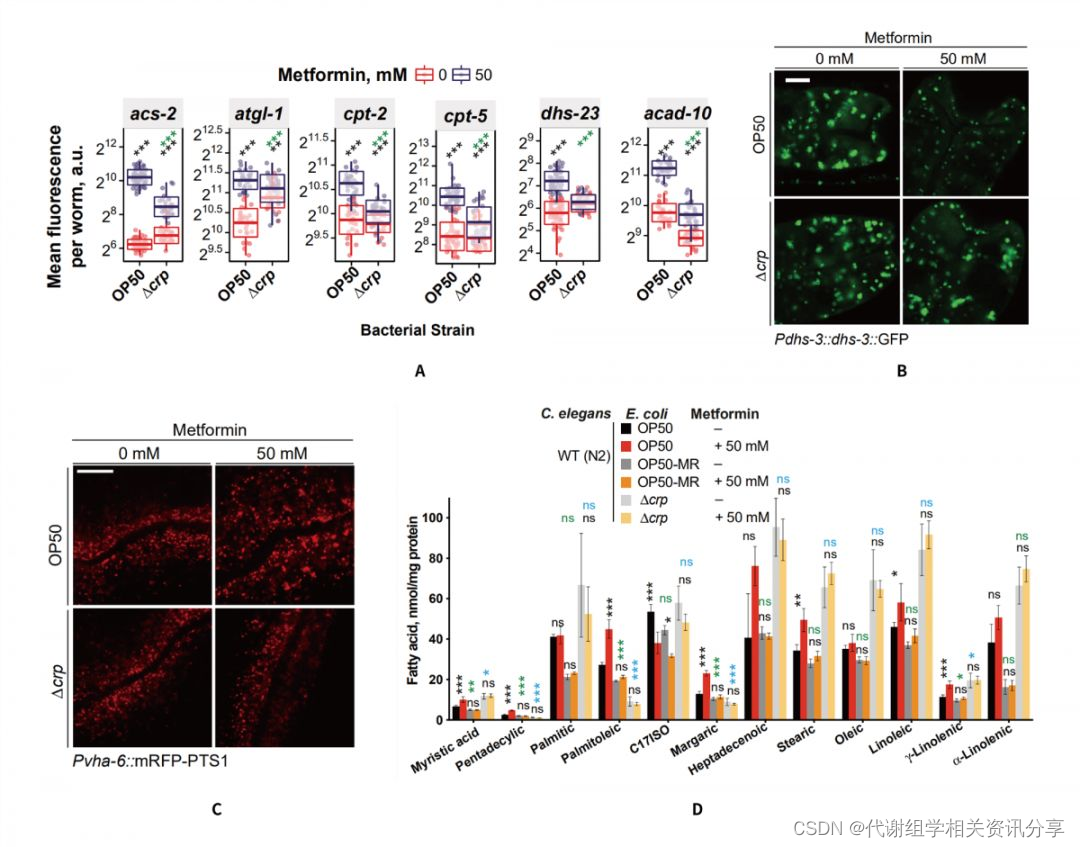
使用Optuna进行机器学习模型调参
- Optuna简介
- 框架特点
- 安装方式
- 举个例子
- 高级配置
- 搜索方式
- 分支(Branches)与循环(Loops)
- 分布式优化
- 命令行界面
- 用户定义属性
- 将用户定义属性添加到Study
- 将用户属性添加到Trial中
- 对无望的Trial进行剪枝(Pruning)
- 开启Pruner
- 用于Pruning的集成模块
- 用户定义的采样器(Sampler)
- Sampler概述
- 案例,实现模拟退火Sampler(SimulatedAnnealingSampler)
- 使用Optuna对LGBM进行调参
- 定义Objective
- 调参try
- 绘图
- 优化历史
- 并行化参数选择
- 重要性参数
- 使用Optuna对XGBoost进行调参
- 定义Objective
- 调参try
- 绘图
- 参考资料
- 参考资料
Optuna简介
Optuna 是一个使用Python编写的开源的超参数优化框架,它可以自动为机器学习模型找到最佳超参数。最基本的(也可能是众所周知的)替代方案是 sklearn 的 GridSearchCV,它将尝试多种超参数组合并根据交叉验证选择最佳组合。
- GridSearchCV 将在先前定义的空间内尝试组合。例如,对于随机森林分类器,可能想要测试几个不同的树的最大深度。GridSearchCV 会提供每个超参数的所有可能值,并查看所有组合。
- Optuna会在定义的搜索空间中使用自己尝试的历史来确定接下来要尝试的值。它使用的方法是一种称为“
Tree-structured Parzen Estimator”的贝叶斯优化算法。
PS: Optuna是一种为自动和加速研究而设计的框架。
这种不同的方法意味着它不是无意义的地尝试每一个值,而是在尝试之前寻找最佳候选者,这样可以节省时间,否则这些时间会花在尝试没有希望的替代品上(并且可能也会产生更好的结果)。
一个极简的Optuna的优化程序只有三个最核心的概念,目标函数(objective),单次实验(trial)和研究(study),其中objective负责定义待优化函数并指定参数/超参数的范围,trial对应着objective的单次执行,study则负责管理优化,决定优化的方式,总实验的次数、实验结果的记录等功能。
最后,它与框架无关,这意味着可以将它与TensorFlow、Keras、PyTorch 或任何其他 ML 框架一起使用。
框架特点
- 小巧轻量,通用且与平台无关
- Python形式的超参数空间搜索
- 高效的优化算法
- 写法简单,可以并行
- 快速可视化
安装方式
(1)PyPI
$ pip install optuna
(2)Anaconda
$ conda install -c conda-forge optuna
举个例子
定义 x , y ∈ ( − 10 , 10 ) x,y\in (-10, 10) x,y∈(−10,10),求 f ( x ) = ( x + y ) 2 f(x)=(x+y)^2 f(x)=(x+y)2取得最大值时,x,y的取值?
