目录
1. 前言
2. 路由定义
3. 路由定义整体源码分析
3.1 partial实现path函数调用
3.2 图解_path函数
3.3 最终
4.URLPattern和Pattern的简单解析
5. 小结
1. 前言
在学习Django框架的时候,我们大多时候都只会使用如何去开发项目,对其实现流程并不是很清楚明了。
这篇文章的目的就是带你先从Django最基础的路由层开始剖析底层源码,一步一步带你学会,Django路由是如何来进行实现的,它的底层又是基于什么来完成的。
2. 路由定义
若你只想看源码解析,请直接跳过当前点
Django的路由定义是在urls.py里面的,我们通过两种形式来定义路由:
- 普通路由定义:path方法
urlpatterns = [
path('test/', views.test),
]第一个参数:路径名
第二个参数:执行的视图函数
- 正则路由定义:re_path方法
from django.urls import path, re_path
from app01 import views
urlpatterns = [
re_path(r'login/(?P<name>\d{4})/', views.login),
]第一个参数:路径+正则匹配
第二个参数:执行的视图函数
补充:
我在这里采用的有名分组,也就是将后面匹配到的参数传递给login函数,并且形参得跟路由定义的分组名一样
加上括号的原因:将匹配到的参数传递给视图函数,不加的话,就不会进行传递,只会进行匹配
- 无名分组:没有名字的分组参数,将参数传递到函数,此时的形参可以任意名字:
urlpatterns = [
re_path(r'login/(\d{4})/', views.login),
]def login(request, vv):
print(vv)
return HttpResponse('code')![]()

- 有名分组:顾名思义,在进行正则匹配的时候,传递一个固定的参数名:
语法:?P<名字>
urlpatterns = [
re_path(r'login/(?P<name>\d{4})/', views.login),
]def login(request, name):
print(name)
return HttpResponse('code')3. 路由定义整体源码分析
ok, 前面上点开胃菜,现在才开始正餐了。
从上面可以看出来,path和re_path已经帮我们都封装好了,我们只需要直接定义就好了,前面写匹配URL,后面写视图函数
那么此时,就会通过我们在网址栏输入的URL来进行相应视图函数的匹配
下面,我们来看path函数的内部实现
3.1 partial实现path函数调用
我们通过ctrl + 左键,点击path函数,可以进入到内部源码进行查看,如下:
path = partial(_path, Pattern=RoutePattern)
这里涉及到partial函数,大致说一下:
partial:可以实现在调用函数之前,固定一部分参数,并且返回一个新函数,
主要用于简化函数的调用,从而封装两个具有部分功能相同的函数,但部分不同的。提高了代码的可维护性和可读性。
用法:
1. 参数一:原函数
2. 关键字参数:原函数的关键字参数,需要固定的一部分参数
可以从源码中,很好的体现这一点:
path = partial(_path, Pattern=RoutePattern) re_path = partial(_path, Pattern=RegexPattern)
path和re_path的共同方法都是_path,都是采用相同的方式进行路由匹配的,但是不同的是他们匹配的方式是不一样的
path是普通的匹配,但是re_path是通过正则的形式来进行匹配的,所以我们通过提前固定好Pattern,来实现两个不同的匹配机制,这使得代码更有维护性,也更方便,只需要更改Pattern,就可以更换不同的匹配模式。
当然,再写path的时候,我们所传递的参数,最终都会通过partial传递给_path
3.2 图解_path函数
我们先直接来看_path的整体
def _path(route, view, kwargs=None, name=None, Pattern=None):
from django.views import View
if kwargs is not None and not isinstance(kwargs, dict):
raise TypeError(
f"kwargs argument must be a dict, but got {kwargs.__class__.__name__}."
)
if isinstance(view, (list, tuple)):
# For include(...) processing.
pattern = Pattern(route, is_endpoint=False)
urlconf_module, app_name, namespace = view
return URLResolver(
pattern,
urlconf_module,
kwargs,
app_name=app_name,
namespace=namespace,
)
elif callable(view):
pattern = Pattern(route, name=name, is_endpoint=True)
return URLPattern(pattern, view, kwargs, name)
elif isinstance(view, View):
view_cls_name = view.__class__.__name__
raise TypeError(
f"view must be a callable, pass {view_cls_name}.as_view(), not "
f"{view_cls_name}()."
)
else:
raise TypeError(
"view must be a callable or a list/tuple in the case of include()."
)直接上图(通过代码 + 图解一步一步分析):

