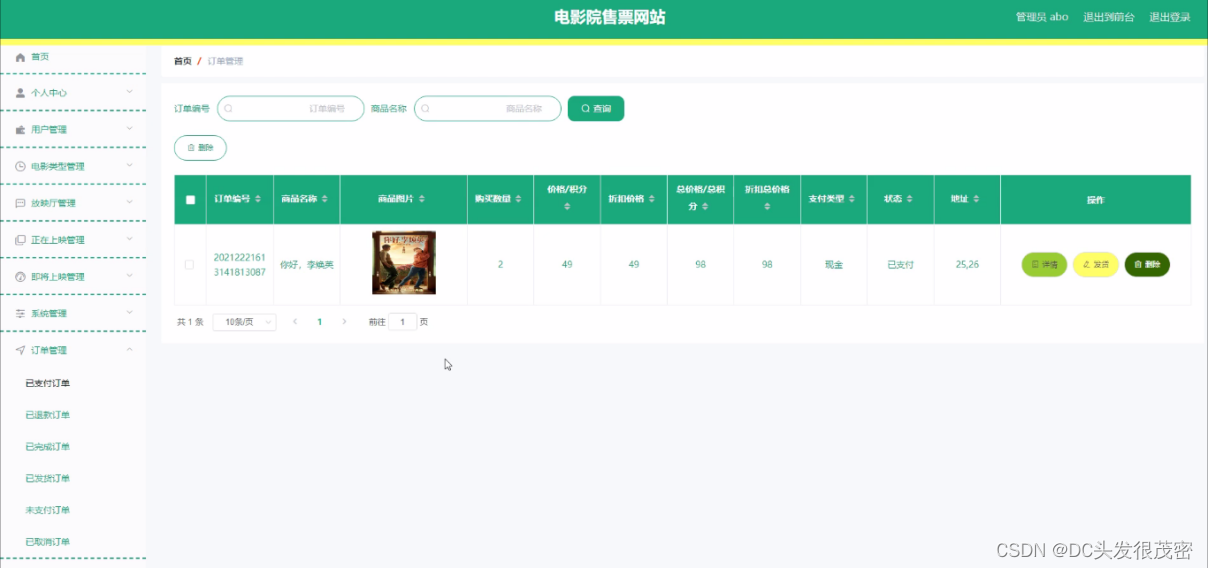
在学习完语言模型中的编码器与解码器知识后,让我们继续深入学习大语言模型中一个非常关键的技术:词向量表示,以及如何通过Transformer模型实现对next token的预测。
1、词向量
要了解语言模型的工作原理,首先需要了解它们如何表示单词。人类用字母序列来表示英文单词,比如C-A-T表示猫。语言模型使用的是一个叫做词向量的长串数字列表。例如,这是一种将猫表示为向量的方式:
[0.0074, 0.0030, -0.0105, 0.0742, 0.0765, -0.0011, 0.0265, 0.0106, 0.0191, 0.0038, -0.0468, -0.0212, 0.0091, 0.0030, -0.0563, -0.0396, -0.0998, -0.0796, …, 0.0002]
(注:完整的向量长度实际上有300个数字)
为什么要使用如此复杂的表示法?这里有个类比,华盛顿特区位于北纬38.9度,西经77度,我们可以用向量表示法来表示:
• 华盛顿特区的坐标是[38.9,77]
• 纽约的坐标是[40.7,74]
• 伦敦的坐标是[51.5,0.1]
• 巴黎的坐标是[48.9,-2.4]
这对于推理空间关系很有用。你可以看出,纽约离华盛顿特区很近,因为坐标中38.9接近40.7,77接近74。同样,巴黎离伦敦也很近。但巴黎离华盛顿特区很远。
语言模型采用类似的方法:每个词向量代表了“词空间(word space)”中的一个点,具有相似含义的词的位置会更接近彼此。例如,在向量空间中与猫最接近的词包括狗、小猫和宠物。用实数向量表示单词(相对于“C-A-T”这样的字母串)的一个主要优点是,数字能够进行字母无法进行的运算。
单词太复杂,无法仅用二维表示,因此语言模型使用具有数百甚至数千维度的向量空间。人类无法想象具有如此高维度的空间,但计算机完全可以对其进行推理并产生有用的结果。
几十年来,研究人员一直在研究词向量,但这个概念真正引起关注是在2013年,那时Google公布了word2vec项目。Google分析了从Google新闻中收集的数百万篇文档,以找出哪些单词倾向于出现在相似的句子中。随着时间的推移,一个经训练过的神经网络学会了将相似类别的单词(如狗和猫)放置在向量空间中的相邻位置。
Google的词向量还具有另一个有趣的特点:你可以使用向量运算“推理”单词。例如,Google研究人员取出最大的(biggest)向量,减去大的(big)向量,再加上小的(small)向量。与结果向量最接近的词就是最小的(smallest)向量。

