ConcurrentSkipListMap
ConcurrentSkipListMap与TreeMap对应,相当于线程安全的TreeMap,key有序,TreeMap基于红黑树,ConcurrentSkipListMap基于跳表。
无锁链表的问题
用跳表而不用红黑树是因为目前计算机领域还未找到一种高效的、作用在树上的、无锁的、增加和删除节点的办法。(Doug Lea原话)
一般的无锁队列、栈,都是只在队头、队尾进行CAS操作,通常不会有问题。如果在链表的中间进行插入或删除操作,按照通常的CAS做法,就会出现问题。
操作1:在节点10后面插入节点20。如下图所示,首先把节点20的next指针指向节点30,然后对节点10的next指针执行CAS操作,使其指向节点20。
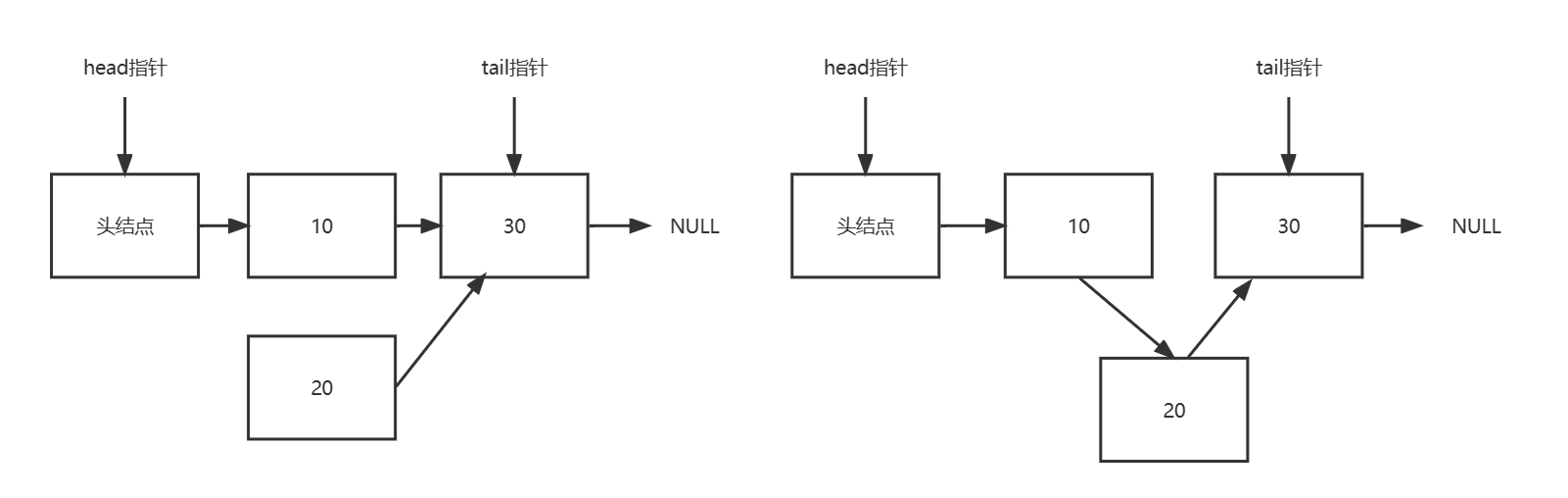
操作2:删除节点10。如下图所示,只需把头节点的next指针,进行CAS操作到节点30。
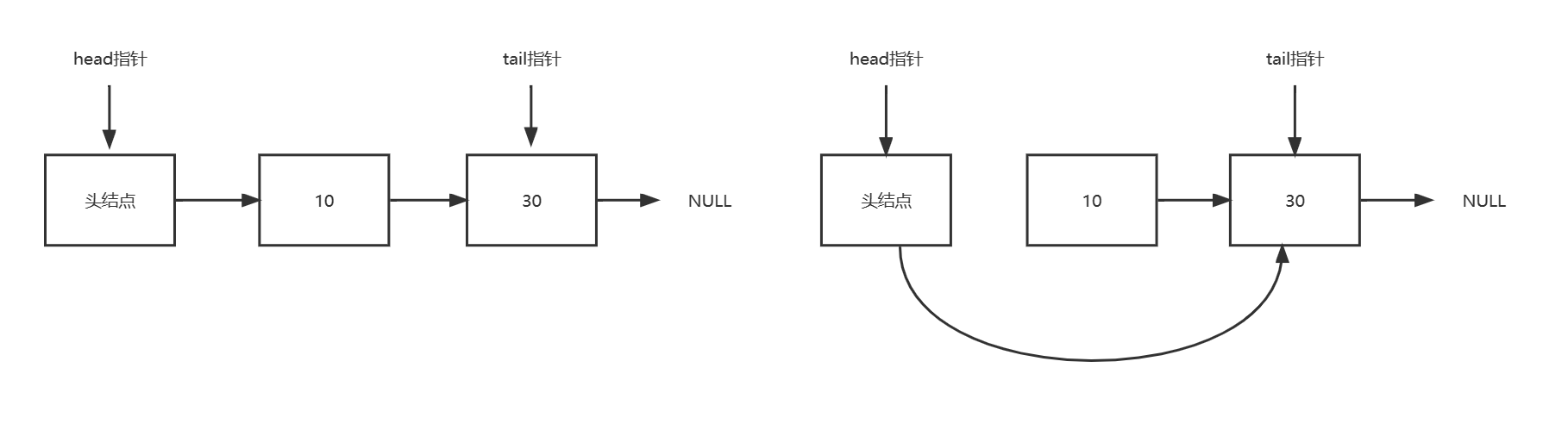
但是,如果两个线程同时操作, 一个删除节点10,一个要在节点10后面插入节点20。并且这两个操作都各自是CAS的,此时就会出现问题。删除节点10,可能会同时把新插入的节点20也删除掉。
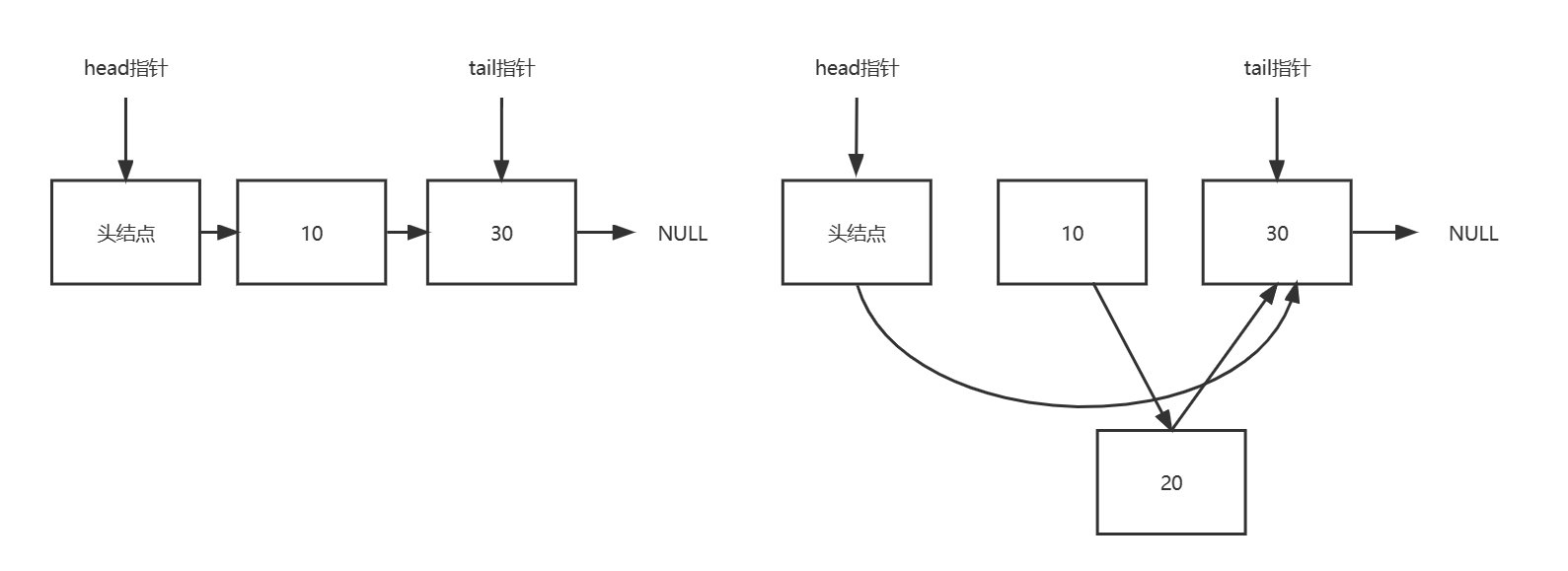
