前言
Web Scraper 是一个浏览器扩展,可以实现无需编码即可爬取网页上的数据。只需按照规则进行配置,即可实现一键爬取导出数据。
安装
进入Google应用商店安装此插件,安装步骤如下:


进入Google应用商店需要外网VPN才能访问,如果你不能进入外网。可以直接访问此链接下载:
链接:https://pan.baidu.com/s/16AZRpKSrtHu_b2OjlYhnGA 提取码:rtk7
安装后, 打开 F12开发者工具会多出一个名 Web Scraper 的面板,接下来以此作为开始。
快速上手
写个例子:提取百度首页底部几个导航按钮的文字,了解下 Web Scraper 是如何工作。
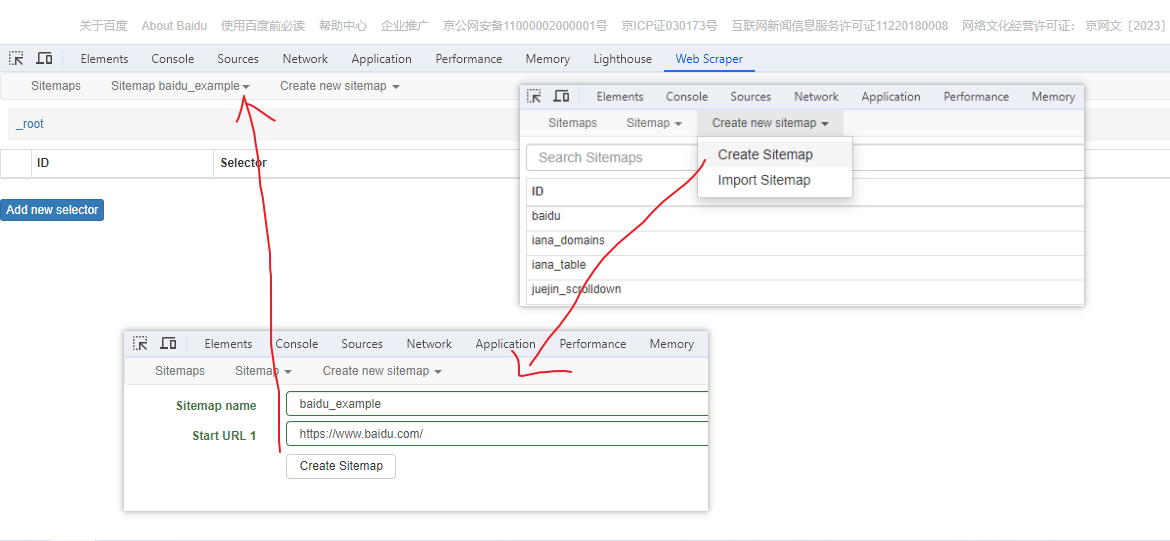
创建任务
创建任务,即创建 SiteMap(这词不常用,还是用我们熟悉的词吧,意思大致一样就行)。打开 百度首页,再打开开发者面板如下操作,其中URL可以使用特殊语法,这个后面再谈。
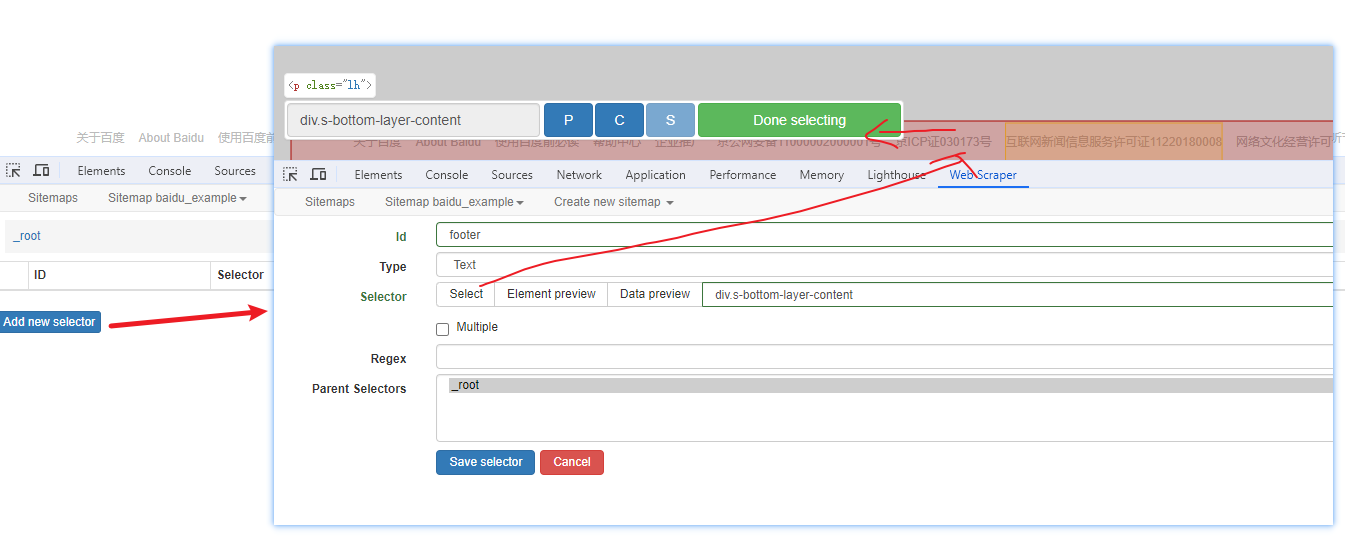
选择内容
开始抓取