import optuna
def objective(trial):
x = trial.suggest_uniform('x', -10, 10)
y = trial.suggest_uniform('y', -10, 10)
return (x + y) **2
study = optuna.create_study(direction='maximize')
study.optimize(objective, n_trials=100)
print(study.best_params)
print(study.best_value)
执行结果:
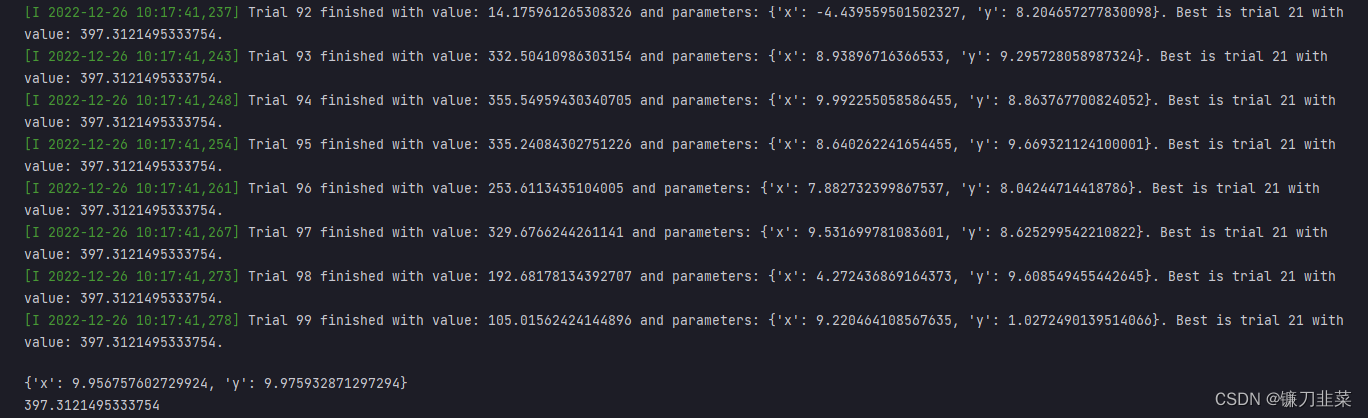
获得最佳trial:
print(study.best_trial)
FrozenTrial(number=21, values=[397.3121495333754], datetime_start=datetime.datetime(2022, 12, 26, 10, 17, 40, 813392), datetime_complete=datetime.datetime(2022, 12, 26, 10, 17, 40, 818404), params={'x': 9.956757602729924, 'y': 9.975932871297294}, distributions={'x': FloatDistribution(high=10.0, log=False, low=-10.0, step=None), 'y': FloatDistribution(high=10.0, log=False, low=-10.0, step=None)}, user_attrs={}, system_attrs={}, intermediate_values={}, trial_id=21, state=TrialState.COMPLETE, value=None)
获得所有 trials:
print(study.trials)
获得trials的数目:
len(study.trials)
(在优化结束后)通过再次执行 optimize(),我们可以继续优化过程。
study.optimize(objective, n_trials=100)
Optuna Dashboard是Optuna的实时web仪表板。可以在图表中检查优化历史、超参数重要性等。
% pip install optuna-dashboard
% optuna-dashboard sqlite:///db.sqlite3
高级配置
搜索方式
optuna根据需要,支持多种不同的搜索方式(含有low和high值的都是左闭右开):
def objective(trial):
# Categorical parameter
optimizer = trial.suggest_categorical('optimizer', ['MomentumSGD', 'Adam']) # 选择型搜索方式
# Int parameter
num_layers = trial.suggest_int('num_layers', 1, 3) # 整数型搜索方式
# Uniform parameter
dropout_rate = trial.suggest_uniform('dropout_rate', 0.0, 1.0) # 连续均匀采样搜索方式
# Loguniform parameter
learning_rate = trial.suggest_loguniform('learning_rate', 1e-5, 1e-2) # 对数均匀采样方式
# Discrete-uniform parameter
drop_path_rate = trial.suggest_discrete_uniform('drop_path_rate', 0.0, 1.0, 0.1) # 离散均匀采样方式
...
除此之外,对于trail.suggest_uniform,trail.suggest_loguniform以及trail.suggest_discrete_uniform三种形式,optuna提供了一个统一封装形式(详情见OPTUNA/optuna/trail/_trail.py) def suggest_float(self,name,low,high,*,step,log)->float.
