基于JWT的模拟登录爬取实战
JWT(JSON Web Token)主要由三部分组成:
- Header:包含了Token的类型(“typ”)和签名算法(“alg”)信息。通常情况下,这个部分会指定为
{"alg": "HS256", "typ": "JWT"},表示使用HMAC SHA-256算法进行签名。 - Payload:包含了要传输的信息,也称为声明(claims)。其中可以包含注册声明(registered claims)、公共声明(public claims)和私有声明(private claims),例如用户ID、姓名等信息。一些注册声明包括
iss(issuer)、sub(subject)、aud(audience)、exp(expiration time)、nbf(not before time)等。 - Signature:对Header和Payload进行签名后生成的结果,以确保JWT的完整性和真实性。签名通常使用Base64编码的Header和Payload,并结合一个密钥使用指定的算法进行计算得到。
JWT的三个部分都是使用Base64 URL编码的,并且它们之间通过句点(.)来分隔。最终生成的JWT字符串就是由这三部分组成的。.JWT的格式是明文的,因此不应将敏感数据直接存储在JWT中,特别是不要在Payload中存储敏感信息,因为Payload中的内容可以被Base64解码。敏感信息应该通过加密或其他安全手段进行处理。
- 案例介绍
案例网站是https://login3.scrape.center/,访问这个网站,同样会打开一个登录页面,如图所示。
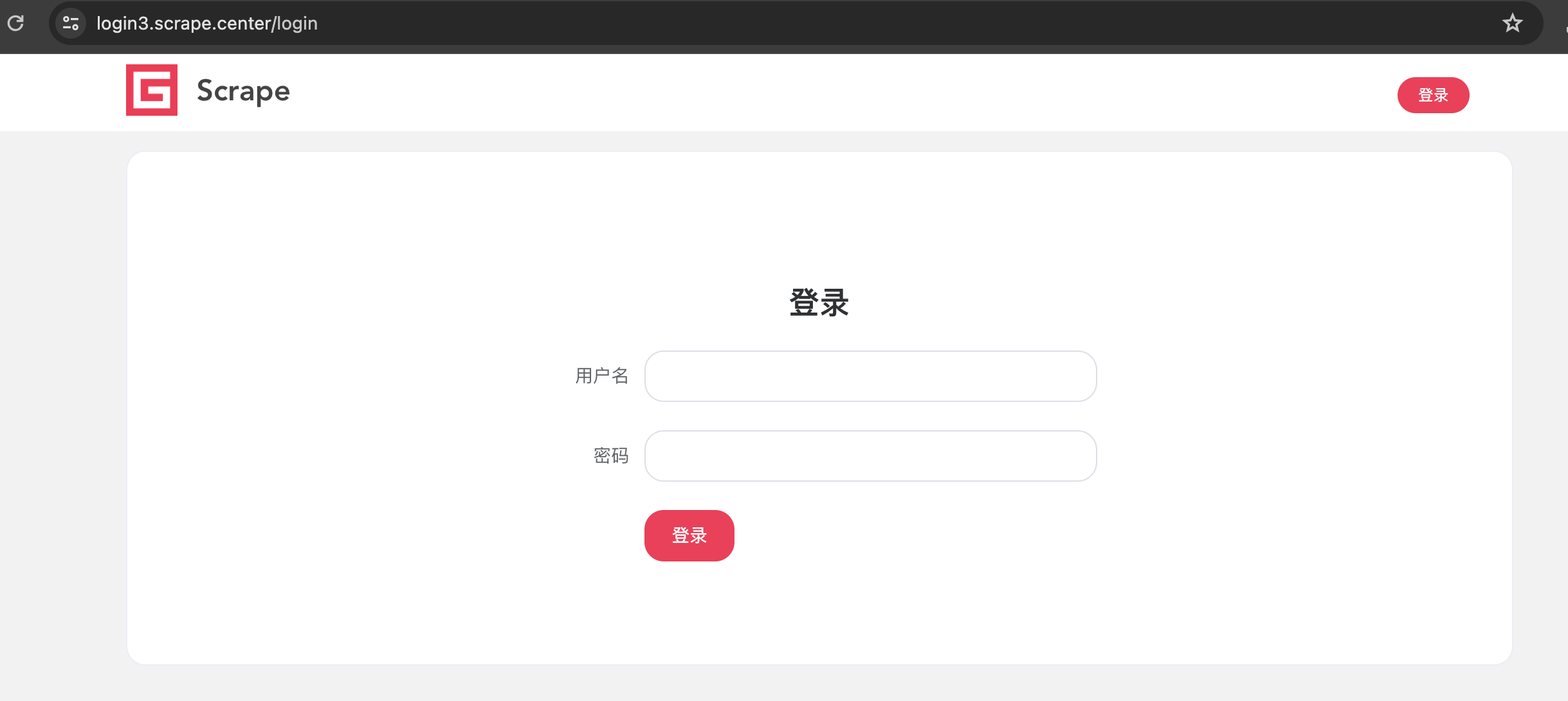
用户名和密码都是admin,输入后点击登录按钮会跳转到首页,证明登录成功。
- 模拟登录
基于JWT的网站通常采用的是前后端分离式,前后端的数据传输依赖于Ajax,登录验证依赖于JWT这个本身就是token的值,如果JWT经验证是有效的,服务器就会返回相应的数据。打开开发者工具,执行登录操作,看一下登录过程中产生的请求,如图所示:

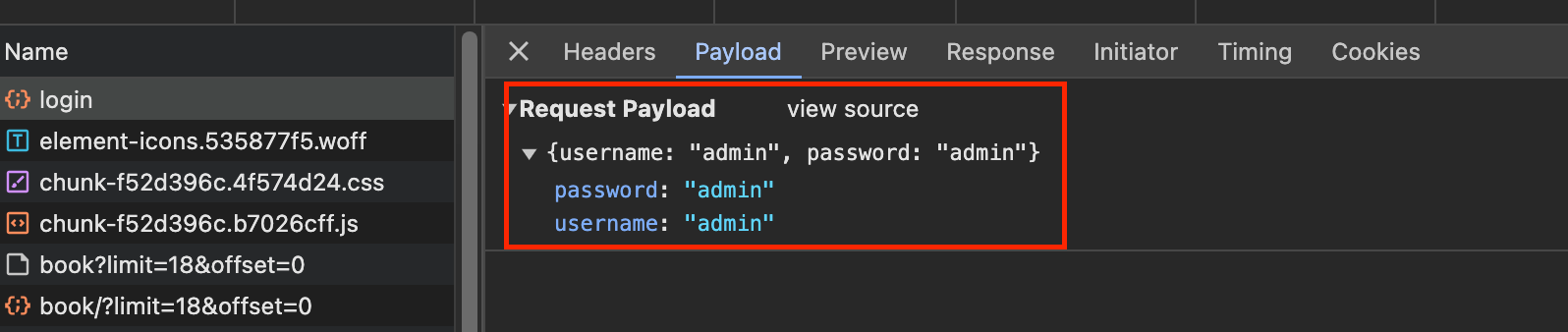
从上图中可以看出,登录时的请求URL为https://login3.scrape.center/api/login,是通过Ajax请求的。请求体是JSON格式的数据,而不是表单数据,返回状态码为200.然后看一下返回结果是怎样的,如下图所示:

从上图中看出,返回结果也是JSON格式的数据,包含一个token字段,其内容为:
