关注小庄 顿顿解馋(`▿´)
喜欢的小伙伴可以多多支持小庄的文章哦
📒 数据结构
📒 C++
引言 : 上一篇博客我们了解了C++入门语法的一部分,今天我们来了解函数重载,引用的技术,请放心食用 ~
文章目录
- 一. 🏠 函数重载
- 📒 函数重载的概念
- 📒 函数重载的误区
- 1.形参顺序不同是不同类型形参顺序不同
- 2.函数返回值不是构成重载的条件
- 3.函数在同一作用域才构成重载
- 4.缺省参数不是构成重载的条件
- 📒 C++支持函数重载的原因
- 二. 🏠 引用
- 📒 认识引用
- 📒 引用特性
- 📒 常引用
- 📒 使用场景
- 📒 传值 传引用 效率比较
- 📒 引用的大小
- 📒 引用和指针的区别
一. 🏠 函数重载
void Swap(int x ,int y)
{
int tmp = 0;
temp = x;
x = y;
y = temp;
}
这个函数想必不会陌生吧,可我们发现这个Swap函数只能交换整形,如果我同样调换这个函数就能交换浮点型呢?这里C++就给我们提供了函数重载的技术。
📒 函数重载的概念
函数重载:是函数的一种特殊情况,C++允许在
同一作用域中声明几个功能类似的同名函数,这些同名函数的形参列表(参数个数或类型或类型顺序)不同,常用来处理实现功能类似数据类型不同的问题。
我们上代码来感受一下
形参类型不同
#include<iostream>
using namespace std;
// 1、参数类型不同
int Add(int left, int right)
{
cout << "int Add(int left, int right)" << endl;
return left + right;
}
double Add(double left, double right)
{
cout << "double Add(double left, double right)" << endl;
return left + right;
}
