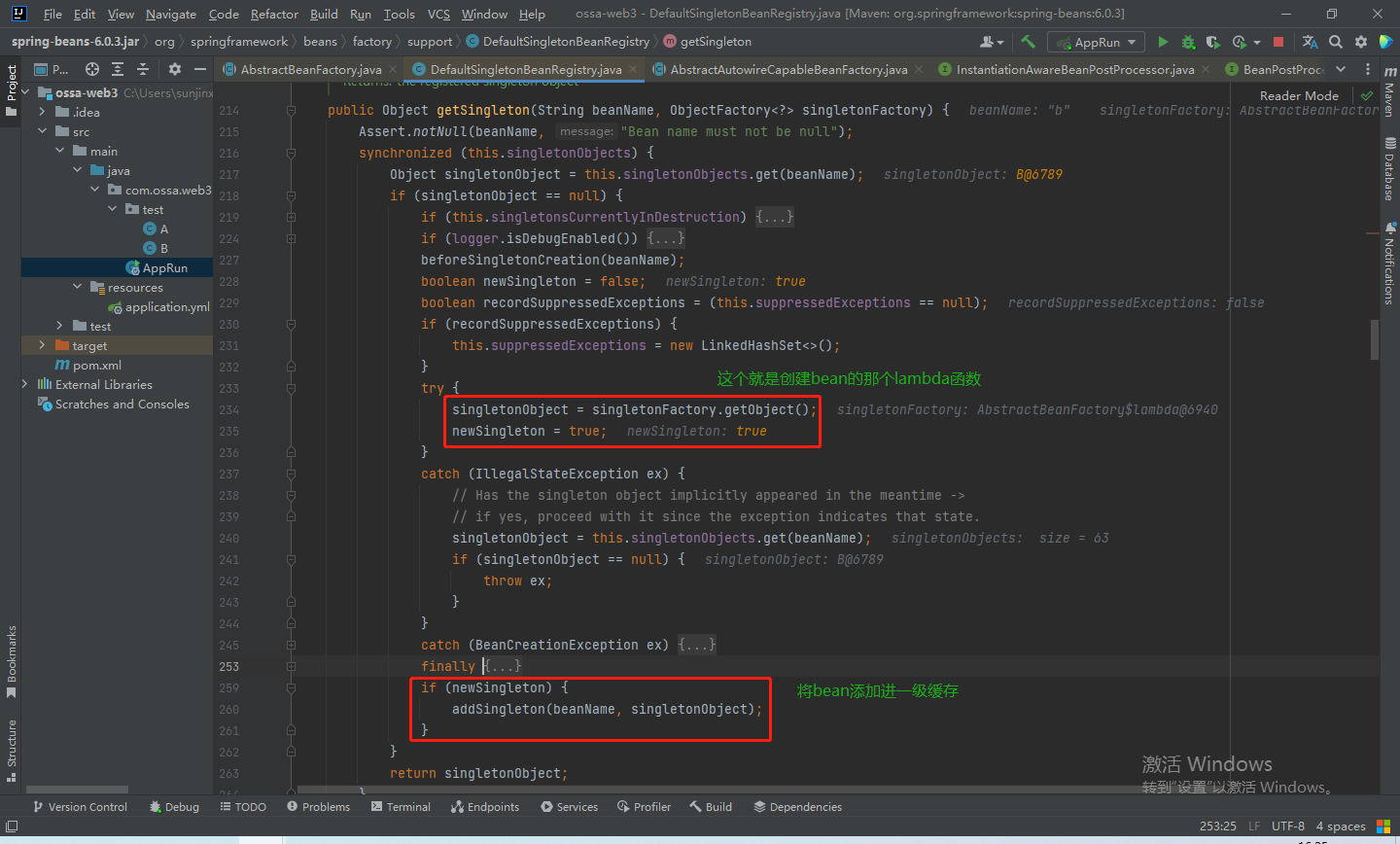
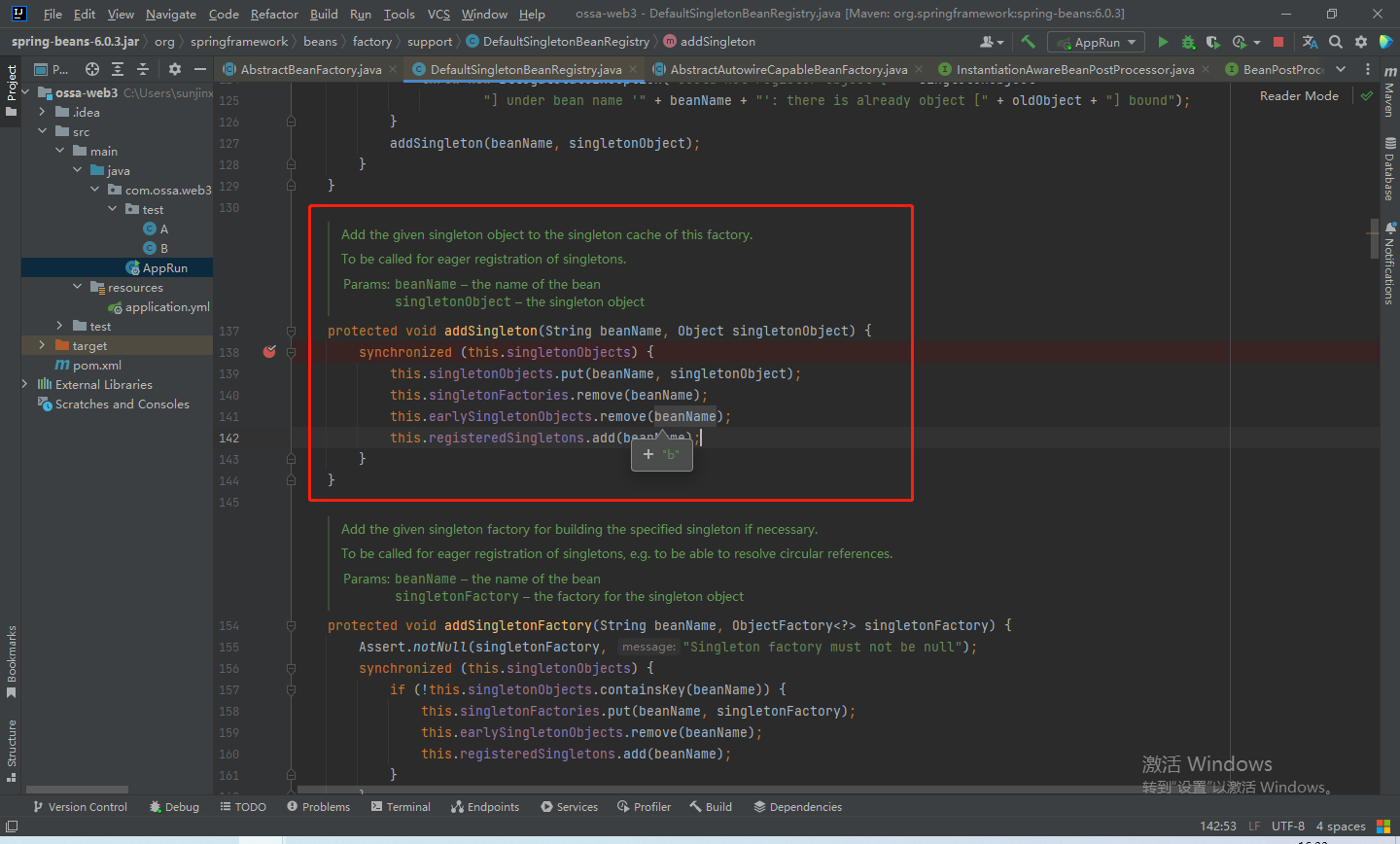
将b放进一级缓存同样也标志着b初始化结束,紧接着,a会将b设置为自己的属性。