目录
引言
1 导入数据集
2 清洗数据集
3 确定允许的最大序列长度
4 选择合理的文本和摘要
5 对文本进行标记
6 删除空文本和摘要
7 构建模型
7.1 编码器
7.2 解码器
8 训练模型
9 测试模型
10 注意
11 整体代码
引言
文本摘要是指在捕捉其本质的同时缩短长文本的技术。这对于捕获大段文本的底线很有用,从而减少了所需的阅读时间。本文利用使用编码器-解码器序 Seq2Seq 模型构建的深度学习模型来构建文本摘要器,而不是依赖手动摘要。参考原文
在此模型中,编码器接受实际文本和摘要,训练模型以创建编码表示,并将其发送到解码器,解码器将编码表示解码为可靠的摘要。随着训练的进行,训练后的模型可用于对新文本进行推理,从中生成可靠的摘要。
1 导入数据集
在这里,我们将使用新闻摘要数据集。它由两个 CSV 文件组成:一个包含有关作者、标题、源 URL、短文章和完整文章的信息,另一个仅包含标题和文本。在当前应用程序中,您将从两个 CSV 文件中提取标题和文本以训练模型。
使用 pandas 的方法将新闻摘要数据集导入工作区 read_csv()
import pandas as pd # 导入 pandas 库,并将其重命名为 pd(惯例)
summary = pd.read_csv('./data/news_summary.csv', encoding='iso-8859-1') # 从 CSV 文件中读取数据到 DataFrame,指定编码为 iso-8859-1
raw = pd.read_csv('./data/news_summary_more.csv', encoding='iso-8859-1') # 从另一个 CSV 文件中读取数据到 DataFrame,指定编码为 iso-8859-1
summary 数据形式:
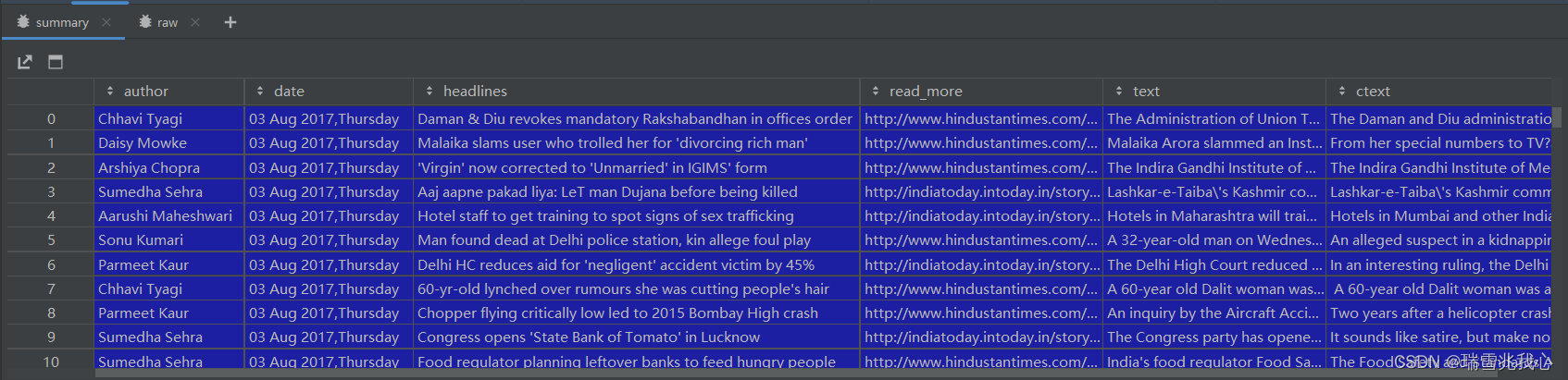
raw 数据形式:
将两个 CSV 文件中的数据合并为一个
pre1 = raw.iloc[:, 0:2].copy() # 复制 raw DataFrame 的前两列数据到 pre1 DataFrame
pre2 = summary.iloc[:, 0:6].copy() # 复制 summary DataFrame 的前六列数据到 pre2 DataFrame
# 创建一个新列 'text',其中包含了多个列的文本值,用于构建可靠的模型
pre2['text'] = pre2['author'].str.cat(pre2['date'].str.cat(pre2['read_more'].str.cat(pre2['text'].str.cat(pre2['ctext'], sep=' '), sep=' '), sep=' '), sep=' ')pre1 数据形式:
pre2 数据形式:

将两个 CSV 文件中的数据合并为一个
pre = pd.DataFrame() # 创建一个空的 DataFrame pre
# 将 pre1 和 pre2 中的 'text' 列合并到 pre DataFrame 中,并忽略索引,重新编号
pre['text'] = pd.concat([pre1['text'], pre2['text']], ignore_index=True)
# 将 pre1 和 pre2 中的 'headlines' 列合并到 pre DataFrame 中,并忽略索引,重新编号
pre['summary'] = pd.concat([pre1['headlines'], pre2['headlines']], ignore_index=True)pre 数据形式(第一列 text 是 raw 中 headlines 一列;第二列 summary 是 raw 中 headlines 列):

注意:为了增加数据点的摄入量来训练模型,使用一个CSV文件构造了一个新的“文本”列。
2 清洗数据集
获取的数据包含非字母字符,在训练模型之前删除这些字符。
import re # 导入 re 模块,用于正则表达式操作
# 去除非字母字符(数据清洗)
def text_strip(column):
for row in column:
row = re.sub("(\\t)", " ", str(row)).lower() # 将制表符替换为空格,并转换为小写
row = re.sub("(\\r)", " ", str(row)).lower() # 将回车符替换为空格,并转换为小写
row = re.sub("(\\n)", " ", str(row)).lower() # 将换行符替换为空格,并转换为小写
# 如果连续出现两次以上的下划线,替换为空格
row = re.sub("(__+)", " ", str(row)).lower()
# 如果连续出现两次以上的减号,替换为空格
row = re.sub("(--+)", " ", str(row)).lower()
# 如果连续出现两次以上的波浪线,替换为空格
row = re.sub("(~~+)", " ", str(row)).lower()
# 如果连续出现两次以上的加号,替换为空格
row = re.sub("(\+\++)", " ", str(row)).lower()
# 如果连续出现两次以上的句点,替换为空格
row = re.sub("(\.\.+)", " ", str(row)).lower()