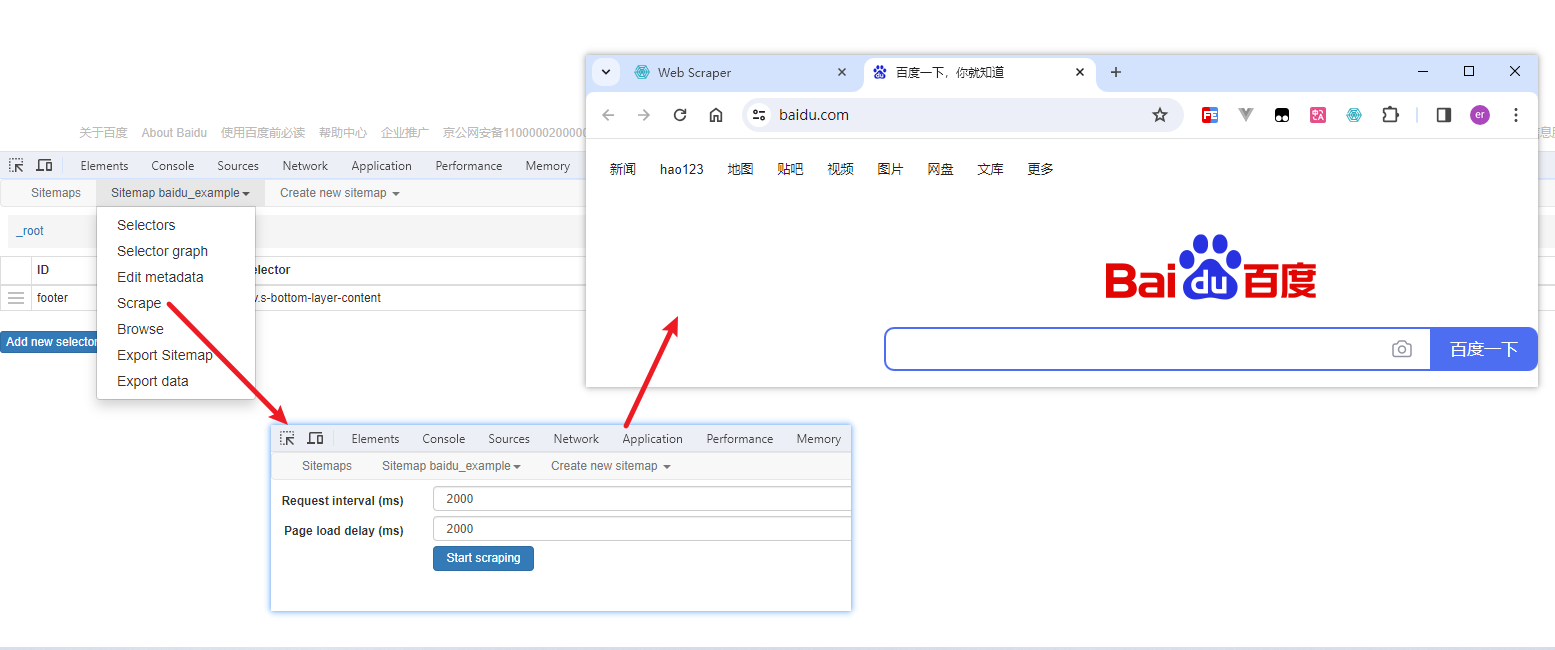
浏览数据
抓取完肯定要确认数据是否正确,格式不正确需要重新调整选择器,浏览数据的步骤如下:
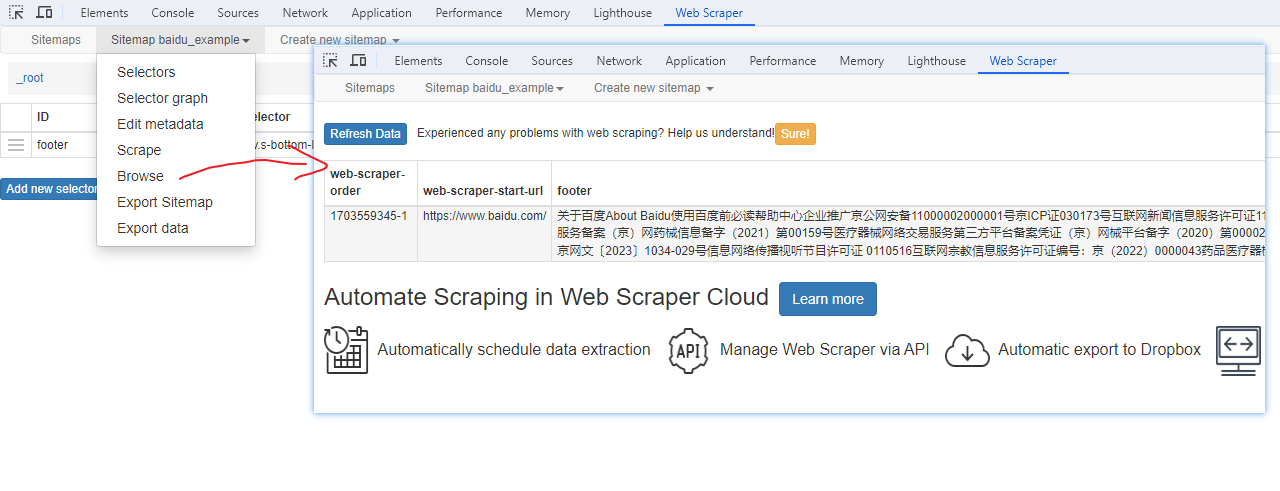
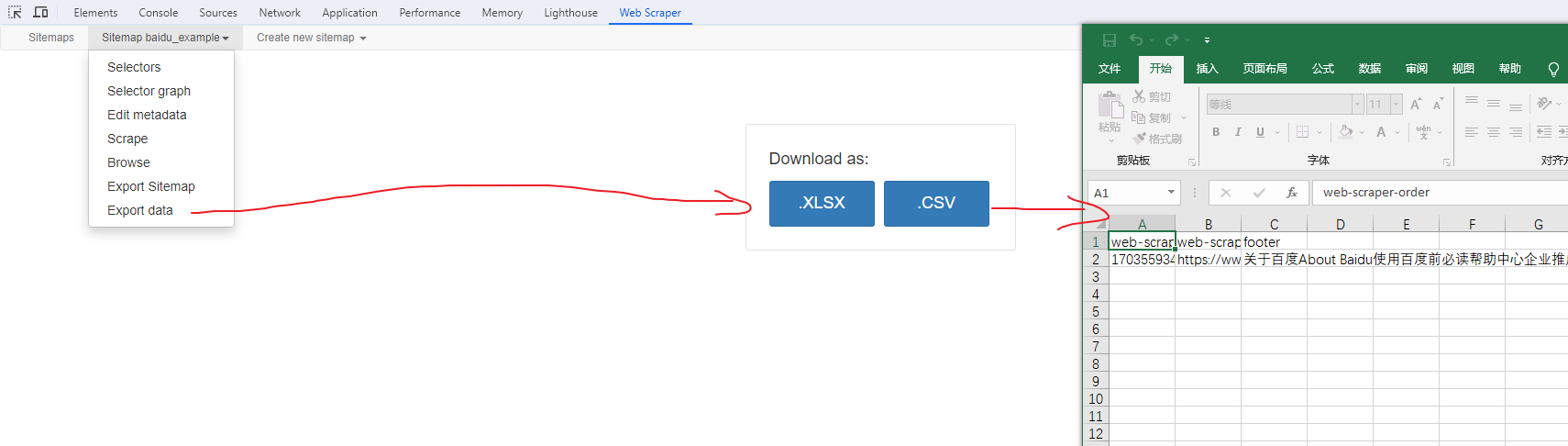
保存数据
确认无误后,就可以进行保存(如下)。目前只能导出 excel 或 csv 格式,json 需要充值(会员),不过也不是啥大问题,随便找个在线网站转一下就行。
