论文题目:Vision Mamba: Efficient Visual Representation Learning with Bidirectional State Space Model
双向状态空间模型下的高效视觉表示学习
论文链接:http://arxiv.org/abs/2401.09417
代码链接:https://github.com/hustvl/Vim
1、摘要
双向 Mamba 块(Vim) 通过为图像序列添加位置嵌入,并利用双向 SSMs 压缩视觉表示。
具有高效硬件设计的状态空间模型State Space Models(SSMs),如Mamba深度学习模型,在长序列建模方面展现出巨大潜力,比 Transformers 等模型更好地处理长序列。
2、关键问题
1、对于处理图像和视频等视觉数据的通用纯SSM基干网络,尚未进行深入探索。
2、Transformer中的自注意力机制在处理长程视觉依赖,如处理高分辨率图像时,面临着速度和内存使用的问题。
3、对比
与针对视觉任务的其他SSM模型相比,Vim是一个纯SSM方法,以序列方式处理图像,对于通用和高效的基干网络更具前景。由于双向压缩建模和位置感知,Vim是首个处理密集预测任务的纯SSM模型。与最具有说服力的Transformer模型(如DeiT[59])相比,Vim在ImageNet分类任务上表现出色。此外,对于高分辨率图像,Vim在GPU内存和推理时间上更高效。这种内存和速度效率使得Vim可以直接进行顺序视觉表示学习,无需依赖于2D先验(如ViTDet[37]中的2D局部窗口)来理解高分辨率视觉任务,同时在准确性上超过DeiT。
4、原理
(1) Preliminaries预备知识
基于状态空间模型(SSM)的模型,如结构化状态空间序列模型(S4)和Mamba,其灵感来源于连续系统,该系统通过隐藏状态
h
(
t
)
∈
R
N
h(t) ∈ R^{N}
h(t)∈RN将一维函数或序列
x
(
t
)
∈
R
x(t) ∈ R
x(t)∈R映射到输出
y
(
t
)
∈
R
y(t) ∈ R
y(t)∈R。这个系统使用
A
∈
R
N
×
N
A ∈ R^{N \times N}
A∈RN×N作为演化参数,
B
∈
R
N
×
1
B ∈ R^{N \times 1}
B∈RN×1 和
C
∈
R
1
×
N
C ∈ R^{1 \times N}
C∈R1×N作为投影参数,其工作原理如下:
h ′ ( t ) = A h ( t ) + B x ( t ) , y ( t ) = C h ( t ) . ( 1 ) h'(t) = A h(t) + B x(t),y(t) = C h(t). (1) h′(t)=Ah(t)+Bx(t),y(t)=Ch(t).(1)
S4和Mamba是连续系统的离散版本,引入了一个时间尺度参数Δ,用于将连续参数A和B转换为离散参数A和B。常用的转换方法是零阶保持(ZOH),定义如下:
A = e x p ( Δ A ) , B = ( Δ A ) − 1 ∗ ( e x p ( Δ A ) − I ) ∗ Δ B . ( 2 ) A = exp(\Delta A),B = (\Delta A)^{-1} * (exp(\Delta A) - I) * \Delta B. (2) A=exp(ΔA),B=(ΔA)−1∗(exp(ΔA)−I)∗ΔB.(2)
在离散化A和B后,使用步长 Δ \Delta Δ的离散化版本的式(1)可以重写为:
h t = A h t − 1 + B x t , y t = C h t . ( 3 ) h_t = Ah_{t-1} + Bx_t,y_t = Ch_t. (3) ht=Aht−1+Bxt,yt=Cht.(3)
最后,这些模型通过全局卷积计算输出:
K = ( C B , C A B , . . . , C A M − 1 B ) , y = x ∗ K , ( 4 ) K = (CB, CAB, ..., CA^{M-1}B),y = x * K,(4) K=(CB,CAB,...,CAM−1B),y=x∗K,(4)
其中M是输入序列 x x x的长度, K ∈ R M K ∈ R^{M} K∈RM是一个结构化的卷积核。
(2) Vision Mamba

图2展示了所提出的Vim的概览。标准的Mamba是为一维序列设计的。为了处理视觉任务,首先将二维图像
t
∈
R
(
H
×
W
×
C
)
t ∈ R^{(H \times W \times C)}
t∈R(H×W×C)转换为扁平化的二维图像块
x
p
∈
R
J
×
P
2
×
C
x_{p}∈ R^{J \times P^{2} \times C}
xp∈RJ×P2×C,其中
(
H
,
W
)
(H, W)
(H,W)是输入图像的大小,
C
C
C是通道数,
P
P
P是图像块的大小。接着,线性地将
x
p
x_p
xp投影到大小为
D
D
D的向量,并添加位置嵌入
E
p
o
s
∈
R
(
J
+
1
)
×
D
E_{pos} ∈ R(J+1) \times D
Epos∈R(J+1)×D,如下所示:
T
0
=
[
t
c
l
s
;
t
p
1
W
;
t
p
2
W
;
.