"token": "eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJ1c2VyX2lkIjoxLCJ1c2VybmFtZSI6ImFkbWluIiwiZXhwIjoxNzEyMTkyMDY1LCJlbWFpbCI6ImFkbWluQGFkbWluLmNvbSIsIm9yaWdfaWF0IjoxNzEyMTQ4ODY1fQ.-SIR4TI_nqkyfKoV7OudZeMnIGz09D4CxS6H8ANOAJM"
由“."把整个字符串分为三段。有了这个JWT,怎么获取后续的数据呢?翻下一页,看看后续的请求内容,如下图所示:
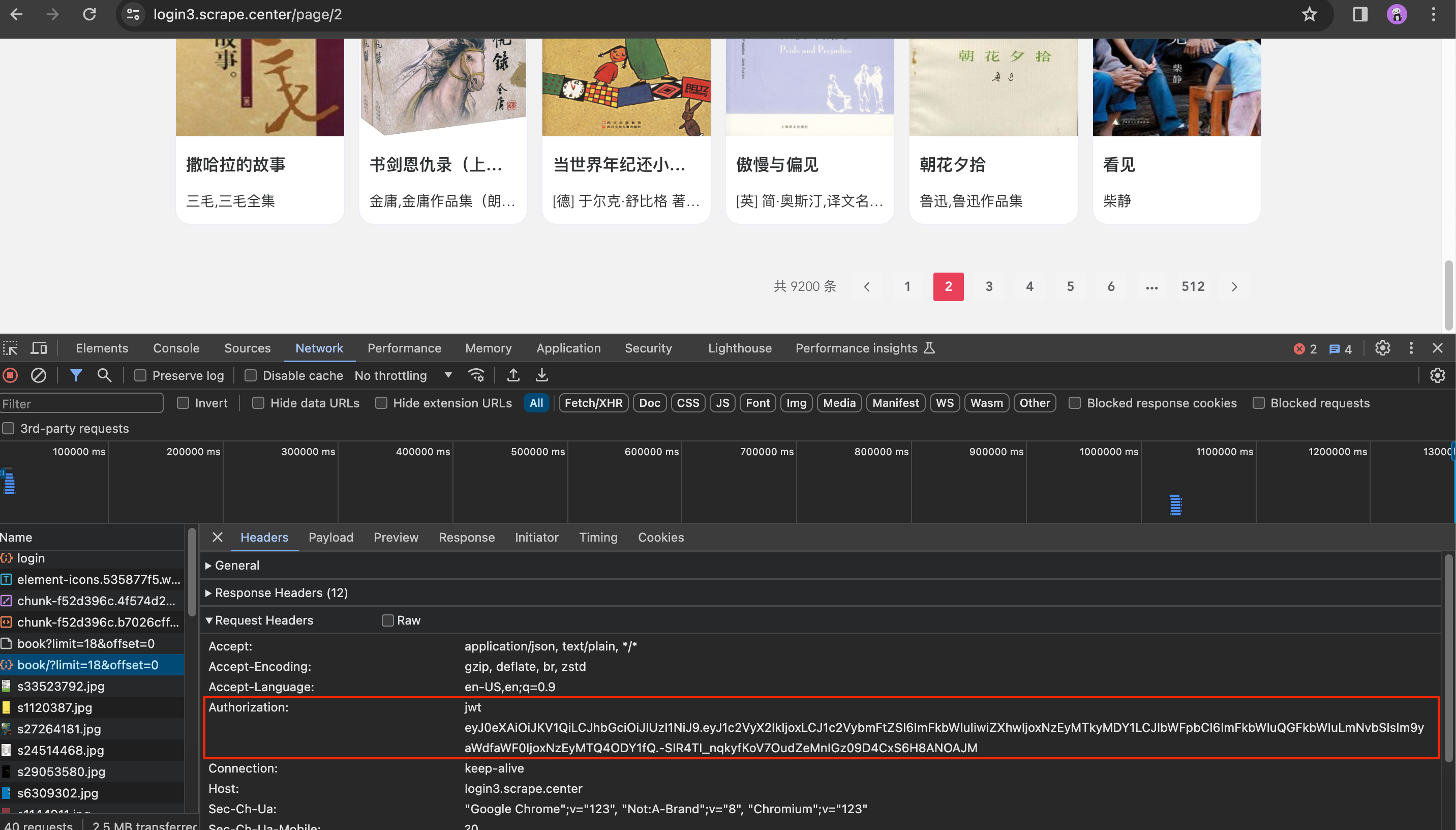
从上图中可看出,在后续发出的用于获取数据的Ajax请求中,请求头里多了一个Authorization字段,其内容为jwt加上刚才图中token字段的内容,返回结果也是JSON格式数据,如图所示:
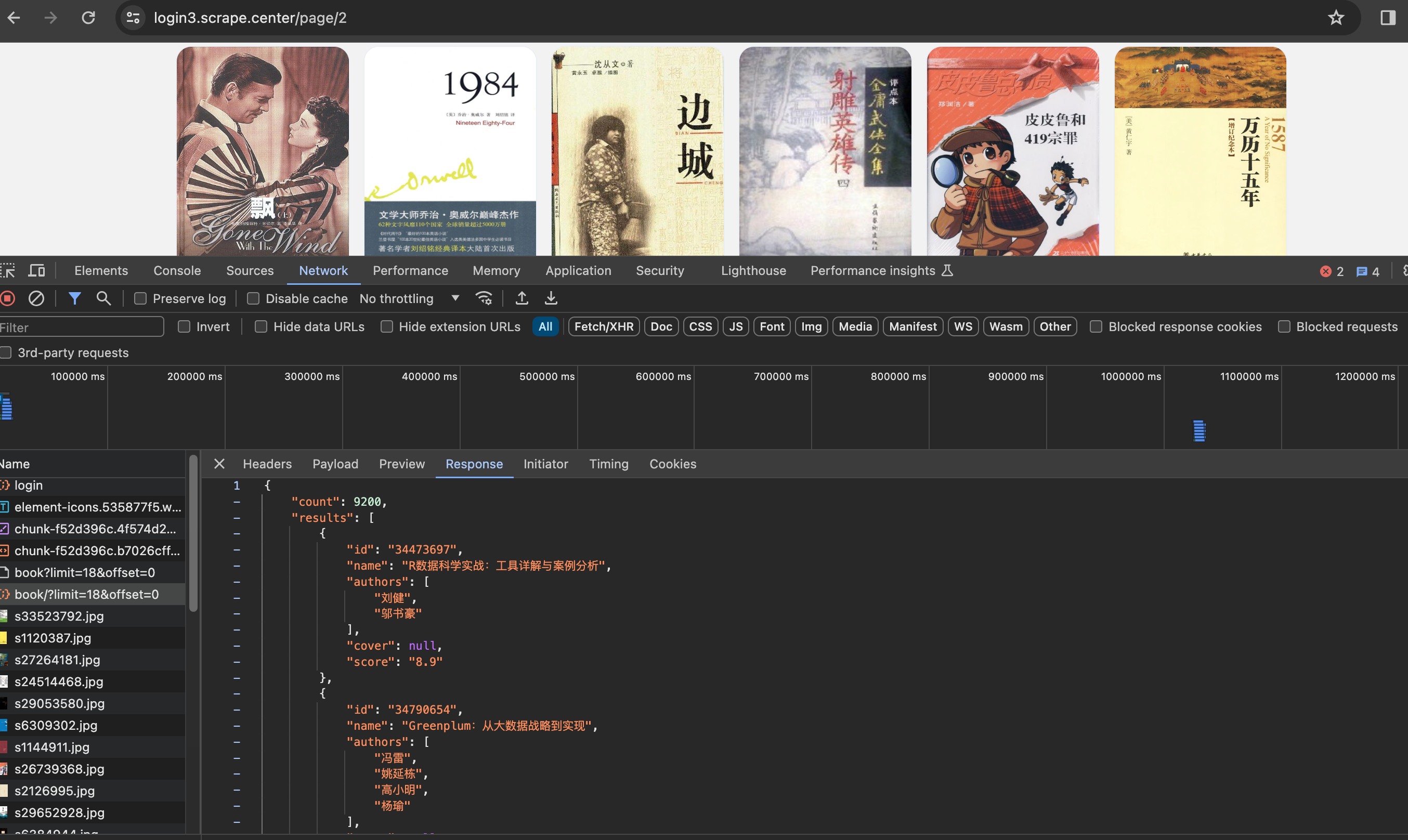
可以看出,返回结果正是网站首页显示的内容,这也是我们应该模拟爬取的内容。那么现在,模拟登录的整个思路就有了,其实就是如下两个步骤:
- 模拟登录请求,带上必要的登录信息,获取返回的JWT;
- 之后发送请求时,在请求头里面加上Authorization字段,值就是JWT对应的内容。
实现代码如下:
import requests
from urllib.parse import urljoin
BASE_URL = '<https://login3.scrape.center/>'
LOGIN_URL = urljoin(BASE_URL, '/api/login')
INDEX_URL = urljoin(BASE_URL, '/api/book')
USERNAME = 'admin'
PASSWORD = 'admin'
response_login = requests.post(LOGIN_URL, json={
'username': USERNAME,
'password': PASSWORD
})
data = response_login.json()
print('Response JSON', data)
jwt = data.get('token')
print('JWT', jwt)
headers = {
'Authorization': f'jwt {jwt}'
}
response_index = requests.get(INDEX_URL, params={'limit': 18, 'offset': 0}, headers=headers)