在删除节点10的时候,实际受到操作的是节点10的前驱,也就是头节点。节点10本身没有任何变化。所以往节点10后插入节点20的线程,并不知道节点10发生了什么(可能被删除)。
解决办法
第一步,把节点10的next指针,标记成删除,即软删除;
第二步,找机会,物理删除。
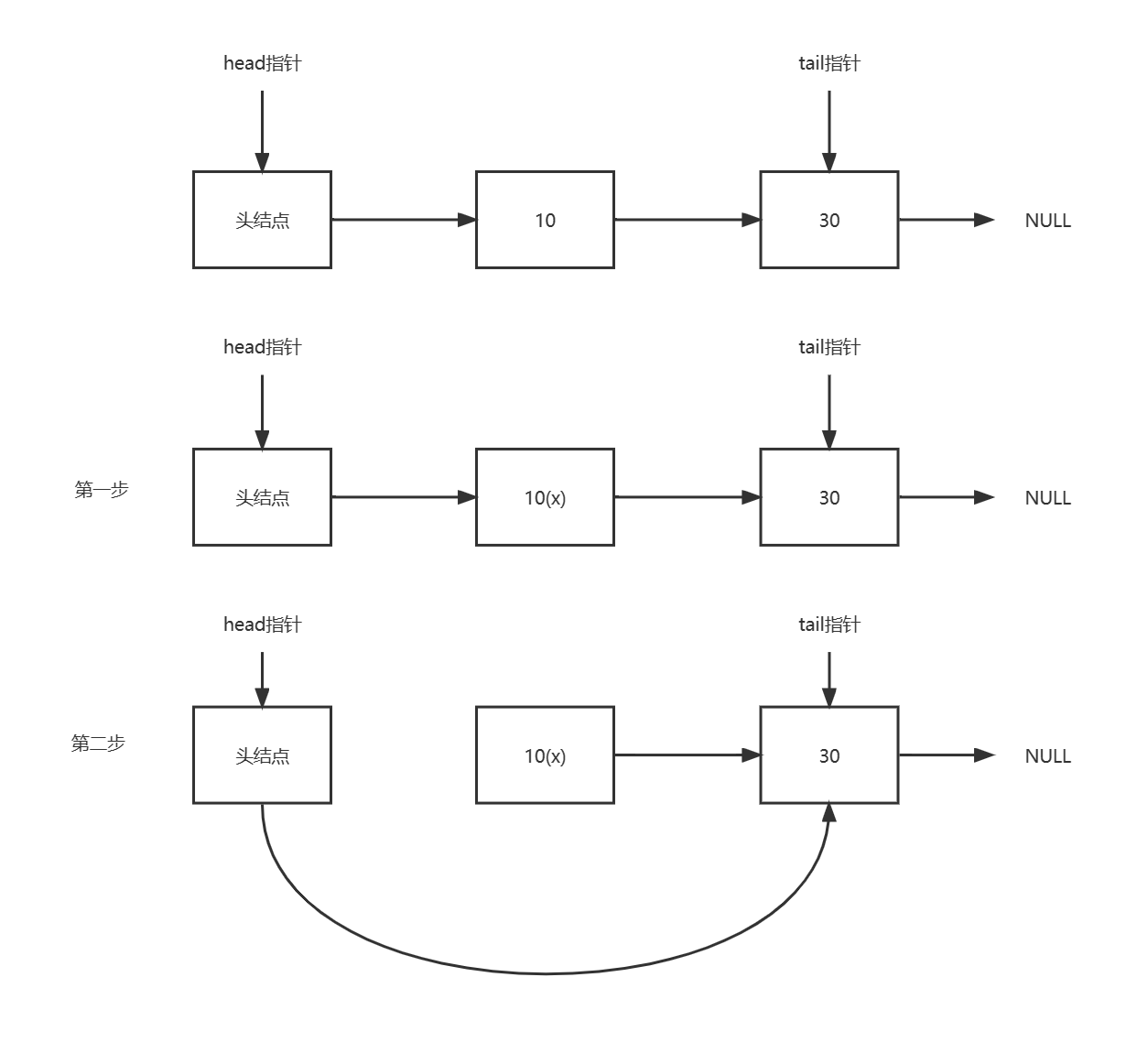
做标记之后,当线程再往节点10后面插入节点20的时候,便可以先进行判断,节点10是否已经被删除,从而避免在一个删除的节点10后面插入节点20。这个解决方法有一个关键点: “把节点10的next指针指向节点20(插入操作)”和“判断节点10本身是否已经删除(判断操作)”,必须是原子的,必须在1个CAS操作里面完成!