.
.
;
t
p
J
W
]
+
E
p
o
s
,
(
5
)
T_0 = [t_{cls}; t^{1}_{p}W; t^{2}_{p}W; ...; t^{J}_{p}W] + E_{pos}, (5)
T0=[tcls;tp1W;tp2W;...;tpJW]+Epos,(5)
其中
t
p
j
t^{j}_{p}
tpj是
t
t
t的第
j
j
j个块,
W
∈
R
P
2
×
C
×
D
W ∈ R^{P^{2} \times C \times D}
W∈RP2×C×D是可学习的投影矩阵。受ViT [13]和BERT [30]的启发,文中还使用class token来表示整个块序列,表示为
t
c
l
s
t_{cls}
tcls。然后,将token序列(
T
l
−
1
T_{l-1}
Tl−1)传递给Vim编码器的第
l
l
l层,得到输出
T
l
T_{l}
Tl。最后,规范化输出的class token
T
L
0
T^{0}_{L}
TL0,并将其输入到多层感知器(MLP)头中,以获取最终预测
p
p
p,如下:
T
l
=
V
i
m
(
T
l
−
1
)
+
T
l
−
1
,
f
=
N
o
r
m
(
T
L
0
)
,
p
=
M
L
P
(
f
)
,
(
6
)
T_{l} = Vim(T_{l-1}) + T_{l-1}, f = Norm(T^{0}_{L}), p = MLP(f), (6)
Tl=Vim(Tl−1)+Tl−1,f=Norm(TL0),p=MLP(f),(6)
其中Vim是提出的视觉Mamba块,L是层数,Norm是归一化层。
(3) Vim Block
Vim块为视觉任务融合了双向序列建模。Vim块如图2所示。Vim Block流程图如下:

操作流程:首先,输入的token序列 T l − 1 T_{l-1} Tl−1 通过归一化层进行标准化。接着,将标准化的序列线性映射到维度大小为 E E E的x和z轴。然后,分别从正向和反向处理 x x x。对于每个方向,首先对x应用一维卷积,得到 x o ′ x'_{o} xo′ 。接着,将 x o ′ x'_{o} xo′ 线性映射到 B o B_{o} Bo, C o C_{o} Co和 δ o \delta_{o} δo,然后将 δ o \delta_{o} δo 分别转换为 A ˉ o \bar A_{o} Aˉo、 B ˉ o \bar B_{o} Bˉo。最后通过 SSM计算 y f o r w a r d y_{forward} yforward 和 y b a c k w a r d y_{backward} ybackward。然后, y f o r w a r d y_{forward} yforward 和 y b a c k w a r d y_{backward} ybackward被 z z z门控并相加得到输出token序列 T l T_{l} Tl。
总结来说,架构超参数总结如下:
L:块的数量,D:隐藏状态维度,E:扩展状态维度,N:状态空间模型(SSM)维度。