print('Response Status', response_index.status_code)
print('Response URL', response_index.url)
print('Response Data', response_index.json())
这里我们先定义了登录接口和获取数据的接口,分别是LOGIN_URL和INDEX_URL,接着调用requests的post方法进行了模拟登录。由于这里提交的数据是JSON格式,所以使用json参数来传递。接着获取并打印出返回结果中包含的JWT。然后构造请求头,设置Authorization字段并传入刚获取的JWT,这样就能成功获取数据了。
运行结果如下:
Response JSON {'token': 'eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJ1c2VyX2lkIjoxLCJ1c2VybmFtZSI6ImFkbWluIiwiZXhwIjoxNzEyMTk0MTMxLCJlbWFpbCI6ImFkbWluQGFkbWluLmNvbSIsIm9yaWdfaWF0IjoxNzEyMTUwOTMxfQ.jJNKrqLFxjmedcf333nO9E1XFNXpL-Ab8dF6zP_JUOQ'}
JWT eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJ1c2VyX2lkIjoxLCJ1c2VybmFtZSI6ImFkbWluIiwiZXhwIjoxNzEyMTk0MTMxLCJlbWFpbCI6ImFkbWluQGFkbWluLmNvbSIsIm9yaWdfaWF0IjoxNzEyMTUwOTMxfQ.jJNKrqLFxjmedcf333nO9E1XFNXpL-Ab8dF6zP_JUOQ
Response Status 200
Response URL <https://login3.scrape.center/api/book/?limit=18&offset=0>
Response Data {'count': 9200, 'results': [{'id': '34473697', 'name': 'R数据科学实战:工具详解与案例分析','authors': ['刘健', '邬书豪'], 'cover': None, 'score': '8.9'}, {'id': '34790654', 'name': 'Greenplum:从大数据战略到实现', 'authors': ['冯雷', '姚延栋','高小明', '杨瑜'], 