实现
Mark节点
记录标记节点10已经被删除,需要标记它的next字段。可以新造一个Marker节点,使节点10的next指针指向该Marker节点。这样,当向节点10的后面插入节点20的时候,就可以在插入的同时判断节点10的next指针是否执行了一个Marker节点,这两个操作可以在一个CAS操作里面完成。
跳表
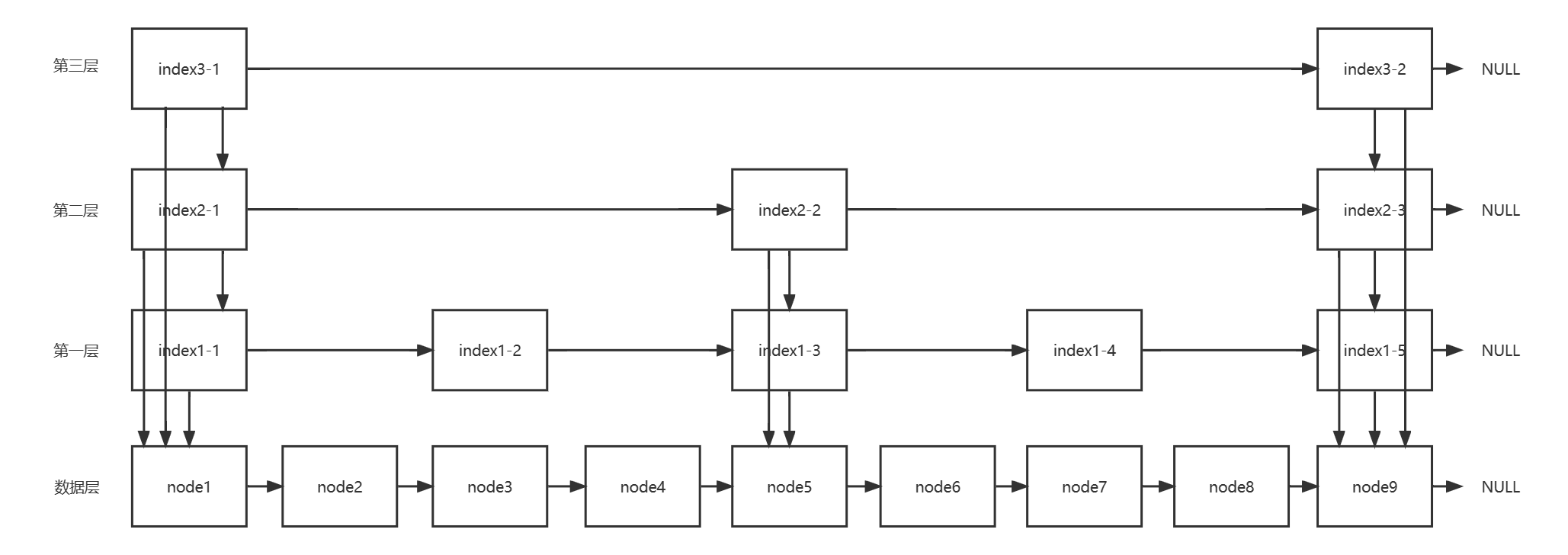
结构
由于跳表由多层链表叠起来构成,所以解决了无锁链表的插入或删除问题,也就解决了跳表的一个关键问题。
跳表底层的节点按照从小到大的顺序排列。
ConcurrentSkipListMap中跳表的部分结构源码如下
//底层Node节点,所有的数据节点都在此链表上
static final class Node<K,V> {
final K key;
volatile Object value;
//后继节点
volatile Node<K, V> next;
Node(K key, Object value, Node<K,V> next) {
this.key = key;
this.value = value;
this.next = next;
}
//删除清理逻辑,b,f分别是此节点的前驱,后继
void helpDelete(Node<K,V> b, Node<K,V> f) {
if (f == next && this == b.next) {
if (f == null || f.value != f) // 如果f是null或者没被标记,此节点后继设为marker节点
casNext(f, new Node<K,V>(f));
else //否则让b的后继为f
b.casNext(this, f.next);
}
}
}
//上层的索引节点
static class Index<K,V> {
//不存储数据,指向Node
final Node<K, V> node;
//每一个索引都有一个指针指向下一层对应的节点
final Index<K, V> down;
//索引的后继节点
volatile Index<K, V> right;
Index(Node<K,V> node, Index<K,V> down, Index<K,V> right) {
this.node = node;
this.down = down;
this.right = right;
}
//CAS操作,本节点的后继节点由cmp替换为val
final boolean casRight(Index<K,V> cmp, Index<K,V> val) {
return UNSAFE.compareAndSwapObject(this, rightOffset, cmp, val);
}
final boolean unlink(Index<K,V> succ) {
return node.value != null && casRight(succ, succ.right);
}
}
//index的头节点
static final class HeadIndex<K,V> extends Index<K,V> {
//第几层
final int level;
HeadIndex(Node<K,V> node, Index<K,V> down, Index<K,V> right, int level) {
super(node, down, right);
this.level = level;
}
}
//跳查表的最顶层节点,只需记住这一个节点
private transient volatile HeadIndex<K,V> head;查找前驱节点
//找到节点的前驱
private Node<K,V> findPredecessor(Object key, Comparator<? super K> cmp) {
if (key == null)
throw new NullPointerException();
for (;;) {
//head为最顶层HeadIndex节点
for (Index<K,V> q = head, r = q.right, d;;) {
if (r != null) {
//取当前索引指向的数据节点
Node<K,V> n = r.node;
K k = n.key;
//如果r指向的数据节点的值为null
if (n.value == null) {
if (!q.unlink(r)) // CAS移除索引节点r,如果失败则重新循环
break;
r = q.right;// CAS成功则重新读取r
continue;
}
//比较大小,如果给定的key比当前索引指向的数据节点的key大,q和r都往后移动一位
if (cpr(cmp, key, k) > 0) {
q = r;
r = r.right;
continue;
}
}
//如果q是第一层索引,返回q指向的数据节点
if ((d = q.down) == null)
return q.node;
//向下移动一层
q = d;
r = d.right;
}
}
}
static final int cpr(Comparator c, Object x, Object y) {