文中遵循ViT [13] 和DeiT [60] 的做法,首先使用内核大小为 16 × 16 16 \times 16 16×16的投影层,将图像划分为非重叠的嵌入序列。接着,直接堆叠 L L L个Vim块。默认情况下,设置块的数量 L L L为24,SSM维度 N N N为16。为了与DeiT系列的模型大小对齐。对于tiny尺寸变体,将隐藏状态维度 D D D设置为192,扩展状态维度 E E E设置为384。对于small尺寸变体,将 D D D设置为384, E E E设置为768。
(4) Efficiency Analysis
传统基于状态空间模型(SSM)的方法利用快速傅立叶变换(FFT)来提升卷积操作,如公式(4)所示。对于数据依赖型方法,如Mamba,其内存效率主要体现在:为避免内存溢出问题并降低处理长序列时的内存消耗,Vim采取了与Mamba相同的重计算策略。在计算大小为(B, M, E, N)中间状态的梯度时,Vim在网络反向传播阶段重新计算这些状态。对于诸如激活函数输出和卷积的中间激活,Vim也会重新计算,以优化GPU内存需求,因为激活值占用大量内存,但重计算速度较快。
计算效率方面:Vim块中的状态空间模型(见算法流程图中的第11行)和Transformer中的自注意力机制都起着关键作用,它们能自适应地提供全局上下文信息。对于一个视觉序列
T
∈
R
(
1
×
M
×
D
)
T ∈ R^{(1 \times M \times D)}
T∈R(1×M×D),假设默认设置
E
=
2
D
E = 2D
E=2D,全局自注意力和SSM的计算复杂度分别为:
Ω
(
s
e
l
f
−
a
t
t
e
n
t
i
o
n
)
=
4
M
D
2
+
2
M
2
D
,
(
7
)
Ω(self-attention) = 4MD^{2} + 2M^{2}D, (7)
Ω(self−attention)=4MD2+2M2D,(7)
Ω
(
S
S
M
)
=
3
M
(
2
D
)
N
+
M
(
2
D
)
N
,
(
8
)
Ω(SSM) = 3M(2D)N + M(2D)N, (8)
Ω(SSM)=3M(2D)N+M(2D)N,(8)
其中,自注意力的计算复杂度与序列长度
M
M
M的平方成正比,而SSM则与序列长度M线性相关(N是一个固定的参数,通常默认设置为16)。这种计算效率使得Vim能够应对具有大序列长度的高分辨率应用,实现可扩展性。
5、实验
1、Image Classification
实验设置:在ImageNet-1K数据集上对Vim进行基准测试,该数据集包含128万张训练图像和5万张验证图像,涵盖1000个类别。所有模型都在训练集上进行训练,并在验证集上报告Top-1精度。为了公平比较,训练设置主要遵循DeiT的方法[60]。具体来说,应用随机裁剪、随机水平翻转、标签平滑正则化、混合增强和随机遮挡作为数据增强。当使用224×224的输入图像训练时,我们使用AdamW优化器[43],动量为0.9,总批次大小为1024,权重衰减为0.05。我们使用余弦退火策略训练300个epoch,初始学习率为 1 × 1 0 − 3 1×10^{-3} 1×10−3,并使用EMA。测试阶段在验证集上应用中心裁剪,以获取224×224的图像。实验在8个A800 GPU上进行。