'cover': None, 'score': '8.9'},{'id': '34893933', 'name': '江湖外史(2019精装版)','authors': ['王怜花'], 'cover': '<https://cdn.scrape.center/book/s33523792.jpg>', 'score': '8.3'}, {'id': '17707842', 'name': None, 'authors': None, 'cover': None, 'score': None}, {'id': '27080632', 'name': 'Streaming Systems', 'authors': ['Tyler Akidau', 'Slava Chernyak', 'Reuven Lax'], 'cover': None, 'score': ' 8.9 '}, {'id': '1046276', 'name': '温暖和百感交集的旅程', 'authors': ['\\n 余华', '余华作品系列'], 'cover': '<https://cdn.scrape.center/book/s1120387.jpg>', 'score': '8.1'}, {'id': '25862578', 'name': '解忧杂货店', 'authors': ['\\n [日]\\n 东野圭吾', '新经典文化', '新经典文库·东野圭吾作品'], 'cover': '<https://cdn.scrape.center/book/s27264181.jpg>', 'score': '8.5'}, {'id': '10554308', 'name': '白夜行', 'authors': ['[日] 东野圭吾'], 'cover': '<https://cdn.scrape.center/book/s24514468.jpg>', 'score': '9.2'}, {'id': '4913064', 'name': '活着', 'authors': ['余华'], 'cover': '<https://cdn.scrape.center/book/s29053580.jpg>', 'score': '9.4'}, {'id': '6015822', 'name': '在细雨中呼喊', 'authors': ['\\n 余华', '余华作品(2008版)'], 'cover': '<https://cdn.scrape.center/book/s6309302.jpg>', 'score': '8.5'}, {'id': '10594787', 