最后也会把a放进一级缓存,就此over~
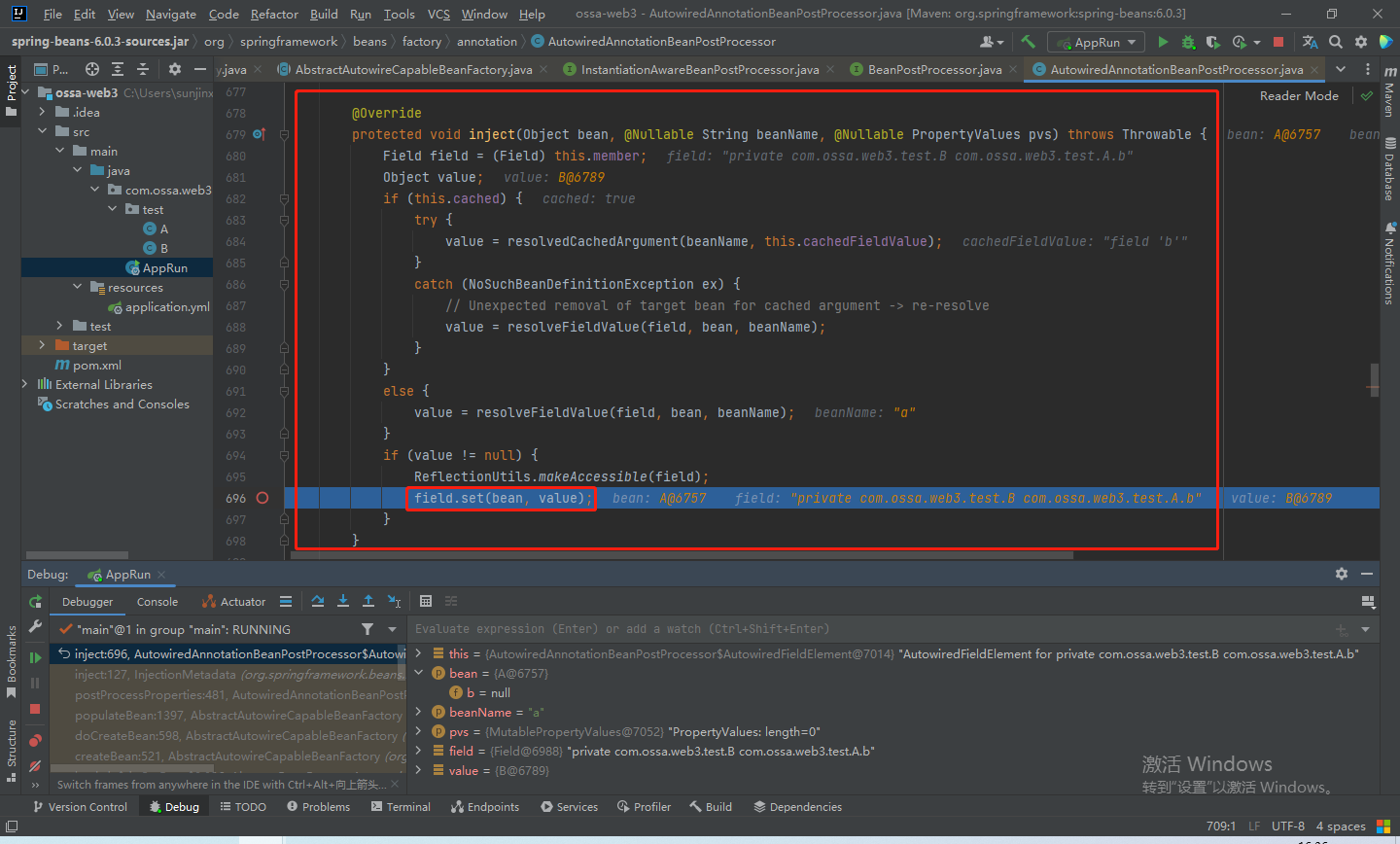
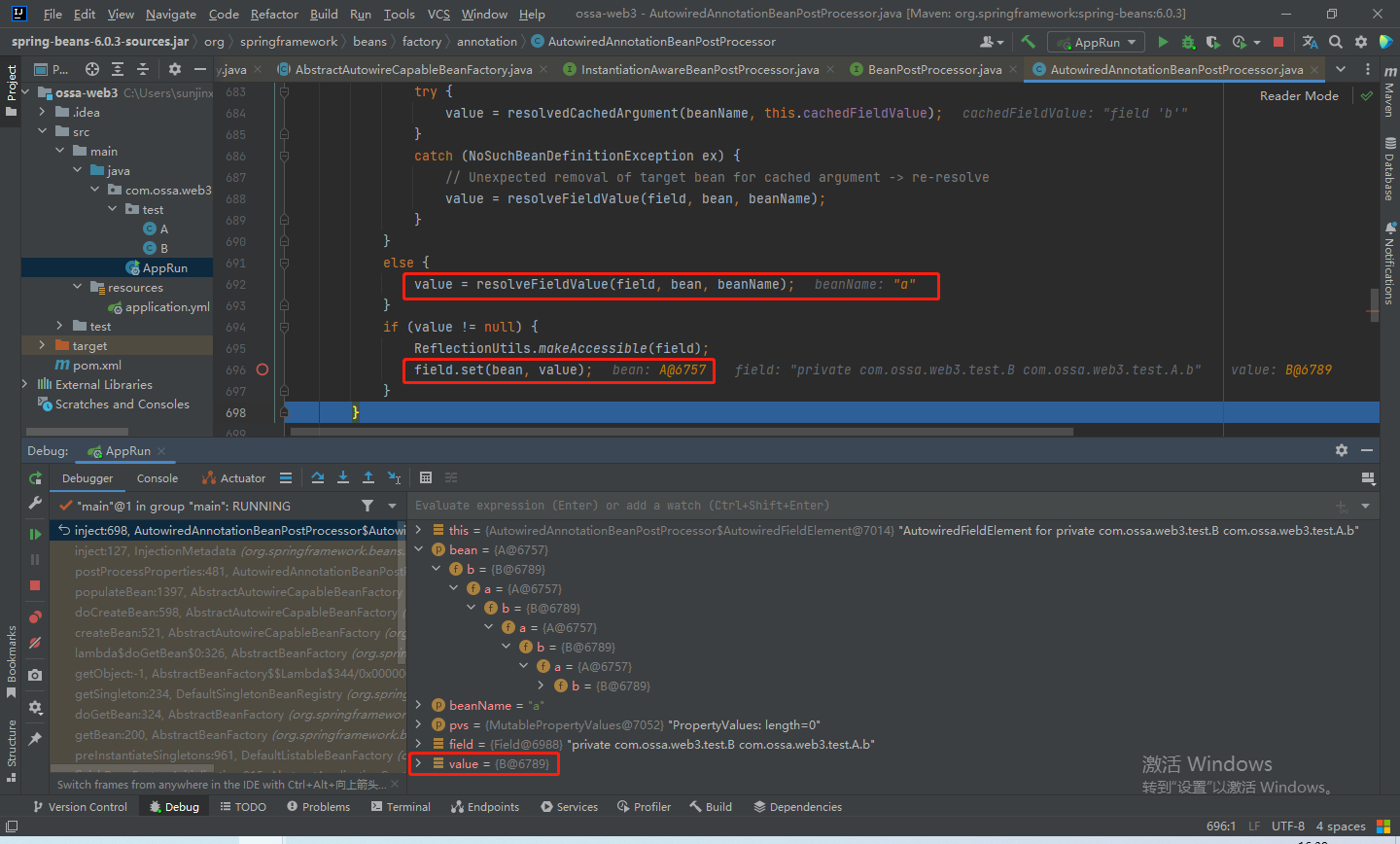
当然,这里可能还存在很多问题,我给的这个demo,并不能完全展示出二级缓存的作用,因为a只有一个属性b,那么填充属性之后,a就已经存在一级缓存中。
可以这样,A同时依赖于B和C,B和C都依赖于A。这样就可以看出二级缓存的作用了。
其实对于解决循环依赖来说,两个缓存就完全足够,一个存放未初始化的bean,一个存放已经初始化的bean,那么要三级缓存干什么?
具体原因我们可以放在下一篇aop的源码解析。