长序列微调:为了充分利用Vim高效处理长序列的能力,在ImageNet预训练后,继续使用长序列设置对Vim进行30个epoch的微调。具体来说,设置提取块的步长为8,保持块大小不变,恒定学习率为
1
×
1
0
−
5
1×10^{-5}
1×10−5,权重衰减为
1
×
1
0
−
8
1×10^{-8}
1×10−8。与基于卷积的ResNet[24]相比,Vim表现出更好的性能。
例如,当参数数量相近时,Vim-Small的Top-1精度达到80.5,比ResNet50高出4.3个百分点。与传统的基于自注意力的ViT[13]相比,Vim在参数数量和分类精度上都有显著优势。
例如,Vim-Tiny相对于DeiT-Tiny的Top-1精度高出3.9个百分点,Vim-Small相对于DeiT-Small高出0.7个百分点。与基于SSM的S4ND-ViT-B[46]相比,Vim在参数更少的情况下达到更高的Top-1精度。经过长序列微调后,Vim-Tiny和Vim-S的表现都有所提升。其中,Vim-S甚至达到与DeiT-B相当的结果。这些结果表明,Vim能够轻松适应更长序列建模,并提取出更强的视觉表示。
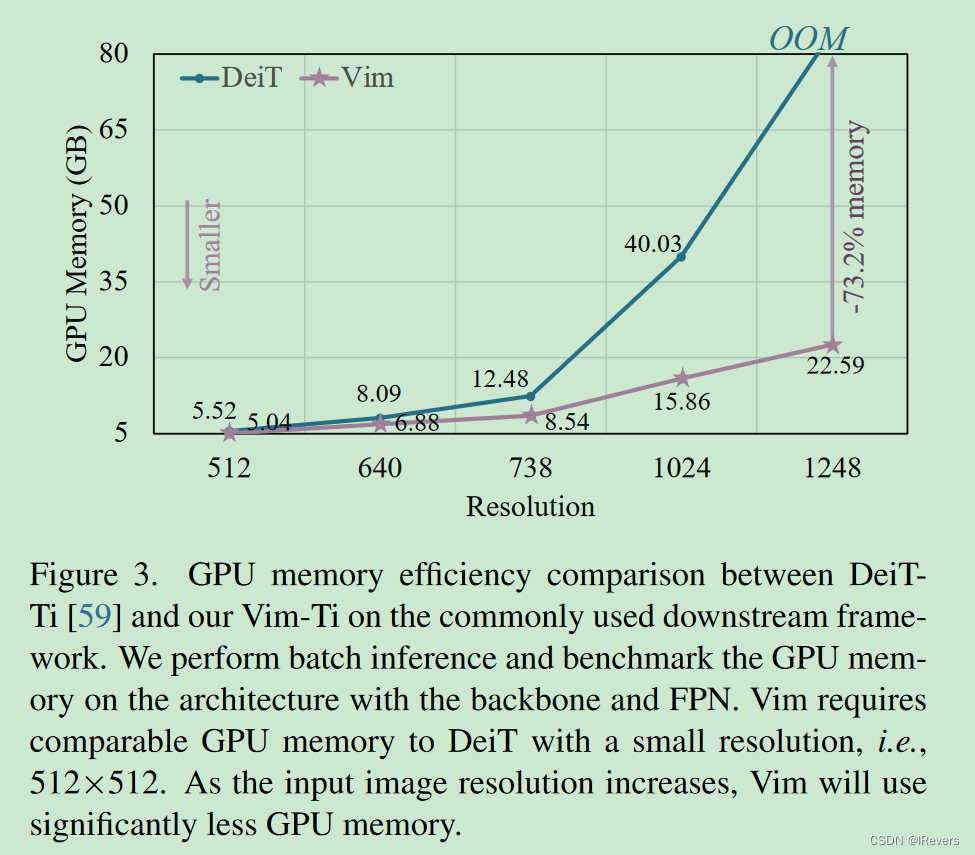
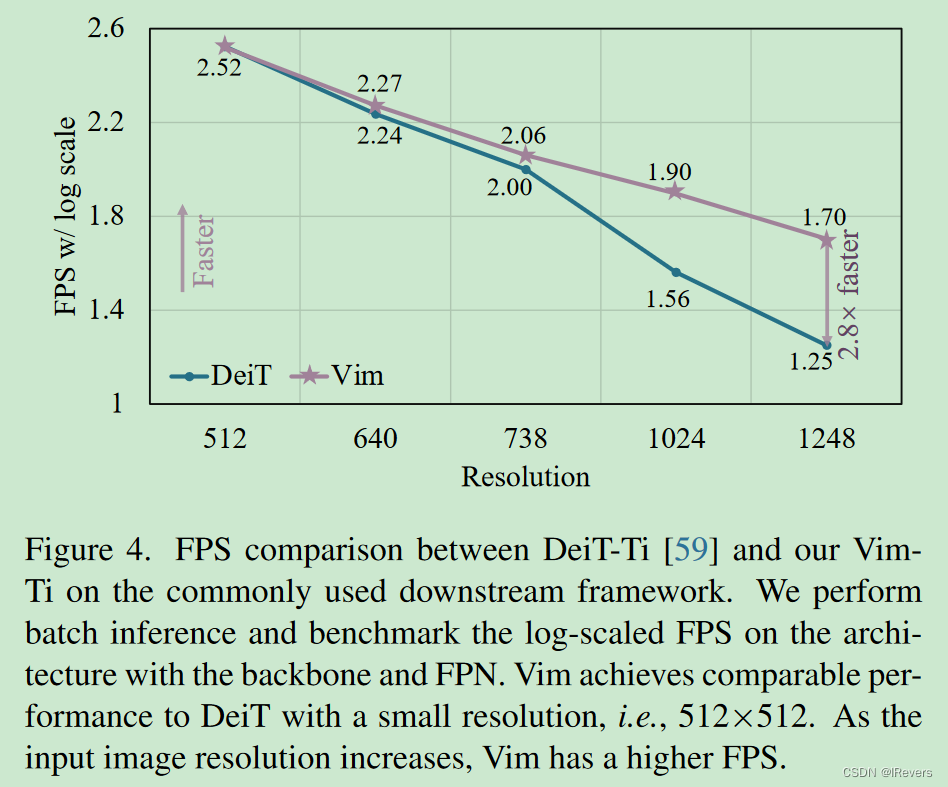
图1(b)和©比较了Tiny尺寸Vim和DeiT的FPS和GPU内存。随着图像分辨率的增加,Vim在速度和内存效率上表现出更好的性能。具体来说,当图像大小为512×512时,Vim的FPS和内存与DeiT相当。当图像大小增加到1248×1248时,Vim的速度比DeiT快2.8倍,节省了86.8%的GPU内存。Vim在序列长度上的线性扩展优势明显,使其适用于高分辨率的下游视觉应用和长序列多模态应用。


2、Semantic Segmentation
实验设置:在ADE20K [73] 上进行语义分割实验,并采用UperNet[70]作为分割框架。在ADE20K [73] 数据集上进行语义分割实验。ADE20K包含150个精细类别,训练集有20,000张,验证集有2,000张,测试集有3,000张。我们选择UperNet [69] 作为基础框架。在训练过程中,使用AdamW优化器,权重衰减为0.01,总批次大小为16。训练采用初始学习率为
6
×
1
0
−
5
6×10^{-5}
6×10−5,线性学习率衰减,1,500次的线性warm up,总共训练160,000个迭代。数据增强遵循常见设置,包括随机水平翻转、随机缩放(比例范围为[0.5, 2.0])和随机光度扭曲。测试时将图像调整为较短边为512像素。

3、Object Detection and Instance Segmentation
