本篇内容对应 “Redis高级数据类型”小节 和 “7.5 网站数据统计”小节
对应视频:
Redis高级数据结构
网站数据统计
1 什么是UV和DAU?
| DAU | UV | |
|---|---|---|
| 英文全称 | Daily Active User | Unique Visotr |
| 中文全称 | 日活跃用户量 | 独立访客 |
| 如何统计数据 | 通过用户ID排重统计数据 | 通过用户IP排重统计数据 |
| 记录的是什么 | 记录的是用户 | 记录的是设备 |
| 使用的Redis数据结构 | Bitmaps | HyperLogLog |
2 什么是Redis的Bitmap和HyperLoLog?
2.1 Bitmaps
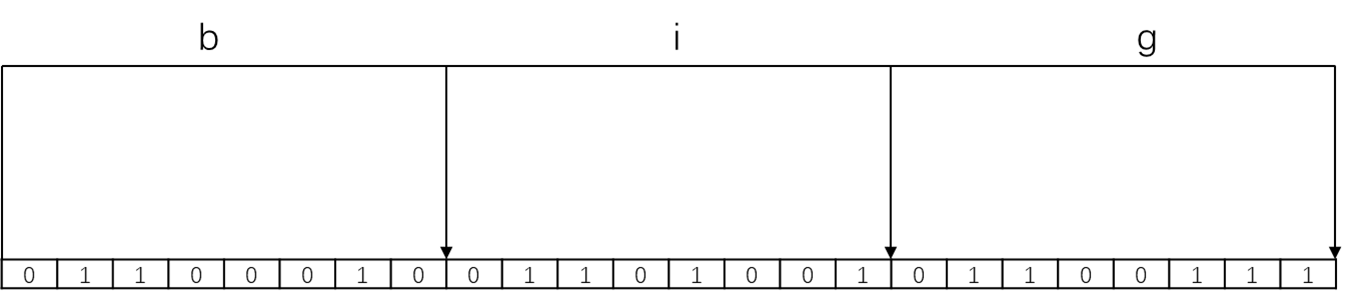
计算机是用二进制作为信息的基础单位,1个字节是8个bit位。例如"big"字符由3个字节组成,实际在计算机存储时将其用二进制表示。"big"中每个字符分别对应的ASCII码是98,105和103,这些十进制数对应的8位二进制数如下:
许多开发语言都提供了此操作位的功能,例如Java语言中:
i >> 1 // 右移1位 等价于 i / 2
i << 1 // 左移1位 等价于 i * 2
i & j // 按符号与
i | j // 按符号或
i ^ j // 按符号异或
~i // 按位取非
合理地使用位操作能够有效地提高内存使用率和开发效率。Redis也提供了操作位的功能,即利用Bitmaps这个“数据结构”实现对位的操作,这里使用Bitmaps时要注意两点:
- Bitmaps本身不是一种数据结构,实际上它就是字符串,只不过它可以对字符串的位进行操作。
- Bitmaps单独提供了一套命令,所以在Redis中使用Bitmaps和使用字符串的方法不太相同。可以把Bitmaps想象成一个以位为单位的数组,数组的每个单元只能存储0和1,数组的下标在Bitmaps中叫偏移量。

将每个独立用户是否访问过网站存放在Bitmaps中,将访问的用户记作1,没有访问的用户记作0,用偏移量作为用户的id。
1.设置值
设置键的第offset个位的值(从0开始算起),假设现在有20个用户,userid=0, 5, 11, 15, 19 的用户对网站进行了访问,我们使用以下Redis命令向Bitmaps中添加这几个访问用户的id,2024-04-03表示这天的独立访问的用户的Bitmaps
setbit unique:users:2024-04-03 0 1
setbit unique:users:2024-04-03 5 1
setbit unique:users:2024-04-03 11 1
setbit unique:users:2024-04-03 15 1
setbit unique:users:2024-04-03 19 1
我使用lua脚本,在redis中可以直接将这5条命令一次执行:
EVAL "
redis.call('SETBIT', 'unique:users:2024-04-03', 0, 1)
redis.call('SETBIT', 'unique:users:2024-04-03', 5, 1)
redis.call('SETBIT', 'unique:users:2024-04-03', 11, 1)
redis.call('SETBIT', 'unique:users:2024-04-03', 15, 1)
