1 查询/索引部分
1.1 层次索引

- 创建两个索引——一个由摘要组成,另一个由文档块组成
- 分两步进行搜索:首先通过摘要过滤出相关文档,接着只在这个相关群体内进行搜索
1.2 假设性问题
- 让LLM为每个块生成一个假设性问题,并将这些问题以向量形式嵌入
- 在运行时,针对这个问题向量的索引进行查询搜索(用问题向量替换文档的块向量)
- 检索后将原始文本块作为上下文发送给LLM以获取答案
- 这种方法由于查询和假设性问题之间的语义相似性更高,从而提高了搜索质量
1.3 句子窗口检索
- 文档中的每个句子都被单独嵌入向量
- 在检索到的关键句子前后各扩展k个句子,然后将这个扩展的上下文发送给LLM

1.4 父文档检索器(自动合并检索器)
- 文档被分割成一个层级化的块结构,随后用最小的叶子块进行索引
- 在检索过程中检索出top k个叶子块
- 如果存在n个叶子块都指向同一个更大的父块,那么我们就用这个父块来替换这些子块,并将其送入大模型用于生成答案。

1.4 查询扩展
1.4.1 使用生成的答案进行查询扩展
Precise Zero-Shot Dense Retrieval without Relevance Labels
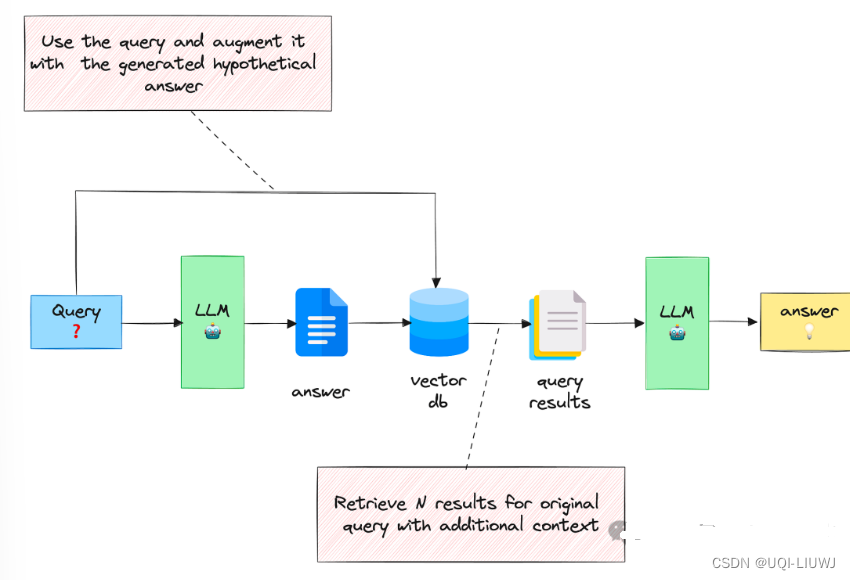
- 给定输入查询后,这种方法首先会指示 LLM 提供一个假设答案,无论其正确性如何
- 然后,将查询和生成的答案合并在一个提示中,并发送给检索系统
- 基本目的是希望检索到更像答案的文档。
- 假设答案的正确性并不重要,因为感兴趣的是它的结构和表述
1.4.2 用多个相关问题扩展查询
Query Expansion by Prompting Large Language Models
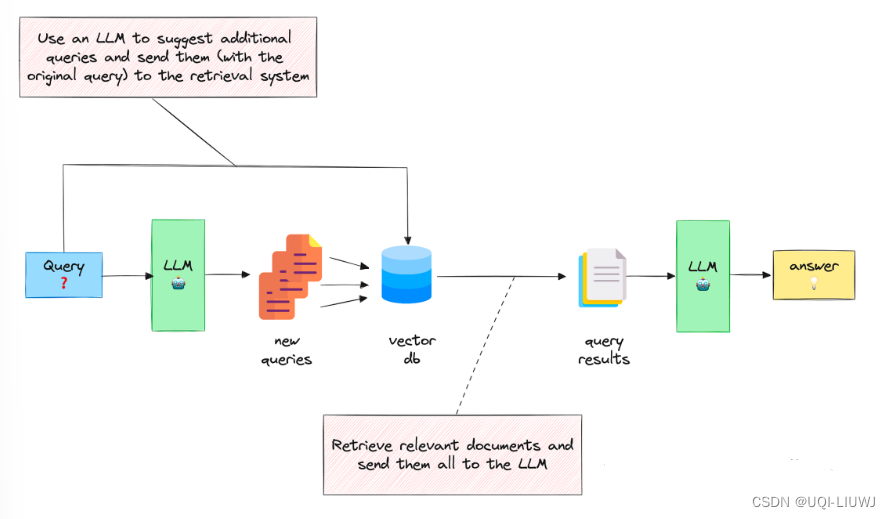
