在数学中,双线性的含义为,二元函数固定任意一个自变量时,函数关于另一个自变量线性
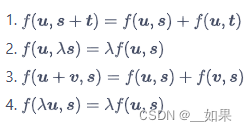
矩阵分解
设想有N个用户和M部电影,构建一个用户画像库,包含每个用户更偏好哪些类型的特征,以及偏好的程度。假设特征的个数是d,那么所有电影的特征构成的矩阵是P∈R^Mxd,用户喜好构成的矩阵是Q∈R^Nxd
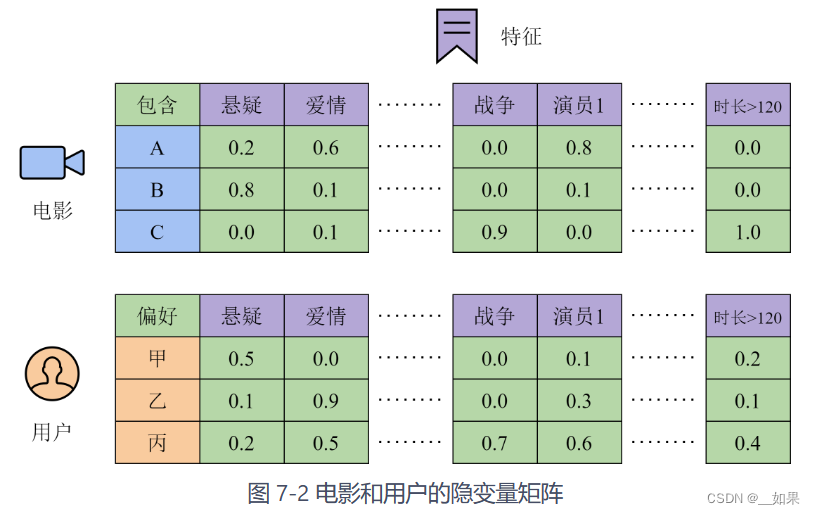
最后,用这两个矩阵的乘积 R = P.T * Q 可以还原出用户对电影的评分。即使用户对某部电影并没有打分,我们也能通过矩阵乘积,根据用户喜欢的特征和该电影具有的特征,预测出用户对电影的喜好程度
实际上,我们通常能获取到的并不是P和Q,而是打分的结果R。并且由于一个用户只会对极其有限的一部分电影打分,矩阵R是非常稀疏的,绝大多数元素都是空白。因此,我们需要从R有限的元素中推测出用户的喜好P和电影的特征Q

变成MSE形式+正则化得到:
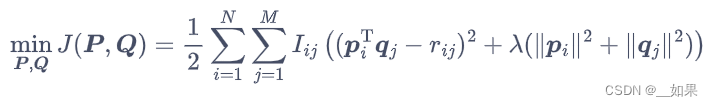
这里的正则化不是针对整个矩阵,而是每一行,因为电影之间、用户之间是相互独立的
对p和q的梯度:
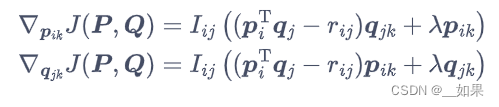
动手实现矩阵分解
import numpy as np
import matplotlib.pyplot as plt
from tqdm import tqdm # 进度条工具
data = np.loadtxt('movielens_100k.csv', delimiter=',', dtype=int)
print('数据集大小:', len(data))
# 用户和电影都是从1开始编号的,我们将其转化为从0开始
data[:, :2] = data[:, :2] - 1
# 计算用户和电影数量
users = set()
items = set()
for i, j, k in data:
users.add(i)
items.add(j)
user_num = len(users)
item_num = len(items)
print(f'用户数:{user_num},电影数:{item_num}')
# 设置随机种子,划分训练集与测试集
np.random.seed(0)
ratio = 0.8
split = int(len(data) * ratio)
np.random.shuffle(data)
train = data[:split]
test = data[split:]
# 统计训练集中每个用户和电影出现的数量,作为正则化的权重
user_cnt = np.bincount(train[:, 0], minlength=user_num)
item_cnt = np.bincount(train[:, 1], minlength=item_num)
print(user_cnt[:10])
print(item_cnt[:10])
# 用户和电影的编号要作为下标,必须保存为整数
user_train, user_test = train[:, 0], test[:, 0]
item_train, item_test = train[:, 1], test[:, 1]
y_train, y_test = train[:, 2], test[:, 2]用set去重
user_cnt用np.bincount计算数组 train 中第一列中每个元素出现的次数
class MF:
def __init__(self, N, M, d):
# N是用户数量,M是电影数量,d是特征维度
# 定义模型参数
self.user_params = np.ones((N, d))