# 移除字符 - <>()|&©ø"',;?~*!
row = re.sub(r"[<>()|&©ø\[\]\'\",;?~*!]", " ", str(row)).lower()
# 移除字符串 "mailto:"
row = re.sub("(mailto:)", " ", str(row)).lower()
# 移除文本中的 \x9* 字符
row = re.sub(r"(\\x9\d)", " ", str(row)).lower()
# 将 INC 后面跟着数字的部分替换为 "INC_NUM"
row = re.sub("([iI][nN][cC]\d+)", "INC_NUM", str(row)).lower()
# 将 CM# 或者 CHG# 后面跟着数字的部分替换为 "CM_NUM"
row = re.sub("([cC][mM]\d+)|([cC][hH][gG]\d+)", "CM_NUM", str(row)).lower()
# 移除单词末尾的标点符号
row = re.sub("(\.\s+)", " ", str(row)).lower()
row = re.sub("(\-\s+)", " ", str(row)).lower()
row = re.sub("(\:\s+)", " ", str(row)).lower()
# 将任何 URL 替换为域名部分
try:
url = re.search(r"((https*:\/*)([^\/\s]+))(.[^\s]+)", str(row))
repl_url = url.group(3)
row = re.sub(r"((https*:\/*)([^\/\s]+))(.[^\s]+)", repl_url, str(row))
except:
pass
# 移除多余的空格
row = re.sub("(\s+)", " ", str(row)).lower()
# 移除两个空格之间的单个字符
row = re.sub("(\s+.\s+)", " ", str(row)).lower()
yield row在文本和摘要上调用 text_strip() 函数。
# 对 'text' 列进行文本处理
processed_text = text_strip(pre['text'])
# 对 'summary' 列进行文本处理
processed_summary = text_strip(pre['summary'])processed_text 数据形式:
![]()
processed_summary 数据形式:
![]()
使用 spacy 提供的方法批量加载数据,确保所有文本和摘要都具有数据类型。
import spacy # 导入 spacy 库
from time import time # 从 time 模块中导入 time 函数
nlp = spacy.blank('en') # 创建一个空的英语语言模型对象
# 以批处理方式处理文本,并按顺序生成 Doc 对象
text = [str(doc) for doc in nlp.pipe(processed_text, batch_size=5000)]
# 对摘要文本进行处理,在每个摘要前加上 '_START_',在每个摘要后加上 '_END_'
summary = ['_START_ ' + str(doc) + ' _END_' for doc in nlp.pipe(processed_summary, batch_size=5000)]'_START_' 和 '_END_' 分别表示摘要的开始和结束,用于检测和删除空摘要。
![]()
text[0] 和 summary[0] 数据形式:

3 确定允许的最大序列长度
接下来,将 text 和 summary 列表存储在 pandas 对象中。
pre['cleaned_text'] = pd.Series(text)
pre['cleaned_summary'] = pd.Series(summary)绘制图表以确定与文本和摘要的长度相关的频率范围,即确定最大数量的文本和摘要所属的单词长度范围。
import matplotlib.pyplot as plt # 导入 matplotlib.pyplot 模块,并将其重命名为 plt
text_count = [] # 创建一个空列表 text_count,用于存储文本长度统计结果
summary_count = [] # 创建一个空列表 summary_count,用于存储摘要长度统计结果
for sent in pre['cleaned_text']: # 遍历 pre DataFrame 中 'cleaned_text' 列中的每个文本
text_count.append(len(sent.split())) # 将每个文本按空格分割后的单词数量添加到 text_count 列表中
for sent in pre['cleaned_summary']: # 遍历 pre DataFrame 中 'cleaned_summary' 列中的每个摘要
summary_count.append(len(sent.split())) # 将每个摘要按空格分割后的单词数量添加到 summary_count 列表中
graph_df = pd.DataFrame() # 创建一个空的 DataFrame graph_df,用于存储文本和摘要长度统计结果
graph_df['text'] = text_count # 将文本长度统计结果存储在 graph_df 中的 'text' 列中
graph_df['summary'] = summary_count # 将摘要长度统计结果存储在 graph_df 中的 'summary' 列中
graph_df.hist(bins=5) # 绘制图表,将文本长度和摘要长度的频率分布绘制成直方图,设置分箱数量为5
plt.show() # 显示绘制的直方图
运行结果如下:
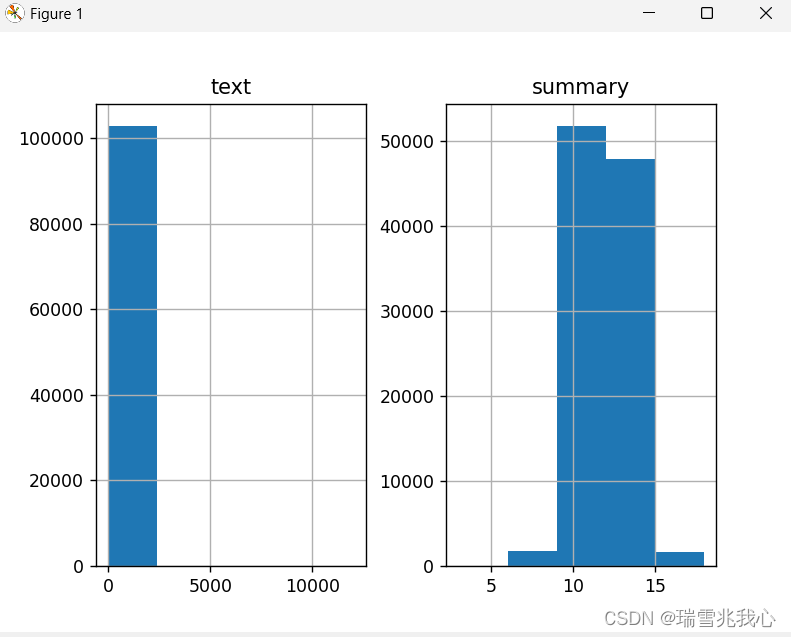
从上图中,可以确定摘要的范围大致指定为 [0-15]。
但我们无法从上图中清楚地解读最大单词数所属的范围,只能用找一个随机范围查看落入该范围单词的百分比。
cnt = 0 # 初始化计数器 cnt,用于统计单词数量不超过 100 的文本数量
for i in pre['cleaned_text']: # 遍历 pre DataFrame 中 'cleaned_text' 列中的每个文本
if len(i.split()) <= 100: # 如果当前文本按空格分割后的单词数量不超过 100
cnt = cnt + 1 # 则计数器 cnt 自增 1
print(cnt / len(pre['cleaned_text'])) # 打印计数器 cnt 除以 'cleaned_text' 列的总数,即平均每个文本中单词数量不超过 100 的比例
运行结果如下:
![]()
现在初始化文本和摘要的最大允许长度。
max_text_len = 100 # 设置文本最大长度为 100
max_summary_len = 15 # 设置摘要最大长度为 15
4 选择合理的文本和摘要
选择低于第 3 部分中定义的最大长度的文本和摘要。
import numpy as np # 导入 numpy 库并重命名为 np
cleaned_text = np.array(pre['cleaned_text']) # 将 'cleaned_text' 列转换为 numpy 数组
cleaned_summary= np.array(pre['cleaned_summary']) # 将 'cleaned_summary' 列转换为 numpy 数组
short_text = [] # 创建一个空列表 short_text,用于存储长度符合要求的文本
short_summary = [] # 创建一个空列表 short_summary,用于存储长度符合要求的摘要
for i in range(len(cleaned_text)): # 遍历 numpy 数组的索引范围
if len(cleaned_summary[i].split()) <= max_summary_len and len(cleaned_text[i].split()) <= max_text_len:
# 如果当前摘要和文本的单词数量均不超过指定的最大长度
short_text.append(cleaned_text[i]) # 将当前文本添加到 short_text 列表中
short_summary.append(cleaned_summary[i]) # 将当前摘要添加到 short_summary 列表中
post_pre = pd.DataFrame({'text': short_text,'summary': short_summary}) # 创建一个新的 DataFrame post_pre,包含符合要求的文本和摘要
post_pre.head(2) # 显示 post_pre DataFrame 中前两行数据
运行结果如下:

现在添加序列的开始(sostok)和序列的结束(eostok)分别表示摘要的开始和结束。这对于在推理阶段触发摘要的开始很有用。
post_pre['summary'] = post_pre['summary'].apply(lambda x: 'sostok ' + x \
+ ' eostok') # 对 'summary' 列中的每个摘要应用 lambda 函数,在摘要前加上 'sostok ',在摘要后加上 ' eostok'
post_pre.head(2) # 显示经过处理后的 post_pre DataFrame 中前两行数据
运行结果如下:

5 对文本进行标记
首先将数据分成训练数据块和测试数据块。
from sklearn.model_selection import train_test_split # 导入 train_test_split 函数
x_tr, x_val, y_tr, y_val = train_test_split( # 使用 train_test_split 函数划分数据集,并将结果赋值给四个变量
np.array(post_pre["text"]), # 将 "text" 列转换为 numpy 数组作为训练集特征 x_tr
np.array(post_pre["summary"]), # 将 "summary" 列转换为 numpy 数组作为训练集标签 y_tr
