引用
引用时C++引入的一个新的概念,他和指针有着千丝万缕的关系。
首先我们要了解的是引用不是新定义一个变量,而是给已存在变量取了一个别名,编译器不会为引用变量开辟内存空 间,它和它引用的变量共用同一块内存空间。语法格式如下
int main()
{
int a = 0;
int& b =a;
return 0;
}与指针十分的相似,&是b为引用的标志,int为引用对象的类型,所以int& b =a;表明b是变量a的引用。那这有什么用呢?下面我们看段代码。
int main()
{
int a = 0;
int& b =a;
cout << a << " " << b << endl;
b = 1;
cout << a << " " << b << endl;
return 0;
} 这段代码的运行结果是什么呢?结果如下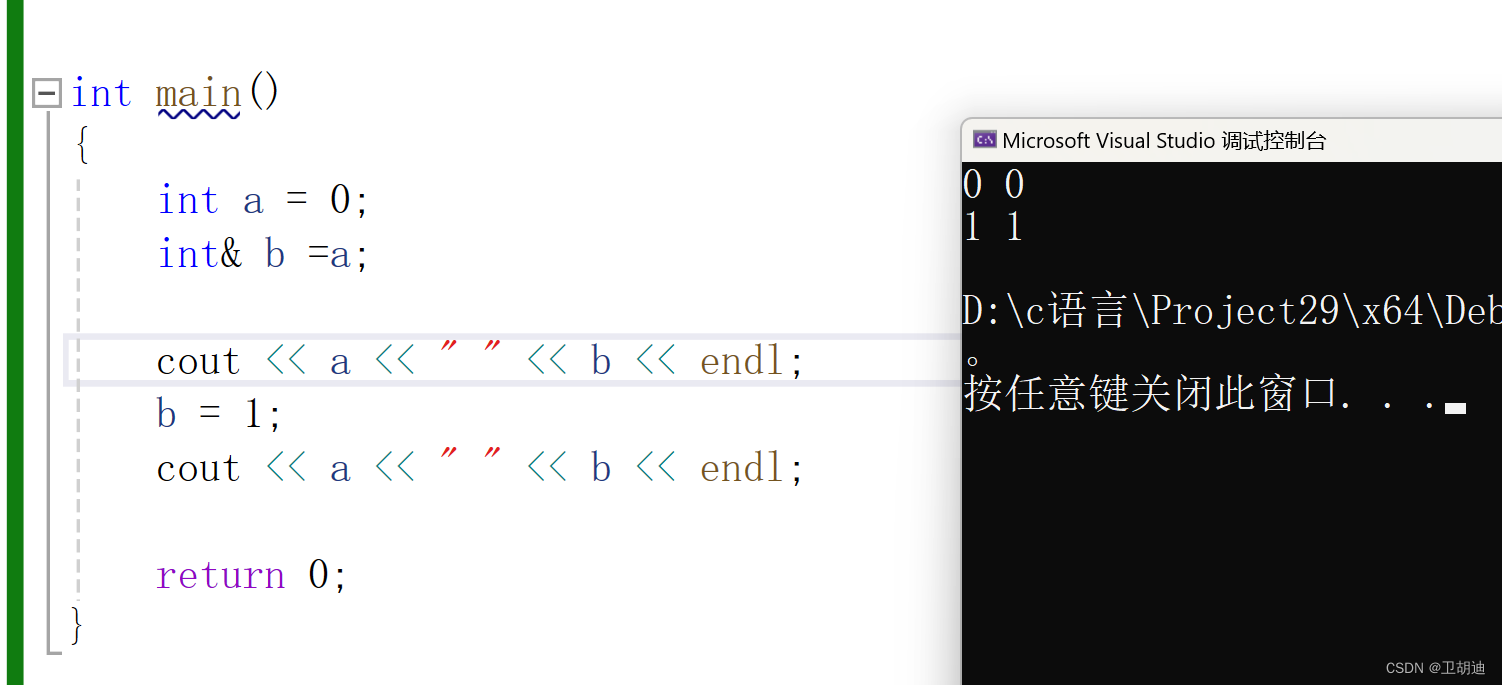
从结果不难看出,除了定义外,我们使用b就相当与使用a,修改b的值就相当于修改了a的值,他们两个使用同一块空间,我们可以通过下图的方式验证。
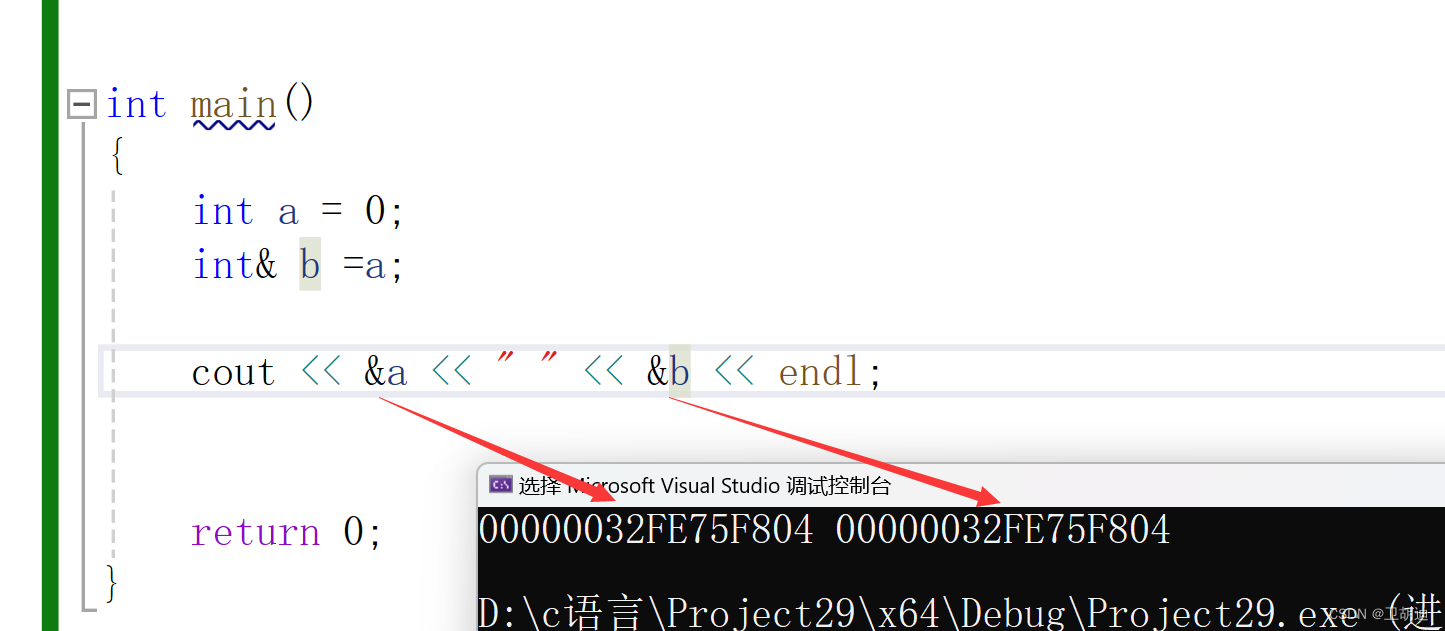
通过打印地址我们不难发现,a与b的地址是相同的,所以我们使用b就相当于使用a。那么我们的C++之父为什么要加入引用的概念呢?上述操作用指针完全可以完成,为什么要多次一举呢?
我们将上面的代码改写成如下指针操作,便可完成不使用a,却改变a的方法。
int main()
{
int a = 0;
int* b =&a;
cout << a << " " << *b << endl;
*b = 1;
cout << a << " " << *b << endl;
return 0;
}这两个方法达成的效果是完全一样的,但我们仔细观察他们的区别。