self.item_params = np.ones((M, d))
def pred(self, user_id, item_id):
# 预测用户user_id对电影item_id的打分
# 获得用户偏好和电影特征
user_param = self.user_params[user_id]
item_param = self.item_params[item_id]
# 返回预测的评分
rating_pred = np.sum(user_param * item_param, axis=1)
return rating_pred
def update(self, user_grad, item_grad, lr):
# 根据参数的梯度更新参数
self.user_params -= lr * user_grad
self.item_params -= lr * item_grad给定用户 ID 和电影 ID,计算用户参数和电影参数的乘积,并返回预测的评分
def train(model, learning_rate, lbd, max_training_step, batch_size):
train_losses = []
test_losses = []
batch_num = int(np.ceil(len(user_train) / batch_size))
with tqdm(range(max_training_step * batch_num)) as pbar:
for epoch in range(max_training_step):
# 随机梯度下降
train_rmse = 0
for i in range(batch_num):
# 获取当前批量
st = i * batch_size
ed = min(len(user_train), st + batch_size)
user_batch = user_train[st: ed]
item_batch = item_train[st: ed]
y_batch = y_train[st: ed]
# 计算模型预测
y_pred = model.pred(user_batch, item_batch)
# 计算梯度
P = model.user_params
Q = model.item_params
errs = y_batch - y_pred
P_grad = np.zeros_like(P)
Q_grad = np.zeros_like(Q)
for user, item, err in zip(user_batch, item_batch, errs):
P_grad[user] = P_grad[user] - err * Q[item] + lbd * P[user]
Q_grad[item] = Q_grad[item] - err * P[user] + lbd * Q[item]
model.update(P_grad / len(user_batch), Q_grad / len(user_batch), learning_rate)
train_rmse += np.mean(errs ** 2)
# 更新进度条
pbar.set_postfix({
'Epoch': epoch,
'Train RMSE': f'{np.sqrt(train_rmse / (i + 1)):.4f}',
'Test RMSE': f'{test_losses[-1]:.4f}' if test_losses else None
})
pbar.update(1)
# 计算测试集上的RMSE
train_rmse = np.sqrt(train_rmse / len(user_train))
train_losses.append(train_rmse)