test_size=0.1, # 测试集占总数据的比例为 0.1
random_state=0, # 随机数种子为 0,保证每次划分结果相同
shuffle=True, # 对数据进行随机洗牌
)准备文本数据并对其进行标记。
from keras.preprocessing.text import Tokenizer # 导入 Tokenizer 类
from keras.preprocessing.sequence import pad_sequences # 导入 pad_sequences 函数
x_tokenizer = Tokenizer() # 创建 Tokenizer 对象 x_tokenizer
x_tokenizer.fit_on_texts(list(x_tr)) # 在训练集上拟合 Tokenizer,将文本转换为序列并构建词汇表查找文本中罕见单词(例如,出现次数少于 5 次)的出现百分比。
thresh = 5 # 阈值设为 5,用于筛选稀有词
cnt = 0 # 初始化计数器 cnt,用于统计稀有词的数量
tot_cnt = 0 # 初始化总计数器 tot_cnt,用于统计词汇表中词的总数
for key, value in x_tokenizer.word_counts.items(): # 遍历 Tokenizer 对象中词频统计字典的键值对
tot_cnt = tot_cnt + 1 # 总计数器自增 1,统计词汇表中词的总数
if value < thresh: # 如果词频小于设定的阈值
cnt = cnt + 1 # 计数器 cnt 自增 1,统计稀有词的数量
print("% of rare words in vocabulary: ", (cnt / tot_cnt) * 100) # 打印稀有词在词汇表中的比例通过考虑总单词数减去罕见出现的单词数来再次对文本进行标记。将文本转换为数字并将它们全部填充到相同的长度。
x_tokenizer = Tokenizer(num_words=tot_cnt - cnt) # 根据稀有词的数量重新实例化 Tokenizer 对象,num_words 参数设置为词汇表中词的总数减去稀有词的数量
x_tokenizer.fit_on_texts(list(x_tr)) # 在重新实例化的 Tokenizer 对象上拟合训练集文本
x_tr_seq = x_tokenizer.texts_to_sequences(x_tr) # 将训练集文本转换为序列
x_val_seq = x_tokenizer.texts_to_sequences(x_val) # 将验证集文本转换为序列
x_tr = pad_sequences(x_tr_seq, maxlen=max_text_len, padding='post') # 对训练集序列进行填充,使其长度为 max_text_len
x_val = pad_sequences(x_val_seq, maxlen=max_text_len, padding='post') # 对验证集序列进行填充,使其长度为 max_text_len
x_voc = x_tokenizer.num_words + 1 # 计算 Tokenizer 对象中词汇表的大小,加 1 是为了考虑未知词汇
print("Size of vocabulary in X = {}".format(x_voc)) # 打印 Tokenizer 对象中词汇表的大小
运行结果如下:

对摘要也执行相同的操作。
y_tokenizer = Tokenizer() # 创建 Tokenizer 对象 y_tokenizer
y_tokenizer.fit_on_texts(list(y_tr)) # 在训练集标签上拟合 Tokenizer 对象
thresh = 5 # 阈值设为 5,用于筛选稀有词
cnt = 0 # 初始化计数器 cnt,用于统计稀有词的数量
tot_cnt = 0 # 初始化总计数器 tot_cnt,用于统计词汇表中词的总数
for key, value in y_tokenizer.word_counts.items(): # 遍历 Tokenizer 对象中词频统计字典的键值对
tot_cnt = tot_cnt + 1 # 总计数器自增 1,统计词汇表中词的总数
if value < thresh: # 如果词频小于设定的阈值
cnt = cnt + 1 # 计数器 cnt 自增 1,统计稀有词的数量
print("% of rare words in vocabulary:", (cnt / tot_cnt) * 100) # 打印稀有词在词汇表中的比例
y_tokenizer = Tokenizer(num_words=tot_cnt - cnt) # 根据稀有词的数量重新实例化 Tokenizer 对象,num_words 参数设置为词汇表中词的总数减去稀有词的数量
y_tokenizer.fit_on_texts(list(y_tr)) # 在重新实例化的 Tokenizer 对象上拟合训练集标签
y_tr_seq = y_tokenizer.texts_to_sequences(y_tr) # 将训练集标签转换为序列
y_val_seq = y_tokenizer.texts_to_sequences(y_val) # 将验证集标签转换为序列
y_tr = pad_sequences(y_tr_seq, maxlen=max_summary_len, padding='post') # 对训练集标签序列进行填充,使其长度为 max_summary_len
y_val = pad_sequences(y_val_seq, maxlen=max_summary_len, padding='post') # 对验证集标签序列进行填充,使其长度为 max_summary_len
y_voc = y_tokenizer.num_words + 1 # 计算 Tokenizer 对象中词汇表的大小,加 1 是为了考虑未知词汇
print("Size of vocabulary in Y = {}".format(y_voc)) # 打印 Tokenizer 对象中词汇表的大小运行结果如下:

6 删除空文本和摘要
从数据中删除所有空摘要(仅具有 START 和 END 标记)及其关联文本。
# 从数据中删除所有空摘要(仅具有 START 和 END 标记)及其关联文本。
ind = [] # 创建一个空列表 ind,用于存储需要删除的索引
for i in range(len(y_tr)): # 遍历训练集标签中的每个序列
cnt = 0 # 初始化计数器 cnt,用于统计非零元素的数量
for j in y_tr[i]: # 遍历序列中的每个元素
if j != 0: # 如果元素不为零
cnt = cnt + 1 # 计数器 cnt 自增 1
if cnt == 2: # 如果序列中非零元素的数量为 2,即仅具有 START 和 END 标记
ind.append(i) # 将该序列的索引添加到 ind 列表中
y_tr = np.delete(y_tr, ind, axis=0) # 使用 np.delete 函数删除训练集标签中指定索引的序列
x_tr = np.delete(x_tr, ind, axis=0) # 使用 np.delete 函数删除训练集文本中指定索引的文本对验证数据也重复相同的操作。
# 对验证数据也重复相同的操作。
ind = [] # 创建一个空列表 ind,用于存储需要删除的索引
for i in range(len(y_val)): # 遍历验证集标签中的每个序列
cnt = 0 # 初始化计数器 cnt,用于统计非零元素的数量
for j in y_val[i]: # 遍历序列中的每个元素
if j != 0: # 如果元素不为零
cnt = cnt + 1 # 计数器 cnt 自增 1
if cnt == 2: # 如果序列中非零元素的数量为 2,即仅具有 START 和 END 标记
ind.append(i) # 将该序列的索引添加到 ind 列表中
y_val = np.delete(y_val, ind, axis=0) # 使用 np.delete 函数删除验证集标签中指定索引的序列
x_val = np.delete(x_val, ind, axis=0) # 使用 np.delete 函数删除验证集文本中指定索引的文本继续在第 2 部分构建模型、训练模型并进行推理。
7 构建模型
首先,导入所有必需的库文件。
from keras.preprocessing.text import Tokenizer # 导入 Tokenizer 类,用于文本预处理
from keras.preprocessing.sequence import pad_sequences # 导入 pad_sequences 函数,用于填充序列
from keras.layers import Input, LSTM, Embedding, Dense, Concatenate, TimeDistributed # 导入模型层类,包括输入层、LSTM层、嵌入层、全连接层和时间分布层等
from keras.models import Model # 导入 Model 类,用于构建模型
from keras.callbacks import EarlyStopping # 导入 EarlyStopping 类,用于早停法回调接下来,定义编码器和解码器网络。
7.1 编码器
编码器接受的输入长度等于在第 3 部分中估计的最大文本长度。然后将其赋予维度为(文本收录中抓取的单词总数 × 嵌入层中的节点数)的嵌入层。接下来是 3 个 LSTM 网络,其中每层返回 LSTM 输出,以及在先前时间步骤中观察到的隐藏状态和单元状态。
latent_dim = 300 # 定义编码器和解码器 LSTM 层的隐藏状态维度
embedding_dim = 200 # 定义嵌入层的维度
# Encoder(编码器)部分
encoder_inputs = Input(shape=(max_text_len, )) # 定义编码器输入,形状为 (最大文本长度,)
# Embedding layer(嵌入层)
enc_emb = Embedding(x_voc, embedding_dim, trainable=True)(encoder_inputs) # 创建可训练的嵌入层并应用于编码器输入