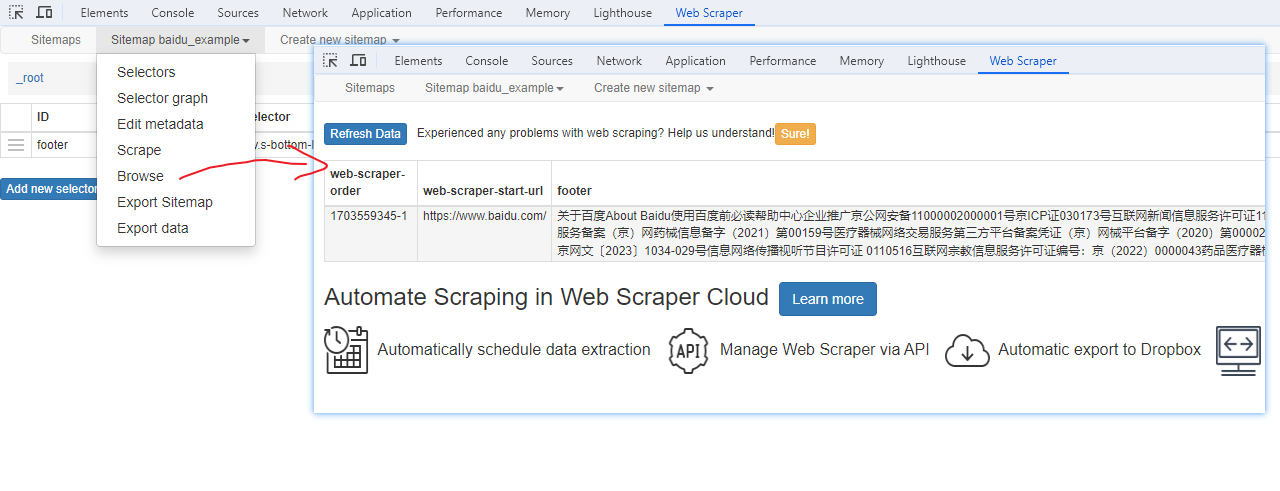
浏览数据
抓取完肯定要确认数据是否正确,格式不正确需要重新调整选择器,浏览数据的步骤如下:
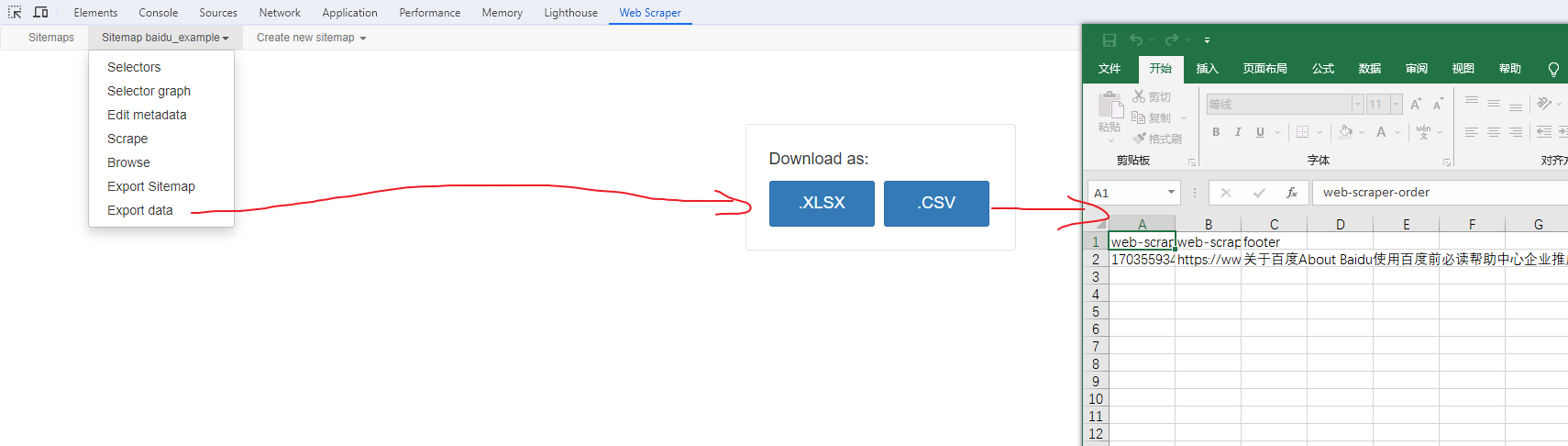
保存数据
确认无误后,就可以进行保存(如下)。目前只能导出 excel 或 csv 格式,json 需要充值(会员),不过也不是啥大问题,随便找个在线网站转一下就行。
小结
图片选择器
抓取的URL支持特殊语法,如果页面分页体现在URL上的话还是非常有用的。如下:
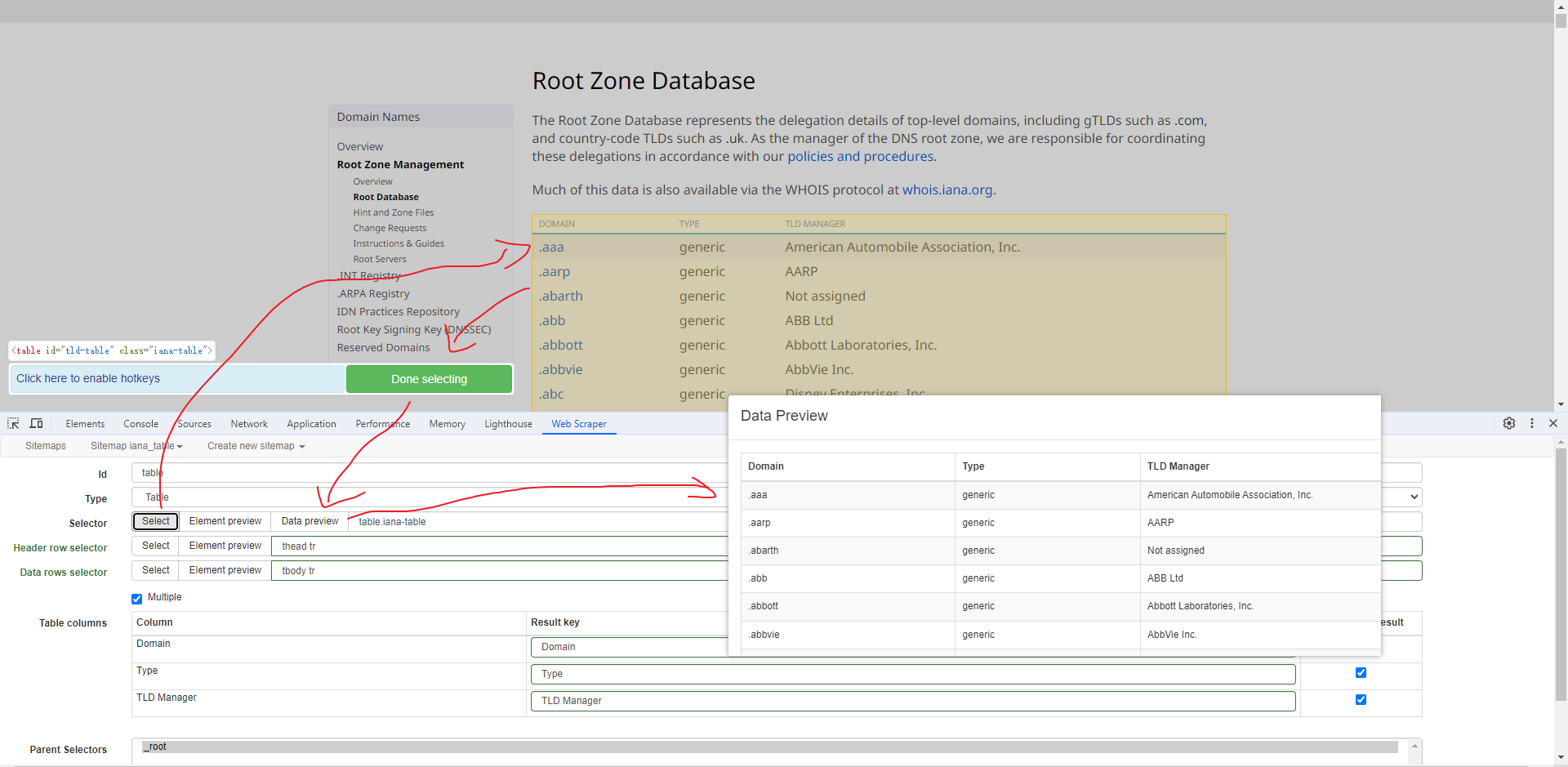
表格选择器
提取表格数据,以 IANA的域名列表 为例,如下:
链接选择器
提取链接名字和地址,以 百度首页 为例, 如下:
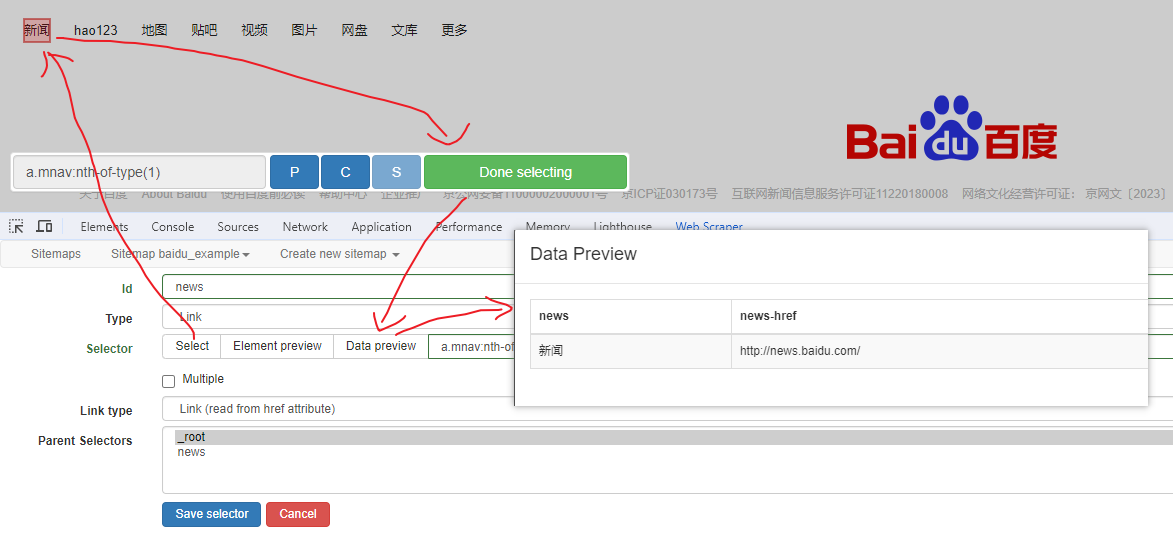
百度首页 为例, 如下:
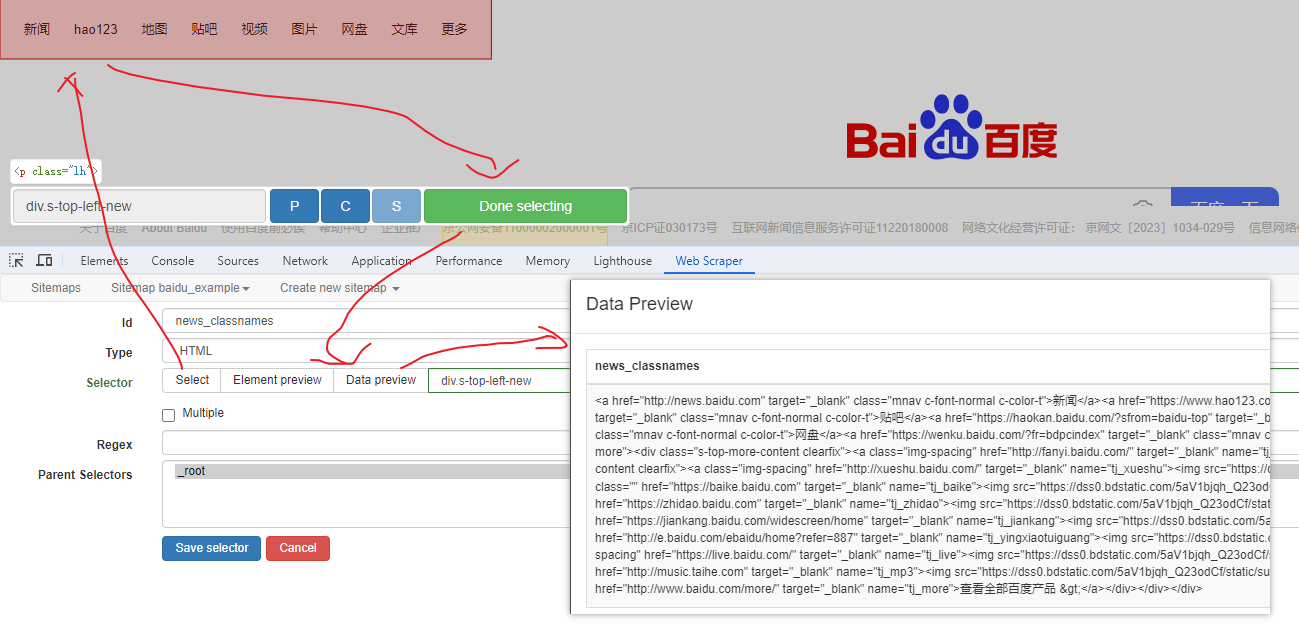
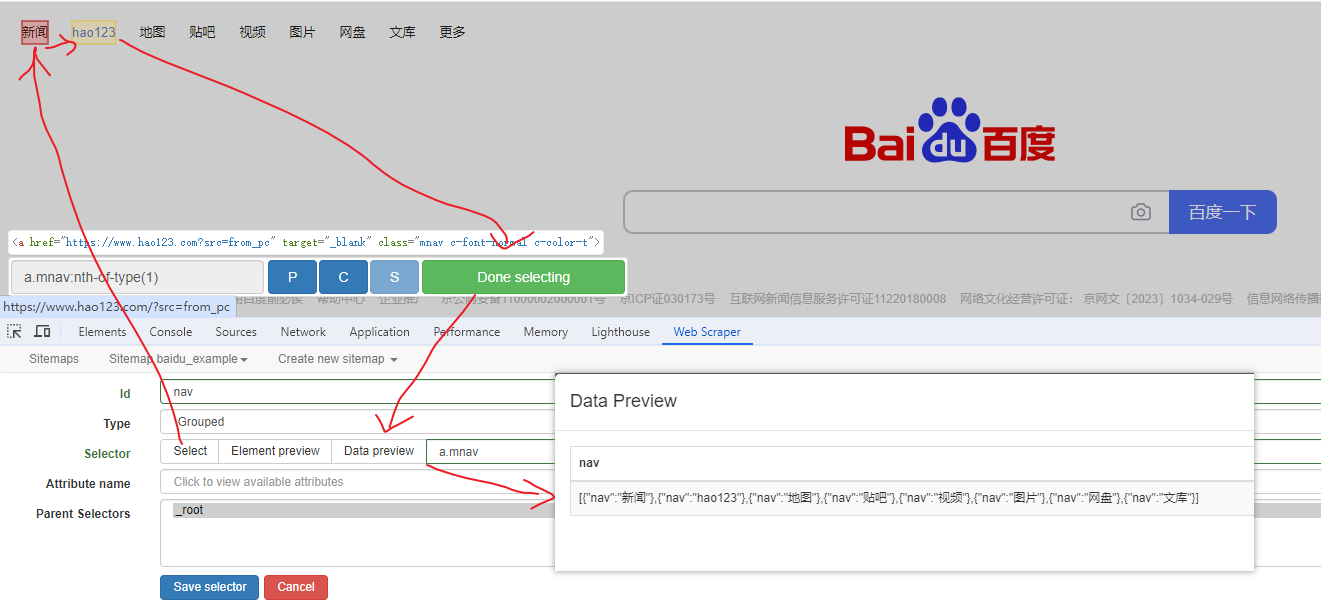
属性选择器