当然,里面有很多其实是不需要的,对于我们现在
我们逐步来进行分析并且删除:
- 第一步

直接看黑色的圈起来的部分,这部分是判断传递进来的是否有kwargs这个额外参数,目前是用不上的,可以直接剔除
- 第二步

这一部分可以看到,这里的isinstance是用于判断view是否是列表或者元组
回到开始,我们传递进来的path参数是一个视图函数 , 是一个函数,所以这部分也可以剔除
path('test/', views.test)
- 第三步

callable 的作用是:判断当前是否为可执行的
函数,肯定是可执行的,所以会走这一层,那么下一层也不需要了
- 最终
最终,我们获得目前的_path函数所需要的内容
def _path(route, view, kwargs=None, name=None, Pattern=None):
from django.views import View
pattern = Pattern(route, name=name, is_endpoint=True)
return URLPattern(pattern, view, kwargs, name)
3.3 最终
可以看到哈,我们最终返回了一个
URLPattern(pattern, view, kwargs, name)
也就是URLPattern对象
在URLPattern中,又封装了Pattern对象,而这个Pattern对象,其实就是最开始我们通过partial传递进来的匹配模式
所以,最终path函数就是这样的:
urlpatterns = [
URLPattern(
Pattern('test/', is_endpoint=True),
views.test,
)
]本质上,就是一个URLPattern的对象
4.URLPattern和Pattern的简单解析
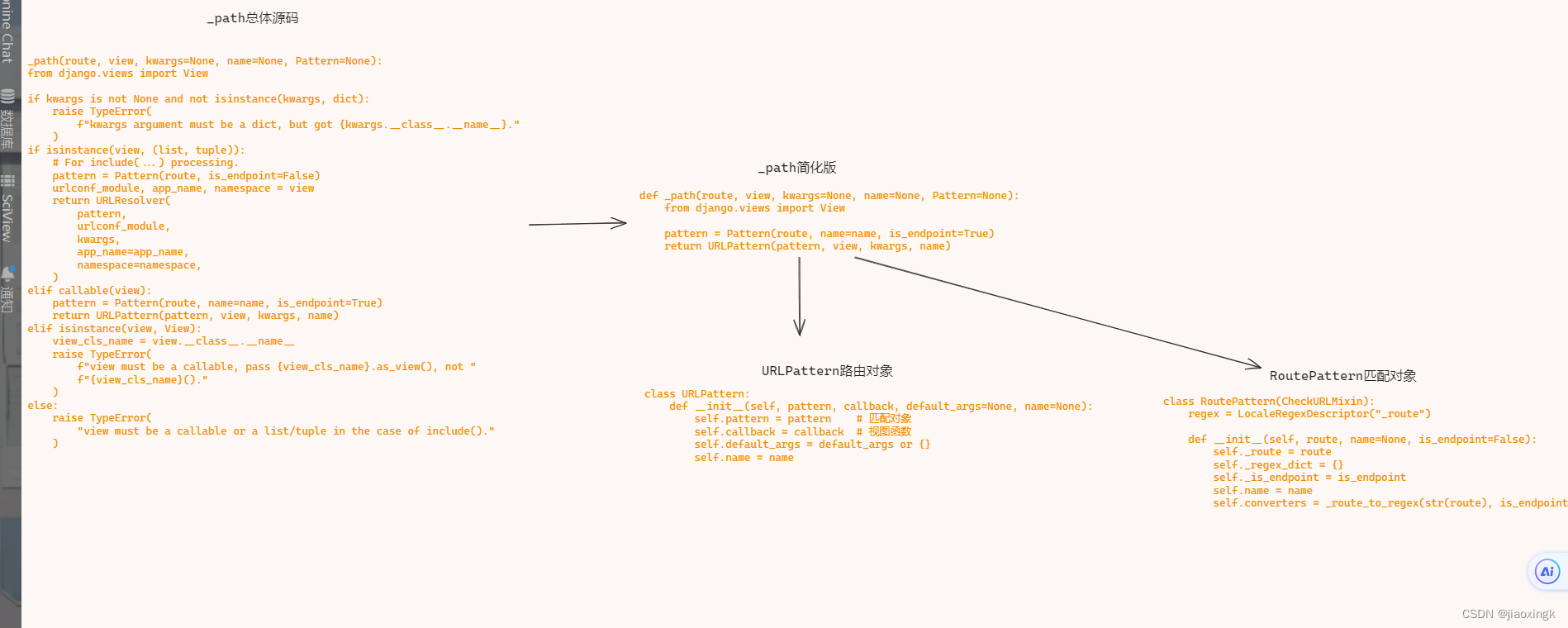
![]()
本质上,URLPattern和Pattern都是两个被封装好的类,一个是路由整体对象,一个是用于路由匹配的匹配模式对象,在这里很好的体现了面向对象的封装性,在后续维护中,我们也能很好的进行修改维护,比如我们需要再添加一个匹配模型,我们可以另外单独定义一个Pattern类,传递给_path,这样就可以使用我们自己的模式匹配了。
5. 小结
当然,本篇文章只是简单介绍了path的底层源码,并没有分析具体的匹配过程,但下一篇文章会继更新相关的匹配过程。
明白了path的底层本质,对于后面我们分析具体的匹配机制,会更加轻松。






![[MSSQL]理解SQL Server AlwaysOn AG的备份](https://img-blog.csdnimg.cn/direct/fbb3cf8c28554ad69d321437742e428d.png)