你可以使用向量运算来做类比!在这个例子中,大(big)与最大的(biggest)的关系,类似于小(small)与最小的(smallest)的关系。Google的词向量捕捉到了许多其他的关系:
• 瑞士人与瑞士类似于柬埔寨人与柬埔寨。(国籍)
• 巴黎与法国类似于柏林与德国。(首都)
• 不道德的与道德的类似于可能的与不可能的。(反义词)
• Mouse(老鼠)与mice(老鼠的复数)类似于dollar(美元)与dollars(美元的复数)。(复数形式)
• 男人与女人类似于国王与女王。(性别角色)
因为这些向量是从人们使用语言的方式中构建的,它们反映了许多存在于人类语言中的偏见。例如,在某些词向量模型中,(医生)减去(男人)再加上(女人)等于(护士)。减少这种偏见是一个很新颖的研究领域。
尽管如此,词向量是语言模型的一个有用的基础,它们编码了词之间微妙但重要的关系信息。如果一个语言模型学到了关于猫的一些知识(例如,它有时会去看兽医),那同样的事情很可能也适用于小猫或狗。如果模型学到了关于巴黎和法国之间的关系(例如,它们共用一种语言),那么柏林和德国以及罗马和意大利的关系很可能是一样的。
2、词的意义取决于上下文
像这样简单的词向量方案并没有捕获到自然语言的一个重要事实:词通常有多重含义。
例如,单词“bank”可以指金融机构或河岸。或者考虑以下句子:
• John picks up a magazine(约翰拿起一本杂志)。
• Susan works for a magazine(苏珊为一家杂志工作)。
这些句子中,“magazine”的含义相关但又有不同。约翰拿起的是一本实体杂志,而苏珊为一家出版实体杂志的机构工作。
当一个词有两个无关的含义时,语言学家称之为同音异义词(homonyms)。当一个词有两个紧密相关的意义时,如“magazine”,语言学家称之为多义词(polysemy)。
像ChatGPT这样的语言模型能够根据单词出现的上下文以不同的向量表示同一个词。有一个针对“bank(金融机构)”的向量,还有一个针对“bank(河岸)”的向量。有一个针对“magazine(实体出版物)”的向量,还有一个针对“magazine(出版机构)”的向量。正如你预想的那样,对于多义词的含义,语言模型使用的向量更相似,而对于同音异义词的含义,使用的向量则不太相似。
到目前为止,我们还没有解释语言模型是如何做到这一点——很快会进入这个话题。不过,我们正在详细说明这些向量表示,这对理解语言模型的工作原理非常重要。
传统软件的设计被用于处理明确的数据。如果你让计算机计算“2+3”,关于2、+或3的含义不存在歧义问题。但自然语言中的歧义远不止同音异义词和多义词:
• 在“the customer asked the mechanic to fix his car(顾客请修理工修理他的车)”中,“his”是指顾客还是修理工?