redis.call('SETBIT', 'unique:users:2024-04-03', 19, 1)
" 0
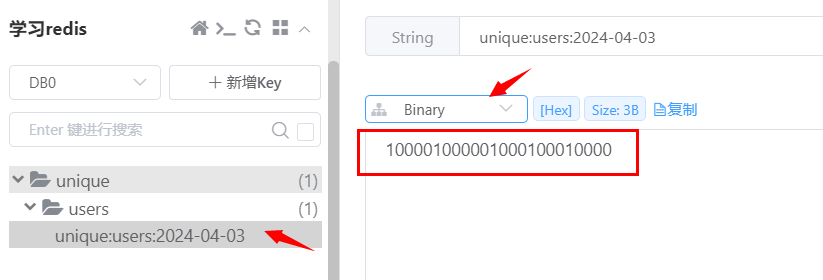
当前Bitmaps初始化结果是:

如果此时有一个userid=50的用户访问了网站,会将这个用户添加到Btimaps中:
setbit unique:users:2024-04-03 50 1

对应的Bitmaps应该长这样:
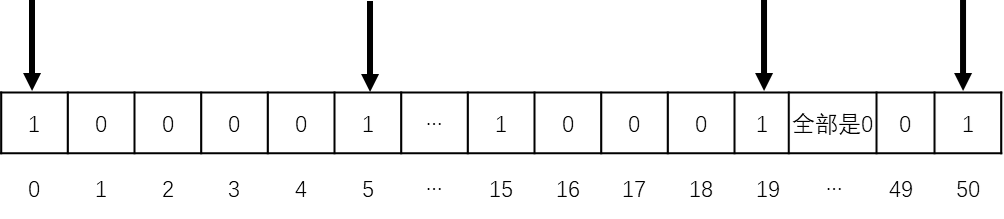
在使用Bitmaps统计独立访问的用户时,需要注意以下几点:
- 一些应用的用户id可能以一个指定的数字开头(例如1000),直接使用这样的用户id作为偏移量会造成一定的浪费,可以考虑减去一个特定的数字。
- 在第一次初始化Bitmaps,如果偏移量较大,整个初始化过程会比较慢,可能造成Redis的阻塞。
2.获取值
获取userid=8的用户在2024-04-03这天是否访问过网站:
getbit unique:users:2024-04-03 8

结果返回0,表示该用户在2024-04-03这天没有访问过网站,由于前面我们没有添加过userid=8的这个用户,所以这个结果时符合逻辑的。
获取一个不存在的userid,比如偏移量是10000,结果也是返回0:
getbit unique:users:2024-04-03 10000

3.获取Bitmaps指定范围值为1的个数
下面这个命令会计算2024-04-03这天网站的独立访问用户数量:
bitcount unique:users:2024-04-03

通过bitcout命令就可以计算出2024-04-03这天这天网站的DAU,值是6
4.Bitmaps间的运算
假设
2024-04-04这天访问网站的用户是userid=1, 2, 5, 9;
2024-04-05这天访问网站的用户是userid=0, 1, 4, 9
现在要计算2024-04-04和2024-04-05这两天都访问过网站的用户数量,首先初始化这连天的Bitmaps,可以使用bitio and命令将这两个Bitmaps取交集。
图示过程如下:
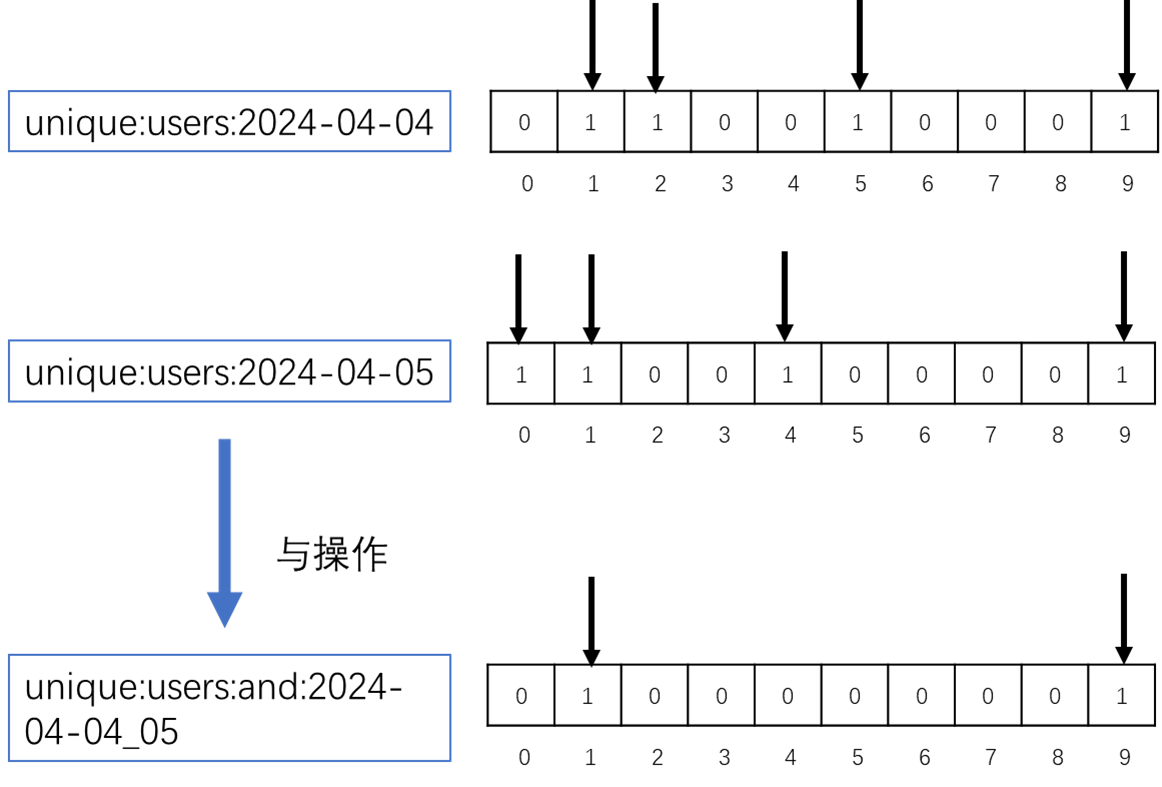
再用前面介绍的bitcout命令即可获取与操作之后的Btimaps数量。
Bitmaps性能分析
假设网站由一亿用户,每天独立访问的用户有5千万。分别用集合类型和Bitmaps类型计算DAU,性能比较如下:
| 数据类型 | 每个用户id占用的空间 | 需要存储的用户量 | 全部内存量 |
|---|---|---|---|
| 集合 | 64 位 | 5千万 | 64位 X 5千万=400MB |
| Bitmaps | 1 位 | 1亿 | 1位X1亿=12.5MB |
首先,我们知道:
1 Byte = 8 Bit
1 KB = 1024 Byte
1 MB = 1024 KB
那么,64乘以5千万个bit就是:
64 * 50,000,000 Bit
将Bit转换为Byte:
64 * 50,000,000 Bit / 8 = 400,000,000 Byte
再将Byte转换为KB:
400,000,000 Byte / 1024 = 390,625 KB
最后将KB转换为MB:
390,625 KB / 1024 = 381.47 MB
最后结果大约在400M