形参个数不同
void f()
{
cout << "f()" << endl;
}
void f(int a)
{
cout << "f(int a)" << endl;
}
形参顺序不同
void f(int a, char b)
{
cout << "f(int a,char b)" << endl;
}
void f(char b, int a)
{
cout << "f(char b, int a)" << endl;
}
只要满足一个条件即可发生重载
📒 函数重载的误区
1.形参顺序不同是不同类型形参顺序不同
void f(int a, int b)
{
cout << "f(int a,char b)" << endl;
}
void f(int b,int a)
{
cout << "f(int a,char b)" << endl;
}
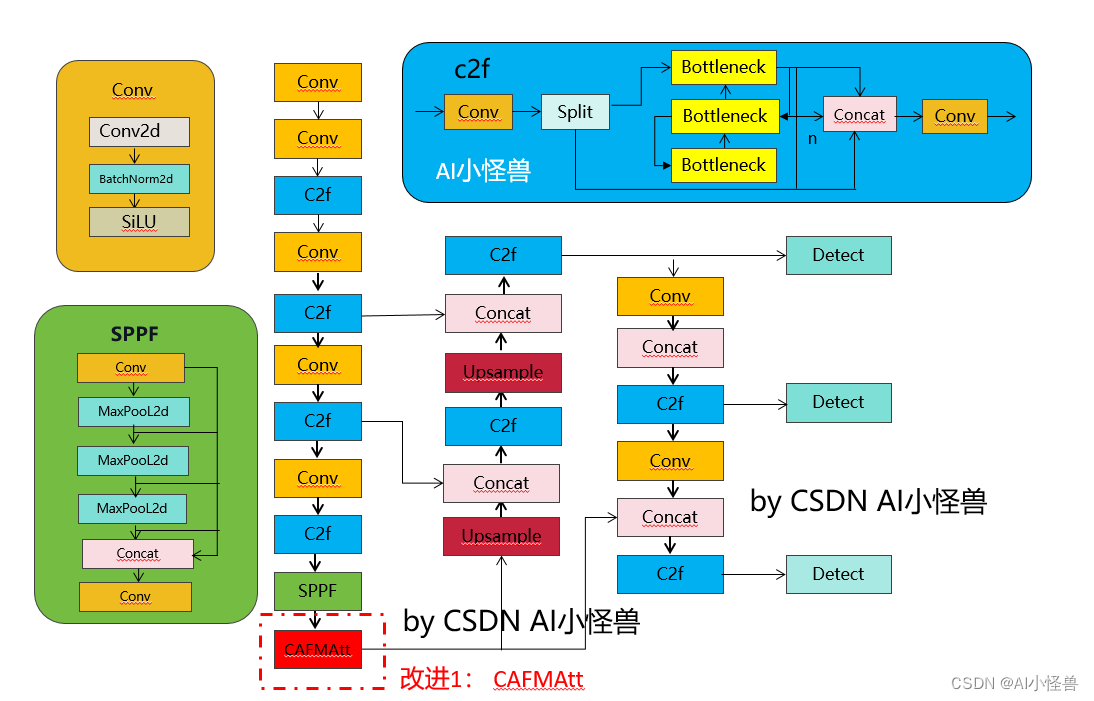
这里形参顺序不同坑定能正常编译吧老铁,实则不然
注:函数重载形参顺序不同,指的是不同类型形参的顺序不同
2.函数返回值不是构成重载的条件
int func()
{
cout << "use int func()" << endl;
return 0;
}
void func()
{
cout << "use void func(int a)" << endl;
}
对于这段代码同样不能正常编译,函数返回值不作为函数重载的条件,首先函数这里会产生调用歧义(语法上调哪一个都可以),同时函数返回值不一定要接收
3.函数在同一作用域才构成重载
namespace N1
{
void Mul(int a, int b)
{
cout << a * b << endl;
}
}
namespace N2
{
void Mul(int a, int b)
{
cout << a * b * 2 << endl;
}
}
此时这两个函数是否构成重载呢?