分支(Branches)与循环(Loops)
根据不同的参数,选择使用分支或者循环
def objective(trial):
classifier_name = trial.suggest_categorical('classifier', ['SVC', 'RandomForest'])
if classifier_name == 'SVC':
svc_c = trial.suggest_loguniform('svc_c', 1e-10, 1e10)
classifier_obj = sklearn.svm.SVC(C=svc_c)
else:
rf_max_depth = int(trial.suggest_loguniform('rf_max_depth', 2, 32))
classifier_obj = sklearn.ensemble.RandomForestClassifier(max_depth=rf_max_depth)
...
def create_model(trial):
n_layers = trial.suggest_int('n_layers', 1, 3)
layers = []
for i in range(n_layers):
n_units = int(trial.suggest_loguniform('n_units_l{}'.format(i), 4, 128))
layers.append(L.Linear(None, n_units))
layers.append(F.relu)
layers.append(L.Linear(None, 10))
return chainer.Sequential(*layers)
注意:随着参数个数的增长,优化的难度约成指数增长。也就是说,当你增加参数的个数的时候,优化所需要的 trial 个数会呈指数增长。因此我们推荐不要增加不必要的参数。
分布式优化
Optuna的分布式优化只需要让不同的节点/进程共享一个相同的study名。
- 首先,使用
optuna create-study命令(如果是在Python脚本中的话,就用optuna.create_study())创建一个共享的study。
$ optuna create-study --study-name "distributed-example" --storage "sqlite:///example.db"
[I 2018-10-31 18:21:57,885] A new study created with name: distributed-example
- 然后写一个包含如下代码的脚本,foo.py,来进行优化。
import optuna
def objective(trial):
x = trial.suggest_uniform('x', -10, 10)
return (x - 2) ** 2
if __name__ == '__main__':
study = optuna.load_study(study_name='distributed-example', storage='sqlite:///example.db')
study.optimize(objective, n_trials=100)
- 最后,从不同的进程中分别运行这个share study。比如说,在一个终端中运行Process 1,在另一个终端中运行Process 2。这些进程基于这个共享study的trial历史记录来获取参数建议(parameter suggrestion)
进程1:
$ python foo.py
[I 2018-10-31 18:46:44,308] Finished a trial resulted in value: 1.1097007755908204. Current best value is 0.00020881104123229936 with parameters: {'x': 2.014450295541348}.
[I 2018-10-31 18:46:44,361] Finished a trial resulted in value: 0.5186699439824186. Current best value is 0.00020881104123229936 with parameters: {'x': 2.014450295541348}.
......
进程2(使用和进程 1 相同的命令):
$ python foo.py
[I 2018-10-31 18:47:02,912] Finished a trial resulted in value: 29.821448668796563. Current best value is 0.00020881104123229936 with parameters: {'x': 2.014450295541348}.
[I 2018-10-31 18:47:02,968] Finished a trial resulted in value: 0.7962498978463782. Current best value is 0.00020881104123229936 with parameters: {'x': 2.014450295541348}.
...
注意:
- 不推荐在大型的分布式优化中使用 SQLite,因为这可能导致性能问题。在这种情况下,请考虑使用其他数据库,比如 PostgreSQL 或 MySQL.
- 在运行分布式优化时,不要将 SQLite 数据库文件放在 NFS (Network File System) 文件系统中。具体原因见 : https://www.sqlite.org/faq.html#q5
命令行界面
| 命令 | 功能描述 |
|---|---|
| create-study | 创建一个新的study |
| delete-study | 删除所给的 study |
| dashboard | 启动 web 面板 (beta) |
| storage upgrade | 升级数据库 schema |
| studies | 输出study列表 |
| study optimize | 针对一个study开始优化过程 |
| study set-user-attr | 设置study的用户属性 |
Optuna提供的命令行界面包括上表中的所有命令。
示例(Python脚本文件):
import optuna
def objective(trial):
x = trial.suggest_uniform('x', -10, 10)
return (x - 2) ** 2
if __name__ == '__main__':
study = optuna.create_study()
study.optimize(objective, n_trials=100)
print('Best value: {} (params: {})\n'.format(study.best_value, study.best_params))
然后,通过optuna命令,可以少些一些上面的模板代码。假设有一个foo.py文件,它只包含如下代码:
def objective(trial):
x = trial.suggest_uniform('x', -10, 10)
return (x - 2) ** 2
即使在这种情况下,我们也可以利用如下命令启动优化过程:
$ cat foo.py
def objective(trial):
x = trial.suggest_uniform('x', -10, 10)
return (x - 2) ** 2
$ STUDY_NAME=`optuna create-study --storage sqlite:///example.db`
$ optuna study optimize foo.py objective --n-trials=100 --storage sqlite:///example.db --study-name $STUDY_NAME
[I 2018-05-09 10:40:25,196] Finished a trial resulted in value: 54.353767789264026. Current best value is 54.353767789264026 with parameters: {'x': -5.372500782588228}.
[I 2018-05-09 10:40:25,197] Finished a trial resulted in value: 15.784266965526376. Current best value is 15.784266965526376 with parameters: {'x': 5.972941852774387}.
...
[I 2018-05-09 10:40:26,204] Finished a trial resulted in value: 14.704254135013741. Current best value is 2.280758099793617e-06 with parameters: {'x': 1.9984897821018828}.
