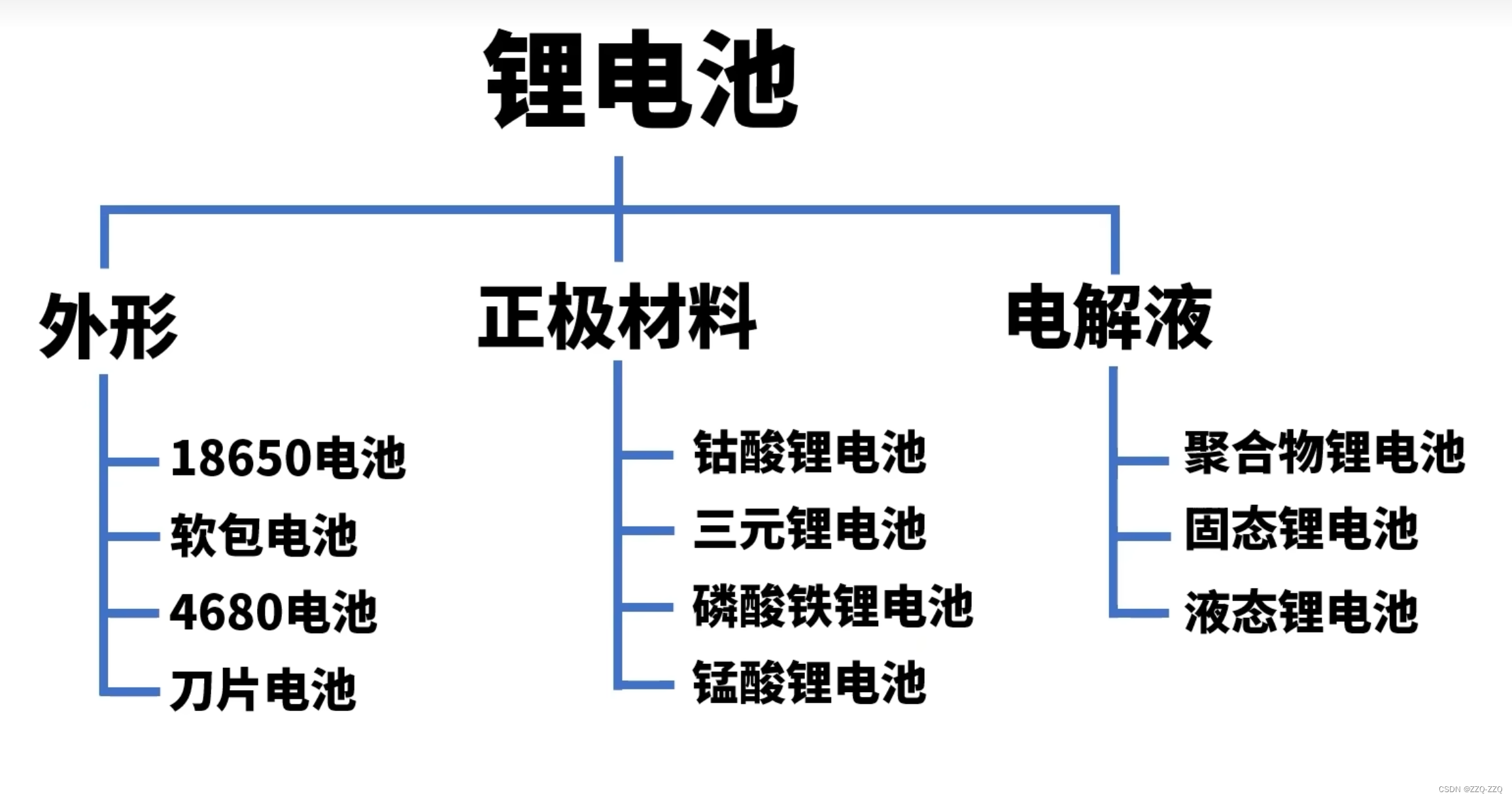
目录
前言
进程创建
认识fork
写时拷贝
再谈fork
进程终止
进程退出码
用代码来终止进程
常见的进程终止的方式
exit
_exit
进程等待
进程等待的必要性
进程等待的方式
wait
waitpid
详解status参数
详解option参数
前言
本文适合有一点基础的人看的,否则的话有点难以理解,如果有问题,可以在评论区将你的问题打出来,我会一一解答的。
关于本文可以先去看看上篇的进程地址空间可以更好的理解这里的内容
进程创建
认识fork
fork函数是从已存在进程中创建一个新进程,新进程为子进程,原进程为父进程