注:函数重载是要在同一作用域下的,这里N1和N2是两个不同的命名空间域
注:不同域可以定义同名,相同域也可以但要符合重载条件。
那如果我展开他们的命名空间呢?
using namespace N1;
using namespace N2;
Mul(1,2);
Mul(1,3);
此时这两个函数虽然都展开引入了全局域中,但仍然不构成重载,会产生调用歧义。
4.缺省参数不是构成重载的条件
void func(int a = 10)
{
cout << "func(int a = 10)" << endl;
}
void func(int a = 2)
{
cout << "func(int a = 2)" << endl;
}
能否构成函数重载呢?编译器会给我们答案

很显然,缺省参数是不构成函数重载的条件的
如果是这样呢?
void func()
{
cout << "func(int a = 10)" << endl;
}
void func(int a = 2)
{
cout << "func(int a = 2)" << endl;
}
此时两个函数确实构成重载,但会发生调用歧义。
📒 C++支持函数重载的原因
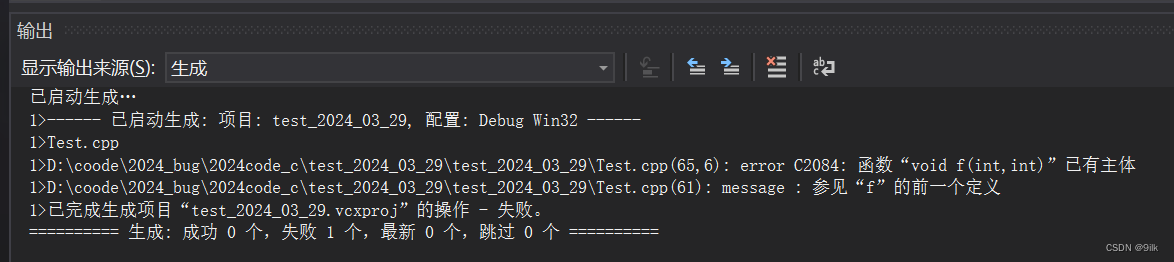
我们知道在C语言中函数不能同名,那为什么C++就支持重载,C语言不支持呢?我们得先来回顾一下编译和链接的过程
-
C语言
编译链接的过程大致如下,可以参考博主之前写的文章编译与链接
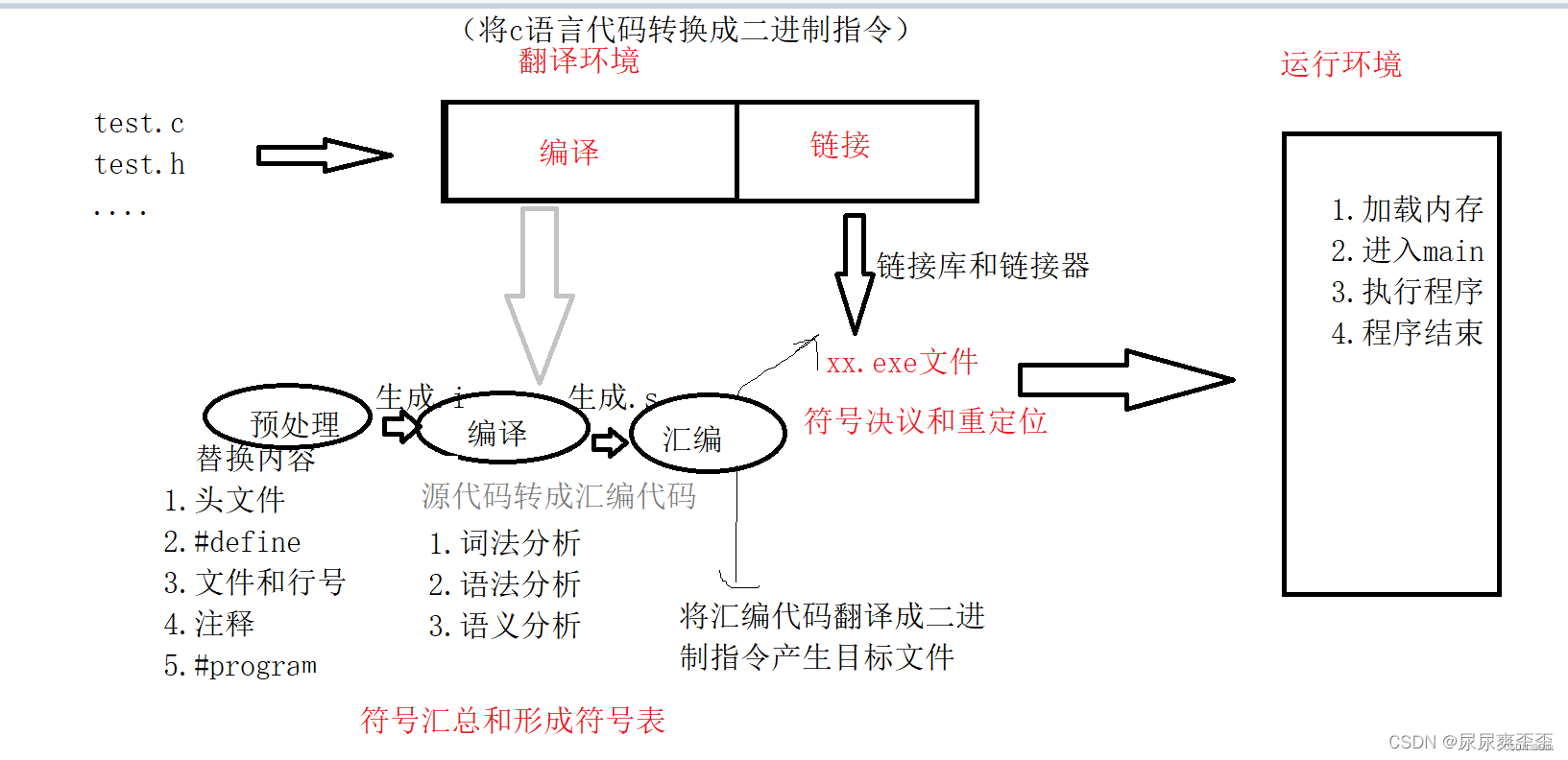
在链接时,我们会进行符号决议和重定位,也就是我们调用函数时,编译器会根据函数名符号表中的符号去找函数地址,与我们.c文件调用的符号链接起来
补充:
- 在只有函数声明的文件中,在编译过程中没有函数的地址,但能通过语法检查
- 有函数定义才能形成一系列的汇编指令,函数定义的第一条就是函数的地址
总结:C语言直接通过函数名字去查找函数,这样无法区分,故不支持重栽
- C++