指针方法下的b可以被修改指向,修改指向其他int类型变量。
引用方法下b在创建的时候便以确定了唯一的指向,代表a,后序不可更改。相当于a的一个别名。一个人可以叫李华,可以取小名小李,小华但不论名字如何改变他都是指向李华这个人。
这样看似乎没有太大的差别,但指针成也灵活败也灵活,指针b的地址可以写成任意的地址,编译器至少赋值时检查不出来。这就导致了一个严重的问题,如果你每次都正确的使用指针那没有什么问题,但如果你不小心让指针成为野指针,指向栈帧内的地址或已经free的内存,那么他就有可能改变我们原来的数据内容,造成严重的安全问题,这也是许多语言放弃指针的原因,尽管指针的效率十分高。
而引用就完美的解决了这个问题,他右和指针差不多的效率,也可以修改对象的内容,而不会产生类似野指针造成的安全问题。他不可改变指向,你初始化为什么,他就只能修改指定向,不可以修改任意项。这也是祖师爷最初设计引用的初衷,增加代码的健壮性。
在我们学习的初期,我们可以简单的理解引用为受限制的指针,例如如下代码。const修饰b,b从语法上限制不可修改。而引用就是编译器帮我i们完成了解引用的过程,并且将int&重新定义为一种限制的语法。
int main()
{
int a = 0;
int* const b =&a;
cout << a << " " << *b << endl;
*b = 1;
cout << a << " " << *b << endl;
return 0;
}如果我们试图修改b的指向便会报出如下的错误。

其实编译器对于指针和引用实在看待同一种东西,引用就是指针的再次封装。为什么可以这么说呢?我们看汇编代码,当然也只是一些简单的汇编指令。
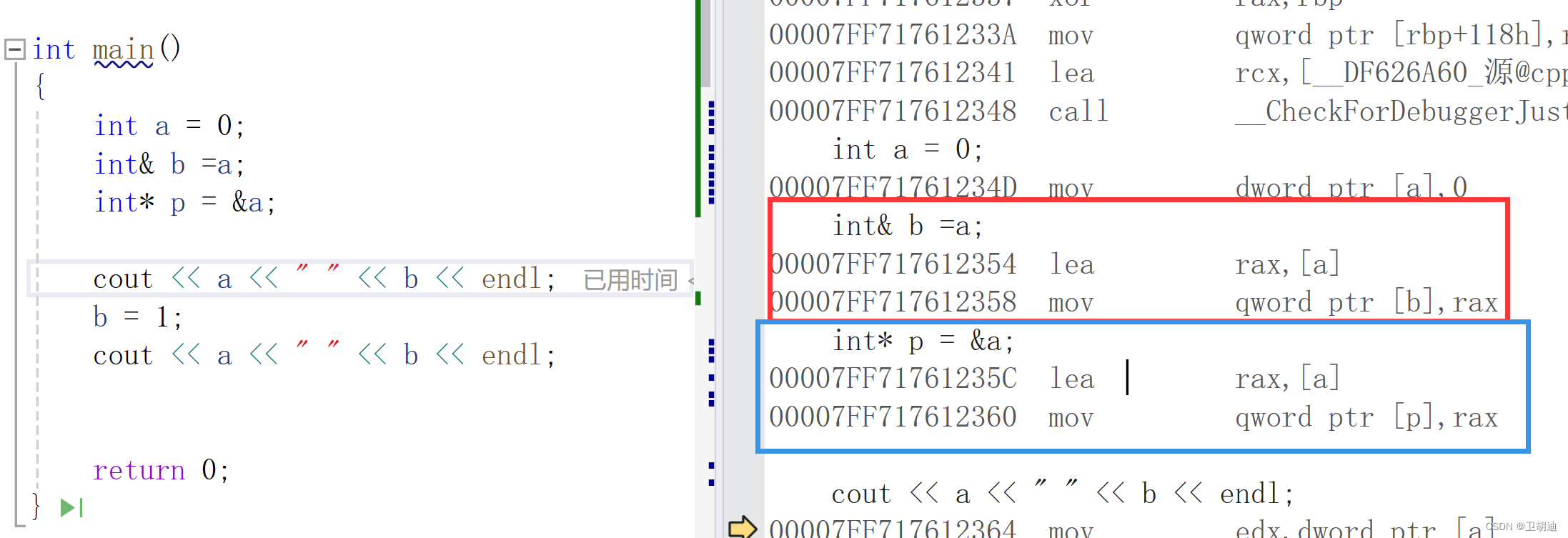