return (c != null) ? c.compare(x, y) : ((Comparable)x).compareTo(y);
}
get方法
public V get(Object key) {
return doGet(key);
}
private V doGet(Object key) {
if (key == null)
throw new NullPointerException();
Comparator<? super K> cmp = comparator;
outer: for (;;) {
//先找到前驱结点
for (Node<K,V> b = findPredecessor(key, cmp), n = b.next;;) {
Object v; int c;
if (n == null)
break outer;
Node<K,V> f = n.next;
if (n != b.next) // 不一致读,重新循环
break;
if ((v = n.value) == null) { // 如果n的值为null,相当于被删除,执行协助删除方法
n.helpDelete(b, f);
break;
}
if (b.value == null || v == n) // 如果b被删除了,重新循环
break;
if ((c = cpr(cmp, key, n.key)) == 0) { //找到了,返回
@SuppressWarnings("unchecked") V vv = (V)v;
return vv;
}
if (c < 0) //没找到,跳出循环返回null
break outer;
//b和n后移一位,继续查找
b = n;
n = f;
}
}
return null;
}put方法
public V put(K key, V value) {
if (value == null)
throw new NullPointerException();
return doPut(key, value, false);
}
private V doPut(K key, V value, boolean onlyIfAbsent) {
Node<K,V> z; // 要添加的节点
if (key == null)
throw new NullPointerException();
Comparator<? super K> cmp = comparator;
outer: for (;;) {
// 首先找到小于key的前驱结点b,n作为key的后继节点
for (Node<K,V> b = findPredecessor(key, cmp), n = b.next;;) {
if (n != null) {
Object v; int c;
Node<K,V> f = n.next;
if (n != b.next) // 不一致读则重新外层循环
break;
if ((v = n.value) == null) { // 如果n被删除了,执行协助删除方法
n.helpDelete(b, f);
break;
}
if (b.value == null || v == n) // 如果b被删除了,则重新开始外层循环
break;
if ((c = cpr(cmp, key, n.key)) > 0) {//待插入的key大于n节点的key,则把b和n向后移动一位
b = n;
n = f;
continue;
}
if (c == 0) {//如果key对应的节点存在,直接CAS操作修改value
if (onlyIfAbsent || n.casValue(v, value)) {
@SuppressWarnings("unchecked") V vv = (V)v;
return vv;
}
break; // 如果CAS失败则重新外层循环
}
// else c < 0; 给定key小于n的key则插入失败
}
z = new Node<K,V>(key, value, n);
if (!b.casNext(n, z))// 将b的后继由n换成z,如果CAS失败则重新外层循环
break;
//成功插入后结束外层死循环
break outer;
}
}
//成功插入不存在的node会走到这里,判断是否需要给新插入的节点增加索引
int rnd = ThreadLocalRandom.nextSecondarySeed();
if ((rnd & 0x80000001) == 0) {
int level = 1, max;
while (((rnd >>>= 1) & 1) != 0)
++level;
Index<K,V> idx = null;
HeadIndex<K,V> h = head;
if (level <= (max = h.level)) {
for (int i = 1; i <= level; ++i)
idx = new Index<K,V>(z, idx, null);
}
else {
level = max + 1;
@SuppressWarnings("unchecked") Index<K,V>[] idxs =