# Encoder LSTM 1(编码器 LSTM 1)
encoder_lstm1 = LSTM(latent_dim, return_sequences=True, return_state=True, dropout=0.4, recurrent_dropout=0.4) # 创建第一个编码器 LSTM 层
(encoder_output1, state_h1, state_c1) = encoder_lstm1(enc_emb) # 应用编码器 LSTM 1 层于嵌入层输出
# Encoder LSTM 2(编码器 LSTM 2)
encoder_lstm2 = LSTM(latent_dim, return_sequences=True, return_state=True, dropout=0.4, recurrent_dropout=0.4) # 创建第二个编码器 LSTM 层
(encoder_output2, state_h2, state_c2) = encoder_lstm2(encoder_output1) # 应用编码器 LSTM 2 层于第一个编码器 LSTM 输出
# Encoder LSTM 3(编码器 LSTM 3)
encoder_lstm3 = LSTM(latent_dim, return_sequences=True, return_state=True, dropout=0.4, recurrent_dropout=0.4) # 创建第三个编码器 LSTM 层
(encoder_outputs, state_h, state_c) = encoder_lstm3(encoder_output2) # 应用编码器 LSTM 3 层于第二个编码器 LSTM 输出7.2 解码器
在解码器中,定义了一个嵌入层,后面是一个 LSTM 网络。 LSTM 网络的初始状态是从编码器获取的最后一个隐藏状态和单元状态。 LSTM 的输出被提供给包裹在 TimeDistributed 层中的 Dense 层,并附加了 softmax 激活函数。
# 设置解码器部分,使用编码器状态作为初始状态
decoder_inputs = Input(shape=(None, )) # 定义解码器输入,形状为 (None,)
# Embedding layer(嵌入层)
dec_emb_layer = Embedding(y_voc, embedding_dim, trainable=True) # 创建可训练的嵌入层
dec_emb = dec_emb_layer(decoder_inputs) # 应用嵌入层于解码器输入
# Decoder LSTM(解码器 LSTM)
decoder_lstm = LSTM(latent_dim, return_sequences=True, return_state=True, dropout=0.4, recurrent_dropout=0.2) # 创建解码器 LSTM 层
(decoder_outputs, decoder_fwd_state, decoder_back_state) = \
decoder_lstm(dec_emb, initial_state=[state_h, state_c]) # 应用解码器 LSTM 层于嵌入层输出,并传入初始状态
# Dense layer(全连接层)
decoder_dense = TimeDistributed(Dense(y_voc, activation='softmax')) # 创建时间分布的全连接层,使用 softmax 激活函数
decoder_outputs = decoder_dense(decoder_outputs) # 应用全连接层于解码器 LSTM 输出
# 定义模型
model = Model([encoder_inputs, decoder_inputs], decoder_outputs) # 创建模型,输入为编码器和解码器输入,输出为解码器输出
print(model.summary()) # 打印模型摘要信息运行结果如下:
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) [(None, 100)] 0 []
embedding (Embedding) (None, 100, 200) 5927600 ['input_1[0][0]']
lstm (LSTM) [(None, 100, 300), 601200 ['embedding[0][0]']
(None, 300),
(None, 300)]
input_2 (InputLayer) [(None, None)] 0 []
lstm_1 (LSTM) [(None, 100, 300), 721200 ['lstm[0][0]']
(None, 300),
(None, 300)]
embedding_1 (Embedding) (None, None, 200) 2576600 ['input_2[0][0]']
lstm_2 (LSTM) [(None, 100, 300), 721200 ['lstm_1[0][0]']
(None, 300),
(None, 300)]
lstm_3 (LSTM) [(None, None, 300), 601200 ['embedding_1[0][0]',
(None, 300), 'lstm_2[0][1]',
(None, 300)] 'lstm_2[0][2]']
time_distributed (TimeDist (None, None, 12883) 3877783 ['lstm_3[0][0]']
ributed)
==================================================================================================
Total params: 15026783 (57.32 MB)
Trainable params: 15026783 (57.32 MB)
Non-trainable params: 0 (0.00 Byte)
__________________________________________________________________________________________________总而言之,该模型接受编码器(文本)和解码器(摘要)作为输入,并输出摘要。预测是通过根据摘要的前一个单词预测摘要中即将出现的单词来进行的。
8 训练模型
在训练阶段,解码器接受给予模型的输入摘要,并学习必须跟随某个给定单词的每个单词。
编译模型并定义 EarlyStopping 一旦验证损失指标停止减少就停止训练模型。
model.compile(optimizer='rmsprop', loss='sparse_categorical_crossentropy') # 编译模型,使用 rmsprop 优化器和稀疏分类交叉熵损失函数
es = EarlyStopping(monitor='val_loss', mode='min', verbose=1, patience=2) # 创建 EarlyStopping 回调函数,监控验证集损失,模式为最小化,显示详细信息,忍耐次数为2次接下来,使用该 model.fit() 方法来拟合训练数据,可以将批量大小定义为 128。发送文本和摘要(不包括摘要中的最后一个单词)作为输入,以及包含每个单词(从第二个单词)作为输出(这解释了将智能注入模型以在给定前一个单词的情况下预测单词)。此外,为了在训练阶段启用验证,还需要发送验证数据。
history = model.fit( # 拟合模型
[x_tr, y_tr[:, :-1]], # 训练数据为编码器输入和解码器输入(截断最后一个词)
y_tr.reshape(y_tr.shape[0], y_tr.shape[1], 1)[:, 1:], # 训练标签为解码器输出(截断第一个词)
epochs=50, # 迭代次数为50轮
callbacks=[es], # 使用 EarlyStopping 回调函数
batch_size=128, # 批大小为128
validation_data=([x_val, y_val[:, :-1]], # 验证数据为编码器输入和解码器输入(截断最后一个词)
y_val.reshape(y_val.shape[0], y_val.shape[1], 1)[:, 1:]), # 验证标签为解码器输出(截断第一个词)
)接下来,绘制在训练阶段观察到的训练和验证损失指标。
from matplotlib import pyplot # 导入 pyplot 模块
# 绘制训练集损失和验证集损失的曲线
pyplot.plot(history.history['loss'], label='train') # 绘制训练集损失曲线,设置标签为 'train'
pyplot.plot(history.history['val_loss'], label='test') # 绘制验证集损失曲线,设置标签为 'test'
pyplot.legend() # 添加图例
pyplot.show() # 显示图像
9 测试模型
在测试阶段使用推理模型生成预测。 现在我们已经训练了模型,为了从给定的文本片段生成摘要,首先将索引反向映射到单词。此外,将单词映射到摘要分词器中的索引,该索引用于检测序列的开头和结尾。
reverse_target_word_index = y_tokenizer.index_word # 创建反转的目标词索引,用于将索引转换为单词
reverse_source_word_index = x_tokenizer.index_word # 创建反转的源词索引,用于将索引转换为单词
target_word_index = y_tokenizer.word_index # 获取目标词的索引现在定义编码器和解码器推理模型以开始进行预测。使用 keras.Model() 对象创建推理模型。
编码器推理模型接受文本并返回从三个 LSTM 以及隐藏状态和单元状态生成的输出。解码器推理模型接受序列标识符 (sostok) 的开头并预测即将出现的单词,最终预测整个摘要。
定义推理模型的架构。
# 推断模型
# 编码输入序列以获取特征向量
encoder_model = Model(inputs=encoder_inputs, outputs=[encoder_outputs, state_h, state_c]) # 创建编码器模型