返回值
- 创建成功,在父进程中返回子进程的PID,并在子进程中返回0
- 创建失败,父进程返回-1,子进程不返回,并设置错误码
当进程中调用了fork,那么内核就会做以下事情
- 分配新的内存块和内核数据结构给子进程
- 将父进程部分数据结构内容拷贝至子进程
- 添加子进程到系统进程列表中
- fork返回,开始调度器调度
#include <stdio.h>
#include <unistd.h>
int main()
{
printf("这是父进程, pid:%d\n", getpid());
pid_t id = fork();
if(id < 0)
{
printf("创建子进程失败!!!");
return 1;
}
else if(id == 0)
{
//子进程
while(1)
{
printf("我是子进程, pid:%d, ppid:%d\n", getpid(), getppid());
sleep(1);
}
}
else
{
//父进程
while(1)
{
printf("我是父进程, pid:%d, ppid:%d\n", getpid(), getppid());
sleep(1);
}
}
return 0;
}

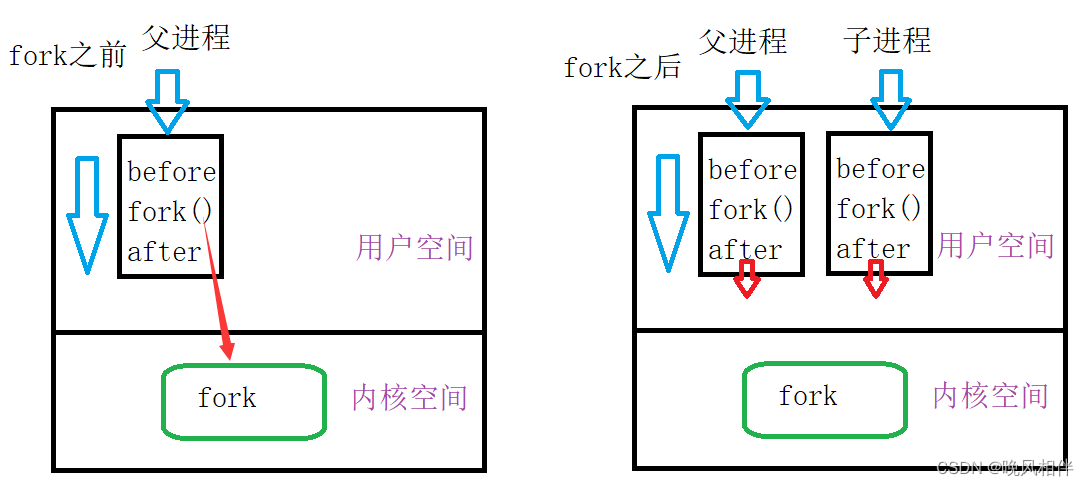
fork之前只有父进程在执行,fork之后,父子进程分别执行。注:fork之后,父子进程谁先执行是由调度器决定的。
写时拷贝
从上面的内容我们知道,子进程也有自己的数据和代码,但是一般而言,我们的代码和数据没有在磁盘加载的过程,也就是说,子进程没有自己的代码和数据,所以子进程和父进程的共享代码和数据。对于代码而言,都是不可写的只能读取,所以父子共享没有问题;但对于数据而言可能会被修改,所以父子进程的数据必须分离。
那么数据分离是创建进程的时候就直接拷贝分离,还是修改数据时才拷贝分离呢?
答案肯定是需要修改数据时才拷贝分离
因为当你创建子进程时,可能其中的数据根本不会用到,即使用到了,也只是读取,那么这样的话在创建进程时就将数据直接拷贝分离是非常浪费空间的,所以操作系统选择了,当你需要对数据进行修改时才拷贝一份,这样父子进程的数据进行了分离且互不影响。而这个技术就叫做写时拷贝。
看一下下面代码的结果
从结果可以看出,编译器编译程序的时候,尚且知道节省空间何况是操作系统呢
那么操作系统为何要选择写时拷贝技术对父子进程进行分离呢?
- 当用到数据时,再将数据进行分离是高效使用内存的一种表现
- 操作系统在代码执行前无法预知哪些空间会被访问,也就无法对数据进行分离