y_test_pred = model.pred(user_test, item_test)
test_rmse = np.sqrt(np.mean((y_test - y_test_pred) ** 2))
test_losses.append(test_rmse)
return train_losses, test_lossesnp.ceil 用于计算数组中每个元素的向上取整值
遍历训练集中的每个批量,进行随机梯度下降训练
根据梯度公式求梯度,并根据批大小调整
通过 set_postfix 方法设置进度条的附加信息,在更新完附加信息后,使用 pbar.update(1) 更新进度条,使其前进一步
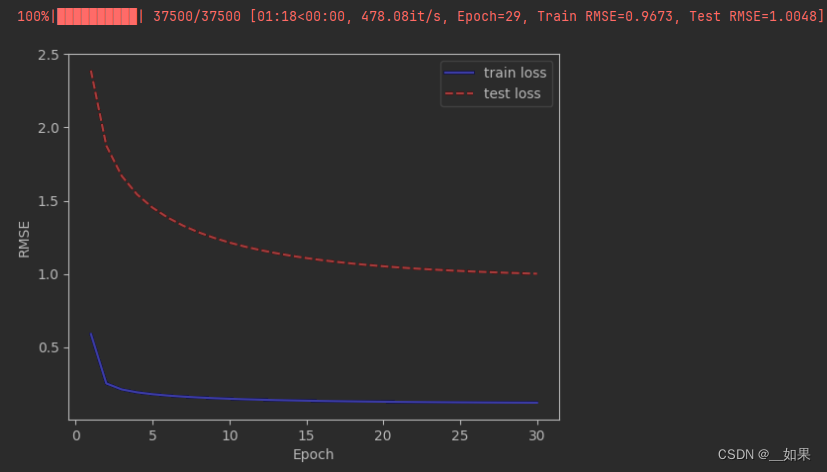
pred的结果:也差不多相差1

因子分解机
FM 的应用场景与 MF 有一些区别,MF 的目标是从交互的结果中计算出用户和物品的特征;而 FM 则正好相反,希望通过物品的特征和某个用户点击这些物品的历史记录,预测该用户点击其他物品的概率,即点击率(click through rate,CTR)
由于被点击和未被点击是一个二分类问题,CTR 预估可以用逻辑斯谛回归模型来解决,然而逻辑回归的线性参数化假设中不同的特征xi与xj之间并没有运算,因此需要进一步引入双线性部分:
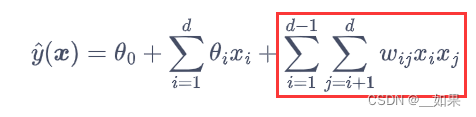
写成向量形式:
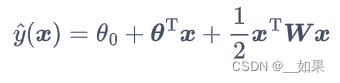
物体的特征向量one-hot后会过于稀疏,y(x)对w求导后得到的xixj大多地方都是0,所以难以对wij更新

从该结果中可以看出,只要xs≠0,参数的梯度vs就不为零,可以用梯度相关的算法对其更新。因此,即使特征向量非常稀疏,FM 模型也可以正常进行训练
模型还存在一个问题。双线性模型考虑不同特征之间乘积的做法,虽然提升了模型的能力,但也引入了额外的计算开销。可以对上面的公式做一些变形,改变计算顺序来降低时间复杂度
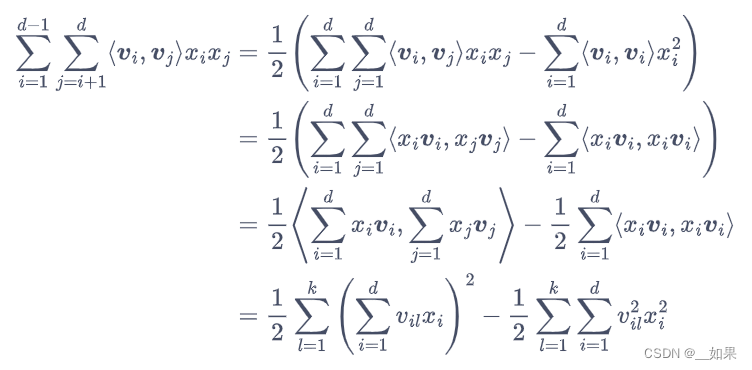
至此,FM 的预测公式为:
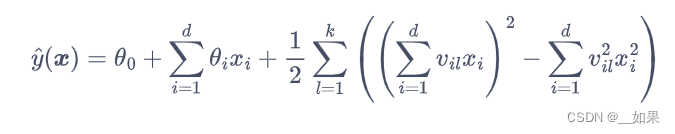
动手实现因子分解机
class FM:
def __init__(self, feature_num, vector_dim):
# vector_dim代表公式中的k,为向量v的维度
self.theta0 = 0.0 # 常数项
self.theta = np.zeros(feature_num) # 线性参数
self.v = np.random.normal(size=(feature_num, vector_dim)) # 双线性参数
self.eps = 1e-6 # 精度参数
def _logistic(self, x):
# 工具函数,用于将预测转化为概率
return 1 / (1 + np.exp(-x))
def pred(self, x):
# 线性部分
linear_term = self.theta0 + x @ self.theta
# 双线性部分
square_of_sum = np.square(x @ self.v)
sum_of_square = np.square(x) @ np.square(self.v)
# 最终预测
y_pred = self._logistic(linear_term \
+ 0.5 * np.sum(square_of_sum - sum_of_square, axis=1))
# 为了防止后续梯度过大,对预测值进行裁剪,将其限制在某一范围内
y_pred = np.clip(y_pred, self.eps, 1 - self.eps)
return y_pred