'name': '霍乱时期的爱情', 'authors': ['[哥伦比亚] 加西亚·马尔克斯'], 'cover': '<https://cdn.scrape.center/book/s11284102.jpg>', 'score': '9.0'}, {'id': '27064488', 'name': '活着', 'authors': ['余华'], 'cover': '<https://cdn.scrape.center/book/s29652928.jpg>', 'score': '9.4'}, {'id': '1974038', 'name': '南腔北调集', 'authors': ['鲁迅'], 'cover': '<https://cdn.scrape.center/book/s2126995.jpg>', 'score': '8.6'}, {'id': '1491325', 'name': '皮皮鲁和梦中人', 'authors': ['\\n 郑渊洁', '皮皮鲁总动员'], 'cover': '<https://cdn.scrape.center/book/s26739368.jpg>', 'score': '8.7'}, {'id': '6082808', 'name': '百年孤独', 'authors': ['\\n [哥伦比亚]\\n 加西亚·马尔克斯', '新经典文化', '\\n 范晔', '新经典文库:加西亚·马尔克斯作品'], 'cover': '<https://cdn.scrape.center/book/s6384944.jpg>', 'score': '9.2'}, {'id': '34672176', 'name': '呼吸', 'authors': ['[美] 特德·姜'], 'cover': '<https://cdn.scrape.center/book/s33519539.jpg>', 'score': '8.6'}, {'id': '34434309', 'name': '82年生的金智英', 'authors': ['[韩]赵南柱'], 'cover': '<https://cdn.scrape.center/book/s33463759.jpg>', 'score': '7.9'}, {'id': '1200840', 'name': '平凡的世界(全三部)', 'authors': ['\\n 路遥', '茅盾文学奖获奖作品全集'], 'cover': '<https://cdn.scrape.center/book/s1144911.jpg>', 'score': '9.0'}]}
模拟登录成功!