但是这并不说明Bitmaps是万金油,如果用户量还是1亿,但是每天访问的用户只有10万,也就是说注册的用户大量是僵尸用户。这时他们之间的性能对比如下:
| 数据类型 | 每个用户id占用的空间 | 需要存储的用户量 | 全部内存量 |
|---|---|---|---|
| 集合 | 64 位 | 10万 | 64位 X 10万=800KB |
| Bitmaps | 1 位 | 1亿 | 1位X1亿=12.5MB |
因为Bitmaps不管你每天具体独立访问的用户数量,而是关系用户id,如果有一个id很大的用户访问一次,那么Bitmaps也会变得非常大。
2.2 HyperLogLog
HyperLogLog是一种基数算法,实际数据类型还是字符串类型,通过HyperLogLog可以利用很小的内存空间完成独立总数的统计,数据集可以是IP、Email、ID等。
Philippe Flajolet教授发表的论文首次提出的HyperLogLog基数算法
论文:The analysis of a near-optimal cardinality estimation algorithm
1.添加
pfadd用于向HyperLogLog添加元素,如果添加成功返回1:
pfadd 2024_04_03:unique:ids uuid-1 uuid-2 uuid-3 uuid-4
2.计算独立用户数
pfcount用于计算一个或多个HyperLogLog的独立总数:
pfcount 2024_04_03:unique:ids
3.HyperLogLog内存占用实验
一两条数据看不出HyperLogLog内存占用小的优势,我们使用linux的bash脚本,向redis插入100万条用户uuid。
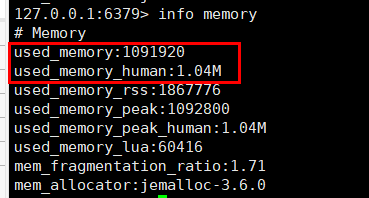
首先我们查询插入前的内存大小,我们执行关注前两行数据即可:
info memory
向redis HyperLogLog中的2024_04_04:unique:ids键插入100万个用户id的bash脚本如下
#!/bin/bash
# 初始化变量
elements=""
key="2024_04_04:unique:ids"
# 循环生成并插入用户ID
for i in $(seq 1 1000000); do
elements="${elements} user-"${i}
if [[ $((i%1000)) == 0 ]]; then
# 使用Redis的pfadd命令插入用户
redis-cli pfadd ${key} ${elements}
# 清空elements变量,准备下一次插入
elements=""
fi
done
# 如果最后一次循环的用户数量不足1000,将剩余的用户插入
if [[ -n "$elements" ]]; then
redis-cli pfadd ${key} ${elements}
fi
我们将该bash脚本命名为insert_users.sh,然后在Linux运行该脚本

./insert_users.sh
如果报bash: ./insert_users.sh: Permission denied 错误,说明这个文件没有执行权限
使用chmod +x insert_users.sh命令给该文件添加执行权限,然后再次运行即可
执行完毕后到redis中,再次执行查询内存的命令
info memory
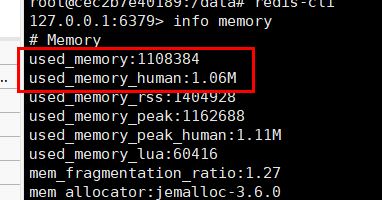