# 解码器设置
# 下面的张量将保存上一个时间步长的状态
decoder_state_input_h = Input(shape=(latent_dim, )) # 创建解码器隐藏状态输入张量
decoder_state_input_c = Input(shape=(latent_dim, )) # 创建解码器细胞状态输入张量
decoder_hidden_state_input = Input(shape=(max_text_len, latent_dim)) # 创建解码器隐藏状态输入张量
# 获取解码器序列的嵌入
dec_emb2 = dec_emb_layer(decoder_inputs) # 应用嵌入层于解码器输入
# 为了预测序列中的下一个词,将初始状态设置为上一个时间步长的状态
(decoder_outputs2, state_h2, state_c2) = decoder_lstm(dec_emb2, initial_state=[decoder_state_input_h, decoder_state_input_c]) # 应用解码器 LSTM 层
# 一个密集的 softmax 层生成目标词汇上的概率分布
decoder_outputs2 = decoder_dense(decoder_outputs2) # 应用全连接层于解码器 LSTM 输出
# 最终解码器模型
decoder_model = Model([decoder_inputs] + [decoder_hidden_state_input, decoder_state_input_h, decoder_state_input_c], [decoder_outputs2] + [state_h2, state_c2]) # 创建解码器模型现在定义一个函数 decode_sequence(),它接受输入文本并输出预测摘要。从开始 sostok 并继续生成单词,直到 sostok 遇到或达到摘要的最大长度。通过选择具有最大概率的单词来预测给定单词中即将出现的单词,并相应地更新解码器的内部状态。
def decode_sequence(input_seq):
# 将输入编码为状态向量
(e_out, e_h, e_c) = encoder_model.predict(input_seq)
# 生成长度为 1 的空目标序列
target_seq = np.zeros((1, 1))
# 使用起始词填充目标序列的第一个单词
target_seq[0, 0] = target_word_index['sostok']
stop_condition = False # 停止条件为 False
decoded_sentence = '' # 初始化解码后的句子
while not stop_condition: # 当停止条件为 False 时执行循环
(output_tokens, h, c) = decoder_model.predict([target_seq] + [e_out, e_h, e_c]) # 使用解码器模型预测输出
# 采样一个 token
sampled_token_index = np.argmax(output_tokens[0, -1, :]) # 获取最可能的 token 索引
sampled_token = reverse_target_word_index[sampled_token_index] # 获取对应的单词
if sampled_token != 'eostok': # 如果采样的 token 不是结束标记
decoded_sentence += ' ' + sampled_token # 添加到解码后的句子中
# 退出条件:达到最大长度或者找到停止词
if sampled_token == 'eostok' or len(decoded_sentence.split()) >= max_summary_len - 1:
stop_condition = True # 设置停止条件为 True
# 更新目标序列(长度为 1)
target_seq = np.zeros((1, 1)) # 重置目标序列
target_seq[0, 0] = sampled_token_index # 更新为预测的 token 索引
# 更新内部状态
(e_h, e_c) = (h, c) # 更新编码器状态
return decoded_sentence # 返回解码后的句子
定义两个函数 seq2summary() 和 seq2text() 分别将摘要和文本的数字表示形式转换为字符串表示形式。
# 将序列转换为摘要
def seq2summary(input_seq): # 定义将序列转换为摘要的函数
newString = '' # 初始化新字符串
for i in input_seq: # 遍历输入序列
if i != 0 and i != target_word_index['sostok'] and i != target_word_index['eostok']: # 如果索引不是零、sostok 或 eostok
newString = newString + reverse_target_word_index[i] + ' ' # 添加单词到新字符串
return newString # 返回新字符串
# 将序列转换为文本
def seq2text(input_seq): # 定义将序列转换为文本的函数
newString = '' # 初始化新字符串
for i in input_seq: # 遍历输入序列
if i != 0: # 如果索引不是零
newString = newString + reverse_source_word_index[i] + ' ' # 添加单词到新字符串
return newString # 返回新字符串最后,通过发送文本来生成预测。
# 打印预测结果
for i in range(0, 19): # 遍历前19个序列
print('Review:', seq2text(x_tr[i])) # 打印文本序列
print('Original summary:', seq2summary(y_tr[i])) # 打印原始摘要
print('Predicted summary:', decode_sequence(x_tr[i].reshape(1, max_text_len))) # 打印预测摘要
print('\n') # 打印空行10 注意
原文中导入的 tensorflow 库改为下述代码:
第 5 部分:

第 7 部分:

11 整体代码
import pandas as pd # 导入 pandas 库,并将其重命名为 pd(惯例)
import matplotlib # 导入 matplotlib 库
matplotlib.use('TkAgg') # 使用 TkAgg 后端来绘制 matplotlib 图形
summary = pd.read_csv('./data/news_summary.csv', encoding='iso-8859-1') # 从 CSV 文件中读取数据到 DataFrame,指定编码为 iso-8859-1
raw = pd.read_csv('./data/news_summary_more.csv', encoding='iso-8859-1') # 从另一个 CSV 文件中读取数据到 DataFrame,指定编码为 iso-8859-1
pre1 = raw.iloc[:, 0:2].copy() # 复制 raw DataFrame 的前两列数据到 pre1 DataFrame
pre2 = summary.iloc[:, 0:6].copy() # 复制 summary DataFrame 的前六列数据到 pre2 DataFrame
# 创建一个新列 'text',其中包含了多个列的文本值,用于构建可靠的模型
pre2['text'] = pre2['author'].str.cat(pre2['date'].str.cat(pre2['read_more'].str.cat(pre2['text'].str.cat(pre2['ctext'], sep=' '), sep=' '), sep=' '), sep=' ')
pre = pd.DataFrame() # 创建一个空的 DataFrame pre
# 将 pre1 和 pre2 中的 'text' 列合并到 pre DataFrame 中,并忽略索引,重新编号
pre['text'] = pd.concat([pre1['text'], pre2['text']], ignore_index=True)
# 将 pre1 和 pre2 中的 'headlines' 列合并到 pre DataFrame 中,并忽略索引,重新编号
pre['summary'] = pd.concat([pre1['headlines'], pre2['headlines']], ignore_index=True)
import re # 导入 re 模块,用于正则表达式操作
# 去除非字母字符(数据清洗)
def text_strip(column):
for row in column:
row = re.sub("(\\t)", " ", str(row)).lower() # 将制表符替换为空格,并转换为小写
row = re.sub("(\\r)", " ", str(row)).lower() # 将回车符替换为空格,并转换为小写
row = re.sub("(\\n)", " ", str(row)).lower() # 将换行符替换为空格,并转换为小写
# 如果连续出现两次以上的下划线,替换为空格
row = re.sub("(__+)", " ", str(row)).lower()
# 如果连续出现两次以上的减号,替换为空格
row = re.sub("(--+)", " ", str(row)).lower()
# 如果连续出现两次以上的波浪线,替换为空格
row = re.sub("(~~+)", " ", str(row)).lower()
# 如果连续出现两次以上的加号,替换为空格
row = re.sub("(\+\++)", " ", str(row)).lower()
# 如果连续出现两次以上的句点,替换为空格
row = re.sub("(\.\.+)", " ", str(row)).lower()