再谈fork

在重新回到认识fork的图中,fork之后,父子进程代码共享,是after共享,还是所有的共享?
答案是:所有的啦
那么子进程为什么不会从before之后在执行代码,而是直接从after开始执行代码呢?也就是说子进程是怎么知道代码执行到哪里了呢?
答案是:通过进程的上下文数据
我们的代码形成汇编之后,会有很多行代码,并且每行代码加载到内存之后都有对应的地址。但是进程由于一些原因随时可能会被中断(还没执行完),那么当进程下次回来时,还必须从当前中断的位置继续向后执行,这时就必须要求CPU随时记录下当前进程执行的位置,所以CPU内会有对应的寄存器(EIP,也叫PC指针)用来记录当前进程执行的位置,寄存器在CPU内只有一份,但是寄存器内的数据可以有多份。而这个寄存器中的数据就叫做进程的上下文数据,是数据就会发生写时拷贝。虽然父子进程各自会调度,各自会修改EIP,但是子进程已经认为自己EIP起始值就是fork之后的代码。

fork的常规用法
- 父子进程同时执行不同的代码段。例如父进程等待客户端请求,子进程处理请求。
- 一个进程要执行一个不同的程序。例如子进程从fork返回后调用exec函数。
fork调用失败的原因
- 系统中有太多的进程
- 用户的进程数超过了限制
进程终止
进程退出码
进程退出的三种情况
- 代码运行完,结果正确
- 代码运行完,结果错误
- 代码没有运行完,程序崩溃了
当我们写代码时总是在main函数的最后return 0,那么main函数返回的意义是什么呢,return 0的含义又是什么,为什么返回的总是0呢?
下面就让我来一一解答这些问题吧
其实main函数返回的并不总是0,也可以是其它数字,而main函数返回的这个值其实是叫做进程的退出码。例如下面代码
int main() { printf("hello world"); return 10; }
echo $?:用于获取最近一个进程执行完毕的退出码
我们返回的这个10的作用其实是用来标识代码执行完毕,结果是正确的,所以我们return 0的含义是:0表示代码执行完毕,结果正确;非0表示的是运行的结果不正确。非0值有无数个,不同的非0值可以标识不同的错误原因。所以我们也就可以根据这个返回值来判定代码运行完后的正确性。
因此我们也就明白了main函数返回的意义就是返回给上一级进程用来评判该进程的执行结果,如果结果不正确方便我们定位错误的原因细节。
在Linux下就定义了134个退出码,分别标识了不同的错误原因。
可以用strerror函数将这些退出码对应的错误原因打印出来
#include <stdio.h> #include <string.h> int main() { for(int number = 0; number <= 134; number++) { printf("%d:%s\n", number, strerror(number)); } return 0; }
当然我们也可以使用这些退出码和含义,但是如果我们想自己定义也可以自己设计一套退出方案来。



上面的分析都是针对进程退出的前两种情况,那么第三种情况呢?
程序崩溃而导致的退出其退出码没有任何意义,因为崩溃退出没有执行对应的rreturn语句。
#include <stdio.h>
int main()
{
int* ptr= NULL;
*ptr = 10;//野指针
printf("hello world\n");
return 0;
}
![]()
用代码来终止进程
常见的进程终止的方式
- 在main函数内使用return语句
- 调用exit函数,可以在代码的任何地方调用都表示终止进程。
- 调用系统接口_exit
exit

#include <stdio.h>
#include <stdlib.h>
void Func()
{
//打印1-10
for(int i = 1; i <= 10; i++)
{
printf("%d ", i);
}
printf("\n");
exit(22);
}
int main()
{
printf("hello world\n");
printf("hello world\n");
Func();
printf("hello world\n");
exit(11);
printf("hello world\n");
return 0;
}

_exit

#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main()
{
printf("hello world\n");
sleep(3);
exit(22);
}
上面这个代码是先打印hello world还是先sleep呢?

很显然是先打印hello world再sleep,那么我们把\n去掉呢?