与C语言不同的是,C++在链接时是通过修饰后的函数名去查找,可以起到区分的作用,因此支持重载。
具体是怎么重载的呢?我们上图
//g++编译器 Linux环境
void f(int a,char b);
void f(char a,int b);
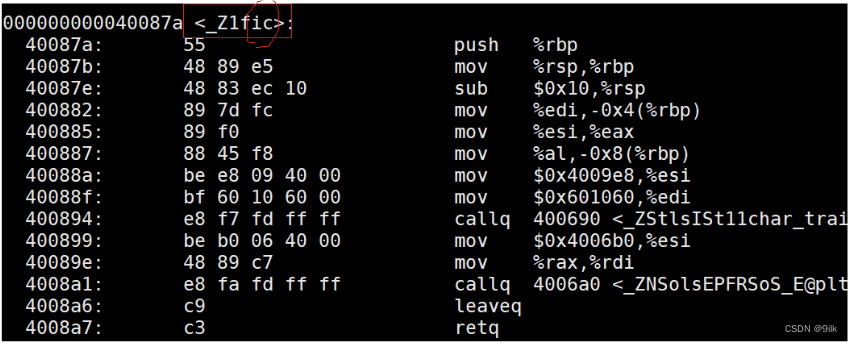
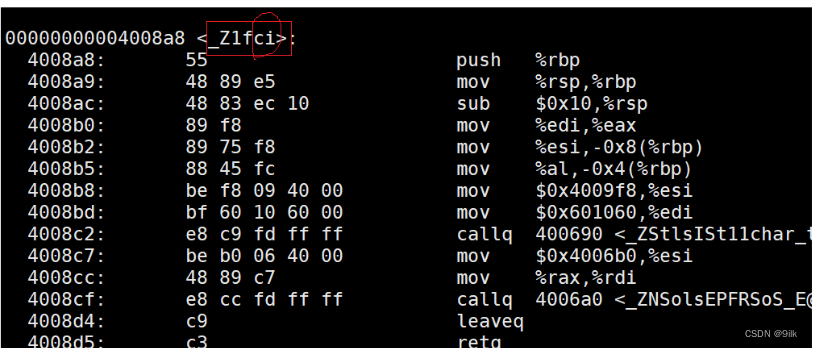
我们可以发现由于形参列表的不同(c表示char i表示int),构成了修饰名的不同,编译器将函数参数类型信息添加到原函数名后
小补充:在不同的平台,函数名的修饰规则是不同的。
windows系统
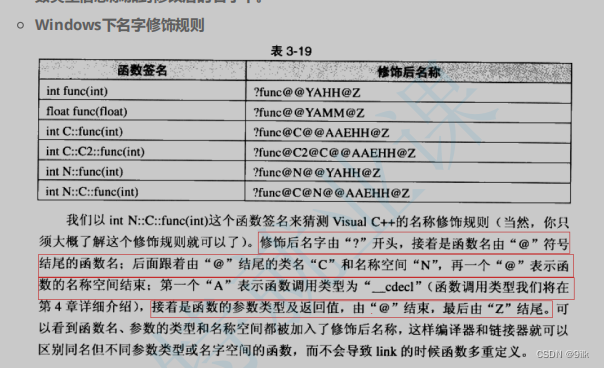
对比Linux会发现,windows下vs编译器对函数名字修饰规则相对复杂难懂,但道理都是类似的,我们就不做细致的研究了。
二. 🏠 引用
📒 认识引用
- 引用的概念
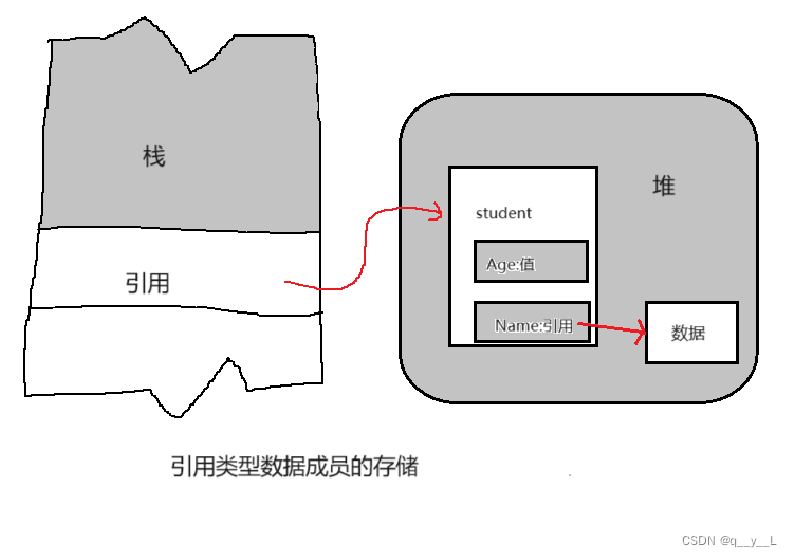
引用不是新定义一个变量,而是给已存在变量取了一个别名,编译器不会为引用变量开辟内存空间,它和它引用的变量共用同一块内存空间。
- 引用的语法形式
类型& 引用变量名(对象名) = 引用实体;// 注意引用类型要和它的引用实体的类型相同
int a = 10;
int& b = a;
cout << &a << endl;
cout << &b << endl;
int* p = &a;
int* & = p;
double d = 1.0;
double& pd = d;
输出
008FF838
008FF838 // 引用和变量确实共用一块空间
📒 引用特性
- 引用定义时必须初始化
int x = 0;
int& a = x;
- 一个变量可以有多个引用
int x = 0;
int & a = x;
int & b = x;
int & c = b;
c++;//这里c改变a b x都会改变