提取属性值,以 百度首页 为例, 如下:

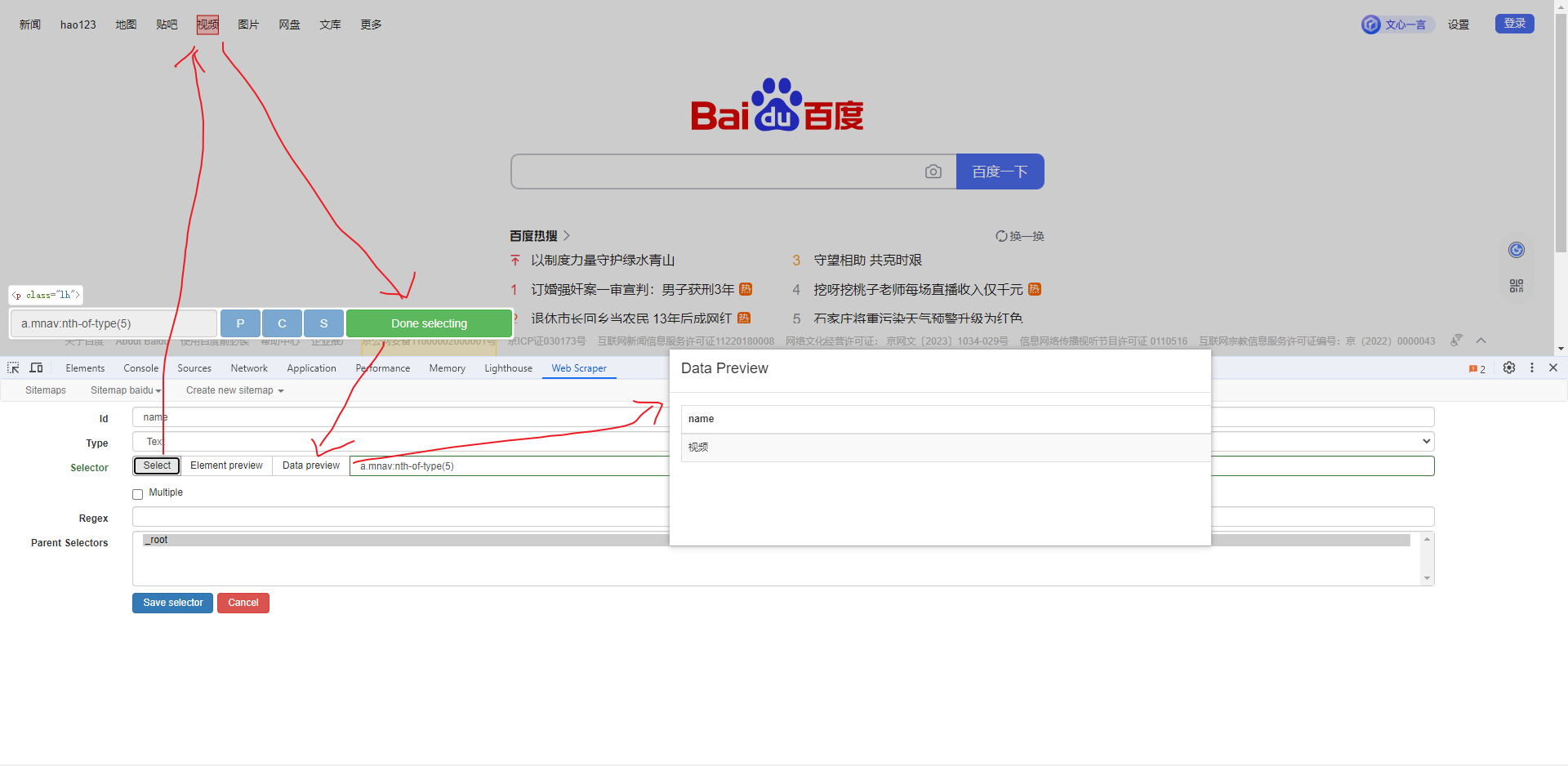
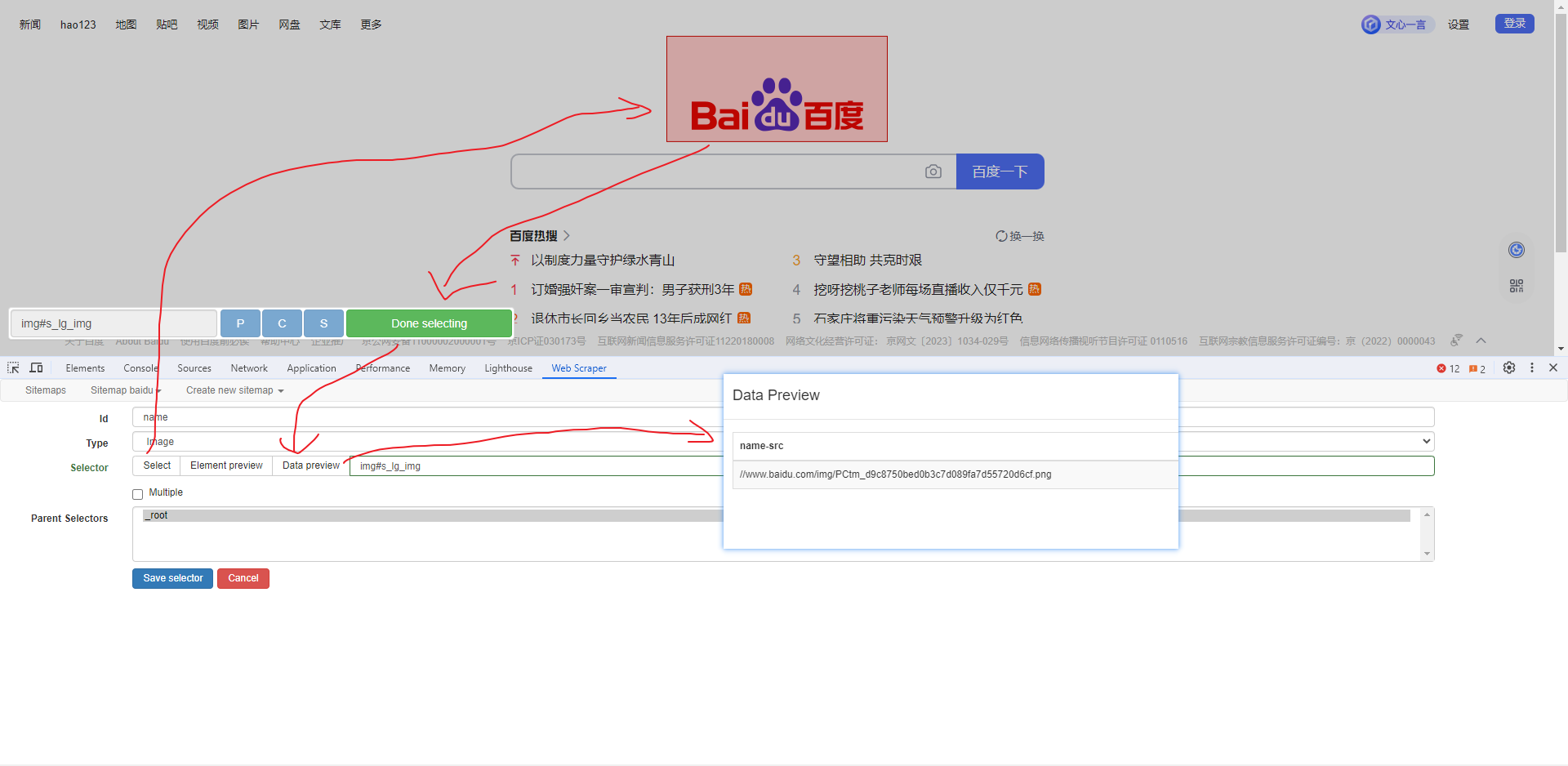
图片选择器
提取图片地址,以 百度首页 为例, 如下:
元素选择器
提取表格数据,以 IANA的域名列表 为例,如下:

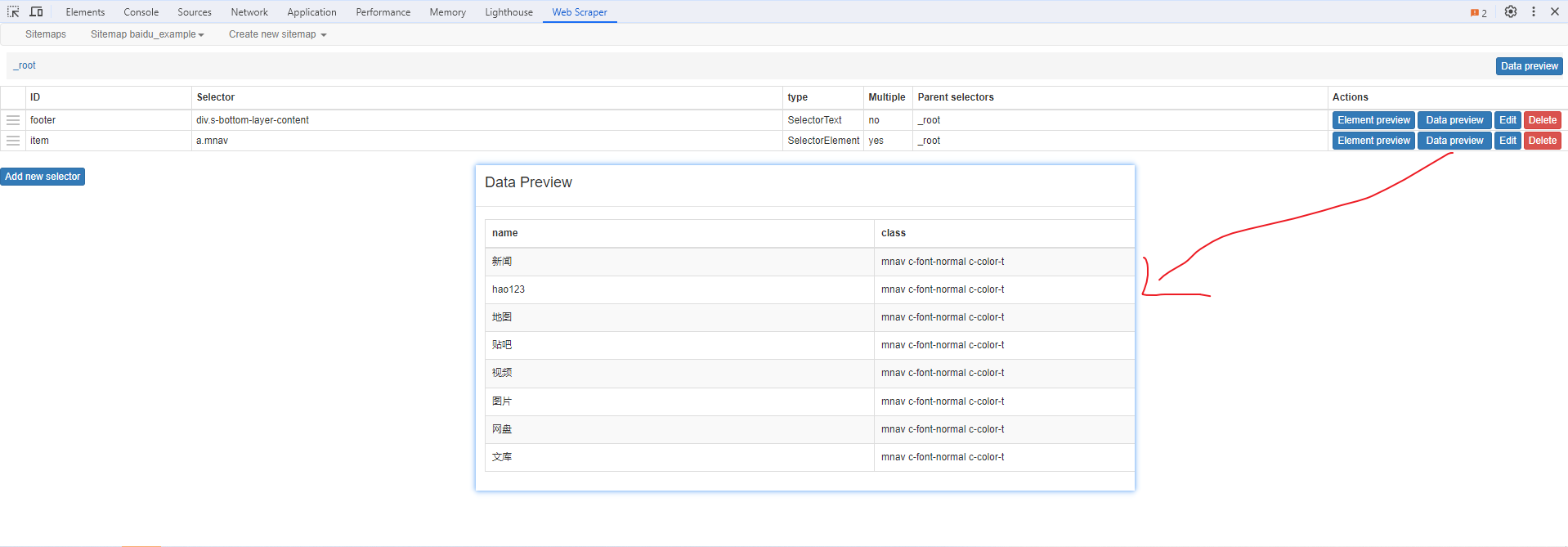
元素和子选择器创建好就可以了,以下是预览到的数据:
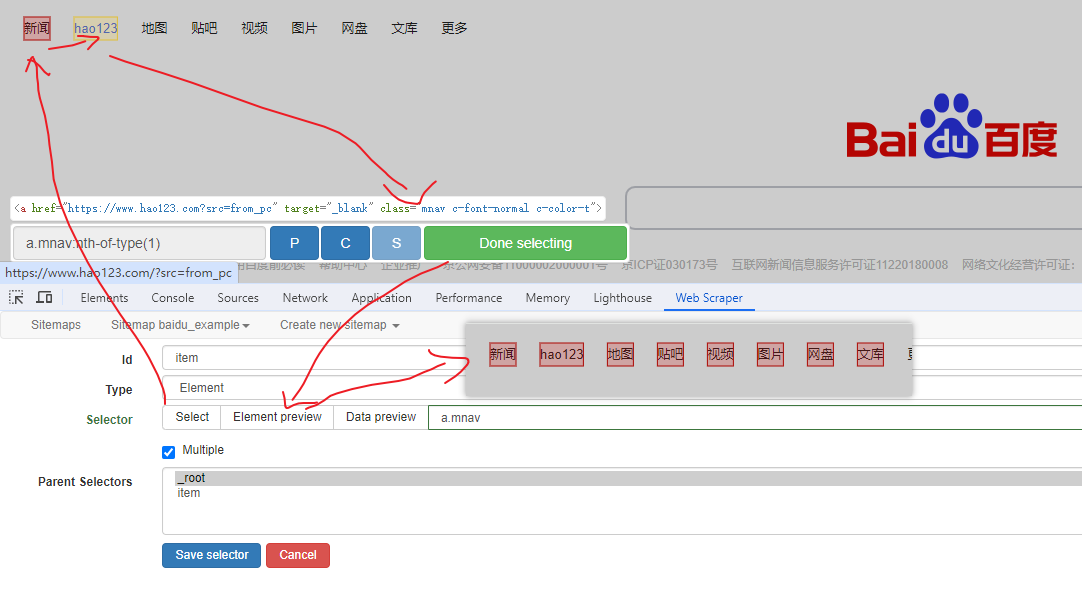
链接选择器
提取链接名字和地址,以 百度首页 为例, 如下:
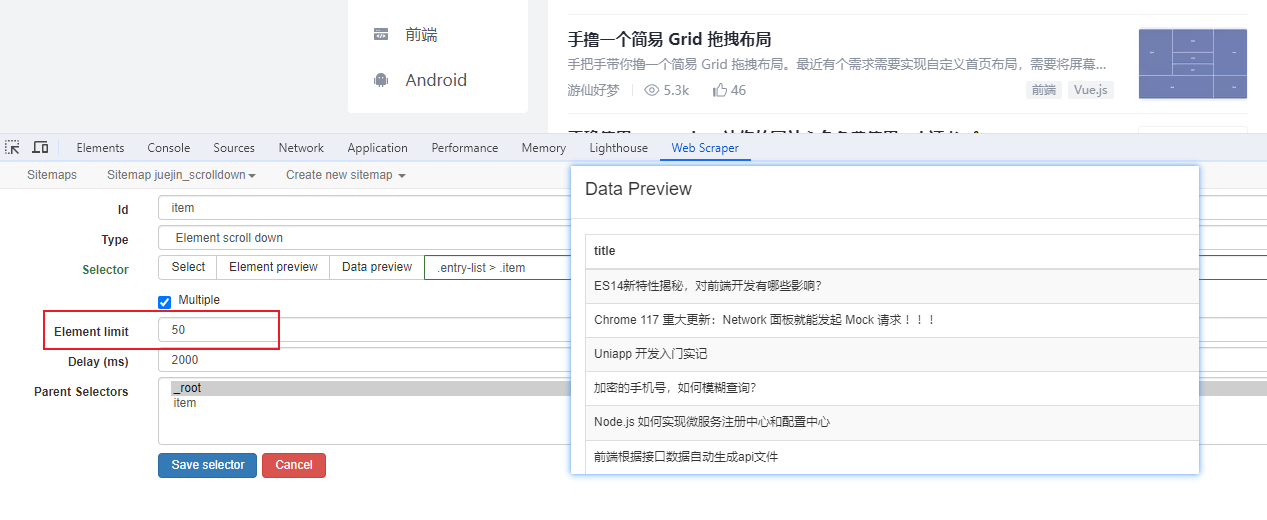
元素点击选择器
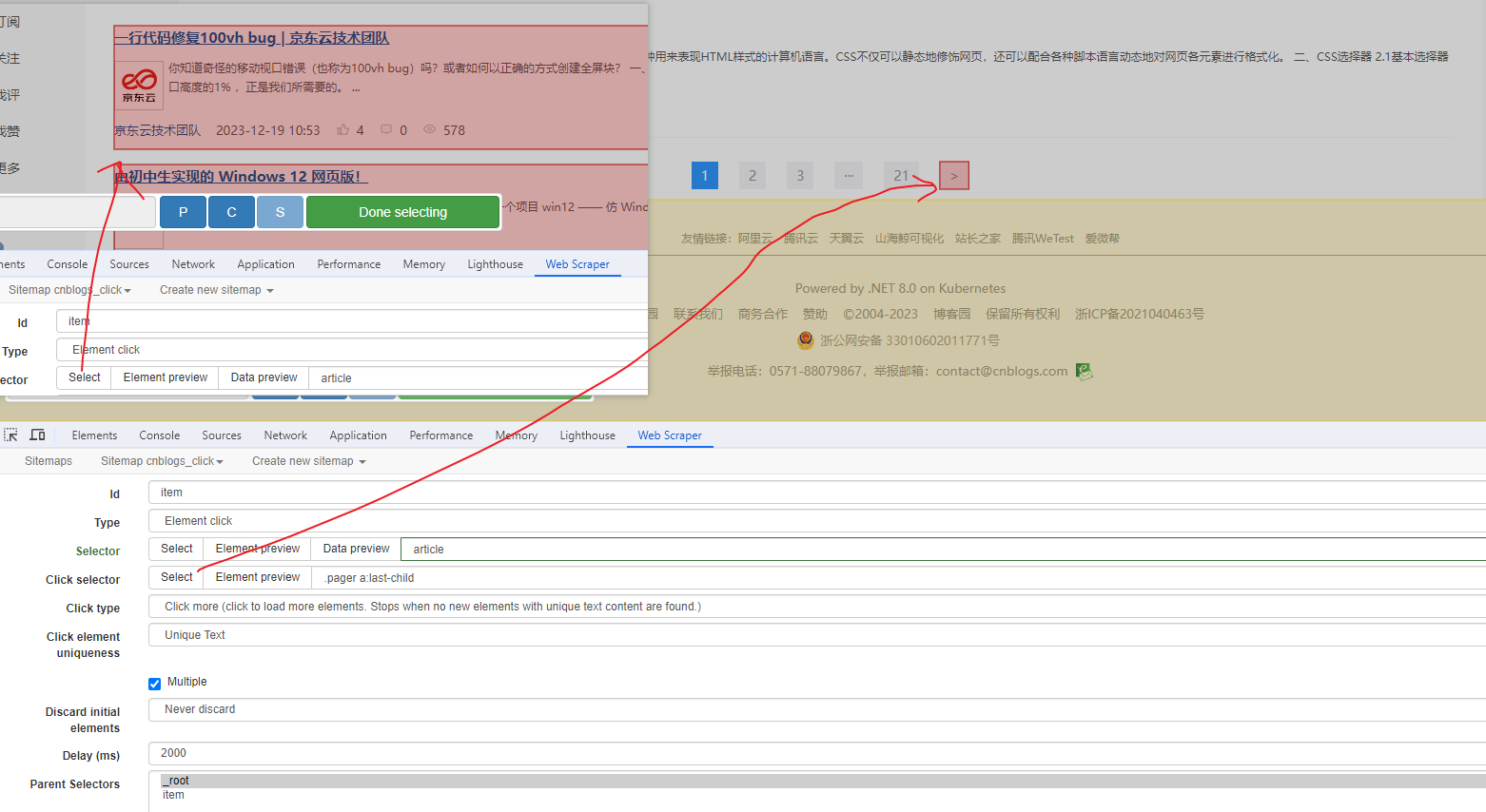
分组选择器
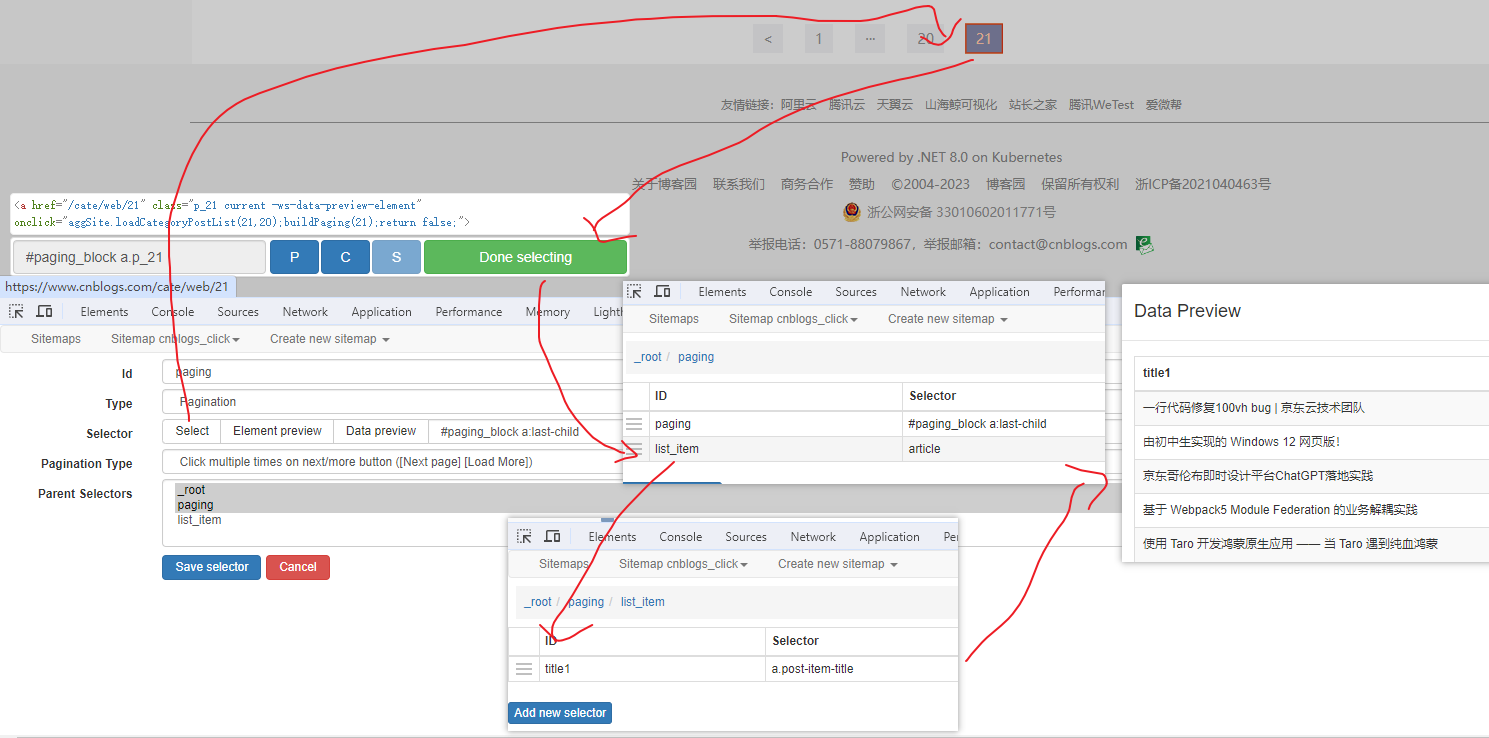
分页选择器
分页查询数据,支持多种类型,比元素滚动选择器、元素点击选择器更强大。值得注意的是,子选择器需放在分页选择器内部。以 博客园WEB分页 为例,模拟上面元素点击选择器的效果,如下:
百度首页 为例, 如下:
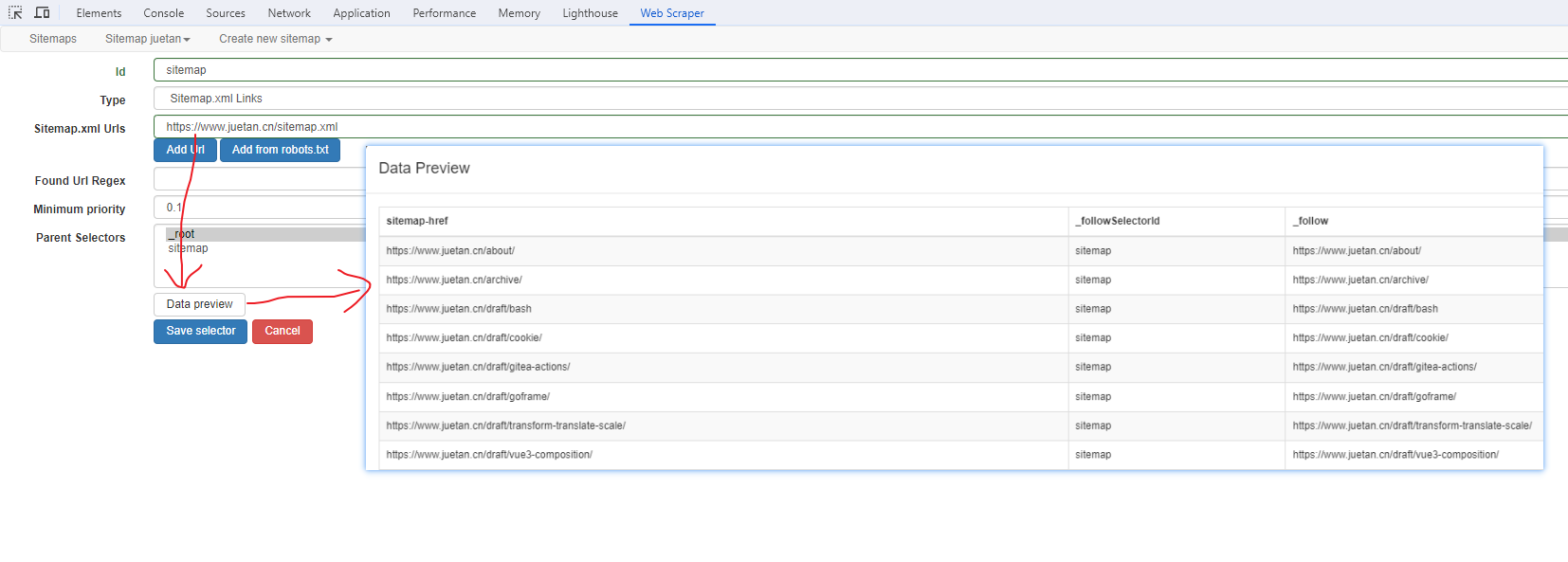
站点地图选择器
这几个比较简单,输入 sitemap.xml 的地址即可,如下:
tips
提取元素,实际是个分组功能。例如,有个列表,每个子项都有名字、链接地址等属性,元素就是包裹这些属性的盒子,可以理解 JS 中的对象。
结语
以上本片的所有内容,你可以利用它去爬取你想要的网页数据例如:知乎、boss直聘、豆瓣等等。