注意:foo.py中只包含目标函数的定义。通过向optuna study optimize命令传递该文件名和对应目标函数的方法名,就可以启动优化过程。
用户定义属性
将用户定义属性添加到Study
Study对象提供了一个将键值对设置为用户自定义属性的方法:set_user_attr()。这里的键应该属于str类型,而值可以是任何能用json.dumps来序列化的对象。
import optuna
study = optuna.create_study(storage='sqlite:///example.db')
study.set_user_attr('contributors', ['Akiba','Sano'])
study.set_user_attr('dataset', 'MNIST')
可以利用user_attr属性来获取所有定义过的属性。
study.user_attrs # {'contributors': ['Akiba', 'Sano'], 'dataset': 'MNIST'}
StudySummary对象中也包含了用户的自定义属性。可以从get_all_study_summaries()中获取它。
study_summaries = optuna.get_all_study_summaries('sqlite:///example.db')
study_summaries[0].user_attrs # {'contributors': ['Akiba', 'Sano'], 'dataset': 'MNIST'}
注意:在命令行界面里,optuna study set-user-attr 可用于设置用户定义属性。
将用户属性添加到Trial中
和Study类似,Trial对象也提供了一个设置属性的方法set_user_attr()方法。这些属性是在目标函数内部设置的。
def objective(trial):
iris = sklearn.datasets.load_iris()
x, y = iris.data, iris.target
svc_c = trial.suggest_loguniform('svc_c', 1e-10, 1e10)
clf = sklearn.svm.SVC(C=svc_c)
accuracy = sklearn.model_selection.cross_val_score(clf, x, y).mean()
trial.set_user_attr('accuracy', accuracy)
return 1.0 - accuracy # return error for minimization
可以用如下方式获取这些注解的属性:
study.trials[0].user_attrs # {'accuracy': 0.83}
注意,在本例中,属性不是被注解到Study的,它属于一个单独的Trial.
对无望的Trial进行剪枝(Pruning)
该功能可以在训练的早期阶段自动终止无望的Trial (a.k.a., 自动化 early-stopping)。 Optuna 提供了一些接口,可以用于在迭代训练算法中简洁地实现剪枝 (Pruning)。
开启Pruner
为了打开Pruning功能,需要在迭代式训练的每一步完成后调用函数report()和should_prune():
- report()定期监测这个过程中的目标函数值。
- should_prune()根据提前定义好的条件,判定该trial是否需要终止。
"""filename: prune.py"""
import sklearn.datasets
import sklearn.linear_model
import sklearn.model_selection
import optuna
def objective(trial):
iris = sklearn.datasets.load_iris()
classes = list(set(iris.target))
train_x, valid_x, train_y, valid_y = \