# 移除字符 - <>()|&©ø"',;?~*!
row = re.sub(r"[<>()|&©ø\[\]\'\",;?~*!]", " ", str(row)).lower()
# 移除字符串 "mailto:"
row = re.sub("(mailto:)", " ", str(row)).lower()
# 移除文本中的 \x9* 字符
row = re.sub(r"(\\x9\d)", " ", str(row)).lower()
# 将 INC 后面跟着数字的部分替换为 "INC_NUM"
row = re.sub("([iI][nN][cC]\d+)", "INC_NUM", str(row)).lower()
# 将 CM# 或者 CHG# 后面跟着数字的部分替换为 "CM_NUM"
row = re.sub("([cC][mM]\d+)|([cC][hH][gG]\d+)", "CM_NUM", str(row)).lower()
# 移除单词末尾的标点符号
row = re.sub("(\.\s+)", " ", str(row)).lower()
row = re.sub("(\-\s+)", " ", str(row)).lower()
row = re.sub("(\:\s+)", " ", str(row)).lower()
# 将任何 URL 替换为域名部分
try:
url = re.search(r"((https*:\/*)([^\/\s]+))(.[^\s]+)", str(row))
repl_url = url.group(3)
row = re.sub(r"((https*:\/*)([^\/\s]+))(.[^\s]+)", repl_url, str(row))
except:
pass
# 移除多余的空格
row = re.sub("(\s+)", " ", str(row)).lower()
# 移除两个空格之间的单个字符
row = re.sub("(\s+.\s+)", " ", str(row)).lower()
yield row
# 对 'text' 列进行文本处理
processed_text = text_strip(pre['text'])
# 对 'summary' 列进行文本处理
processed_summary = text_strip(pre['summary'])
import spacy # 导入 spacy 库
from time import time # 从 time 模块中导入 time 函数
nlp = spacy.blank('en') # 创建一个空的英语语言模型对象
# 以批处理方式处理文本,并按顺序生成 Doc 对象
text = [str(doc) for doc in nlp.pipe(processed_text, batch_size=5000)]
# 对摘要文本进行处理,在每个摘要前加上 '_START_',在每个摘要后加上 '_END_'
summary = ['_START_ ' + str(doc) + ' _END_' for doc in nlp.pipe(processed_summary, batch_size=5000)]
print("text[0]: ", text[0])
print("summary[0]: ", summary[0])
# 确定最大允许序列长度
# 接下来,将 text 和 summary 列表存储在 pandas 对象中。
pre['cleaned_text'] = pd.Series(text)
pre['cleaned_summary'] = pd.Series(summary)
# 绘制图表以确定与文本和摘要的长度相关的频率范围,即确定最大数量的文本和摘要所属的单词长度范围。
import matplotlib.pyplot as plt # 导入 matplotlib.pyplot 模块,并将其重命名为 plt
text_count = [] # 创建一个空列表 text_count,用于存储文本长度统计结果
summary_count = [] # 创建一个空列表 summary_count,用于存储摘要长度统计结果
for sent in pre['cleaned_text']: # 遍历 pre DataFrame 中 'cleaned_text' 列中的每个文本
text_count.append(len(sent.split())) # 将每个文本按空格分割后的单词数量添加到 text_count 列表中
for sent in pre['cleaned_summary']: # 遍历 pre DataFrame 中 'cleaned_summary' 列中的每个摘要
summary_count.append(len(sent.split())) # 将每个摘要按空格分割后的单词数量添加到 summary_count 列表中
graph_df = pd.DataFrame() # 创建一个空的 DataFrame graph_df,用于存储文本和摘要长度统计结果
graph_df['text'] = text_count # 将文本长度统计结果存储在 graph_df 中的 'text' 列中
graph_df['summary'] = summary_count # 将摘要长度统计结果存储在 graph_df 中的 'summary' 列中
graph_df.hist(bins=5) # 绘制图表,将文本长度和摘要长度的频率分布绘制成直方图,设置分箱数量为5
# plt.show() # 显示绘制的直方图
# 从上图中,可以确定摘要的范围大致指定为 [0-15]
# 但我们无法从上图中清楚地解读最大单词数所属的范围,只能用找一个随机范围查看落入该范围单词的百分比。
cnt = 0 # 初始化计数器 cnt,用于统计单词数量不超过 100 的文本数量
for i in pre['cleaned_text']: # 遍历 pre DataFrame 中 'cleaned_text' 列中的每个文本
if len(i.split()) <= 100: # 如果当前文本按空格分割后的单词数量不超过 100
cnt = cnt + 1 # 则计数器 cnt 自增 1
print(cnt / len(pre['cleaned_text'])) # 打印计数器 cnt 除以 'cleaned_text' 列的总数,即平均每个文本中单词数量不超过 100 的比例
max_text_len = 100 # 设置文本最大长度为 100
max_summary_len = 15 # 设置摘要最大长度为 15
import numpy as np # 导入 numpy 库并重命名为 np
cleaned_text = np.array(pre['cleaned_text']) # 将 'cleaned_text' 列转换为 numpy 数组
cleaned_summary = np.array(pre['cleaned_summary']) # 将 'cleaned_summary' 列转换为 numpy 数组
short_text = [] # 创建一个空列表 short_text,用于存储长度符合要求的文本
short_summary = [] # 创建一个空列表 short_summary,用于存储长度符合要求的摘要
for i in range(len(cleaned_text)): # 遍历 numpy 数组的索引范围
if len(cleaned_summary[i].split()) <= max_summary_len and len(cleaned_text[i].split()) <= max_text_len:
# 如果当前摘要和文本的单词数量均不超过指定的最大长度
short_text.append(cleaned_text[i]) # 将当前文本添加到 short_text 列表中
short_summary.append(cleaned_summary[i]) # 将当前摘要添加到 short_summary 列表中
post_pre = pd.DataFrame({'text': short_text, 'summary': short_summary}) # 创建一个新的 DataFrame post_pre,包含符合要求的文本和摘要
print(post_pre.head(2)) # 显示 post_pre DataFrame 中前两行数据
# 现在添加序列的开始(sostok)和序列的结束(eostok)分别表示摘要的开始和结束。这对于在推理阶段触发摘要的开始很有用。
# 对 'summary' 列中的每个摘要应用 lambda 函数,在摘要前加上 'sostok ',在摘要后加上 ' eostok'
post_pre['summary'] = post_pre['summary'].apply(lambda x: 'sostok ' + x + ' eostok')
print(post_pre.head(2)) # 显示经过处理后的 post_pre DataFrame 中前两行数据
# 首先将数据分成训练数据块和测试数据块。
from sklearn.model_selection import train_test_split # 导入 train_test_split 函数
x_tr, x_val, y_tr, y_val = train_test_split( # 使用 train_test_split 函数划分数据集,并将结果赋值给四个变量
np.array(post_pre["text"]), # 将 "text" 列转换为 numpy 数组作为训练集特征 x_tr
np.array(post_pre["summary"]), # 将 "summary" 列转换为 numpy 数组作为训练集标签 y_tr
test_size=0.1, # 测试集占总数据的比例为 0.1
random_state=0, # 随机数种子为 0,保证每次划分结果相同
shuffle=True, # 对数据进行随机洗牌
)
# 准备文本数据并对其进行标记。
from keras.preprocessing.text import Tokenizer # 导入 Tokenizer 类
from keras.preprocessing.sequence import pad_sequences # 导入 pad_sequences 函数
x_tokenizer = Tokenizer() # 创建 Tokenizer 对象 x_tokenizer
x_tokenizer.fit_on_texts(list(x_tr)) # 在训练集上拟合 Tokenizer,将文本转换为序列并构建词汇表