- 引用一旦初始化,不可改变引用实体
int a = 0;
int b = 1;
int& pa = a;
pa = b ; //这里是把b的值赋给a/pa;
📒 常引用
权限的平移
int x = 0;
int &y = x ;
//引用
const int m = 10;//此时m是只读
const int & pm = m;
//指针
const int* p1 = &m;
const int* p2 = p1;
权限的放大
//引用
const int m = 10;
int& r = m; //此时m只能读取,int&是可读可写 权限放大是不行的
//指针
const int* p1 = &m;
int* p2 = p1;//p1只读 权限放大不可以
//普通变量赋值的拷贝
in p = m; //此时是把m的值拷贝给p,p的修改不影响m
权限的缩小
int x = 0;
//引用
const int& z = x;
//z++不行 因为只能读
//指针
int* p3 = &x;
const int* p4 = p3;
double d = 1.9;
//int& t = d; 会报错
const int& r = d;
int x = 1,y = 0;
const int& r = x + y;
//int& pr = x + y; 会报错
在类型转换和表达式求值时,会产生
临时变量(因为要存储他们运算后的结果),而临时变量具有常性(相当于被const修饰,只读),这里用int&接收造成权限的放大。
总结:对于指针和引用权限可以平行缩小,但不能放大;普通变量赋值没有权限之说。
📒 使用场景
- 作为函数的形参
void Swap(int& left, int& right)
{
int temp = left;
left = right;
right = temp;
}
- 作为返回值
int& Count()
{
static int n = 0;
n++;
// ...