很显然是先sleep再打印hello world。\n其实就是将我们打印的内容从缓冲区刷新到我们的屏幕上。
那么我们换用系统接口_exit试一试
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main()
{
printf("hello world");
sleep(3);
_exit(22);
}

可以看出它执行了sleep但是为什么最后没有将hello world给我们打印出来呢?
因为exit()函数是C标准库给我们提供的库函数,它最后也会调用_exit,但在调用_exit之前还做了其它工作
- 执行用户通过atexit或者on_exit定义的清理函数
- 关闭所有打开的流,所有的缓冲区数据均被写入
- 调用_exit
而其中的缓冲区其实是C标准库在给我们维护的而不是操作系统,它在操作系统的上层,所以_exit最后不会将hello world刷新出来

进程等待
进程等待的必要性
当我们用fork创建子进程时,子进程退出,父进程如果不管子进程,就可能造成僵尸进程的问题,进而造成内存泄漏。另外,进程一旦变成僵尸状态,就连kill -9号命令也拿它没办法,因为谁也没办法杀死一个已经死去的进程。最后由于子进程变成僵尸,那么父进程指派给子进程完成的任务我们也无法知道是否已经完成,所以我们必须让父进程通过进程等待的方式回收子进程的资源,获取子进程的退出信息。
进程等待的方式
wait
没调wait之前
#include <stdio.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <stdlib.h>
#include <unistd.h>
int main()
{
pid_t id = fork();
if(id < 0)
{
perror("fork");
exit(0);//创建子进程失败
}
else if(id == 0)
{
//子进程
int cnt = 5;
while(cnt)
{
printf("cnt:%d,我是子进程,pid:%d,ppid:%d\n", cnt, getpid(),getppid());
sleep(1);
cnt--;
}
exit(1);//子进程退出
}
else
{
//父进程
while(1)
{
printf("我是父进程,pid:%d,ppid:%d\n", getpid(), getppid());
sleep(1);
}
}
return 0;
}

5秒之后子进程变僵尸,那么我们调用wait看看现象
返回值:成功则返回被等待进程的pid,失败则返回-1
参数:输出型参数,获取子进程退出状态,不关心其状态则可以设置为NULL

#include <stdio.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <stdlib.h>
#include <unistd.h>
int main()
{
pid_t id = fork();
if(id < 0)
{
perror("fork");
exit(0);//创建子进程失败
}
else if(id == 0)
{
//子进程
int cnt = 5;
while(cnt)
{
printf("cnt:%d,我是子进程,pid:%d,ppid:%d\n", cnt, getpid(),getppid());
sleep(1);
cnt--;
}
exit(1);//子进程退出
}
else
{
//父进程
printf("我是父进程,pid:%d,ppid:%d\n", getpid(), getppid());
sleep(7);
pid_t ret = wait(NULL);
if(ret > 0)
{
printf("等待子进程成功,ret:%d\n",ret);
}
while(1)
{
printf("我是父进程,pid:%d,ppid:%d\n", getpid(), getppid());
sleep(1);
}
}
return 0;
}


从结果很容易看出,5秒后子进程进入僵尸状态,7秒后父进程将子进程回收掉了。
waitpid
返回值:正常返回子进程的进程ID,如果设置了选项WNOHANG并且子进程均已退出,则返回0;如果调用失败则返回-1,并且error会被设置相应的错误码
参数:
- pid==-1,等待任意一个子进程;pid > 0,等待其进程ID与pid相等的子进程。
- 输出型参数,WIFEXITED(status):若为正常终止子进程返回的状态则为真。(可以用来查看进程是否是正常退出),WEXITSTATUS(status): 若WIFEXITED非零,提取子进程的退出码。(查看进程的退出码)。若不关心status可以设置为NULL和wait一样。
- WNOHANG: 若pid指定的子进程没有结束则函数返回0,不予以等待;若正常结束则返回该子进程的ID,这种方式也叫做非阻塞等待。默认为0表示阻塞等待。

将上面代码中的wait换成waipid即可,现象都是一样的

详解status参数
wait和waitpid都有一个status参数,该参数是一个输出型参数,由操作系统填充,如果设置为NULL则表示不关心子进程的退出状态信息,否则操作系统会根据该参数,将子进程的退出信息反馈给父进程。
那么我们用代码实际验证一下status吧
#include <stdio.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <stdlib.h>
#include <unistd.h>
int main()
{
pid_t id = fork();
if(id < 0)
{
perror("fork");
exit(0);//创建子进程失败
}
else if(id == 0)
{
//子进程
int cnt = 5;
while(cnt)
{
printf("cnt:%d,我是子进程,pid:%d,ppid:%d\n", cnt, getpid(),getppid());
sleep(1);
cnt--;
}
exit(100);//子进程退出
}
else
{
//父进程
printf("我是父进程,pid:%d,ppid:%d\n", getpid(), getppid());
int status = 0;
pid_t ret = waitpid(id, &status, 0);//阻塞式等待
if(ret > 0)
{
printf("等待子进程成功,ret:%d,子进程的退出码:%d\n",ret, status);
}
}
return 0;
}