# 查找文本中罕见单词(例如,出现次数少于 5 次)的出现百分比。
thresh = 5 # 阈值设为 5,用于筛选稀有词
cnt = 0 # 初始化计数器 cnt,用于统计稀有词的数量
tot_cnt = 0 # 初始化总计数器 tot_cnt,用于统计词汇表中词的总数
for key, value in x_tokenizer.word_counts.items(): # 遍历 Tokenizer 对象中词频统计字典的键值对
tot_cnt = tot_cnt + 1 # 总计数器自增 1,统计词汇表中词的总数
if value < thresh: # 如果词频小于设定的阈值
cnt = cnt + 1 # 计数器 cnt 自增 1,统计稀有词的数量
print("% of rare words in vocabulary: ", (cnt / tot_cnt) * 100) # 打印稀有词在词汇表中的比例
# 通过考虑总单词数减去罕见出现的单词数来再次对文本进行标记。将文本转换为数字并将它们全部填充到相同的长度。
x_tokenizer = Tokenizer(num_words=tot_cnt - cnt) # 根据稀有词的数量重新实例化 Tokenizer 对象,num_words 参数设置为词汇表中词的总数减去稀有词的数量
x_tokenizer.fit_on_texts(list(x_tr)) # 在重新实例化的 Tokenizer 对象上拟合训练集文本
x_tr_seq = x_tokenizer.texts_to_sequences(x_tr) # 将训练集文本转换为序列
x_val_seq = x_tokenizer.texts_to_sequences(x_val) # 将验证集文本转换为序列
x_tr = pad_sequences(x_tr_seq, maxlen=max_text_len, padding='post') # 对训练集序列进行填充,使其长度为 max_text_len
x_val = pad_sequences(x_val_seq, maxlen=max_text_len, padding='post') # 对验证集序列进行填充,使其长度为 max_text_len
x_voc = x_tokenizer.num_words + 1 # 计算 Tokenizer 对象中词汇表的大小,加 1 是为了考虑未知词汇
print("Size of vocabulary in X = {}".format(x_voc)) # 打印 Tokenizer 对象中词汇表的大小
y_tokenizer = Tokenizer() # 创建 Tokenizer 对象 y_tokenizer
y_tokenizer.fit_on_texts(list(y_tr)) # 在训练集标签上拟合 Tokenizer 对象
thresh = 5 # 阈值设为 5,用于筛选稀有词
cnt = 0 # 初始化计数器 cnt,用于统计稀有词的数量
tot_cnt = 0 # 初始化总计数器 tot_cnt,用于统计词汇表中词的总数
for key, value in y_tokenizer.word_counts.items(): # 遍历 Tokenizer 对象中词频统计字典的键值对
tot_cnt = tot_cnt + 1 # 总计数器自增 1,统计词汇表中词的总数
if value < thresh: # 如果词频小于设定的阈值
cnt = cnt + 1 # 计数器 cnt 自增 1,统计稀有词的数量
print("% of rare words in vocabulary:", (cnt / tot_cnt) * 100) # 打印稀有词在词汇表中的比例
y_tokenizer = Tokenizer(num_words=tot_cnt - cnt) # 根据稀有词的数量重新实例化 Tokenizer 对象,num_words 参数设置为词汇表中词的总数减去稀有词的数量
y_tokenizer.fit_on_texts(list(y_tr)) # 在重新实例化的 Tokenizer 对象上拟合训练集标签
y_tr_seq = y_tokenizer.texts_to_sequences(y_tr) # 将训练集标签转换为序列
y_val_seq = y_tokenizer.texts_to_sequences(y_val) # 将验证集标签转换为序列
y_tr = pad_sequences(y_tr_seq, maxlen=max_summary_len, padding='post') # 对训练集标签序列进行填充,使其长度为 max_summary_len
y_val = pad_sequences(y_val_seq, maxlen=max_summary_len, padding='post') # 对验证集标签序列进行填充,使其长度为 max_summary_len
y_voc = y_tokenizer.num_words + 1 # 计算 Tokenizer 对象中词汇表的大小,加 1 是为了考虑未知词汇
print("Size of vocabulary in Y = {}".format(y_voc)) # 打印 Tokenizer 对象中词汇表的大小
# 从数据中删除所有空摘要(仅具有 START 和 END 标记)及其关联文本。
ind = [] # 创建一个空列表 ind,用于存储需要删除的索引
for i in range(len(y_tr)): # 遍历训练集标签中的每个序列
cnt = 0 # 初始化计数器 cnt,用于统计非零元素的数量
for j in y_tr[i]: # 遍历序列中的每个元素
if j != 0: # 如果元素不为零
cnt = cnt + 1 # 计数器 cnt 自增 1
if cnt == 2: # 如果序列中非零元素的数量为 2,即仅具有 START 和 END 标记
ind.append(i) # 将该序列的索引添加到 ind 列表中
y_tr = np.delete(y_tr, ind, axis=0) # 使用 np.delete 函数删除训练集标签中指定索引的序列
x_tr = np.delete(x_tr, ind, axis=0) # 使用 np.delete 函数删除训练集文本中指定索引的文本
# 对验证数据也重复相同的操作。
ind = [] # 创建一个空列表 ind,用于存储需要删除的索引
for i in range(len(y_val)): # 遍历验证集标签中的每个序列
cnt = 0 # 初始化计数器 cnt,用于统计非零元素的数量
for j in y_val[i]: # 遍历序列中的每个元素
if j != 0: # 如果元素不为零
cnt = cnt + 1 # 计数器 cnt 自增 1
if cnt == 2: # 如果序列中非零元素的数量为 2,即仅具有 START 和 END 标记
ind.append(i) # 将该序列的索引添加到 ind 列表中
y_val = np.delete(y_val, ind, axis=0) # 使用 np.delete 函数删除验证集标签中指定索引的序列
x_val = np.delete(x_val, ind, axis=0) # 使用 np.delete 函数删除验证集文本中指定索引的文本
from keras.layers import Input, LSTM, Embedding, Dense, TimeDistributed # 导入模型层类,包括输入层、LSTM层、嵌入层、全连接层和时间分布层等
from keras.models import Model # 导入 Model 类,用于构建模型
from keras.callbacks import EarlyStopping # 导入 EarlyStopping 类,用于早停法回调
latent_dim = 300 # 定义编码器和解码器 LSTM 层的隐藏状态维度
embedding_dim = 200 # 定义嵌入层的维度
# Encoder(编码器)部分
encoder_inputs = Input(shape=(max_text_len, )) # 定义编码器输入,形状为 (最大文本长度,)
# Embedding layer(嵌入层)
enc_emb = Embedding(x_voc, embedding_dim, trainable=True)(encoder_inputs) # 创建可训练的嵌入层并应用于编码器输入
# Encoder LSTM 1(编码器 LSTM 1)
encoder_lstm1 = LSTM(latent_dim, return_sequences=True, return_state=True, dropout=0.4, recurrent_dropout=0.4) # 创建第一个编码器 LSTM 层
(encoder_output1, state_h1, state_c1) = encoder_lstm1(enc_emb) # 应用编码器 LSTM 1 层于嵌入层输出
# Encoder LSTM 2(编码器 LSTM 2)
encoder_lstm2 = LSTM(latent_dim, return_sequences=True, return_state=True, dropout=0.4, recurrent_dropout=0.4) # 创建第二个编码器 LSTM 层
(encoder_output2, state_h2, state_c2) = encoder_lstm2(encoder_output1) # 应用编码器 LSTM 2 层于第一个编码器 LSTM 输出
# Encoder LSTM 3(编码器 LSTM 3)
encoder_lstm3 = LSTM(latent_dim, return_sequences=True, return_state=True, dropout=0.4, recurrent_dropout=0.4) # 创建第三个编码器 LSTM 层
(encoder_outputs, state_h, state_c) = encoder_lstm3(encoder_output2) # 应用编码器 LSTM 3 层于第二个编码器 LSTM 输出
# 设置解码器部分,使用编码器状态作为初始状态
decoder_inputs = Input(shape=(None, )) # 定义解码器输入,形状为 (None,)
# Embedding layer(嵌入层)
dec_emb_layer = Embedding(y_voc, embedding_dim, trainable=True) # 创建可训练的嵌入层