return n;
}
📒 传值 传引用 效率比较
#include <time.h>
struct A{ int a[10000]; };
void TestFunc1(A a){}
void TestFunc2(A& a){}
void TestRefAndValue()
{
A a;
// 以值作为函数参数
size_t begin1 = clock();
for (size_t i = 0; i < 10000; ++i)
TestFunc1(a);
size_t end1 = clock();
// 以引用作为函数参数
size_t begin2 = clock();
for (size_t i = 0; i < 10000; ++i)
TestFunc2(a);
size_t end2 = clock();
// 分别计算两个函数运行结束后的时间
cout << "TestFunc1(A)-time:" << end1 - begin1 << endl;
cout << "TestFunc2(A&)-time:" << end2 - begin2 << endl;
}
输出结果
“TestFunc1(A)-time:” :27
“TestFunc2(A&)-time:”:0
总结:传引用比传值效率高出很多,可以认为在语法层面上传引用几乎没开空间
那是否引用真的没开空间呢?
int x = 2;
int* p = &x;
int& pr = x;
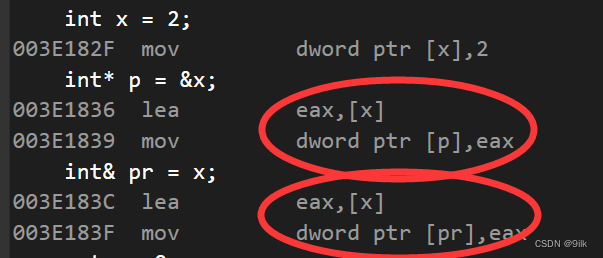
我们转到反汇编观察发现,定义引用时其实也是把变量的地址放到引用变量里。
换句话说,引用的底层也是指针,基于这个理解,我们来看下面的问题。
📒 引用的大小
#include<iostream>
using namespace std;
//x64
cout << sizeof(int&) << endl;
cout << sizeof(short&) << endl;
cout << sizeof(long&) << endl;
//x86
cout << sizeof(int&) << endl;
cout << sizeof(short&) << endl;
cout << sizeof(long&) << endl;
输出结果:
x64环境下
4
2
4
x86环境下
4
2
4
总结:引用大小在语法层面上规定是它引用实体类型大小,毕竟引用是一种语法,sizeof没有意义
那如果是这样呢?
#include<iostream>
using namespace std;
struct Test
{
int& age;
}
struct Test t;
cout << sizeof(t)<<endl;
结合我们之前学的结构体内存对齐知识,这里输出结果是否应该等于4?
输出结果:
32位环境下
4
64位环境下
8
//你是否感到疑惑?同时我这里为什么要以环境来区分?
实际上,结合我们之前的结论引用底层实质是个地址,当我们用结构体定义出一个实际的对象时,底层就有了蓝图,那就需要去翻译和识别它是个指针类型了。
📒 引用和指针的区别
| 指针 | 引用 |
|---|---|
| 指针存的是变量的地址 | 引用是变量的别名 |
| 有空指针NULL | 没有空引用 |
| 有多级指针 | 没有多级引用 |
| 指针可以改变指向 | 引用初始化后不可改变引用实体 |
| 指针相对安全性低 | 引用相对安全性高 |
| sizeof(指针)始终是地址空间所占字节大小 | 引用大小为引用实体类型的大小 |
| 自增是向后偏移一个类型的大小 | 自增是引用实体增加 |
| 指针访问实体要解引用 | 引用访问实体编译器自己处理 |
| 指针不一定要初始化 | 引用一定要初始化 |
学到知识的小伙伴,不妨给小庄一个三连呀 ~