sklearn.model_selection.train_test_split(iris.data, iris.target, test_size=0.25, random_state=0)
alpha = trial.suggest_float('alpha', 0.00001, 0.001, log=True)
clf = sklearn.linear_model.SGDClassifier(alpha=alpha)
for step in range(100):
clf.partial_fit(train_x, train_y, classes=classes)
# Report intermediate objective value.
intermediate_value = 1.0 - clf.score(valid_x, valid_y)
trial.report(intermediate_value, step)
# Handle pruning based on the intermediate value.
if trial.should_prune():
raise optuna.TrialPruned()
return 1.0 - clf.score(valid_x, valid_y)
# Set up the median stopping rule as the pruning condition.
study = optuna.create_study(pruner=optuna.pruners.MedianPruner())
study.optimize(objective, n_trials=20)
运行结果:
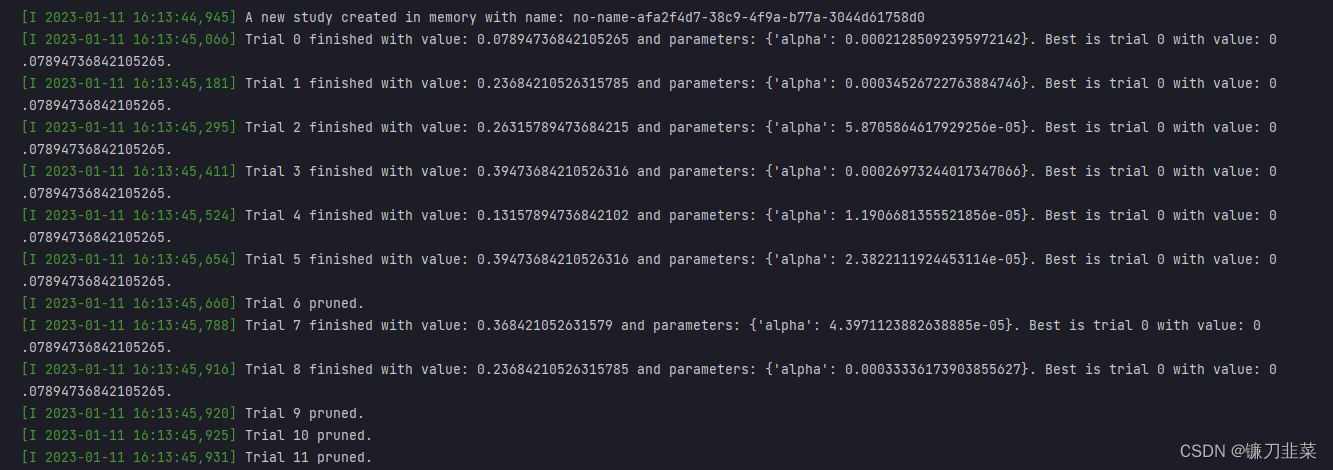
可以在输出信息中看到Setting status of trial#{} as TrialState.PRUNED.这意味着这些 trial 在他们完成迭代之前就被终止了。
用于Pruning的集成模块
为了能更加方便地实现 pruning, Optuna 为以下框架提供了集成模块。
XGBoost: optuna.integration.XGBoostPruningCallbackLightGBM: optuna.integration.LightGBMPruningCallbackChainer: optuna.integration.ChainerPruningExtensionKeras: optuna.integration.KerasPruningCallbackTensorFlowoptuna.integration.TensorFlowPruningHooktf.kerasoptuna.integration.TFKerasPruningCallbackMXNetoptuna.integration.MXNetPruningCallbackPyTorchIgnite optuna.integration.PyTorchIgnitePruningHandlerPyTorchLightning optuna.integration.PyTorchLightningPruningCallbackFastAIoptuna.integration.FastAIPruningCallback
例如,XGBoostPruningCallback在无需修改训练迭代逻辑的情况下引入了pruning。
pruning_callback = optuna.integration.XGBoostPruningCallback(trial, 'validation-error')
bst = xgb.train(param, dtrain, evals=[(dvalid, 'validation')], callbacks=[pruning_callback])
用户定义的采样器(Sampler)
可以使用用户定义的sample来实现:
- 试验自己的采样算法
- 实现具体任务对应的算法来改进优化性能,或者
- 将其他的优化框架包装起来,整合进Optuna的流水线中
Sampler概述