实验设置:在COCO 2017[38]数据集上进行目标检测和实例分割实验。COCO 2017包含118,000张训练图像,5,000张验证图像,以及20,000张测试图像。文中使用经典的Cascade Mask R-CNN[4] 作为基础框架。对于基于ViT的backbones,遵循ViTDet [37] 的设置,应用额外配置(如交错窗口和全局注意力)来处理高分辨率图像。对于基于SSM的Vim,我们直接使用它,无需任何修改。其他训练和评估设置保持不变。在训练时,文中使用AdamW优化器,权重衰减为0.1,总批次大小为64。训练采用初始学习率为 1 × 1 0 − 4 1×10^{-4} 1×10−4,线性学习率衰减,总共训练380,000个迭代。数据增强使用大规模的图像抖动数据增强jitter [18] 对1024×1024输入图像进行处理。测试时将图像调整为较短边为1024像素。


4、Ablation Study
- 无双向:直接采用Mamba块处理视觉序列,仅使用前向方向。
- 双向序列:训练时随机翻转视觉序列,类似数据增强。
- 双向块:堆叠块对,每对的第一个块前向处理视觉序列,第二个块后向处理。
- 双向状态空间模型(Bidirectional SSM):为每个块添加额外的后向状态空间模型处理后向视觉序列。
- 双向状态空间模型 + 1D卷积(Bidirectional SSM + Conv1d):基于双向状态空间模型,我们在后向状态空间模型之前添加一个后向1D卷积(见图2)。如表4所示,直接使用Mamba块在分类任务上表现出色。然而,单向处理在下游密集预测中面临挑战。特别是,初步的双向策略——双向块——实现了7%的分类性能。

在分类设计方面,对Vision Mamba进行了消融研究,以ImageNet-1K分类为基准。文中研究了以下分类策略:
- Mean pool:在最后一个Vision Mamba块的输出特征上采用平均池化,然后进行分类。
- Max pool:首先对视觉序列的每个token适应分类头,然后对序列进行最大池化以获取分类预测结果。
- Head class token:遵循DeiT[60]的做法,将类别token附加到视觉序列的头部进行分类。
- Double class token:基于头部类别token策略,我们额外在序列尾部添加一个类别token。
- Middle class token:在视觉序列的中间添加类别token,然后对最终的中间类别token进行分类。

6、总结
文中提出了Vision Mamba (Vim),旨在探索最新的高效状态空间模型——Mamba,作为通用的视觉背景网络。与先前针对视觉任务设计的混合架构或等效全局2D卷积核的状态空间模型不同,Vim采用序列建模的方式学习视觉表示,避免了图像特定的归纳偏差。这得益于双向状态空间模型,Vim能够获得数据依赖的全局视觉上下文,且拥有与Transformer相当的建模能力,同时计算复杂度更低。得益于Mamba的硬件优化设计,Vim在处理高分辨率图像时,其推理速度和内存使用显著优于Transformer。标准计算机视觉基准测试的结果验证了Vim的建模能力与高效性,Vim将会作为下一代视觉背景网络。







![[机器学习]练习闵可斯基距离](https://img-blog.csdnimg.cn/direct/07a732525cb646da8393979e0fa5826d.png)