上面的代码中子进程的退出码明明是100,为什么打印出来的却是比100大的多的25600呢?
原因是:status并不是按照整数来整体使用的,而是按照比特位的方式将32个比特位进行划分,这里我们只分析低16位

所以我们要获取子进程的退出码就要右移8位并与上0xff


当我们的进程(程序)异常退出或者崩溃,本质上是操作系统杀掉了我们的进程,那么操作系统是通过什么方式来杀掉我们的进程的呢?
答:通过向进程发送信号的方式来杀掉进程。
一共有以下信号

将上面代码进行如下改造
#include <stdio.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <stdlib.h>
#include <unistd.h>
int main()
{
pid_t id = fork();
if(id < 0)
{
perror("fork");
exit(0);//创建子进程失败
}
else if(id == 0)
{
//子进程
int cnt = 5;
while(cnt)
{
printf("cnt:%d,我是子进程,pid:%d,ppid:%d\n", cnt, getpid(),getppid());
sleep(1);
cnt--;
}
exit(100);//子进程退出
}
else
{
//父进程
printf("我是父进程,pid:%d,ppid:%d\n", getpid(), getppid());
int status = 0;
pid_t ret = waitpid(id, &status, 0);//阻塞式等待
if(ret > 0)
{
printf("等待子进程成功,ret:%d,子进程收到的信号编号:%d,子进程的退出码:%d\n",ret, status & 0x7f, (status >> 8)&0xff);
}
}
return 0;
}

0表示正常跑完,100表示结果正确
在代码中加个除0操作


8表示收到了8号信号,代码是异常退出,那么我们的退出码也就无意义了。这里也验证了上面退出码的内容
在代码中加个野指针
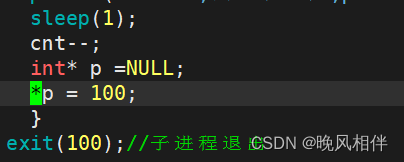

11表示收到了11号信号,也就是段错误。使用kill -9杀掉进程也是类似的,这里就不在演示了。
所以程序(进程)异常不光是内部代码有问题,也可能是外力因素将进程直接干掉了,那么子进程是否跑完,我们也不确定。
知道了上面这些那么让我们来思考一下下面的问题
1、父进程通过wait/waitpid可以拿到子进程的退出结果,那么为什么要用wait/waitpid函数,直接全局变量不行吗?
code为全局变量
很显然是不行的,因为进程具有独立性,全局变量也是数据,那么是数据就要发生写时拷贝,父进程也就无法拿到。
2、既然信号具有独立性,子进程退出的信息也是子进程的数据,那么为什么父进程调用了wait/waitpid就能拿到子进程退出的信息呢?
子进程退出会变成僵尸进程,但是即使变成了僵尸进程也会保留该进程的PCB(task_struct)信息(就跟人死亡后身上会保留死亡的原因),task_struct里面就保留了任何进程退出时的退出信息,所以wait和waitpid本质上就是读取了子进程的task_struct里面相关信息。
3、wait/waitpid有这个权利从PCB中拿到相关信息吗?
肯定有这个权利啊,它们可是系统调用的接口,娘胎里自带的就有这个权利。



我们在获取子进程的退出码时也可以不用位运算,可以使用宏也就是下面的这种写法。
#include <stdio.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <stdlib.h>
#include <unistd.h>
int main()
{
pid_t id = fork();
if(id < 0)
{
perror("fork");
exit(0);//创建子进程失败
}
else if(id == 0)
{
//子进程
int cnt = 5;
while(cnt)
{
printf("cnt:%d,我是子进程,pid:%d,ppid:%d\n", cnt, getpid(),getppid());
sleep(1);
cnt--;
int* p =NULL;
*p = 100;
}
exit(100);//子进程退出
}
else
{
//父进程
printf("我是父进程,pid:%d,ppid:%d\n", getpid(), getppid());
int status = 0;
pid_t ret = waitpid(id, &status, 0);//阻塞式等待
if(ret > 0)
{
if(WIFEXITED(status))
{
printf("子进程执行完毕,子进程的退出码:%d\n", WEXITSTATUS(status));
}
else
{
printf("子进程异常退出:%d,退出信号为:%d\n", WIFEXITED(status), WTERMSIG(status));
}
}
return 0;
}