def update(self, grad0, grad_theta, grad_v, lr):
self.theta0 -= lr * grad0
self.theta -= lr * grad_theta
self.v -= lr * grad_vnp.clip将预测值限制在 [self.eps, 1 - self.eps] 的范围内,如果预测值超出了这个范围,就将其设置为边界值(因为用了sigmoid)
习题
1.B。只要有不为0的特征就能训练
2.C。C不涉及θ1和θ2之间的乘积或内积,因此不是一个双线性模型;D不是标准的双线性形式,但它可以被视为双线性的,它涉及到了θ1和θ2的乘积
3.题目中这种编码方式叫作label encoder
避免顺序假设: Label Encoder 将类别按照它们出现的顺序进行编码,这可能会给模型引入错误的假设,认为类别之间存在顺序关系
避免偏好性: Label Encoder 可能会给编码后的类别赋予不同的数值,这可能导致模型在训练过程中对数值较大的类别产生偏好
适用性广泛: One-Hot Encoder 适用于大多数机器学习模型,包括线性模型、树模型等
4.
class MF:
def __init__(self, N, M, d):
# N是用户数量,M是电影数量,d是特征维度
# 定义模型参数
self.user_params = np.ones((N, d))
self.item_params = np.ones((M, d))
self.global_bias = 0.0 # 全局打分偏置
self.user_bias = np.zeros(N) # 用户打分偏置
self.item_bias = np.zeros(M) # 物品打分偏置
def pred(self, user_id, item_id):
# 预测用户user_id对电影item_id的打分
# 获得用户偏好和电影特征
user_param = self.user_params[user_id]
item_param = self.item_params[item_id]
# 计算预测分数
pred_score = np.sum(user_param * item_param, axis=1)
pred_score += self.global_bias # 添加全局打分偏置
pred_score += self.user_bias[user_id] # 添加用户打分偏置
pred_score += self.item_bias[item_id] # 添加物品打分偏置
return pred_score
def update(self, user_grad, item_grad, global_bias_grad, user_bias_grad, item_bias_grad, lr):
# 根据参数的梯度更新参数
self.user_params -= lr * user_grad
self.item_params -= lr * item_grad
self.global_bias -= lr * global_bias_grad
self.user_bias -= lr * user_bias_grad
self.item_bias -= lr * item_bias_grad
def train(model, learning_rate, lbd, max_training_step, batch_size):
train_losses = []
test_losses = []
batch_num = int(np.ceil(len(user_train) / batch_size))
with tqdm(range(max_training_step * batch_num)) as pbar:
for epoch in range(max_training_step):