lea是Load Effective Adreess 加载有效地址,mov 是把后面的值赋值给前面。我们可以发现编译器把a的地址给了b和p,但因为p与b的类型不同,他们在使用的时候,编译器的处理不同。如下图。
我们可以发现b在调用的时候是先将b里存的地址加载到寄存器中,然后根据这个地址进行赋值操作,相当于编译器层面帮我们做了次解引用。
而指针p是直接对p的地址进行更改,没有编译器的解引用。
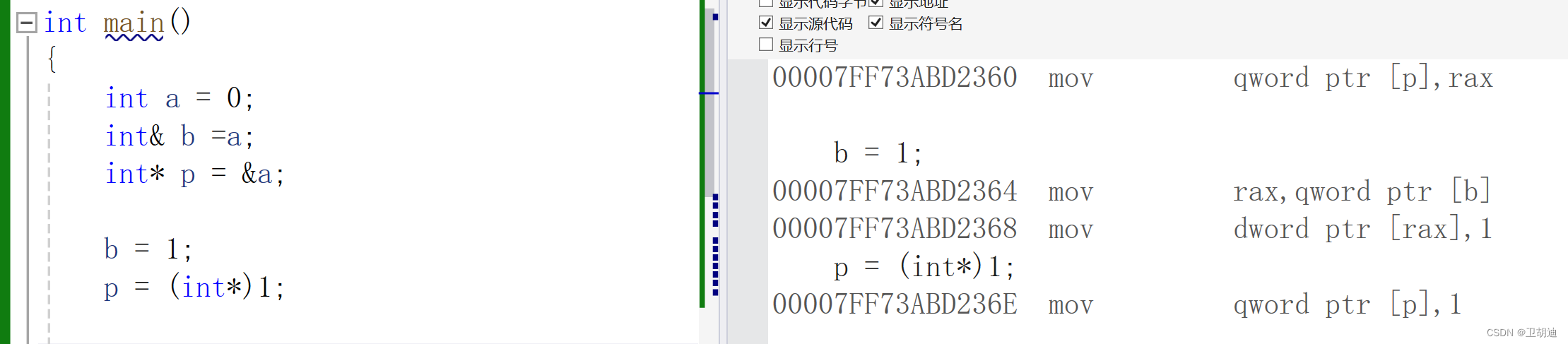
读者再仔细看上面的程序,会发现指针仅仅使用一次强制类型转换,他存的地址便可以是任意地址,然后我们根据这些地址进行修改,便会产生难以预料的后果。这也体现了指针的不安全性。而引用有和指针几乎相同的效率,但安全性却大大的提高了!!
下面我们用引用和指针写一个简单的交换两数的程序。
void Swap(int* p1, int* p2)
{
int t = *p1;
*p1 = *p2;
*p2 = t;
}
void Swap(int& p1, int& p2)
{
int t = p1;
p1 = p2;
p2 = t;
}以上两个代码都可以完成交换两数的程序,且用引用在调用函数的时候不用取地址,相对而言更简单些。
内联函数
例如上面我们写的Swap函数,在排序的时候,函数调用十分的频繁,而函数每次调用都会加建立栈帧,销毁栈帧消耗一定的时间。有没有一种方法可以在处理这些频繁的小问题上不用调用函数这么大费周章?
相信熟悉C语言的读者一定想到了宏函数的使用,但宏函数是十分容易出错的。我们看一个简单的宏函数,大家先自己仔细阅读,看看有问题么?
#define ADD (a,b) a+b;这看起来十分的正常,没有什么问题但我们仔细观察便会发现问题不小。