(Index<K,V>[])new Index<?,?>[level+1];
for (int i = 1; i <= level; ++i)
idxs[i] = idx = new Index<K,V>(z, idx, null);
for (;;) {
h = head;
int oldLevel = h.level;
if (level <= oldLevel)
break;
HeadIndex<K,V> newh = h;
Node<K,V> oldbase = h.node;
for (int j = oldLevel+1; j <= level; ++j)
newh = new HeadIndex<K,V>(oldbase, newh, idxs[j], j);
if (casHead(h, newh)) {
h = newh;
idx = idxs[level = oldLevel];
break;
}
}
}
splice: for (int insertionLevel = level;;) {
int j = h.level;
for (Index<K,V> q = h, r = q.right, t = idx;;) {
if (q == null || t == null)
break splice;
if (r != null) {
Node<K,V> n = r.node;
int c = cpr(cmp, key, n.key);
if (n.value == null) {
if (!q.unlink(r))
break;
r = q.right;
continue;
}
if (c > 0) {
q = r;
r = r.right;
continue;
}
}
if (j == insertionLevel) {
if (!q.link(r, t))
break; // restart
if (t.node.value == null) {
findNode(key);
break splice;
}
if (--insertionLevel == 0)
break splice;
}
if (--j >= insertionLevel && j < level)
t = t.down;
q = q.down;
r = q.right;
}
}
}
return null;
}remove方法
public V remove(Object key) {
return doRemove(key, null);
}
final V doRemove(Object key, Object value) {
if (key == null)
throw new NullPointerException();
Comparator<? super K> cmp = comparator;
outer: for (;;) {
// 首先找到小于key的前驱结点b
for (Node<K,V> b = findPredecessor(key, cmp), n = b.next;;) {
Object v; int c;
if (n == null)
break outer;
// 待删除节点的后继节点
Node<K,V> f = n.next;
if (n != b.next) // 不一致读重新循环
break;
if ((v = n.value) == null) { // 如果n被删除了,执行协助删除方法
n.helpDelete(b, f);
break;
}
if (b.value == null || v == n) // 如果b被删除了,则重新循环
break;
if ((c = cpr(cmp, key, n.key)) < 0) //如果 key比n的key小,说明没找到key,则跳出死循环返回null
break outer;
if (c > 0) { //如果key比n的key大,b和n都向后移动一位
b = n;
n = f;
continue;
}
if (value != null && !value.equals(v)) //如果key匹配了,但是值没有匹配,则也视为未找到,跳出循环返回null
break outer;
if (!n.casValue(v, null)) //删除的元素为n,先将值置为null,然后执行相关删除逻辑
break;
if (!n.appendMarker(f) || !b.casNext(n, f))//在n的后面加上Marker节点
findNode(key);
else {
findPredecessor(key, cmp); // 清除索引,如果head索引的后继为null,则降低索引层数
if (head.right == null)
tryReduceLevel();
}
//返回删除的元素
@SuppressWarnings("unchecked") V vv = (V)v;
return vv;
}
}
return null;
}ConcurrentSkipListSet
内部实际上引用了ConcurrentSkipListMap,map的key存储Set元素的值,value无意义,几乎所有方法都委托给ConcurrentSkipListMap执行。