NLP_class
学堂在线《自然语言处理》实验课代码+报告,授课老师为刘知远老师。课程链接:https://www.xuetangx.com/training/NLP080910033761/1017121?channel=i.area.manual_search。
持续更新中。
所有代码为作者所写,并非最后的“标准答案”,只有实验6被扣了1分,其余皆是满分。仓库链接:https://github.com/W-caner/NLP_classs。 此外,欢迎关注我的CSDN:https://github.com/W-caner/NLP_classs。
部分数据集由于过大无法上传,我会在博客中给出下载链接。如果对代码有疑问,有更好的思路等,也非常欢迎在评论区与我交流~
实验1: Word2Vec & TranE的实现
Word2Vec
基于给定的代码实现Word2Vec,在Text8语料库上进行训练,并在给定的WordSim353数据集上进行测试。
运行word2vec.py训练Word2Vec模型, 在WordSim353上衡量词向量的质量
模型的原始参数设定如下,默认5个周期,负采样为5,CBOW模型:
model = gensim.models.Word2Vec(sents,
size=200,
window=10,
min_count=10,
workers=multiprocessing.cpu_count())
运行原始模型,得到保存的模型和生成的词相关性评估。运行评估代码,结果如下图所示,score=0.6856。

探究Word2Vec中各个参数对模型的影响
编写函数脚本,利用for循环,控制变量进行单个调参。绘制至折线图(为了展示效果,时间按照max进行归一化)。
-
vector_size(词向量的维度):默认值是100。这个维度的取值一般与我们的语料的大小相关,如果是不大的语料,比如小于100M的文本语料,则使用默认值一般就可以了。如果是超大的语料,建议增大维度。
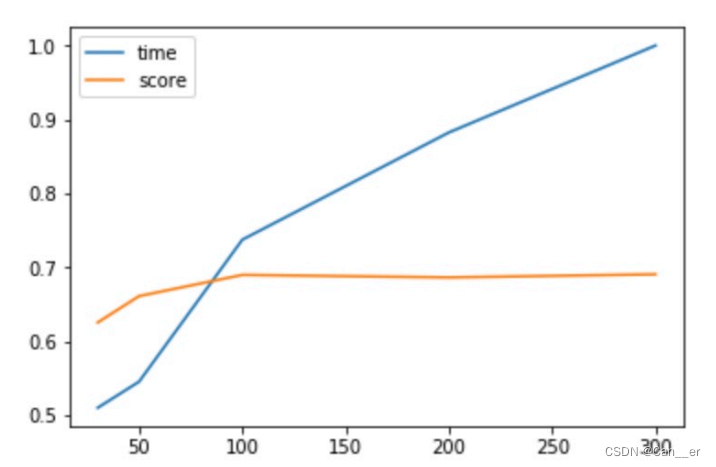
随着size的增大,训练时间和得分都不断增加,score在size为100之后没有明显变化,说明对于该语料库大小,100是足够的维度,为了使词表示的更为充分,最终选择200作为参数。
-
window(窗口大小):window越大,则和某一词较远的词也会产生上下文关系。默认值为5。在实际使用中,可以根据实际的需求来动态调整这个window的大小。如果是小语料则这个值可以设的更小。对于一般的语料这个值推荐在[5,10]之间。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1CmZ6MCw-1673422101479)(./_image/2022-08-30/75d28ee7f7643abaacf44a73b1f2a170.jpg?c=1)]](https://img-blog.csdnimg.cn/0299a05f48754955859ae112676472bc.png)
随着窗口的变大,训练时间和最终得分都不断变大,但是增大的幅度在10左右已经放缓,所以,选取15为窗口大小已经能够关注到较远的词。
-
min_count(最小计数):min_count是为了修剪内部的字典。在十亿单词语料库中,只出现一次或二次的单词可能是不感兴趣的拼写错误和垃圾。此外,这些单词也没有足够的数据来做任何有意义的训练。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-acoIkPih-1673422101479)(./_image/2022-08-30/c8cb0104399509e1885d489245b5e747.jpg?c=1)]](https://img-blog.csdnimg.cn/3ac575d479c54373b82e172b1ba34282.png)
随着最小计数的增大,词表中留下了更少的词汇,时间不断变短,而得分呈现先上升后下降的趋势,说明适当的筛去某些低频词汇有利于词嵌入的表现,而过多的筛去词汇则会导致表达的不完整,损失特征。
对Word2Vec模型进行改进
首先调整iter参数,使得模型得到充分训练,设置为10个周期,得到了更好的表现,score为0.719:

尝试skip-gram方法,没有明显改进,score为0.698:

对于消歧的概念,我读了参考文献中的论文,做了笔记(放到了同一个文件夹下),因为时间关系没有复现代码。
TranE
补全代码,完成训练
_calc():计算给定三元组的得分函数(score function)。norm_flag用于控制是否对向量进行正则化,以保证神经网络的稳定性,这里采用l2正则化,对最低维度(hidden_dim)进行归一化。score的返回值是一个二维narray,分别计算的是每一批次中正例和负例的得分,用于计算loss损失,维度变化见下代码。
def _calc(self, h, t, r):
# TO DO: implement score function
# Hint: you can use F.normalize and torch.norm functions
if self.norm_flag: # normalize embeddings with l2 norm
# dim: [2, batch_size, hidden_dim]
h = F.normalize(h, p=2, dim=2)
r = F.normalize(r, p=2, dim=2)
t = F.normalize(t, p=2, dim=2)
score = h + r - t
# dim: [2, batch_size]
return torch.norm(score, self.p_norm, dim=2)
loss():计算模型的损失函数(loss function),因为向量为一个批次大小正负样本的得分,所以在相减后需要计算平均值计算loss,margin作为控制负样本和正样本得分的最大间距,防止loss的负数情况梯度保证。如果超过该margin(损失小于0),则取0,所以这里使用relu函数即可。
def loss(self, pos_score, neg_score):
# TO DO: implement loss function
# Hint: consider margin
return torch.nn.ReLU()(self.margin + (pos_score - neg_score).mean())
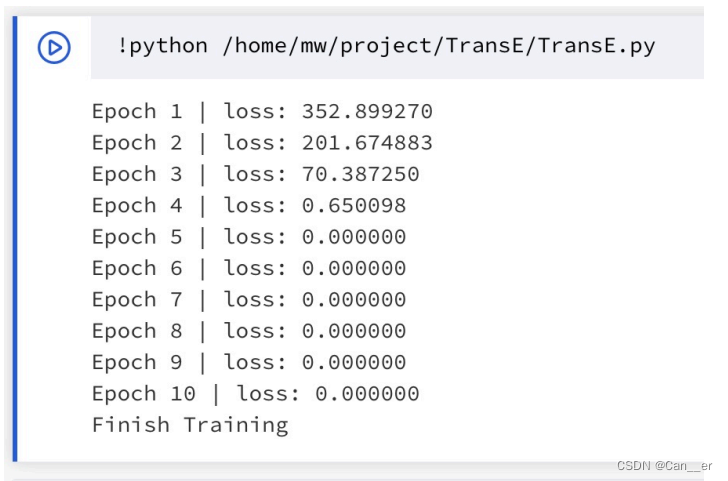
完成TransE的训练,得到实体和关系的向量表示,存储在entity2vec.txt和relation2vec.txt中。采用学习率衰减的方法,由0.1开始衰减,每次衰减为原来的0.95,收敛的很快,如下图所示,在第5个周期loss已经收敛至0。后面在实验的过程中发现**少周期大学习率,不如多周期小学习率,推测是负采样越多,碰到的相近词的概率越大,也越有区分能力。**所以收敛的过快并不一定是好的事情(存疑?),这里不再设置周期数,而是根据学习率和margin的不同进行自己停止,具体做法为设置了最大训练周期100,当在最大周期内,但loss已经无限接近于0的时候,停止训练。
结果分析
-
给定头实体Q30,关系P36,最接近的尾实体是哪些?
在 https://www.wikidata.org/wiki/Q30 和 https://www.wikidata.org/wiki/Property:P36 中查询,Q30为美国,P36为首都,可以推测出,较为合理的答案应该是美国的首都华盛顿,对应实体为Q61。经过对学习率和训练周期的调整,最终测试代码和结果如下所示:
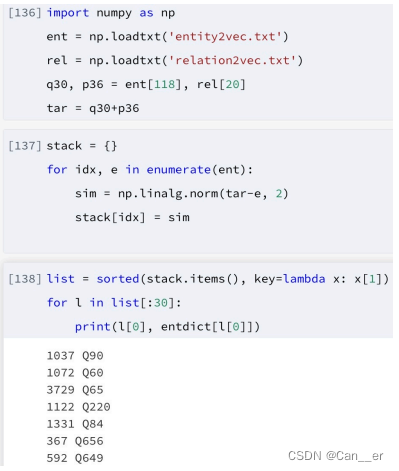
排名第一的是Q90,巴黎,这是法国的首都,推测可能是美国和法国有一定的相似度,训练结果又存在偏差。第二的是Q60纽约,我查询了训练集,发现确实有这个词,说明给定的关系中认为其是合理的,可能由于纽约比华盛顿与其他临近美国的词汇出现的频率高,所以学习的更快。第三是洛杉矶。后面是如伦敦等一些其他国家的首都。华盛顿排名第8,也较为合理。
-
给定头实体Q30,尾实体Q49,最接近的关系是哪些?
Q30为美国,Q49为北美洲,最接近的关系应该是19,P30,大洲。结果排在了第一位。

生成的其他词汇有如"family name","memeber of"等表示从属关系的词汇,还是比较合理的。
改变参数p_norm和margin,分析模型变化
- p_norm:对于l1而言是计算绝对值,而l2是计算平方,对同样的参数而言,l2相当于"扩大"了loss,在训练过程中,收敛的也更慢,需要配合较大的学习率和较小的margin,但是效果也更好,反映在指标上,除了hit10提高了约0.5个百分点,计算出的平均top1的相似度损失(使用的norm2计算)也降低了0.4。
- margin:margin相当于对正负例之间的距离规定,从小到大依次调整该参数,loss随着margin变大而变大。margin较小的时候(0~4),模型对于正负例的区分程度不高,会出现多个"模糊词义"都"不是很接近"的情况,此时相似度最高的往往是低频词汇(许多undifined实体),因为其没有明显的特征被学习到,更容易欠拟合。而margin较大时,为了使之快速收敛,选择较大学习率,此时,负例loss迅速变大,如果存在相近词意的负采样,很容易过拟合,并且loss训练至某个值后很难下降,因为margin规定的距离太大,难以保证每次采样都满足。