1108384b - 1091920b = 16464b = 16.46KB
所以存入100万个用户的uuid之后,内存只增加了16.46KB。可以看到内存占用非常小。我们再来看一下统计结果是否正确,用pfcount命令统计以下:
pfcount 2024_04_04:unique:ids

可以看到结果是1003860,并不是精确的100万,但是也很接近了。考虑到占用的内存有很大的优势,对精确值要求敏感的业务完全可以用HyperLogLog。
再来看一下如果用集合来存储着100万个用户uuid,然后统计总数,bash脚本如下:
#!/bin/bash
# 初始化变量
elements=""
key="2024_04_04:unique:ids:set"
# 循环生成并插入用户ID
for i in $(seq 1 1000000); do
elements="${elements} user-"${i}
if [[ $((i%1000)) == 0 ]]; then
# 使用Redis的sadd命令插入用户
redis-cli sadd ${key} ${elements}
# 清空elements变量,准备下一次插入
elements=""
fi
done
# 如果最后一次循环的用户数量不足1000,将剩余的用户插入
if [[ -n "$elements" ]]; then
redis-cli pfadd ${key} ${elements}
fi
存入insert_users_set.sh脚本文件中,然后运行。
./insert_users_set.sh
执行完后,到redis执行info memory命令,与上一次的内存大中比较:
info memory
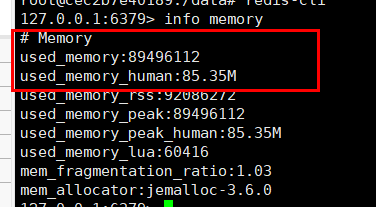
89496112b - 1108384b = 88387728b = 84.28M
可以看到与前一次相比,内存增加了84M左右。但是用集合统计的结果是精确的:
scard 2024_04_04:unique:ids:set

根据上面的实验结果,这里列出了使用集合类型和HyperLogLog类型统计百万级用户的占用空间对比:
| 数据类型 | 1天 | 1个月 | 1年 |
|---|---|---|---|
| 集合 | 80M | 2.4G | 28G |
| HyperLogLog | 15K | 450K | 5M |
可以看到HyperLogLog内存占用量小得惊人,用如此小的空间来估算如此巨大的数据,必然不是100%的精确,存在一定的误差率。Redis官方给出的数字是0.81%的失误率。
4.合并
pfmerge可以求出多个HyperLogLog的并集并赋值给destkey,例如要计算2016年3月5日和3月6日的访问独立用户数,可以按照如下方式来执行:
pfadd 2016_03_06:unique:ids "uuid-1" "uuid-2" "uuid-3" "uuid-4"
pfadd 2016_03_05:unique:ids "uuid-4" "uuid-5" "uuid-6" "uuid-7"
pfmerge 2016_03_05_06:unique:ids 2016_03_05:unique:ids 2016_03_06:unique:ids
pfcount 2016_03_05_06:unique:ids
3 网站数据统计
为什么UV要用ip作为统计访客的依据?