# 随机梯度下降
train_rmse = 0
for i in range(batch_num):
# 获取当前批量
st = i * batch_size
ed = min(len(user_train), st + batch_size)
user_batch = user_train[st: ed]
item_batch = item_train[st: ed]
y_batch = y_train[st: ed]
# 计算模型预测
y_pred = model.pred(user_batch, item_batch)
# 计算梯度
P = model.user_params
Q = model.item_params
errs = y_batch - y_pred
P_grad = np.zeros_like(P)
Q_grad = np.zeros_like(Q)
# 计算全局打分偏置、用户打分偏置和物品打分偏置的梯度
global_bias_grad = -np.mean(errs) # 全局打分偏置梯度
user_bias_grad = np.zeros_like(model.user_bias)
item_bias_grad = np.zeros_like(model.item_bias)
for user, item, err in zip(user_batch, item_batch, errs):
user_bias_grad[user] += -err
item_bias_grad[item] += -err
P_grad[user] = P_grad[user] - err * Q[item] + lbd * P[user]
Q_grad[item] = Q_grad[item] - err * P[user] + lbd * Q[item]
model.update(P_grad / len(user_batch), Q_grad / len(user_batch),
global_bias_grad, user_bias_grad / len(user_batch),
item_bias_grad / len(user_batch), learning_rate)
train_rmse += np.mean(errs ** 2)
# 更新进度条
pbar.set_postfix({
'Epoch': epoch,
'Train RMSE': f'{np.sqrt(train_rmse / (i + 1)):.4f}',
'Test RMSE': f'{test_losses[-1]:.4f}' if test_losses else None
})
pbar.update(1)
# 计算 RMSE 损失
train_rmse = np.sqrt(train_rmse / len(user_train))
train_losses.append(train_rmse)
y_test_pred = model.pred(user_test, item_test)
test_rmse = np.sqrt(np.mean((y_test - y_test_pred) ** 2))
test_losses.append(test_rmse)
return train_losses, test_losses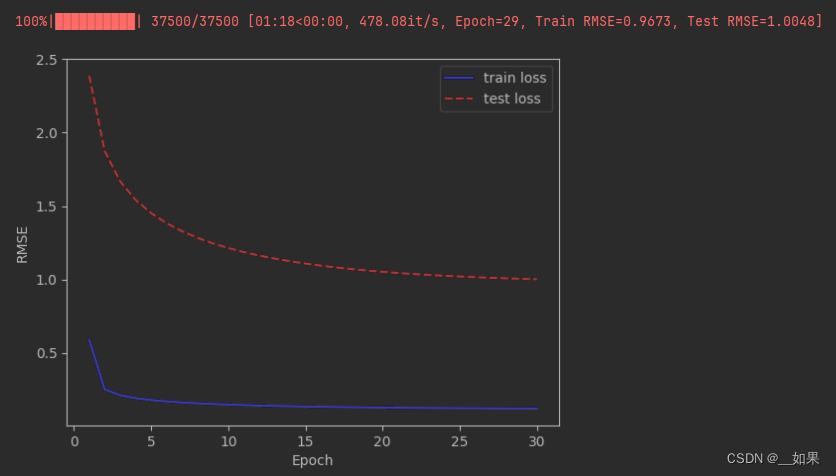
之前
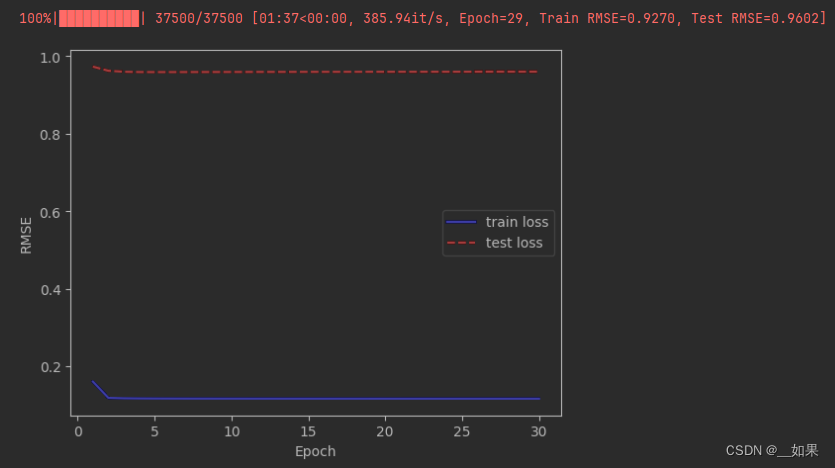
加了之后可以看到loss低了
5.略
6.对不起,做不到>_<






![[html]基础知识点汇总](https://img-blog.csdnimg.cn/direct/720b002beb454909bd5bb68060582374.png)