首先第一个错误ADD与后面的括号有空格,不要小看这一细节。有空格就代表是单纯的宏替换,而不是宏函数不可以传参。进行下面的展开。

删除空格才能是宏函数,有如下传参展开。

那么分号要加么?结果是否定的。我们可能写出如下的代码。那么他就达不到我们想要的结果却可以正常运行。宏展开后为 c=a+b; +4;在加4前的分号导致c没有加4就结束了。
int main()
{
int a = 0;
int b = 1;
int c = 4;
c=ADD(a,b)+4;
return 0;
}其次要考虑的便是展开后的优先级问题。如下代码
c=4*ADD(a,b)+4;我们展开后的代码如下c=4*a+b+4;我们想要a+b的结果乘以4,但由于优先级的问题变成了4*a+b,显然与我们的意图不一样,解决方法也十分简单,在外围加个括号便可以了,保证内部优先级最高,但这就完成了么?还是没有。
假如我们有如下的代码,
c=4*ADD(a|4,b);展开后的结果为c=4*(a|4+b);但+的优先级比|高,就会导致运行先4+b然后与a按位或。我们因此要对a,b也加上括号,最终的结果如下。
#define ADD(a,b) ((a)+(b))一个小小的ADD都有如此多的细节,其他的也不逞多让,不简单。但如果我们写出函数的话,就不用考虑那么多了。没有优先级的问题与其他细节。但消耗的时间大于宏函数。
int ADD(int a, int b)
{
return a + b;
}此时便可以使用内联函数,向编译器申请将代码展开。内联函数的定义十分简单,只需要加上关键字inline即可。
inline int ADD(int a, int b)
{
return a + b;
}编译器会根据函数的大小决定是否在函数调用语句将代码展开。从而减少函数栈帧的消耗。
今天的文章就到此结束了,喜欢的点点关注。如果有错误,欢迎在评论区指出。