因为我们希望将一些匿名的用户,或者一些没有登录的用户或一些没有账号的游客也统计进来。 UV这个统计值关注的是访问量。而不是关注到底注没注册、登没登录。不管是谁,只要你访问就算。所以,我们要对每次访问都要进行统计,每次访问都把这个用户的ip存到HyperLogLog里,HyperLogLog会统计不同ip的个数,得到最终去重以后的结果,虽然有误差率,但是其极致的内存利用率,这点误差率可以忍受的。
为什么HyperLogLog适合用统计UV的数据结构?
因为HyperLogLog最大的特点是性能好,存储空间非常小。而我们网站的访问量,加上游客的话,可能会非常大,每天可能有几十万甚至上百万的访问量。因为即使是同一个ip访问,由于服务器事先不知道,也会取把这个ip记录到数据结构中。所以访问量才这么大。而我们对UV这个统计值要求不是那么精确,HyperLogLog的误差率足以忍受,所以我们使用HyperLogLog来统计UV。
你的网站如何定义用户是否活跃?
我的网站定义只要今天访问一次就算是一个活跃用户。
DAU与UV的区别?
我们统计DAU是根据用户id来进行统计的,也就是说一些没有登录的游客,DAU是不统计的。
为什么DAU要用Bitmaps?
因为我们在统计DAU时更关注用户的有效性,通过Bitmaps不仅可以统计某天的活跃用户数量,还可以通过命令判断某天,某个用户是不是活跃的等功能,也就是Bitmaps虽然空间利用率没有HyperLogLog高,但是一个网站真正注册登录的用户其实相较于访问量会小很多,所以对空间的占用不会特别高。而且Bitmaps统计是精确的结构。我们关注用户的核心程度,所以对于这样的数据,要求它是一个精确的结果。Bitmaps本身统计的内存占用也不大,性能也比较好,能统计出精确的结果。
你如何实现用Bitmaps存储用户id?
在数据库表设计时,我将用户表的userid设计成为int类型,从1开始自增的主键,所以可以直接将用户id作为偏移量,是否访问了网站分别设置为1和0来存入bitmaps中。
由于userid是整数,而我们要记录的是这个userid访没访问过,访问过就是1,没访问过就是0。1就是活跃,0就是不活跃。
例如:bitmaps的key = dau:2024-04-04,然后userid=101的用户在2024-04-04这条访问过我们的网站,我就将Bitmaps的101位设置成1
这样我们每天可能有几万个用户访问了网站,我只需要用一个Bitmaps,这个Bitmaps的长度=max(userid)。所以,Bitmaps也是比较节约空间的,这么多用户我只需用这么些位来统计即可。
下面我们开始编码实现,因为要用到redis来存储数据,所以首先需要定义redisk key。在RedisKeyUtil类里面添加UV和DAU的key:
private static final String PREFIX_UV = "uv";
private static final String PREFIX_DAU = "dau";
如何查看一周的UV?