Sampler负责产生要被用在trial中求值的参数值。在目标函数内,当一个suggest API(比如 suggest_uniform)被调用时,一个对应的分布对象(比如UniformDistribution)就会从内部被创建。Sampler则从该分布汇总采样一个参数值。该采样值会被返回给suggest API的调用者,进而在目标函数内被求值。
为了创建一个新的sample,自己所定义的类需要继承BaseSampler。该基类提供三个抽象方法:infer_relative_search_space(), sample_relative(), sample_independent()。
从这些方法名可以看出,Optuna支持两种类型的采样过程:一种是relative sampling,它考虑了单个trial内参数之间的相关性,另一种是independent sampling,它对各个参数的采样是彼此独立的。
在一个trial刚开始时,infer_relative_search_space()会被调用,它向该trial提供一个相对搜索空间。之后,sample_relative()会被触发,它从该搜索空间中对相对参数进行采样。在目标函数的执行过程中,sample_independent()用于对不属于该相对搜索空间的参数进行采样。
案例,实现模拟退火Sampler(SimulatedAnnealingSampler)
下面的代码根据Simulated Annealing (SA)定义类一个sampler:
def objective(trial):
x = trial.suggest_uniform('x', -10, 10)
y = trial.suggest_uniform('y', -5, 5)
return x**2 + y
sampler = SimulatedAnnealingSampler()
study = optuna.create_study(sampler=sampler)
study.optimize(objective, n_trials=100)
在上面这个优化过程中,参数 x 和 y 的值都是由 SimulatedAnnealingSampler.sample_relative 方法采样得出的。
注意:严格意义上说,在第一个 trial 中,SimulatedAnnealingSampler.sample_independent 用于采样参数值。因为,如果没有已经完成的 trial 的话, SimulatedAnnealingSampler.infer_relative_search_space 中的 intersection_search_space() 是无法对搜索空间进行推断的。
使用Optuna对LGBM进行调参
定义Objective
import optuna
from lightgbm import LGBMRegressor
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
from sklearn import datasets
wine = datasets.load_wine()
data = wine.data
target = wine.target
def objective(trial):
X_train, X_test, y_train, y_test = train_test_split(data, target, train_size=0.3)
param = {
'metric': 'rmse',
'random_state': 48,
'n_estimators': 20000,
'reg_alpha': trial.suggest_loguniform('reg_alpha', 1e-3, 10.0),
'reg_lambda': trial.suggest_loguniform('reg_lambda', 1e-3, 10.0),
'colsample_bytree': trial.suggest_categorical('colsample_bytree', [0.3,0.4,0.5,0.6,0.7,0.8,0.9, 1.0]),
'subsample': trial.suggest_categorical('subsample', [0.4,0.5,0.6,0.7,0.8,1.0]),