详解option参数
option为0,默认是阻塞式等待;WNOHANG选项,代表父进程非阻塞式等待
WNOHANG其实是一个宏定义
![]()
非阻塞式等待的意思是:父进程通过调用waitpid来进行等待,如果子进程没有退出,则立马返回。
举个例子:你家冰箱坏了,你要打电话叫师傅上你家来维修,当你打通了电话,可是师傅说没有空这时你就立马挂断了电话去处理自己的事情了;过了一段时间,你再次去拨打师傅的电话,可是师傅还在忙,你又立马挂断了电话去处理别的事情了;又过了一段时间,你又拨通了师傅的电话,师傅这时有空了,说立马上门维修。在这个例子中你每次拨打电话的过程其实就是非阻塞调用,非阻塞调用采用的是轮询检测的方案。而如果你在第一次拨打师傅电话时,你一直不挂断电话,等到师傅有空了你才挂断电话,而这就是阻塞等待。
阻塞的本质其实是进程阻塞在系统调用的内部
废话不多说上代码演示
#include <iostream>
#include <vector>
#include <stdio.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <stdlib.h>
#include <unistd.h>
typedef void (*handler_t)(); //函数指针类型
std::vector<handler_t> handlers; //函数指针数组
void fun_one()
{
int a = 10;
int b = 20;
printf("这是一个加法: %d + %d = %d\n", a, b, a + b);
}
void fun_two()
{
int a = 10;
int b = 20;
printf("这是一个减法: %d - %d = %d\n", b, a, b - a);
}
// 设置对应的方法回调
void Load()
{
handlers.push_back(fun_one);
handlers.push_back(fun_two);
}
int main()
{
pid_t id = fork();
if(id < 0)
{
perror("fork");
exit(0);//创建子进程失败
}
else if(id == 0)
{
//子进程
int cnt = 5;
while(cnt)
{
printf("cnt:%d,我是子进程,pid:%d,ppid:%d\n", cnt--, getpid(),getppid());
sleep(1);
}
exit(100);//子进程退出
}
else
{
//父进程
int quit = 0;
while(!quit)
{
int status = 0;
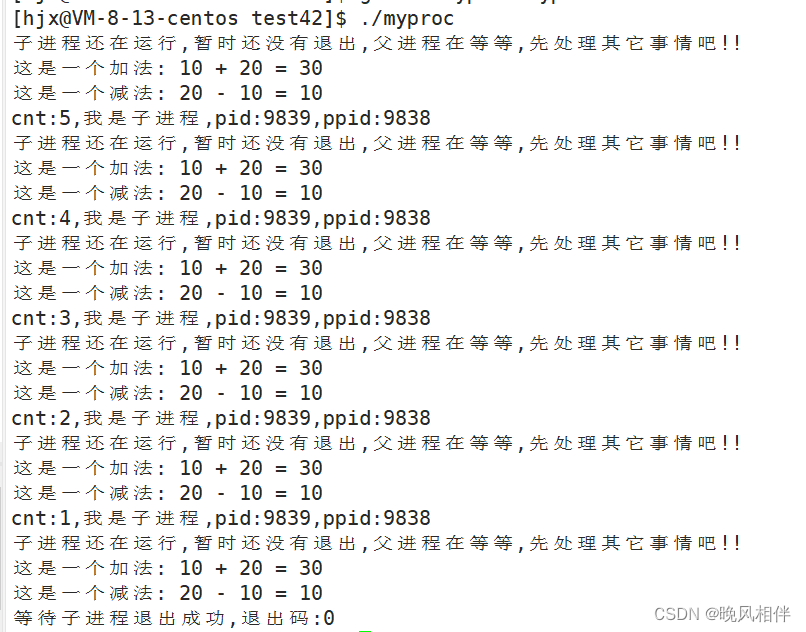
pid_t res = waitpid(-1, 0, WNOHANG);
if(res > 0)
{
//等待成功并且子进程退出
printf("等待子进程退出成功,退出码:%d\n", WEXITSTATUS(status));
quit = 1;
}
else if(res == 0)
{
//等待成功并且子进程还未退出
printf("子进程还在运行,暂时还没有退出,父进程在等等,先处理其它事情吧!!\n");
if(handlers.empty()) Load();
for(auto iter : handlers)
{
//执行其它任务
iter();
}
}
else
{
//等待失败
printf("wait失败\n");
quit = 1;
}
sleep(1);
}
}
return 0;
}
今天的分享就到这里,如果内容有错的话,还望指出谢谢!!!