由于HyperLogLog支持合并,我们只需使用pfmerge命令求出多个HyperLogLog的并集。例如要计算2024-04-04到2024-04-11这一周的UV,我们可以将这一周7天的7个HyperLogLog进行合并。
我们按照单日UV的方式来记录:
// 单日UV
public static String getUVKey(String date) {
return PREFIX_UV + SPLIT + date;
}
单日UV的key类似于:“uv:2024-04-04”。
如果想统计一周,一个区间的UV,可以对多个HyperLogLog合并,合并的适合会产生一个新的数据,这个数据要指定一个新的key,所以我们要构造一周UV的key,即区间UV。
// 区间UV
public static String getUVKey(String startDate, String endDate) {
return PREFIX_UV + SPLIT + startDate + SPLIT + endDate;
}
区间UV的key类似于 “uv:2024-04-04:2024-04-11”。
同理,统计活跃用户也需要但是DAU和区间DAU
// 单日活跃用户
public static String getDAUKey(String date) {
return PREFIX_DAU + SPLIT + date;
}
// 区间活跃用户
public static String getDAUKey(String startDate, String endDate) {
return PREFIX_DAU + SPLIT + startDate + SPLIT + endDate;
}
定义完以后,我们开发首先开发数据访问层,因为我们用的是Redis,所以我们数据访问层不用单独一个组件,直接上来些Service即可。取调用这个RedisTemplate就行了,创建一个新的Server:DataService类。
首先将RedisTemplate 对象注入进来,由于创建DAU和UV的key时要不断的和日期打交道,所以也将SimpleDateFormat 注入进来,日期格式是"yyyyMMdd"
@Autowired
private RedisTemplate redisTemplate;
private SimpleDateFormat df = new SimpleDateFormat("yyyyMMdd");
要统计这个数据包括两个方面:
- 我要把这个数据记录下来,在每一次请求当中,需要截获这次请求,把相关数据记录到redis。(记)
- 当我想看的时候,能够提供一个查询的方法,能够访问到。(查)
首先做UV记的方法:
// 将指定的IP计入UV
public void recordUV(String ip) {
String redisKey = RedisKeyUtil.getUVKey(df.format(new Date()));
redisTemplate.opsForHyperLogLog().add(redisKey, ip);
}
UV区间查的方法:
// 统计指定日期范围内的UV
public long calculateUV(Date start, Date end) {
if (start == null || end == null) {
throw new IllegalArgumentException("参数不能为空!");
}
// 整理该日期范围内的key
List<String> keyList = new ArrayList<>();
Calendar calendar = Calendar.getInstance();
calendar.setTime(start);
while (!calendar.getTime().after(end)) {
String key = RedisKeyUtil.getUVKey(df.format(calendar.getTime()));
keyList.add(key);
calendar.add(Calendar.DATE, 1);
}
/*
* 如果是同一天,2024-04-03 00:00:00~ 2024-04-03 23:59:59
* 合并生成的redisKey是vu:2024-04-03:2024-04-04
* keyList的值是[vu:2024-04-03],union操作只union了一个
* 实现了一个方法统计单日UV和区间UV
* 下面DAU查的方式也是一样的
* */
// 合并这些数据
String redisKey = RedisKeyUtil.getUVKey(df.format(start), df.format(end));
redisTemplate.opsForHyperLogLog().union(redisKey, keyList.toArray());
// 返回统计的结果
return redisTemplate.opsForHyperLogLog().size(redisKey);
}
DAU的记和查的逻辑类似:
// 将指定用户计入DAU
public void recordDAU(int userId) {
String redisKey = RedisKeyUtil.getDAUKey(df.format(new Date()));
redisTemplate.opsForValue().setBit(redisKey, userId, true);
}
// 统计指定日期范围内的DAU
public long calculateDAU(Date start, Date end) {
if (start == null || end == null) {
throw new IllegalArgumentException("参数不能为空!");
}
// 整理该日期范围内的key
List<byte[]> keyList = new ArrayList<>();
Calendar calendar = Calendar.getInstance();
calendar.setTime(start);
while (!calendar.getTime().after(end)) {
String key = RedisKeyUtil.getDAUKey(df.format(calendar.getTime()));
keyList.add(key.getBytes());
calendar.add(Calendar.DATE, 1);
}
/*
* redisTemplate.opsForValue().setBit 可以设置位
* 但是要使用or运算必须使用底层连接
* */
// 进行OR运算
return (long) redisTemplate.execute(new RedisCallback() {
@Override
public Object doInRedis(RedisConnection connection) throws DataAccessException {
String redisKey = RedisKeyUtil.getDAUKey(df.format(start), df.format(end));
connection.bitOp(RedisStringCommands.BitOperation.OR,
redisKey.getBytes(), keyList.toArray(new byte[0][0]));
return connection.bitCount(redisKey.getBytes());
}
});
}
业务层逻辑写好以后,接下来就可以写表现层的逻辑。表现从逻辑一分为二:
- 什么时候去记录这个值
- 什么时候去查看这个值
记录这个值需要每次请求都进行记录,因为每次请求都有可能是一个新的访问,所以我们在拦截器里面写这个代码。请求到底Handler之前将请求拦截

创建一个DataInterceptor类,只需要重写preHandle方法即可,在该方法里面进行DAU和UV的统计。
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
// 统计UV
String ip = request.getRemoteHost();
dataService.recordUV(ip);
// 统计DAU
User user = hostHolder.getUser();
if (user != null) {
dataService.recordDAU(user.getId());
}
return true;
}
然后将该拦截器注册。
之后就是统计方法,比较简单。