'learning_rate': trial.suggest_categorical('learning_rate', [0.006,0.008,0.01,0.014,0.017,0.02]),
'max_depth': trial.suggest_categorical('max_depth', [5, 7, 9, 11, 13, 15, 17, 20, 50]),
'num_leaves' : trial.suggest_int('num_leaves', 1, 1000),
'min_child_samples': trial.suggest_int('min_child_samples', 1, 300),
'cat_smooth' : trial.suggest_int('cat_smooth', 1, 100)
}
lgb = LGBMRegressor(**param)
lgb.fit(X_train, y_train, eval_set=[(X_test, y_test)], early_stopping_rounds=100, verbose=False)
pred_lgb = lgb.predict(X_test)
rmse = mean_squared_error(y_test, pred_lgb, squared=False)
return rmse
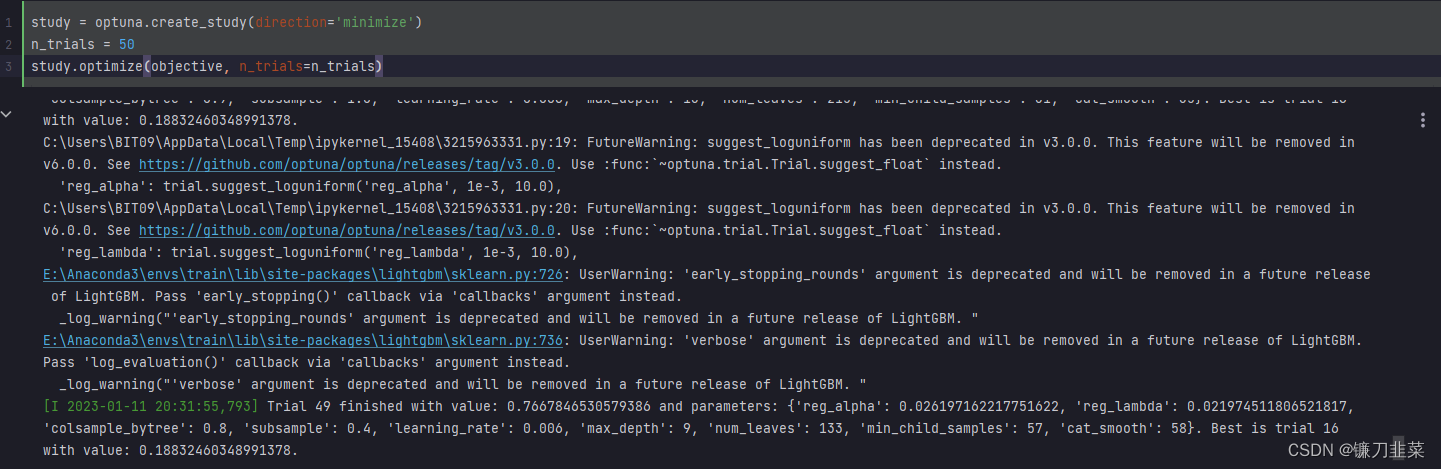
调参try
绘图
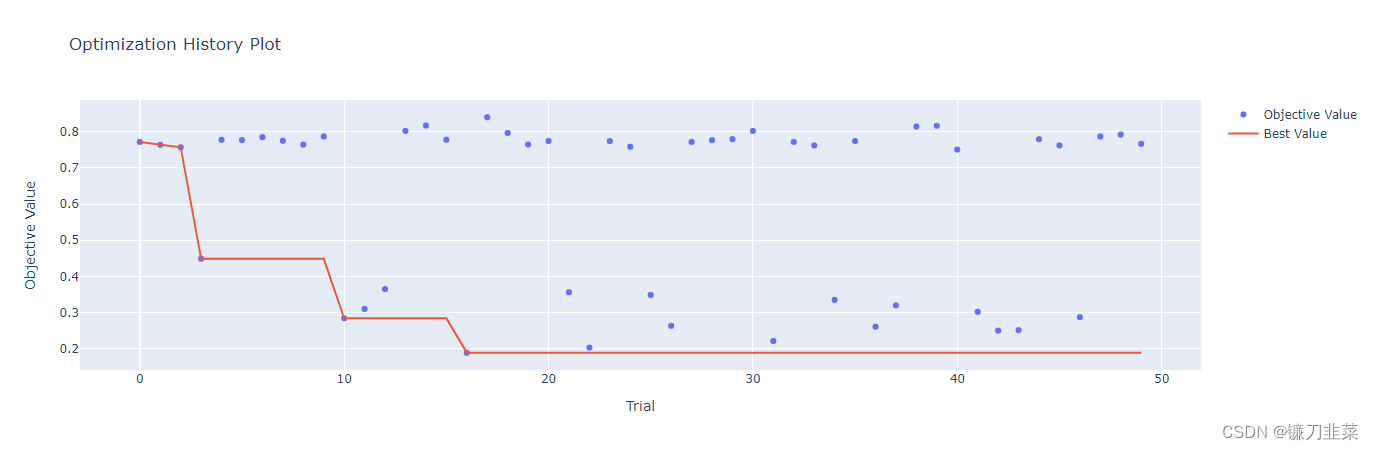
优化历史
optuna.visualization.plot_optimization_history(study)
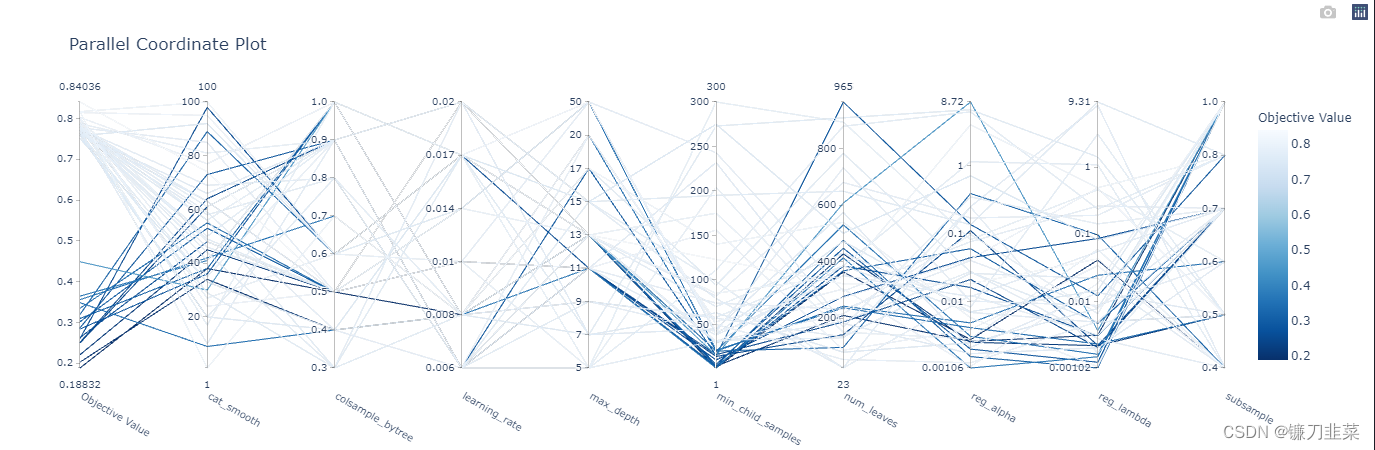
并行化参数选择
optuna.visualization.plot_parallel_coordinate(study)
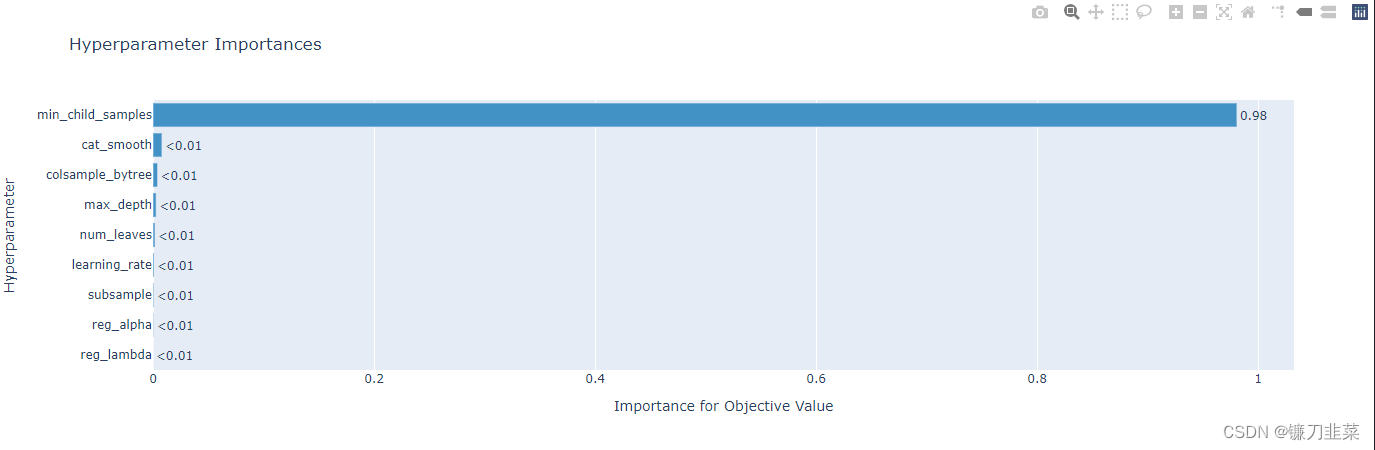
重要性参数
optuna.visualization.plot_param_importances(study)
最佳参数:
params = study.best_params
params['metric'] = 'rmse'
params
'''
{'reg_alpha': 0.002773386365643535,
'reg_lambda': 0.041227320518631407,
'colsample_bytree': 0.5,
'subsample': 0.4,
'learning_rate': 0.008,
'max_depth': 13,
'num_leaves': 363,
'min_child_samples': 1,
'cat_smooth': 38,
'metric': 'rmse'}
'''
使用Optuna对XGBoost进行调参
定义Objective
import xgboost as xgb
def objective(trial):
X_train, X_test, y_train, y_test = train_test_split(data, target, train_size=0.3, random_state=2023)
param = {
'lambda': trial.suggest_loguniform('lambda', 1e-3, 10.0),
'alpha': trial.suggest_loguniform('alpha', 1e-3, 10.0),
'colsample_bytree': trial.suggest_categorical('colsample_bytree', [0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0]),
'subsample': trial.suggest_categorical('subsample', [0.4, 0.5, 0.6, 0.7, 0.8, 1.0]),