• 在“the professor urged the student to do her homework(教授催促学生完成她的家庭作业)”中,“her”是指教授还是学生?
• 在“fruit flies like a banana”中,“flies”是一个动词(指在天空中飞的水果像一只香蕉)还是一个名词(指喜欢香蕉的果蝇)?
人们根据上下文来解决这类歧义,但并没有简单或明确的规则。相反,这需要理解关于这个世界的实际情况。你需要知道修理工通常会修理顾客的汽车,学生通常完成自己的家庭作业,水果通常不会飞。
词向量为语言模型提供了一种灵活的方式,以在特定段落的上下文中表示每个词的准确含义。现在让我们看看它们是如何做到这一点的。
3、将词向量转化为词预测
ChatGPT原始版本背后的GPT-3模型,由数十个神经网络层组成。每一层接受一系列向量作为输入——输入文本中的每个词对应一个向量——并添加信息以帮助澄清该词的含义,并且更好地预测接下来可能出现的词。
让我们从一个简单的事例说起。

LLM的每个层都是一个Transformer,2017年,Google在一篇里程碑的论文中首次介绍了这一神经网络结构。
在图表底部,模型的输入文本是“John wants his bank to cash the(约翰想让他的银行兑现)”, 这些单词被表示为word2vec风格的向量,并传送至第一个Transformer。这个Transformer确定了wants和cash都是动词(这两个词也可以是名词)。我们用小括号中的红色文本表示这一附加的上下文,但实际上模型会通过修改词向量的方式来存储这一信息,这种方式对人类来说很难解释。这些新的向量被称为隐藏状态(hidden state),并传递给下一个Transformer。
第二个Transformer添加了另外两个上下文信息:它澄清了bank是指金融机构(financial institution)而不是河岸,并且his是指John的代词。第二个Transformer产生了另一组隐藏状态向量,这一向量反映的是该模型之前所学习的所有信息。
上述图表描绘的是一个纯假设的LLM,所以不要对细节过于较真。真实的LLM往往有更多层。例如,最强大的GPT-3版本有96层。
研究表明(https://arxiv.org/abs/1905.05950),前几层专注于理解句子的语法并解决上面所示的歧义。后面的层(为保持图表大小的可控性上述图标没有显示)则致力于对整个段落的高层次理解。
例如,当LLM“阅读”一篇短篇小说时,它似乎会记住关于故事角色的各种信息:性别和年龄、与其他角色的关系、过去和当前的位置、个性和目标等等。
研究人员并不完全了解LLM是如何跟踪这些信息的,但从逻辑上讲,模型在各层之间传递时信息时必须通过修改隐藏状态向量来实现。现代LLM中的向量维度极为庞大,这有利于表达更丰富的语义信息。
例如,GPT-3最强大的版本使用有12288个维度的词向量,也就是说,每个词由一个包含12288个的数字列表表示。这比Google在2013年提出的word2vec方案要大20倍。你可以把所有这些额外的维度看作是GPT-3可以用来记录每个词的上下文的一种“暂存空间(scratch space)”。较早层所做的信息笔记可以被后来的层读取和修改,使模型逐渐加深对整篇文章的理解。
因此,假设我们将上面的图表改为,描述一个96层的语言模型来解读一个1000字的故事。第60层可能包括一个用于约翰(John)的向量,带有一个表示为“(主角,男性,嫁给谢丽尔,唐纳德的表弟,来自明尼苏达州,目前在博伊西,试图找到他丢失的钱包)”的括号注释。同样,所有这些事实(可能还有更多)都会以一个包含12288个数字列表的形式编码,这些数字对应于词John。或者,该故事中的某些信息可能会编码在12288维的向量中,用于谢丽尔、唐纳德、博伊西、钱包或其他词。
这样做的目标是,让网络的第96层和最后一层输出一个包含所有必要信息的隐藏状态,以预测下一个单词。