- 利用 LLM 生成 N 个与原始查询相关的问题
- 将所有问题(加上原始查询)发送给检索系统。
- 通过这种方法,可以从向量库中检索到更多文档。
1.4.3RAG-Fusion
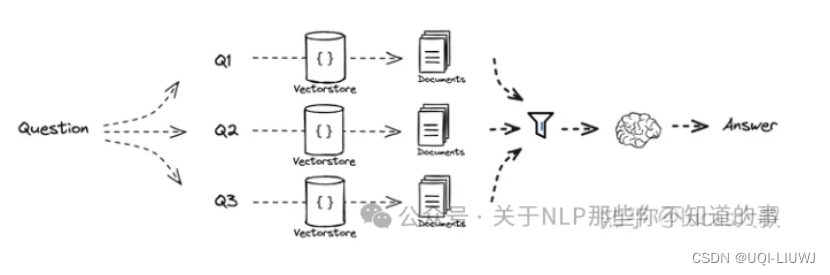
- 首先根据原始question从不同角度生成多个版本的新question
- 然后针对每个question进行向量检索
- 在喂给LLM生成答案之前增加了一个排序的步骤
- 排序包含两个动作
- 一是独立对每个question检索返回的内容根据相似度排序,确定每个返回chunk在各自候选集中的位置,相似度越高排名越靠前。
- 对所有question 返回的内容利用RRF(Reciprocal Rank Fusion)综合排序
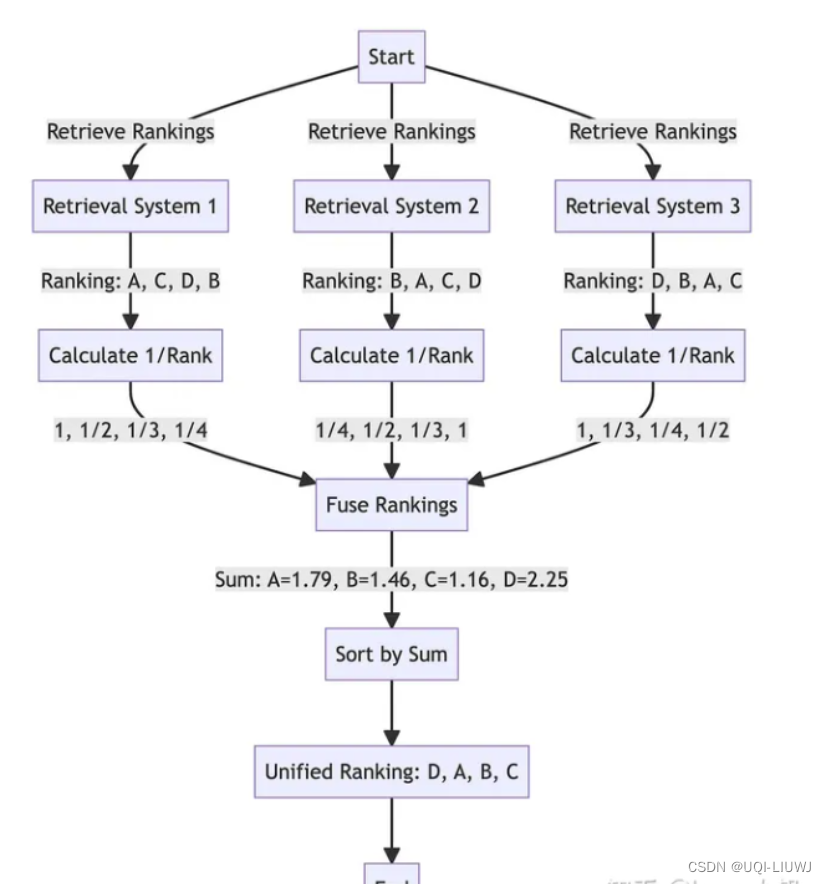
- 这里rank计算的结果可能有问题,总之就是根据不同的question,得到不同的检索结果组合;分别计算他们各自的1/rank,然后加总,再排序
- 排序包含两个动作
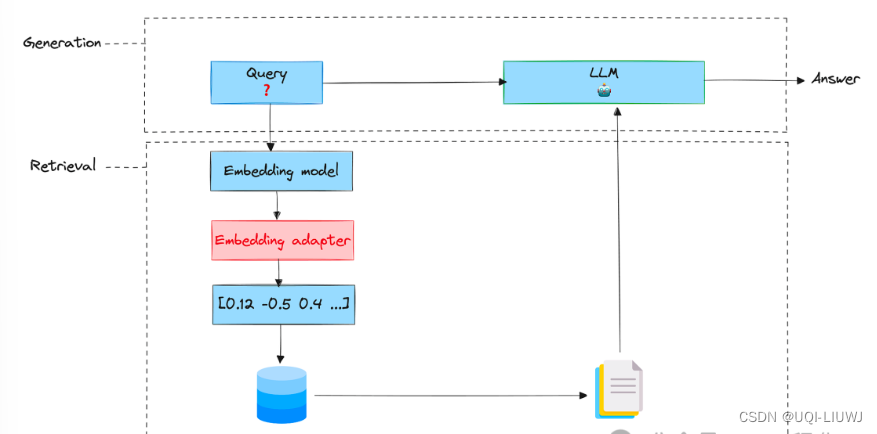
1.5 嵌入适配器
- 训练适配器的根本目的是改变嵌入查询,从而为特定任务产生更好的检索结果。
- 嵌入适配器是在嵌入阶段之后、检索之前插入的一个阶段。
- 可以把它想象成一个矩阵(带有经过训练的权重)
1.6 混合检索
- 将字面相似的传统搜索算法(Best Matching 25, BM25)与向量相似性检索相结合,实现混合搜索
- 可以加权融合分数、取各自topk检索后并集或RRF+Rerank
参考内容:
提升RAG检索质量的三个高级技巧(查询扩展、交叉编码器重排序和嵌入适配器)
从0开始学RAG之RAG-Fusion