dec_emb = dec_emb_layer(decoder_inputs) # 应用嵌入层于解码器输入
# Decoder LSTM(解码器 LSTM)
decoder_lstm = LSTM(latent_dim, return_sequences=True, return_state=True, dropout=0.4, recurrent_dropout=0.2) # 创建解码器 LSTM 层
(decoder_outputs, decoder_fwd_state, decoder_back_state) = \
decoder_lstm(dec_emb, initial_state=[state_h, state_c]) # 应用解码器 LSTM 层于嵌入层输出,并传入初始状态
# Dense layer(全连接层)
decoder_dense = TimeDistributed(Dense(y_voc, activation='softmax')) # 创建时间分布的全连接层,使用 softmax 激活函数
decoder_outputs = decoder_dense(decoder_outputs) # 应用全连接层于解码器 LSTM 输出
# 定义模型
model = Model([encoder_inputs, decoder_inputs], decoder_outputs) # 创建模型,输入为编码器和解码器输入,输出为解码器输出
print(model.summary()) # 打印模型摘要信息
# 训练模型
model.compile(optimizer='rmsprop', loss='sparse_categorical_crossentropy') # 编译模型,使用 rmsprop 优化器和稀疏分类交叉熵损失函数
es = EarlyStopping(monitor='val_loss', mode='min', verbose=1, patience=2) # 创建 EarlyStopping 回调函数,监控验证集损失,模式为最小化,显示详细信息,忍耐次数为2次
history = model.fit( # 拟合模型
[x_tr, y_tr[:, :-1]], # 训练数据为编码器输入和解码器输入(截断最后一个词)
y_tr.reshape(y_tr.shape[0], y_tr.shape[1], 1)[:, 1:], # 训练标签为解码器输出(截断第一个词)
epochs=50, # 迭代次数为50轮
callbacks=[es], # 使用 EarlyStopping 回调函数
batch_size=128, # 批大小为128
validation_data=([x_val, y_val[:, :-1]], # 验证数据为编码器输入和解码器输入(截断最后一个词)
y_val.reshape(y_val.shape[0], y_val.shape[1], 1)[:, 1:]), # 验证标签为解码器输出(截断第一个词)
)
# 接下来,绘制在训练阶段观察到的训练和验证损失指标。
from matplotlib import pyplot # 导入 pyplot 模块
# 绘制训练集损失和验证集损失的曲线
pyplot.plot(history.history['loss'], label='train') # 绘制训练集损失曲线,设置标签为 'train'
pyplot.plot(history.history['val_loss'], label='test') # 绘制验证集损失曲线,设置标签为 'test'
pyplot.legend() # 添加图例
pyplot.show() # 显示图像
reverse_target_word_index = y_tokenizer.index_word # 创建反转的目标词索引,用于将索引转换为单词
reverse_source_word_index = x_tokenizer.index_word # 创建反转的源词索引,用于将索引转换为单词
target_word_index = y_tokenizer.word_index # 获取目标词的索引
# 推断模型
# 编码输入序列以获取特征向量
encoder_model = Model(inputs=encoder_inputs, outputs=[encoder_outputs, state_h, state_c]) # 创建编码器模型
# 解码器设置
# 下面的张量将保存上一个时间步长的状态
decoder_state_input_h = Input(shape=(latent_dim, )) # 创建解码器隐藏状态输入张量
decoder_state_input_c = Input(shape=(latent_dim, )) # 创建解码器细胞状态输入张量
decoder_hidden_state_input = Input(shape=(max_text_len, latent_dim)) # 创建解码器隐藏状态输入张量
# 获取解码器序列的嵌入
dec_emb2 = dec_emb_layer(decoder_inputs) # 应用嵌入层于解码器输入
# 为了预测序列中的下一个词,将初始状态设置为上一个时间步长的状态
(decoder_outputs2, state_h2, state_c2) = decoder_lstm(dec_emb2, initial_state=[decoder_state_input_h, decoder_state_input_c]) # 应用解码器 LSTM 层
# 一个密集的 softmax 层生成目标词汇上的概率分布
decoder_outputs2 = decoder_dense(decoder_outputs2) # 应用全连接层于解码器 LSTM 输出
# 最终解码器模型
decoder_model = Model([decoder_inputs] + [decoder_hidden_state_input, decoder_state_input_h, decoder_state_input_c], [decoder_outputs2] + [state_h2, state_c2]) # 创建解码器模型
def decode_sequence(input_seq):
# 将输入编码为状态向量
(e_out, e_h, e_c) = encoder_model.predict(input_seq)
# 生成长度为 1 的空目标序列
target_seq = np.zeros((1, 1))
# 使用起始词填充目标序列的第一个单词
target_seq[0, 0] = target_word_index['sostok']
stop_condition = False # 停止条件为 False
decoded_sentence = '' # 初始化解码后的句子
while not stop_condition: # 当停止条件为 False 时执行循环
(output_tokens, h, c) = decoder_model.predict([target_seq] + [e_out, e_h, e_c]) # 使用解码器模型预测输出
# 采样一个 token
sampled_token_index = np.argmax(output_tokens[0, -1, :]) # 获取最可能的 token 索引
sampled_token = reverse_target_word_index[sampled_token_index] # 获取对应的单词
if sampled_token != 'eostok': # 如果采样的 token 不是结束标记
decoded_sentence += ' ' + sampled_token # 添加到解码后的句子中
# 退出条件:达到最大长度或者找到停止词
if sampled_token == 'eostok' or len(decoded_sentence.split()) >= max_summary_len - 1:
stop_condition = True # 设置停止条件为 True
# 更新目标序列(长度为 1)
target_seq = np.zeros((1, 1)) # 重置目标序列
target_seq[0, 0] = sampled_token_index # 更新为预测的 token 索引
# 更新内部状态
(e_h, e_c) = (h, c) # 更新编码器状态
return decoded_sentence # 返回解码后的句子
# 将序列转换为摘要
def seq2summary(input_seq): # 定义将序列转换为摘要的函数
newString = '' # 初始化新字符串
for i in input_seq: # 遍历输入序列
if i != 0 and i != target_word_index['sostok'] and i != target_word_index['eostok']: # 如果索引不是零、sostok 或 eostok
newString = newString + reverse_target_word_index[i] + ' ' # 添加单词到新字符串
return newString # 返回新字符串
# 将序列转换为文本
def seq2text(input_seq): # 定义将序列转换为文本的函数
newString = '' # 初始化新字符串
for i in input_seq: # 遍历输入序列
if i != 0: # 如果索引不是零
newString = newString + reverse_source_word_index[i] + ' ' # 添加单词到新字符串
return newString # 返回新字符串
# 打印预测结果
for i in range(0, 19): # 遍历前19个序列
print('Review:', seq2text(x_tr[i])) # 打印文本序列
print('Original summary:', seq2summary(y_tr[i])) # 打印原始摘要
print('Predicted summary:', decode_sequence(x_tr[i].reshape(1, max_text_len))) # 打印预测摘要
print('\n') # 打印空行

![[机器学习]练习闵可斯基距离](https://img-blog.csdnimg.cn/direct/07a732525cb646da8393979e0fa5826d.png)