1. 构造合适的验证集
当出现训练集和测试集分布不一致的,我们可以试图去构建跟测试集分布近似相同的验证集,保证线下验证跟线上测试分数不会抖动,这样我们就能得到稳定的benchmark。Qiuyan918在基于对抗验证的基础上,提出了三种构造合适的验证集的办法:
人工划分验证集
选择和测试集最相似的样本作为验证集
有权重的交叉验证
1.1人工划分验证集
以时间序列举例,因为一般测试集也会是未来数据,所以我们也要保证训练集是历史数据,而划分出的验证集是未来数据,不然会发生“时间穿越”的数据泄露问题,导致模型过拟合(例如用未来预测历史数据),这个时候就有两种验证划分方式可参考使用:
TimeSeriesSplit:Sklearn提供的TimeSeriesSplit。
固定窗口滑动划分法:固定时间窗口,不断在数据集上滑动,获得训练集和验证集。(个人推荐这种)

除了时间序列数据,其它数据集的验证集划分都要遵循一个原则,即尽可能符合测试集的数据模式。
1.2选择和测试集最相似的样本作为验证集
前面在讲对抗验证时,我们有训练出一个分类器去分类训练集和测试集,那么自然我们也能预测出训练集属于测试集的概率(即训练集在‘Is_Test’标签下预测概率),我们对训练集的预测概率进行降序排列,选择概率最大的前20%样本划分作为验证集,这样我们就能从原始数据集中,得到分布跟测试集接近的一个验证集了,具体样例代码详见[7]。之后,我们还可以评估划分好的验证集跟测试集的分布状况,评估方法:将验证集和测试集做对抗验证,若AUC越小,说明划分出的验证集和测试集分布越接近(即分类器越分不清验证集和测试集)。

选择和测试集最相似的样本作为验证集
1.3 有权重的交叉验证
如果我们对训练集里分布更偏向于测试集分布的样本更大的样本权重,给与测试集分布不太一致的训练集样本更小权重,也能一定程度上,帮助我们线下得到不易抖动的评估分数。在lightgbm库的Dataset初始化参数中,便提供了样本加权的参数weight[1]。上图中对抗验证的分类器预测训练集的Is_Test概率作为权重即可。
2. 删除分布不一致特征
如果我们遇到分布不一致且不太重要的特征,我们可以选择直接删去这种特征。该方法在各大比赛中十分常见。例如: 在2018年蚂蚁金服风险大脑-支付风险识别比赛中,亚军团队根据特征在训练集和测试集上的表现,去除分布差异较大的特征,如图【2】

虽然个人建议的是删除分布不一致但不太重要的特征,但有时避免不了碰到分布不一致但又很重要的特征,这时候其实就需要自行trade off特征分布和特征重要性的关系了,比如在第四届工业大数据创新竞赛-注塑成型工艺的虚拟量测中,第5名团队保留了sensor1_mean特征而删除了pack_press_2特征,尽管他们发现pack_press_2从实际生产角度和相关性角度都非常重要,可为了提升模型在测试集的泛化能力和分数,他们没用pack_press_2特征,如图 (工业大数据之注塑成型虚拟量测Top5分享 - 公众号: Coggle数据科学)

3. 修正分布不一致的预测输出
除了对输入特征进行分布检查,我们也可以检查目标特征的分布,看是否存在可修正的空间。这种案例很少见,因为正常情况下,你看不到测试集的目标特征值。
在“AI Earth”人工智能创新挑战赛里,我们有提到官方提供两类数据集作为训练集,分别是CMIP模拟数据和SODA真实数据,然后测试集又是SODA真实数据,其中前排参赛者YueTan就将CMIP和SODA的目标特征分布画在一起,然后发现SODA的值更集中,且整体分布偏右一些,所以对用CMIP训练得到的预测值加了一个小的常数,修正CMIP下模型的预测输出,使得它分布更偏向于SODA分布

4. 伪标签
伪标签是半监督方法,利用未标注数据加入训练,我们先看看伪标签的思路,再讨论为什么它可能在一定程度上对分布不一致的数据集有帮助。伪标签最常见的方法是:
使用有标注的训练集训练模型M;
然后用模型M预测未标注的测试集;
选取测试集中预测置信度高的样本加入训练集中;
使用标注样本和高置信度的预测样本训练模型M';
预测测试集,输出预测结果。
TripleLift知乎主提供的入门版伪标签思路图如下所示,建议有兴趣的朋友阅读他原文[3],他还提供了进阶版和创新版的伪标签技术,值得借鉴学习。

由上图我们可以看到,模型的训练引入了部分测试集的样本,这样相当于引入了部分测试集的分布。但需要注意:
(1) 相比于前面的方法,伪标签通常没有表现的很好,因为它引入的是置信度高的测试集样本,这些样本很可能跟训练集分布接近一致,所以才会预测概率高。因此引入的测试集分布也没有很不同,所以使用时常发生过拟合的情况。
(2) 注意引入的是高置信度样本,如果引入低置信度样本,会带来很大的噪声。另外,高置信度样本也不建议选取过多加入训练集,这也是为了避免模型过拟合。
(3) 伪标签适用于图像领域更多些,表格型比赛建议最后没办法再考虑该方法
5. 半监督学习
半监督学习 是介于传统监督学习和无监督学习之间,其思想是通过在模型训练中直接引入无标记样本,以充分捕捉数据整体潜在分布,以改善如传统无监督学习过程盲目性、监督学习在训练样本不足导致的学习效果不佳的问题。
通过半监督学习,训练时候可以充分捕捉数据整体潜在分布,同理也可以缓解预测数据分布有差异的问题。
半监督分类常用的做法是,通过业务含义或者模型选择出一些虽然无标签的样本,并打上大概率的某个标签(伪标签)加入到训练数据中,验证待预测样本的效果有没有变好。
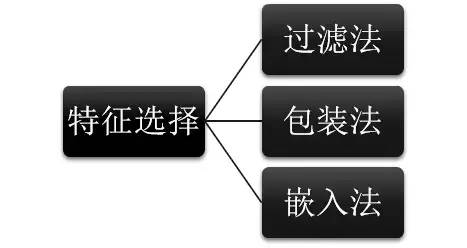
6. 特征选择
对于常见的协变量偏移,用特征选择是一个不错的方法。我们可以分析各个特征在分布稳定性(如PSI值)的情况,筛选掉分布差异比较大的特征。需要注意的是,这里适用的是筛掉特征重要性一般且稳定性差的特征。
参考资料
[1] lightgbm.Dataset(), 文档: https://lightgbm.readthedocs.io/en/latest/pythonapi/lightgbm.Dataset.html#lightgbm.Dataset
[2] 蚂蚁金服ATEC风险大脑-支付风险识别--TOP2方案 - 吊车尾学院-E哥, 文章: https://zhuanlan.zhihu.com/p/57347243?from_voters_page=true
[3] 伪标签(Pseudo-Labelling)——锋利的匕首 - TripleLift, 文章: https://zhuanlan.zhihu.com/p/157325083
希望大家点赞+收藏支持~
您的鼓励是我坚持下去的动力~🙏