'learning_rate': trial.suggest_categorical('learning_rate',
[0.008, 0.009, 0.01, 0.012, 0.014, 0.016, 0.018, 0.02]),
'n_estimators': 4000,
'max_depth': trial.suggest_categorical('max_depth', [5, 7, 9, 11, 13, 15, 17, 20]),
'random_state': trial.suggest_categorical('random_state', [24, 48, 2020]),
'min_child_weight': trial.suggest_int('min_child_weight', 1, 300),
}
model = xgb.XGBRegressor(**param)
model.fit(X_train, y_train, eval_set=[(X_test, y_test)], early_stopping_rounds=100, verbose=False)
preds = model.predict(X_test)
rmse = mean_squared_error(y_test, preds, squared=False)
return rmse
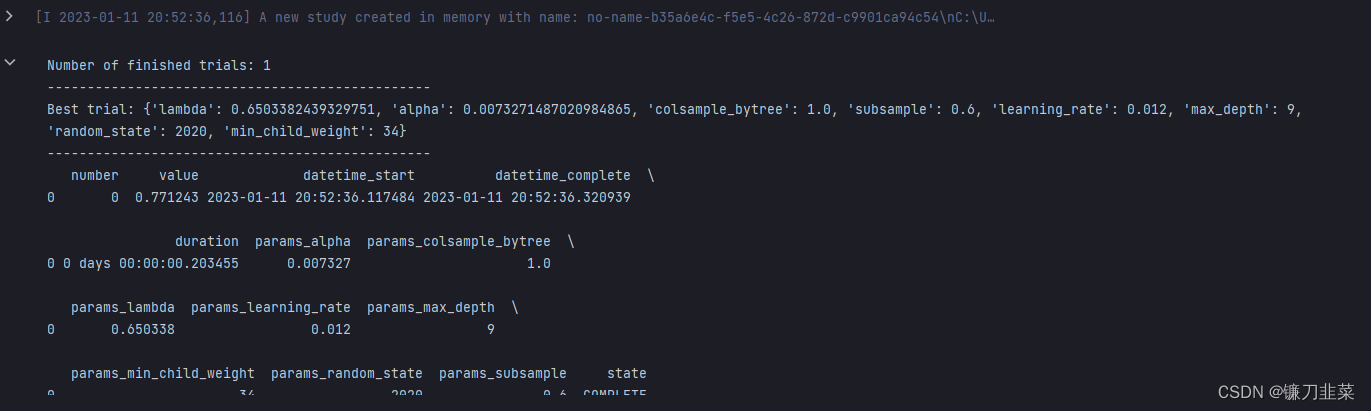
调参try
study = optuna.create_study(direction='minimize')
n_trials=1
study.optimize(objective, n_trials=n_trials)
print('Number of finished trials:', len(study.trials))
print("------------------------------------------------")
print('Best trial:', study.best_trial.params)
print("------------------------------------------------")
print(study.trials_dataframe())
print("------------------------------------------------")
绘图
optuna.visualization.plot_optimization_history(study).show()
optuna.visualization.plot_parallel_coordinate(study).show()
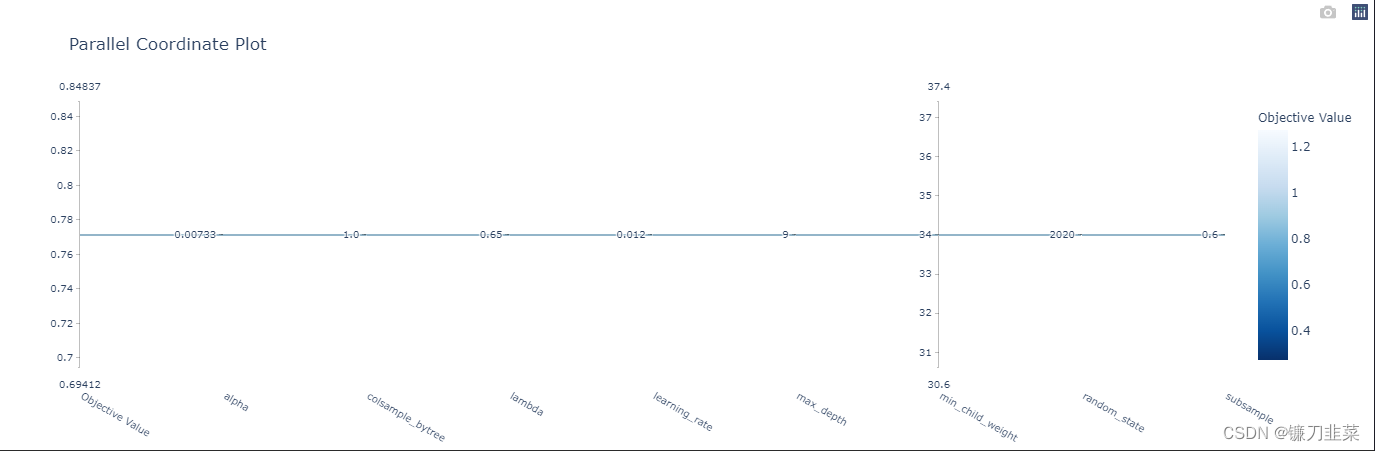
optuna.visualization.plot_slice(study).show()
optuna.visualization.plot_contour(study, params=['alpha',
#'max_depth',
'lambda',
'subsample',
'learning_rate',
'subsample']).show()
params=study.best_params
params
'''
{'lambda': 0.6503382439329751,
'alpha': 0.0073271487020984865,
'colsample_bytree': 1.0,
'subsample': 0.6,
'learning_rate': 0.012,
'max_depth': 9,
'random_state': 2020,
'min_child_weight': 34}
'''
参考资料
[1] 8个可以提高数据科学工作效率、节省宝贵时间的Python库
[2] Optuna — 超参自动化调整利器 学习笔记
[3] Optuna Tutorial
参考资料
[1] 8个可以提高数据科学工作效率、节省宝贵时间的Python库
[2] Optuna机器学习模型调参(LightGBM、XGBoost)
[3] optuna官网